Spark join数据倾斜调优
Spark中常见的两种数据倾斜现象如下
- stage部分task执行特别慢

一般情况下是某个task处理的数据量远大于其他task处理的数据量,当然也不排除是程序代码没有冗余,异常数据导致程序运行异常。
- 作业重试多次某几个task总会失败

常见的退出码143、53、137、52以及heartbeat timed out异常,通常可认为是executor内存被打满。
RDD调优方法
- 查看数据分布
Spark Core中shuffle算子出现数据倾斜时,可在Spark作业中加入查看key分布的代码,也可以将代码拆解出来使用spark-shell做测试
val rdd = sc.parallelize(Array("hello", "hello", "hello", "hi")).map((_,1))// 数据量较少
rdd.reduceByKey(_ + _)
.sortBy(_._2, false)
.take(20)
// 数据量较大, 用sample采样后在统计
rdd.sample(false, 0.1)
.reduceByKey(_+_)
.sortBy(_._2, false)
.take(20)
- 调整shuffle并行度
原理:Spark在做shuffle时,默认使用HashPartitioner(非Hash Shuffle)对数据进行分区。如果并行度设置的不合适如比较小,可能造成大量不相同的key对应的数据被分配到了同一个task上,造成该task所处理的数据远大于其它task,从而造成数据倾斜
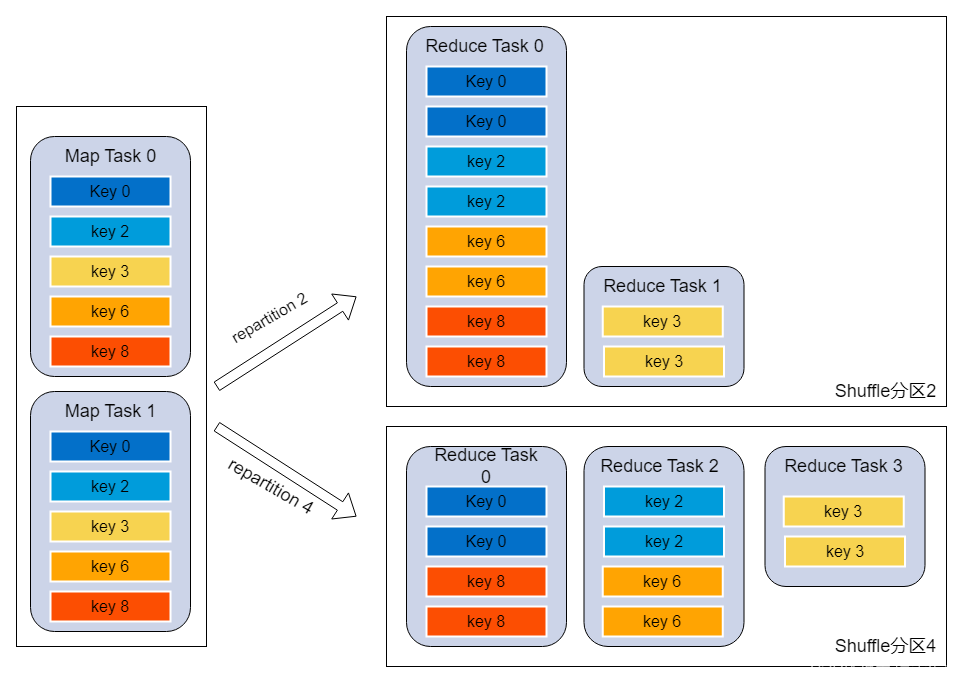
调优建议:
- 使用spark.default.parallelism调整分区数,默认值200建议500或更大
- 在shuffle的算子上直接设置分区数,如:a.join(b, 500)、rdd.reduceByKey(_ + _, 500)
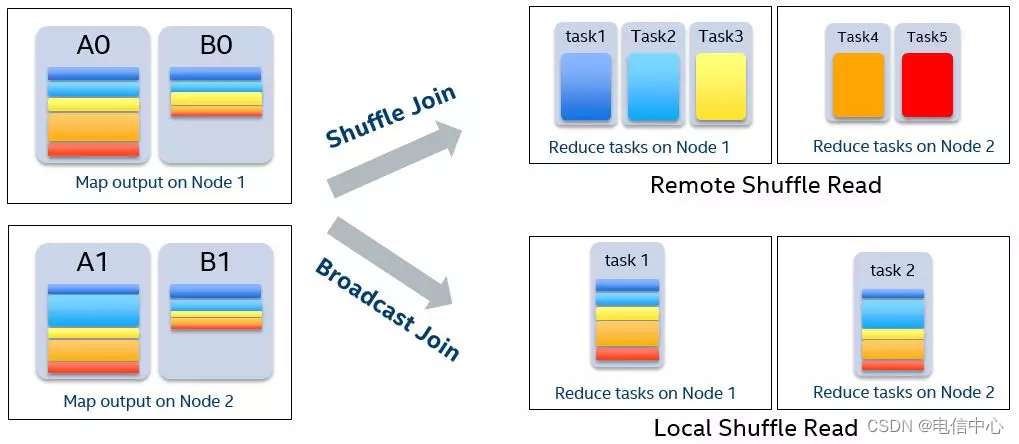
- reduce join转map join
原理:不使用join算子直接进行连接操作,而使用broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的出现
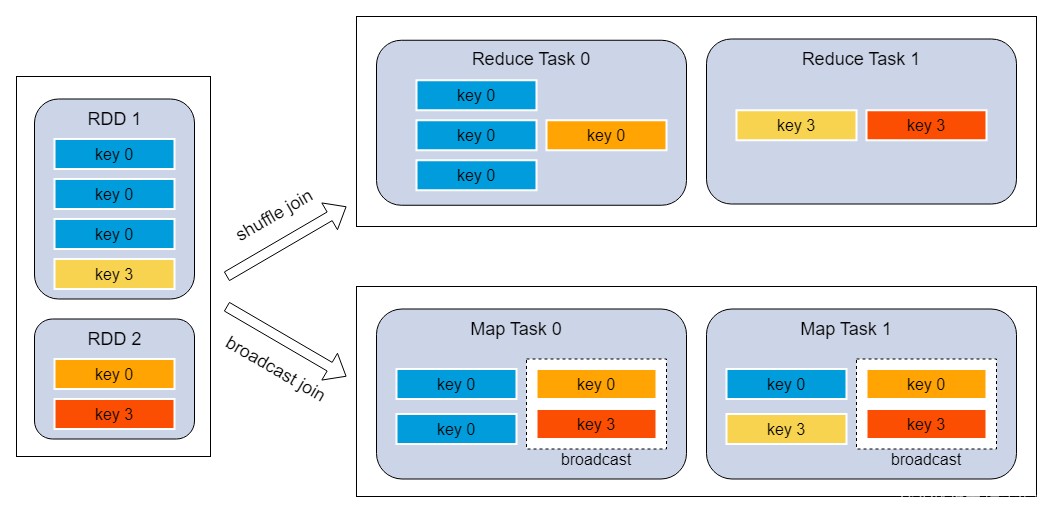
调优建议:
- broadcast的数据量不要超过500M, 过大driver/executor可能会oom
// 1.broadcast小表
val rdd1Broadcast = sc.broadcast(rdd1.collect())
