大模型笔记1: Longformer环境配置
论文:
https://arxiv.org/abs/2004.05150
目录
库安装
LongformerForQuestionAnswering
库安装
首先保证电脑上配置了git.
git环境配置:
https://blog.csdn.net/Andone_hsx/article/details/87937329
| 3.1、找到git安装路径中bin的位置,如:D:\Program Files\Git\bin 找到git安装路径中git-core的位置,如:D:\Program Files\Git\libexec\git-core; 注:"D:\Program Files\Git\"是安装路径,可能与你的安装路径不一样,要按照你自己的路径替换"D:\Program Files\Git\" 3.2、右键“计算机”->“属性”->“高级系统设置”->“环境变量”->在下方的“系统变量”中找到“path”->选中“path”并选择“编辑”->将 3.1中找到的bin和git-core路径复制到其中->保存并退出 注:“path”中,每个路径之间要以英文输入状态下的分号——“;”作为间隔 |
| D:\Program Files\Git\mingw64\bin D:\Program Files\Git\mingw64\libexec\git-core |
安装环境
| conda create --name longformer python=3.7 y conda activate longformer conda install cudatoolkit=10.0 y pip install git+https://github.com/allenai/longformer.git |
报错:
| ERROR: Could not find a version that satisfies the requirement pandas>=0.20.3 (from test-tube) (from versions: none) ERROR: No matching distribution found for pandas>=0.20.3 |
| No module named 'pandas' |
Install装不上, 在anaconda navigator装的
更换清华源后似乎可以继续运行了, 参考:
https://www.cnblogs.com/raiuny/p/15950043.html
| conda config --add channels Index of /anaconda/cloud/pytorch/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror conda config --set show_channel_urls yes conda config --set auto_activate_base false pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple |
好几次报错128, 也许是RP问题, 总之重新运行几次后安装成功了.
环境安装成功会显示successful.
接着跑tests文件夹的test_readme.py, 注意需要下载longformer-base-4096.tar.gz
这个文件我放在项目目录下的/tmp文件夹和tests/tmp都无法读取, 因此修改了self.model_dir路径为绝对路径, 并注释下载解压代码, 就可以运行了:

LongformerForQuestionAnswering
1)test_readme中默认使用的Longformer模型输出是embedding, 缺少LMHead把embedding映射成tokenid或logits等, 无法输出文字. 如果使用Longformer完成最终任务, 需要自己写映射并训练.
2)文档其它longformer模型. 大部分为分类模型. 其中LongformerForQuestionAnswering符合extractive summarization
3)coding过程中可以参考huggingface上的文档例子从transformers库里面调用其它种类的longformer
| from transformers import AutoTokenizer, LongformerForQuestionAnswering import torch tokenizer = AutoTokenizer.from_pretrained("allenai/longformer-large-4096-finetuned-triviaqa") model = LongformerForQuestionAnswering.from_pretrained("allenai/longformer-large-4096-finetuned-triviaqa") question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet" encoding = tokenizer(question, text, return_tensors="pt") input_ids = encoding["input_ids"] # default is local attention everywhere # the forward method will automatically set global attention on question tokens attention_mask = encoding["attention_mask"] outputs = model(input_ids, attention_mask=attention_mask) start_logits = outputs.start_logits end_logits = outputs.end_logits all_tokens = tokenizer.convert_ids_to_tokens(input_ids[0].tolist()) answer_tokens = all_tokens[torch.argmax(start_logits) : torch.argmax(end_logits) + 1] answer = tokenizer.decode( tokenizer.convert_tokens_to_ids(answer_tokens) ) # remove space prepending space token |
如果加载其它qa模型(longformer_base_4096_QA_SQUAD)不配套会报错:
| Some weights of the model checkpoint at tmp/longformer_base_4096_QA_SQUAD were not used when initializing LongformerForQuestionAnswering: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias'] |
按照示例代码加载longformer-large-4096-finetuned-triviaqa后报错
| start_logits = outputs.start_logits AttributeError: 'tuple' object has no attribute 'start_logits' |
这个报错的意思是返回值不是对象而是元组, 因此判断如果是元组, 则手动解析
| if isinstance(outputs, tuple): loss,start_logits, end_logits,hidden_states,attentions = outputs else: start_logits = outputs.start_logits end_logits = outputs.end_logits |
| 库中LongformerForQuestionAnswering类代码有两处可能返回 1. output = (start_logits, end_logits) + outputs[2:] 2. return SequenceClassifierOutput( loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions, ) |
相关文章:
大模型笔记1: Longformer环境配置
论文: https://arxiv.org/abs/2004.05150 目录 库安装 LongformerForQuestionAnswering 库安装 首先保证电脑上配置了git. git环境配置: https://blog.csdn.net/Andone_hsx/article/details/87937329 3.1、找到git安装路径中bin的位置,如:D:\Prog…...
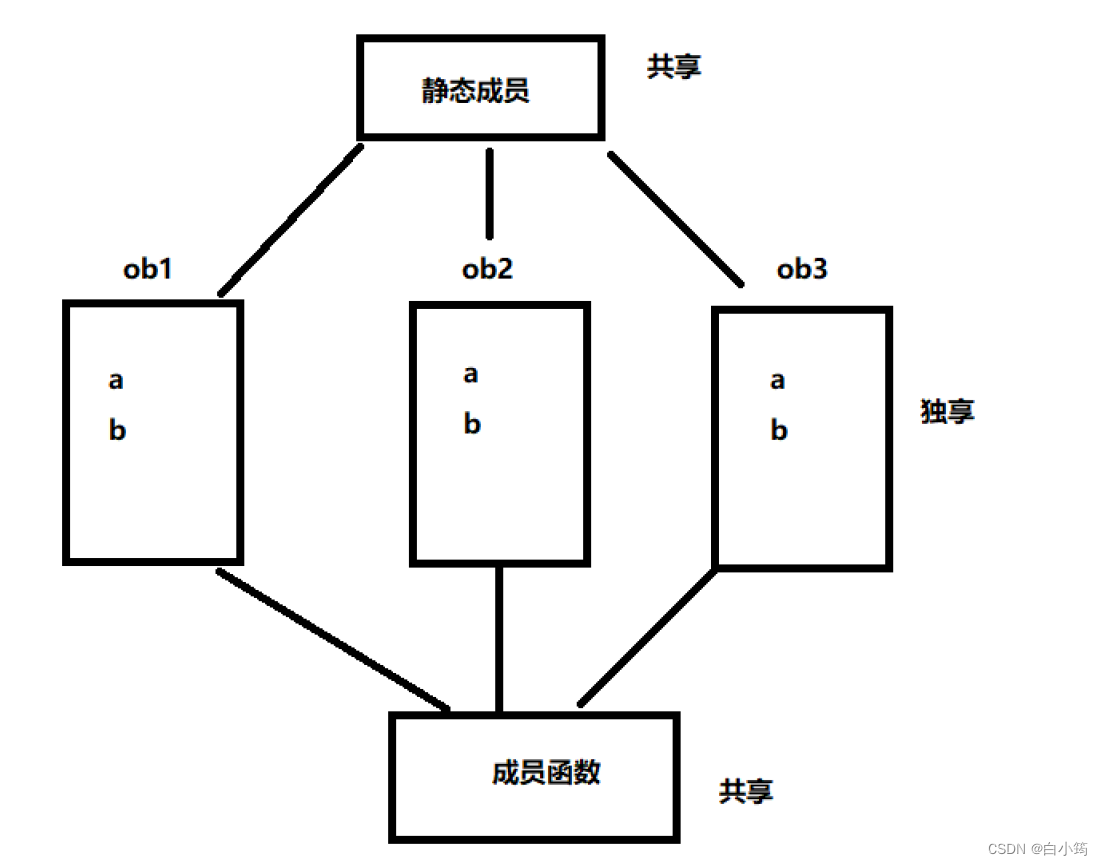
类和对象(提高)
类和对象(提高) 1、定义一个类 关键字class 6 class Data1 7 { 8 //类中 默认为私有 9 private: 10 int a;//不要给类中成员 初始化 11 protected://保护 12 int b; 13 public://公共 14 int c; 15 //在类的内部 不存在权限之分 16 void showData(void)…...

免费最好用的证件照制作软件,一键换底+老照片修复+图片动漫化,吊打付费!
这款软件真的是阿星用过的,最好用的证件照制作软件,没有之一! 我是阿星,今天要给大家安利一款超实用的证件照工具,一键换底,自动排版,免费无广告,让你在家就能轻松搞定证件照&#…...

antfu/ni 在 Windows 下的安装
问题 全局安装 ni 之后,第一次使用会有这个问题 解决 在 powershell 中输入 Remove-Item Alias:ni -Force -ErrorAction Ignore之后再次运行 ni Windows 11 下的 Powershell 环境配置 可以参考 https://github.com/antfu-collective/ni?tabreadme-ov-file#how …...

Linux 生产消费者模型
💓博主CSDN主页:麻辣韭菜💓 ⏩专栏分类:Linux初窥门径⏪ 🚚代码仓库:Linux代码练习🚚 🌹关注我🫵带你学习更多Linux知识 🔝 前言 1. 生产消费者模型 1.1 什么是生产消…...

深入浅出:MongoDB中的背景创建索引
深入浅出:MongoDB中的背景创建索引 想象一下,你正忙于将成千上万的数据塞入你的MongoDB数据库中,你的用户期待着实时的响应速度。此时,你突然想到:“嘿,我应该给这些查询加个索引!” 没错&…...

