Hive查询优化 - 面试工作不走弯路
引言:Hive作为一种基于Hadoop的数据仓库工具,广泛应用于大数据分析。然而,由于其依赖于MapReduce框架,查询的性能可能会受到影响。为了确保Hive查询能够高效运行,掌握查询优化技巧至关重要。在日常工作中,高效的Hive查询不仅能提高数据处理的速度,还能有效节省计算资源,降低成本。同时,优化Hive查询的能力也是大数据工程师面试中的常见问题之一,能够展示出你的技术深度和实际操作能力。我们将深入探讨Hive查询优化的多种方法,包括数据存储优化、查询写法优化、配置优化以及性能监控与调优。无论是正在准备面试,还是在实际工作中遇到了Hive查询性能瓶颈都能游刃有余。

目录
了解Hive的架构
Hive的工作原理
Hive与Hadoop的关系
查询的执行过程
数据存储优化
分区表的使用
桶表的使用
合理的数据格式
查询优化技巧
合理使用索引
优化JOIN操作
优化GROUP BY和ORDER BY
优化SQL写法
避免使用SELECT *
使用LIMIT限制返回结果
避免笛卡尔积
使用合适的过滤条件
配置优化
内存和资源的合理配置
设置合理的参数
性能监控与调优
使用EXPLAIN分析查询计划
常见性能瓶颈的识别与解决
使用Hive的性能监控工具
了解Hive的架构
在进行Hive查询优化之前,首先需要了解Hive的基本架构和工作原理。Hive将SQL查询翻译为MapReduce任务在Hadoop上运行。我们先来了解Hive的主要组件和它们的作用。
Hive的工作原理
Hive是一个基于Hadoop的数据仓库工具,允许用户使用类似SQL的语言(HiveQL)来查询存储在HDFS(Hadoop Distributed File System)上的数据。Hive的核心组件包括以下几个部分:
- 用户接口:Hive提供多种用户接口,包括CLI(命令行接口)、JDBC/ODBC驱动程序和Web UI等,方便用户提交查询。
- 编译器:编译器将用户的HiveQL查询解析成抽象语法树(AST),然后进一步转换成逻辑计划。
- 优化器:优化器对逻辑计划进行优化,包括查询重写、选择合适的Join策略、推测过滤条件等,以提高查询效率。
- 执行引擎:优化后的查询计划会被转换成一个或多个MapReduce任务,由Hadoop的执行引擎来调度和执行。
- 元数据存储:Hive使用一个元数据存储(如MySQL、PostgreSQL等)来存储表结构、分区信息、列类型等元数据。
Hive与Hadoop的关系
Hive依赖于Hadoop的分布式计算和存储能力,通过将SQL查询转换为MapReduce任务在Hadoop集群上运行,实现了大规模数据的处理能力。以下是Hive与Hadoop交互的主要步骤:
- 提交查询:用户通过CLI或其他接口提交HiveQL查询。
- 解析与编译:编译器将查询解析成AST,并转换为逻辑计划。
- 优化:优化器对逻辑计划进行优化,选择最佳执行策略。
- 生成MapReduce任务:优化后的查询计划被转换成一个或多个MapReduce任务。
- 执行任务:MapReduce任务在Hadoop集群上执行,处理数据并生成结果。
- 返回结果:查询结果通过用户接口返回给用户。
查询的执行过程
了解Hive查询的执行过程有助于识别潜在的性能瓶颈并进行优化。以下是一个典型的Hive查询执行过程:
- 解析:编译器将HiveQL查询解析为AST。
- 逻辑计划生成:编译器将AST转换为逻辑计划,包括操作符树。
- 优化:优化器对逻辑计划进行优化,选择合适的Join策略、推测过滤条件等。
- 物理计划生成:优化后的逻辑计划被转换为物理计划,即MapReduce任务。
- 任务执行:物理计划在Hadoop集群上执行,处理数据并生成中间结果。
- 结果合并:MapReduce任务的输出被合并,生成最终查询结果。
- 返回结果:查询结果通过用户接口返回给用户。
数据存储优化
数据存储的优化是提高Hive查询性能的重要手段。通过合理的表设计和数据格式,可以显著减少查询的执行时间和资源消耗。以下是一些常用的优化方法。
分区表的使用
分区表是将表按照某个列或多个列的值进行分区存储,这样在查询时可以只扫描相关分区的数据,从而大大减少扫描的数据量,提高查询效率。
-- 创建按年份和月份分区的销售表
CREATE TABLE sales (product_id INT,amount DOUBLE,date STRING
)
