llm学习-3(向量数据库的使用)
1:数据读取和加载
接着上面的常规操作
加载环境变量---》获取所有路径---》加载文档---》切分文档
代码如下:
import os
from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv()) # 获取folder_path下所有文件路径,储存在file_paths里
file_paths = []
folder_path = './llm-universe/data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):# print('*'*50)# print('root:', root)# print('dirs:', dirs)# print('files:', files)# print('*'*50)for file in files:file_path = os.path.join(root, file)file_paths.append(file_path)
print('*'*50)
print('file_paths:', file_paths)from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []for file_path in file_paths:# 按照后缀对文件进行读取file_type = file_path.split('.')[-1]if file_type == 'pdf':loaders.append(PyMuPDFLoader(file_path))elif file_type == 'md':loaders.append(UnstructuredMarkdownLoader(file_path))# 加载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load())
'''
载入后的变量类型为langchain_core.documents.base.Document, 文档变量类型同样包含两个属性
page_content 包含该文档的内容。
meta_data 为文档相关的描述性数据。
'''
text = texts[1]
# print(f"每一个元素的类型:{type(text)}.",
# f"该文档的描述性数据:{text.metadata}",
# f"查看该文档的内容:\n{text.page_content[0:]}",
# sep="\n------\n")from langchain.text_splitter import RecursiveCharacterTextSplitter# 切分文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
print('text_splitter_type:', type(text_splitter))
split_docs = text_splitter.split_documents(texts)
print('split_docs_type:', type(split_docs))
print('split_docs长度:', len(split_docs))
print('split_docs[0]:', split_docs[0])2:加载词向量模型和向量数据库
# 定义持久化路径
persist_directory = './vector_db_test/'# 删除旧的数据库文件(如果文件夹中有文件的话),windows电脑请手动删除 !rm -rf '../../data_base/vector_db/chroma'#加载chroma
from langchain.vectorstores.chroma import Chromavectordb = Chroma.from_documents(documents=split_docs[:5], # 为了速度,只选择前 20 个切分的 doc 进行生成;使用千帆时因QPS限制,建议选择前 5 个docembedding=embedding,persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)#存储向量数据库
vectordb.persist()
print(f"向量库中存储的数量:{vectordb._collection.count()}")在加载chroma的时候如果本身有向量数据库可能会产生错误:
Traceback (most recent call last):File "/workspaces/test_codespace/createVectordb.py", line 94, in <module>vectordb = Chroma.from_documents(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 778, in from_documentsreturn cls.from_texts(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 736, in from_textschroma_collection.add_texts(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 297, in add_textsself._collection.upsert(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 299, in upsertself._client._upsert(File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 352, in _upsertself._validate_embedding_record(coll, r)File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 633, in _validate_embedding_recordself._validate_dimension(collection, len(record["embedding"]), update=True)File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 648, in _validate_dimensionraise InvalidDimensionException(
chromadb.errors.InvalidDimensionException: Embedding dimension 384 does not match collection dimensionality 1024这个就是因为你没有把之前的删除干净,解决方法就是要么删除原来的,要么重新开一个路径
3:向量检索
(1):相似度检索
Chroma的相似度搜索使用的是余弦距离,即:下面博客里面有相似度计算的向量数据库相关知识(搬运学习,建议还是看原文,这个只是我自己的学习记录)-CSDN博客
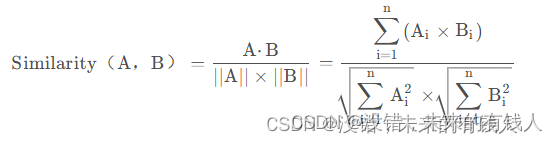
当你需要数据库返回严谨的按余弦相似度排序的结果时可以使用similarity_search函数。
(2):最大边际相关性 (MMR, Maximum marginal relevance) 检索
如果只考虑检索出内容的相关性会导致内容过于单一,可能丢失重要信息。
最大边际相关性 (MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度。
核心思想是在已经选择了一个相关性高的文档之后,再选择一个与已选文档相关性较低但是信息丰富的文档。这样可以在保持相关性的同时,增加内容的多样性,避免过于单一的结果。

