【基于R语言群体遗传学】-5-扩展到两个以上等位基因及多基因位点
我们现在继续对于群体遗传学进行统计建模,书接上回,我们讨论了孤雌生殖的物种违反哈代温伯格遗传比例的例子,那我们现在来看多于两个等位基因的情况的计算。
如果没有看过之前文章的同学,可以先去看一下之前的文章:
群体遗传学_tRNA做科研的博客-CSDN博客
多等位基因情况
到目前为止,我们一直专注于一个双等位基因(bi-allelic)系统,其中一个等位基因的频率表示为p,另一个等位基因的频率表示为(1-p)。然而,基因型预测可以很容易地扩展到超过两个等位基因。由于我们总是假设完全随机交配,我们理论上预期的纯合子数量仍然将等于p²,无论我们考虑多少个等位基因。一组j个等位基因的预期纯合率会是每个等位基因频率平方的和。

p1 <- 0.2
p2 <- 0.3
p3 <- 0.5
sum(sapply(c(p1,p2,p3),function(x) x^2))假设我们有三个等位基因频率,p1、p2和p3,并希望计算总体预期的纯合子基因型频率
这给了我们一个总体的纯合子基因型频率为38%。然后我们可以相当容易地得到一个预期的杂合子频率:

多位点情况
接下来让我们读取一个来自东地中海地区阿勒颇松(Pinus halepensis)的真实多采样等位基因数据集,整理这些数据,并计算我们预期的以及观察到的杂合子频率(改编自Gershberg等人,2016)。使用popgenr包,安装请看前面的博客:

基因型中的数据都来自微卫星。微卫星是由短重复的核苷酸组成特征的DNA片段。这类遗传标记因其高度变异(即具有高突变率)而常用于研究。让我们用str()函数来了解一下数据:
library("popgenr")
data(genotypes)
str(genotypes)
我们可以看到这个数据框有181个观测值(行)和20列。其中十八列代表不同的位点,每个独特的数字是一个不同的等位基因,前两列是每个样本的个体ID($ID)和种群分配($Pop)。我们想要编写一个迭代代码来遍历数据集进行计算;为了简化这个过程,我们先对数据进行一些简化处理。
rownames(genotypes) <- genotypes$ID
genotypes <- genotypes[,-c(1,2)]根据这个数据集的设置,每个个体有两列,代表在一棵采样的二倍体松树中一个位点的两个拷贝。让我们计算数据集中位点的总数。对数据框使用length()函数应该只返回列的数量。由于每个位点由两列表示,我们可以将其除以2得到采样的位点总数:
(num.loci <- (length(genotypes))/2)现在我们知道我们正在处理九个不同的位点。接下来我们需要弄清楚每个位点实际上有多少个等位基因。我们将使用for循环来为每个位点进行等位基因计数。、
Hom_exp <- NULL
Het_exp <- NULL
Hom_obs <- NULL
Het_obs <- NULL
for(n in 1:(num.loci)){ # 对于每一个基因座current <- n*2-1 # 计算当前基因座的起始位置locus <- c(genotypes[,current],genotypes[,current+1]) # 获取当前基因座的两个等位基因alleles <- unique(locus) # 获取该基因座的所有独特等位基因alleles <- alleles[alleles!=-1] # 移除非等位基因标记(例如缺失数据标记为-1)p_allele <- NULL # 初始化等位基因频率向量for(a in 1:length(alleles)){ # 对于每个独特的等位基因p_allele <- c(p_allele,sum(alleles[a]==locus)/sum(locus!=-1)) # 计算等位基因频率}Hom_exp <- c(Hom_exp, sum(sapply(p_allele,function(x) x^2))) # 期望纯合子频率是每个等位基因频率的平方和obs <- 0 # 初始化观察到的纯合子计数for(i in 1:length(genotypes[,current])){ # 对于当前基因座的每个个体if(genotypes[i, current]!=-1){ # 如果等位基因不是缺失数据if(genotypes[i, current]==genotypes[i,current+1]){ # 如果两个等位基因相同obs <- obs+1 # 增加纯合子计数}}}Hom_obs <- c(Hom_obs,obs/(sum(locus!=-1)/2)) # 观察到的纯合子频率是纯合子计数除以有效等位基因总数的一半
}在R语言中,极少数会使用繁琐的循环,但是为了处理这里的数据我们不得不这样做,所以这也是为什么我们课题组会使用Java进行计算,我简述一下这个代码的意思:我们写一个循环遍历每个基因座(locus)--内部循环计算每个等位基因的频率--计算期望纯合子频率--计算观察到的纯合子频率:
现在要找到预期和观察到的杂合子频率,我们只需从频率的总和中减去我们的纯合子频率:
Het_exp <- 1- Hom_exp
Het_obs <- 1- Hom_obs让我们绘制这九个位点的观察到的杂合度频率与预期杂合度频率的对比图,看看它们之间的关系如何。我们将从简单地使用plot绘制Het_obs和Het_exp开始,然后绘制一条回归线。我们将使用lm(线性模型)函数来估计数据集之间的线性关系(最小二乘线性回归)
# 绘制观测值与期望值的散点图
plot(Het_obs, Het_exp)# 添加线性回归线
abline(lm(Het_exp ~ Het_obs))# 进行线性回归分析并打印摘要
reg <- summary(lm(Het_exp ~ Het_obs))
print(reg)# 提取并打印决定系数(r-squared)
rr <- reg$r.squared
rrlabel <- paste("r-squared =", round(rr, digits = 3))
text(0.6, 0.2, rrlabel)# 提取并打印P值
pv <- reg$coefficients[2, 4]
pvlabel <- paste("P-value =", pv)
text(0.6, 0.15, pvlabel)

