黑马点评DAY5|商户查询缓存
商户查询缓存
缓存的定义
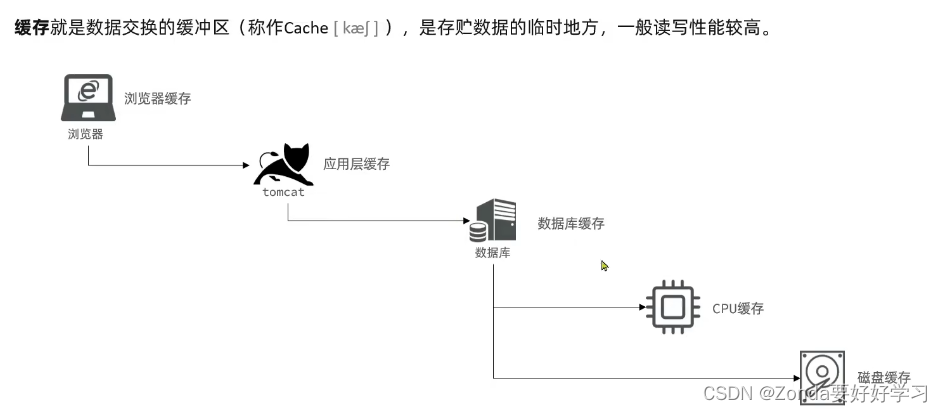
缓存就是数据交换的缓冲区(Cache),是存储数据的临时地方,一般读写性能较高。
- 比如计算机的CPU计算速度非常快,但是需要先从内存中读取数据再放入CPU的寄存器中进行运算,这样会限制CPU的运算速度,所以CPU中也会设计一个缓存,存入经常需要用到的数据,提升了运算效率。CPU缓存也是衡量CPU性能好坏的重要标准之一。
- 再比如浏览器缓存,会缓存一些页面静态资源(js、css),浏览器缓存未命中的一些数据就会去Tomcat中的Java应用请求,而Java应用也有应用层缓存,一般用Redis去做。如果缓存再没有命中,就可以去数据库查询,数据库也有缓存,mysql中如索引数据。最后还会去查询CPU缓存,磁盘缓存。
缓存的优缺点
优点:
- 降低了后端的负载,实际开发的过程中,企业的数据量,少则几十万,多则几千万,如果没有缓存来作为避震器,这么大的用户并发量服务器是扛不住的。
- 缓存的读写效率非常高,响应时间短
缺点:
- 数据一致性成本高
- 代码维护成本高,解决一致性问题需要复杂的业务编码,也有可能出现缓存穿透、缓存雪崩等问题
- 运维成本,缓存需要大规模集群模式,需要人力成本
给店铺查询任务添加缓存
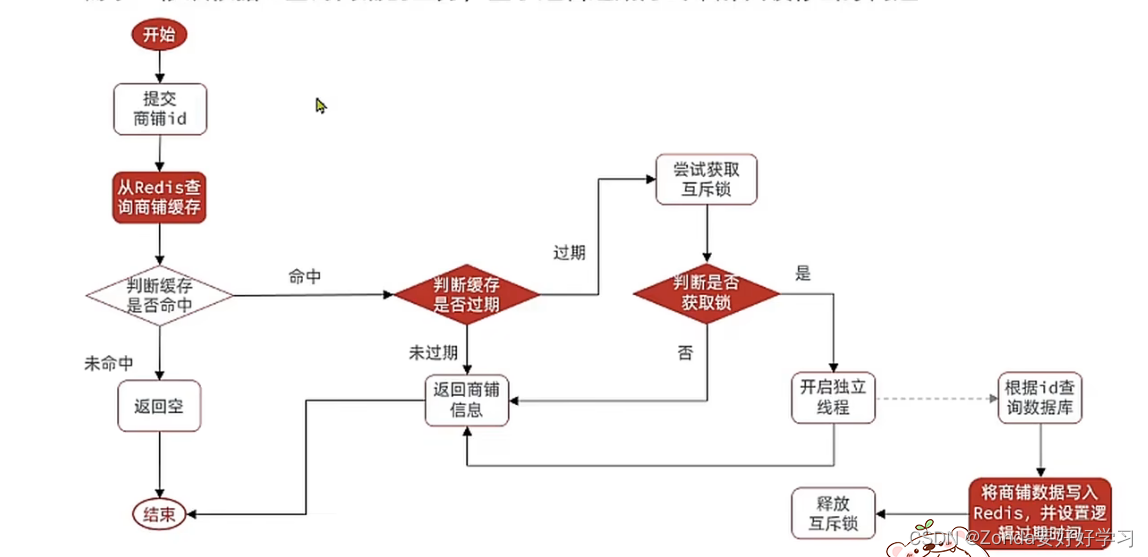
整体的业务逻辑如下图所示:
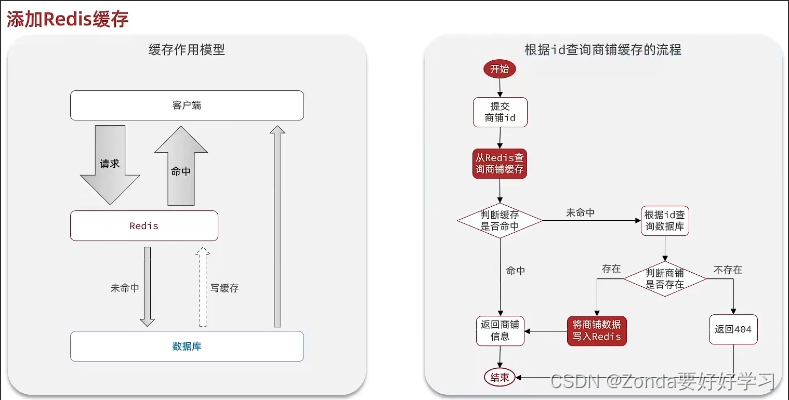
- 先从redis中通过店铺id查询缓存数据,登录模块是用map存的,这里我们使用String来存,就需要将对象先转为JSON格式。
- 如果redis中存在,就返回店铺信息。
- 如果redis中不存在,就继续向数据库中查询。
- 如果数据库不存在,返回“店铺不存在”
- 如果数据库存在,将店铺信息写入redis
- 返回店铺信息
代码如下:
package com.hmdp.service.impl;import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.dto.Result;
import com.hmdp.entity.Shop;
import com.hmdp.mapper.ShopMapper;
import com.hmdp.service.IShopService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;import static com.hmdp.utils.RedisConstants.CACHE_SHOP_KEY;/*** <p>* 服务实现类* </p>** @author 虎哥* @since 2021-12-22*/
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {@AutowiredStringRedisTemplate stringRedisTemplate;@Overridepublic Result queryById(Long id) {String key = CACHE_SHOP_KEY + id;//1.从redis中查询String shopJson = stringRedisTemplate.opsForValue().get(key);//2.存在,返回店铺信息if (!StringUtils.isBlank(shopJson)) {return Result.ok(JSONUtil.toBean(shopJson, Shop.class));}//3.不存在,用id在数据库查询Shop shop = getById(id);//4.不存在,返回“店铺不存在”if (shop == null) {return Result.ok("店铺不存在");}//5.存在,缓存到redisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));//6.返回店铺信息return Result.ok(shop);}
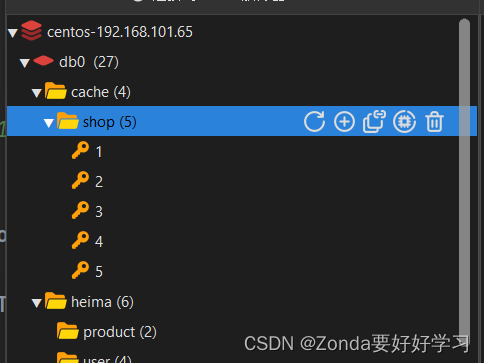
}然后再去第二次查询某一个美食的数据,发现速度由2ms变成了1ms。
在resp中也发现了cache:shop:id的缓存。
拓展练习
将首页的店铺种类信息缓存到redis中

