零基础入门 Ai 数据挖掘竞赛-速通 Baseline-1
#AI夏令营
#Datawhale
#夏令营
本项目为Datawhale 2024 年 AI 夏令营赛事,零基础入门 AI 数据挖掘竞赛-速通学习手册配套的代码项目。
项目链接:https://aistudio.baidu.com/bd-cpu-02/user/2961857/8113198/home#codelab
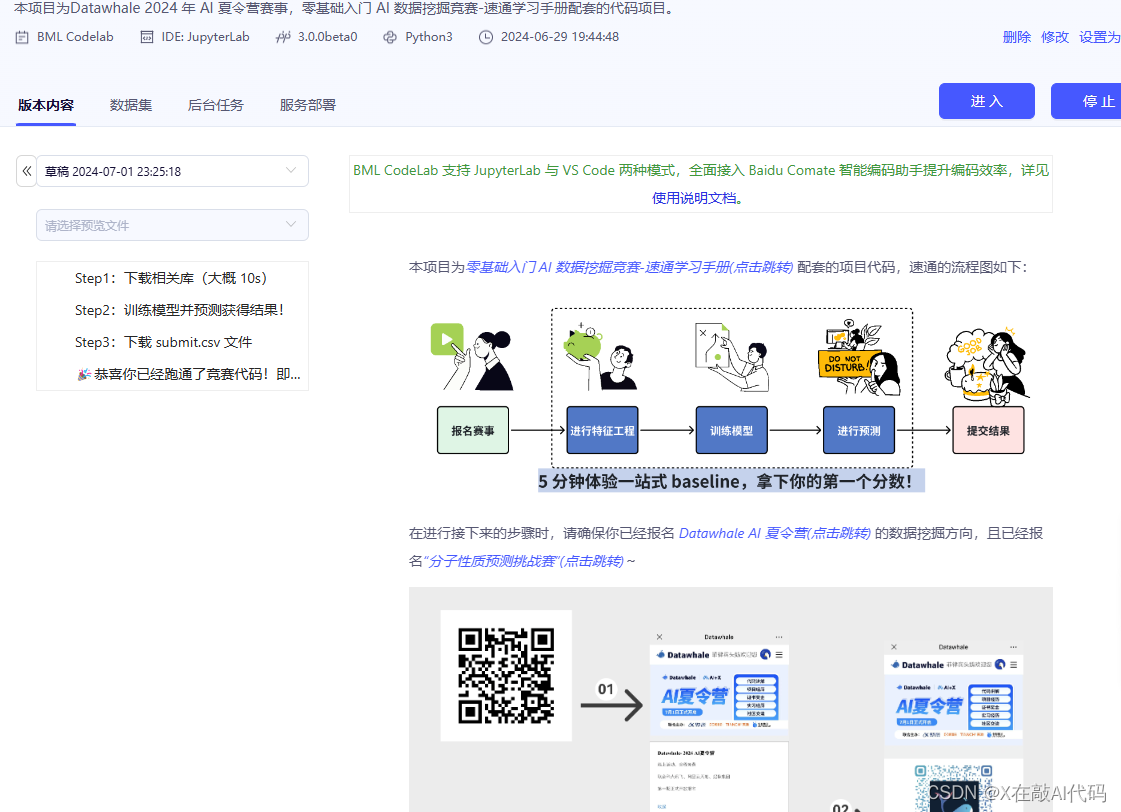
任务目标
根据给的test,train数据集,训练模型,从而 预测PROTACs的降解能力 (在demo中用label表示,0表示差,1表示好)
DC50>100nM&Dmax<80% -》Label=0
DC50<=100nM||Dmax>=80%-》Label=1)。
解题思路
1.选用机器学习方法,能达到和深度学习相同的结果,且更方便简捷
2.这里从逻辑回归和决策树中选择,哪一个模型更加合适?
逻辑回归的适用条件:
- 目标变量类型:
- 逻辑回归主要用于处理二分类问题,即目标变量是二元的,如是/非、成功/失败等。
- 输入变量类型:
- 逻辑回归可以处理连续变量、类别变量以及二进制变量。
- 数据分布假设:
- 逻辑回归通常假设数据服从伯努利分布,即目标变量服从二项分布。
- 线性关系:
- 逻辑回归假设自变量与对数几率的关系是线性的。
- 解释性:
- 逻辑回归模型相对简单,模型的输出可以解释为概率,因此在需要理解影响因素和解释模型结果时比较有优势。
决策树的适用条件:
- 目标变量类型:
- 决策树既可以处理分类问题,也可以处理回归问题。
- 输入变量类型:
- 决策树可以处理数值型数据 分类型数据 序数型数据和类别变量,不需要对数据做过多的预处理工作。
1.数值型数据:例如连续的浮点数或整数。
2.分类型数据:例如名义变量,通常是有限个数的离散取值,比如颜色、性别等。
3.序数型数据:具有顺序关系的分类型数据,比如教育程度(小学、中学、大学)。
- 决策树可以处理数值型数据 分类型数据 序数型数据和类别变量,不需要对数据做过多的预处理工作。
- 非线性关系:
- 决策树能够处理非线性关系,不需要对数据做线性假设。
- 解释性:
- 决策树的决策路径比较直观,易于理解和解释,能够呈现特征的重要性。
- 处理缺失值:
- 决策树能够自动处理缺失值,不需要额外的数据预处理步骤。
总结比较:
- 逻辑回归适合于简单的二分类问题,当数据满足线性关系假设时表现较好,适合作为基线模型进行比较和解释。
- 决策树则更适合处理复杂的非线性关系,能够处理多分类问题和回归问题,同时具备一定的解释性和容错性。
- 选择决策树
- 决策树能够处理非线性关系,并且可以自动捕获特征之间的交互作用。
- 它可以生成可解释的规则,有助于理解模型如何做出决策。
- 决策树能够处理不同类型的特征,包括分类和数值型。
决策树基本代码
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 1. 准备数据
# 假设有一个名为 'data.csv' 的数据集,包含特征和标签# 读取数据集
data = pd.read_csv('data.csv')# 分离特征和标签
X = data.drop('target_column_name', axis=1) # 特征列
y = data['target_column_name'] # 标签列# 2. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 3. 创建决策树模型
model = DecisionTreeClassifier()# 4. 训练模型
model.fit(X_train, y_train)# 5. 预测
y_pred = model.predict(X_test)# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')# 可选步骤:可视化决策树
