10 - Python文件编程和异常
文件和异常
在实际开发中,常常需要对程序中的数据进行持久化操作,而实现数据持久化最直接简单的方式就是将数据保存到文件中。说到“文件”这个词,可能需要先科普一下关于文件系统的知识,对于这个概念,维基百科上给出了很好的诠释,这里不再浪费笔墨。
在Python中实现文件的读写操作其实非常简单,通过Python内置的open函数,我们可以指定文件名、操作模式、编码信息等来获得操作文件的对象,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件还是二进制文件)以及做什么样的操作(读、写还是追加),具体的如下表所示。
| 操作模式 | 具体含义 |
|---|---|
'r' | 读取 (默认) |
'w' | 写入(会先截断之前的内容) |
'x' | 写入,如果文件已经存在会产生异常 |
'a' | 追加,将内容写入到已有文件的末尾 |
'b' | 二进制模式 |
't' | 文本模式(默认) |
'+' | 更新(既可以读又可以写) |
下面这张图来自于菜鸟教程网站,它展示了如果根据应用程序的需要来设置操作模式。

读写文本文件
读取文本文件时,需要在使用open函数时指定好带路径的文件名(可以使用相对路径或绝对路径)并将文件模式设置为'r'(如果不指定,默认值也是'r'),然后通过encoding参数指定编码(如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码),如果不能保证保存文件时使用的编码方式与encoding参数指定的编码方式是一致的,那么就可能因无法解码字符而导致读取失败。下面的例子演示了如何读取一个纯文本文件。
def main():f = open('致橡树.txt', 'r', encoding='utf-8')print(f.read())f.close()if __name__ == '__main__':main()
请注意上面的代码,如果open函数指定的文件并不存在或者无法打开,那么将引发异常状况导致程序崩溃。为了让代码有一定的健壮性和容错性,我们可以使用Python的异常机制对可能在运行时发生状况的代码进行适当的处理,如下所示。
def main():f = Nonetry:f = open('致橡树.txt', 'r', encoding='utf-8')print(f.read())except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')finally:if f:f.close()if __name__ == '__main__':main()
在Python中,我们可以将那些在运行时可能会出现状况的代码放在try代码块中,在try代码块的后面可以跟上一个或多个except来捕获可能出现的异常状况。例如在上面读取文件的过程中,文件找不到会引发FileNotFoundError,指定了未知的编码会引发LookupError,而如果读取文件时无法按指定方式解码会引发UnicodeDecodeError,我们在try后面跟上了三个except分别处理这三种不同的异常状况。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源,由于finally块的代码不论程序正常还是异常都会执行到(甚至是调用了sys模块的exit函数退出Python环境,finally块都会被执行,因为exit函数实质上是引发了SystemExit异常),因此我们通常把finally块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。如果不愿意在finally代码块中关闭文件对象释放资源,也可以使用上下文语法,通过with关键字指定文件对象的上下文环境并在离开上下文环境时自动释放文件资源,代码如下所示。
def main():try:with open('致橡树.txt', 'r', encoding='utf-8') as f:print(f.read())except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')if __name__ == '__main__':main()
除了使用文件对象的read方法读取文件之外,还可以使用for-in循环逐行读取或者用readlines方法将文件按行读取到一个列表容器中,代码如下所示。
import timedef main():# 一次性读取整个文件内容with open('致橡树.txt', 'r', encoding='utf-8') as f:print(f.read())# 通过for-in循环逐行读取with open('致橡树.txt', mode='r') as f:for line in f:print(line, end='')time.sleep(0.5)print()# 读取文件按行读取到列表中with open('致橡树.txt') as f:lines = f.readlines()print(lines)if __name__ == '__main__':main()
要将文本信息写入文件文件也非常简单,在使用open函数时指定好文件名并将文件模式设置为'w'即可。注意如果需要对文件内容进行追加式写入,应该将模式设置为'a'。如果要写入的文件不存在会自动创建文件而不是引发异常。下面的例子演示了如何将1-9999直接的素数分别写入三个文件中(1-99之间的素数保存在a.txt中,100-999之间的素数保存在b.txt中,1000-9999之间的素数保存在c.txt中)。
from math import sqrtdef is_prime(n):"""判断素数的函数"""assert n > 0for factor in range(2, int(sqrt(n)) + 1):if n % factor == 0:return Falsereturn True if n != 1 else Falsedef main():filenames = ('a.txt', 'b.txt', 'c.txt')fs_list = []try:for filename in filenames:fs_list.append(open(filename, 'w', encoding='utf-8'))for number in range(1, 10000):if is_prime(number):if number < 100:fs_list[0].write(str(number) + '\n')elif number < 1000:fs_list[1].write(str(number) + '\n')else:fs_list[2].write(str(number) + '\n')except IOError as ex:print(ex)print('写文件时发生错误!')finally:for fs in fs_list:fs.close()print('操作完成!')if __name__ == '__main__':main()