因为店铺种类有十种,可以通过LIst的数据结构存储,但是需要将List中的ShopType对象先转为JSON,取出的时候再由JSON转为ShopType对象。具体代码如下:
package com.hmdp.service.impl;import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.dto.Result;
import com.hmdp.entity.ShopType;
import com.hmdp.mapper.ShopTypeMapper;
import com.hmdp.service.IShopTypeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.List;import static com.hmdp.utils.RedisConstants.CACHE_SHOP_TYPE_KEY;/*** <p>* 服务实现类* </p>** @author 虎哥* @since 2021-12-22*/
@Service
public class ShopTypeServiceImpl extends ServiceImpl<ShopTypeMapper, ShopType> implements IShopTypeService {@AutowiredStringRedisTemplate stringRedisTemplate;public Result queryTypeList() {//1.从redis中查找店铺类型数据List<String> shopTypesByRedis = stringRedisTemplate.opsForList().range(CACHE_SHOP_TYPE_KEY, 0, 9);//2.存在,返回店铺信息,最终需要返回List<ShopType>形式的list,因此需要将JSON转换为ShopType类型List<ShopType> shopTypes = new ArrayList<>();if(shopTypesByRedis.size() != 0){for(String s:shopTypesByRedis){//转为JSONShopType shoptype = JSONUtil.toBean(s, ShopType.class);shopTypes.add(shoptype);}return Result.ok(shopTypes);}//3.不存在,去数据库中寻找,并根据sort排序List<ShopType> shopTypesByMysql = query().orderByAsc("sort").list();//4.数据库不存在,返回店铺信息不存在if(shopTypesByMysql.size() == 0){return Result.ok("店铺信息不存在");}//5.店铺信息存在,存入redis中for(ShopType shop:shopTypesByMysql){stringRedisTemplate.opsForList().leftPush(CACHE_SHOP_TYPE_KEY, JSONUtil.toJsonStr(shop));}//6.返回店铺信息return Result.ok(shopTypesByMysql);}
}缓存更新策略
在业务中,如果我们对数据库数据做了一些修改,但是缓存中的数据没有保持同步更新,用户查询时会查到缓存中的旧数据,这在很多场景下是不允许的。缓存更新的几种策略有三种:
- 内存淘汰(该机制默认存在)
缓存设定一定的上限,当达到这个上限就会自动淘汰部分数据。一致性保持较差,因为淘汰的这一部分数据才可以更新,维护成本为0. - 超时剔除
通过redis中的expire关键字添加TTL时间,到期后自动删除缓存。
一致性强弱取决于TTL的时间,一致性一般好于内存淘汰机制。维护成本也不是很高。 - 主动更新 <\font>
自己编写业务逻辑,在修改数据库的同时,更新缓存。
一致性好,但是维护成本较高。
业务场景选择更新策略的原则:
- 低一致性需求:使用内存淘汰机制,例如店铺类型的查询缓存
- 高一致性需求:主动更新,并以超时剔除作为兜底方案。如店铺详情查询。
一般采用01的方式主动更新缓存

