Linux 生产消费者模型
💓博主CSDN主页:麻辣韭菜💓
⏩专栏分类:Linux初窥门径⏪
🚚代码仓库:Linux代码练习🚚
🌹关注我🫵带你学习更多Linux知识
🔝

前言
1. 生产消费者模型
1.1 什么是生产消费者模型?
1.2 生产消费者模型原则
1.3 生产消费者模型的优点
2. 基于阻塞队列实现生产消费者模型
2.1 单生产单消费模型
2.2 多生产多消费
3. POSIX 信号量
POSIX 信号量有两种类型:
POSIX 信号量的基本操作:
4. 基于循环队列实现生产消费者模型
4.1 多生产多消费
环形队列的优缺点:
阻塞队列的优缺点:
前言
生产者-消费者模型是一个经典的并发编程问题,它描述了两种角色:生产者和消费者。生产者负责生成数据,而消费者则负责消费这些数据。这个模型通常用于处理多线程或多进程环境中的资源分配问题。
1. 生产消费者模型
1.1 什么是生产消费者模型?
上面的名词有些抽象,我们直接用生活中案例来举例子,大家就会豁然开朗。
 超市工作模式:
超市工作模式:
超市需要从工厂拿货,工厂则需要提供给超市商品
消费者在超市消费,超市需要向顾客提供商品
超市的作用就是平衡消费者和工厂供需平衡
为什么这么说?
简单来说就是要做到 顾客可以在超市买到想要购买的商品,工厂也能同超市完成足量的需求订单,超市这样就可以为双方提供便利。
顾客再也不用到工厂去买商品
工厂也不需要将商品亲自送到顾客手中。
如果没有超市,顾客直接去工厂消费,工厂生产出来商品再送到顾客手中,这种关系就是高度相互依赖,离开谁都不能干。这就是传说中的强耦合关系。
超市的出现,极大了提高效率,从而顾客和工厂之间不再单方面的依赖。使得它们之间依赖度降低。而这就是传说的中解耦。
生产者消费者模型的本质:忙闲不均
我们再回到编程的视角
- 工厂 —> 生产者
- 顾客 —> 消费者
- 超市 —> 某种容器
这样我们就可以利用线程来干事了,线程充当生产者和消费者。利用STL的队列容器(缓冲区)充当超市。 常见的有 阻塞队列 和 环形队列
在实现中,超市不可能只面向一个顾客,一个工厂。在多线程中,也就意味着它们都能看到这个队列(超市),那么必须就要让线程之间存在互斥与同步。对于互斥与同步不理解的可以看 Linux 线程的同步与互斥
从上面我们就可以的得出它们之间关系。
生产者VS生产者:互斥

一张图解释一切,这么多汽车生产商,相互竞争,对于多线程之间也是一样,所以需要互斥。
消费者VS消费者:互斥
比如宝马4S店里,只剩最后一辆宝马7系,如果这时来了两个消费者,张三李四都想要这辆车,如果是张三先交了订金,那么李四就没有机会了,但是如果李四私下愿意加钱。那么张三和李四之间存在竞争。对于线程来说,我们需要互斥。
生产者VS消费者:互斥、同步
我们假设李四拿到了车,但是张三是个非常执着的人,其他车都不要,就要宝马7系。对于4S店来说,它就应该给工厂发消息生产7系车。然后再告诉张三有车了,进而消费。就对于生产线程和消费线程那就是同步。
如果宝马一直疯狂生产,也不管4S店到底卖出去没有,也不管消费者到底买不买,那么这样就乱套了。结局只有破产!!!所以需要根据消费者的需求来进行合理生产。反过来消费者和宝马也是同理。而这对于多线程来说,那就是互斥。
1.2 生产消费者模型原则
生产消费者模型原则:321原则
三种关系:
- 生产者VS生产者:互斥
- 消费者VS消费者:互斥
- 生产者VS消费者:同步、互斥
两种角色:
- 生产者
- 消费者
一个交易场所:
- 特定的容器:阻塞队列、环形队列
生产消费者模型原则,书本是没有这个概念,为了方便记忆,大牛提炼总结出来的。
1.3 生产消费者模型的优点
为什么生产消费者模型高效?
- 生产者、消费者 可以在同一个交易场所中进行操作
- 生产者在生产时,无需关注消费者的状态,只需关注交易场所中是否有空闲位置
- 消费者在消费时,无需关注生产者的状态,只需关注交易场所中是否有就绪数据
- 可以根据不同的策略,调整生产者于与消费者间的协同关系
生产消费者模型可以根据供需关系灵活调整策略做到忙闲不均。生产者和消费者无需关心他人的状态,做到并发。
2. 基于阻塞队列实现生产消费者模型
在正式编写代码前,我们先了解阻塞队列与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)