PARTITIONED BY (year INT, month INT)
STORED AS ORC;-- 加载数据到分区表
LOAD DATA INPATH '/path/to/data' INTO TABLE sales PARTITION (year=2023, month=6);-- 查询特定分区的数据
SELECT product_id, amount
FROM sales
WHERE year=2023 AND month=6;
桶表的使用
桶表通过将数据划分为多个桶,可以在JOIN操作和聚合操作中显著提高性能。每个桶的数据存储在一个单独的文件中。
-- 创建按用户ID划分为16个桶的用户信息表
CREATE TABLE user_info (user_id INT,name STRING,age INT
)
CLUSTERED BY (user_id) INTO 16 BUCKETS
STORED AS ORC;-- 加载数据到桶表
INSERT INTO TABLE user_info SELECT * FROM user_info_source;-- 查询桶表
SELECT user_id, name, age
FROM user_info
WHERE age > 30;
合理的数据格式
选择合适的数据格式和压缩方式可以显著提高查询性能。列式存储格式如ORC和Parquet在处理大数据时具有更高的压缩比和查询效率。
-- 创建使用ORC格式存储的交易表
CREATE TABLE transactions (trans_id INT,trans_date STRING,amount DOUBLE
)
STORED AS ORC;-- 加载数据到ORC格式表
LOAD DATA INPATH '/path/to/transactions' INTO TABLE transactions;-- 创建压缩存储的销售表
CREATE TABLE compressed_sales (product_id INT,amount DOUBLE,date STRING
)
STORED AS ORC TBLPROPERTIES ("orc.compress"="ZLIB");-- 加载数据到压缩表
LOAD DATA INPATH '/path/to/data' INTO TABLE compressed_sales;
查询优化技巧
除了数据存储的优化外,查询优化技巧也能显著提高Hive查询的性能。通过合理的索引使用、优化JOIN操作、优化GROUP BY和ORDER BY等方法,可以减少查询的执行时间和资源消耗。
合理使用索引
索引可以加速查询,但也会增加写操作的开销。因此,根据查询频率和数据更新情况,合理创建和使用索引非常重要。
-- 在销售表的金额列上创建索引
CREATE INDEX idx_amount ON TABLE sales (amount) AS 'COMPACT' WITH DEFERRED REBUILD;-- 重建索引
ALTER INDEX idx_amount ON sales REBUILD;-- 查询使用索引
SELECT product_id, amount
FROM sales
WHERE amount > 1000;
优化JOIN操作
JOIN操作是Hive查询中常见的性能瓶颈。选择合适的JOIN策略(Map-side Join或Reduce-side Join)和合理设置分布键,可以显著提高JOIN操作的性能。
-- Map-side Join
SELECT /*+ MAPJOIN(b) */a.id, a.name, b.salary
FROMemployees a
JOINemployee_salaries b
ON a.id = b.id;-- Reduce-side Join
SELECTa.id, a.name, b.salary
FROMemployees a
JOINemployee_salaries b
ON a.id = b.id
DISTRIBUTE BY a.id
SORT BY a.id;
优化GROUP BY和ORDER BY
通过在Map阶段进行部分聚合和排序,可以减少Reduce阶段的负担,从而提升查询效率。
-- Map-side aggregation
SET hive.map.aggr=true;
SET hive.groupby.mapaggr.checkinterval=100000;-- 分布式排序
