【01-02】Mybatis的配置文件与基于XML的使用
1、引入日志
- 在这里我们引入SLF4J的日志门面,使用logback的具体日志实现;
- 引入相关依赖:
<!--日志的依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.30</version></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency>
- 添加logback的配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true"><!--追加器:日志以哪种方式输出,name:自定义追加器的名称,class:追加器实现类的全限定名(不同实现类输出的方式不同,下面是以控制台方式输出)--><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><encoder><!--设置日志输出格式--><pattern>%d{YYYY-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} ---> %msg%n</pattern><charset>UTF-8</charset></encoder></appender><!--设置全局日志级别--><root level="INFO"><!--设置当前日志级别输出到哪个追加器上--><appender-ref ref="CONSOLE" /></root><!--设置某个包或者某个类的局部日志级别--><logger name="org.example.mapper" level="debug" /><logger name="org.apache.ibatis.transaction" level="debug" /></configuration>
- 测试结果:

2、全局配置文件
在mybatis的项目中,有一个mybatis-config.xml的配置文件,这个配置文件是mybatis的全局配置文件,用来进行相关的全局配置。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><properties resource="db.properties"></properties><settings> </settings><typeAliases> </typeAliases><environments></environments><mappers></mappers>
</configuration>
1、propertis(属性)
<!--配置外部属性资源文件,通过 ${} 来进行引用--><properties resource="db.properties"><!--也可以在内部自定义属性--><property name="driver" value="com.mysql.cj.jdbc.Driver"/><property name="url" value="jdbc:mysql://localhost:3306/trs-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull"/><property name="username" value="root"/><property name="password" value="rootxq"/></properties>
2、setting(设置)
<settings><!-- 设置默认执行器:SIMPLE(普通执行器)、REUSE(可重复使用执行器,会重用预处理语句)、BATCH(批量执行器,不仅重用预处理语句,而且可以批量更新)--><setting name="defaultExecutorType" value="SIMPLE"/><!-- 开启驼峰命名自动映射--><setting name="mapUnderscoreToCamelCase" value="true"/><!-- 在懒加载下,哪些方法会触发立即加载,默认:equals、toString、hashCode--><!--<setting name="lazyLoadTriggerMethods" value=""/>--><!-- 开启全局的延迟加载:true 所有的嵌套查询都是懒加载,false 所有嵌套查询都会被立即加载--><setting name="lazyLoadingEnabled" value="true"/><!-- 设置加载的数据是否按需加载--><setting name="aggressiveLazyLoading" value="false"/><!-- 开启二级缓存--><setting name="cacheEnabled" value="true"/></settings>
3、typeAliases(类型别名)
<!--设置类的别名,可以降低冗余的全局限定名的书写--><typeAliases><!--1、可以设置包下所有类的别名:会使用类名作为别名(是忽略大小写的)--><!--<package name="org.example.pojo"/>--><!--2、可以自定义设置某个类的别名--><typeAlias type="org.example.pojo.Emp" alias="emp"/><typeAlias type="org.example.pojo.Dept" alias="dept"/></typeAliases>
4、environments(环境配置)
<!--配置数据源连接信息--><!--可以配置多个数据源(environment),例如:测试环境、生产环境各配置一个数据源,default:设置默认使用哪个数据源--><environments default="development"><environment id="development"><!--事务管理器:type 设置事务管理类型(1)JDBC:使用JDBC的事务管理方式(2)MANAGED:不运用事务 --><transactionManager type="JDBC"/><!--数据源:type 设置数据源类型(1)UNPOOLED:不使用连接池(2)POOLED:使用Mybatis的连接池--><dataSource type="POOLED"><property name="driver" value="${db.driver}"/><property name="url" value="${db.url}"/><property name="username" value="${db.username}"/><property name="password" value="${db.password}"/></dataSource></environment></environments>
5、mappers(映射器)
<!--映射器:有4种配置方式--><mappers><!--1、设置MapperXML的方式,适用于根据statementId进行操作--><mapper resource="mapper/DeptMapper.xml"/><mapper resource="mapper/EmpMapper.xml"/><!--2、设置Mapper接口的方式,适用于接口绑定的方式--><!--<mapper class="org.example.mapper.EmpMapper"/>--><!--<mapper class="org.example.mapper.DeptMapper"/>--><!--3、使用磁盘的绝对路径(基本不用)--><!--4、根据包路径设置该包下的所有Mapper接口,适用于接口绑定和注解的方式(应用最多的方式)--><!--<package name="org.example.mapper"/>--></mappers>
3、SQL映射文件
- MyBatis 的真正强大之处在于它的语句映射。由于它的异常强大,映射器的XML 文件就显得相对简单。MyBatis 致力于减少使用成本,让用户能更专注于 SQL 代码。
- 映射文件中极其重要的几大标签:
select:映射查询语句insert:映射插入语句update:映射更新语句delete:映射删除语句sql:定义可重用的sql语句;cache:设置当前命名空间下的缓存配置;cache-ref:引用其他命名空间下的缓存配置;resultMap:描述如何从数据库的结果集中加载对象;
- 每个顶级元素标签中可以添加很多个属性,下面介绍相关属性的作用
- (1)id:设置当前命名空间中各个映射标签的唯一标识符(同一个命名空间中的id不允许重复,对应mapper接口中的方法名称);
- (2)paramType:设置SQL的参数类型(mybatis会根据接口方法的参数自动读取参数的类型,所以不强制要求设置);
- (3)statementType:设置当前的Statement类型(默认为PREPARED):
- STATEMENT:代表JDBC的Statement,不支持参数预解析;
- PREPARED:代表JDBC的PreparedStatement,支持参数预解析;
- CALLABLE:代表JDBC的CallableStatement,支持存储过程调用;
- (4)useGeneratedKeys:启用主键生成策略,设置是否获取插入后的自增长主键的值,默认是false,设置为true时,才会获取自增长主键的值;
- (5)keyProperty:设置将获取到的自增长主键值映射到实体类的哪个属性上;
- (6)keyColumn:如果存在组合主键的情况,指定获取哪个主键的字段名;
- 例如:
<insert id="insertEmp" useGeneratedKeys="true" keyProperty="eId" ><!--如果数据库不支持列值自增长的话,可以使用下面的方法:selectKey:可以在增删改操作之前或者之后执行相关属性:order:设置执行时机(BEFORE表示之前,AFTER表示之后)keyProperty:设置将当前查询结果放到哪个POJO的属性上resultType:设置返回值的类型--><selectKey order="BEFORE" keyProperty="eId" resultType="int">SELECT MAX(eid)+1 FROM emp</selectKey>INSERT INTO emp (eid,e_name,e_mail,salary,did) values (#{eId},#{eName},#{eMail},#{salary},#{did})</insert>
4、基于XML的详细使用
- POJO实体类
public class Emp{private Integer eId;private String eName;private String eMail;private Double salary;private Integer did; }public class Dept{private Integer did;private String dName; }
1、参数的获取方式
#{}==> sql = “SELECT * FROM emp WHERE eid = ?”- a、会经过JDBC中的PreparedStatement对象进行预编译处理,会根据不同的数据类型来编译成对应数据库所对应的数据类型;
例如:String id = “100010”,#{id} ==> sql = "SELECT * FROM emp WHERE eid = ‘100010’;
例如:Integer id = 100010,#{id} ==> sql = "SELECT * FROM emp WHERE eid = 100010; - b、能够有效的防止SQL注入;
- a、会经过JDBC中的PreparedStatement对象进行预编译处理,会根据不同的数据类型来编译成对应数据库所对应的数据类型;
${}==> sql = “SELECT * FROM emp WHERE eid =” + id;- a、不会进行预编译,会直接将获取到的的参数直接拼接在sql中;
- b、存在SQL注入的风险;
- 特殊用法:
(1)调试时可以临时使用,这样可以直接将携带参数的完整sql语句打印在控制台;
(2)需要动态拼接的时候,可以使用${},但是要在保证数据的安全性的前提下操作;
2、参数的传递方式
-
单个参数的传递:
-
(1)参数类型是普通数据类型时:使用
#{参数名称}来获取参数,即:#{id};public interface EmpMapper {Emp selectEmpById(Integer id); }<select id="selectEmpById" resultMap="empResultSet">select * from emp where eid = #{id}</select> -
(2)参数类型是javaBean时:使用
#{属性名}来获取参数,emp.eId ==> #{eId}, emp.eName ==> #{eName}public interface EmpMapper {Emp selectEmpInfo(Emp emp);}<select id="selectEmpInfo" resultType="org.example.pojo.Emp">select * from emp where eid = #{eId} and e_name = #{eName}</select> -
(3)参数类型是数组或者list集合时:mybatis会自动封装成map
- 数组:{key:array,value:array},获取方式:
#{arg0.下标}或者#{array.下标} - 集合:{key:list,value:list},获取方式:
#{arg0.下标}或者#{list.下标} - 如果方法中使用了@Param()注解来指定别名,则获取方式为:
#{别名.下标}
public interface EmpMapper {List<Emp> selectEmpByNames(List<String> names);}<select id="selectEmpByNames" resultType="org.example.pojo.Emp">select * from emp where e_name in (#{arg0.0}, #{list.1}, #{arg0.2}) </select> - 数组:{key:array,value:array},获取方式:
- (4)参数类型是map集合时:与javaBean的参数传递情况一样;
public interface EmpMapper {Emp selectEmpByMap(Map<String,Object> paramMap); }Map<String, Object> paramMap = new HashMap<>();paramMap .put("id",1);paramMap .put("ename","lq");<select id="selectEmpByMap" resultType="org.example.pojo.Emp">select * from emp where eid = #{id} and e_name = #{ename}</select>
-
-
多个参数的传递
- mybatis会对参数按顺序进行封装,将参数封装成map集合;
public interface EmpMapper {Emp selectEmpByIdAndName( Integer id, String ename); }- id ==> {key : arg0,value : id的值} 或者 {key : param1,value : id的值}
- ename ==> {key : arg1,value : ename的值} 或者 {key : param2,value : ename的值}
- 可以使用
#{key}来获取对应的值,
<select id="selectEmpByIdAndName" resultType="org.example.pojo.Emp">select * from emp where eid = #{arg0} and e_name = #{param2} </select>
- 可以给每个参数设置别名,使其具有参数意义:
- 语法:使用注解:
@Param("参数别名")
public interface EmpMapper {Emp selectEmpByIdAndName( @Param("id")Integer id, @Param("ename")String ename); }- id ==> #{id} 或者 #{param1}
- ename ==> #{ename} 或者 #{param2}
- 可以使用
#{参数别名}来获取对应的值
<select id="selectEmpByIdAndName" resultType="org.example.pojo.Emp">select * from emp where eid = #{id} and e_name = #{ename}</select> - 语法:使用注解:
- 如果是参数类型既有普通数据类型又有javaBean时:
public interface EmpMapper {Emp selectEmpInfoByDid(Integer did,@Param("emp") Emp emp); }- id ==> #{param1} 或者 @Param(“did”)
- emp.eName ==> #{param2.eName} 或者 emp.eName
- 注意:多个参数时,获取JavaBean中的属性时,使用#{参数别名.属性名};
<select id="selectEmpInfoByDid" resultType="org.example.pojo.Emp">select * from emp where did = #{param1} and e_name = #{emp.eName}</select>
- mybatis会对参数按顺序进行封装,将参数封装成map集合;
3、处理返回结果
- 返回类型设置:
- 如果返回单行数据,可是使用Java基础数据类型或者POJO或者Map接收;
- 如果返回多行数据,可以使用List< POJO>或者List< Map >接收,需要在
resultType中指定List中的泛型类型;
- 当返回结果是集合的时候,返回值的类型依然写的是集合中具体的类型
<select id="selectAllEmp" resultType="org.example.pojo.Emp">select * from emp</select> - 在查询时可以设置返回值的类型为map,当mybatis查询完成之后会把列的名称作为key,列的值作为value,转换到map中;
<select id="selectEmpByEmpReturnMap" resultType="map">select * from emp where empno = #{empno} </select>
4、自定义结果集
- 如果数据库表的字段与POJO的属性名不一致时,除了可使用
'AS'来设置别名,还可以使用resultMap来设置自定义结果集,注意:resultType与resultMap二者只能使用其一。 - 相关属性:
id:唯一标识,需要与select标签中的resultMap进行关联;type:需要映射的Pojo类型;autoMapping:是否自动映射,默认为false,只要字段名与属性名遵循映射规则就可以自动映射;extends:如果同一命名空间内,如果有多个resultMap有重复的映射,可以声明父resultMap,将公共的映射提取出来,可以减少子resultMap的映射冗余;