2.1 单生产单消费模型
为了方便理解我们先用单生产、单消费的方式来讲解
先创建Blockqueue.hpp的头文件。
#include <iostream>
#include <queue>
#include <pthread.h>template <class T>
class Blockqueue
{static const int defaultnum= 10;public:Blockqueue(int maxcap = defaultnum): _maxcap(maxcap){pthread_mutex_init(&_mutex, nullptr);pthread_cond_init(&_c_cond, nullptr);pthread_cond_init(&_p_cond, nullptr);}void push(const T &data) //生产数据{}T pop() //取数据{}~Blockqueue(){pthread_mutex_destroy(&_mutex);pthread_cond_destroy(&_c_cond);pthread_cond_destroy(&_p_cond);}private:std::queue<T> _q;int _maxcap; // 极值pthread_mutex_t _mutex;pthread_cond_t _c_cond; // 消费者pthread_cond_t _p_cond; // 生产者
};阻塞队列框架搭建出来后,生产和消费我们后面实现。
由于我们是单生产单消费的生产消费者模型。所以
在mian.cc主函数中创建两个线程
#include "Blockqueue.cpp"void * Consumer(void *args) //消费者
{}
void * Productor(void *args) //生产者
{}int main()
{Blockqueue<int> *bq = new Blockqueue<int>;//创建线程(生产、消费)pthread_t c,p;pthread_create(&c,nullptr,Consumer,bq);pthread_create(&p,nullptr,Productor,bq);pthread_join(c,nullptr);pthread_join(p,nullptr);delete bq;return 0;
}上面就是生产消费者模型的大致框架,我们在实现具体细节之前,我们先要明白一个关键问题。
生产和消费要不要耗费时间?
生产和消费是肯定要耗费时间的,一辆车不会平白无故的出现,车从生产到成品这个过程是要耗费大量的数据,同理作为消费者使用车,也是要耗费时间的。开车不需要耗费时间吗?
所以在代码层面角度来说:生产和消费都是需要耗费时间的,并不是一味的在阻塞队列里进行生产和消费。而是生产者在生产数据之前,要对数据做加工,做完之后才放进阻塞队列,消费者也不是从阻塞队列拿到数据就完事了,而是拿到数据之后,对数据做分析,然后决策。
为什么生产和消费只需要同一把锁?
因为它们两个是基于阻塞队列的,我们可以把阻塞队列看成一份整体资源,所以只需要一把锁,但是共享资源也可以被看做多份。
为什么生产和消费各自需要一个条件变量?
这就是为什么叫做阻塞队列。两个线程各自基于自己的条件变量,当条件不满足时候,那么就会阻塞等待。
明白这点之后 我们来实现生产和消费
生产和消费都能看到同一个阻塞队列,之前我们也说了生产和消费是既有同步又互斥的关系,那么生产线程和消费线程在访问阻塞队列时,只能是只有一个在访问。那么必然要互斥
void push(const T &data) //生产数据{pthread_mutex_lock(&_mutex);_q.push(data);pthread_mutex_unlock(&_mutex);}生产是想生产就能生产的吗?
当然不是,阻塞队列如同超市一样,商品在货架上都放满了,生产出来的商品没有人买,那不是妥妥亏钱?
所以在生产之前还得问问超市,条件满足不?满足生产,不满足堵塞等待被唤醒
void push(const T &data) //生产数据{pthread_mutex_lock(&_mutex);if(_q.size() == _maxcap) {pthread_cond_wait(&_p_cond,&_mutex);//不满足阻塞}_q.push(data);pthread_cond_signal(&_c_cond);pthread_mutex_unlock(&_mutex);}当生产条件不满足的时候,那么生产线程要去等待。这里就有个问题,生产线程在访问条件满不满足的时候,是已经拿到了锁的,不释放锁去等待,那么会造成死锁的问题。所以我们利用
pthread_cond_wait函数 ,等待的同时解锁。
同理消费数据也是一样。
T pop() //消费数据{pthread_mutex_lock(&_mutex);if(_q.size() == 0) {pthread_cond_wait(&_c_cond,&_mutex);//不满足阻塞}T out = _q.front();_q.pop();pthread_cond_signal(&_p_cond);pthread_mutex_unlock(&_mutex);return out;}那么我们在实现了生产和消费之后,就需要在mian.cc中实现生产消费的回调函数
我们先srand函数模拟随机数
srand(time(nullptr) ^ getpid());#include <ctime>
#include <unistd.h>
void *Consumer(void *args) // 消费者
{Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);while (true){int t = bq->pop();std::cout << "消费了一个数据..." << t << std::endl;}
}
void *Productor(void *args) // 生产者
{Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);while (true){int data = rand() % 10 + 1;bq->push(data);std::cout << "生产了一个数据..." << data << std::endl;sleep(1);}
}

