项目实战--Spring Boot 3整合Flink实现大数据文件处理
一、应用背景
公司大数据项目中,需要构建和开发高效、可靠的数据处理子系统,实现大数据文件处理、整库迁移、延迟与乱序处理、数据清洗与过滤、实时数据聚合、增量同步(CDC)、状态管理与恢复、反压问题处理、数据分库分表、跨数据源一致性以及实时异常检测与告警等功能,确保数据的准确性、一致性和实时性。采用Spring Boot 3.+和Flink平台上进行数据治理的方案。
二、方案优势
由于是大数据项目,因此在处理大规模数据集时,文件处理能力直接影响到数据驱动决策的效果,高效的大数据文件处理既要能保证数据的时效性和准确性,也要能提升整体系统的性能和可靠性。
Spring Boot 3.+和Flink结合使用,在处理大数据文件时有不少独特的优势。
首先,这两者能够相互补充,带来高效和便捷的文件处理能力的原因在于:
(1)统一的开发体验:
Spring Boot 3.+和Flink结合使用,可以在同一项目中综合应用两者的优势。Spring Boot可以负责微服务的治理、API的管理和调度,而Flink则专注于大数据的实时处理和分析。两者的结合能够提供一致的开发体验和简化的集成方式。(2)动态扩展和高可用性:
微服务架构下,Spring Boot提供的良好扩展性和Flink的高可用性,使得系统可以在需求增长时动态扩展,确保系统稳定运行。Flink的容错机制配合Spring Boot的服务治理能力,可以有效提高系统的可靠性。(3)灵活的数据传输和处理:
通过Spring Boot的REST API和消息队列,可以轻松地将数据传输到Flink进行处理,Flink处理完毕后还可以将结果返回到Spring Boot处理的后续业务逻辑中。这种灵活的处理方式使得整个数据处理流程更为高效且可控。
三、实现步骤
1.首先配置Spring Boot 3.x和Flink的开发环境。在pom.xml中添加必要的依赖:
<dependencies><!-- Spring Boot 依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Apache Flink 依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.14.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.14.0</version></dependency><!-- 其他必要依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-filesystem_2.11</artifactId><version>1.14.0</version></dependency>
</dependencies>
2.数据的读取、处理和写入流程
2.1 数据读取
数据源选择:(项目中使用的是HDFS,故后续文档展示从HDFS中并行读取数据)
(1)本地文件系统:适用于中小规模数据处理,开发和调试方便。
(2)分布式文件系统(HDFS):适用于大规模数据处理,具备高扩展性和容错能力。
(3)云存储(S3):适用于云环境下的数据处理,支持弹性存储和高可用性。
为提高读取性能,采用多线程并行读取和数据分片等策略。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class HDFSDataReader {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 从 HDFS 中读取数据,并通过并行流的方式对数据进行处理和统计。DataStream<String> text = env.readTextFile("hdfs://localhost:9000/resources/datafile");DataStream<Tuple2<String, Integer>> wordCounts = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {for (String word : value.split("\\s")) {out.collect(new Tuple2<>(word, 1));}}}).keyBy(0).sum(1);wordCounts.writeAsText("hdfs:///path/to/output/file", FileSystem.WriteMode.OVERWRITE);env.execute("HDFS Data Reader");}
}
2.2 数据处理
数据清洗和预处理是大数据处理中重要的一环,包括步骤:
数据去重:移除重复的数据,确保数据唯一性。
数据过滤:排除不符合业务规则的无效数据。
数据转换:将数据格式转换为统一的规范格式,便于后续处理。
进行简单的数据清洗操作:
DataStream<String> cleanedData = inputStream.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) {// 过滤空行和不符合格式的数据return value != null && !value.trim().isEmpty() && value.matches("regex");}}).map(new MapFunction<String, String>() {@Overridepublic String map(String value) {// 数据格式转换return transformData(value);}});
在数据清洗之后,需要对数据进行各种聚合和分析操作,如统计分析、分类聚类等。这是大数据处理的核心部分,Flink 提供丰富的内置函数和算子来帮助实现这些功能。
对数据进行简单的聚合统计:
DataStream<Tuple2<String, Integer>> aggregatedData = cleanedData.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {for (String word : value.split("\\s+")) {out.collect(new Tuple2<>(word, 1));}}}).keyBy(0).sum(1);
2.3 数据写入
处理后的数据需要高效地写入目标存储系统,常见的数据存储包括文件系统、数据库和消息队列等。选择合适的存储系统不仅有助于提升整体性能,同时也有助于数据的持久化和后续分析。
文件系统:适用于批处理结果的落地存储。
数据库:适用于结构化数据的存储和查询。
消息队列:适用于实时流处理结果的传输和消费。
为提高写入性能,可以采取分区写入、批量写入和压缩等策略。
使用分区写入和压缩技术将处理后的数据写入文件系统:
outputStream.map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> value) {// 数据转换为字符串格式return value.f0 + "," + value.f1;}}).writeAsText("file:output/tag/datafile", FileSystem.WriteMode.OVERWRITE).setParallelism(4) // 设置并行度.setWriteModeWriteParallelism(FileSystem.WriteMode.NO_OVERWRITE); // 设置写入模式和压缩
3.性能优化
3.1 并行度设置
Flink 支持高度并行的数据处理,通过设置并行度可以提高整体处理性能。
设置Flink的全局并行度和算子级并行度:
env.setParallelism(8); // 设置全局并行度DataStream<Tuple2<String, Integer>> result = inputStream.flatMap(new Tokenizer()).keyBy(0).sum(1).setParallelism(4); // 设置算子级并行度
3.2 资源管理
合理管理计算资源,避免资源争用,可以显著提高数据处理性能。在实际开发中,可以通过配置Flink的TaskManager资源配额(如内存、CPU)来优化资源使用:
# Flink 配置文件 (flink-conf.yaml)
taskmanager.memory.process.size: 2048m
taskmanager.memory.framework.heap.size: 512m
taskmanager.numberOfTaskSlots: 4
3.3 数据切分和批处理
对于大文件处理,可以采用数据切分技术,将大文件拆分为多个小文件进行并行处理,避免单个文件过大导致的处理瓶颈。同时,使用批处理可以减少网络和I/O操作,提高整体效率。