查看我们的图,我们应该看到一个很好的验证,即哈代-温伯格预测可以扩展到多个位点,在这种情况下,它在预测广泛的杂合性值方面表现得相当好。
下一篇博客我们将讲述血液型及血液等位基因频率的内容,欢迎大家点赞关注!
相关文章:
【基于R语言群体遗传学】-5-扩展到两个以上等位基因及多基因位点
我们现在继续对于群体遗传学进行统计建模,书接上回,我们讨论了孤雌生殖的物种违反哈代温伯格遗传比例的例子,那我们现在来看多于两个等位基因的情况的计算。 如果没有看过之前文章的同学,可以先去看一下之前的文章: …...
是什么?)
重采样(上采样或下采样)是什么?
重采样(Resampling)是在数据处理中常用的一种技术,主要用于处理数据集中的不平衡问题。具体来说,重采样可以分为上采样(Oversampling)和下采样(Undersampling),它们分别是…...
)
AI与Python共舞:如何利用深度学习优化推荐系统?(2)
推荐系统的前世今生 推荐系统的历史可以追溯到20世纪90年代,从最初的基于内容过滤和协同过滤,到现在融合了机器学习甚至是深度学习的混合型推荐,其目标始终如一:更精准、更个性化地为用户推荐内容。随着Python的普及,…...