结果符合预期,生产和消费实现了同步互斥。但是我们就传入个整数,未免有点锉了,我们是用C++写的,而且我们blockqueue是带模板,我们可以传入对象。
先创建一个Task.hpp的头文件
我们在Task.hpp这个头文件中,创建一个Task类。在这个类中实现一些加减乘除的函数方法,由生产者生产任务。然后消费者拿到任务数据做加工
#pragma once
#include <iostream>
#include <string>std::string opers = "+-*/%";enum
{DivZero = 1,ModZero,Unknown
};class Task
{
public:Task(int data1, int data2, char oper): _data1(data1), _data2(data2), _oper(oper), _result(0), _exitcode(0){}void run(){switch (_oper){case '+':_result = _data1 + _data2;break;case '-':_result = _data1 - _data2;break;case '*':_result = _data1 * _data2;break;case '/':{if (_data2 == 0)_exitcode = DivZero;else_result = _data1 / _data2;}break;case '%':{if (_data2 == 0)_exitcode = ModZero;else_result = _data1 % _data2;}break;default:_exitcode = Unknown;break;}}std::string GetResult(){std::string r = std::to_string(_data1);r += _oper;r += std::to_string(_data2);r += "=";r += std::to_string(_result);r += "[code: ";r += std::to_string(_exitcode);r += "]";return r;}std::string GetTask(){std::string r = std::to_string(_data1);r += _oper;r += std::to_string(_data2);r += "=?";return r;}void operator()() //运算符重载让对象像函数一样使用{run();}~Task(){}private:int _data1;int _data2;char _oper;int _result;int _exitcode;
};void *Consumer(void *args) // 消费者
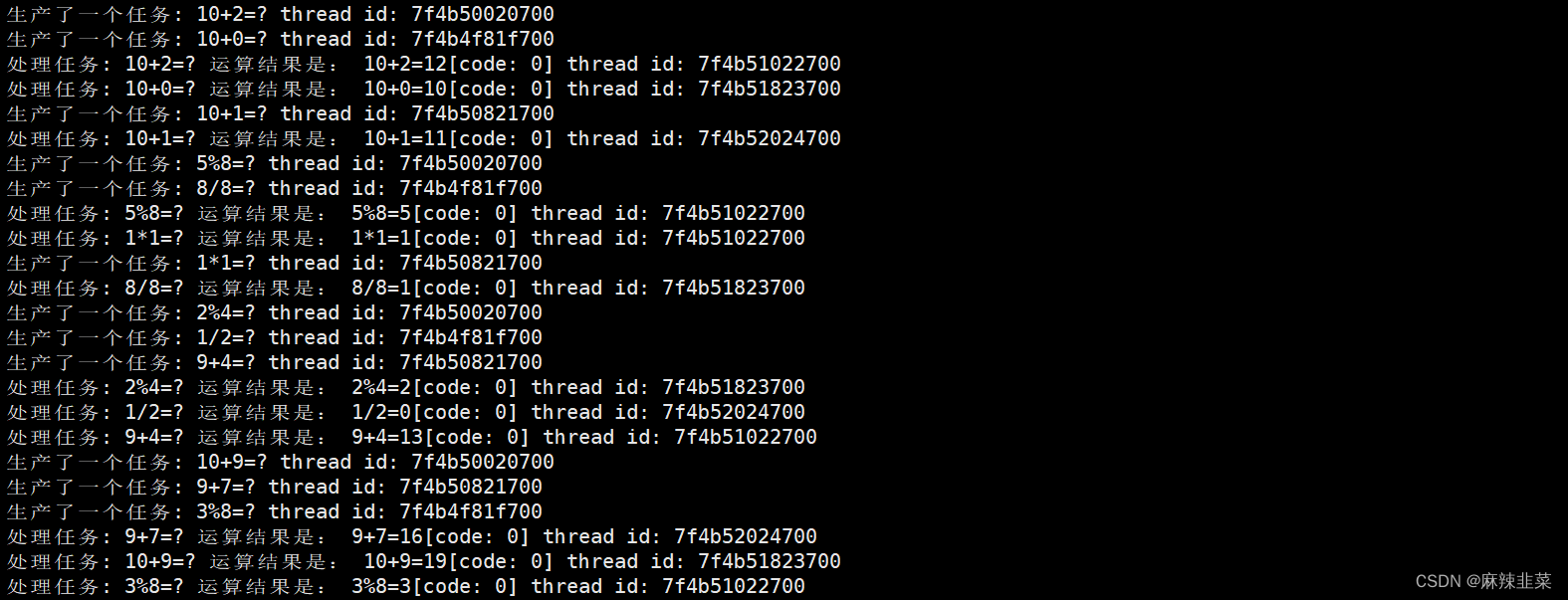
{// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);while (true){Task t = bq->pop();t();std::cout << "处理任务: " << t.GetTask() << " 运算结果是: "<< t.GetResult() << " thread id: " << pthread_self() << std::endl;}
}
void *Productor(void *args) // 生产者
{// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);int len = opers.size();while (true){int data1 = rand() % 10 + 1;int data2 = rand() % 10;char oper = opers[rand() % len];Task t(data1, data2, oper);bq->push(t);std::cout << "生产了一个任务: " << t.GetTask() << " thread id: " << pthread_self() << std::endl;sleep(1);}
}
注:
其实我们不用非要等到满了,才停止生产。我们可以定策略,就如同水库的警戒线,当河水上涨到警戒线时,就开闸放水,而不是等到水库满了才放。消费也是同理。
int low_water_;int high_water_;2.2 多生产多消费
我们实现了单生产单消费,这里改成多生产多消费,非常简单。只需要在mian.cc这里循环创建线程即可
int main()
{srand(time(nullptr) ^ getpid());Blockqueue<Task> *bq = new Blockqueue<Task>;// 创建线程(生产、消费)pthread_t c[3], p[5];for (int i = 0; i < 3; i++){pthread_create(c + i, nullptr, Consumer, bq);}for (int i = 0; i < 5; i++){pthread_create(p + i, nullptr, Productor, bq);}for (int i = 0; i < 3; i++){pthread_join(c[i], nullptr);}for (int i = 0; i < 5; i++){pthread_join(p[i], nullptr);}delete bq;return 0;
}
出现上面的错误是因为伪唤醒的原因
为什么会出现伪唤醒的?