参考:最大边界相关算法MMR(Maximal Marginal Relevance) 实践-CSDN博客
两个检索的代码:
#向量检索
######相似度检索
question="什么是大语言模型"
# 按余弦相似度排序的结果
sim_docs = vectordb.similarity_search(question,k=3)
print(f"检索到的内容数:{len(sim_docs)}")
for i, sim_doc in enumerate(sim_docs):print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")#######MMR检索
mmr_docs = vectordb.max_marginal_relevance_search(question,k=3)
for i, sim_doc in enumerate(mmr_docs):print(f"MMR 检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")相关文章:
llm学习-3(向量数据库的使用)
1:数据读取和加载 接着上面的常规操作 加载环境变量---》获取所有路径---》加载文档---》切分文档 代码如下: import os from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv()) # 获取folder_path下所有文件路径,储存在…...
【01-02】Mybatis的配置文件与基于XML的使用
1、引入日志 在这里我们引入SLF4J的日志门面,使用logback的具体日志实现;引入相关依赖: <!--日志的依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version&g…...
)
Linux-进程间通信(IPC)
进程间通信(IPC)介绍 进程间通信(IPC,InterProcess Communication)是指在不同的进程之间传播或交换信息。IPC 的方式包括管道(无名管道和命名管道)、消息队列、信号量、共享内存、Socket、Stre…...

C++ STL: std::vector与std::array的深入对比
什么是 std::vector 和 std::array 首先,让我们简要介绍一下这两种容器: • std::vector:一个动态数组,可以根据需要动态调整其大小。 • std::array:一个固定大小的数组,其大小在编译时确定。 虽然…...

哈哈看到这条消息感觉就像是打开了窗户
在这个信息爆炸的时代,每一条动态可能成为我们情绪的小小触发器。今天,当我无意间滑过那条由杜海涛亲自发布的“自曝式”消息时,不禁心头一颤——如果这是我的另一半,哎呀,那画面,简直比烧烤摊还要“热辣”…...

10、matlab中字符、数字、矩阵、字符串和元胞合并为字符串并将字符串以不同格式写入读出excel
1、前言 在 MATLAB 中,可以使用不同的数据类型(字符、数字、矩阵、字符串和元胞)合并为字符串,然后将字符串以不同格式写入 Excel 文件。 以下是一个示例代码,展示如何将不同数据类型合并为字符串,并以不…...

如何正确面对GPT-5技术突破
随着人工智能技术的快速发展,预训练语言模型在自然语言处理领域取得了显著的成果。其中,GPT系列模型作为代表之一,受到了广泛关注。2023年,GPT-5模型的发布引起了业界的热烈讨论。本文将从以下几个方面分析GPT-5的发布及其对人工智…...
HarmonyOS ArkUi 官网踩坑:单独隐藏导航条无效
环境: 手机:Mate 60 Next版本: NEXT.0.0.26 导航条介绍 导航条官网设计指南 setSpecificSystemBarEnabled 设置实际效果: navigationIndicator:隐藏导航条无效status:会把导航条和状态栏都隐藏 官方…...
)
解决跨域问题(vite、axios/koa)
两种方法选其一即可 一、后端koa设置中间件 app.use(async (ctx, next)> {ctx.set(Access-Control-Allow-Origin, *);ctx.set(Access-Control-Allow-Headers, Content-Type, Content-Length, Authorization, Accept, X-Requested-With , yourHeaderFeild);ctx.set(Access-C…...
echarts实现3D柱状图(视觉层面)
一、第一种效果 效果图 使用步骤 完整实例,copy就可直接使用 <template><div :class"className" :style"{height:height,width:width}" /> </template><script>import echarts from echartsrequire(echarts/theme/…...

K8S集群进行分布式负载测试
使用K8S集群执行分布式负载测试 本教程介绍如何使用Kubernetes部署分布式负载测试框架,该框架使用分布式部署的locust 产生压测流量,对一个部署到 K8S集群的 Web 应用执行负载测试,该 Web 应用公开了 REST 格式的端点,以响应传入…...

20.《C语言》——【移位操作符】
🌹开场语 亲爱的读者,大家好!我是一名正在学习编程的高校生。在这个博客里,我将和大家一起探讨编程技巧、分享实用工具,并交流学习心得。希望通过我的博客,你能学到有用的知识,提高自己的技能&a…...