主动更新的方法可以采用:当数据库发生改变的时候,删除缓存,当查询数据库的时候,更新缓存。
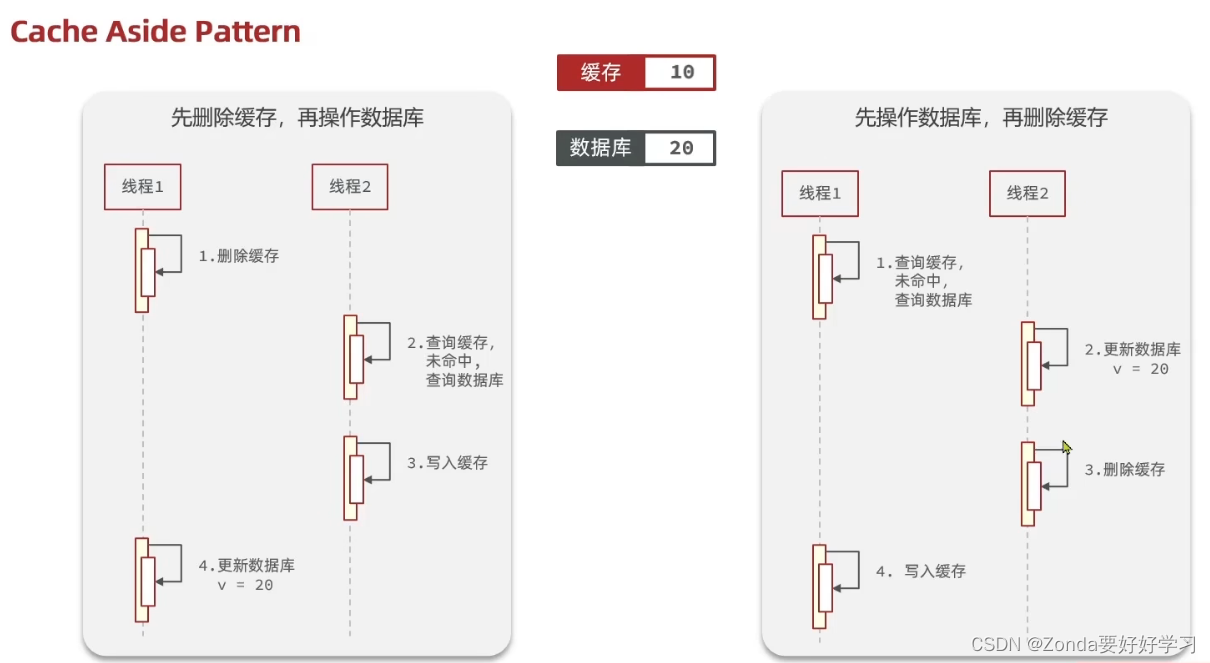
这里有两种操作顺序的选择:
- 先删除缓存,再操作数据库,但是有可能发生如下图左图的安全问题。
- 先操作数据库,再删除缓存。有可能发生如下图右图的安全问题。
- 但是因为数据库读写时间远远大于缓存读写时间,因此右图发生的概率更低。万一发生,超时时间可以兜底。
业务修改
- 根据id查询商铺信息,如果未能在缓存命中,从数据库查询,并写入缓存,设置超时时间
//5.存在,缓存到redis,加入有效时间限制stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
- 根据id修改商铺信息,先修改数据库,再删除缓存。这两个动作需要绑定,所以该方法用事务控制其原子性。
@Override@Transactionalpublic Result update(Shop shop) {Long id = shop.getId();if(id == null){return Result.fail("店铺id不为空");}//1.更新数据库updateById(shop);//2.删除缓存stringRedisTemplate.delete(CACHE_SHOP_KEY+shop.getId());return Result.ok();}
测试:
- 首先测试当访问某一家店铺信息的时候,未命中,是否会缓存到redis中
- 再测试修改店铺信息是否会删除redis缓存,因为修改的功能只能在商家界面做,所以这里用http-client对业务逻辑进行测试。==发送请求,数据库修改,redis缓存也被删除。==说明业务修改成功。这样可以有效解决一致性问题。
PUT http://localhost:8081/shop
Content-Type: application/json{"area":"大关","openHours": "10:00-22:00","sold": 4215,"address": "china","comments":3035,"avgPrice": 80,"score": 37,"name": "110茶餐厅","typeId": 1,"id": 1
}
缓存穿透
客户端请求的数据在缓存和数据库中都不存在,那么根据我们的缓存更新策略,最终都会向数据库索取数据;那么如果有不怀好意的人用并发的线程用虚假的id向数据库请求数据,就会搞垮数据库。
两种解决方案:
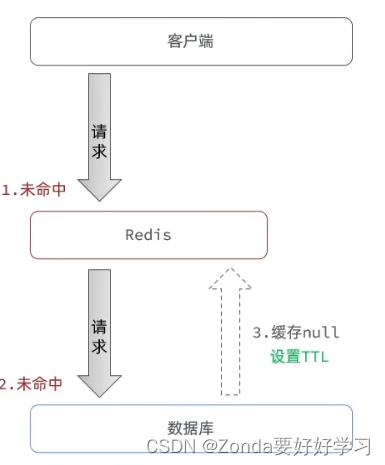
- 缓存空对象:如果redis和数据库中都未能命中,最终数据库会向redis写入一个null,这样在下一次向redis请求的时候就不会再到达数据库。
优点:实现简单、维护方便
缺点:- 有额外的内存消耗(但是也可以给null设置一个TTL)
- 可能造成短期的不一致(可以控制TTL的时长)
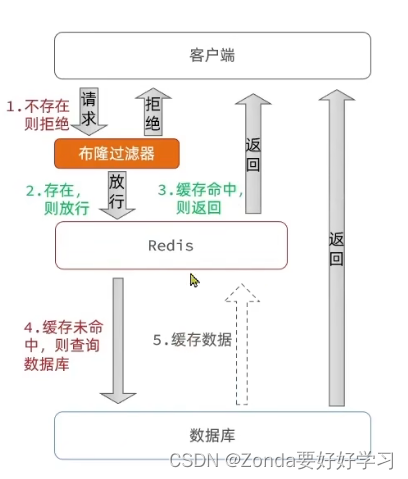
- 布隆过滤器
- 布隆过滤器的原理:
- 定义:布隆过滤器(Bloom Filter)是一种空间效率非常高的概率型数据结构,用于判断一个元素是否属于某个集合。
- 构成:
1.布隆过滤器使用一个固定长度的位数组,所有位初始都设置为0。
