高职人工智能专业实训课之“生成对抗网络(GAN)”
一、前言
生成对抗网络(GAN)作为人工智能领域的一项重要技术,已经在图像生成、风格迁移、数据增强等多个领域展现出巨大的潜力和应用价值。为了满足高职院校对GAN专业实训课程的需求,唯众人工智能教学实训凭借其前沿的教育技术平台,特别是GPU虚拟化技术,为学生提供了高效、便捷的GAN实训环境。

二、GPU虚拟化技术
在GAN的实训中,计算资源的高效利用和分配是关键。唯众人工智能教学实训通过GPU虚拟化技术,实现了GPU资源的高效分配和管理,确保每位学生都能获得足够的算力支持,进行GAN模型的训练和测试。这使得学生在进行图像生成、风格迁移等GAN任务时,能够享受到流畅、高效的计算体验,从而提高实训效果,为实践和创新提供更多可能。
三、实训课程亮点
生成对抗网络(GAN)实训课程
• 丰富的实训资源:唯众人工智能教学实训提供了各种GAN相关的数据集、深度学习框架以及完善的实验环境,确保学生能够在最佳的学习环境中进行实训。
• GPU虚拟化支持:通过GPU虚拟化技术,学生可以在实训课程中充分利用GPU资源,提高GAN模型的训练效率,从而更加深入地理解和掌握GAN技术。
• 实践与创新:学生可以在唯众人工智能教学实训的实训环境中自由探索和学习,通过实践不断提高自己的GAN技能和能力,为未来的职业发展奠定坚实的基础。
四、代码示例
以下是唯众人工智能教学实训上生成对抗网络(GAN)实训课程中的一个示例,展示了如何使用PyTorch框架和GPU虚拟化技术进行GAN模型的训练:
(1)导入必要的库
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.autograd.variable import Variable # 检查CUDA是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 超参数
image_size = 28
batch_size = 64
num_epochs = 50
learning_rate = 0.0002 (2)加载MNIST数据集
transform = transforms.Compose([ transforms.Resize(image_size), transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))
]) dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True) (3)定义生成器和判别器
class Generator(nn.Module): def __init__(self, latent_dim=64, img_shape=(1, 28, 28)): super(Generator, self).__init__() self.img_shape = img_shape def block(in_feat, out_feat, normalize=True): layers = [nn.Linear(in_feat, out_feat)] if normalize: layers.append(nn.BatchNorm1d(out_feat, 0.8)) layers.append(nn.LeakyReLU(0.2, inplace=True)) return layers self.model = nn.Sequential( *block(latent_dim, 128, normalize=False), *block(128, 256), *block(256, 512), *block(512, 1024), nn.Linear(1024, int(np.prod(img_shape))), nn.Tanh() ) def forward(self, z): img = self.model(z) img = img.view(img.size(0), *self.img_shape) return img class Discriminator(nn.Module): def __init__(self, img_shape=(1, 28, 28)): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Linear(int(np.prod(img_shape)), 512), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 1), nn.Sigmoid(), ) def forward(self, img): img_flat = img.view(img.size(0), -1) validity = self.model(img_flat) return validity (4)实例化生成器和判别器,并移动到GPU
generator = Generator().to(device)
discriminator = Discriminator().to(device) (5)定义优化器
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate) # 定义损失函数(通常使用二元交叉熵损失)
criterion = nn.BCELoss() (6)训练循环
for epoch in range(num_epochs): for i, (real_images, _) in enumerate(dataloader): # 转换为GPU张量 real_images = real_images.to(device) # --------------------- # 训练判别器 # --------------------- # 将真实图像标签设为1,伪造图像标签设为0 real_labels = torch.ones(batch_size, 1).to(device) fake_labels = torch.zeros(batch_size, 1).to(device) # 真实图像通过判别器outputs = discriminator(real_images) d_loss_real = criterion(outputs, real_labels) real_scores = outputs # 生成伪造图像noise = torch.randn(batch_size, latent_dim).to(device) fake_images = generator(noise)# 伪造图像通过判别器 outputs = discriminator(fake_images.detach()) # detach防止梯度回传到生成器 d_loss_fake = criterion(outputs, fake_labels) fake_scores = outputs # 判别器总损失 d_loss = d_loss_real + d_loss_fake # 反向传播和优化 optimizer_D.zero_grad() d_loss.backward() optimizer_D.step() # --------------------- # 训练生成器 # --------------------- # 伪造图像和真实标签再次通过判别器 outputs = discriminator(fake_images) # 生成器损失(即希望判别器对伪造图像的预测接近真实标签1)g_loss = criterion(outputs, real_labels)# 反向传播和优化 optimizer_G.zero_grad() g_loss.backward() optimizer_G.step() # 打印统计信息 print(f'[{epoch+1}/{num_epochs}][{i+1}/{len(dataloader)}] Loss_D: {d_loss.item()}, Loss_G: {g_loss.item()}, D(x): {real_scores.mean().item()}, D(G(z)): {fake_scores.mean().item()}')(7)保存模型
# 保存Generator模型
torch.save(generator.state_dict(), 'generator_model.pth')
print('Generator model saved!') # 保存Discriminator模型
torch.save(discriminator.state_dict(), 'discriminator_model.pth')
print('Discriminator model saved!')(8)加载模型
# 加载Generator模型
generator = Generator() # 实例化一个新的Generator模型
generator.load_state_dict(torch.load('generator_model.pth'))
generator.eval() # 设置模型为评估模式
print('Generator model loaded!') # 加载Discriminator模型
discriminator = Discriminator() # 实例化一个新的Discriminator模型
discriminator.load_state_dict(torch.load('discriminator_model.pth'))
discriminator.eval() # 设置模型为评估模式
print('Discriminator model loaded!')五、总结
唯众人工智能教学实训凭借其前沿的GPU虚拟化技术,为高职生成对抗网络(GAN)实训课程提供了强有力的支持。在实训课程中,学生不仅能够获得丰富的实训资源和技术支持,还能在GPU虚拟化技术的助力下,享受到流畅、高效的计算体验。
相关文章:
高职人工智能专业实训课之“生成对抗网络(GAN)”
一、前言 生成对抗网络(GAN)作为人工智能领域的一项重要技术,已经在图像生成、风格迁移、数据增强等多个领域展现出巨大的潜力和应用价值。为了满足高职院校对GAN专业实训课程的需求,唯众人工智能教学实训凭借其前沿的教育技术平…...