现在是多个线程了,也就是说当阻塞队列满时,所有的生产线程被阻塞等待被唤醒。消费线程这时消费一个数据,当阻塞队列不满时,那么就会唤醒所有的生产线程,3个线程只有一个线程能拿到锁,其中一个拿到锁线程进行生产此时阻塞队列已经满了。等其他线程拿到锁后,条件不满足。生产不了,这就是伪唤醒。
所以我们把if改成while 循环判断防止伪唤醒
void push(const T &data) // 生产数据{pthread_mutex_lock(&_mutex);while (_q.size() == _maxcap) // 用while防止伪唤醒,判断条件满不满足{pthread_cond_wait(&_p_cond, &_mutex); // 不满足阻塞}_q.push(data);pthread_cond_signal(&_c_cond);pthread_mutex_unlock(&_mutex);}T pop() // 消费数据{pthread_mutex_lock(&_mutex);while (_q.size() == 0) // 用while防止伪唤醒,判断条件满不满足{pthread_cond_wait(&_c_cond, &_mutex); // 不满足阻塞}T out = _q.front();_q.pop();pthread_cond_signal(&_p_cond);pthread_mutex_unlock(&_mutex);return out;} 
这里我们直接用C++的锁。

std:: mutex _mutex;
void *Consumer(void *args) // 消费者
{// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);while (true){Task t = bq->pop();t();std::lock_guard<std::mutex> guard(_mutex);std::cout << "处理任务: " << t.GetTask() << " 运算结果是: " << t.GetResult() << " thread id: "<< std::hex << pthread_self() << std::endl;}
}
void *Productor(void *args) // 生产者
{int len = opers.size();// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);while (true){ sleep(1);int data1 = rand() % 10 + 1;int data2 = rand() % 10;char oper = opers[rand() % len];Task t(data1, data2, oper);bq->push(t);std::lock_guard<std::mutex> guard(_mutex);std::cout << "生产了一个任务: " << t.GetTask() << " thread id: " << std::hex << pthread_self() << std::endl;}
}