2.一组独立的哈希函数,用于将输入元素映射到位数组中的某个位置。 - 判断原理:向布隆过滤器中添加元素时,通过k个哈希函数计算出k个位置,并将这些位置上的位设置为1。查询元素时,使用同样的哈希函数计算出k个位置,并检查这些位置上的位是否全为1。如果所有位置都为1,则元素可能在集合中;如果有一个位置为0,则元素肯定不在集合中。
- 优点:内存占用小,没有多余的key
- 缺点:实现复杂、存在误判可能
- 布隆过滤器的原理:
采用缓存空对象解决缓存穿透问题
我们应该做如下修改:
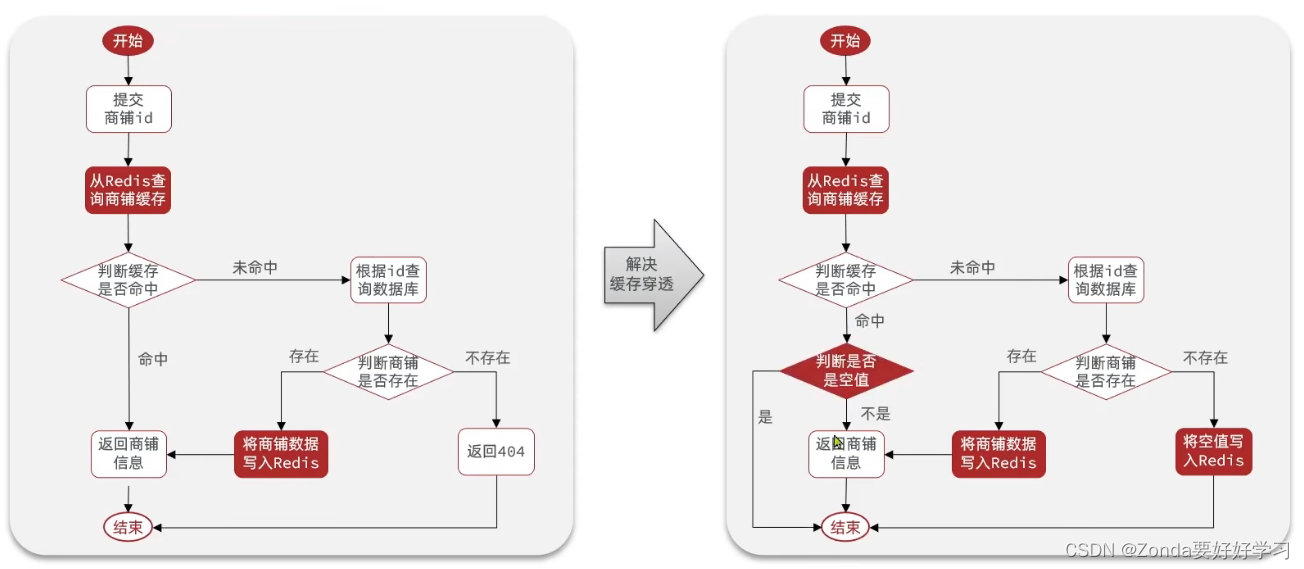
我们需要修改queryById方法,注意字符串判断内容是否相等用equals:shopJson.equals(“”)
@Overridepublic Result queryById(Long id) {String key = CACHE_SHOP_KEY + id;//1.从redis中查询String shopJson = stringRedisTemplate.opsForValue().get(key);//2.命中,返回店铺信息if (!StringUtils.isBlank(shopJson)) {return Result.ok(JSONUtil.toBean(shopJson, Shop.class));}//如果命中的是"",就返回"店铺信息不存在!"if(shopJson != null){return Result.fail("店铺信息不存在!");}//3.不存在,用id在数据库查询Shop shop = getById(id);//4.不存在,返回“店铺不存在”if (shop == null) {//如果数据库不存在该id的商铺,就向redis中存入空字符串,并返回"店铺信息不存在!"stringRedisTemplate.opsForValue().set(key, "");return Result.ok("店铺信息不存在!");}//5.存在,缓存到redis,加入有效时间限制stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);//6.返回店铺信息return Result.ok(shop);}
然后进行测试,发送请求:http://localhost:8080/api/shop/1111,id=1111并不存在,但是该数据会被缓存到redis中:
 再次发送这个请求,不会到达数据库,而是访问redis之后直接就返回。控制台也没有任何数据库调用的日志打印出来。
再次发送这个请求,不会到达数据库,而是访问redis之后直接就返回。控制台也没有任何数据库调用的日志打印出来。
其他解决方案:
- 增加id的复杂度,让攻击者无发猜测到id格式。
- 对id做一些基础的格式校验
- 加强用户权限的管理
- 做好热点参数的限流
缓存雪崩
缓存雪崩指的是大量可以在同一时段同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
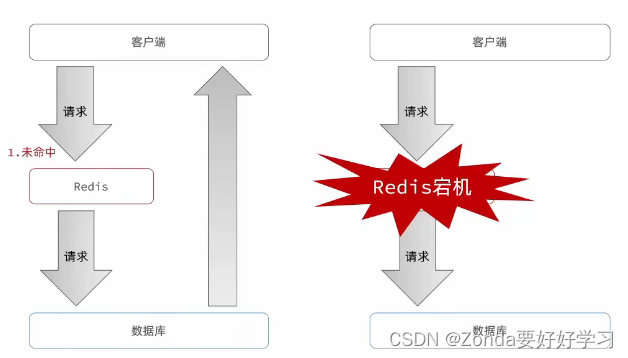
解决方案:
- 给不同的key的TTL添加随机值,这样key就不会在同一时间宕机
- 提高==Redis集群(Redis哨兵模式)==服务的可用性。当一个Redis挂了,会被监控到,立马启动另外一个Redis提供服务。也可以使用主从结构构成集群,防止主节点的数据丢失。
- 给缓存业务添加降级限流策略(比如快速失败、拒绝服务)