读写二进制文件
知道了如何读写文本文件要读写二进制文件也就很简单了,下面的代码实现了复制图片文件的功能。
def main():try:with open('guido.jpg', 'rb') as fs1:data = fs1.read()print(type(data)) # <class 'bytes'>with open('吉多.jpg', 'wb') as fs2:fs2.write(data)except FileNotFoundError as e:print('指定的文件无法打开.')except IOError as e:print('读写文件时出现错误.')print('程序执行结束.')if __name__ == '__main__':main()
读写JSON文件
通过上面的讲解,我们已经知道如何将文本数据和二进制数据保存到文件中,那么这里还有一个问题,如果希望把一个列表或者一个字典中的数据保存到文件中又该怎么做呢?答案是将数据以JSON格式进行保存。JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,现在已经被广泛的应用于跨平台跨语言的数据交换,原因很简单,因为JSON也是纯文本,任何系统任何编程语言处理纯文本都是没有问题的。目前JSON基本上已经取代了XML作为异构系统间交换数据的事实标准。关于JSON的知识,更多的可以参考JSON的官方网站,从这个网站也可以了解到每种语言处理JSON数据格式可以使用的工具或三方库,下面是一个JSON的简单例子。
{'name': '骆昊','age': 38,'qq': 957658,'friends': ['王大锤', '白元芳'],'cars': [{'brand': 'BYD', 'max_speed': 180},{'brand': 'Audi', 'max_speed': 280},{'brand': 'Benz', 'max_speed': 320}]
}
可能大家已经注意到了,上面的JSON跟Python中的字典其实是一样一样的,事实上JSON的数据类型和Python的数据类型是很容易找到对应关系的,如下面两张表所示。
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int / real) | int / float |
| true / false | True / False |
| null | None |
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True / False | true / false |
| None | null |
我们使用Python中的json模块就可以将字典或列表以JSON格式保存到文件中,代码如下所示。
import jsondef main():mydict = {'name': '骆昊','age': 38,'qq': 957658,'friends': ['王大锤', '白元芳'],'cars': [{'brand': 'BYD', 'max_speed': 180},{'brand': 'Audi', 'max_speed': 280},{'brand': 'Benz', 'max_speed': 320}]}try:with open('data.json', 'w', encoding='utf-8') as fs:json.dump(mydict, fs)except IOError as e:print(e)print('保存数据完成!')if __name__ == '__main__':main()
json模块主要有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
这里出现了两个概念,一个叫序列化,一个叫反序列化。自由的百科全书维基百科上对这两个概念是这样解释的:“序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换为可以存储或传输的形式,这样在需要的时候能够恢复到原先的状态,而且通过序列化的数据重新获取字节时,可以利用这些字节来产生原始对象的副本(拷贝)。与这个过程相反的动作,即从一系列字节中提取数据结构的操作,就是反序列化(deserialization)”。
目前绝大多数网络数据服务(或称之为网络API)都是基于HTTP协议提供JSON格式的数据,关于HTTP协议的相关知识,可以看看阮一峰老师的《HTTP协议入门》,如果想了解国内的网络数据服务,可以看看聚合数据和阿凡达数据等网站,国外的可以看看{API}Search网站。下面的例子演示了如何使用requests模块(封装得足够好的第三方网络访问模块)访问网络API获取国内新闻,如何通过json模块解析JSON数据并显示新闻标题,这个例子使用了天行数据提供的国内新闻数据接口,其中的APIKey需要自己到该网站申请。
import requests
import jsondef main():resp = requests.get('http://api.tianapi.com/guonei/?key=APIKey&num=10')data_model = json.loads(resp.text)for news in data_model['newslist']:print(news['title'])if __name__ == '__main__':main()
在Python中要实现序列化和反序列化除了使用json模块之外,还可以使用pickle和shelve模块,但是这两个模块是使用特有的序列化协议来序列化数据,因此序列化后的数据只能被Python识别。关于这两个模块的相关知识可以自己看看网络上的资料。另外,如果要了解更多的关于Python异常机制的知识,可以看看segmentfault上面的文章《总结:Python中的异常处理》,这篇文章不仅介绍了Python中异常机制的使用,还总结了一系列的最佳实践,很值得一读。
相关文章:
10 - Python文件编程和异常
文件和异常 在实际开发中,常常需要对程序中的数据进行持久化操作,而实现数据持久化最直接简单的方式就是将数据保存到文件中。说到“文件”这个词,可能需要先科普一下关于文件系统的知识,对于这个概念,维基百科上给出…...
AI绘画-Stable Diffusion 原理介绍及使用
引言 好像很多朋友对AI绘图有兴趣,AI绘画背后,依旧是大模型的训练。但绘图类AI对计算机显卡有较高要求。建议先了解基本原理及如何使用,在看看如何实现自己垂直行业的绘图AI逻辑。或者作为使用者,调用已有的server接口。 首先需…...