ChatGPT:Java中的对象引用实现方式
ChatGPT:Java中的对象引用实现方式 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与对象类型数据各自的具体地址信息。 你提到的句柄机制是…...
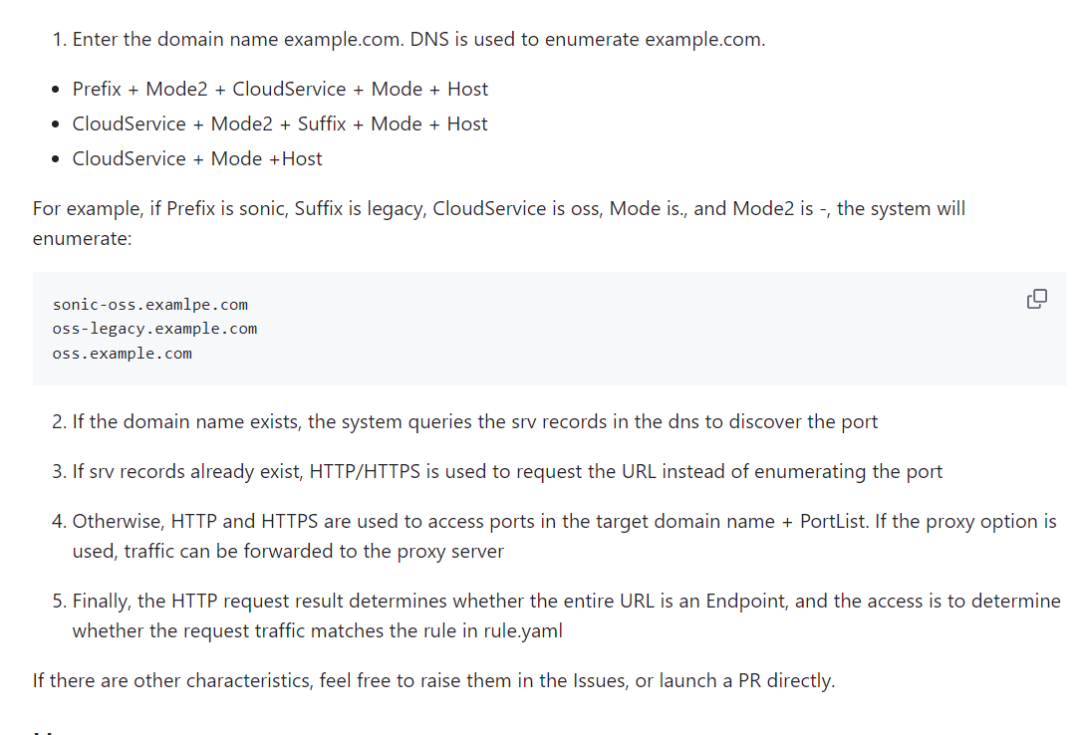
云渗透实战手册:云API攻防之云服务端点侦查
在云计算环境中的渗透,与传统渗透相比,新增加了许多新的攻击面,同时也因为云计算的特点我们需要转变渗透的思维,用云计算的方式去思考云渗透。 基础知识 在云渗透开始之前,我们需要首先阐述标题中提到的云服务端点概…...

PHP 爬虫之使用 Curl库抓取淘宝商品列表数据网页的方法
使用 PHP 的 cURL 库来抓取淘宝商品列表数据网页需要谨慎,因为淘宝等电商平台通常会有反爬虫机制,以防止数据被滥用。然而,如果你只是出于学习目的,并且了解并遵守了淘宝的robots.txt文件和相关的使用条款,你可以尝试使…...
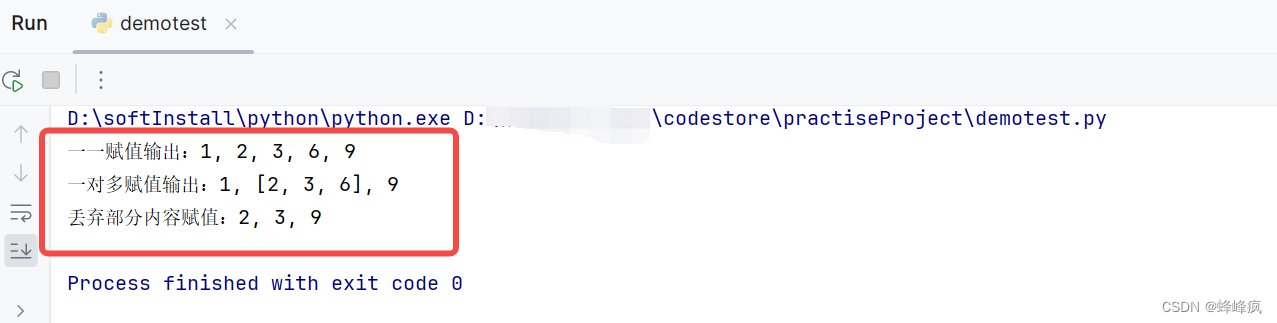
Python基础小知识问答系列-可迭代型变量赋值
1. 问题: 怎样简洁的把列表中的元素赋值给单个变量? 当需要列表中指定几个值时,剩余的变量都收集在一起,该怎么进行变量赋值? 当只需要列表中指定某几个值,其他值都忽略时,该怎么…...

