Redis 7.x 系列【16】持久化机制之 AOF
有道无术,术尚可求,有术无道,止于术。
本系列Redis 版本 7.2.5
源码地址:https://gitee.com/pearl-organization/study-redis-demo
文章目录
- 1. 概述
- 2. 执行原理
- 2.1 Redis 6.x
- 2.1.1 直接写
- 2.1.2 重写
- 2.2 Redis 7.x
- 2.2.1 直接写
- 2.2.2 重写
- 3. 配置项
- 3.1 appendonly
- 3.2 appendfilename
- 3.3 appenddirname
- 3.4 appendfsync
- 3.5 no-appendfsync-on-rewrite
- 3.6 auto-aof-rewrite-percentage、auto-aof-rewrite-min-size
- 3.7 aof-load-truncated
- 3.8 aof-use-rdb-preamble
- 3.9 aof-timestamp-enabled
1. 概述
默认情况下,Redis 使用RDB持久化,但如果进程出现问题或电源中断,可能会导致几分钟的写入数据丢失(具体取决于配置的保存点)。
Append Only File(AOF)是另一种持久化模式,它提供了更好的持久性保证。AOF 以日志的形式来记录每个写操作,Redis重启时通过读取和执行AOF文件中的命令来重建数据集。
优点:
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作
AOF文件,可以处理误操作。
缺点:
- 比起
RDB占用更多的磁盘空间。 - 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
- 存在个别
Bug,造成不能恢复。
2. 执行原理
2.1 Redis 6.x
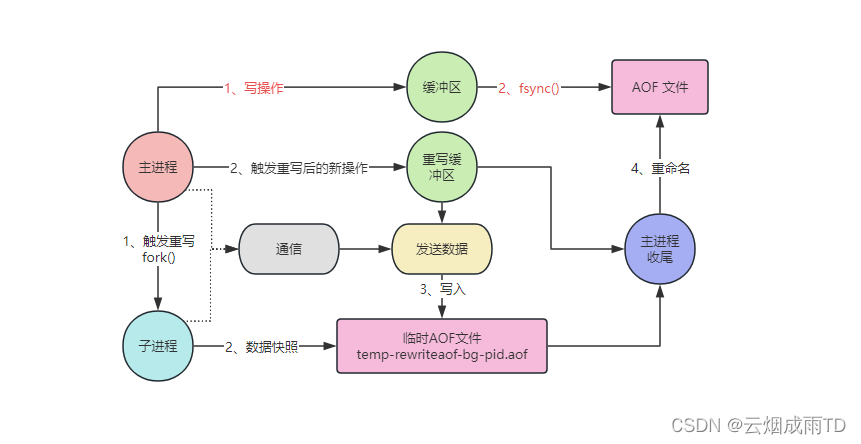
Redis 6 及之前的版本中,生成的 AOF 只有一个( appendonly.aof ),整个执行流程如下:
2.1.1 直接写
Redis 在执行写操作时,并不是将指令直接写入到文件中,而是先写入到缓冲区(aof_buf),然后根据相应的策略同步( fsync )到磁盘中,支持以下三种不同的模式(后面配置有详细介绍):
no:操作系统自行决定always:每次写入都会立即被刷新到磁盘everysec:每秒只进行一次fsync调用
写入的 AOF 文件如下所示:

当 Redis 宕机重启时,可以通过读取和执行 AOF 文件中的命令来重建数据集。但是每一次写指令都会存入到 AOF 文件,可能会导致文件变得非常大,文件太大时,无论是写入还是加载都会变得特别慢。
2.1.2 重写
为了避免 AOF 文件多大问题,控制文件大小并优化性能,Redis 支持运行时触发 AOF 文件重写(rewrite),用以压缩 AOF 文件的大小。
重写机制可以通过 BGREWRITEAOF 命令手动触发,也可以自动触发,配置参数如下:
# 当 AOF 文件大小超过上次重写后 AOF 文件大小的百分比时自动触发,默认值为 100
auto-aof-rewrite-percentage 100
# 当 AOF 文件大小超过指定值时自动触发,默认值为 64 MB
auto-aof-rewrite-min-size 64mb
当触发重写机制后, Redis 主进程会阻塞等待(微秒级)并执行 fork 创建子进程,创建完成后,会继续接收新的请求命令,并将 fork 后的写操作写入到缓冲区并刷盘。此外新操作还会写入到重写缓冲区(aof_rewrite_buf)中,以便重写完成后合并到新文件中,确保和内存数据的一致性。
重写子进程会根据当前时刻 Redis 的数据快照,将每个键值对转换为相应的写入命令,并写入到一个临时文件中 ( temp-rewriteaof-bg-pid.aof)。当上述操作完成后,主进程会将重写缓冲区中的数据发送给子进程,由子进程将数据追加到临时AOF文件中。
子进程重写完成后,会发送消息给主进程,主进程负责将重写缓冲区(可能存在未发送的数据)中剩余数据继续追加到临时AOF文件,并执行原子性的重命名操作,覆盖原先的AOF文件,至此整个重写流程结束。
上述 AOF 重写机制存在一些问题:
- 内存开销:主进程
fork之后的新操作,会同时写入到缓冲区和重写缓冲区,重复内容会带来额外的内存冗余开销。一旦内存开销太大,可能会触发Redis内存限制,影响正常命令的写入,甚至会触发操作系统限制被OOM Killer杀死,导致服务不可用。 CPU开销:可能会造成Redis在执行命令时出现RT上的抖动,甚至造成客户端超时的问题。- 重写期间主进程需要花费
CPU时间向重写缓冲区写数据,并使用eventloop事件循环向子进程发送重写缓冲区中的数据 - 在子进程执行重写操作的后期,会循环读取
pipe中主进程发送来的增量数据,然后追加写入到临时AOF文件 - 在子进程完成重写操作后,主进程会进行收尾工作。其中一个任务就是将在重写期间重写缓冲区中没有消费完成的数据写入临时
AOF文件。如果遗留的数据很多,这里也将消耗CPU时间。
- 重写期间主进程需要花费
- 磁盘
IO开销:重写期间主进程的双写操作,缓冲区中的数据最终会被写入到当前使用的旧AOF文件中,产生磁盘IO。重写缓冲区中的数据也会被写入重写生成的新AOF文件中,产生磁盘IO。因此,同一份数据会产生两次磁盘IO。 - 代码复杂度:
Redis使用六个pipe进行主进程和子进程之间的数据传输和控制交互,这使得整个重写逻辑变得更为复杂和难以理解。
2.2 Redis 7.x
Redis 7 对 AOF 机制进行了优化,发布了新特性Multi Part AOF,将单个 AOF 拆分为多个,该特性由阿里云数据库Tair团队贡献。
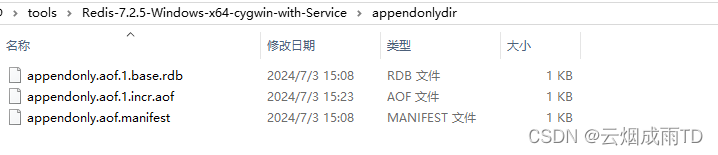
AOF文件分为三种类型:
BASE:基础AOF文件,它一般由子进程通过重写产生,该文件最多只有一个。INCR:增量AOF文件,它一般会在重写开始执行时被创建,该文件可能存在多个。HISTORY:表示历史AOF,它由BASE和INCR AOF变化而来,每次重写成功完成时,本次重写之前对应的BASE和INCR AOF都将变为HISTORY,HISTORY类型的AOF会被Redis自动删除。
为了管理这些AOF文件,引入了一个清单(manifest)文件来跟踪、管理这些AOF。同时,为了便于AOF备份和拷贝,所有的AOF文件和manifest文件放入一个单独的文件目录中,默认为 appendonlydir :
整个执行流程如下:
2.2.1 直接写
Redis 刚启动时,就会创建BASE、INCR文件:
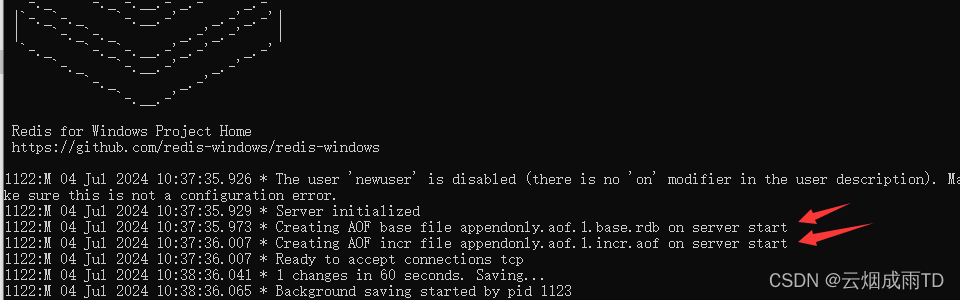
在没有触发重写机制时,执行流程和 Redis 6 一样,只是命令被写入的文件是 appendonly.aof.1.incr.aof 。当 Redis 重启时,会加载BASE、INCR文件中的命令来重建数据集。

