Elasticsearch 第四期:搜索和过滤
序
2024年4月,小组计算建设标签平台,使用ES等工具建了一个demo,由于领导变动关系,项目基本夭折。其实这两年也陆陆续续接触和使用过ES,两年前也看过ES的官网,当时刚毕业半年多,由于历史局限性导致根本看不懂。因此趁着这个机会,在5月~6月期间,基本看了一遍ES的官方文档,先从整体梳理了ES的基础知识,共四期。
Elasticsearch 第一期:ES的前世今生-CSDN博客
Elasticsearch 第二期:基础的基础概念-CSDN博客
Elasticsearch 第三期:倒排索引,分析,映射-CSDN博客
Elasticsearch 第四期:搜索和过滤-CSDN博客
前言
这篇文章的内容是根据ES官方关于搜索的章节整理的。但目录结构做了重新整理。分别从相关性,搜索,过滤进行了介绍。具体如下:
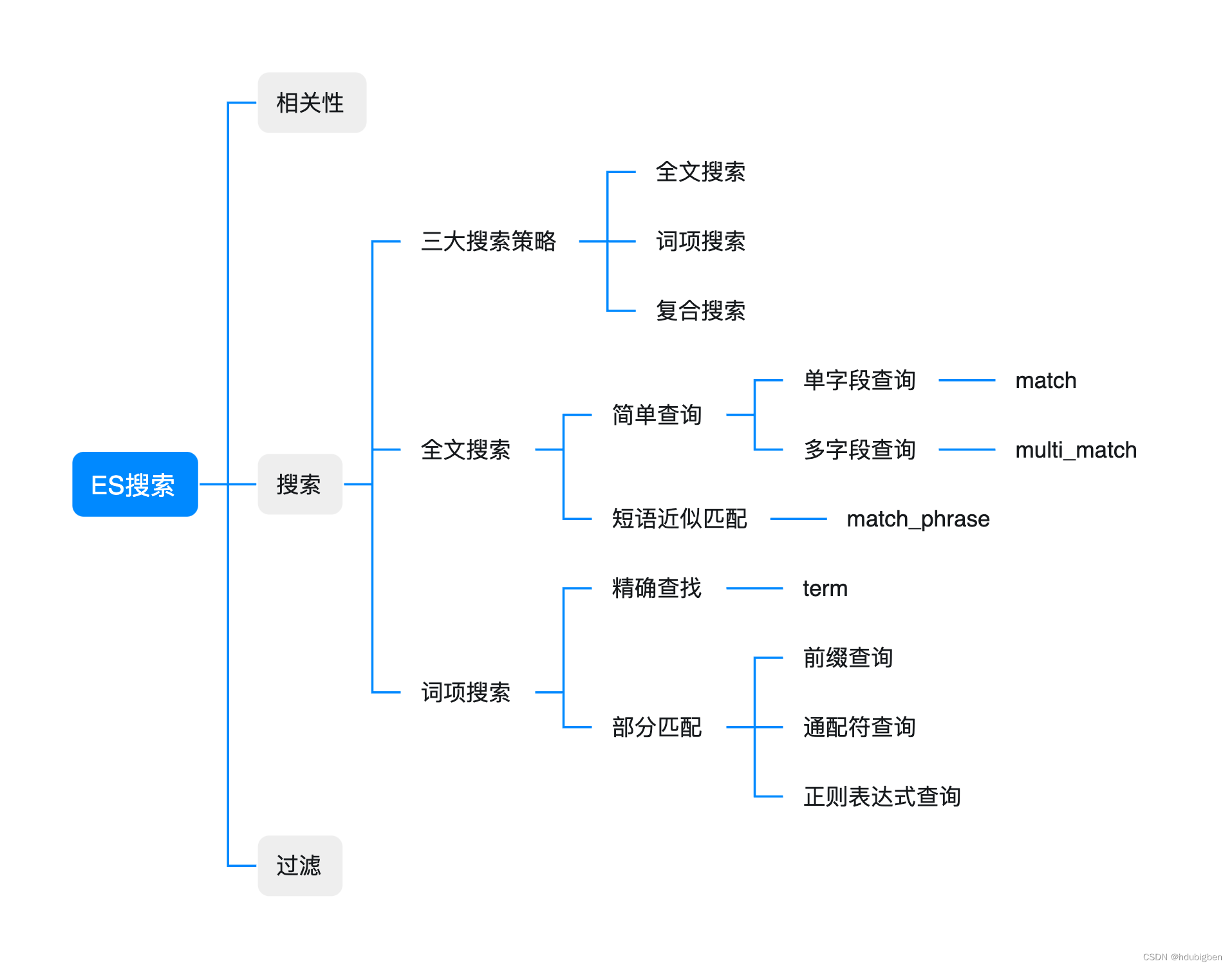
相关性
ES搜索的本质其实是把文档根据搜索内容进行相关性排序。所以在介绍ES搜索之前,先简单介绍一下ES相关性。关于相关性的理论知识具体可以参考官网。当然相关性得分只是搜索排序的一种,还有特殊场景的排序方法,如地理位置邻近算法。
众所周知,查询语句会为每个文档生成一个评分: _score 。通常我们说的 相关性 是用来计算全文本字段的值相对于全文本检索词相似程度的算法。
Elasticsearch 的相似度算法被定义为:TF/IDF(检索词频率/反向文档频率) 。
检索词频率:检索词在该字段出现的频率。出现频率越高,相关性也越高。 字段中出现过 5 次要比只出现过 1 次的相关性高。
反向文档频率:每个检索词在全部索引中出现的频率。频率越高,计算相关时相关性的权重越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
字段长度准则:该字段的长度是多少。长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
| 检索词频率 | title:dog love person | 很明显,dog在第二个文档中出现了2次,因此文档2相关性更强 |
| title:dog love dog | ||
| 反向文档频率 | title:dog love person | 当使用dog和person来搜索时,虽然文档2被命中了2次,但person在全部文档中出现了频率比dog少,因此计算person相关性权重的时候会更大 |
| title:dog love dog | ||
| 字段长度准则 | title:dog love person | 搜索love时可以名字两个文档,但文档2中的字段相对较短,其得分更高。 |
| title:dog love dog |
搜索
搜索的过程就是在全文字段中搜索到最相关的文档。搜索两个最重要的方面是:
相关性(Relevance)它是评价查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力
分析(Analysis)它是将搜索关键字和文档内容转换为有区别的、规范化的 词项(token) 的一个过程。 目的是为了(a)创建倒排索引 (b)查询倒排索引。
在Elasticsearch 7.x中,它提供了三种主要的文档检索方式:全文搜索、词项搜索和复合搜索。
全文搜索
简单查询
全文搜索是Elasticsearch最常见的搜索方式,主要用于搜索文本字段。用户只需要提供关键词,Elasticsearch就能自动地在索引中找到包含这些关键词的文档。在全文搜索中,Elasticsearch使用了一种名为“倒排索引”的数据结构,可以非常高效地执行搜索操作。
全文搜索主要通过match查询实现。match查询会对用户给出的关键词进行解析,然后进行分词处理。只要查询语句中的任意一个词项在文档中被匹配,该文档就会被检索到。
全文搜索经常用的命令包括:
| match | 匹配查询,用于单字段搜索 |
| multi_match | 在多个字段上反复执行相同查询 |
match
{"query": {"match": {"title":{"query":"BROWN DOG!","operator":and //所有词项都要匹配时"minimum_should_match":"50%"}}}