主流 Canvas 库对比:Fabric.js、Konva.js 和 Pixi.js
在前端开发中,HTML5 Canvas 是一个强大的工具,可以用来创建图形、动画和各种视觉效果。为了简化和增强 Canvas 的使用,社区中出现了许多库。本文将对比三种主流的 Canvas 库:Fabric.js、Konva.js 和 Pixi.js,分析它们的…...

backbone是什么?
在深度学习中,特别是计算机视觉领域,"backbone"(骨干网络)是指用于提取特征的基础网络。它通常是卷积神经网络(CNN),其任务是从输入图像中提取高层次特征,这些特征然后被用…...

四十篇:内存巨擘对决:Redis与Memcached的深度剖析与多维对比
内存巨擘对决:Redis与Memcached的深度剖析与多维对比 1. 引言 在现代的系统架构中,内存数据库已经成为了信息处理的核心技术之一。这类数据库系统的高效性主要来源于其对数据的即时访问能力,这是因为数据直接存储在RAM中,而非传统…...
HTML5的多线程技术:Web Worker API
Web Workers API 是HTML5的一项技术,它允许在浏览器后台独立于主线程运行脚本,即允许进行多线程处理。这对于执行密集型计算任务特别有用,因为它可以防止这些任务阻塞用户界面,从而保持网页的响应性和交互性。Web Workers在自己的…...
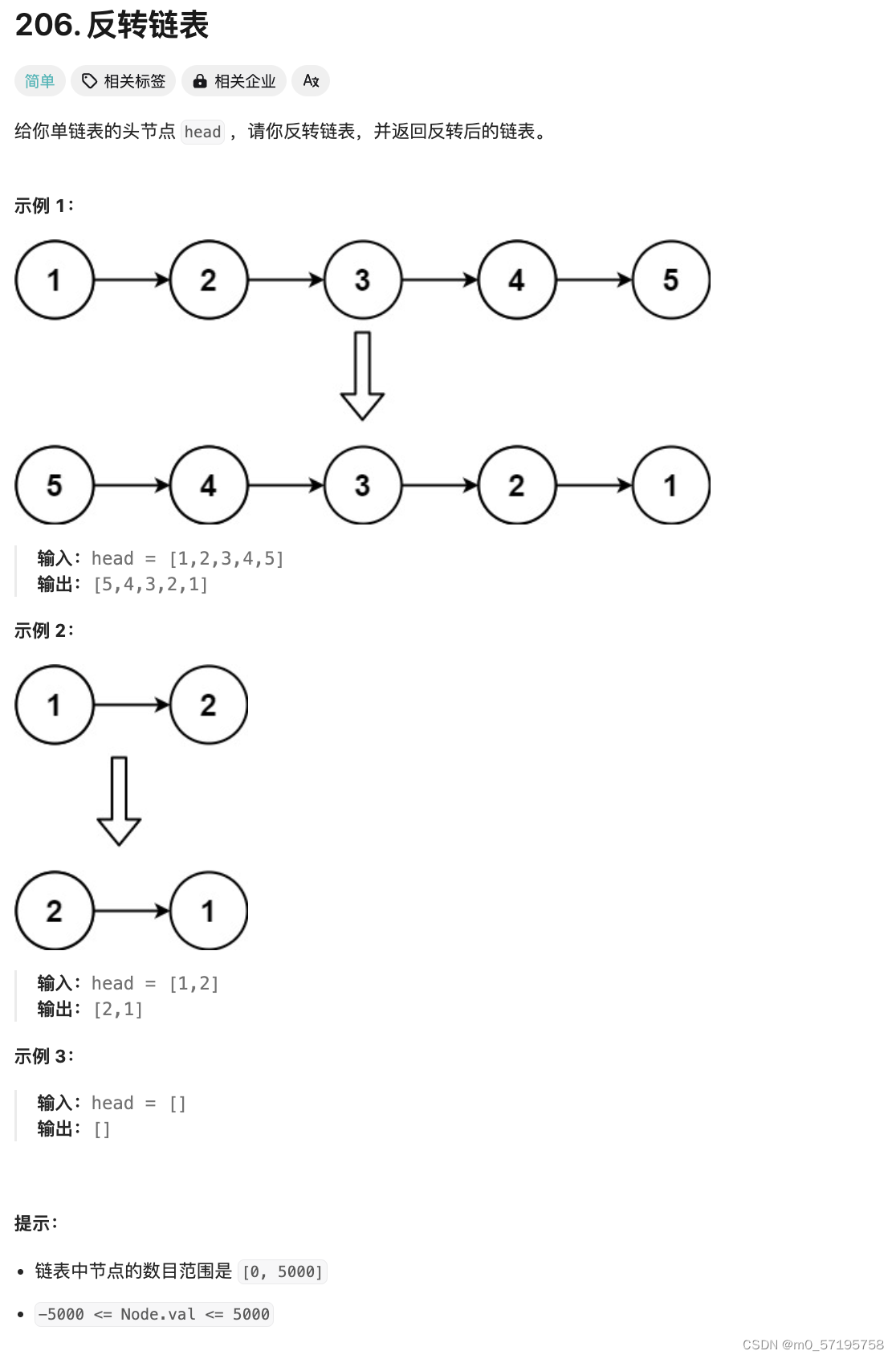
Java | Leetcode Java题解之第206题反转链表
题目: 题解: class Solution {public ListNode reverseList(ListNode head) {if (head null || head.next null) {return head;}ListNode newHead reverseList(head.next);head.next.next head;head.next null;return newHead;} }...