2.2.2 重写
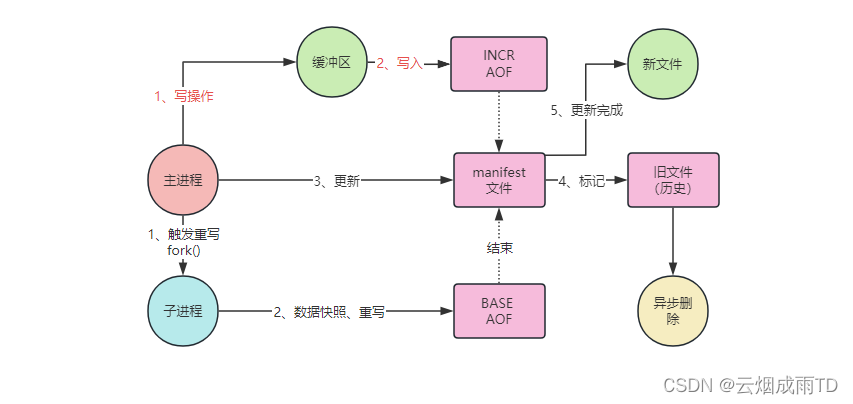
当触发重写机制后, Redis 主进程会阻塞等待(微秒级)并执行 fork 创建子进程,创建完成后,会继续接收新的请求命令,并将 fork 后的写操作写入到新打开的INCR(增量AOF)文件,不再需要写入到重写缓冲区(aof_rewrite_buf)中,降低了内存消耗。
子进程的重写操作完全是独立的,重写期间不会与主进程进行任何的数据和控制交互,最终重写操作会产生一个新打开的BASE AOF文件。
新生成的BASE AOF和新打开的INCR AOF就代表了当前时刻 Redis的全部数据。重写结束时,主进程会负责更新 manifest 文件,将新生成的BASE AOF和INCR AOF信息加入进去,并将之前的BASE AOF和INCR AOF标记为HISTORY(会被Redis异步删除)。一旦manifest文件更新完毕,就标志整个重写流程结束。
Multi Part AOF的引入,成功的解决了之前重写存在的内存和CPU开销,解决了对Redis实例甚至业务访问带来的不利影响。
3. 配置项
redis.conf 中 AOF 相关的配置如下:
############################## APPEND ONLY MODE ################################ By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check https://redis.io/topics/persistence for more information.appendonly no# The base name of the append only file.
#
# Redis 7 and newer use a set of append-only files to persist the dataset
# and changes applied to it. There are two basic types of files in use:
#
# - Base files, which are a snapshot representing the complete state of the
# dataset at the time the file was created. Base files can be either in
# the form of RDB (binary serialized) or AOF (textual commands).
# - Incremental files, which contain additional commands that were applied
# to the dataset following the previous file.
#
# In addition, manifest files are used to track the files and the order in
# which they were created and should be applied.
#
# Append-only file names are created by Redis following a specific pattern.
# The file name's prefix is based on the 'appendfilename' configuration
# parameter, followed by additional information about the sequence and type.
#
# For example, if appendfilename is set to appendonly.aof, the following file
# names could be derived:
#
# - appendonly.aof.1.base.rdb as a base file.
# - appendonly.aof.1.incr.aof, appendonly.aof.2.incr.aof as incremental files.
# - appendonly.aof.manifest as a manifest file.appendfilename "appendonly.aof"# For convenience, Redis stores all persistent append-only files in a dedicated
# directory. The name of the directory is determined by the appenddirname
# configuration parameter.appenddirname "appendonlydir"# The fsync() call tells the Operating System to actually write data on disk
# instead of waiting for more data in the output buffer. Some OS will really flush
# data on disk, some other OS will just try to do it ASAP.
#
# Redis supports three different modes:
#
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
#
# The default is "everysec", as that's usually the right compromise between
# speed and data safety. It's up to you to understand if you can relax this to
# "no" that will let the operating system flush the output buffer when
# it wants, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting),
# or on the contrary, use "always" that's very slow but a bit safer than
# everysec.
#
# More details please check the following article:
# http://antirez.com/post/redis-persistence-demystified.html
#
# If unsure, use "everysec".# appendfsync always
appendfsync everysec
