flink使用StatementSet降低资源浪费
背景
项目中有很多ods层(mysql 通过cannal)kafka,需要对这些ods kakfa做一些etl操作后写入下一层的kafka(dwd层)。
一开始采用的是executeSql方式来执行每个ods→dwd层操作,即类似:
def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentval tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)val configuration: Configuration = tableEnv.getConfig.getConfigurationtableEnv.createTemporarySystemFunction("etl_handle", classOf[ETLFunction])// source/sink ddltableEnv.executeSql(CREATE_DB_DDL)tableEnv.executeSql(SOURCE_KAFKA_ODS_TABLE1)tableEnv.executeSql(SINK_KAFKA_DWD_TABLE1)tableEnv.executeSql(SOURCE_KAFKA_ODS_TABLE2)tableEnv.executeSql(SINK_KAFKA_DWD_TABLE2)....// insert dml,在insert语句中调用etl_handle进行预处理和写入tableEnv.executeSql(INSERT_DWD_TABLE1)tableEnv.executeSql(INSERT_DWD_TABLE2)...
}当有多个ods->dwd操作放在同一个flink作业中时,发现这种方式会导致每次insert操作都是单独的DAG,非常消耗资源,特别是这些处理都是比较轻量级的,最好是能融合在同一个DAG中共享资源。
解决方案
查看flink文档:INSERT 语句 | Apache Flink

因此,可以采用statementset的方式,将不同insert sql进行分组执行,每组的insert sql会先被缓存到 StatementSet 中,并在StatementSet.execute() 方法被调用时,同一组的 insert sql(sink) 会被优化成一张DAG共用taskmanager,减少资源浪费,即类似:
def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentval tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)val configuration: Configuration = tableEnv.getConfig.getConfigurationtableEnv.createTemporarySystemFunction("etl_handle", classOf[ETLFunction])// source/sink ddltableEnv.executeSql(CREATE_DB_DDL)tableEnv.executeSql(SOURCE_KAFKA_ODS_TABLE1)tableEnv.executeSql(SINK_KAFKA_DWD_TABLE1)tableEnv.executeSql(SOURCE_KAFKA_ODS_TABLE2)tableEnv.executeSql(SINK_KAFKA_DWD_TABLE2)....// insert dmltableEnv.createStatementSet().addInsertSql(INSERT_DWD_TABLE1).addInsertSql(INSERT_DWD_TABLE2).addInsertSql(INSERT_DWD_TABLE3).execute()tableEnv.createStatementSet().addInsertSql(INSERT_DWD_TABLE4).addInsertSql(INSERT_DWD_TABLE5).addInsertSql(INSERT_DWD_TABLE6).execute()
}其他
如果是纯flink sql而不用data stream api,也是可以达到同样的效果的。
相关文章:
flink使用StatementSet降低资源浪费
背景 项目中有很多ods层(mysql 通过cannal)kafka,需要对这些ods kakfa做一些etl操作后写入下一层的kafka(dwd层)。 一开始采用的是executeSql方式来执行每个ods→dwd层操作,即类似: def main(…...

FineDataLink4.1.9支持Kettle调用
FDL更新至4.1.9后,新增kettle调用功能,支持不增加额外负担的情况下,将现有的Kettle任务平滑迁移到FineDataLink。 一、更新版本前存在的问题与痛点 在此次功能更新前,用户可能会遇到以下问题: 1.对于仅使用kettle的…...

SwanLinkOS首批实现与HarmonyOS NEXT互联互通,软通动力子公司鸿湖万联助力鸿蒙生态统一互联
在刚刚落下帷幕的华为开发者大会2024上,伴随全场景智能操作系统HarmonyOS Next的盛大发布,作为基于OpenHarmony的同根同源系统生态,软通动力子公司鸿湖万联全域智能操作系统SwanLinkOS首批实现与HarmonyOS NEXT互联互通,率先攻克基…...