660错题
不能局部求导,局部洛必达...
GAMES104:04游戏引擎中的渲染系统1:游戏渲染基础-学习笔记
文章目录 概览:游戏引擎中的渲染系统四个课时概览 一,渲染管线流程二,了解GPUSIMD 和 SIMTGPU 架构CPU到GPU的数据传输GPU性能限制 三,可见性Renderable可渲染对象提高渲染效率Visibility Culling 可见性裁剪 四,纹理压…...
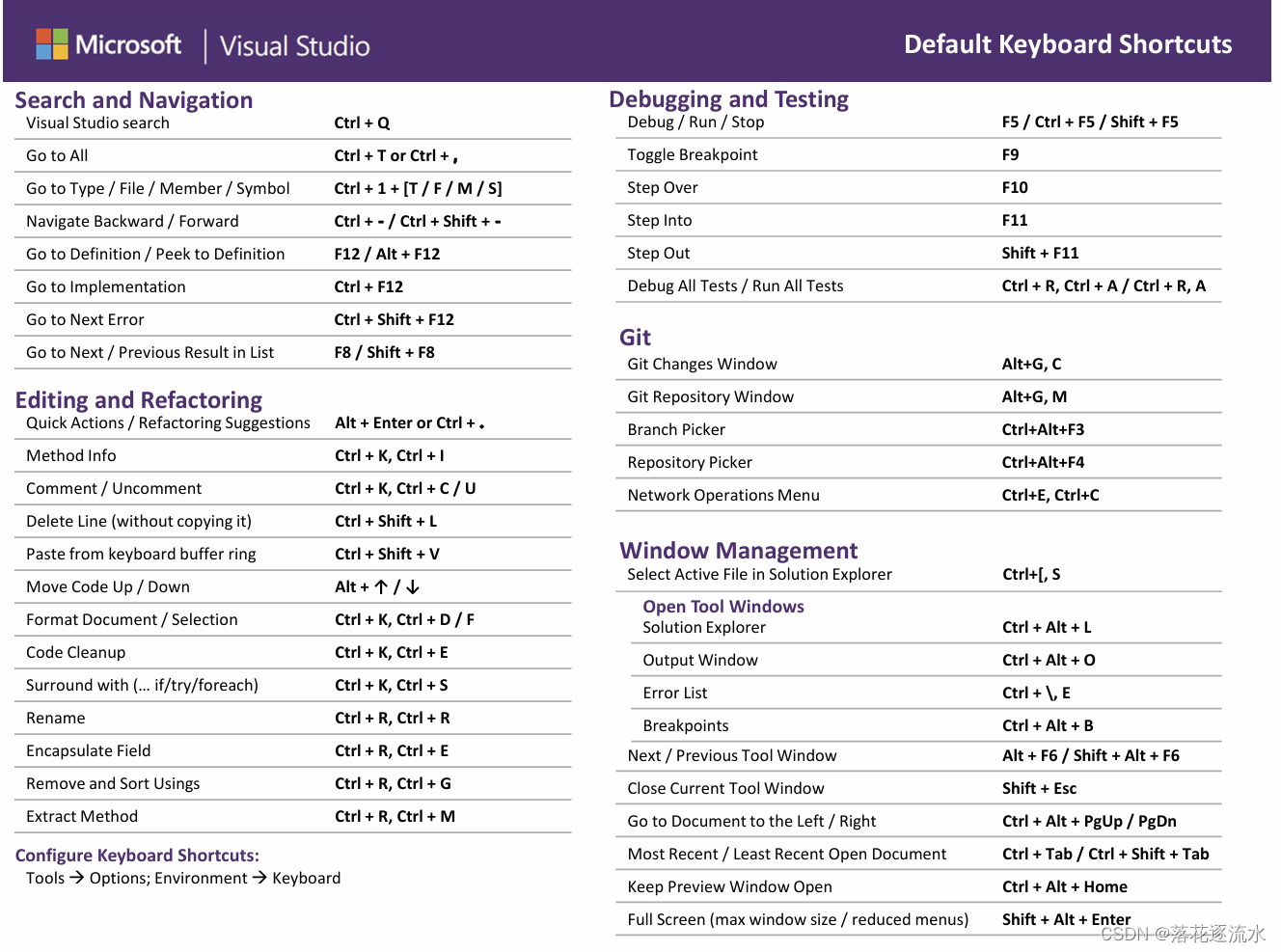
Visual Studio 中的键盘快捷方式
1. Visual Studio 中的键盘快捷方式 1.1. 可打印快捷方式备忘单 1.2. Visual Studio 的常用键盘快捷方式 本部分中的所有快捷方式都将全局应用(除非另有指定)。 “全局”上下文表示该快捷方式适用于 Visual Studio 中的任何工具窗口。 生成࿱…...