// 2.map join
rdd2.map { x =>val rdd1DataMap = rdd1Broadcast.value.toMaprdd1DataMap.get(x._1) match {case Some(v) => (x._1, (x._2, v))case None => (x._1, (x._2, null))}
}
// 2.或者直接
rdd2.join(rdd1Broadcast)
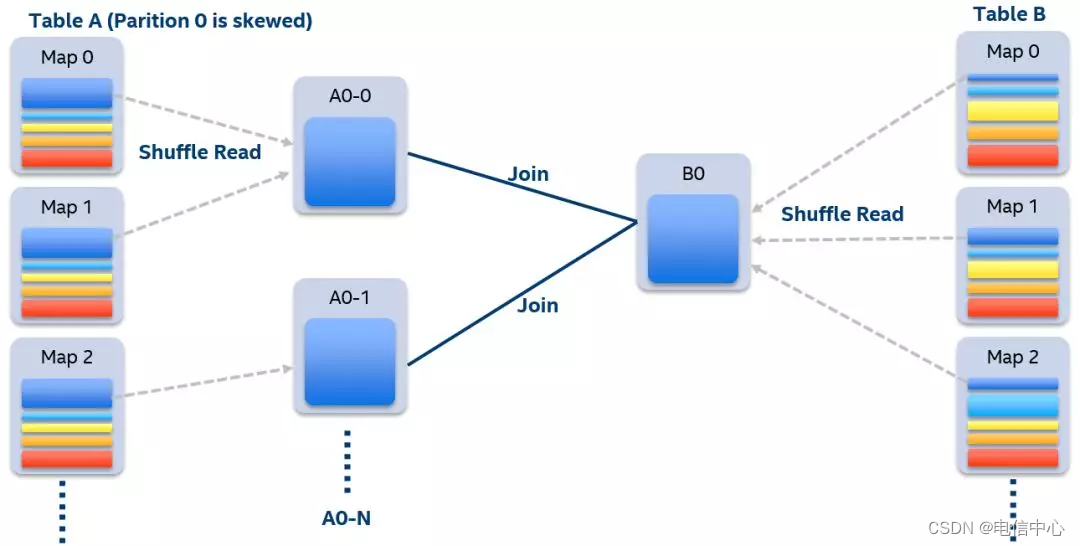
- 分拆join在union
原理:将有数据倾斜的RDD1中倾斜key对应的数据集单独抽取出来加盐(随机前缀),另外一个RDD2每条数据分别与所有的随机前缀结合形成新的RDD(相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者join之后去掉前缀;然后将不包含倾斜key的剩余数据进行join;最后将两次join的结果集通过union合并,即可得到全部join结果。
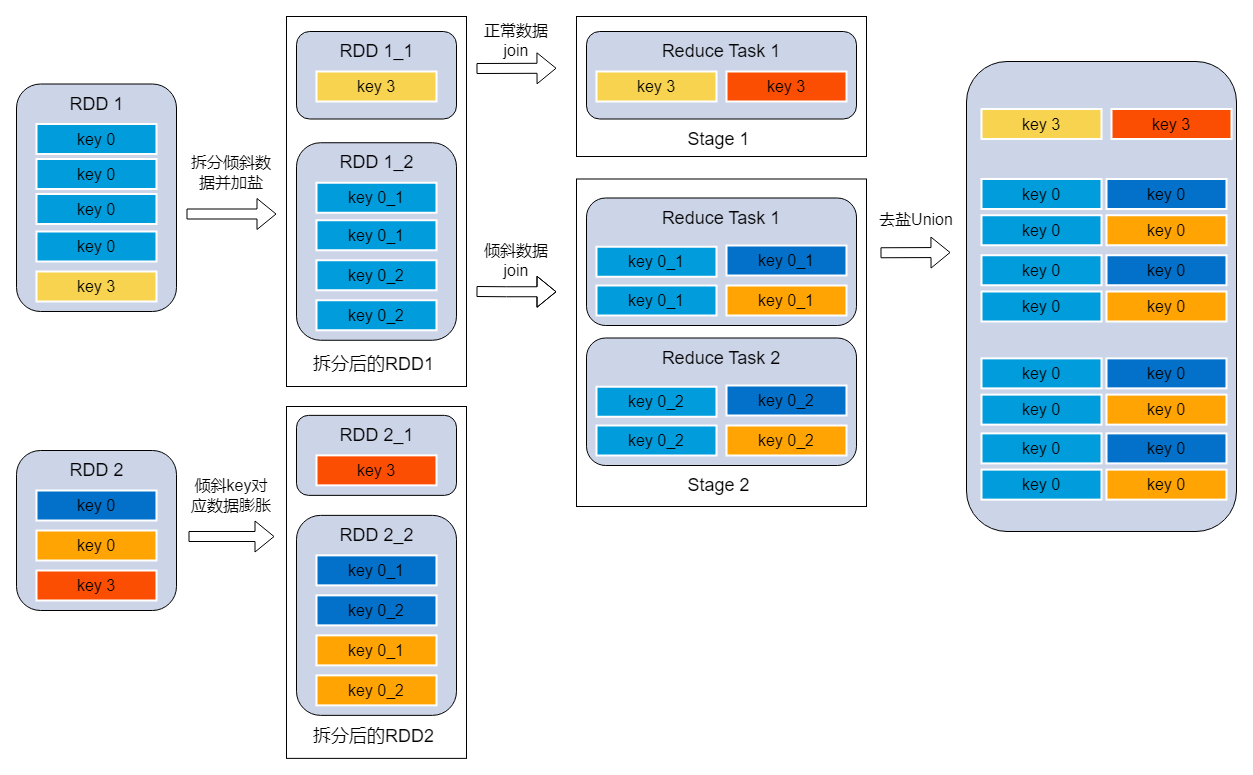
调优建议:
// 1.统计数量最大的key
val skewedKeySet = rdd1.sample(false, 0.2).reduceByKey(_ + _).sortBy(_._2, false).take(10).map(x => x._1).toSet// 2.拆分异常的rdd, 倾斜key加上随机数
val rdd1_1 = rdd1.filter(x => skewedKeySet.contains(x._1)).map { x =>val prefix = scala.util.Random.nextInt(10).toString(s"${prefix}_${x._1}", x._2)
}
val rdd1_2 = rdd1.filter(x => !skewedKeySet.contains(x._1))// 3.正常rdd存在倾斜key的部分进行膨胀
val rdd2_1 = rdd2.filter(x => skewedKeySet.contains(x._1)).flatMap { x =>val list = 0 until 10list.map(i => (s"${i}_${x._1}", x._2))}val rdd2_2 = rdd2.filter(x => !skewedKeySet.contains(x._1))// 4.倾斜key的rdd进行join
val skewedRDD = rdd1_1.join(rdd2_1).map(x => (x._1.split("_")(1), x._2))