# appendfsync no# When the AOF fsync policy is set to always or everysec, and a background
# saving process (a background save or AOF log background rewriting) is
# performing a lot of I/O against the disk, in some Linux configurations
# Redis may block too long on the fsync() call. Note that there is no fix for
# this currently, as even performing fsync in a different thread will block
# our synchronous write(2) call.
#
# In order to mitigate this problem it's possible to use the following option
# that will prevent fsync() from being called in the main process while a
# BGSAVE or BGREWRITEAOF is in progress.
#
# This means that while another child is saving, the durability of Redis is
# the same as "appendfsync no". In practical terms, this means that it is
# possible to lose up to 30 seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.no-appendfsync-on-rewrite no# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb# An AOF file may be found to be truncated at the end during the Redis
# startup process, when the AOF data gets loaded back into memory.
# This may happen when the system where Redis is running
# crashes, especially when an ext4 filesystem is mounted without the
# data=ordered option (however this can't happen when Redis itself
# crashes or aborts but the operating system still works correctly).
#
# Redis can either exit with an error when this happens, or load as much
# data as possible (the default now) and start if the AOF file is found
# to be truncated at the end. The following option controls this behavior.
#
# If aof-load-truncated is set to yes, a truncated AOF file is loaded and
# the Redis server starts emitting a log to inform the user of the event.
# Otherwise if the option is set to no, the server aborts with an error
# and refuses to start. When the option is set to no, the user requires
# to fix the AOF file using the "redis-check-aof" utility before to restart
# the server.
#
# Note that if the AOF file will be found to be corrupted in the middle
# the server will still exit with an error. This option only applies when
# Redis will try to read more data from the AOF file but not enough bytes
# will be found.
aof-load-truncated yes# Redis can create append-only base files in either RDB or AOF formats. Using
# the RDB format is always faster and more efficient, and disabling it is only
# supported for backward compatibility purposes.
aof-use-rdb-preamble yes# Redis supports recording timestamp annotations in the AOF to support restoring
# the data from a specific point-in-time. However, using this capability changes
# the AOF format in a way that may not be compatible with existing AOF parsers.
aof-timestamp-enabled no
3.1 appendonly
appendonly 用于控制是否启用AOF持久化。
appendonly no
被设置为 no(默认) 时,Redis 不会使用 AOF 持久化机制。
3.2 appendfilename
appendfilename 用于配置 AOF 文件的基础名称。
appendfilename "appendonly.aof"
Redis 7 及更高版本使用一组仅追加文件进行AOF,文件主要有两种类型:
- 基础文件:是数据集在文件创建时完整状态的快照。基础文件可以是
RDB(二进制序列化)格式或AOF(文本命令)格式。 - 增量文件:包含在上一个文件之后对数据集应用的其他命令。
此外,还使用清单文件来跟踪文件的创建顺序,以及它们应该被应用的顺序。