Win11禁止右键菜单折叠的方法
背景 在使用windows11的时候,会发现默认情况下,右键菜单折叠了。以至于在使用一些软件的右键菜单时总是要点击“显示更多选项”菜单展开所有菜单,然后再点击。而且每次在显示菜单时先是全部展示,再隐藏一下,看着着实难…...
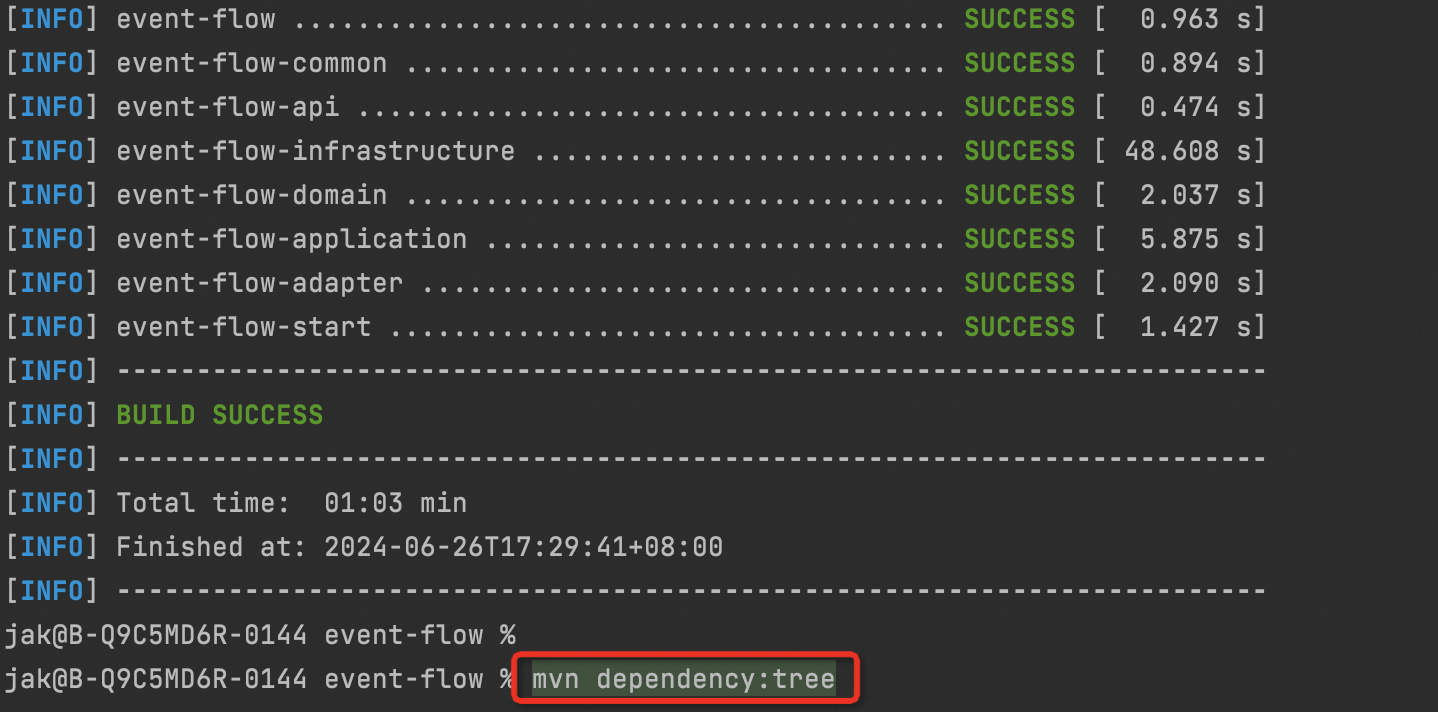
Maven列出所有的依赖树
在 IntelliJ IDEA 中,你可以使用 Maven 插件来列出项目的依赖树。Maven 插件提供了一个名为dependency:tree的目标,可以帮助你获取项目的依赖树详细信息。 要列出项目的依赖树,可以执行以下步骤: 打开 IntelliJ IDEA,…...

测试开发面试题和答案
Python 请解释Python中的列表推导式(List Comprehension)是什么,并给出一个示例。 答案: 列表推导式是Python中一种简洁的构建列表的方法。它允许从一个已存在的列表创建新列表,同时应用一个表达式来修改或选择元素。…...