为什么只修改线程创建的代码,多线程就能适应原来的消费场景?
原因有2点:
- 生产者、消费者都是在对同一个
_queue操作,用一把锁,保护一个临界资源,足够了 - 当前的
_queue始终是被当作一个整体使用的,无需再增加锁区分
当然也可以让生产者和消费者各自拿一把锁,但是都是基于_queue的完全没有必要,画蛇添足。
3. POSIX 信号量
在 POSIX 标准中,信号量(semaphore)是一种用于控制多个进程或线程对共享资源访问的同步机制。信号量是一个计数器,它可以跟踪一定数量的资源或信号量单位。进程或线程可以通过原子操作对信号量进行增加或减少,从而实现对共享资源的协调访问。
也就是说,让线程的同步的方法,不仅仅只有条件变量,还有信号量。
POSIX 信号量有两种类型:
-
无名信号量(Unnamed semaphores):也称为进程间信号量,因为它们可以在不同的进程之间共享。无名信号量使用
sem_t类型表示,并通过sem_init()函数初始化,使用sem_destroy()函数销毁。无名信号量需要一个与之关联的键值来标识,这个键值可以通过ftok()或shmget()函数获得。 -
命名信号量(Named semaphores):也称为系统V信号量,它们是系统范围内唯一的,并且可以跨会话使用。命名信号量通过
semget()函数创建,使用semctl()函数控制,使用semop()函数进行操作。
文档的话太抽象了,下面我用大白话来解释信号量
我们将阻塞队列比喻成电影院,而信号量就如同电影票,电影院是一个整体的公共资源,那么电影院的座位就把电影院这个整体划分为无数份的资源。而信号量就是预定座位资源。
那么当我们购买电影票成功或不成功,对应编程来说,其实就是在访问临界资源的同时进行了临界资源就绪或者不就绪判断。
就绪意味者线程可以访问
不就绪意味着线程不可访问
POSIX 信号量的基本操作:
初始化:使用 sem_init() 初始化一个无名信号量
int sem_init(sem_t *sem, int pshared, unsigned int value);sem:指向信号量变量的指针。pshared:非零表示信号量可以被其他进程访问,零表示只能在当前进程内访问。value:信号量的初始值。
等待(减):使用 sem_wait() 或 sem_trywait() 减少信号量,如果信号量的值大于零,则减少其值,否则进程将等待。
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);信号量值增加(信号):使用 sem_post() 增加信号量的值,如果其他进程因为信号量的值小于或等于零而等待,则其中一个进程将被唤醒。
int sem_post(sem_t *sem);获取信号量值:使用 sem_getvalue() 获取信号量的当前值。
int sem_getvalue(sem_t *sem, int *sval);销毁信号量:使用 sem_destroy() 销毁一个无名信号量。
int sem_destroy(sem_t *sem);这些接口使用起来还是比较简单,下面我们用信号量来实现生产消费者模型。前面用的是阻塞队列,我们用信号量实现基于循环队列版本。
4. 基于循环队列实现生产消费者模型
在实现之前我们先了解循环队列这种数据结构。我们利用数组这种数据结构,然后对下标进行取模可以让数组变成循环的结构