}上面是match搜索的一个用例。搜索内容可以是一个词项,也可以是多个词项。若是多个词项场景,这些词语会被解析成单个词,然后在倒序索引中进行精确(term)查找。默认是这些词之间的关系是or,即满足文档中包含其中一个词就会被找到。
match有两个参数来控制搜索操作和返回结果。
-
operator:需要搜索的关键词必须全部出现 -
minimum_should_match:最小匹配参数
有时候需要搜索的关键词必须全部出现,可以使用参数 operator ,设置为 and 。
若文档数量超多,可以对相关性设定阈值,而我们只希望返回相关性高的文档, 可以使用 minimum_should_match 最小匹配参数。该参数的值设置有两种方式,指定必须匹配的词项数用来表示一个文档是否相关。具体数值可以参考:
1. 设置为某个具体数字来制定匹配的词项数量
2. 将其设置为一个百分数:百分数可以设置为正值(75%)也可以设置为负值(-25%)。计算必须文档中要匹配的词项数量
| 75% | -25% | |
| 4个搜索关键词 | 4*75%=3 | 4-4*25%=3 |
| 4个搜索关键词 | 5*75%=3(向下取整) | 5-5*25%=4(向下取整) |
multi_match
multi_match 则是match在多字段查到的一个简便方式。可以在能在多个字段上反复执行相同查询。
{"query":{"multi_match": {"query": "BROWN DOG","fields":["title","body"]}}短语近似匹配
简单查询中match 或者multi_match查询可以获得包含查询词条的文档。但搜索查询时没有考虑词语之间的关系(如:位置关系,词性关系),甚至都不能确定匹配到的内容是否来自同一个字段。
1. Java是一门很好的语言,很多工程师都喜欢使用.
2. Java工程师都很优秀.
用 match 搜索 Java 工程师 上面的两个文档都会得到匹配,但很明显,其实文档2是我们需要的可能性更大。
当使用分析器将文档内容和搜索关键词进行分词之后,理解分词之间的关系是一个复杂的难题。我们也无法通过更换查询方式或者底层存储结构来解决分词问题。但我们至少可以通过出现在彼此附近或者相邻的分词来判断分词之间的相关性。
这就是短语匹配或者近似匹配的所属领域。对于短语匹配,match_phrase也是经常用的搜索方式之一。例如下面的例子:
{"query": {"match_phrase": {"title": {"query":"quick brown fox","slop":2}}}
}对于与match和multi_match查询不同的是,除了将查询关键字解析成一个词项,然后在倒排索引中进行搜索查询外,match_phrase还会比较快搜索词项之间的位置,最终结果只会保留 位置 与搜索词项相同的文档。
精确短语匹配 或许是过于严格了。也许我们想要包含 “Java 高级 工程师” 的文档也能够匹配 “Java 工程师,” ,可以通过使用 slop 参数将灵活度引入短语匹配中。
slop 参数告诉 match_phrase 查询词条相隔多远时仍然能将文档视为匹配 。 相隔多远的意思是为了让查询和文档匹配你需要移动词条多少次。
词项搜索
词项搜索与全文搜索不同,查询不会对输入进行分词处理,而是将输入作为一个整体进行搜索。词项搜索方式本文整理了精确查找--term和部分匹配搜索。
精确查找和范围查找
我们首先来看最为常用的 term 查询和range查询。正如上面所说,词项搜索不会对输入进行分词处理,而是将输入作为一个整体,在倒排索引中查找准确的词项。term和range一般适用于用来处理数字(numbers)、布尔值(Booleans)、日期(dates)等。
| term | 查询某个字段等于搜索词的文档 | "term":{ "address":"香港"} 查询地址等于'香港'的文档 |
| terms | 查询某个字段里包含多个关键词的文档 | terms":{ "address":["香港","北京"]} 查询地址等于"香港"或"北京"的 |
| range | 实现范围查询 | "range": { "age": { "from": 18, "to": 28, "include_lower": true, "include_upper": true } } |