llm学习-3(向量数据库的使用)
1:数据读取和加载 接着上面的常规操作 加载环境变量---》获取所有路径---》加载文档---》切分文档 代码如下: import os from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv()) # 获取folder_path下所有文件路径,储存在…...
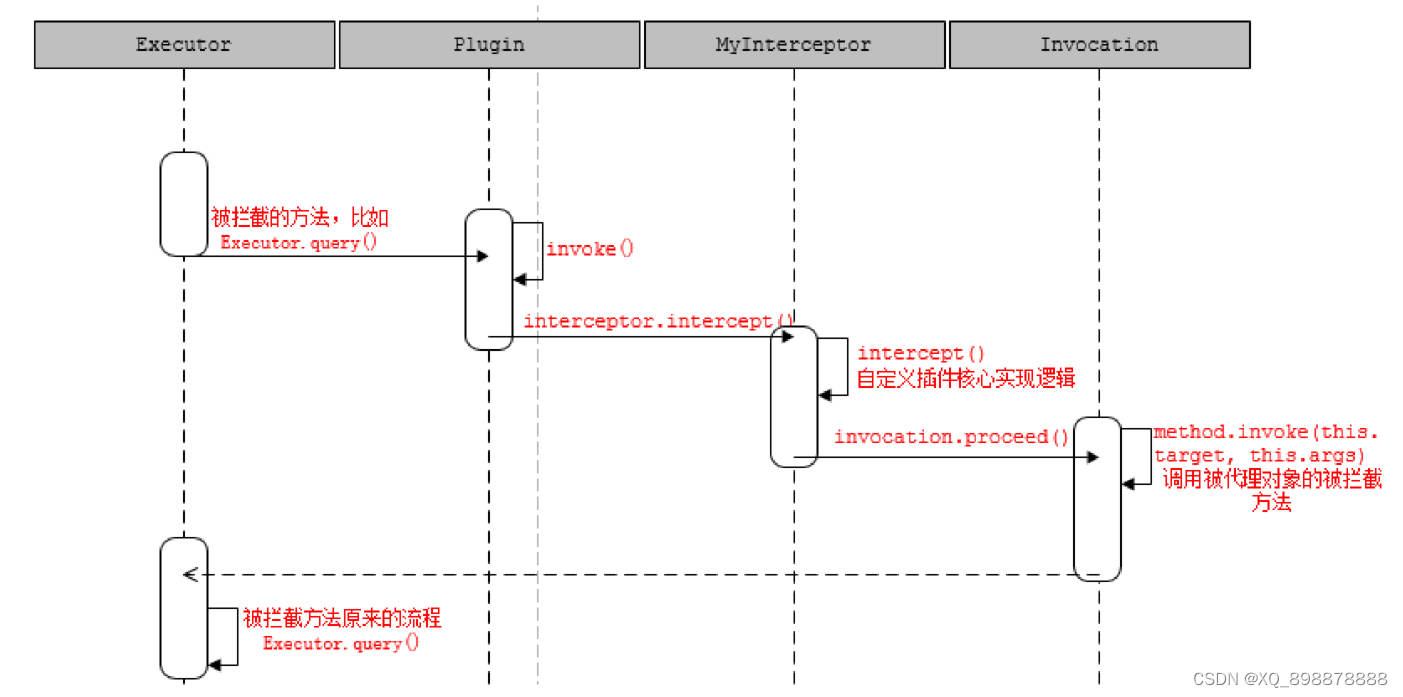
【01-02】Mybatis的配置文件与基于XML的使用
1、引入日志 在这里我们引入SLF4J的日志门面,使用logback的具体日志实现;引入相关依赖: <!--日志的依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version&g…...
)
Linux-进程间通信(IPC)
进程间通信(IPC)介绍 进程间通信(IPC,InterProcess Communication)是指在不同的进程之间传播或交换信息。IPC 的方式包括管道(无名管道和命名管道)、消息队列、信号量、共享内存、Socket、Stre…...

C++ STL: std::vector与std::array的深入对比
什么是 std::vector 和 std::array 首先,让我们简要介绍一下这两种容器: • std::vector:一个动态数组,可以根据需要动态调整其大小。 • std::array:一个固定大小的数组,其大小在编译时确定。 虽然…...

哈哈看到这条消息感觉就像是打开了窗户
在这个信息爆炸的时代,每一条动态可能成为我们情绪的小小触发器。今天,当我无意间滑过那条由杜海涛亲自发布的“自曝式”消息时,不禁心头一颤——如果这是我的另一半,哎呀,那画面,简直比烧烤摊还要“热辣”…...

10、matlab中字符、数字、矩阵、字符串和元胞合并为字符串并将字符串以不同格式写入读出excel
1、前言 在 MATLAB 中,可以使用不同的数据类型(字符、数字、矩阵、字符串和元胞)合并为字符串,然后将字符串以不同格式写入 Excel 文件。 以下是一个示例代码,展示如何将不同数据类型合并为字符串,并以不…...