一张动图搞定循环队列这种数据结构
这里有几个关键问题:
问题1:生产者关注什么资源?消费者关注什么资源?
生产者关注的是数组还有多少空间、消费者关注的是数组还有多少数据。
问题2:生产者和消费者什么时候才会指向同一个位置?
要么数组为空、要么数组为满。(这两种状态只能是生产和消费其中一个进行访问,空生产者访问、满消费者访问。)
反之一定是指向不同的位置 (这句话非常重要,意味着生产和消费可以同时访问)
那么循环队列要正常运行必须满足3个条件
1. 空或者满只能有一个人访问
2. 消费者一定不能超过生产者
3. 生产者一定不能套圈消费者
如果消费者超过生产者,前面都没有数据,访问什么?
为什么这么说?因为最开始一定为空。那么一定是生产者先走!毫无疑问
如果生产者套圈消费者意味着生产速度大于消费速度之前没有消费的数据要被覆盖。数据出现覆盖,严重错误。
理解了这些问题我们直接多生产多消费来实现
4.1 多生产多消费
老规矩先创建RingQueue.hpp头文件
#include <iostream>
#include <vector>
#include <pthread.h>
#include <semaphore.h>
const static int defaultcap = 5;
template <class T>
class RingQueue
{
public:RingQueue(int cap = defaultcap): _ringqueue(cap), _cap(cap), _c_step(0), _p_step(0)sem_init(&_cdata_sem, 0, 0);sem_init(&_pspace_sem, 0, cap);pthread_mutex_init(&_c_mutex, nullptr);pthread_mutex_init(&_p_mutex, nullptr);}void push(const T& data){}T pop(T* out){}~RingQueue(){sem_destroy(&_cdata_sem);sem_destroy(&_pspace_sem);pthread_mutex_destroy(&_c_mutex);pthread_mutex_destroy(&_p_mutex);}private:std::vector<T> _ringqueue; // 循环队列int _cap; // 循环队列容量int _c_step; // 消费者下标int _p_step; // 生产者下标sem_t _cdata_sem; // 消费者关注的数据资源sem_t _pspace_sem; // 生产者关注的空间资源pthread_mutex_t _c_mutex; // 消费者锁pthread_mutex_t _p_mutex; // 生产者锁
};框架大致构建出来,为了方便生产消费的互斥与同步。我们接下来对生产和消费线程互斥与同步的函数进行封装
void Lock(pthread_mutex_t &mutex){pthread_mutex_lock(&mutex);}void UnLock(pthread_mutex_t &mutex){pthread_mutex_unlock(&mutex);}void P(sem_t &sem) //减少{sem_wait(&sem);}void v(sem_t &sem) //增加{sem_post(&sem);}
实现push 和 pop函数
void Push(const T &data){P(_pspace_sem);Lock(_p_mutex);_ringqueue[_p_step++] = data;_p_step %= _cap;UnLock(_p_mutex);V(_cdata_sem);}T Pop(T *out){P(_cdata_sem);Lock(_c_mutex);*out = _ringqueue[_c_step++];_c_step %= _cap;Unlock(_c_mutex);V(_pspace_sem);return out;}这里解释push函数P操作为什么传入的是空间信号量,很简单生产者关注的是空间资源,所以这里P判断空间资源就不就绪,V为什么传入的是数据信号量?当P申请成功意味着可以生产,那么对应空间资源减少,数据资源增加。
同理pop也是一样。
我们mian.cc创建线程 和回调函数
#include <unistd.h>
#include <mutex>
#include <ctime>
#include "RingQueue.hpp"
#include "Task.hpp"
std::mutex _mutex;
void *consumer(void *args)
{RingQueue<Task> *rq = static_cast<RingQueue<Task> *>(args);while (true){Task t;rq->Pop(&t);t();std::lock_guard<std::mutex> guard(_mutex);std::cout << "处理任务: " << t.GetTask() << " 运算结果是: " << t.GetResult() << " thread id: "<< std::hex << pthread_self() << std::endl;}
}
void *productor(void *args)
{RingQueue<Task> *rq = static_cast<RingQueue<Task> *>(args);int len = opers.size();while (true){sleep(1);int data1 = rand() % 10 + 1;int data2 = rand() % 10;char oper = opers[rand() % len];Task t(data1, data2, oper);rq->Push(t);std::lock_guard<std::mutex> guard(_mutex);std::cout << "生产了一个任务: " << t.GetTask() << " thread id: " << std::hex << pthread_self() << std::endl;}
}int main()
{srand(time(nullptr) ^ getpid()); // 随机数种子RingQueue<Task> *rq = new RingQueue<Task>(40);pthread_t c[3], p[3];for (int i = 0; i < 3; i++){pthread_create(c + i, nullptr, consumer, rq);}for (int i = 0; i < 3; i++){pthread_create(p + i, nullptr, productor, rq);}for (int i = 0; i < 3; i++){pthread_join(c[i], nullptr);}for (int i = 0; i < 3; i++){pthread_join(p[i], nullptr);}delete rq;return 0;
}
这里打印只打印了线程ID,我们可以重新创建一个线程名字的类。把线程名字加入进去
struct ThreadData
{RingQueue<Task> *rq;std::string threadname;
};
细节: 加锁行为放在信号量申请成功之后,可以提高并发度