部分匹配
可以发现,以上提出的搜索查询方式都是针对倒排索引整个词的操作。即根据词项在倒排索引中进行匹配查找。也就是说只能查找倒排索引中存在的词,最小的单元为单个词。
但如果想匹配倒排索引中存在词项一部分, 如搜索Java的时候,也希望把JavaScript查出来。这个时候怎么办呢?这个便是接下来要解释的内容--部分匹配。
部分匹配 允许用户指定查找词的一部分并找出所有包含这部分片段的结果。默认状态下, 部分匹配默认不做相关度评分计算,它只是将所有匹配的文档返回。部分匹配有三种方式,这三种方式也不会对搜索词进行分词:
-
前缀查询
-
通配符查询
-
正则表达式查询
|
| 不会在搜索之前分析查询字符串,它假定传入前缀就正是要查找的前缀。 | "prefix": {"postcode": "W1"} |
|
| 使用标准的 shell 通配符查询: | "wildcard": { "postcode": "W?F*HW" , "postcode": "W[0-9].+" } |
|
| 正则式 | { "regexp": { "title": "br.*" }} |
复合搜索
复合搜索是Elasticsearch中最强大的搜索方式之一,它允许用户组合多种查询条件,实现复杂的搜索需求。在Elasticsearch中,复合搜索主要通过bool查询实现。bool查询可以利用逻辑关系(如and、or、not)组合多个其他的查询,从而构建出复杂的查询条件。
除了bool查询,Elasticsearch还提供了其他一些复合查询方式,如filter查询、join查询等。这些查询方式可以进一步扩展复合搜索的能力,满足更复杂的搜索需求。
bool 过滤器一般由以下三部分组成:
{"bool" : {"must" : [],"should" : [],"must_not" : []}
}|
| 必须 匹配这些条件才能被包含进来。 |
|
| 必须不 匹配这些条件才能被包含进来。 |
|
| 如果满足这些语句中的任意语句,将增加 |
过滤
过滤和搜索不同,过滤不需要谈论相关性或得分。过滤得到的结果: 非是即否。它简单的对文档包括或排除处理。fliter可以单独使用,也可以结合bool复合搜索来实现功能更强大的操作。
Elasticsearch 会在运行过滤查询时执行多个操作,如执行下面语句时,Elasticsearch行为包含4步:
{ "filter":{"term":{"age": [3,63]},"term":{"price": 30}}
}-
查找匹配文档.
term 查询在倒排索引中查找,获取包含该 term 的所有文档。
2. 创建 bitset.
过滤器会创建一个 bitset (一个包含 0 和 1 的数组),它描述了哪个文档会包含该 term 。匹配文档的标志位是 1 。如有四个文档,执行完"term":{"age": [3,63]}语句之后,会得到一个bitset 的值: [1,0,0,0] 。
3. 迭代 bitset(s)
一旦为每个查询生成了 bitsets ,Elasticsearch 就会循环迭代 bitsets 从而找到满足所有过滤条件的匹配文档的集合。一般来说先迭代稀疏的 bitset (因为它可以排除掉大量的文档)。
4. 增量使用计数.
Elasticsearch 能够缓存过滤查询从而获取更快的访问,而且过滤查询也不会计算相关行。因此,filter速度要快于query。
总结
本文先介绍了相关性的知识,然后从全文搜 索,词项搜索,复合搜索三方面来介绍了ES搜索的常见场景和操作。最后介绍了与搜索对应的过滤操作。
本文的内容意在梳理ES搜索操作,并未细究背后的原理,如相关性算法等。后续如果有需要会补充。当然,在实际应用中,要综合考虑具体场景来选择相应的搜索方式。
参考文档
https://www.cnblogs.com/qdhxhz/p/11493677.html
Elasticsearch 7.x文档检索的三大策略:全文搜索、词项搜索与复合搜索-百度开发者中心
相关文章:
Elasticsearch 第四期:搜索和过滤
序 2024年4月,小组计算建设标签平台,使用ES等工具建了一个demo,由于领导变动关系,项目基本夭折。其实这两年也陆陆续续接触和使用过ES,两年前也看过ES的官网,当时刚毕业半年多,由于历史局限性导…...