// 5.普通key的rdd进行join
val sampleRDD = rdd1_2.join(rdd2_2)
// 6.结果union
skewedRDD.union(sampleRDD)
SQL调优方法
- 查看数据分布
统计某个查询结果或表中出现次数超过200次的key
WITH a AS (${query})
SELECT k,s
FROM (SELECT ${key} AS k,count(*) AS sFROM aGROUP BY ${key}
)
WHERE s > 200
- 自动调整shuffle并行度
原理:自适应执行开启的前提下(AQE),假设我们设置的shuffle partition个数为5,在map stage结束之后,我们知道每一个partition的大小分别是70MB,30MB,20MB,10MB和50MB。假设我们设置每一个reducer处理的目标数据量是64MB,那么在运行时,我们可以实际使用3个reducer。第一个reducer处理partition 0 (70MB),第二个reducer处理连续的partition 1 到3,共60MB,第三个reducer处理partition 4 (50MB)
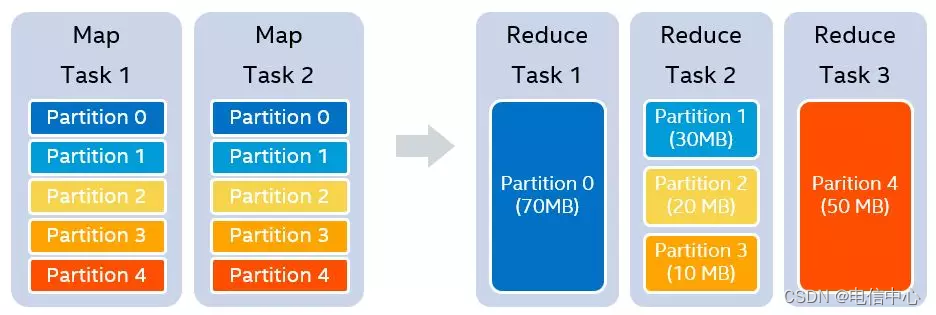
Spark参数:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| spark.sql.adaptive.enabled | 开启自适应执行 | 线上默认值true |
| spark.sql.adaptive.coalescePartitions.minPartitionNum | 自适应执行中使用的最小shuffle后分区数,默认值executor*core数 | 无 |
| spark.sql.adaptive.coalescePartitions.initialPartitionNum | 合并前的初始shuffle分区数量,默认值spark.sql.shuffle.partitions | 无 |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 合并小分区到建议的目标值, 默认256m | 无 |
| spark.sql.shuffle.partitions | join等操作分区数,默认值200 | 推荐500或更大 |
- 自动优化Join
原理:自适应执行开启的前提下(AQE),我们可以获得SortMergeJoin两个子stage的数据量,在满足条件的情况下,即一张表小于broadcast阈值,可以将SortMergeJoin转化成BroadcastHashJoin