Redis 根据特定的模式创建AOF文件的名称。文件名的前缀基于appendfilename配置参数,后面跟着关于序列和类型的额外信息。
例如,如果 appendfilename被设置为appendonly.aof,那么可能会产生以下文件名:
appendonly.aof.1.base.rdb作为基础文件。appendonly.aof.1.incr.aof,appendonly.aof.2.incr.aof作为增量文件。appendonly.aof.manifest作为清单文件。
3.3 appenddirname
appenddirname 配置AOF文件的存储目录。
appenddirname "appendonlydir"
3.4 appendfsync
appendfsync 用于配置AOF缓冲区将操作同步(sync)到磁盘的AOF文件中的策略。
# appendfsync always
appendfsync everysec
# appendfsync no
fsync() 是一个系统调用,它告诉操作系统将数据实际写入磁盘,而不是等待更多的数据进入输出缓冲区。不同的操作系统对 fsync() 的实现可能有所不同,一些系统会立即将数据写入磁盘,而另一些系统则会尽快尝试这样做。
Redis 支持三种不同的 fsync 模式:
no:不进行fsync调用,让操作系统自行决定何时将数据刷新到磁盘。这种方式速度最快,但可能存在数据丢失的风险。always:每次写入AOF日志后都进行fsync调用。这是最慢但最安全的方式,因为每次写入都会立即被刷新到磁盘。everysec:每秒只进行一次fsync调用。这是速度和数据安全性之间的一个折中方案。
默认值是 everysec,因为它通常是在速度和数据安全性之间最好的折中方案。你可以根据自己的需求调整这个设置。如果你能接受一些数据丢失的风险并且追求更好的性能,可以考虑使用 no 模式(但请注意,如果你能接受数据丢失,那么默认的基于快照的持久化模式可能更合适)。相反,如果你追求更高的数据安全性,即使这意味着性能会降低,可以使用 always 模式。
3.5 no-appendfsync-on-rewrite
no-appendfsync-on-rewrite 用于配置在BGSAVE或BGREWRITEAOF正在进行时,是否阻止主进程调用fsync()。
no-appendfsync-on-rewrite no
当AOF的fsync策略设置为always或everysec时,如果有一个后台保存进程(后台保存或AOF日志后台重写)正在对磁盘进行大量I/O操作,在某些Linux配置下,Redis可能会在fsync()调用上阻塞过长时间。目前这个问题没有修复方法,因为即使在不同的线程中执行fsync也会阻塞我们的同步write调用。
默认为no,不阻止主进程fsync(),还是会把数据往磁盘里刷,但是遇到重写操作,可能会发生阻塞,数据安全,但是性能降低。
当设置为yes时,在BGSAVE或BGREWRITEAOF正在进行时,主进程将不会执行fsync调用。这意味着在这段时间内,Redis的持久性与appendfsync no设置时相同,即数据不会立即同步到磁盘。在最坏的情况下,你可能会丢失最多30秒(使用默认Linux设置)的AOF日志数据。因此,如果你对延迟很敏感,可以将其设置为yes。但是,从持久性的角度来看,将其保持为no(默认值)是最安全的选择。
3.6 auto-aof-rewrite-percentage、auto-aof-rewrite-min-size
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis会fork出一条新进程来将文件重写,也是先写临时文件最后再重命名。
重写过程会创建一个新的 AOF 文件,其中只包含能够恢复当前数据状态所必需的最少命令,从而减小 AOF 文件的大小。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
auto-aof-rewrite-percentage 用于设置一个百分比阈值,当 AOF 文件的大小相对于上一次重写后的大小增长了超过这个百分比时,Redis 就会自动触发 BGREWRITEAOF 命令来重写 AOF 文件。设置为 100(即 100%),那么当 AOF 文件的大小增长了一倍时触发重写。
auto-aof-rewrite-min-size 用于设置一个 AOF 文件重写所需的最小大小(以字节为单位)。只有当 AOF 文件的大小既超过了指定的百分比( auto-aof-rewrite-percentage ),又超过了 auto-aof-rewrite-min-size 指定的最小大小时,Redis 才会触发 AOF 文件的重写。
3.7 aof-load-truncated
aof-load-truncated 用于配置如果 AOF 文件末尾被截断时的相关处理策略。
aof-load-truncated yes
在 Redis 启动过程中,当 AOF 数据被加载回内存时,可能会发现 AOF 文件末尾被截断。例如,在运行 Redis 的操作系统崩溃时,尤其是当 ext4 文件系统被挂载但没有使用 data=ordered 选项。然而,当 Redis 本身崩溃或中止但操作系统仍然正常工作时,这种情况不会发生。
当发生这种情况时,Redis 可以选择报错退出,或者加载尽可能多的数据(现在是默认行为)并启动,如果 AOF 文件末尾被截断。以下选项控制这种行为。
aof-load-truncated yes:会加载一个被截断的AOF文件,并且Redis服务器会开始记录日志以通知用户该事件。aof-load-truncated no:服务器会报错并拒绝启动。当选项设置为no时,用户需要使用 “redis-check-aof” 工具修复AOF文件后再重新启动服务器。
3.8 aof-use-rdb-preamble
aof-use-rdb-preamble 用于配置是否使用 RDB 格式创建AOF的基础文件。使用 RDB 格式总是更快、更高效。
aof-use-rdb-preamble yes
3.9 aof-timestamp-enabled
aof-timestamp-enabled 用于配置 Redis 是否支持在 AOF 中记录时间戳,以支持从特定时间点恢复数据。但是,使用这种功能会以可能与现有 AOF 解析器不兼容的方式更改 AOF 格式。
aof-timestamp-enabled no
相关文章:
Redis 7.x 系列【16】持久化机制之 AOF
有道无术,术尚可求,有术无道,止于术。 本系列Redis 版本 7.2.5 源码地址:https://gitee.com/pearl-organization/study-redis-demo 文章目录 1. 概述2. 执行原理2.1 Redis 6.x2.1.1 直接写2.1.2 重写 2.2 Redis 7.x2.2.1 直接写2…...