SET hive.optimize.sort.dynamic.partition=true;
优化SQL写法
优化SQL查询的写法是提高Hive查询性能的关键步骤之一。通过避免不必要的操作和使用高效的查询语句,可以显著减少查询的执行时间和资源消耗。
避免使用SELECT *
使用SELECT * 会检索表中的所有列,这可能会导致大量不必要的数据传输和处理,尤其是在表包含许多列时。最好只选择需要的列。
-- 不推荐的用法
SELECT * FROM sales WHERE year=2023 AND month=6;-- 推荐的用法
SELECT product_id, amount FROM sales WHERE year=2023 AND month=6;
使用LIMIT限制返回结果
在进行数据探索或调试时,可以使用LIMIT子句限制返回的结果数量,以减少查询的执行时间和资源消耗。
-- 限制返回结果的数量
SELECT product_id, amount FROM sales WHERE year=2023 AND month=6 LIMIT 100;
避免笛卡尔积
笛卡尔积会生成所有可能的行组合,导致巨大的数据集。确保JOIN操作有合理的连接条件,以避免生成笛卡尔积。
-- 不推荐的用法:没有连接条件,可能生成笛卡尔积
SELECT a.id, a.name, b.salary
FROM employees a, employee_salaries b;-- 推荐的用法:有连接条件
SELECT a.id, a.name, b.salary
FROM employees a
JOIN employee_salaries b
ON a.id = b.id;
使用合适的过滤条件
在查询中尽可能使用WHERE子句进行过滤,以减少扫描的数据量和处理时间。
-- 不推荐的用法:没有过滤条件
SELECT * FROM sales;-- 推荐的用法:使用过滤条件
SELECT * FROM sales WHERE year=2023 AND amount > 1000;
配置优化
除了优化SQL查询和数据存储,Hive的配置优化也是提升查询性能的重要手段。通过合理配置内存、资源和参数,可以更好地利用集群资源,提高查询效率。
内存和资源的合理配置
根据数据量和查询复杂度,调整Map和Reduce任务的内存设置,可以有效避免内存不足导致的任务失败或性能下降。同时,合理设置并行度可以提高任务的执行效率。
-- 设置Map任务的内存大小
SET mapreduce.map.memory.mb=2048;-- 设置Reduce任务的内存大小
SET mapreduce.reduce.memory.mb=4096;-- 启用并行执行
SET hive.exec.parallel=true;-- 设置并行执行的线程数
SET hive.exec.parallel.thread.number=8;
设置合理的参数
通过设置Hive的执行参数,可以优化查询执行的各个环节,提高整体性能。
-- 设置每个Reduce任务处理的数据量
SET hive.exec.reducers.bytes.per.reducer=67108864; -- 64MB per reducer-- 启用动态分区
SET hive.exec.dynamic.partition=true;-- 设置动态分区模式
SET hive.exec.dynamic.partition.mode=nonstrict;-- 启用Map侧聚合
SET hive.map.aggr=true;-- 设置Map侧聚合检查间隔
SET hive.groupby.mapaggr.checkinterval=100000;-- 启用动态分区排序优化
SET hive.optimize.sort.dynamic.partition=true;
性能监控与调优
持续的性能监控与调优是确保Hive查询高效运行的重要步骤。通过使用性能监控工具和分析查询执行计划,可以识别和解决性能瓶颈,提高查询效率。
使用EXPLAIN分析查询计划
EXPLAIN命令可以显示Hive查询的执行计划,包括各个阶段的操作步骤和资源使用情况。通过分析查询计划,可以识别潜在的性能问题并进行优化。
-- 分析查询执行计划
EXPLAIN SELECT product_id, amount FROM sales WHERE year=2023 AND month=6;