- 给业务添加多级缓存(Nginx缓存–JVM缓存–Redis缓存–数据库缓存)。
缓存击穿
缓存击穿也叫热点Key问题,就是一个被高并发访问(比如正在做活动的某一件商品)并且缓存建立业务较为复杂的key失效了,突然大量的请求会在瞬间给数据库带来巨大的冲击。
两种解决方案:
互斥锁解决缓存击穿
让多线程只有一个线程能获取锁来创建缓存
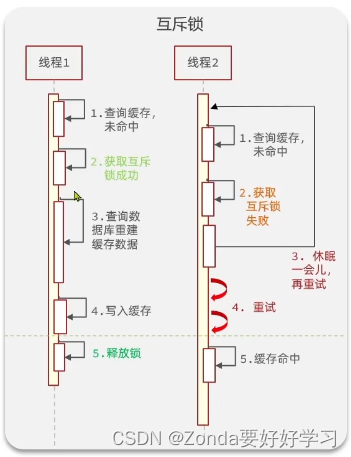
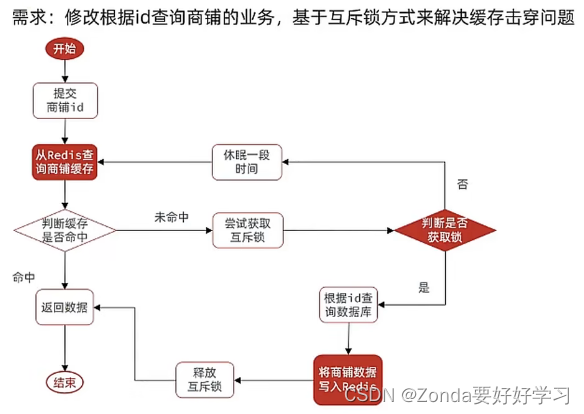
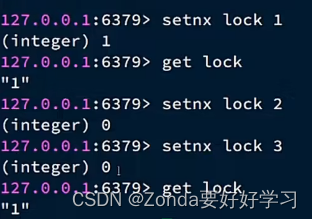
我们可以手动地设定一个锁来实现这样的功能,redis中的setnx表示只有当一个key不存在的时候才可以写入,那么这样就可以达到互斥的效果。那么,
- 获取锁的操作就是:setnx lock 1通常还会给锁加一个TTL,如果超过这个时间,就自动删除锁。防止获取到锁的线
在这里插入代码片程出问题。 - 释放锁的操作就是:del lock
代码实现: - 首先定义获取锁和释放锁的方法:
获取锁:
private boolean tryLock(String key){//获取锁Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10L, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);}
释放锁:
private void unLock(String key){stringRedisTemplate.delete(key);}
将缓存穿透的业务逻辑封装,最终返回Shop对象
//解决缓存穿透的代码public Shop queryWithPassThroough(Long id){String key = CACHE_SHOP_KEY + id;//1.从redis中查询String shopJson = stringRedisTemplate.opsForValue().get(key);//2.命中,返回店铺信息if (!StringUtils.isBlank(shopJson)) {return JSONUtil.toBean(shopJson, Shop.class);}//如果命中的是"",就返回"店铺信息不存在!"if(shopJson != null){return null;}//3.不存在,用id在数据库查询Shop shop = getById(id);//4.不存在,返回“店铺不存在”if (shop == null) {//如果数据库不存在该id的商铺,就向redis中存入空字符串,并返回"店铺信息不存在!"stringRedisTemplate.opsForValue().set(key, "");return shop;}//5.存在,缓存到redis,加入有效时间限制stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);//6.返回店铺信息return shop;}
用互斥锁解决缓存击穿的问题:
//用互斥锁解决缓存击穿的问题public Shop queryWithMutex(Long id){String key = CACHE_SHOP_KEY + id;//1.从redis中查询String shopJson = stringRedisTemplate.opsForValue().get(key);//2.命中,返回店铺信息if (!StringUtils.isBlank(shopJson)) {return JSONUtil.toBean(shopJson, Shop.class);}//3.如果命中的是"",就返回"店铺信息不存在!"if(shopJson != null){return null;}Shop shop = null;//4.实现缓存重建//4.1 获取互斥锁String lockKey = "lock:shop:" + id;boolean isLock = tryLock(lockKey);try {//4.2 判断是否获取成功//4.3 失败,则休眠并重试if(!isLock){Thread.sleep(50);return queryWithMutex(id);}//4.4 成功,用id在数据库查询shop = getById(id);//5.不存在,返回“店铺不存在”if (shop == null) {//如果数据库不存在该id的商铺,就向redis中存入空字符串,并返回"店铺信息不存在!"stringRedisTemplate.opsForValue().set(key, "");return shop;}//6.存在,缓存到redis,加入有效时间限制stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);//7.释放互斥锁} catch (InterruptedException e) {throw new RuntimeException(e);}finally{unLock(lockKey);}//8.返回店铺信息return shop;}
- 通过自动化测试工具jmeter对进行压力测试
执行完发现没有报错
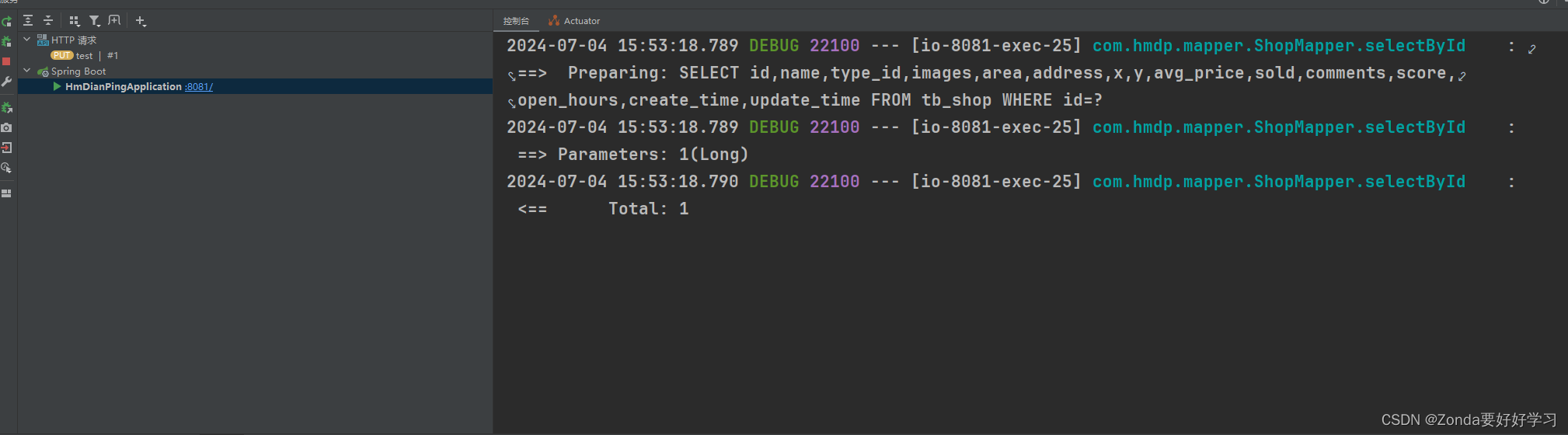
并且数据库只调用了一次select操作,说明互斥锁成功实现了
设置逻辑过期时间解决缓存击穿
- 缓存工具封装对象:
先定义一个类用来保存以及超时时间,对原来代码没有侵入性。
package com.hmdp.entity;import lombok.Data;import java.time.LocalDateTime;/*** @author Zonda* @version 1.0* @description TODO* @2024/7/4 16:21*/
@Data
public class RedisData {private LocalDateTime expireTime;private Object data;}在ShopServiceImpl 新增此方法,利用单元测试进行缓存预热
public void saveShop2Redis(Long id,Long expireSeconds){Shop shop = getById(id);RedisData redisData = new RedisData();redisData.setData(shop);redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));}
相关文章:
黑马点评DAY5|商户查询缓存
商户查询缓存 缓存的定义 缓存就是数据交换的缓冲区(Cache),是存储数据的临时地方,一般读写性能较高。 比如计算机的CPU计算速度非常快,但是需要先从内存中读取数据再放入CPU的寄存器中进行运算,这样会限…...