使用 PostGIS 生成矢量图块
您喜欢视听学习吗?观看视频指南! 或者直接跳到代码 Overture Maps Foundation是由亚马逊、Meta、微软和 tomtom 发起的联合开发基金会项目,旨在创建可靠、易于使用、可互操作的开放地图数据。 Overture Maps 允许我们以GeoJSON格式下载开放…...

WebSocket 心跳机制如何实现
是一种简单并且有效的策略,用于维持长链接的活跃状态,防止因为网络空闲或者不稳定因素,导致链接意外中断。通过周期性的心跳消息,确保了链接的持久性和周期性,是维持实时通信服务稳定运行的关键组件。 1. 定时发送心跳…...

Docker 容器连接
Docker 容器连接 引言 在当今的软件开发和运维领域,Docker 已经成为了一个不可或缺的工具。它通过容器化的方式,为开发者提供了一种轻量级、可移植的计算环境。然而,要充分发挥 Docker 的潜力,我们需要掌握如何连接这些容器。本文将深入探讨 Docker 容器连接的概念、方法…...

【C语言】continue 关键字
当在C语言中使用continue关键字时,它用于控制循环语句的执行流程。与break不同,continue不会终止整个循环,而是终止当前迭代,并立即开始下一次迭代。这种行为使得可以在循环内部根据特定条件跳过某些代码块,从而控制程…...
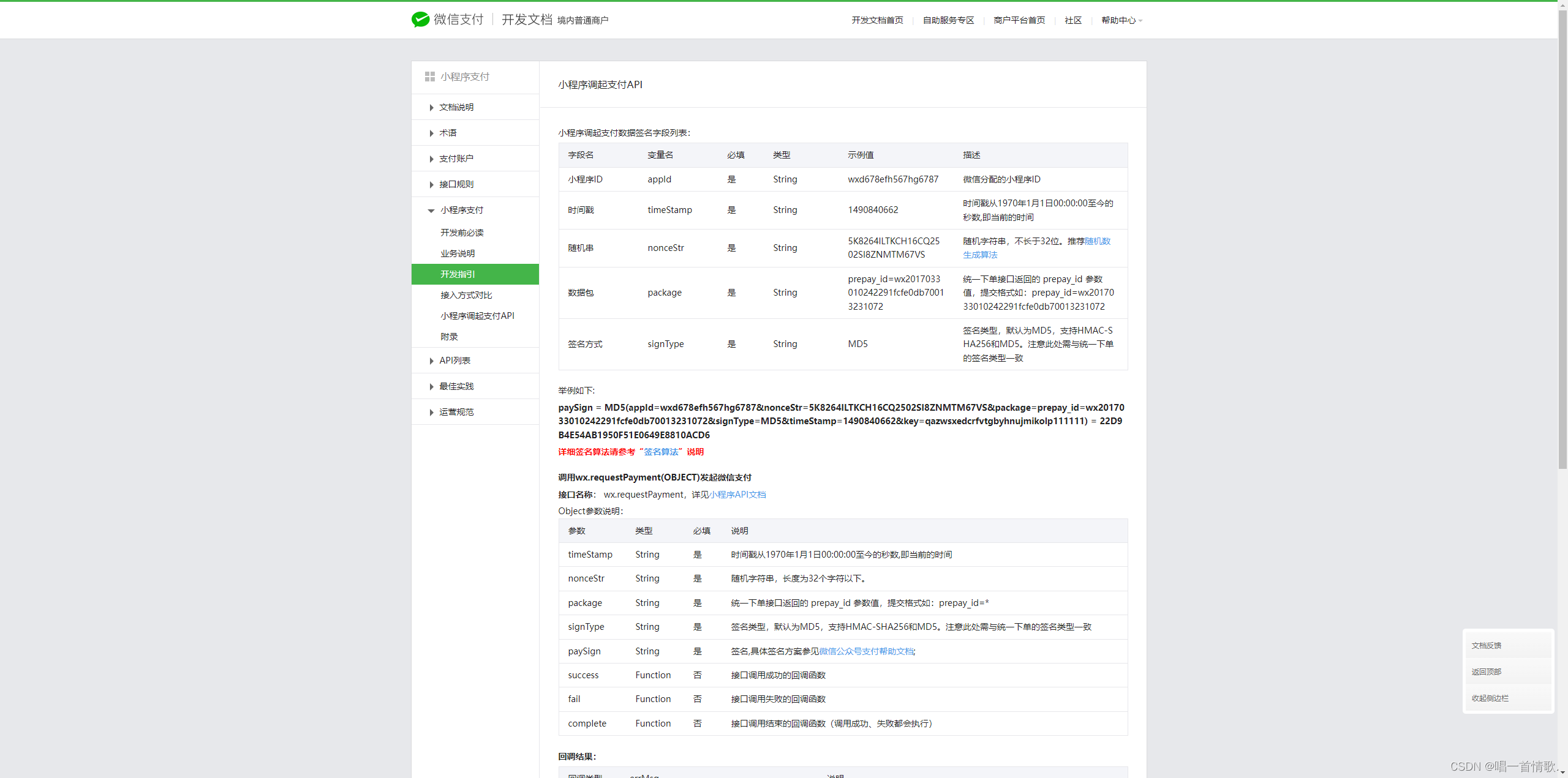
Taro + vue3 中微信小程序中实现拉起支付
在前端开发中 H5 的拉起支付和微信小程序的拉起支付 是不太一样的 现在分享一下微信小程序中的拉起支付 逻辑都在后端 我是用的Taro 框架 其实就是一个Api Taro 文档...

003-GeoGebra如何无缝嵌入到PPT里
GeoGebra无缝嵌入到PPT里真是一个头疼的问题,已成功解决,这里记录一下,希望可以帮助到更多人。 注意,后续所有的文章说的PPT都是Offce Power Point, 不要拿着WPS的bug来问我哦,我已经戒WPS了(此处表示无奈&…...

AI:开发者的朋友还是对手?
AI是在帮助开发者还是取代他们? 在软件开发领域,生成式人工智能(AIGC)正在改变开发者的工作方式。无论是代码生成、错误检测还是自动化测试,AI工具正在成为开发者的得力助手。然而,这也引发了对开发者职业…...