| 参数 | 说明 | 推荐值 |
|---|---|---|
| spark.sql.adaptive.enabled | 开启自适应执行 | 线上默认值true |
| spark.sql.autoBroadcastJoinThreshold | 默认10M,设置为-1可以禁用广播;实际根据hive表存储的统计信息或文件预估大小与此值做判断看是否做broadcast,由于文件是压缩格式一般情况下此参数并不可靠 | 建议膨胀系数spark.sql.sources.fileCompressionFactor=10推荐此参数保持默认,调整自适应的broadcast参数 |
| spark.sql.adaptive.autoBroadcastJoinThreshold | 此参数仅影响自适应执行阶段join优化时broadcast阈值;设置为-1可以禁用广播;默认值spark.sql.autoBroadcastJoinThreshold | 自适应执行得到的数据比较准确,driver内存足够的前提下可以将此值调大如200M |
- 自动处理数据倾斜
原理:自适应执行开启的前提下(AQE),我们可以在运行时很容易地检测出有数据倾斜的partition。当执行某个stage时,我们收集该stage每个mapper 的shuffle数据大小和记录条数。如果某一个partition的数据量或者记录条数超过中位数的N倍,并且大于某个预先配置的阈值,我们就认为这是一个数据倾斜的partition,需要进行特殊的处理
| 参数 | 说明 | 推荐值 |
|---|---|---|
| spark.sql.adaptive.enabled | 开启自适应执行 | 线上默认值true |
| spark.sql.adaptive.skewJoin.enabled | 开启自动解决数据倾斜,默认值true | 无 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 影响因子,某分区数据大小超过所有分区中位数与影响因子乘积,才会被认为发生了数据倾斜 | 无 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 视为倾斜分区的分区数据最小值 | 无 |
相关文章:
Spark join数据倾斜调优
Spark中常见的两种数据倾斜现象如下 stage部分task执行特别慢 一般情况下是某个task处理的数据量远大于其他task处理的数据量,当然也不排除是程序代码没有冗余,异常数据导致程序运行异常。 作业重试多次某几个task总会失败 常见的退出码143、53、137…...