Owl 中的 Props 概述
在动态的 Web 开发环境中,创建模块化和可重用组件对于构建可扩展应用程序至关重要。将这种方法提升到新水平的一个框架是 Owl,其中“props”(属性的缩写)的概念在协调父组件和子组件之间的通信中起着关键作用。在 Owl 框架中&…...

【大数据综合试验区1008】揭秘企业数字化转型:大数据试验区政策数据集大公开!
今天给大家分享的是国内顶级期刊中国工业经济2023年发布的最新期刊《政策赋能、数字生态与企业数字化转型——基于国家大数据综合试验区的准自然实验》文章中所使用到的数据集——国家大数据综合试验区政策数据集以及工具变量数据,该文章基于2009-2019年中国上市企业…...

在 WebGPU 与 Vulkan 之间做出正确的选择(Making the Right Choice between WebGPU vs Vulkan)
在 WebGPU 与 Vulkan 之间做出正确的选择(Making the Right Choice between WebGPU vs Vulkan) WebGPU 和 Vulkan 之间的主要区别WebGPU 是什么?它适合谁使用?Vulkan 是什么?它适合谁使用?WebGPU 和 Vulkan…...

亚马逊云服务器的价格真的那么贵吗?一年要花多少钱?
亚马逊Web服务(AWS)作为全球领先的云计算平台,其定价策略常常引起用户的关注。很多人可能会问:"AWS真的那么贵吗?"实际上,这个问题的答案并不是简单的"是"或"否",…...

Python学习篇:Python基础知识(三)
目录 1 Python保留字 2 注释 3 行与缩进 编辑4 多行语句 5 输入和输出 6 变量 7 数据类型 8 类型转换 9 表达式 10 运算符 1 Python保留字 Python保留字(也称为关键字)是Python编程语言中预定义的、具有特殊含义的标识符。这些保留字不能用作…...

C++字体库开发之字体回退三
代码片段 class FontCoverage { public: using SP std::shared_ptr<FontCoverage>; virtual ~FontCoverage() default; virtual void set(int index, FontTypes::CoverageLevel level) 0; virtual FontTypes::Coverag…...

python vtk lod 设置
在Python中使用VTK库设置Level of Detail (LOD)可以通过vtkLODProp3D类来实现。这个类允许你为一个模型指定不同级别的细节表示,从而在渲染时根据模型与摄像机的距离自动切换到更适合的表示。 以下是一个简单的例子,展示如何使用vtkLODProp3D来设置LOD&…...

Rhino 犀牛三维建模工具下载安装,Rhino 适用于机械设计广泛领域
Rhinoceros,这款软件小巧而强大,无论是机械设计、科学工业还是三维动画等多元化领域,它都能展现出其惊人的建模能力。 Rhinoceros所包含的NURBS建模功能,堪称业界翘楚。NURBS,即非均匀有理B样条,是计算机图…...