【MySQL系列】隐式转换
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

亿发:信息化建设or面子工程?究竟什么才是真正的信息化解决方案
在现代企业的竞争中,信息化建设扮演着越来越重要的角色。信息化技术不仅是企业提升管理效率、优化运营模式的利器,更是企业在市场竞争中脱颖而出的关键。然而,许多企业在推进信息化的过程中,往往容易陷入“面子工程”的误区。那么…...

【微信小程序开发实战项目】——如何制作一个属于自己的花店微信小程序(1)
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...

树形结构C语言的实现
一.什么是树: 树形结构是一层次的嵌套结构。一个树形结构的外层和内层有相似的结构,所以这种结构多可以递归的表示。经典数据结构中的各种树状图是一种典型的树形结构:一棵树可以简单的表示为根,左子树,右子树。左子树…...

小程序渗透测试的两种方法——burpsuite、yakit
首先呢主要是配置proxifier,找到小程序的流量,然后使用burpsuite或者yakit去抓包。 一、使用burpsuiteproxifier的抓包测试 1、先配置proxifier,开启http流量转发 勾选确定 2、配置burp对应代理端口,选择profile,点…...

代码随想录训练营Day56
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、搜索插入位置二、在排序数组中查找元素的第一个和最后一个位置 前言 提示:这里可以添加本文要记录的大概内容: 今天是跟着代码随想…...