DataStream<String> partitionedStream = inputStream.rebalance() // 重新分区.mapPartition(new MapPartitionFunction<String, String>() {@Overridepublic void mapPartition(Iterable<String> values, Collector<String> out) {for (String value : values) {out.collect(value);}}}).setParallelism(env.getParallelism());
3.4 使用缓存和压缩
对于高频访问的数据,可将中间结果缓存到内存中,以减少重复计算和I/O操作。此外,在写入前对数据进行压缩(如 gzip)可以减少存储空间和网络传输时间。
四、完整示例
通过一个完整的示例来实现Spring Boot 3.+和Flink大数据文件的读取和写入。涵盖上述从数据源读取文件、数据处理、数据写入到目标文件的过程。
首先,通过Spring Initializer创建一个新的Spring Boot项目(spring boot 3需要jdk17+),添加以下依赖:
<dependencies><!-- Spring Boot 依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Apache Flink 依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.14.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.14.0</version></dependency><!-- 其他必要依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-filesystem_2.11</artifactId><version>1.14.0</version></dependency>
</dependencies>
定义一个配置类来管理文件路径和其他配置项:
import org.springframework.context.annotation.Configuration;@Configuration
public class FileProcessingConfig {// 输入文件路径public static final String INPUT_FILE_PATH = "fhdfs://localhost:9000/resources/datafile";// 输出文件路径public static final String OUTPUT_FILE_PATH = "file:output/tag/datafile";
}
在业务逻辑层定义文件处理操作:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.core.fs.FileSystem;
import org.springframework.stereotype.Service;@Service
public class FileProcessingService {public void processFiles() throws Exception {// 创建Flink执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 配置数据源,读取文件DataStream<String> inputStream = env.readTextFile(FileProcessingConfig.INPUT_FILE_PATH);// 数据处理逻辑,将数据转换为大写DataStream<String> processedStream = inputStream.map(new MapFunction<String, String>() {@Overridepublic String map(String value) {return value.toUpperCase();}});// 将处理后的数据写入文件processedStream.writeAsText(FileProcessingConfig.OUTPUT_FILE_PATH, FileSystem.WriteMode.OVERWRITE);// 启动Flink任务env.execute("File Processing Job");}
}
在主应用程序类中启用Spring调度任务:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.beans.factory.annotation.Autowired;@EnableScheduling
@SpringBootApplication
public class FileProcessingApplication {@Autowiredprivate FileProcessingService fileProcessingService;public static void main(String[] args) {SpringApplication.run(FileProcessingApplication.class, args);}// 定时任务,每分钟执行一次@Scheduled(fixedRate = 60000)public void scheduleFileProcessingTask() {try {fileProcessingService.processFiles();} catch (Exception e) {e.printStackTrace();}}
}
优化数据处理部分,加入更多处理步骤,包括数据校验和过滤来确保数据的质量和准确性。
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class EnhancedFileProcessingService {public void processFiles() throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> inputStream = env.readTextFile(FileProcessingConfig.INPUT_FILE_PATH);// 数据预处理:数据校验和过滤DataStream<String> filteredStream = inputStream.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) {// 过滤长度小于5的字符串return value != null && value.trim().length() > 5;}});// 数据转换:将每行数据拆分为单词DataStream<Tuple2<String, Integer>> wordStream = filteredStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {for (String word : value.split("\\W+")) {out.collect(new Tuple2<>(word, 1));}}});// 数据聚合:统计每个单词的出现次数DataStream<Tuple2<String, Integer>> wordCounts = wordStream.keyBy(value -> value.f0).sum(1);// 将结果转换为字符串并写入输出文件DataStream<String> resultStream = wordCounts.map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> value) {return value.f0 + ": " + value.f1;}});resultStream.writeAsText(FileProcessingConfig.OUTPUT_FILE_PATH, FileSystem.WriteMode.OVERWRITE);env.execute("Enhanced File Processing Job");}
}
增加以下步骤:
数据校验和过滤:过滤掉长度小于5的行,确保数据质量。
数据转换:将每行数据拆分为单词,并为每个单词附加计数1。
数据聚合:统计每个单词的出现次数。
结果写入:将统计结果写入输出文件。
对Flink的资源配置进行优化,有效管理 TaskManager 的内存和并行度,以确保文件处理任务的高效执行:
# Flink 配置文件 (flink-conf.yaml)
taskmanager.memory.process.size: 4096m
taskmanager.memory.framework.heap.size: 1024m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 4
好,ok,刹国!
相关文章:

项目实战--Spring Boot 3整合Flink实现大数据文件处理
一、应用背景 公司大数据项目中,需要构建和开发高效、可靠的数据处理子系统,实现大数据文件处理、整库迁移、延迟与乱序处理、数据清洗与过滤、实时数据聚合、增量同步(CDC)、状态管理与恢复、反压问题处理、数据分库分表、跨数据…...

开发者工具攻略:前端测试的极简指南
前言 许多人存在一个常见的误区,认为测试只是测试工程师的工作。实际上,测试是整个开发团队的责任,每个人都应该参与到测试过程中。 在这篇博客我尽量通俗一点地讲讲我们前端开发过程中,该如何去测试 浏览器开发者工具简介 开…...

git保存分支工作状态
git stash...

系统架构设计师——计算机体系结构
分值占比3-4分 计算机硬件组成 计算机硬件组成主要包括主机、存储器和输入/输出设备。 主机:主机是计算机的核心部分,包括运算器、控制器、主存等组件。运算器负责执行算术和逻辑运算;控制器负责协调和控制计算机的各个部件;主存…...
3D鸡哥又上开源项目!单图即可生成,在线可玩
大家好,今天和大家分享几篇最新的工作 1、Unique3D Unique3D从单视图图像高效生成高质量3D网格,具有SOTA水平的保真度和强大的通用性。 如下图所示 Unique3D 在 30 秒内从单视图野生图像生成高保真且多样化的纹理网格。 例如属于一张鸡哥的打球写真照 等…...

设计模式实现思路介绍
设计模式是在软件工程中用于解决特定问题的典型解决方案。它们是在多年的软件开发实践中总结出来的,并且因其重用性、通用性和高效性而被广泛接受。设计模式通常被分为三种主要类型:创建型、结构型和行为型。 创建型设计模式 创建型设计模式专注于如何创…...

Node.js学习教程
Node.js学习教程可以从基础到高级,逐步深入理解和掌握这一强大的JavaScript运行环境。以下是一个详细的Node.js学习教程概述,帮助初学者和进阶者更好地学习Node.js。 一、Node.js基础入门 1. 了解Node.js 定义:Node.js是一个基于Chrome V8…...