执行EXPLAIN命令后,Hive会显示查询的详细执行计划,包括MapReduce任务的数量、数据扫描量、排序和聚合操作等信息。通过分析这些信息,可以识别查询的性能瓶颈,并采取相应的优化措施。
常见性能瓶颈的识别与解决
通过性能监控和查询计划分析,可以识别以下常见的性能瓶颈,并采取相应的解决措施:
- 数据倾斜:如果某些分区或桶中的数据量显著多于其他分区或桶,会导致计算资源不均衡,影响查询性能。解决方法包括重新划分数据、调整分区或桶的数量等。
- 内存不足:如果Map或Reduce任务的内存设置不足,会导致任务失败或性能下降。解决方法是增加内存配置,如提高
mapreduce.map.memory.mb和mapreduce.reduce.memory.mb的值。 - 过多的MapReduce任务:如果查询生成了过多的MapReduce任务,会增加任务调度和执行的开销。解决方法包括优化查询写法、减少不必要的操作、合并小文件等。
使用Hive的性能监控工具
Hive集成了多种性能监控工具,可以帮助用户实时监控查询的执行情况,识别和解决性能问题。常见的性能监控工具包括:
- Hadoop资源管理器(ResourceManager):可以监控MapReduce任务的执行情况,包括任务的运行时间、内存使用情况、数据传输量等。
- Ganglia:分布式监控系统,可以实时监控集群的资源使用情况,包括CPU、内存、网络等。
- Nagios:网络监控系统,可以监控Hive和Hadoop集群的运行状态,并在发现问题时发送告警。
相关文章:
Hive查询优化 - 面试工作不走弯路
引言:Hive作为一种基于Hadoop的数据仓库工具,广泛应用于大数据分析。然而,由于其依赖于MapReduce框架,查询的性能可能会受到影响。为了确保Hive查询能够高效运行,掌握查询优化技巧至关重要。在日常工作中,高…...

【VUE3】uniapp + vite中 uni.scss 使用 /deep/ 不生效(踩坑记录三)
vite 中使用 /deep/ 进行样式穿透报错 原因:vite 中不支持,换成 ::v-deep 或:deep即可...
容器部署rabbitmq集群迁移
1、场景: 因业务需要,要求把rabbitmq-A集群上的数据迁移到rabbitmq-B集群上,rabbitmq的数据包括元数据(RabbitMQ用户、vhost、队列、交换和绑定)和消息数据,而消息数据存储在单独的消息存储库中。 2、迁移要…...

DP:背包问题----0/1背包问题
文章目录 💗背包问题💛背包问题的变体🧡0/1 背包问题的数学定义💚解决背包问题的方法💙例子 💗解决背包问题的一般步骤?💗例题💗总结 ❤️❤️❤️❤️❤️博客主页&…...

React antd umi 监听当前页面离开,在菜单栏提示操作
需求是我这里有个页面,离开当前页面之后,需要在菜单栏显示个提示,也就是Tour const [unblock, setUnblock] useState<() > void>(() > () > {});const [next, setNext] useState();useEffect(() > {const unblockHandler…...

在 Windows PowerShell 中模拟 Unix/Linux 的 touch 命令
在 Unix 或 Linux 系统中,touch 命令被广泛用于创建新文件或更新现有文件的时间戳。不过,在 Windows 系统中,尤其是在 PowerShell 环境下,并没有内置的 touch 命令。这篇博客将指导你如何在 Windows PowerShell 中模拟 touch 命令…...

鸿蒙NEXT
[中国,东莞,2024年6月24日] 华为开发者大会(HDC)正式开幕,带来全新的 HarmonyOS NEXT、盘古大模型5.0等最创新成果,持续为消费者和开发者带来创新体验。 HarmonyOS NEXT 鸿蒙生态 星河璀璨 鸿蒙生态设备数…...

VUE3-Elementplus-form表单-笔记
1. 结构相关 el-row表示一行,一行分成24份 el-col表示列 (1) :span"12" 代表在一行中,占12份 (50%) (2) :span"6" 表示在一行中,占6份 (25%) (3) :offset"3" 代表在一行中,左侧margin份数 el…...