Spring事务十种失效场景
首先我们要明白什么是事务?它的作用是什么?它在什么场景下在Spring框架下会失效? 事务:本质上是由数据库和程序之间交互的过程中的衍生物,它是一种控制数据的行为规则。有几个特性 1、原子性:执行单元内,要…...

JELR-630HS漏电继电器 30-500mA 导轨安装 约瑟JOSEF
JELR-HS系列 漏电继电器型号: JELR-15HS漏电继电器;JELR-25HS漏电继电器; JELR-32HS漏电继电器;JELR-63HS漏电继电器; JELR-100HS漏电继电器;JELR-120HS漏电继电器; JELR-160HS漏电继电器&a…...

如何实现一个简单的链表或栈结构
实现一个简单的链表或栈结构是面向对象编程中的基础任务。下面我将分别给出链表和栈的简单实现。 链表(单链表)的实现 链表是由一系列节点组成的集合,每个节点都包含数据部分和指向列表中下一个节点的链接(指针或引用࿰…...

抖音外卖服务商入驻流程及费用分别是什么?入驻官方平台的难度大吗?
随着抖音关于新增《【到家外卖】内容服务商开放准入公告》的意见征集通知(以下简称“通知”)的发布,抖音外卖服务商入驻流程及费用逐渐成为众多创业者所关注和热议的话题。不过,就当前的讨论情况来看,这个话题似乎没有…...

“小红书、B站崩了”,背后的阿里云怎么了?
导语:阿里云不能承受之重 文 | 魏强 7月2日,“小红书崩了”、“B站崩了”等话题登上了热搜。 据第一财经、财联社等报道,7月2日,用户在B站App无法使用浏览历史关注等内容,消息界面、更新界面、客服界面均不可用&…...
nginx的配置文件
nginx.conf 1、全局模块 worker_processes 1; 工作进程数,设置成服务器内核数的2倍(一般不超过8个,超过8个反正会降低性能,4个 1-2个 ) 处理进程的过程必然涉及配置文件和展示页面,也就是涉及打开文件的…...

艾滋病隐球菌病的病原学诊断方法包括?
艾滋病隐球菌病的病原学诊断方法包括()查看答案 A.培养B.隐球菌抗原C.墨汁染色D.PCR 在感染性疾病研究中,单细胞转录组学的应用包括哪些()? A.细胞异质性研究B.基因组突变检测C.感染过程单细胞分析D.代谢通路分析 开展病原微生物网络实验室体系建设,应通…...

jQuery Tooltip 插件使用教程
jQuery Tooltip 插件使用教程 引言 jQuery Tooltip 插件是 jQuery UI 套件的一部分,它为网页元素添加了交互式的提示框功能。通过这个插件,开发者可以轻松地为链接、按钮、图片等元素添加自定义的提示信息,从而增强用户的交互体验。本文将详细介绍如何使用 jQuery Tooltip…...

访问者模式在金融业务中的应用及其框架实现
引言 访问者模式(Visitor Pattern)是一种行为设计模式,它允许你在不改变对象结构的前提下定义作用于这些对象的新操作。通过使用访问者模式,可以将相关操作分离到访问者中,从而提高系统的灵活性和可维护性。在金融业务…...

.npy格式图像如何进行深度学习模型训练处理,亲测可行
import torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npfrom torch.utils.data import DataLoader, Datasetfrom torchvision import transformsfrom PIL import Imageimport json# 加载训练集和测试集数据train_images np.load(../dataset/tra…...

XFeat快速图像特征匹配算法
XFeat(Accelerated Features)是一种新颖的卷积神经网络(CNN)架构,专为快速和鲁棒的像匹配而设计。它特别适用于资源受限的设备,同时提供了与现有深度学习方法相比的高速度和准确性。 轻量级CNN架构…...
普元EOS学习笔记-低开实现图书的增删改查
前言 在前一篇《普元EOS学习笔记-创建精简应用》中,我已经创建了EOS精简应用。 我之前说过,EOS精简应用就是自己创建的EOS精简版,该项目中,开发者可以进行低代码开发,也可以进行高代码开发。 本文我就记录一下自己在…...

动态住宅代理IP详细解析
在大数据时代的背景下,代理IP成为了很多企业顺利开展的重要工具。代理IP地址可以分为住宅代理IP地址和数据中心代理IP地址。选择住宅代理IP的好处是可以实现真正的高匿名性,而使用数据中心代理IP可能会暴露自己使用代理的情况。 住宅代理IP是指互联网服务…...

等保2.0 实施方案之信息软件验证要求
一、等保2.0背景及意义 随着信息技术的快速发展和网络安全威胁的不断演变,网络安全已成为国家安全、社会稳定和经济发展的重要保障。等保2.0(即《信息安全技术 网络安全等级保护基本要求》2.0版本)作为网络安全等级保护制度的最新标准&#x…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...