项目页面优化,我们该怎么做呢?
避免页面卡顿 怎么衡量页面卡顿的情况呢? 失帧和帧率FPS 60Hz就是帧率fps,即一秒钟60帧,换句话说,一秒钟的动画是由60幅静态图片连在一起形成的。 卡了,失帧了,或者掉帧了,一秒钟没有60个画面&…...
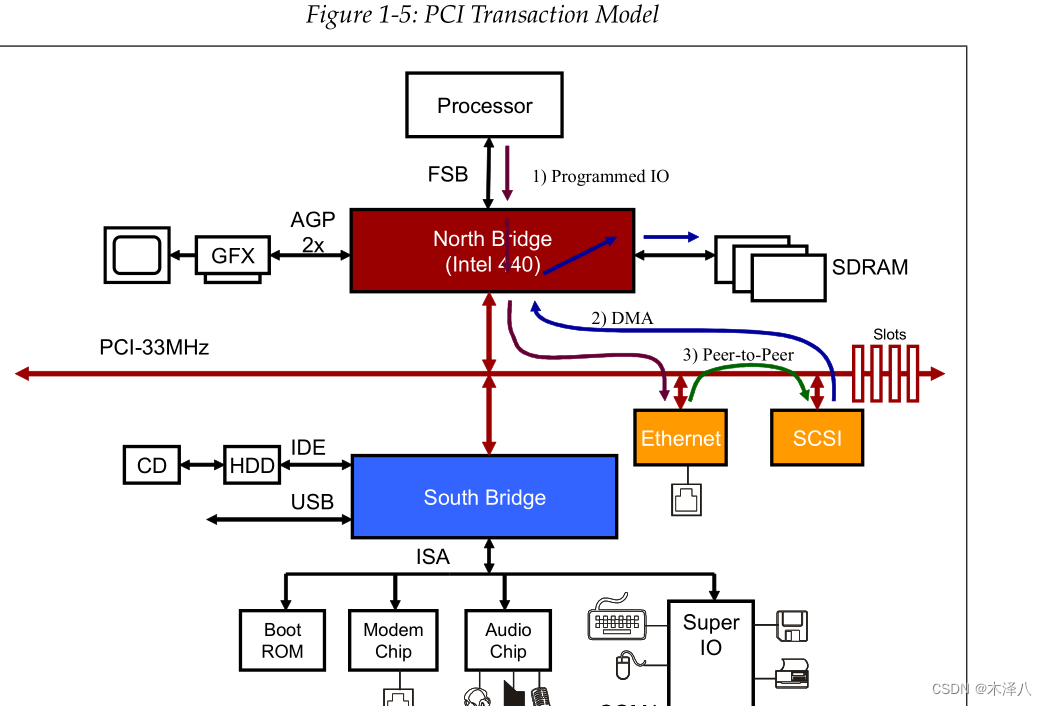
【PCIe】P2P DMA
PCIe P2P (peer-to-peer communication)是PCIe的一种特性,它使两个PCIe设备之间可以直接传输数据,而不需要使用主机RAM作为临时存储。如下图3的走向 比如EP1要发送和数据给EP2,操作流程如下: 1. 打开EP1的dma控制器;--client侧 …...

Linux shell编程学习笔记62: top命令 linux下的任务管理器
0 前言 top命令是Unix 和 Linux下常用的性能分析工具,提供了一个动态的、交互式的实时视图,显示系统的整体性能信息,以及正在运行的进程的相关信息,包括各个进程的资源占用状况,类似于Windows的任务管理器。 1 top命令…...