# 如果需要可解释性,可以将训练好的模型可视化
# 可以使用 Graphviz 和 export_graphviz 方法
# 例如:from sklearn.tree import export_graphviz# 注意:上述代码中的 'target_column_name' 是你数据集中的目标列名,需要根据实际情况替换为正确的列名。LGB树模型
1.[LightGBM]是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
2.LightGBM:跟之前常用的XGBoot在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。
LightGBM通过引入高效的直方图算法来优化决策树的训练过程。传统的梯度提升算法(如GBoost)是按层生长(level-wise growth)的,而LightGBM则采用了按叶子生长(leaf-wise growth)的策略,这样能够更快地生成深度较少但分裂质量较高的决策树。
-LightGBM在构建每棵决策树时,还利用了特征的直方图信息,有效地减少了内存使用并提高了训练速度。这种优化对于处理大规模数据和高维特征特别有用。
原理
机器学习—LightGBM的原理、优化以及优缺点-CSDN博客
示例代码
# 导入必要的库
import lightgbm as lgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 1. 准备数据
# 假设有一个名为 'data.csv' 的数据集,包含特征和标签# 读取数据集
data = pd.read_csv('data.csv')# 分离特征和标签
X = data.drop('target_column_name', axis=1) # 特征列
y = data['target_column_name'] # 标签列# 2. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 3. 创建LightGBM模型
params = {'boosting_type': 'gbdt', # 使用gbdt提升器'objective': 'binary', # 二分类任务'metric': 'binary_logloss', # 使用logloss作为评估指标'num_leaves': 31, # 每棵树的叶子节点数'learning_rate': 0.05, # 学习率'feature_fraction': 0.9, # 训练每棵树时使用的特征比例'bagging_fraction': 0.8, # 每轮迭代时用来训练模型的数据比例'bagging_freq': 5, # bagging的频率'verbose': 0 # 不显示训练过程中的输出信息
}lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)# 4. 训练模型
gbm = lgb.train(params,lgb_train,num_boost_round=100, # 迭代次数valid_sets=lgb_eval,early_stopping_rounds=10) # 当验证集的性能不再提升时停止训练# 5. 预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)# 将预测概率转换为类别
y_pred_binary = [1 if pred > 0.5 else 0 for pred in y_pred]# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred_binary)
print(f'Accuracy: {accuracy}')# 可选步骤:特征重要性分析
# gbm.feature_importance() 可以获取特征重要性完整代码
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 从 lightgbm 模块中导入 LGBMClassifier 类