<resultMap id="empResultSet" type="org.example.pojo.Emp"><!--<id>:用来指定主键字段的映射关系<result>:用来指定普通字段的映射关系column:需要映射的数据库表中字段的名称property:需要映射的POJO中的属性名称--><id column="eid" property="eId"/><result column="e_name" property="eName"/><result column="e_mail" property="eMail"/><result column="salary" property="salary"/><result column="did" property="did"/></resultMap><select id="selectEmp" resultMap="empResultSet">select * from emp where did = #{dept_id}</select>
5、高级结果映射
1、联合查询
public class EmpDeptDto extends Emp{private Dept dept;public Dept getDept() {return dept;}public void setDept(Dept dept) {this.dept = dept;}@Overridepublic String toString() {return super.toString() + "EmpDeptDto{" +"dept=" + dept +'}';}
}
1、多对一映射
- 查询所有员工的信息以及对应的部门(多员工同属一个部门)
<resultMap id="empAndDeptMap" extends="empResultSet" type="org.example.pojo.EmpDeptDto"><!--普通方式:对象属性名.属性--><!--<result property="dept.dName" column="d_name"/>--><!--<result property="dept.did" column="did"/>--><!--association方式:会强行使我们的结果映射为多对一property:指定的“一”javaType:“一“的类型(自定义映射的时候才需要指定,与resultType二者使用其一)resultMap:调用已经存在的映射关系(重用resultMap)columnPrefix: 如果出现两张表的字段有重复时,则需要使用as来起别名,可以给字段加上前缀,在映射的时候,可以使用columnPrefix自动将前缀去掉,这样就能映射成功--><association property="dept" columnPrefix="dept_" javaType="org.example.pojo.Dept" resultMap="org.example.mapper.DeptMapper.baseDeptMap"><!--<id property="did" column="did"/>--><!--<result property="dName" column="d_name"/>--></association></resultMap><select id="selectEmpAndDept" resultMap="empAndDeptMap">SELECTe.*,d.did AS dept_did,d.d_name AS dept_d_nameFROMemp AS eLEFT JOIN dept AS d ON e.did = d.did</select>
2、一对多映射
- 查询部门信息以及所属的员工信息(一个部门包含多个员工)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""https://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="org.example.mapper.DeptMapper"><resultMap id="baseDeptMap" type="org.example.pojo.Dept"><id column="did" property="did"/><result column="d_name" property="dName"/></resultMap><!--一对多映射关系property:指定的“多”ofType:“多”的类型(自定义映射的时候才需要指定,与resultType二者使用其一)resultMap:调用已经存在的映射关系(重用resultMap)无论是association还是collection,都需要查询主键值--><resultMap id="deptAndEmpMap" extends="baseDeptMap" type="org.example.pojo.DeptEmpDto"><collection property="emps" ofType="org.example.pojo.Emp" resultMap="org.example.mapper.EmpMapper.empResultSet"><!--也可以自定义映射关系--><!--<id column="eid" property="eId"/>--><!--<result column="e_name" property="eName"/>--><!--<result column="e_mail" property="eMail"/>--><!--<result column="salary" property="salary"/>--><!--<result column="did" property="did"/>--></collection></resultMap><select id="getDeptAndEmp" resultMap="deptAndEmpMap">SELECTd.*,e.*FROM dept d LEFT JOIN emp eON d.did = e.did</select>
</mapper>
2、嵌套查询
<!--嵌套查询:分步查询select:查询关联对象的sql语句column:需要传递的参数值的字段fetchType:懒加载(延迟查询):嵌套查询的对象用到的时候才回去查询数据--><resultMap id="queryDeptAndEmpMap" type="org.example.pojo.DeptEmpDto" extends="baseDeptMap"><collection property="emps" fetchType="lazy" select="org.example.mapper.EmpMapper.selectEmp" column="did"/></resultMap><select id="queryDeptAndEmp" resultMap="queryDeptAndEmpMap">select * from dept</select>
3、延迟查询
- 当我们在进行表关联的时候,有可能在查询结果的时候不需要关联对象的属性值,那么此时可以通过延迟加载来实现功能。在全局配置文件中添加如下属性:
<!‐‐ 开启延迟加载,所有分步查询都是懒加载 (默认是立即加载)‐‐><setting name="lazyLoadingEnabled" value="true"/><!‐‐当开启式, 使用pojo中任意属性都会加载延迟查询 ,默认是false<setting name="aggressiveLazyLoading" value="false"/>‐‐><!‐‐设置对象的哪些方法调用会加载延迟查询 默认:equals,clone,hashCode,toString‐‐><setting name="lazyLoadTriggerMethods" value=""/>
- 如果设置了全局加载,但是希望在某一个sql语句查询的时候不使用延时策略,可以添加fetchType下属性;
<association property="dept" column="dept_id" fetchType="eager" resultMap="org.example.mapper.DeptMapper.baseDeptMap"></association>
6、动态SQL
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
如果出现SQL语句中因特殊字符报错的话,可以使用转义字符或者<![CDATA[]]>来解决
1、动态SQL之if
- 语法:
< if test="条件表达式 可以是OGNL表达式">< /if> - 作用:完成简单的条件判断,加载动态条件
- 问题:如果无法确定第一个条件是否成立,导致无法确定是否拼接 and或者or 的拼接
- (1)可以设置 1=1 避免报错
- (2)可以使用< where>标签,它会自动拼接或者删除and或者or
- (3)可以使用< trim>标签
<select id="queryEmps" resultType="org.example.pojo.Emp">select * from emp where 1=1<if test="salary != null and salary != ''">AND salary <![CDATA[<=]]> #{salary}</if><if test="eName != null and salary != ''">AND e_name = #{eName}</if><if test="eId != null and salary != ''">AND eid = #{eId}</if> </select>
2、动态SQL之where
- 语法:
< where>< /where> - 作用:如果存在条件则自动拼接where关键字,也可以动态的删除条件语句中的and或者or
<select id="queryEmps" resultType="org.example.pojo.Emp">select * from emp <where><if test="salary != null and salary != ''">AND salary <![CDATA[<=]]> #{salary}</if><if test="eName != null and salary != ''">AND e_name = #{eName}</if><if test="eId != null and salary != ''">AND eid = #{eId}</if></where></select>
3、动态SQL之trim
- 语法:
< trim prefix="" prefixOverrides="" suffix="" suffixOverrides="">< /trim> - 作用:它的功能比较灵活、广泛,可以在条件判断完的SQL语句前后添加或者去掉指定的字符
- 相关属性:
- prefix:前缀,需要添加的前缀
- prefixOverrides:需要去掉的前缀,例如:and|or
- suffix:后缀,需要添加的后缀
- suffixOverrides:需要去掉的后缀,例如:,
<select id="queryEmps" resultType="org.example.pojo.Emp">select * from emp <trim prefix="where" prefixOverrides="and|or" suffix="" suffixOverrides=""><if test="salary != null and salary != ''">AND salary <![CDATA[<=]]> #{salary}</if><if test="eName != null and salary != ''">AND e_name = #{eName}</if><if test="eId != null and salary != ''">AND eid = #{eId}</if></trim></select>
4、动态SQL之choose、when、otherwise
- 作用:它有着类似于if、elseif、else的作用。
<select id="queryEmps2" resultMap="empResultSet">select * from emp<where><choose><when test="eName == 'lv'">eid = 1</when><when test="eName == 'zlq'">eid = 2</when><otherwise>eid = 3</otherwise></choose></where></select>
5、动态SQL之set
- 作用:主要用于解决修改操作中SET关键字以及SQL语句中可能多出的逗号问题
<update id="updateEmp">update emp<set><if test="eName != null and eName != ''">e_name = #{eName},</if><if test="eMail != null and eMail != ''">e_mail = #{eMail},</if><if test="salary != null and salary != ''">salary = #{salary},</if><if test="did != null and did != ''">did = #{did},</if></set>where eid = #{eId}</update>
6、动态SQL之foreach
- 作用:循环遍历集合或者数组
- 相关属性:
- collection:指定需要遍历的集合名称
- item:每次遍历的集合元素
- index:遍历时的下标
- separator:分隔符
- open:循环开始时添加的字符
- close:循环结束时添加的字符
<select id="queryEmpByNames" resultMap="empResultSet">select * from empwhere e_name in<foreach collection="names" item="name" index="i" separator="," open="(" close=")">#{name}</foreach></select>
7、动态SQL之sql片段
- 作用:提取重复冗余的sql语句,使其可以被共用
- 相关属性:
- id:唯一标识,使用< include refid=“sql片段的Id” />标签来引用
<sql id="querySQL">select * from emp</sql><select id="selectEmpByMap" resultType="org.example.pojo.Emp"><include refid="querySQL"/>where eid = #{id} and e_name = #{ename}</select>
8、常用的OGNL表达式
- (1)e1 or e2:逻辑或
- (2)e1 and e2:逻辑与
- (3)e1 != e2 或者 e1 neq e2:判断两个对象是否不相等
- (4)e1 == e2 或者 e1 eq e2:判断两个对象是否相等
- (5)e1 > e2 或者 e1 gt e2:判断e1是否大于e2
- (6)e1 >= e2 或者 e1 gte e2:判断e1是否大于等于e2
- (7)e1 < e2 或者 e1 lt e2:判断e1是否小于e2
- (8)e1 <= e2 或者 e1 lte e2:判断e1是否小于等于e2
- (9)e1 instanceof e2:判断e1是否是e2的实例
- (10)e1.method(e2):调用e1对象的method方法,并将e2作为参数传递给method方
- (11)e1 in e2:判断e1是否在e2中
- (12)e1 not in e2:判断e1是否不在e2中(13)e1 like e2:判断e1是否和e2匹配
- (13)e1 not like e2:判断e1是否和e2不匹配
- (14)e1 between e2 and e3:判断e1是否在e2和e3之间
- (15)e1 not between e2 and e3:判断e1是否不在e2和e3之间
- (16)e1 is null:判断e1是否为null
- (17)e1 is not null:判断e1是否不为null
- (18)!e1:逻辑非
- (19)e1+e2,e1-e2,e1*e2,e1/e2:加减乘除
7、缓存
- MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。
- 在进行配置的时候还会分为一级缓存和二级缓存:
- 一级缓存:线程级别的缓存,是本地缓存,sqlSession级别的缓存;
- 二级缓存:全局范围的缓存,不仅局限于当前会话;
1、一级缓存
- 特性:
- 1、默认开启,也可以关闭一级缓存,localCacheScope=STATENENT
- 2、作用域默认是基于sqlSession的,就是一次数据库操作会话
- 3、缓存默认的实现类是:
PerpetualCache,使用map进行存储,key ==> hashcode + sqlid + sql + hashcode + environment的id - 4、查询完就会进行数据的缓存
- 失效情况:
- 1、不同的sqlSession会使一级缓存失效
- 2、同一个sqlSession,但是查询语句不同,也会使一级缓存失效
- 3、同一个sqlSession,查询语句相同,但在中间过程中执行了增删改操作,也会使一级缓存失效
- 4、同一个sqlSession,查询语句相同,执行手动清除缓存,会使一级缓存失效
- 例如:
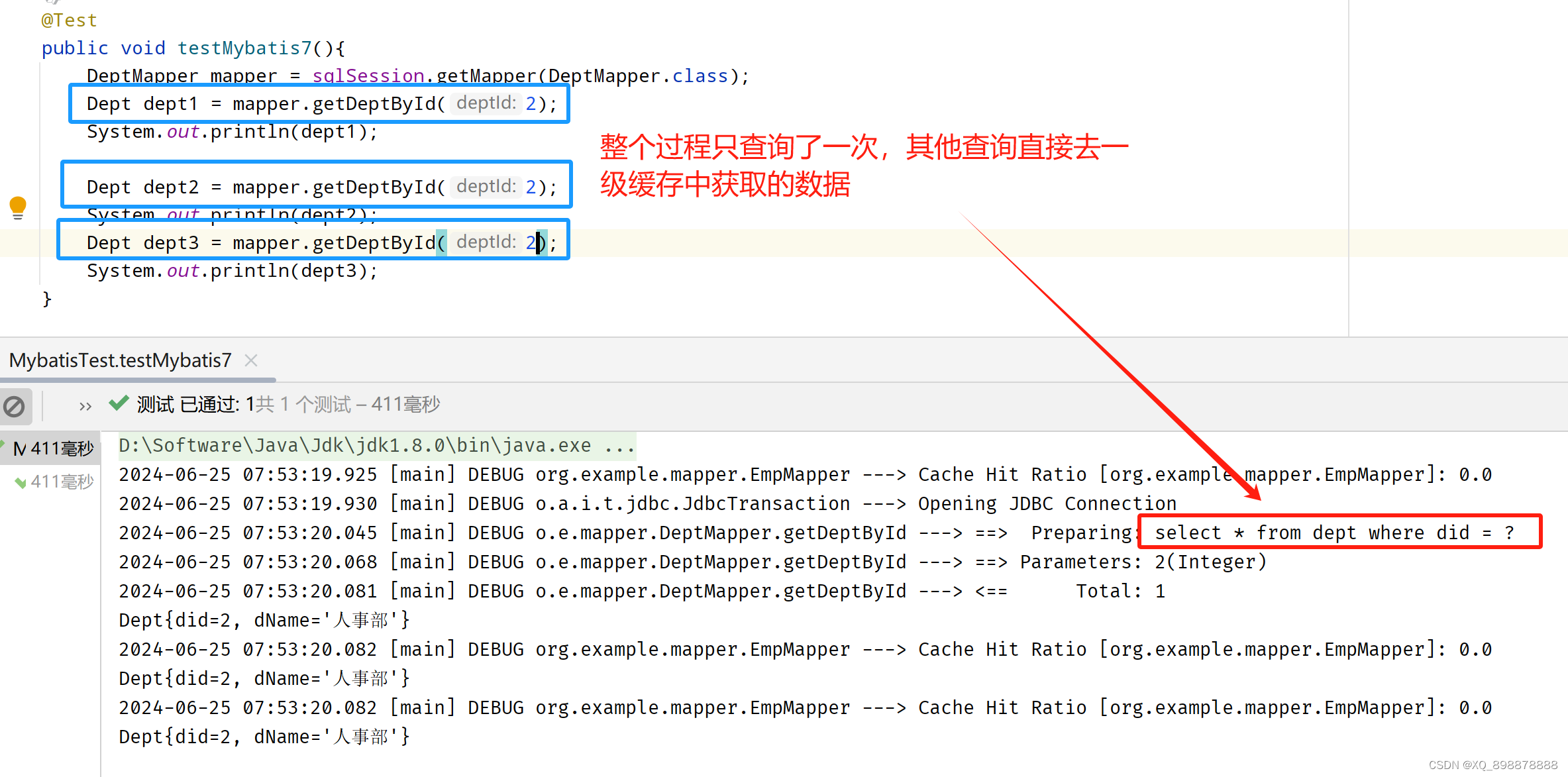
2、二级缓存
- 特性:
- 1、默认开启,但没有实现
- 2、作用域,是全局范围的,存储到Java进程当中的,如果线程过多,会出现OOM
- 3、缓存默认的实现类也是
PerpetualCache,使用map进行存储,但是,使用map存储的是二级缓存根据不同的mapper命名空间多包了一层的map。即:key:mapper的命名空间,value:Map<k,PerpetualCache.map>; - 4、提交事务时或者sqlSession关闭的时候进行数据缓存
- 实现:
- 1、在全局配置文件中开启二级缓存,
< setting name="cacheEnabled" value="true"/> - 2、在需要用到二级缓存的mapper映射文件中加入,
< cache>< /cache>,它是基于Mapper映射文件来实现存储的.
- 1、在全局配置文件中开启二级缓存,
- 查询顺序:
- 先从二级缓存中获取,再从一级缓存中获取,如果都没有,则查询数据库
- 失效情况:
- 1、同一个命名空间下进行增删改操作,会使二级缓存失效
- 2、如果不想增删改操作后缓存被清空,则可以给对应的增删改sql设置
flushCache="false",但是设置要慎重,因为会造成数据脏读问题。 - 3、让查询到的数据不缓存到二级缓存中:设置useCache=“false” 即:
<select id="getDeptById" useCache="false"> - 4、如果希望其他mapper映射文件的命名空间执行了增删改也清空另外的命名空间的缓存,可以在某个命名空间下使用:
< cache-ref namespace=""/>
- 例如
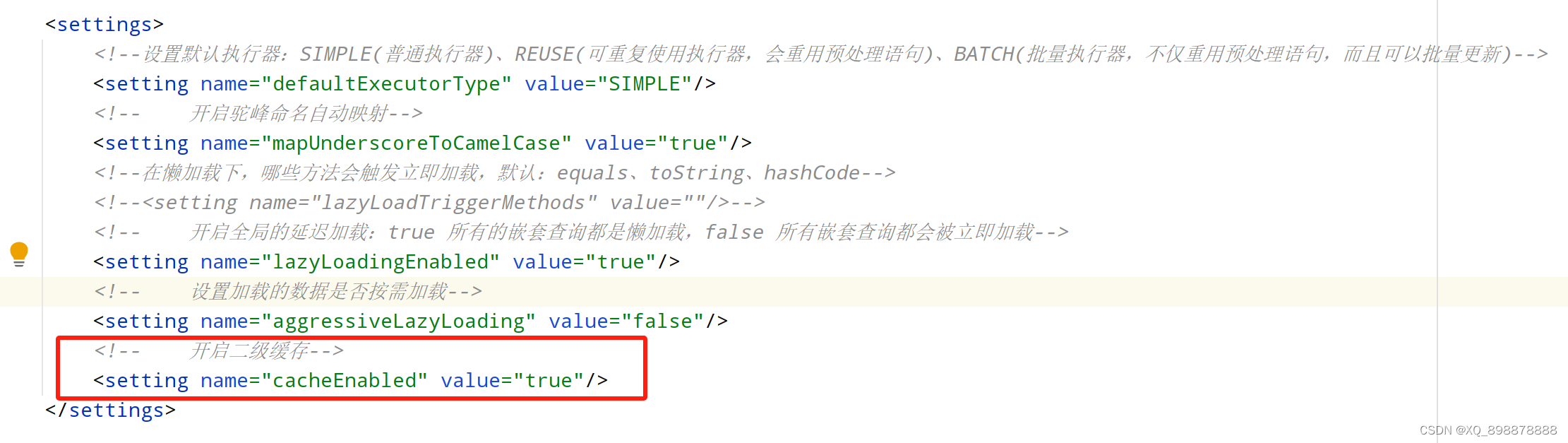