如何正确面对GPT-5技术突破
随着人工智能技术的快速发展,预训练语言模型在自然语言处理领域取得了显著的成果。其中,GPT系列模型作为代表之一,受到了广泛关注。2023年,GPT-5模型的发布引起了业界的热烈讨论。本文将从以下几个方面分析GPT-5的发布及其对人工智…...
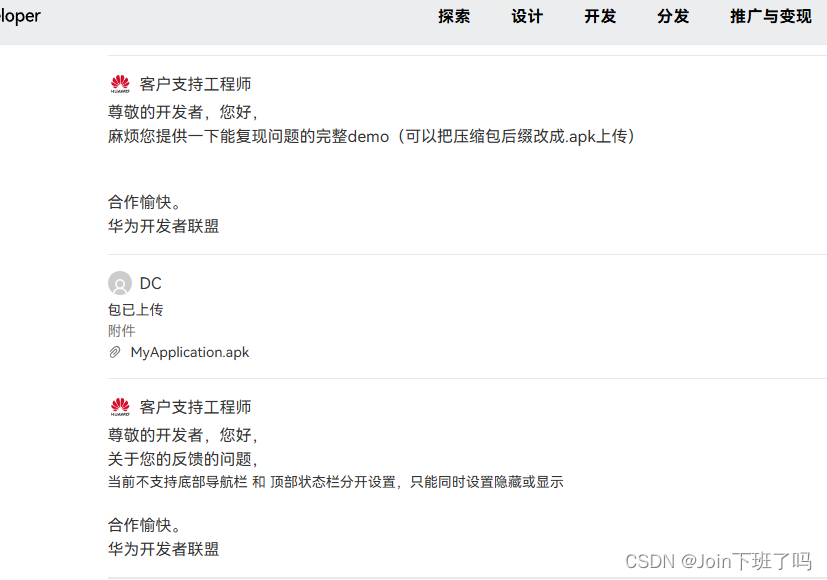
HarmonyOS ArkUi 官网踩坑:单独隐藏导航条无效
环境: 手机:Mate 60 Next版本: NEXT.0.0.26 导航条介绍 导航条官网设计指南 setSpecificSystemBarEnabled 设置实际效果: navigationIndicator:隐藏导航条无效status:会把导航条和状态栏都隐藏 官方…...
)
解决跨域问题(vite、axios/koa)
两种方法选其一即可 一、后端koa设置中间件 app.use(async (ctx, next)> {ctx.set(Access-Control-Allow-Origin, *);ctx.set(Access-Control-Allow-Headers, Content-Type, Content-Length, Authorization, Accept, X-Requested-With , yourHeaderFeild);ctx.set(Access-C…...
echarts实现3D柱状图(视觉层面)
一、第一种效果 效果图 使用步骤 完整实例,copy就可直接使用 <template><div :class"className" :style"{height:height,width:width}" /> </template><script>import echarts from echartsrequire(echarts/theme/…...

K8S集群进行分布式负载测试
使用K8S集群执行分布式负载测试 本教程介绍如何使用Kubernetes部署分布式负载测试框架,该框架使用分布式部署的locust 产生压测流量,对一个部署到 K8S集群的 Web 应用执行负载测试,该 Web 应用公开了 REST 格式的端点,以响应传入…...

20.《C语言》——【移位操作符】
🌹开场语 亲爱的读者,大家好!我是一名正在学习编程的高校生。在这个博客里,我将和大家一起探讨编程技巧、分享实用工具,并交流学习心得。希望通过我的博客,你能学到有用的知识,提高自己的技能&a…...

你想活出怎样的人生?
hi~好久不见,距离上次发文隔了有段时间了,这段时间,我是裸辞去感受了一下前端市场的水深火热,那么这次咱们不聊技术,就说一说最近这段时间的经历和一些感触吧。 先说一下自己的个人情况,目前做前端四年&am…...
py黑帽子学习笔记_burp
配置burp kali虚机默认装好了社区版burp和java,其他os需要手动装 burp是用java,还得下载一个jython包,供burp用 配apt国内源,然后apt install jython --download-only,会只下载包而不安装,下载的目录搜一…...

Topit:macOS窗口置顶神器,让多任务处理效率翻倍
Topit:macOS窗口置顶神器,让多任务处理效率翻倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个任务时…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...

集成Taotoken为OpenClaw工作流提供持久化模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 集成Taotoken为OpenClaw工作流提供持久化模型支持 在构建基于OpenClaw的自动化Agent工作流时,一个稳定且可灵活切换的模…...