from lightgbm import LGBMClassifier# 2. 读取训练集和测试集
# 使用 read_excel() 函数从文件中读取训练集数据,文件名为 'traindata-new.xlsx'
train = pd.read_excel('./data/data280993/traindata-new.xlsx')
# 使用 read_excel() 函数从文件中读取测试集数据,文件名为 'testdata-new.xlsx'
test = pd.read_excel('./data/data280993/testdata-new.xlsx')# 3 特征工程
# 3.1 test数据不包含 DC50 (nM) 和 Dmax (%),将train数据中的DC50 (nM) 和 Dmax (%)删除
train = train.drop(['DC50 (nM)', 'Dmax (%)'], axis=1)# 3.2 将object类型的数据进行目标编码处理
for col in train.columns[2:]:if train[col].dtype == object or test[col].dtype == object:train[col] = train[col].isnull()test[col] = test[col].isnull()# 4. 加载决策树模型进行训练
model = LGBMClassifier(verbosity=-1)
model.fit(train.iloc[:, 2:].values, train['Label'])
pred = model.predict(test.iloc[:, 1:].values, )# 5. 保存结果文件到本地
pd.DataFrame({'uuid': test['uuid'],'Label': pred}
).to_csv('submit.csv', index=None)
model = LGBMClassifier(verbosity=-1)
model.fit(train.iloc[:, 2:].values, train['Label'])
pred = model.predict(test.iloc[:, 1:].values, )#1. `LGBMClassifier(verbosity=-1)` 创建了一个 LightGBM 分类模型,并设置了 `verbosity=-1`,表示禁止输出训练过程中的信息。#2. `model.fit(train.iloc[:, 2:].values, train['Label'])` 使用训练集 `train` 的特征列(从第三列开始,即 `train.iloc[:, 2:]`)和标签列(`train['Label']`)来训练模型。#3. `pred = model.predict(test.iloc[:, 1:].values)` 对测试集 `test` 的特征列(从第二列开始,即 `test.iloc[:, 1:]`)进行预测,并将预测结果存储在 `pred` 变量中。所以,这段代码的作用是利用 LightGBM 模型对测试集进行预测,并且假设测试集中的特征列是从第二列开始(因为使用了 `test.iloc[:, 1:]`)。相关文章:
零基础入门 Ai 数据挖掘竞赛-速通 Baseline-1
#AI夏令营 #Datawhale #夏令营 本项目为Datawhale 2024 年 AI 夏令营赛事,零基础入门 AI 数据挖掘竞赛-速通学习手册配套的代码项目。 项目链接:https://aistudio.baidu.com/bd-cpu-02/user/2961857/8113198/home#codelab 任务目标 根据给的test&…...
(Python))
第二十六章 生成器(generator)(Python)
文章目录 前言一、生成器函数 前言 在 Python 中,使用了 yield 的函数被称为生成器(generator) yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值ÿ…...