如何在Java中实现高性能的网络通信
如何在Java中实现高性能的网络通信 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 1. 引言 在当今互联网时代,高性能的网络通信是构建大规模分布…...
政务单位网站SSL证书选择策略
在数字化快速发展的今天,政务单位网站作为政府与公众沟通的重要桥梁,其安全性和可信度显得尤为重要。SSL证书作为保障网站安全的重要手段,其选择对于政务单位网站来说至关重要。本文将探讨政务单位网站在选择SSL证书时应该考虑的因素…...
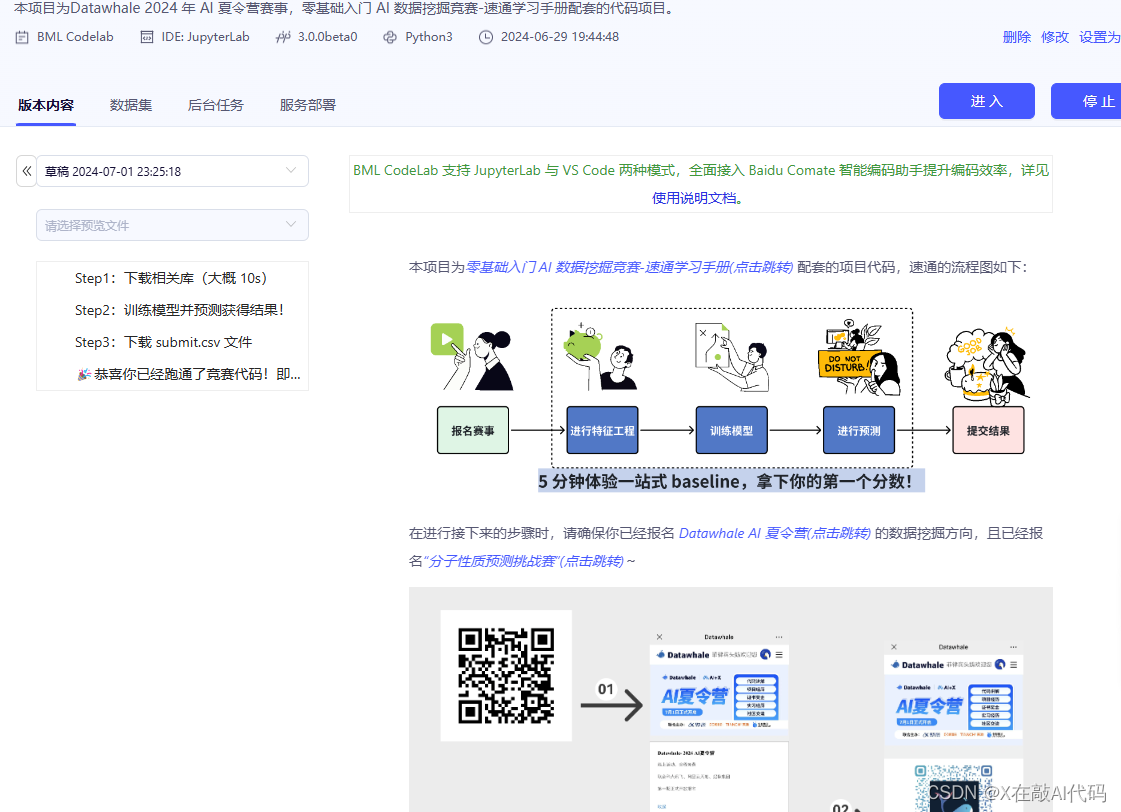
零基础入门 Ai 数据挖掘竞赛-速通 Baseline-1
#AI夏令营 #Datawhale #夏令营 本项目为Datawhale 2024 年 AI 夏令营赛事,零基础入门 AI 数据挖掘竞赛-速通学习手册配套的代码项目。 项目链接:https://aistudio.baidu.com/bd-cpu-02/user/2961857/8113198/home#codelab 任务目标 根据给的test&…...
(Python))
第二十六章 生成器(generator)(Python)
文章目录 前言一、生成器函数 前言 在 Python 中,使用了 yield 的函数被称为生成器(generator) yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值ÿ…...

Vue通过Key管理状态
Vue通过Key管理状态 Vue 默认按照“就地更新”的策略来更新,通过 v-for 渲染的元素列表。当数据项的顺序改变时,Vue 不会随之移动 DOM 元素的顺序,而是就地更新每个元素,确保它们在原本指定的索引位置上渲染。为了给 Vue 一个提示…...
鸿蒙 HarmonyOs 网络请求 快速入门
官方文档: ArkUI简介-ArkUI(方舟UI框架)-应用框架 | 华为开发者联盟 (huawei.com) 一、通过原有的http组件进行网络请求(方式一) 1.1 HttpRequestOptions的操作 名称类型描述methodRequestMethod请求方式ÿ…...

Kubernetes云原生存储解决方案openebs部署实践-4.0.1版本(helm部署)
Kubernetes云原生存储解决方案openebs部署实践-4.0.1版本(helm部署) 简介 OpenEBS 是一种开源云原生存储解决方案。OpenEBS 可以将 Kubernetes 工作节点可用的任何存储转化为本地或复制的 Kubernetes 持久卷。OpenEBS 帮助应用和平台团队轻松地部署需要…...

如何使用Pip生成requirements.txt文件:全面指南与实践示例
如何使用Pip生成requirements.txt文件:全面指南与实践示例 Python的包管理工具Pip是Python开发中不可或缺的一部分。它不仅可以帮助我们安装和管理Python包,还可以通过生成requirements.txt文件来记录项目所需的所有依赖。本文将详细介绍如何使用Pip生成…...
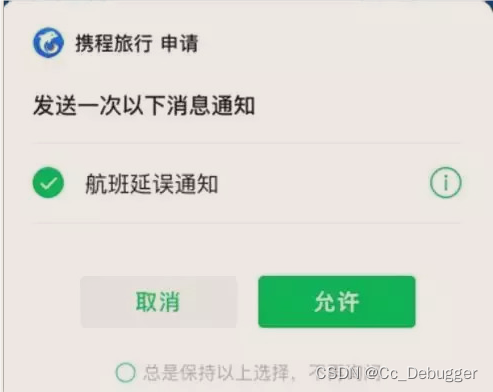
微信小程序消息通知(一次订阅)
在微信公众平台配置通知模版 通过wx.login获取code发送给后端 let that this // 登陆codewx.login({success: function (res) {if (res.code) {// 发送code到后端换取openid和session_keythat.setData({openCode: res.code})console.log(that.data.openCode, openCode);// 调…...