8、分页插件
- Mybatis通过提供插件机制,让我们可以根据自己的需要去增强Mybatis的功能。Mybatis的插件可以在不修改原来代码的情况下,通过拦截的方式,改变四大核心对象的行为,例如:处理参数、处理SQL、处理结果等等;
- Mybatis的分页默认是基于内存分页的(查出所有,再截取),在数据量大的情况下效率较低,不过使用mybatis插件可以改变该行为,只需要拦截StatementHandler类的prepare方法,改变要执行的SQL语句为分页语句即可;
1、应用过程
1、添加依赖
<!--mybatis分页插件依赖--><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>5.1.11</version></dependency>
2、插件注册
- 在mybatis-config.xml配置文件中进行注册:
<plugins><!--注册分页插件--><plugin interceptor="com.github.pagehelper.PageInterceptor"><!--设置当前数据库的方言(默认会自动检查当前数据库环境实用的数据库)--><property name="helperDialect" value="mysql"/><!--自动合理化设置分页参数--><property name="reasonable" value="true"/><!--支持通过Mapper接口的参数来传递分页参数,默认值为false,分页参数名称为:pageNum、pageSize--><property name="supportMethodsArguments" value="true"/></plugin></plugins>
3、调用
<select id="queryEmpList" resultType="org.example.pojo.Emp">select * from emp</select>
@Testpublic void testMybatis9(){EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);PageHelper.startPage(1,2);List<Emp> emps = mapper.queryEmpList();System.out.println(emps);//PageInfo对象中包含了很多分页相关的属性,例如,当前页,总页数,总记录数,是否有上/下一页等等PageInfo<Emp> pageInfo = new PageInfo<>(emps);pageInfo.getList().forEach(System.out::println);System.out.println(pageInfo.getTotal());System.out.println(Arrays.toString(pageInfo.getNavigatepageNums()));}
2、代理和拦截的实现
- 四大对象什么时候被代理
- Executor 是openSession()的时候创建的;
- StatementHandler 是SimpleExecutor.doQuery()创建的,里面包含了处理参数的ParameterHandler 和 处理结果集的ResultSetHandler 的创建,创建之后即调用InterceptorChain.pluginAll(),返回层层代理后的对象。
- 代理是由Plugin 类创建。在我们重写的plugin() 方法里面可以直接调用returnPlugin.wrap(target, this);返回代理对象。
- 因为代理类是Plugin,所以最后调用的是Plugin 的invoke()方法。它先调用了定义的拦截器的intercept()方法。可以通过invocation.proceed()调用到被代理对象被拦截的方法。