Vue通过Key管理状态
Vue通过Key管理状态 Vue 默认按照“就地更新”的策略来更新,通过 v-for 渲染的元素列表。当数据项的顺序改变时,Vue 不会随之移动 DOM 元素的顺序,而是就地更新每个元素,确保它们在原本指定的索引位置上渲染。为了给 Vue 一个提示…...
鸿蒙 HarmonyOs 网络请求 快速入门
官方文档: ArkUI简介-ArkUI(方舟UI框架)-应用框架 | 华为开发者联盟 (huawei.com) 一、通过原有的http组件进行网络请求(方式一) 1.1 HttpRequestOptions的操作 名称类型描述methodRequestMethod请求方式ÿ…...

Kubernetes云原生存储解决方案openebs部署实践-4.0.1版本(helm部署)
Kubernetes云原生存储解决方案openebs部署实践-4.0.1版本(helm部署) 简介 OpenEBS 是一种开源云原生存储解决方案。OpenEBS 可以将 Kubernetes 工作节点可用的任何存储转化为本地或复制的 Kubernetes 持久卷。OpenEBS 帮助应用和平台团队轻松地部署需要…...

如何使用Pip生成requirements.txt文件:全面指南与实践示例
如何使用Pip生成requirements.txt文件:全面指南与实践示例 Python的包管理工具Pip是Python开发中不可或缺的一部分。它不仅可以帮助我们安装和管理Python包,还可以通过生成requirements.txt文件来记录项目所需的所有依赖。本文将详细介绍如何使用Pip生成…...
微信小程序消息通知(一次订阅)
在微信公众平台配置通知模版 通过wx.login获取code发送给后端 let that this // 登陆codewx.login({success: function (res) {if (res.code) {// 发送code到后端换取openid和session_keythat.setData({openCode: res.code})console.log(that.data.openCode, openCode);// 调…...

电传动无杆飞机牵引车交付用户
自2019年起,我们计划做电传动控制,先后做了电传动水泥搅拌罐车罐体控制(国内首创),初步理解了电机控制的特点。 20-21年接着做了10t飞机牵引车控制,还是电液控制联合的,把越野叉车的行驶控制方…...
react框架,使用vite和nextjs构建react项目
react框架 React 是一个用于构建用户界面(UI)的 JavaScript 库,它的本质作用是使用js动态的构建html页面,react的设计初衷就是为了更方便快捷的构建页面,官方并没有规定如何进行路由和数据获取,要构建一个完整的react项目,我们需要…...

Games101学习笔记 Lecture16 Ray Tracing 4 (Monte Carlo Path Tracing)
Lecture16 Ray Tracing 4 (Monte Carlo Path Tracing 一、蒙特卡洛积分 Monte Carlo Integration二、路径追踪 Path tracing1.Whitted-Style Ray Tracings Problems2.只考虑直接光照时3.考虑全局光照①考虑物体的反射光②俄罗斯轮盘赌 RR (得到正确shade函数&#x…...
数据结构概念
文章目录 1. 概念 2. 数据结构和算法的关系 3. 内存 4. 数据的逻辑结构 5. 数据的存储结构 1. 顺序存储结构 2. 链式存储结构 3. 索引存储结构 4. 散列存储结构 6. 数据的运算 1. 概念 定义1(宏观): 数据结构是为了高效访问数据而…...
Windows 下载安装ffmpeg
下载地址 https://ffmpeg.org/download.html 测试 管理员方式打开控制台,输入ffmpeg测试 配置环境变量...

Java AI 编程助手
Java AI 编程助手是指利用人工智能技术来增强和优化Java开发过程中的各种任务和活动。它可以涵盖从代码生成和分析到测试和优化的多个方面,帮助开发人员提高生产效率、降低错误率,并优化代码质量和性能。 ### 功能和特点 1. **智能代码生成和建议**&am…...

day10:01集合
1 作用 Python中的集合(Set)是一个无序的、不包含重复元素的容器。它主要用于去重、成员测试、以及执行数学上的集合运算(如并集、交集、差集和对称差集)等操作。集合的内部实现通常基于哈希表,这提供了快速的成员测试…...

03浅谈提示工程、RAG和微调
03浅谈提示工程、RAG和微调 提示词Prompt Prompt(提示词)是指在使用大模型时,向模型提供的一些指令或问题。这些指令作为模型的输入,引导模型产生所需要的输出。例如,在生成文本时,Prompt可能是一个问题或…...

硅纪元视角 | AI纳米机器人突破癌症治疗,精准打击肿瘤细胞
在数字化浪潮的推动下,人工智能(AI)正成为塑造未来的关键力量。硅纪元视角栏目紧跟AI科技的最新发展,捕捉行业动态;提供深入的新闻解读,助您洞悉技术背后的逻辑;汇聚行业专家的见解,…...

刷代码随想录有感(125):动态规划——最长公共子序列
题干: 代码: class Solution { public:int longestCommonSubsequence(string text1, string text2) {vector<vector<int>>dp(text1.size() 1, vector<int>(text2.size() 1, 0));for(int i 1; i < text1.size(); i){for(int j …...