力扣1124.表现良好的最长时间段
力扣1124.表现良好的最长时间段 哈希表存最小的下标 当s[i] > 0 那么他到头可以构成一个合法时间段否则 找到之前的 s[i] - 1 的下标: 因为连续的前缀和一定只相差1若想算更小的s[i] - 2,s[i] - 3…一定会先算到s[i] - 1那么这些更小数必然在 s[i]−1 首次出现的…...

算法训练营day67
题目1: #include <iostream> #include <vector> #include <string> #include <unordered_set> #include <unordered_map> #include <queue>using namespace std;int main() {string beginStr, endStr;int n;cin >> n;ci…...

人工智能--图像语义分割
个人主页:欢迎来到 Papicatch的博客 课设专栏 :学生成绩管理系统 专业知识专栏:专业知识 文章目录 🍉引言 🍉介绍 🍈工作原理 🍍数据准备 🍍特征提取 🍍像素分…...

fl studio20和21用哪一个好?FL-Chan from FL Studio欣赏
最近接到很多小伙伴的私信,都在问我平时会使用哪些音乐软件,能不能给一些参考。其实每个人的使用习惯不一样,需求也不一样。以DAW为例,有些人就是喜欢FL Studio,有些人吹爆Studio One,还有些人习惯使用Cuba…...

OpenCV直方图计算函数calcHist的使用
操作系统:ubuntu22.04OpenCV版本:OpenCV4.9IDE:Visual Studio Code编程语言:C11 功能描述 图像的直方图是一种统计表示方法,用于展示图像中不同像素强度(通常是灰度值或色彩强度)出现的频率分布。具体来说…...
09 docker 安装tomcat 详解
目录 一、安装tomcat 1. tomcat镜像的获取 2. docker创建容器实列 3. 访问测试 404错误 4. 解决方案 5. 使用免修改版容器镜像 5.1. 运行实列的创建 5.2. 出现问题及解决: 6. 验证 OK 一、安装tomcat 1. tomcat镜像的获取 docker search tomcat #docker …...