2024年过半,新能源车谁在掉链子?
2024年过半之际,各品牌上半年的销量数据也相继出炉,是时候考察今年以来的表现了。 理想和鸿蒙智行两大增程霸主占据头两名,仍处于焦灼状态;极氪和蔚来作为高端纯电品牌紧随其后,两者之间差距很小;零跑和哪…...

离线查询+线段树,CF522D - Closest Equals
一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 522D - Closest Equals 二、解题报告 1、思路分析 考虑查询区间已经给出,我们可以离线查询 对于这类区间离线查询的问题我们通常可以通过左端点排序,然后遍历询问同时维护左区间信息…...

CTF常用sql注入(二)报错注入(普通以及双查询)
0x05 报错注入 适用于页面无正常回显,但是有报错,那么就可以使用报错注入 基础函数 floor() 向下取整函数 返回小于或等于传入参数的最大整数。换句话说,它将数字向下取整到最接近的整数值。 示例: floor(3.7) 返回 3 floor(-2…...
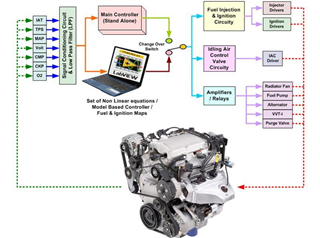
LabVIEW汽车ECU测试系统
开发了一个基于LabVIEW开发的汽车发动机控制单元(ECU)测试系统。该系统使用了NI的硬件和LabVIEW软件,能够自动执行ECU的功能测试和性能测试,确保其在不同工作条件下的可靠性和功能性。通过自动化测试系统,大大提高了测…...
3个让你爽到爆炸的学习工具
We OCR WeOCR 是一个基于浏览器的文字识别工具,用户可以通过上传图片来识别其中的文本信息。它是一个渐进式网络应用程序(PWA),可以在浏览器中离线使用。WeOCR 是开源的,并且基于 Tesseract OCR 引擎开发。用户无需在本…...

Java 重载和重写
Java 重载和重写 重写重载定义指子类定义了一个与其父类中具有相同名称、参数列表和返回类型的方法,并且子类方法的实现覆盖了父类方法的实现。 参数列表和方法名必须相同,即外壳不变,核心重写指在一个类里面,方法名字相同&#x…...
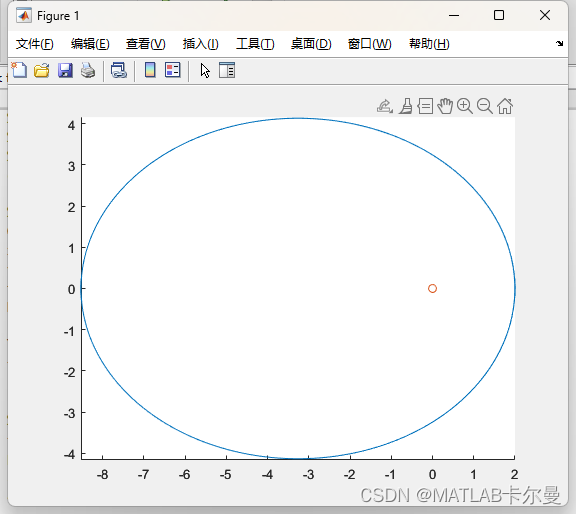
ode45的例程|MATLAB例程|四阶龙格库塔定步长节微分方程
ode45自己编的程序和测试代码 模型 模拟一个卫星绕大行星飞行的轨迹计算。 结果 轨迹图如下: 源代码 以下代码复制到MATLAB上即可运行,并得到上面的图像: % ode45自己编的程序和测试代码 % Evand©2024 % 2024-7-2/Ver1 clear;clc;close all; rng(0); % 参数设定…...