S32K3 工具篇4:如何在S32DS中使用lauterbach下载
S32K3 工具篇4:如何在S32DS中使用lauterbach下载 1. TRACE32软件下载与配置2. 如何在S32DS里面构建劳德巴赫的接口2.1 新建工程带有lauterbach2.2 已有工程没有lauterbach 劳德巴赫lauterbach是一款非常经典强悍的调试器,还带有trace功能,在汽…...
深度神经网络语言识别
「AI秘籍」系列课程: 人工智能应用数学基础人工智能Python基础人工智能基础核心知识人工智能BI核心知识人工智能CV核心知识 使用 DNN 和字符 n-gram 对一段文本的语言进行分类(附 Python 代码) 资料来源,flaticon:htt…...
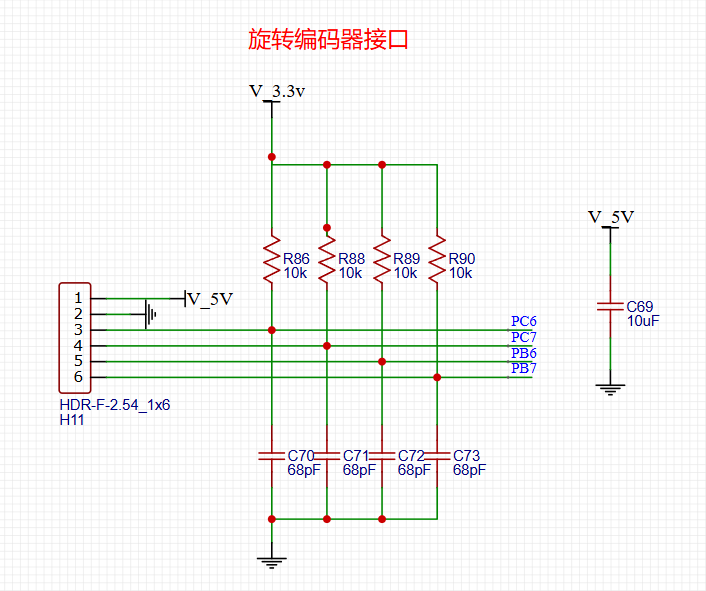
STM32自己从零开始实操07:电机电路原理图
一、LC滤波电路 其实以下的滤波都可以叫低通滤波器。 1.1倒 “L” 型 LC 滤波电路 1.1.1定性分析 1.1.2仿真实验 电感:通低频阻高频的。仿真中高频信号通过电感,因为电感会阻止电流发生变化,故说阻止高频信号 电容:隔直通交。…...
网页计算器的实现
简介 该项目实现了一个功能完备、交互友好的网页计算器应用。只使用了 HTML、CSS 和 JavaScript ,用于检验web前端基础水平。 开发环境:Visual Studio Code开发工具:HTML5、CSS3、JavaScript实现效果 功能设计和模块划分 显示模块&#…...

JAVA设计模式-监听者模式
什么是监听者模式 监听器模式是一种观察者模式的扩展,也被称为发布-订阅模式。在监听器模式中,存在两类角色:事件源(Event Source)和监听器(Listener)。事件源负责产生事件,而监听器…...
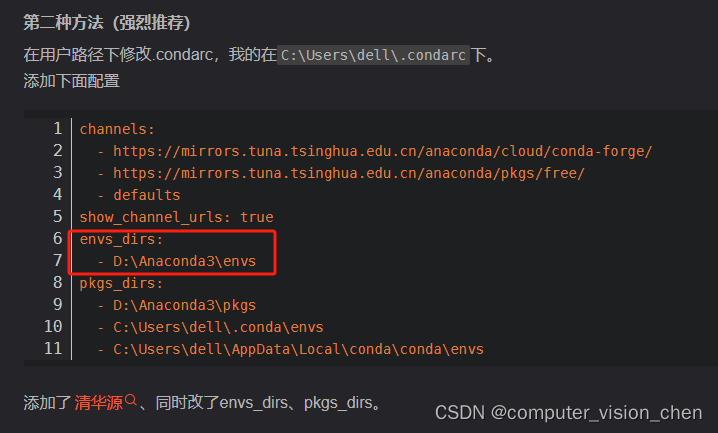
anaconda命令大全
目录 查看所有虚拟环境查看某虚拟环境安装的包创建虚拟环境激活创建好的虚拟环境回到之前的环境删除创建的虚拟环境查看conda所在的位置、虚拟环境位置等信息conda修改虚拟环境所在的位置 查看所有虚拟环境 conda env list查看某虚拟环境安装的包 激活要查看的虚拟环境之后&a…...