如何在Android Studio中查看APP客户端日志
测试Android应用时,日志查看是一个至关重要的调试工具,它帮助测试人员快速定位问题。幸运的是,Android Studio为我们提供了一个强大的工具——Logcat,使得查看运行时日志变得直接且简单。本文将引导你如何在Android Studio中使用L…...
2024微信小程序期末大作业-点奶茶微信小程序(后端nodejs-server)(附下载链接)_微信小程序期末大作业百度网盘下载
菜单展示 购物车展示: 提交订单: 支付详情页展示: 订单查看: 查看历史消费: 部分代码展示: <!--pages/home/home.wxml--> <block wx:for"{{listData}}" wx:key"itemlist&qu…...
Qt:4.信号和槽
目录 1.信号源、信号和槽: 2.Qt类的继承关系: 3.自定义槽函数: 4.第一种信号和槽的连接的方法: 5.第二种信号和槽的连接的方法: 6.自定义信号: 7.发射信号: 8.信号和槽的传参:…...

Ubuntu20.04更新GLIBC到2.35版本
目录 1 背景2 增加源2.1 标准源2.2 镜像源 3 更新 1 背景 Ubuntu20.04默认GLIBC库版本是2.31.今天碰到一个软件需要2.35版本的GLIBC。 升级GLIBC库有两种方式: 下载高版本库源码,编译后替换系统中低版本库。由于GLIBC库是Linux系统中最基础库ÿ…...
元对象系统 | 7.1、简介)
Qt 实战(7)元对象系统 | 7.1、简介
文章目录 一、简介1、元对象系统的基本条件2、元对象系统的核心功能3、元对象系统的核心类4、总结 Qt的元对象系统(Meta-Object System)是Qt框架中一个极其重要的组成部分,它为Qt提供了信号与槽机制、实时类型信息(RTTI࿰…...

iOS 真机打包,证书报错No signing certificate “iOS Distribution” found
之前将APP从旧账号转移到了新账号,在新账号打包的时候遇到的证书问题。 因为新账号还没有导出“本地签名证书”,也还没有创建新的“发布证书”。当我创建好这两者之后,在xcode打包的时候就报错了。 报错信息: No signing certifi…...

2024年7月3日 (周三) 叶子游戏新闻
老板键工具来唤去: 它可以为常用程序自定义快捷键,实现一键唤起、一键隐藏的 Windows 工具,并且支持窗口动态绑定快捷键(无需设置自动实现)。 卸载工具 HiBitUninstaller: Windows上的软件卸载工具 《魅魔》新DLC《Elysian Fields…...

linux守护进程生命周期管理-supervisord
简介 supervisor是一个client/server系统,允许用户控制多个类unix系统的进程,摆脱rc.d脚本的不方便性.supervisor具有简单,集中化管理,搞笑,可扩展性,高兼容. 整套软件包含:supervisord(守护进程),supervisorctl(命令行工具),web server(一个web交互界面),XML-RPC 交互 安装 …...

rtpengine_mr12.0 基础建设容器运行
目录 Dockerfile rtpengine.conf 容器内编译安装 RTPEngine 正常提供功能 1. 启动RTPEngine服务 2. 删除 RTPEngine服务 3. 加载内核模块 检查所有进程是否正在运行 上传到仓库 博主wx:yuanlai45_csdn 博主qq:2777137742 后期会创建粉丝群&…...

逐步深入:掌握sklearn中的增量学习
🚀 逐步深入:掌握sklearn中的增量学习 在机器学习领域,增量学习(也称为在线学习)是一种重要的学习方式,它允许模型在新数据到来时进行更新,而不需要重新训练整个数据集。这对于处理大量数据或实…...

【机器学习】机器学习与图像识别的融合应用与性能优化新探索
文章目录 引言第一章:机器学习在图像识别中的应用1.1 数据预处理1.1.1 数据清洗1.1.2 数据归一化1.1.3 数据增强 1.2 模型选择1.2.1 卷积神经网络1.2.2 迁移学习1.2.3 混合模型 1.3 模型训练1.3.1 梯度下降1.3.2 随机梯度下降1.3.3 Adam优化器 1.4 模型评估与性能优…...

Unity射击游戏开发教程:(29)躲避敌人的子弹射击
在这篇文章中,我将介绍如何创建一个可以使玩家火力无效的敌人。创建的行为如下...... 当玩家向敌人开火时,敌人会向左或向右移动。向左或向右的移动是随机选择的,并在一段时间后停止敌人的移动。如果敌人移出屏幕,它就会绕到另一边。将一个精灵拖到画布上,将其缩小以匹配游…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...