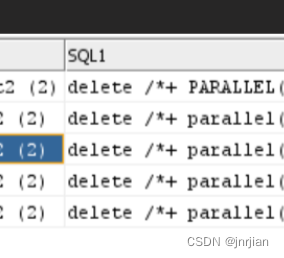
Analyze an ORA-12801分析并行 parallel 12801 实际原因
"ORA-06512: at "PKG_P_DATA", line 19639 ORA-06512: at "PKG_P_DATA", line 19595 ORA-06512: at "PKG_P_DATA", line 14471-JOB 调用 -ORA-12801: error signaled in parallel query server P009, instance rac2:dwh2 (2) Error: ORA-12…...
高级运维工程师讲述银河麒麟V10SP1服务器加固收回权限/tmp命令引起生产mysql数据库事故实战
高级运维工程师讲述银河麒麟V10SP1服务器加固收回权限/tmp命令引起生产MySql数据库事故实战 一、前言 作为运维工程师经常会对生产服务器进行安全漏洞加固,一般服务厂商、或者甲方信息安全中心提供一些安全的shell脚本,一般这种shell脚本都是收回权限&…...

昇思25天学习打卡营第09天|sea_fish
打开第九天,本次学习的内容为保存与加载,记录学习的过程。本次的内容少而且简单。 在训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型推理与部署,因…...
flutter开发实战-Charles抓包设置,dio网络代理
flutter开发实战-Charles抓包设置 在开发过程中抓包,可以看到请求参数等数据,方便分析问题。flutter上使用Charles抓包设置。dio需要设置网络代理。 一、dio设置网络代理 在调试模式下需要抓包调试,所以需要使用代理,并且仅用H…...
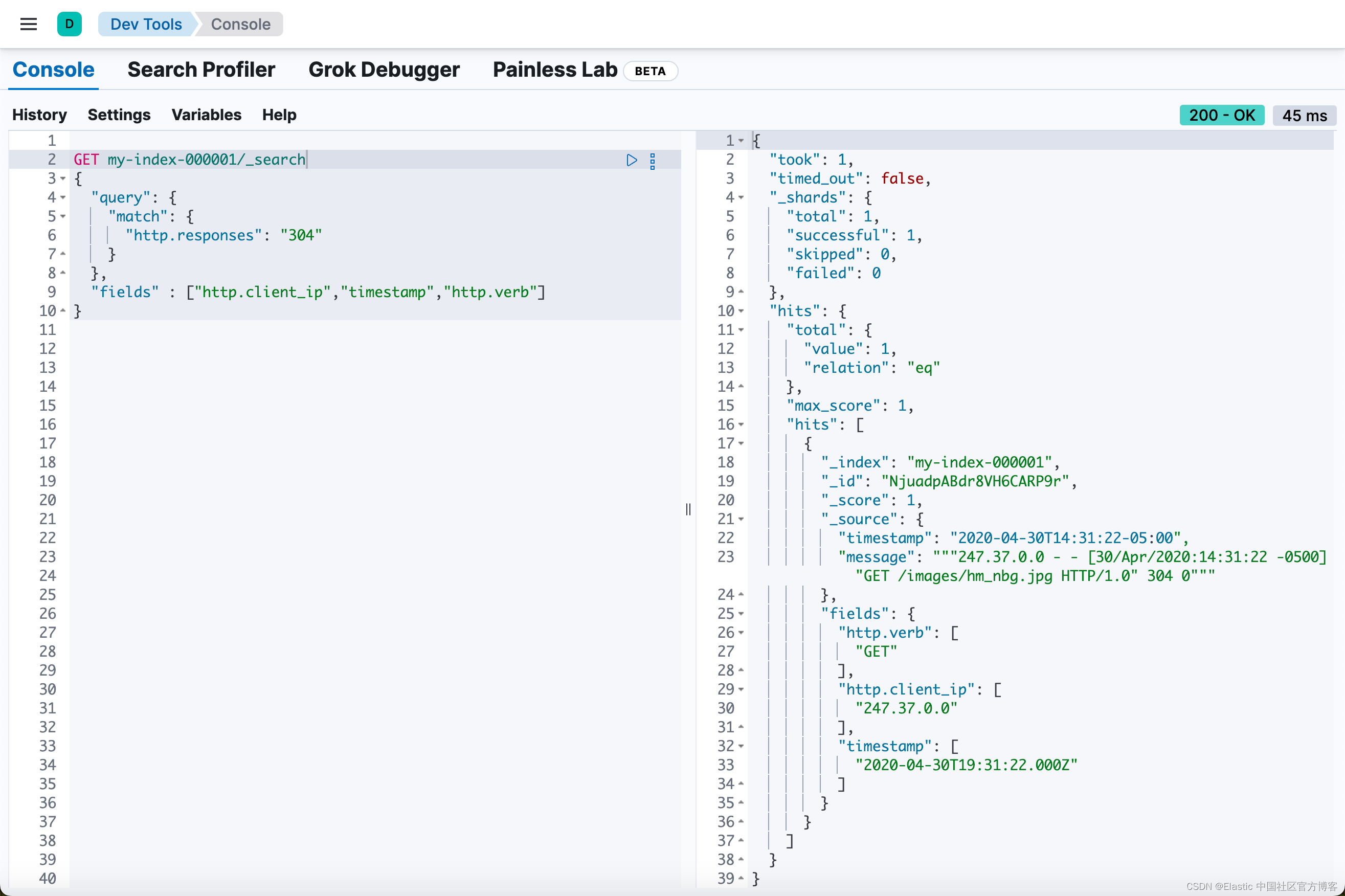