- 调用流程时序图
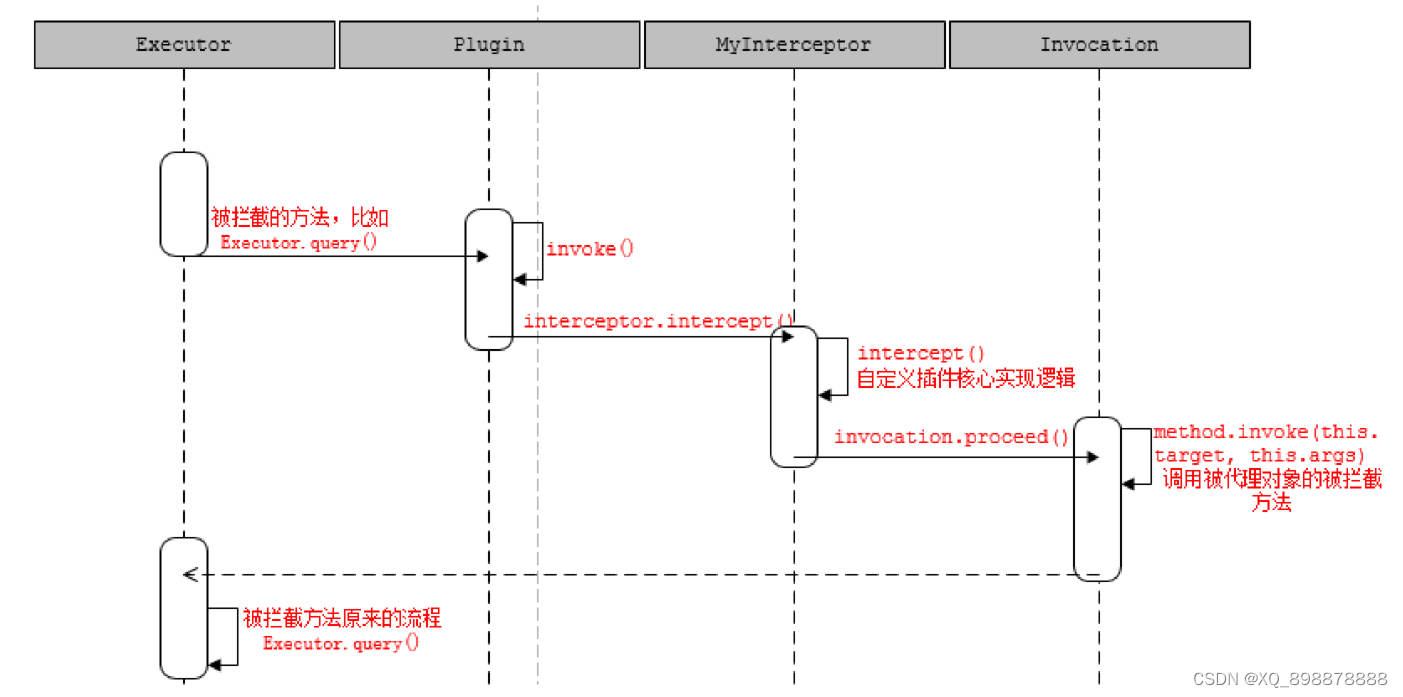
相关文章:
【01-02】Mybatis的配置文件与基于XML的使用
1、引入日志 在这里我们引入SLF4J的日志门面,使用logback的具体日志实现;引入相关依赖: <!--日志的依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version&g…...
)
Linux-进程间通信(IPC)
进程间通信(IPC)介绍 进程间通信(IPC,InterProcess Communication)是指在不同的进程之间传播或交换信息。IPC 的方式包括管道(无名管道和命名管道)、消息队列、信号量、共享内存、Socket、Stre…...