你想活出怎样的人生?
hi~好久不见,距离上次发文隔了有段时间了,这段时间,我是裸辞去感受了一下前端市场的水深火热,那么这次咱们不聊技术,就说一说最近这段时间的经历和一些感触吧。 先说一下自己的个人情况,目前做前端四年&am…...
py黑帽子学习笔记_burp
配置burp kali虚机默认装好了社区版burp和java,其他os需要手动装 burp是用java,还得下载一个jython包,供burp用 配apt国内源,然后apt install jython --download-only,会只下载包而不安装,下载的目录搜一…...
selenium,在元素块下查找条件元素
def get_norms_ele_text(self):elementsself.get_norms_elements()locBy.CSS_SELECTOR,"div.sku-select-row-label"by loc[0] # 获取By类型,例如By.CSS_SELECTORvalue loc[1] # 获取具体的CSS选择器字符串,例如"div.sku-select-row-l…...

认识String类
文章目录 String类字符串的遍历字符串的比较字符串的替换字符串的转换字符串的切割字符串的切片字符串的查找 总结 String类 在C语言中已经涉及到字符串了,但是在C语言中要表示字符串只能使用字符数组或者字符指针,可以使用标准库提 供的字符串系列函数完…...

计算机图形学入门23:蒙特卡洛路径追踪
1.前言 前面几篇文章介绍了Whitted-style光线追踪,还介绍了基于物理渲染的基础知识,包括辐射度量学、BRDF以及渲染方程,但并没有给出解渲染方程的方法,或者说如何通过该渲染方程计算出屏幕上每一个坐标的像素值。 Whitted-style光…...

探索 TensorFlow 模型的秘密:TensorBoard 详解与实战
简介 TensorBoard 是 TensorFlow 提供的可视化工具,帮助开发者监控和调试机器学习模型。它提供了多种功能,包括查看损失和精度曲线、可视化计算图、检查数据分布等。下面将介绍如何使用 TensorBoard。 1. 安装 TensorBoard 如果尚未安装 TensorBoard&…...
yolov8obb角度预测原理解析
预测头 ultralytics/nn/modules/head.py class OBB(Detect):"""YOLOv8 OBB detection head for detection with rotation models."""def __init__(self, nc80, ne1, ch()):"""Initialize OBB with number of classes nc and la…...
CICD之Git版本管理及基本应用
CICD:持续集成,持续交付--让对应的资料,对应的项目流程更加规范--提高效率 CICD 有很多的工具 GIT就是其中之一 1.版本控制概念与环境搭建 GIT的概念: Git是一款分布式源代码管理工具(版本控制工具) ,一个协同的工具。 Git得其数据更像是一系列微型文件系统的快照。使用Git&am…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

别让依赖毁了你的实验:记一次Vision Mamba复现中causal_conv1d与mamba-ssm的版本“打架”事件
Vision Mamba复现实战:破解依赖冲突的工程化解决方案在深度学习项目的复现过程中,依赖管理往往是最容易被忽视却又最常导致问题的环节。最近在复现Vision Mamba模型时,我遭遇了一场典型的Python依赖"战争"——causal_conv1d与mamba…...

FModel完整部署指南:UE5资源提取与逆向解析实战
1. 为什么FModel不是“另一个UE资源查看器”,而是虚幻项目逆向分析的起点FModel虚幻引擎资源提取工具完整部署指南——这标题里藏着三个被多数人忽略的关键信号:“FModel”不是泛指,“虚幻引擎”特指UE4/UE5原生资产体系,“完整部…...
:setup / onboard 与本地配置初始化)
OpenClaw 源码解析(五):setup / onboard 与本地配置初始化
1. 本期目标 上一期我们分析了 OpenClaw 的 CLI 启动链路:用户输入 openclaw 命令后,程序会先经过 entry.ts、run-main、Commander Program 构建和命令注册流程,然后再进入具体命令逻辑。 这一期继续往下看,重点分析两个最基础的…...

Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验
Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 你是不是曾经遇到过这样的困扰?连接多个显示器时,文字和图标大小不一&…...

ATTiny85通用开发板PCB-4设计:集成电源、音频与诊断的一站式DIY平台
1. PCB-4:一个为四款经典ATTiny85项目而生的通用开发板如果你玩过一阵子电子DIY,特别是对小巧、低功耗的微控制器项目感兴趣,那你很可能听说过或者自己动手做过基于ATTiny85芯片的小玩意儿。这颗只有8个引脚的“小巨人”,以其极低…...

别再只会用strlen了!CAPL脚本字符串处理实战:从CAN报文解析到日志生成
CAPL脚本字符串处理实战:从CAN报文解析到日志生成在汽车电子测试领域,CAPL脚本是工程师们不可或缺的利器。面对复杂的CAN总线数据流,字符串处理能力往往决定了脚本的效率和可靠性。本文将带您超越基础API的简单调用,探索如何组合运…...