Elasticsearch:Runtime fields - 运行时字段(二)
这是继上一篇文章 “Elasticsearch:Runtime fields - 运行时字段(一)” 的续篇。 在查询时覆盖字段值 如果你创建的运行时字段与映射中已存在的字段同名,则运行时字段会隐藏映射字段。在查询时,Elasticsearch 会评估运…...
)
Python正则表达式的入门用法(上)
Python正则表达式是使用re模块来进行操作的。re模块提供了一组函数,用于进行字符串的匹配和查找操作。 下面是Python中使用正则表达式的一些常用函数: re.search(pattern, string):在字符串中查找并返回第一个匹配的对象。 re.match(patte…...
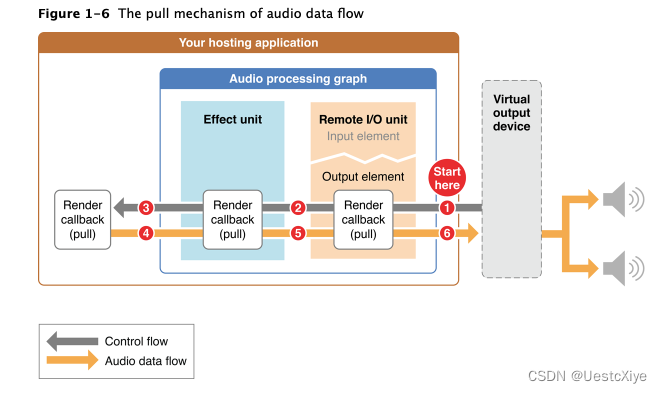
Audio Processing Graphs 管理 Audio Units
Audio Processing Graphs 管理 Audio Units Audio Processing Graphs 管理 Audio UnitsAudio Processing Graph 拥有精确的 I/O UnitAudio Processing Graph 提供线程安全通过 graph "pull" 音频流 Audio Processing Graphs 管理 Audio Units audio processing grap…...

欧盟,又出了新规-通用充电器新规通用充電器的 RED 修正案如何办理?
欧盟,又出了新规-通用充电器新规通用充電器的 RED 修正案如何办理? 欧盟新规委员会发布《通用充电器指令》指南通用充電器的 RED 修正案办理流程: 2024年5月7日,欧盟委员会发布《通用充电器指令》指南,修订了《无线…...