C++ STL: std::vector与std::array的深入对比
什么是 std::vector 和 std::array 首先,让我们简要介绍一下这两种容器: • std::vector:一个动态数组,可以根据需要动态调整其大小。 • std::array:一个固定大小的数组,其大小在编译时确定。 虽然…...

哈哈看到这条消息感觉就像是打开了窗户
在这个信息爆炸的时代,每一条动态可能成为我们情绪的小小触发器。今天,当我无意间滑过那条由杜海涛亲自发布的“自曝式”消息时,不禁心头一颤——如果这是我的另一半,哎呀,那画面,简直比烧烤摊还要“热辣”…...

10、matlab中字符、数字、矩阵、字符串和元胞合并为字符串并将字符串以不同格式写入读出excel
1、前言 在 MATLAB 中,可以使用不同的数据类型(字符、数字、矩阵、字符串和元胞)合并为字符串,然后将字符串以不同格式写入 Excel 文件。 以下是一个示例代码,展示如何将不同数据类型合并为字符串,并以不…...

如何正确面对GPT-5技术突破
随着人工智能技术的快速发展,预训练语言模型在自然语言处理领域取得了显著的成果。其中,GPT系列模型作为代表之一,受到了广泛关注。2023年,GPT-5模型的发布引起了业界的热烈讨论。本文将从以下几个方面分析GPT-5的发布及其对人工智…...
HarmonyOS ArkUi 官网踩坑:单独隐藏导航条无效
环境: 手机:Mate 60 Next版本: NEXT.0.0.26 导航条介绍 导航条官网设计指南 setSpecificSystemBarEnabled 设置实际效果: navigationIndicator:隐藏导航条无效status:会把导航条和状态栏都隐藏 官方…...
)
解决跨域问题(vite、axios/koa)
两种方法选其一即可 一、后端koa设置中间件 app.use(async (ctx, next)> {ctx.set(Access-Control-Allow-Origin, *);ctx.set(Access-Control-Allow-Headers, Content-Type, Content-Length, Authorization, Accept, X-Requested-With , yourHeaderFeild);ctx.set(Access-C…...
echarts实现3D柱状图(视觉层面)
一、第一种效果 效果图 使用步骤 完整实例,copy就可直接使用 <template><div :class"className" :style"{height:height,width:width}" /> </template><script>import echarts from echartsrequire(echarts/theme/…...

K8S集群进行分布式负载测试
使用K8S集群执行分布式负载测试 本教程介绍如何使用Kubernetes部署分布式负载测试框架,该框架使用分布式部署的locust 产生压测流量,对一个部署到 K8S集群的 Web 应用执行负载测试,该 Web 应用公开了 REST 格式的端点,以响应传入…...

20.《C语言》——【移位操作符】
🌹开场语 亲爱的读者,大家好!我是一名正在学习编程的高校生。在这个博客里,我将和大家一起探讨编程技巧、分享实用工具,并交流学习心得。希望通过我的博客,你能学到有用的知识,提高自己的技能&a…...