YOLOv5初学者问题——用自己的模型预测图片不画框
如题,我在用自己的数据集训练权重模型的时候,在训练完成输出的yolov5-v5.0\runs\train\exp2目录下可以看到,在训练测试的时候是有输出描框的。 但是当我引用训练好的best.fangpt去进行预测的时候, 程序输出的图片并没有描框。根据…...
【linux学习---1】点亮一个LED---驱动一个GPIO
文章目录 1、原理图找对应引脚2、IO复用3、IO配置4、GPIO配置5、GPIO时钟使能6、总结 1、原理图找对应引脚 从上图 可以看出, 蜂鸣器 接到了 BEEP 上, BEEP 就是 GPIO5_IO05 2、IO复用 查找IMX6UL参考手册 和 STM32一样,如果某个 IO 要作为…...

Redis分布式锁代码实现详解
引言 在分布式系统中,资源竞争和数据一致性问题常常需要通过锁机制来解决。Redis作为一个高性能的键值存储系统,因其提供的原子操作、丰富的数据结构以及网络延迟低等特点,成为了实现分布式锁的理想选择。本文将详细介绍如何使用Redis来实现…...
Day01-02-gitlab
Day01-02-gitlab 1. 什么是gitlab2. Gitlab vs Github/Gitee3. Gitlab 应用场景4. 架构5. Gitlab 快速上手指南5.0 安装要求5.1 安装Gitlab组件5.3 配置访问url5.6 初始化5.8 登录与查看5.9 汉化5.10 设置密码5.11 目录结构5.12 删除5.13 500 vs 5025.14 重置密码 6. Gitlab用户…...