为什么这么说,信号量在加锁之前就好比,没进电影院之前就已经选好了座位,如果在加锁之后,那就如同进到电影院之后在选座位,而再选座位就又得排队买票。而且信号量本身就是原子操作。
那既然阻塞队列也能实现生产消费者模型,那搞出来个循坏队列又有什么用?
环形队列的优缺点:
优点:
- 空间利用率高:由于是环形结构,已使用的空间可以重复利用,不会像普通队列一样造成空间的浪费。
- 插入和删除速度快:由于是线性结构,环形队列的插入和删除操作通常很快,因为它们只涉及到头尾指针的移动。
- 固定大小的存储空间:可以避免内存泄漏等问题,因为不会动态地分配和回收内存。
缺点:
- 需要额外的指针维护状态:增加了复杂度,需要维护队列头和队尾的指针。
- 存储空间可能未被充分利用:一旦队列满了,就需要覆盖队列头的元素,这可能导致存储空间没有被完全利用。
- 队列大小必须预先定义:难以动态调整大小,这在某些需要灵活内存使用的场景下可能是一个限制。
阻塞队列的优缺点:
优点:
- 线程同步:阻塞队列可以很好地实现线程之间的同步,简化了生产者和消费者之间的数据传递和通信。
- 解耦合:作为生产者消费者模式的缓冲空间,阻塞队列降低了生产者和消费者之间的耦合性。
- 削峰填谷:由于阻塞队列的大小是有限的,它可以起到限制作用,平衡突发的流量高峰。
缺点:
- 可能引发死锁:如果使用不当,比如生产者和消费者互相等待对方释放资源时,可能会发生死锁。
- 对性能的影响:线程的挂起和唤醒操作可能会对系统性能产生影响,尤其是在高并发场景下。
- 处理超时操作较复杂:在设置了超时时间的情况下,需要处理超时异常并进行相应的补偿或回滚操作,增加了编程复杂性。
每种数据结构都有其特定的使用场景和限制,开发者在选择时应根据具体需求和上下文来决定使用哪一种。
本篇我们学习了什么是生产消费者模型,基于两种数据结构,分别实现了生产消费者模型,
还掌握了一个线程同步神奇——信号量。这对于提高线程之间的并发度非常有用。再次理解了生产消费者模型为什么高效?总之生产消费者模型非常值得我们学习。

相关文章:
Linux 生产消费者模型
💓博主CSDN主页:麻辣韭菜💓 ⏩专栏分类:Linux初窥门径⏪ 🚚代码仓库:Linux代码练习🚚 🌹关注我🫵带你学习更多Linux知识 🔝 前言 1. 生产消费者模型 1.1 什么是生产消…...

深入浅出:MongoDB中的背景创建索引
深入浅出:MongoDB中的背景创建索引 想象一下,你正忙于将成千上万的数据塞入你的MongoDB数据库中,你的用户期待着实时的响应速度。此时,你突然想到:“嘿,我应该给这些查询加个索引!” 没错&…...

Spring事务十种失效场景
首先我们要明白什么是事务?它的作用是什么?它在什么场景下在Spring框架下会失效? 事务:本质上是由数据库和程序之间交互的过程中的衍生物,它是一种控制数据的行为规则。有几个特性 1、原子性:执行单元内,要…...

JELR-630HS漏电继电器 30-500mA 导轨安装 约瑟JOSEF
JELR-HS系列 漏电继电器型号: JELR-15HS漏电继电器;JELR-25HS漏电继电器; JELR-32HS漏电继电器;JELR-63HS漏电继电器; JELR-100HS漏电继电器;JELR-120HS漏电继电器; JELR-160HS漏电继电器&a…...

如何实现一个简单的链表或栈结构
实现一个简单的链表或栈结构是面向对象编程中的基础任务。下面我将分别给出链表和栈的简单实现。 链表(单链表)的实现 链表是由一系列节点组成的集合,每个节点都包含数据部分和指向列表中下一个节点的链接(指针或引用࿰…...

抖音外卖服务商入驻流程及费用分别是什么?入驻官方平台的难度大吗?
随着抖音关于新增《【到家外卖】内容服务商开放准入公告》的意见征集通知(以下简称“通知”)的发布,抖音外卖服务商入驻流程及费用逐渐成为众多创业者所关注和热议的话题。不过,就当前的讨论情况来看,这个话题似乎没有…...

“小红书、B站崩了”,背后的阿里云怎么了?
导语:阿里云不能承受之重 文 | 魏强 7月2日,“小红书崩了”、“B站崩了”等话题登上了热搜。 据第一财经、财联社等报道,7月2日,用户在B站App无法使用浏览历史关注等内容,消息界面、更新界面、客服界面均不可用&…...
nginx的配置文件
nginx.conf 1、全局模块 worker_processes 1; 工作进程数,设置成服务器内核数的2倍(一般不超过8个,超过8个反正会降低性能,4个 1-2个 ) 处理进程的过程必然涉及配置文件和展示页面,也就是涉及打开文件的…...