“论单元测试方法及应用”写作框架,软考高级论文,系统架构设计师论文
论文真题 1、概要叙述你参与管理和开发的软件项目,以吸你所担的主要工作。 2、结给你参与管理和开发的软件项目,简要叙述单元测试中静态测试和动态测试方法的基本内容。 3、结给你惨与管理和研发的软件项目,体阐述在玩测试过程中,如何确定白盒测试的覆盖标准,及如…...
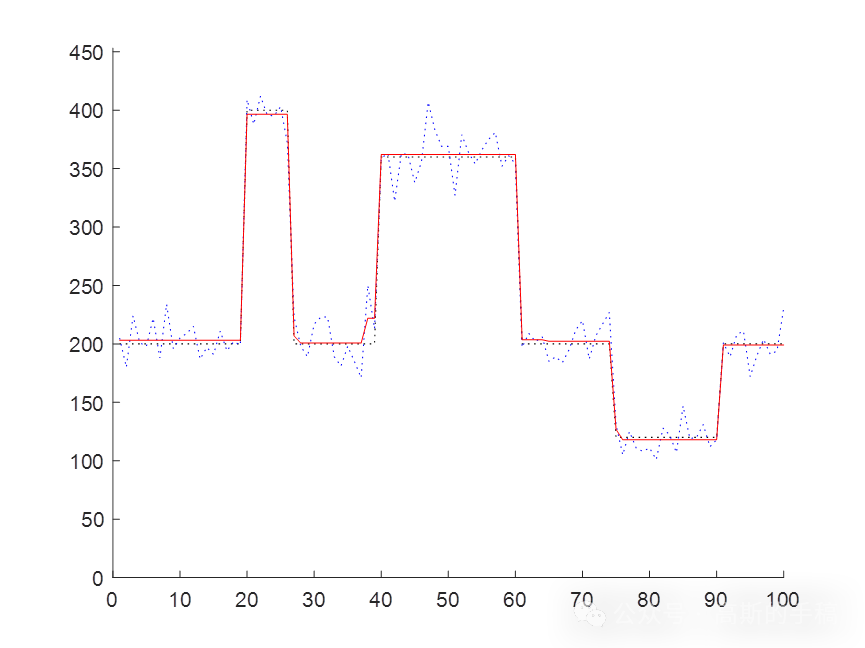
基于布雷格曼偏差校正技术的全变分一维时间序列信号降噪方法(MATLAB R2018A)
信号降噪是信号处理的重要步骤之一,目的是提高所获得信号数据的质量,以达到更高的定性和定量分析精度。信号降噪能提升信号处理其他环节的性能和人们对信息识别的准确率,给信号处理工作提供更可靠的保证。信号降噪的难点是降低噪声的同时也会…...

【CentOS 7.6】Linux版本 portainer本地镜像导入docker安装配置教程,不需要魔法拉取!(找不着镜像的来看我)
吐槽 我本来根本不想写这篇博客,但我很不解也有点生气,CSDN这么大没有人把现在需要魔法才能拉取的镜像放上来。 你们都不放,根本不方便。我来上传资源。 portainer-ce-latest.tar Linux/amd64 镜像下载地址: 链接:h…...

【windows|012】光猫、路由器、交换机详解
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社…...
Node之Web服务
前言 本文将讲解node的web服务 通过讲解http请求,node创建web服务等知识点让你更加深入的理解web服务和node创建的web服务 HTTP请求是什么? HTTP请求是客户端(通常是浏览器或其他应用程序)与服务器之间进行通信的一种方式。 …...

