CVPR2024自动驾驶轨迹预测方向的论文整理
2024年自动驾驶轨迹预测方向的论文汇总
1、Producing and Leveraging Online Map Uncertainty in Trajectory Prediction
论文地址:https://arxiv.org/pdf/2403.16439
提出针对在线地图不确定性带给轨迹预测的影响对应的解决方案。
在轨迹预测中,利用在线地图不确定性是一个重要的课题。随着位置数据的增加和地图更新的频率加快,准确地处理这些不确定性变得至关重要。以下是一些关键步骤:
- 收集数据:首先,需要收集大量的位置数据,并确保这些数据来自可靠的来源。
- 构建地图模型:使用收集到的数据来构建地图模型。这可能涉及到使用机器学习算法来识别模式并生成预测。
- 处理不确定性:考虑到地图更新的频率,必须考虑如何处理不确定性。一种方法是使用概率分布来表示每个位置点的不确定性。
- 集成实时更新:为了保持准确性,需要将实时更新集成到模型中。这可以通过定期更新地图模型来实现。
- 评估性能:最后,对模型进行评估以确保其在实际应用中的有效性。可以使用各种指标来衡量模型的性能,例如平均绝对误差(MAE)或均方根误差(RMSE)。
通过这些步骤,我们可以有效地利用在线地图的不确定性来提高轨迹预测的准确性。
2、CaDeT: a Causal Disentanglement Approach for Robust Trajectory Prediction in Autonomous Driving
论文:https://openaccess.thecvf.com/content/CVPR2024/papers/Pourkeshavarz_CaDeT_a_Causal_Disentanglement_Approach_for_Robust_Trajectory_Prediction_in_CVPR_2024_paper.pdf
CaDeT的核心思想是通过因果分解来分离出环境因素对轨迹预测的影响,并将其从预测模型中剔除从而训练一个自动适应新环境的轨迹预测模型。
实验数据集:AV2,无代码公开
3、Adapting to Length Shift: FlexiLength Network for Trajectory Prediction
论文:https://arxiv.org/pdf/2404.00742
篇论文主要关注的是如何解决轨迹预测任务中长度变化的问题,通过引入一个长度控制模块来实现的,该模块可以根据输入轨迹的长度动态地生成一个长度向量,用于指导后续的预测过程。
数据集:nuScenes, AV1,base model:HiVT,下图为HiVT使用了他的方案后的涨点:

4、HPNet: Dynamic Trajectory Forecasting with Historical Prediction Attention
论文地址:https://arxiv.org/pdf/2404.06351
代码地址:https://github.com/XiaolongTang23/HPNet
该论文介绍了一种名为 HPNet 的新方法,它利用历史预测注意力来提高轨迹预测的准确性。传统的轨迹预测模型通常只考虑当前时刻的环境信息,而忽视了之前预测的历史信息。然而,HPNet 引入了一个历史预测注意力机制,使得模型能够更好地利用先前的预测结果来指导后续的预测过程。
具体来说,HPNet 包含以下几个关键步骤:首先,需要收集大量的位置数据,并确保这些数据来自可靠的来源。其次使用收集到的数据来训练一个能够产生更准确预测的模型。在这个过程中,引入历史预测注意力机制。
然后使用历史预测注意力机制来训练模型,使其能够更好地利用先前的预测结果来指导后续的预测过程。最后,对模型进行评估以确保其在实际应用中的有效性。可以使用各种指标来衡量模型的性能,例如平均绝对误差(MAE)或均方根误差(RMSE)。通过这些步骤,HPNet 提供了一种新的方法来提高动态轨迹预测的准确性和鲁棒性。
实验数据集:Argoverse1
代码地址:https://github.com/XiaolongTang23/HPNet
论文地址:https://arxiv.org/pdf/2404.06351
实验结果:数据集:AV1