“第六感”真的存在吗?
现在已有证据表明,人类除视觉、听觉、嗅觉、味觉和触觉五种感觉以外,确实存在“第六感” “第六感”的学术名称为“超感自知觉”(简称ESP),它能透过正感官之外的渠道接收信息, 预知将要发生的事,而且与当事人之前的经…...

软信天成:您的数据仓库真的“达标”了吗?
在复杂多变的数据环境中,您的数据仓库是否真的“达标”了?本文将深入探讨数据仓库的定义、合格标准及其与数据库的区别,帮助您全面审视并优化您的数据仓库。 一、什么是数据仓库? 数据仓库是一个面向主题的、集成的、相对稳定的、…...

TCP/IP模型每层内容和传输单位
TCP/IP(Transmission Control Protocol/Internet Protocol)模型是一种用于描述网络通信中协议层次结构的模型,它最初被设计用来描述互联网的协议栈。TCP/IP模型通常分为四层,自下而上分别为: 网络接入层(Ne…...
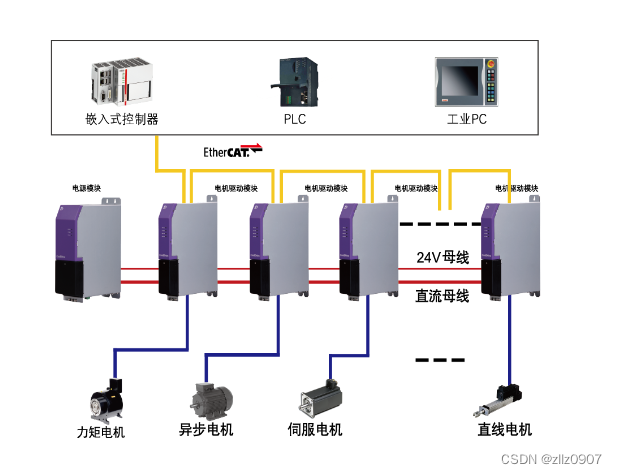
EtherCAT通讯介绍
一、EtherCAT简介 EtherCAT(Ethernet for Control Automation Technology)是一种实时以太网技术,是由德国公司Beckhoff Automation在2003年首次推出的。它是一种开放的工业以太网标准,被设计用于满足工业自动化应用中的高性能和低…...
14-4 深入探究小型语言模型 (SLM)
大型语言模型 (LLM) 已经流行了一段时间。最近,小型语言模型 (SLM) 增强了我们处理和使用各种自然语言和编程语言的能力。但是,一些用户查询需要比在通用语言上训练的模型所能提供的更高的准确性和领域知识。此外,还需要定制小型语言模型&…...

ai智能语音机器人化繁为简让沟通无界限
人工智能这些年的飞速发展一方面顺应着国家智能化发展的规划,一方面印证着智能改动生活的预言。人工智能的开展与人们最息息相关大约就是智能手机的换代更迭,相信大家都有这方面的感受吧!如今企业的电销话务员越来越少,机器人智能…...

c++ primer plus 第15章友,异常和其他:友元类
c primer plus 第15章友,异常和其他:友元类 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:友元类 提示:写完文章后,目录可以自动生成,如何生成可参考右边的…...

面试题002-Java-Java集合
面试题002-Java-Java集合 目录 面试题002-Java-Java集合题目自测题目答案1. 说说 List,Set,Map 三者的区别?三者底层的数据结构?2. 有哪些集合是线程不安全的?怎么解决呢?3. 比较 HashSet 、LinkedHashSet 和 TreeSet 三者的异同&…...

数组越界情况
数组越界情况...

工作日常学习记录
使用情景 今天开发上遇到一个搜索的需求,要求可以多选,模糊查询。我首先和前端沟通,前端多选后使用逗号分隔,拼成字符串传输给我,我后端再进行具体的处理。 具体处理 初步构想 由于需要查询的字段也是一个长的字符…...

C#中的容器
1、数组 数组是存储相同类型元素的固定大小的顺序集合 声明数组时,必须指定数组的大小 2.数组的插入和删除数据比较麻烦,但是查询比较快 2、动态数组(ArrayList) 动态数组:可自动调节数组的大小 可以存储任意类型数…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析
TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析 【免费下载链接】torchdynamo A Python-level JIT compiler designed to make unmodified PyTorch programs faster. 项目地址: https://gitcode.com/gh_mirrors/to/torchdynamo TorchDynamo 是一个…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...