PyCharm远程开发配置(2024以下版本)
目录 PyCharm远程开发配置 1、清理远程环境 1.1 点击Setting 1.2 进入Interpreter 1.3 删除远程环境 1.4 删除SSH 2、连接远程环境 2.1 点击Close Project 2.2 点击New Project 2.3 项目路径设置 2.4 SSH配置 2.5 选择python3解释器在远程环境的位置 2.6 配置远程…...

解决Ucharts在小程序上的层级过高问题
<qiun-wx-ucharts canvas2d"{{true}}" type"pie" opts"{{rectificationRateOpts}}" chartData"{{rectificationRateData}}" /> 开启2d渲染即可解决(在小程序开发工具上看着层级还是高,但是在手机上是正常…...

重保期间的网站安全防护:网站整站锁的应用与实践
标题:重保期间的网站安全防护:网站整站锁的应用与实践 一、引言 在重大活动或事件(通常被称为“重保”)期间,网站的安全问题尤为突出。由于此时网站的访问量和关注度可能达到高峰,因此也成为了黑客攻击的…...

Qt自定义类型
概述 在使用Qt创建用户界面时,特别是那些具有特殊控件和特性的界面时,开发人员有时需要创建新的数据类型,以便与Qt现有的值类型集一起使用或代替它们。 QSize、QColor和QString等标准类型都可以存储在QVariant对象中,作为基于qo…...