Linux和mysql中的基础知识
cpu读取的指令大部分在内存中(不考虑缓存) 任何程序在运行之前都的加入到内存。 eip->pc指针,指明当前指令在什么位置。 代码大概率是从上往下执行的,基于这样的基本理论。既可以将一部分指令加载到CPU对应的缓存中…...
编辑 12 编辑模版)
ArcGIS Pro SDK (七)编辑 12 编辑模版
ArcGIS Pro SDK (七)编辑 12 编辑模版 文章目录 ArcGIS Pro SDK (七)编辑 12 编辑模版1 在图层上按名称查找编辑模板2 查找属于独立表的表模板3 当前模板4 更改模板的默认编辑工具5 隐藏或显示模板上的编辑工具6 使用图层创建新模…...
)
数据结构底层之HashMap(面经篇1)
1 . 讲一下hashmap的数据结构 HashMap是一种基于哈希表实现的数据结构,通常用于关联键值对,其中键是唯一的,而值可以重复。在Java中,HashMap是java.util.Map接口的一个实现,它提供了快速的查找、插入和删除操作。 数据…...

匿名内部类的使用场景 java反射机制
一、匿名内部类的使用场景匿名内部类是一种没有显式类名、直接在创建对象时定义并实例化的内部类。它通常用于“一次性使用”的场景,让代码更简洁紧凑。主要使用场景包括:1. 事件监听器(GUI 编程)在 Swing、AWT 或 Android 开发中…...

图机器学习在农药生态毒性预测中的应用与挑战
1. 项目概述:当图机器学习遇见农药设计农药,这个听起来有些“硬核”的词汇,其实是我们现代农业的基石。从除草剂到杀虫剂,它们守护着全球的粮食安全。但硬币的另一面是,农药的生态毒性问题日益凸显,尤其是对…...

QQ音乐加密音频一键解密:qmc-decoder让你的音乐重获自由 [特殊字符]
QQ音乐加密音频一键解密:qmc-decoder让你的音乐重获自由 🎵 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾有这样的经历?从QQ音…...

总结模式的智能化升级
📋 本文目录 一、前言 二、从工具到智能系统的升级 三、工具链完整演示 四、智能总结Agent整合实战 五、智能总结系统的核心价值 六、总结与展望 一、前言 1.1 本节内容简介 我们已经有了5个好用的总结工具,但问题来了:工具是死的&am…...

C++ 智能指针简介
文章目录1.由来2.基本思想3.引用计数4.实现模板参考文献1.由来 C 动态内存管理是通过一对运算符来完成的,new 用于申请内存空间,调用对象构造函数初始化对象并返回指向该对象的指针。delete 接收一个动态对象的指针,调用对象的析构函数销毁对…...

Graph Fusion:一张 512 节点的图怎么压到 120 个以内
Operator Fusion 解决单点算子合并,Graph Fusion 在更大范围做整图级别的融合。GE 图引擎收到 ATC 编译好的图后,不是直接拿去执行——它先跑一遍图优化流水线,常量折叠、算子替换、模式匹配、Buffer 复用,把几百个节点的"散…...

网络技术05-TCP拥塞控制算法——从CUBIC到BBR的性能进化
🚗 一句话总结:TCP拥塞控制就像开车——看到前面堵车就减速(拥塞避免),路通畅了就慢慢加速(慢启动)。CUBIC是"看到堵车就猛踩刹车",BBR是"根据路况预测提前调整"…...

通过Hermes Agent对接Taotoken自定义模型提供方
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Hermes Agent对接Taotoken自定义模型提供方 Hermes Agent是一个流行的AI Agent开发框架,它支持通过统一的接口调用…...

3分钟解锁微信网页版:wechat-need-web插件让你的浏览器变身全能微信客户端
3分钟解锁微信网页版:wechat-need-web插件让你的浏览器变身全能微信客户端 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为工作电脑…...

卖轴承怎么找客户?下游工厂在哪里
卖轴承找客户,本质是找用轴承的下游工厂,核心难点是拿到这些下游厂的名单和联系人。轴承是机械传动的通用基础件,消耗量大、采购频繁,但下游行业分散、各自聚集在不同产业带,如果没有系统盘过下游版图,销售…...