电传动无杆飞机牵引车交付用户
自2019年起,我们计划做电传动控制,先后做了电传动水泥搅拌罐车罐体控制(国内首创),初步理解了电机控制的特点。 20-21年接着做了10t飞机牵引车控制,还是电液控制联合的,把越野叉车的行驶控制方…...

第一次给 CANN 社区做贡献?从 community 仓库入手
前言 开源社区是个奇妙的地方。你用着别人免费分享的代码,享受着别人免费提供的文档,突然有一天你想:我是不是也能为这个社区做点贡献? 但紧接着你就被一堆问题拦住了:怎么提 Issue?怎么提 PR?…...

实验二 基于 VMware Workstation 的虚拟机平台搭建、客户机安装与虚拟网络模式验证
作者:非凡大爹|版本:v1|日期:2026-03-24|DocID:CN-LAB-2026-03-VMNet-1-LG-V2 原创声明:本文为作者原创实验教学资料,首发于 CSDN。 版权声明:本文版权归作者…...

脉冲神经网络在工业预测性维护中的低功耗应用
1. 脉冲神经网络在工业预测性维护中的低功耗革命在工业物联网(IIoT)领域,设备健康监测一直面临着能耗与精度的双重挑战。传统振动监测方案需要将高分辨率数据上传云端分析,不仅产生巨大通信开销,更限制了电池供电设备的续航能力。我们团队最近…...

不变量理论:从数学原理到机器学习中的对称性特征工程
1. 项目概述:从“区分”到“表达”的核心思想在数据科学和机器学习的世界里,我们常常面对一个根本性的挑战:如何从一堆看似杂乱无章、经过各种变换(如旋转、平移、对称操作)的数据中,提取出真正有意义的、稳…...
)
别急着买云服务器!手把手教你用闲置Win10电脑搭建个人SSH服务器(保姆级教程)
闲置Win10变身SSH服务器:零成本打造远程开发环境家里那台吃灰的旧电脑,其实藏着个免费云服务器——这话听起来像天方夜谭?去年我用一台2015年的联想笔记本搭建的SSH服务器,至今稳定运行着三个Python爬虫和两个测试项目。下面这套方…...

耦合振荡器模型在MPI并行计算同步分析中的应用
1. 耦合振荡器系统概述耦合振荡器模型为理解复杂系统中的同步行为提供了强有力的数学框架。在分布式计算领域,特别是MPI(Message Passing Interface)并行程序中,这种模型能够精确刻画计算节点间的动态交互过程。每个计算进程可视为…...

突破索尼相机数字枷锁:Sony-PMCA-RE逆向工程技术深度解析
突破索尼相机数字枷锁:Sony-PMCA-RE逆向工程技术深度解析 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 在数码摄影领域,索尼相机以其卓越的成像技术和创新…...

澜起科技股东上海融迎拟减持:可套现超30亿 公司刚港股募资80亿港元
雷递网 乐天 5月23日澜起科技股份有限公司(证券代码:688008 证券简称:澜起科技)日前发布公告,宣布公司股东上海融迎企业管理合伙企业(有限合伙)拟转让 A 股股份总数为12,228,000 股,…...

Windows关机修复机制:漏洞补丁静默安装原理与实操
1. 这不是“一键修复”,而是系统级补丁调度机制的落地实践很多人看到“360安全卫士漏洞修复全新升级”这个标题,第一反应是:又一个弹窗广告式功能更新。但如果你真点开设置页、翻过日志、对比过前后两次关机流程的系统行为,就会发…...

李白的思乡诗 / 山水诗 / 豪放诗有哪些?诗词在线app手工整理
"酒入豪肠,七分酿成了月光,余下的三分啸成剑气,绣口一吐就半个盛唐。" 李白的诗,是盛唐最耀眼的星,既有 "天生我材必有用" 的豪放,也有 "低头思故乡" 的柔情,更有…...