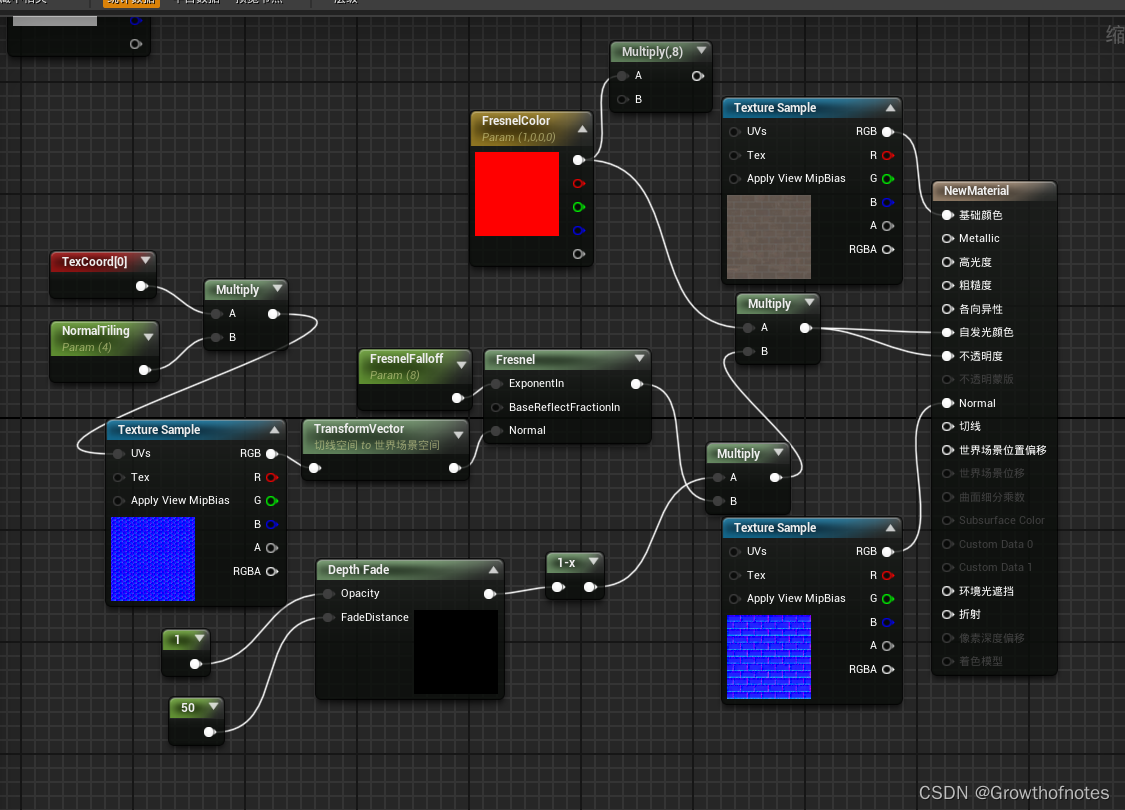
UE4_材质_材质节点_DepthFade
一、DepthFade参数 DepthFade(深度消退)表达式用来隐藏半透明对象与不透明对象相交时出现的不美观接缝。 项目说明属性消退距离(Fade Distance)这是应该发生消退的全局空间距离。未连接 FadeDistance(FadeDistance&a…...
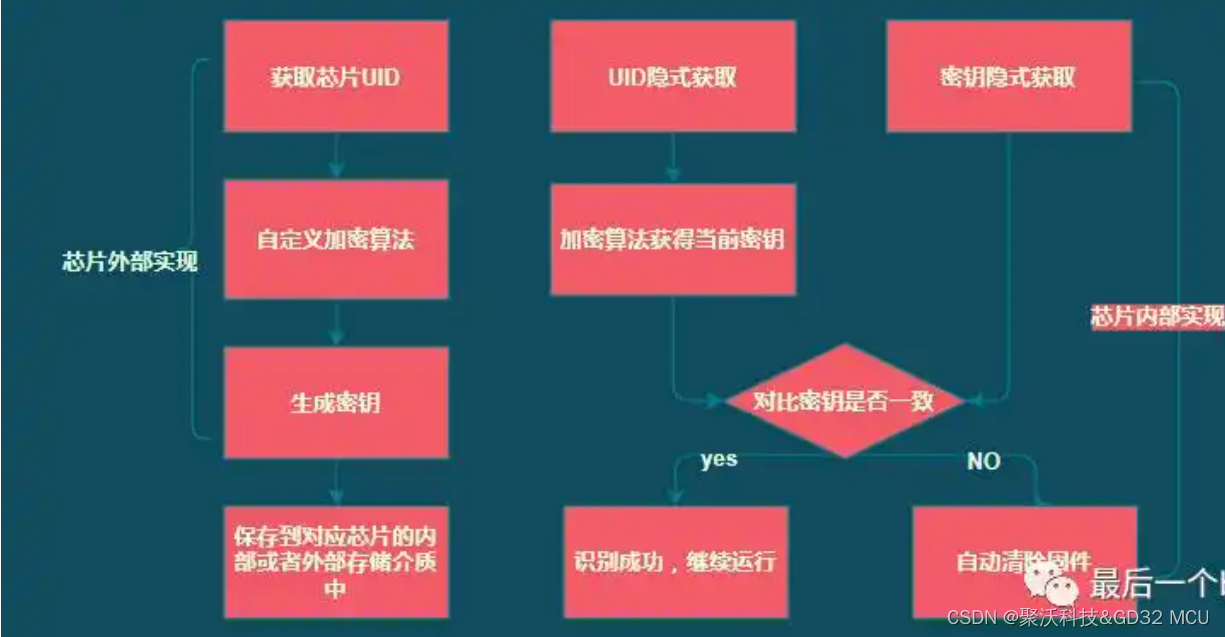
如何对GD32 MCU进行加密?
GD32 MCU有哪些加密方法呢?大家在平时项目开发的过程中,最后都可能会面临如何对出厂产品的MCU代码进行加密,避免产品流向市场被别人读取复制。 下面为大家介绍GD32 MCU所支持的几种常用的加密方法: 首先GD32 MCU本身支持防硬开盖…...
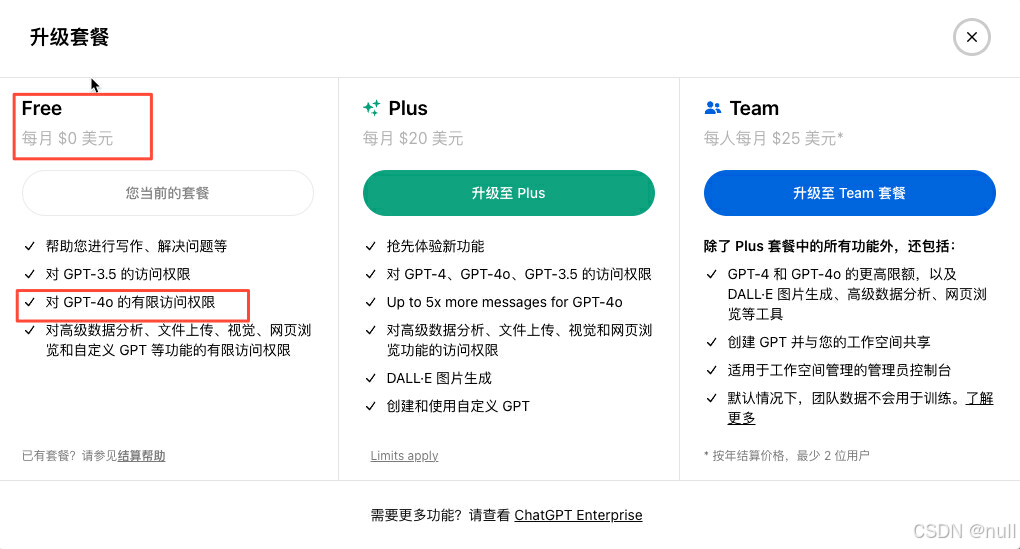
快速了解GPT-4o和GPT-4区别
GPT-4o简介 在5月14日的OpenAI举行春季发布会上,OpenAI在活动中发布了新旗舰模型“GPT-4o”!据OpenAI首席技术官穆里穆拉蒂(Muri Murati)介绍,GPT-4o在继承GPT-4强大智能的同时,进一步提升了文本、图像及语…...