K8S中的某个容器突然出现内存和CPU占用过高的情况解决办法
当K8S中的某个容器突然出现内存和CPU占用过高的情况时,可以采取以下步骤进行处理: 观察和分析: 使用kubectl top pods命令查看集群中各个Pod的CPU和内存占用情况,找出占用资源高的Pod。使用kubectl describe pod <pod-name>…...

Pointnet++改进即插即用系列:全网首发GLSA聚合和表示全局和局部空间特征|即插即用,提升特征提取模块性能
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入GLSA,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步骤三 1.理论介…...

如何选择适合自己的虚拟化技术?
虚拟化技术已成为现代数据中心和云计算环境的核心组成部分。本文将帮助您了解如何选择适合自己需求的虚拟化技术,以实现更高的效率、资源利用率和灵活性。 理解虚拟化技术 首先,让我们了解虚拟化技术的基本概念。虚拟化允许将一个物理服务器划分为多个虚…...

Spring动态代理详解
一,动态代理 我发现Spring框架中的动态代理是一种非常强大的机制,它可以在运行时为接口或类创建动态代理,然后通过这些代理在方法调用前后添加额外的行为。在后续Spring的AOP(面向切面编程)支持中扮演了关键角色。 二…...

Java微服务架构中的消息总线设计
Java微服务架构中的消息总线设计 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨在Java微服务架构中的消息总线设计。 一、什么是消息总线&…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...

还在古法编程?OpenAI Codex 全自动编程!稳定中转 Token 保姆级教程
OpenAI Codex 从安装到进阶实战|终端 AI 编程完全指南(2026 最新) 摘要:OpenAI Codex 是目前最强大的终端 AI 编程工具,支持代码生成、项目重构、Bug 修复、脚本自动化、批量代码优化等全场景能力。本文从零起步&…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...