艾滋病隐球菌病的病原学诊断方法包括?
艾滋病隐球菌病的病原学诊断方法包括()查看答案 A.培养B.隐球菌抗原C.墨汁染色D.PCR 在感染性疾病研究中,单细胞转录组学的应用包括哪些()? A.细胞异质性研究B.基因组突变检测C.感染过程单细胞分析D.代谢通路分析 开展病原微生物网络实验室体系建设,应通…...

jQuery Tooltip 插件使用教程
jQuery Tooltip 插件使用教程 引言 jQuery Tooltip 插件是 jQuery UI 套件的一部分,它为网页元素添加了交互式的提示框功能。通过这个插件,开发者可以轻松地为链接、按钮、图片等元素添加自定义的提示信息,从而增强用户的交互体验。本文将详细介绍如何使用 jQuery Tooltip…...

访问者模式在金融业务中的应用及其框架实现
引言 访问者模式(Visitor Pattern)是一种行为设计模式,它允许你在不改变对象结构的前提下定义作用于这些对象的新操作。通过使用访问者模式,可以将相关操作分离到访问者中,从而提高系统的灵活性和可维护性。在金融业务…...

.npy格式图像如何进行深度学习模型训练处理,亲测可行
import torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npfrom torch.utils.data import DataLoader, Datasetfrom torchvision import transformsfrom PIL import Imageimport json# 加载训练集和测试集数据train_images np.load(../dataset/tra…...

XFeat快速图像特征匹配算法
XFeat(Accelerated Features)是一种新颖的卷积神经网络(CNN)架构,专为快速和鲁棒的像匹配而设计。它特别适用于资源受限的设备,同时提供了与现有深度学习方法相比的高速度和准确性。 轻量级CNN架构…...
普元EOS学习笔记-低开实现图书的增删改查
前言 在前一篇《普元EOS学习笔记-创建精简应用》中,我已经创建了EOS精简应用。 我之前说过,EOS精简应用就是自己创建的EOS精简版,该项目中,开发者可以进行低代码开发,也可以进行高代码开发。 本文我就记录一下自己在…...

动态住宅代理IP详细解析
在大数据时代的背景下,代理IP成为了很多企业顺利开展的重要工具。代理IP地址可以分为住宅代理IP地址和数据中心代理IP地址。选择住宅代理IP的好处是可以实现真正的高匿名性,而使用数据中心代理IP可能会暴露自己使用代理的情况。 住宅代理IP是指互联网服务…...

等保2.0 实施方案之信息软件验证要求
一、等保2.0背景及意义 随着信息技术的快速发展和网络安全威胁的不断演变,网络安全已成为国家安全、社会稳定和经济发展的重要保障。等保2.0(即《信息安全技术 网络安全等级保护基本要求》2.0版本)作为网络安全等级保护制度的最新标准&#x…...

【LeetCode的使用方法】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 🔮LeetCode的使用方法 🔮LeetCode 是一个在线编程平台,广泛…...

【SGX系列教程】(二)第一个 SGX 程序: HelloWorld,linux下运行
文章目录 0. SGX基础原理分析一.准备工作1.1 前提条件1.2 SGX IDE1.3 基本原理 二.程序设计2.1 目录结构2.2 源码设计2.2.1 Encalve/Enclave.edl:Enclave Description Language2.2.2 Enclave/Enclave.lds: Enclave linker script2.2.3 Enclave/Enclave.config.xml: Enclave 配置…...
网页报错dns_probe_possible 怎么办?——错误代码有效修复
当你在浏览网页时遇到dns_probe_possible 错误,这通常意味着你的浏览器无法解析域名系统(DNS)地址。这个问题可能是由多种原因引起的,包括网络配置问题、DNS服务问题、或是本地设备的问题。教大家几种修复网页报错dns_probe_possi…...

Vue.js 中属性绑定的详细解析:冒号 `:` 和非冒号的区别
Vue.js 中属性绑定的详细解析:冒号 : 和非冒号的区别 在 Vue.js 中,属性绑定是一个重要的概念,它决定了如何将数据绑定到 DOM 元素的属性上。Vue.js 提供了两种方式来绑定属性:使用冒号 : 进行动态绑定,或直接书写属性…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...