周末休息日也能及时回应客户消息!微信自动回复神器太就好用啦!
无论是在忙碌时,还是在周末休息日,如果没能及时回应客户,很可能会造成客户流失。 今天,我要为大家介绍一个多微管理神器——个微管理系统,它可以帮助你实现自动回复,提高回复效率。 自动通过好友请求 在…...

力扣404周赛 T1/T2/T3 枚举/动态规划/数组/模拟
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 3200.三角形的最大高度【简单】 题目: 给你两个整数 red 和 b…...

Taurus 性能测试工具详解
文章目录 简介原理安装编写测试配置运行测试集成其他工具结果分析优点与缺点优点缺点 参考资料总结 简介 Taurus 是一个开源的自动化测试工具,用于简化和增强性能测试流程。与其他性能测试工具不同,Taurus 旨在通过友好的 YAML 配置文件和对多种负载测试…...
)
天猫商品详情API接口(店铺|标题|主图|价格|SKU属性等)
天猫商品详情API接口为开发者提供了获取天猫商品详细信息的能力,包括店铺信息、商品标题、主图、价格、SKU属性等。以下是该接口的使用过程和相关技术要点: 注册账号并创建应用 注册账号:需要在天猫开放平台注册一个开发者账号。创建应用&a…...
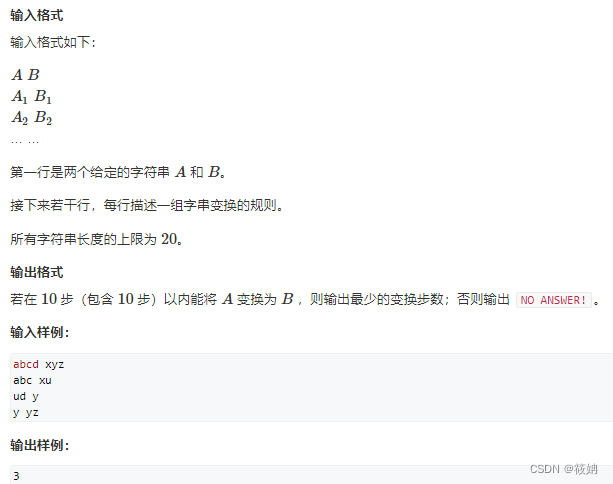
双向广搜——AcWing 190. 字串变换
双向广搜 定义 双向广度优先搜索(Bi-directional Breadth-First Search, Bi-BFS)是一种在图或树中寻找两点间最短路径的算法。与传统的单向广度优先搜索相比,它从起始点和目标点同时开始搜索,从而有可能显著减少搜索空间&#x…...

工商业光伏项目如何快速开发?
一、前期调研与规划 1、屋顶资源评估:详细测量屋顶面积、承重能力及朝向,利用光伏业务管理软件进行日照分析和发电量预测,确保项目可行性。 2、政策与补贴研究:深入了解当地政府对工商业光伏项目的政策支持和补贴情况࿰…...
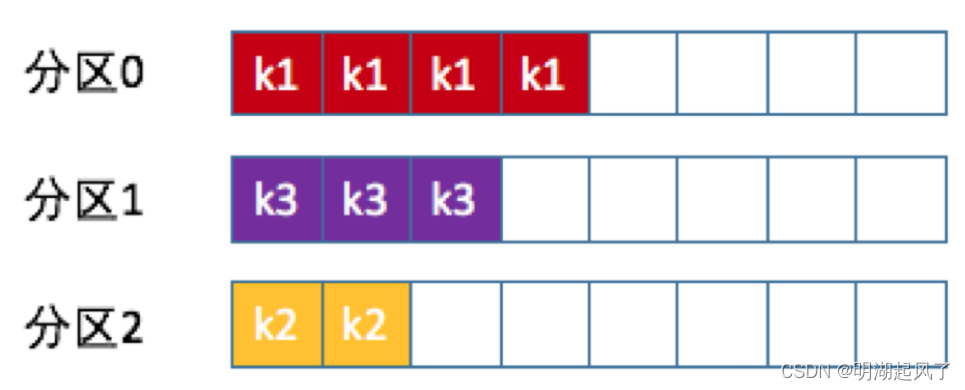
Kafka入门-分区及压缩
一、生产者消息分区 Kafka的消息组织方式实际上是三级结构:主题-分区-消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。 分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为…...

被⽹络罪犯利⽤的5⼤ChatGPT越狱提⽰
⾃ChatGPT发布的近18个月以来,⽹络罪犯们已经能够利⽤⽣成式AI进⾏攻击。OpenAI在其内容政策中制定了限制措施,以阻⽌⽣成恶意内容。作为回应,攻击者们创建了⾃⼰的⽣成式AI平台,如 WormGPT和FraudGPT,并且他们还分享了…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

树莓派工业GPIO接口板:电气隔离与电平转换实战指南
1. 项目概述:为什么需要一块工业级GPIO接口板?如果你用树莓派做过一些硬件项目,尤其是涉及到控制继电器、电机或者连接工业设备(比如PLC、变频器)时,大概率踩过这样的坑:直接用树莓派的GPIO引脚…...

taotoken用量看板如何帮助团队精细化管理api调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken用量看板如何帮助团队精细化管理api调用成本 对于团队管理者而言,将大模型能力集成到产品开发或业务流程中&am…...