你想活出怎样的人生?
hi~好久不见,距离上次发文隔了有段时间了,这段时间,我是裸辞去感受了一下前端市场的水深火热,那么这次咱们不聊技术,就说一说最近这段时间的经历和一些感触吧。 先说一下自己的个人情况,目前做前端四年&am…...
py黑帽子学习笔记_burp
配置burp kali虚机默认装好了社区版burp和java,其他os需要手动装 burp是用java,还得下载一个jython包,供burp用 配apt国内源,然后apt install jython --download-only,会只下载包而不安装,下载的目录搜一…...
selenium,在元素块下查找条件元素
def get_norms_ele_text(self):elementsself.get_norms_elements()locBy.CSS_SELECTOR,"div.sku-select-row-label"by loc[0] # 获取By类型,例如By.CSS_SELECTORvalue loc[1] # 获取具体的CSS选择器字符串,例如"div.sku-select-row-l…...

认识String类
文章目录 String类字符串的遍历字符串的比较字符串的替换字符串的转换字符串的切割字符串的切片字符串的查找 总结 String类 在C语言中已经涉及到字符串了,但是在C语言中要表示字符串只能使用字符数组或者字符指针,可以使用标准库提 供的字符串系列函数完…...

计算机图形学入门23:蒙特卡洛路径追踪
1.前言 前面几篇文章介绍了Whitted-style光线追踪,还介绍了基于物理渲染的基础知识,包括辐射度量学、BRDF以及渲染方程,但并没有给出解渲染方程的方法,或者说如何通过该渲染方程计算出屏幕上每一个坐标的像素值。 Whitted-style光…...

探索 TensorFlow 模型的秘密:TensorBoard 详解与实战
简介 TensorBoard 是 TensorFlow 提供的可视化工具,帮助开发者监控和调试机器学习模型。它提供了多种功能,包括查看损失和精度曲线、可视化计算图、检查数据分布等。下面将介绍如何使用 TensorBoard。 1. 安装 TensorBoard 如果尚未安装 TensorBoard&…...
yolov8obb角度预测原理解析
预测头 ultralytics/nn/modules/head.py class OBB(Detect):"""YOLOv8 OBB detection head for detection with rotation models."""def __init__(self, nc80, ne1, ch()):"""Initialize OBB with number of classes nc and la…...
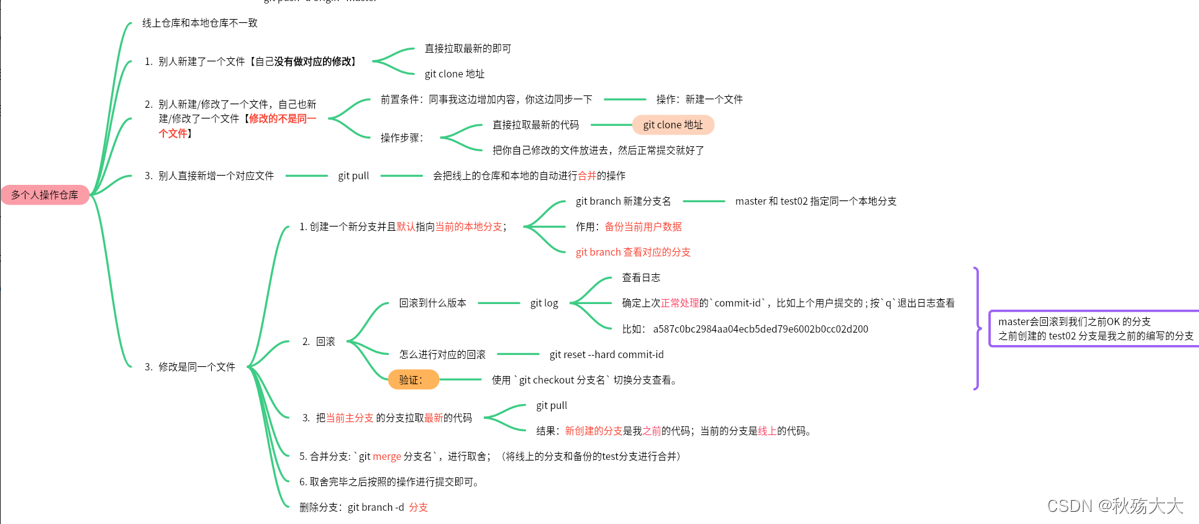
CICD之Git版本管理及基本应用
CICD:持续集成,持续交付--让对应的资料,对应的项目流程更加规范--提高效率 CICD 有很多的工具 GIT就是其中之一 1.版本控制概念与环境搭建 GIT的概念: Git是一款分布式源代码管理工具(版本控制工具) ,一个协同的工具。 Git得其数据更像是一系列微型文件系统的快照。使用Git&am…...

Python作用域及其应用
Python的作用域规则决定了变量在代码中的可见性和访问性。全局作用域中定义的变量可以在整个程序中访问,而局部作用域中定义的变量则只能在其被创建的函数或代码块中访问。 全局作用域与局部作用域 全局作用域中的变量通常在程序的顶层定义,可以被整个…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

为Claude Code配置稳定API源并解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定API源并解决访问限制 Claude Code 作为一款强大的 AI 编程辅助工具,其原生服务在某些情况下可能…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...

避坑指南:Unity动态加载模型时,TriLib插件材质丢失、缩放异常的5个常见问题解决
Unity动态加载模型避坑指南:TriLib插件材质丢失与缩放异常的深度解决方案当你在Unity项目中尝试使用TriLib插件动态加载外部模型时,是否遇到过这些令人抓狂的情况:模型加载后材质全部变成刺眼的粉红色,贴图神秘消失,或…...

终极艾尔登法环存档迁移指南:3分钟学会角色无损转移
终极艾尔登法环存档迁移指南:3分钟学会角色无损转移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档迁移而烦恼吗?当游戏版本更新后,你辛辛苦苦培…...