5、DAMM:Density-Adaptive Model Based on Motif Matrix for Multi-Agent Trajectory Prediction
论文地址:https://openaccess.thecvf.com/content/CVPR2024/papers/Wen_Density-Adaptive_Model_Based_on_Motif_Matrix_for_Multi-Agent_Trajectory_Prediction_CVPR_2024_paper.pdf
技术文档:https://openaccess.thecvf.com/content/CVPR2024/supplemental/Wen_Density-Adaptive_Model_Based_CVPR_2024_supplemental.pdf
实验数据集:nuScenes Argoverse
这篇论文主要探讨如何通过基于模式矩阵的密度自适应模型来实现多代理轨迹预测,模式矩阵是一种用于表示道路用户之间相互作用关系的数据结构, 它能够捕捉到不同道路用户之间的复杂交互行为,例如跟随、并行行驶等。DAM能够根据当前场景中的道路用户密度动态调整其内部参数,从而提高预测准确性。
6、MATRIX: Multi-Agent Trajectory Generation with Diverse Contexts
轨迹生成方向相关。该论文的主要思想是提出一种新的方法来生成具有丰富上下文信息的多智能体轨迹。
论文地址:https://arxiv.org/pdf/2403.06041v1
7、SeNeVA:Quantifying Uncertainty in Motion Prediction with Variational Bayesian Mixture
论文地址:https://arxiv.org/pdf/2404.03789
是一篇关于运动预测中不确定性度量的论文。该论文的主要思想是提出了一种基于变分贝叶斯混合模型(Variational Bayesian Mixture, VBM)的方法来量化运动预测中的不确定性。传统的运动预测方法往往假设预测结果是确定性的,即预测结果只有一个确定的值。然而,在实际应用中,我们经常需要面对各种不确定因素,比如传感器噪声、模型误差等,这些都会导致预测结果存在一定的不确定性。因此,准确地量化并表达这种不确定性对于运动预测系统的可靠性和安全性至关重要。
论文中提出的 VBM 方法通过引入贝叶斯统计学的思想,将预测结果视为由多个潜在状态组成的混合分布。每个潜在状态对应着一种可能的运动模式,而混合系数则反映了不同模式的概率大小。这样,我们就可以通过计算混合系数来衡量预测结果的不确定性。
具体来说,VBM 方法首先构建了一个包含多个潜在状态的混合模型,然后利用变分贝叶斯技术对模型参数进行优化。优化过程中,不仅考虑了数据的似然函数,还考虑了模型的复杂度惩罚项,以避免过度拟合。最终,通过分析混合系数的分布情况,我们可以得到一个概率分布图,直观地展示出预测结果的不确定性。
实验结果在多个数据集上验证(包括AV2),效果优于DenseTNT,Forecast-MAE
8、Continual Learning for Motion Prediction Model via Meta-Representation Learning and Optimal Memory Buffer Retention Strategy
论文地址:https://openaccess.thecvf.com/content/CVPR2024/papers/Kang_Continual_Learning_for_Motion_Prediction_Model_via_Meta-Representation_Learning_and_CVPR_2024_paper.pdf
实验数据集:nuScenes
该论文的主要思想是提出了一种结合元表示学习和最优记忆缓冲区保留策略的连续学习方法。
传统的运动预测模型通常假设训练数据集是静态不变的,然而在现实世界中,我们经常需要处理不断变化的数据流。这就要求我们的模型能够适应新的数据分布,同时保持对之前数据的有效记忆。因此,我们需要引入连续学习的概念,即在模型训练过程中,允许新数据的加入并更新模型参数,同时保留对之前数据的记忆。
9、SmartRefine: A Scenario-Adaptive Refinement Framework for Efficient Motion Prediction
论文:https://arxiv.org/pdf/2403.11492
代码:https://github.com/opendilab/SmartRefine/
论文解读:论文解读
该论文的主要思想是提出了一种场景自适应的精炼框架,通过分析当前的传感器数据或者历史数据,对当前所处的场景进行识别,针对不同的场景,选择最适合的预测策略,对于每个场景,采用不同的精炼算法来进一步优化预测结果。这些算法可以包括但不限于卡尔曼滤波、粒子滤波等,为了持续改进预测性能,论文还提出了一种反馈机制。即当新的数据到来时,不仅会更新当前的预测结果,还会将这些新数据加入到训练集中,用于后续的场景识别和策略选择。
模型框架:

实验结果:

10、Generalized Predictive Model for Autonomous Driving 框架级别 目前线上预测架构设计可以关注
论文:https://arxiv.org/pdf/2403.09630
数据集:kitti,waymo, nuScenes
该论文的主要思想是提出了一种通用的预测模型,旨在为自动驾驶系统提供更准确、可靠的预测能力。前期数据预处理,然后进入模型选择与训练:根据具体的预测任务,选择合适的预测模型进行训练。这些模型可以包括但不限于回归模型、分类模型、强化学习模型等。
集成学习:为了进一步提高预测性能,论文还提出了一种集成学习的方法。即将多个不同的预测模型组合起来,形成一个更为强大的整体模型。
11、Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations
论文地址:https://arxiv.org/pdf/2403.13261
无监督的方法,可解决标注数据没有或者很少的问题.
数据集:nuScenes
该论文的主要思想是提出了一种无监督的、类别的泛化能力更强的运动预测方法,并且通过空间和时间一致性正则化来进一步提升预测精度。
数据增强:首先,通过对原始数据进行随机变换(如旋转、平移、缩放等),生成一系列的伪标签数据。
预测模型训练:然后,使用这些伪标签数据来训练一个运动预测模型。值得注意的是,这里的预测模型并不直接预测车辆的具体类别(如汽车、自行车等),而是预测车辆的运动状态(如位置、速度等)。
空间一致性正则化:为了保证预测结果在空间上的连续性,论文引入了空间一致性正则化。简单来说,就是要求相邻时刻的预测结果在空间上应该尽可能接近。
时间一致性正则化:同样地,为了保证预测结果在时间上的连续性,论文还引入了时间一致性正则化。即要求相邻时刻的预测结果在时间上也应该尽可能接近。
预测结果评估:最后,通过一些标准的评估指标(如均方误差、平均绝对误差等)来评估预测结果的质量。
12、MoST: Multi-Modality Scene Tokenization for Motion Prediction
论文:https://arxiv.org/pdf/2404.1953
端到端的,场景分块,运动预测,效果优于MultiPath++, MTR, 数据集:WOMD
该论文介绍了一种名为 MoST 的新方法,用于运动预测。
传统的运动预测模型往往只关注单个传感器的数据,而忽略了其他可用的信息源。MoST 则引入了多模态场景分割的概念,将来自多个传感器的数据整合起来,从而提高了预测的准确性。具体来说,MoST 包含以下几个关键步骤:
- 数据收集:首先,需要收集多种类型的传感器数据,例如摄像头图像、雷达点云等。
- 建立模型:使用收集到的数据来训练一个能够产生更准确预测的模型。在这个过程中,引入多模态场景分割的概念。
- 训练模型:使用多模态场景分割的概念来训练模型,使其能够更好地利用来自多个传感器的数据来指导运动预测。
-评估性能:最后,对模型进行评估以确保其在实际应用中的有效性。可以使用各种指标来衡量模型的性能,例如平均绝对误差(MAE)或均方根误差(RMSE)。
通过这些步骤,MoST 提供了一种新的方法来提高运动预测的准确性和鲁棒性。
相关文章:
CVPR2024自动驾驶轨迹预测方向的论文整理
2024年自动驾驶轨迹预测方向的论文汇总 1、Producing and Leveraging Online Map Uncertainty in Trajectory Prediction 论文地址:https://arxiv.org/pdf/2403.16439 提出针对在线地图不确定性带给轨迹预测的影响对应的解决方案。 在轨迹预测中,利用在…...
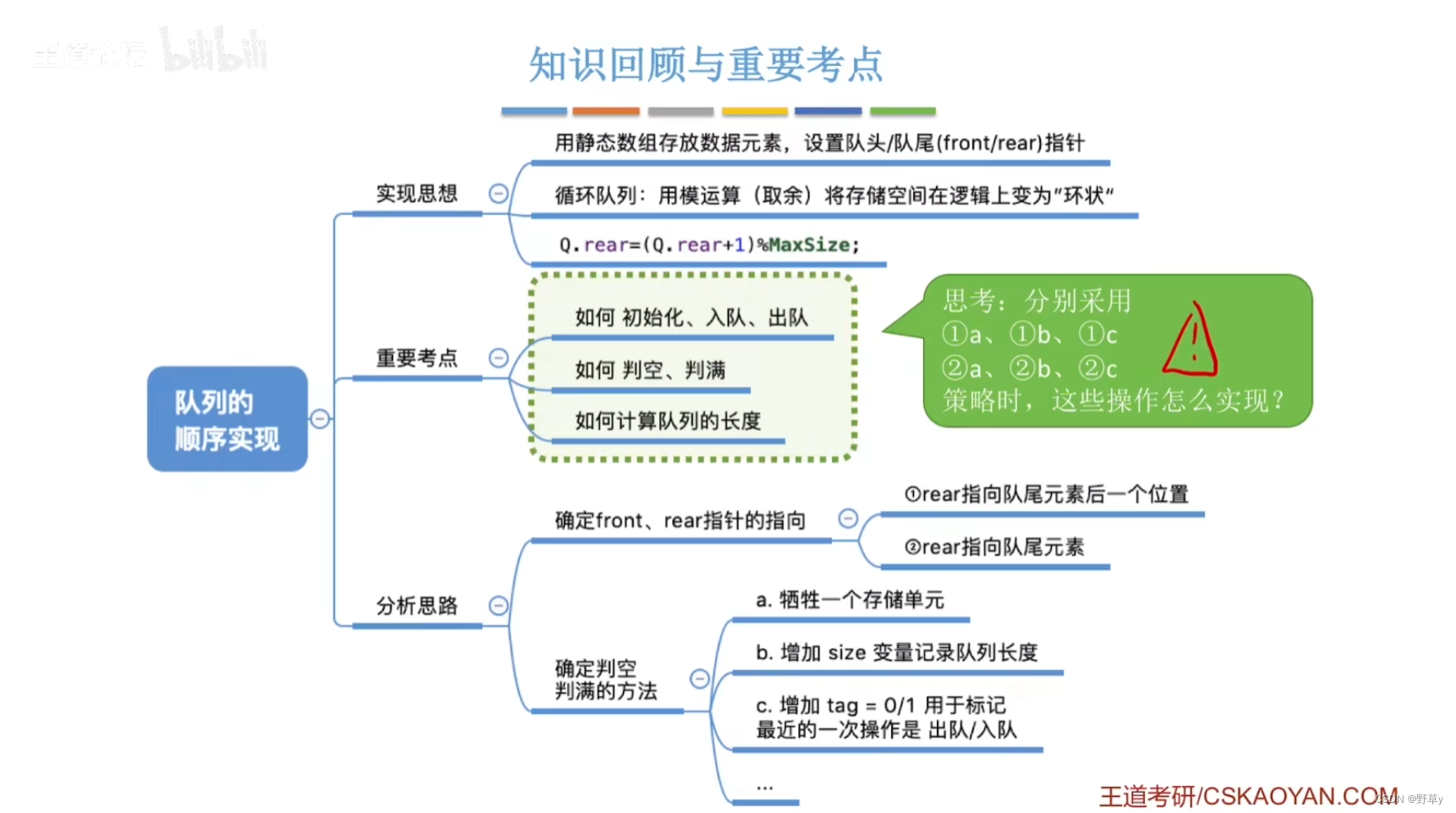
数据结构——队列练习题
在C语言中,.和->运算符用于访问结构体的成员变量。它们之间的区别在于:.运算符用于访问结构体变量的成员。->运算符用于访问结构体指针变量的成员 1a(rear指向队尾元素后一位,判空判满时牺牲一个存储单元) 首先…...