44.实现管理HOOK点的链表对象
上一个内容:43.实现HOOK接管寄存器数据 以 43.实现HOOK接管寄存器数据 它的代码为基础进行修改 首先创建一个类 这里创建的名为HOOKPOINT.h HOOKPOINT.cpp文件里面的内容 #include "pch.h" #include "HOOKPOINT.h"HOOKPOINT::HOOKPOINT() {…...

Unity小知识
1.当我们把摄像机的内容渲染到RenderTexture上而不是屏幕上时,那么相机的Aspect默认会设置成和RenderTexture的分辨率一样.不过最终如果把RenderTexture作为贴图贴到模型上去的时候还是会被UV拉伸和缩小的。 2.要想自定义UnityPackage的内容,只要找到UnityProject/L…...

【Jupyter Notebook与Git完美融合】在Notebook中驾驭版本控制的艺术
标题:【Jupyter Notebook与Git完美融合】在Notebook中驾驭版本控制的艺术 Jupyter Notebook是一个流行的开源Web应用程序,允许用户创建和共享包含实时代码、方程、可视化和解释性文本的文档。而Git是一个广泛使用的分布式版本控制系统,用于跟…...
Python开发者必看:内存优化的实战技巧
更多Python学习内容:ipengtao.com Python是一种高级编程语言,以其易读性和强大的功能而广受欢迎。然而,由于其动态类型和自动内存管理,Python在处理大量数据或高性能计算时,内存使用效率可能不如一些低级语言。本文将介…...

Golang | Leetcode Golang题解之第214题最短回文串
题目: 题解: func shortestPalindrome(s string) string {n : len(s)fail : make([]int, n)for i : 0; i < n; i {fail[i] -1}for i : 1; i < n; i {j : fail[i - 1]for j ! -1 && s[j 1] ! s[i] {j fail[j]}if s[j 1] s[i] {fail[i…...

【ajax实战08】分页功能
本文章目标:点击上/下一页按钮,实现对应页面的变化 实现基本步骤: 一:保存并设置文章总条数 设置一个全局变量,将服务器返回的数据返回给全局变量 二:点击下一页,做临界值判断,并…...

基于Hadoop平台的电信客服数据的处理与分析②项目分析与设计---需求分析-项目场景引入
任务描述 需求分析是软件生命周期中一个非常重要的过程,它决定着整个软件项目的质量,也是整个软件开发的成败所在。本环节任务是完成软件需求规格说明书。 知识点 :软件需求规格说明书的编写 重 点 :软件需求规格说明书内容的…...

debug-mmlab
mmyolo bug1: MMYOLO for yolov5 instance segmentation on balloon dataset getting this error "ValueError: Key img_path is not in available keys. solution: pip install albumentations1.3.1 reference...

年轻人为什么那么爱喝奶茶?
作者 | 艾泊宇 为什么年轻人那么爱喝奶茶?答案很简单:对他们来说,奶茶之于年轻人,正如白酒之于中年人。 奶茶不仅仅是一种饮料,它已经演化成一种文化现象,代表着温暖和爱的象征,甚至在某种程度上…...

手写数组去重
方法1-判断相邻元素 function _deleteRepeat(arr){if(!Array.isArray(arr)){throw new Error(参数必须是数组)}let res[];// 使用slice创建arr的副本,并排序let sortArrarr.slice().sort((a,b)>a-b);for(let i0;i<sortArr.length;i){if(isortArr.length-1||s…...

Firewalld 防火墙
1. 概述 在 RHEL7 系统中,firewalld 防火墙取代了传统的 iptables 防火墙。iptables 的防火墙策略是通过内核层面的 netfilter 网络过滤器来处理的,而 firewalld 则是通过内核层面的 nftables 包过滤框架来处理。firewalld 提供了更为丰富的功能和动态更…...

Hive查询优化 - 面试工作不走弯路
引言:Hive作为一种基于Hadoop的数据仓库工具,广泛应用于大数据分析。然而,由于其依赖于MapReduce框架,查询的性能可能会受到影响。为了确保Hive查询能够高效运行,掌握查询优化技巧至关重要。在日常工作中,高…...

【VUE3】uniapp + vite中 uni.scss 使用 /deep/ 不生效(踩坑记录三)
vite 中使用 /deep/ 进行样式穿透报错 原因:vite 中不支持,换成 ::v-deep 或:deep即可...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...