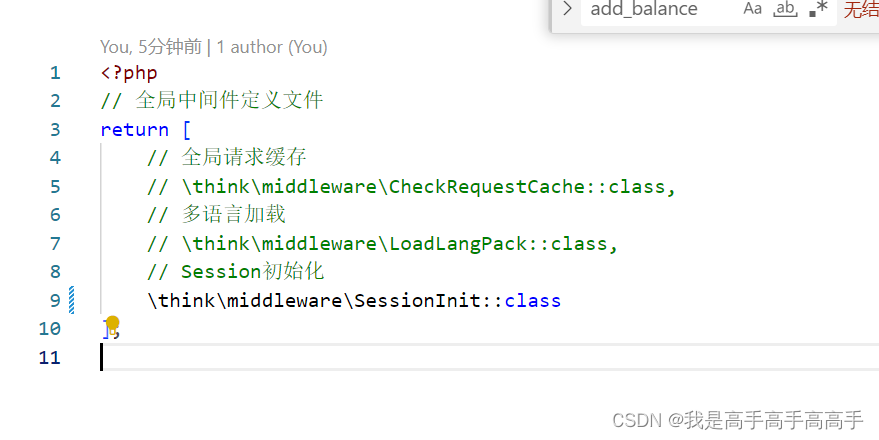
thinkphp6/8 验证码
html和后台验证代码按官方来操作 ThinkPHP官方手册 注意: 如果验证一直失败,看看Session是否开启, 打印dump(session_status());结果2为正确的, PHP_SESSION_DISABLED: Session功能被禁用(返回值为0)。…...
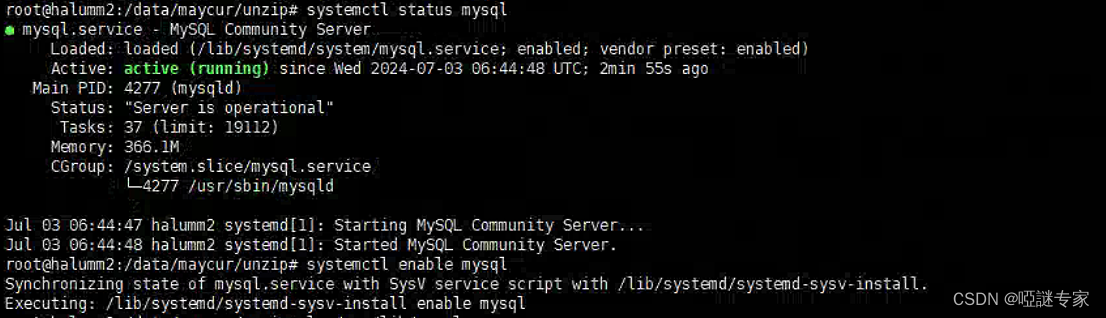
Ubuntu 22.04 LTS 上安装 MySQL8.0.23(在线安装)
目录 在线安装MySQL 步骤1:更新软件包列表 步骤2:安装MySQL服务器 步骤3:启动MySQL服务 步骤4:检查MySQL状态 步骤5:修改密码、权限 在线安装MySQL 步骤1:更新软件包列表 在进行任何软件安装之前&a…...
如何选择优质模型?SD3性能究竟如何?
遇到难题不要怕!厚德提问大佬答! 厚德提问大佬答12 厚德提问大佬答第十二期 你是否对AI绘画感兴趣却无从下手?是否有很多疑问却苦于没有大佬解答带你飞?从此刻开始这些问题都将迎刃而解!你感兴趣的话题,厚德…...
)
Linux上脚本备份数据库(升级版)
直接上代码: #!/bin/bash# 配置部分 mysql_user"root" mysql_host"localhost" mysql_port"3306" mysql_charset"utf8mb4" mysql_defaults_file"/home/mysql/mysql_back/.my.cnf"backup_base_dir"/mnt/sdd/…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...