[Day 24] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
AI在自動駕駛中的應用 1. 簡介 自動駕駛技術是現代交通領域的一個革命性進展。通過結合人工智能(AI)、機器學習(ML)、深度學習(DL)和傳感器技術,自動駕駛汽車可以在無人干預的情況下安全駕駛。…...

计算机图形学入门25:BRDF的测量
1.前言 BRDF(双向反射分布函数)可以用各种各样的材质去描述,但是这只是一种基于物理的描述或者近似,那什么是真正的BRDF?只有测出来的才是真正的。 为什么要测出BRDF?因为之前所描述的BRDF并不准确。如下图所示,以菲涅…...

为什么有些论文,答辩老师越听越不敢卡?
很多学生都经历过一种很明显的反差。有些同学一进答辩室, 老师状态特别紧。问题一个接一个; 追问不断; 语气越来越严肃。但还有一种情况。有些同学刚讲几分钟, 现场气氛就明显变了。老师开始点头; 追问越来越少&#x…...

类和对象概括
类与对象的概念在Java中,类是对象的模板或蓝图,定义了对象的属性和行为。对象是类的实例,具有类定义的属性和方法。类的定义类通过class关键字定义,包含成员变量(属性)和方法(行为)。…...

【Midjourney饱和度调控黄金法则】:20年AI视觉调校专家亲授3类典型过曝/灰暗场景的7步精准校正流程
更多请点击: https://codechina.net 第一章:Midjourney饱和度调控的核心原理与认知重构 Midjourney 的饱和度(Saturation)并非独立控制的图像参数,而是嵌套于其隐式色彩空间映射与扩散过程中的动态响应变量。它由模型…...
)
AI知识管理不是工具升级,而是教学主权重构:一位特级教师用18个月完成“教案→知识流→认知干预”三级跃迁(全程数据脱敏实录)
更多请点击: https://intelliparadigm.com 第一章:AI知识管理在教育领域的应用 AI知识管理正深刻重塑教育生态,通过智能索引、语义理解与个性化推荐,将碎片化教学资源转化为可检索、可推理、可演化的结构化知识网络。教师可借助自…...

ML模型监控工具:监控和维护机器学习模型的性能
ML模型监控工具:监控和维护机器学习模型的性能 一、ML模型监控工具概述 1.1 ML模型监控工具的定义 ML模型监控工具是指用于监控和维护机器学习模型性能的软件工具。它通过收集模型的预测数据、性能指标和数据质量,帮助用户了解模型的状态,及时…...

【限时解密】Claude 3.5 Sonnet专属编程模式:仅开放给前500家企业的上下文感知补全协议
更多请点击: https://kaifayun.com 第一章:Claude 3.5 Sonnet编程辅助的核心能力边界与适用场景 Claude 3.5 Sonnet 在编程辅助领域展现出显著的推理深度与上下文理解能力,但其本质仍是基于大规模语言模型的生成式系统,不具备实时…...

深度强化学习与控制2026 课程总结Week2
深度Q网络——DQN算法流程: (1) 初始化网络参数 (2) 初始化网络参数 (3) 初始化经验回放池R (4) 进入循环迭代训练:for 序列 do获取初始状态for 时间步 do 根据以贪婪策略选择动作,获得,存入经验回放池R若R中数据充足,从R中采样…...

2025大厂Java后端面试:RAG高频考点【干货】
根据近期(2025-2026年)牛客网上字节、腾讯、阿里、快手、京东等大厂的Java后端面经,RAG(检索增强生成)已高频结合传统Java八股进行考察。📚 面试问题分类与总结1. 🏗️ RAG 基础概念与理解这是面…...

终极AMD Ryzen调试工具:SMUDebugTool完全使用指南
终极AMD Ryzen调试工具:SMUDebugTool完全使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...

突破性升级:Windows Package Manager 1.8让软件管理效率提升300%
突破性升级:Windows Package Manager 1.8让软件管理效率提升300% 【免费下载链接】winget-cli WinGet is the Windows Package Manager. This project includes a CLI (Command Line Interface), PowerShell modules, and a COM (Component Object Model) API (Appl…...