Unleashing Text-to-Image Diffusion Models for Visual Perception
mmcv的环境不好满足,不建议复现...
前言)
[2024]docker-compose实战 (1)前言
前言 本文用来记录使用docker-compose来实战搭建一个多项目的测试环境. 环境中包含nodejs, php, html, redis, MongoDB, mysql. 在本次部署流程中, 尽量保证原镜像的"干净简洁", 尽量不会往镜像中加入各种软件和插件, 所有的配置尽可能的在宿主机映射进去. 项目…...

并发编程面试题3
一、CountDownLatch,Semaphore的高频问题: 1.1 CountDownLatch是啥?有啥用?底层咋实现的? CountDownLatch 本质上是一个计数器,用于协调多个线程之间的同步。主要应用场景是在多线程并行处理业务时,需要等待其他线程处理完再进行后续操作,例如合并结果或响应用户请求…...

Movable antenna 早期研究
原英文论文名字Historical Review of Fluid Antenna and Movable Antenna 最近,无线通信研究界对“流体天线”和“可移动天线”两种新兴天线技术的发展引起了极大的关注,这两种技术因其前所未有的灵活性和可重构性而极大地提高了无线应用中的系统性能。…...

Polkadot 安全机制揭秘:保障多链生态的互操作性与安全性
作者:Filippo Franchini,Web3 Foundation 原文:https://x.com/filippoweb3/status/1806318265536242146 编译:OneBlock Polkadot 是一个创新的多链区块链平台,旨在实现不同区块链之间的互操作性和共享安全性。本文将详…...

python将多个文件夹里面的文件拷贝到一个文件夹中
网上可以搜到很多方式,有的好使,有的不好使,亲测如下脚本可用,并可达到我想要的效果,只将多个文件夹里的文件拷贝到一个文件夹中,不拷贝文件夹本身,如果需要文件夹也拷贝打开注释行即可 import…...

docker私有仓库harbor部署
docker私有仓库harbor部署 概述 Docker 官方镜像源被中国大陆政府封锁,导致无法在中国大陆的计算机上直接使用 Docker 拉取镜像,导致使用者一下子手足无措了,的确一开始会有很大的影响,为了应对这种影响我们可以自己构建私有仓库&…...

如何在Java中实现函数式编程
如何在Java中实现函数式编程 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在Java中,函数式编程是一种编程范式,它将计算视为数学函数…...

二叉树与堆相关的时间复杂度问题
目录 满二叉树与完全二叉树高度h和树中节点个数N的关系 向上调整算法: 介绍: 复杂度推导: 向下调整算法: 介绍: 复杂度推导: 向上调整建堆: 介绍: 复杂度推导:…...
goLang小案例-获取从控制台输入的信息
goLang小案例-获取从控制台输入的信息 1. 案例代码展示 package mainimport ("bufio""fmt""log""os" )var pl fmt.Printlnfunc main() {//控制台输出欢迎提示pl("Hello Go")fmt.Print("what is your name? ")…...

1-5题查询 - 高频 SQL 50 题基础版
目录 1. 相关知识点2. 例题2.1.可回收且低脂的产品2.2.寻找用户推荐人2.3.大的国家2.4. 文章浏览 I2.5. 无效的推文 1. 相关知识点 sql判断,不包含null,判断不出来distinct是通过查询的结果来去除重复记录ASC升序计算字符长度 CHAR_LENGTH() 或 LENGTH(…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

Jetson Orin上TVA模型DLA精准卸载配置
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

免费解锁八大网盘限速!LinkSwift直链下载助手终极指南
免费解锁八大网盘限速!LinkSwift直链下载助手终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

HoRain云--Ollama 安装
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

基于傅里叶神经算子的含时密度泛函理论加速模拟
1. 项目概述与核心思路在计算材料科学和量子化学领域,模拟电子在激光等外场驱动下的动力学行为,是理解光催化、光电转换、甚至量子计算基础过程的关键。含时密度泛函理论(TDDFT)是处理这类问题的“金标准”之一,它通过…...

符号的魔法:数学、物理、化学中那些有趣的故事
🔬 符号的魔法:数学、物理、化学中那些有趣的故事 📖 开篇:为什么符号如此重要? 想象一下,如果没有符号: ❌ 没有数学符号: “一个数加上另一个数等于第三个数,如果第一个…...

SSH协议深度解析:从加密隧道到生产级安全加固
1. 这不是“连服务器”的工具,而是现代数字信任的底层地基很多人第一次听说SSH,是在运维同事敲下ssh user192.168.1.100那刻——屏幕一闪,就进了另一台机器的命令行。于是顺理成章把它理解成“远程登录工具”。但这种认知,就像把高…...

工业控制系统安全:基于机器学习的数据融合异常检测实战
1. 项目概述与核心价值在工业控制系统(ICS)安全领域,我们面临着一个日益严峻的挑战:传统的“单点”防御策略越来越难以应对那些横跨网络层和物理过程层的复杂、隐蔽的攻击。想象一下,一个水处理厂的工程师,…...