PLL和CDR的内部结构及其区别
比较PLL和CDR的内部结构及其区别: 基本结构: PLL(相位锁定环): 相位检测器环路滤波器压控振荡器(VCO)分频器(可选,用于频率合成) CDR(时钟数据恢复…...
HarmonyOS APP应用开发项目- MCA助手(Day02持续更新中~)
简言: gitee地址:https://gitee.com/whltaoin_admin/money-controller-app.git端云一体化开发在线文档:https://developer.huawei.com/consumer/cn/doc/harmonyos-guides-V5/agc-harmonyos-clouddev-view-0000001700053733-V5注:…...

华为交换机 LACP协议
华为交换机支持的LACP协议,即链路聚合控制协议,是一种基于IEEE 802.3ad标准的动态链路聚合与解聚合的协议。它允许设备根据自身配置自动形成聚合链路并启动聚合链路收发数据。 在LACP模式下,链路聚合组能够自动调整链路聚合,维护…...

node 下载文件到网络共享目录
1、登录网络共享计算器 2、登录进入后复制要存储文件的目录路径 例如: \\WIN-desktop\aa\bb\cc 3、node 下载后写入网络共享目录 注意(重要):在使用UNC路径时,请确保你正确转义了反斜杠(使用两个反斜杠来表示一个&…...

STM32基础知识
一.STM32概述 第一款STM32单片机发布的时间为2007年6月11日。由意法半导体(ST)公司推出,是STM32系列中的首款产品,具体型号为STM32F1,它是一款基于Cortex-M内核的32位微控制器(MCU)。 STM32F1…...

安装docker版rabbitmq 3.12
本文介绍在Ubuntu22中安装docker版rabbitmq 3.12。 一、拉取镜像 docker pull rabbitmq:3.12.14-management二、创建数据目录和docker-compose文件 创建目录: cd /root mkdir rabbitmq-docker cd rabbitmq-docker mkdir data chmod 777 data创建docker-compose配…...

c++重定向输出和输出(竞赛讲解)
1.命令行重定向 在命令行中指定输出文件 指令 .\重定向学习.exe > 1.txt 效果 命令行输入和输出 指令 .\重定向学习.exe < 2.txt > 1.txt 效果 代码 #include<bits/stdc++.h> using namespace std; int n; int main(){cin>>n;for(int i=0;i<n;i…...

实在智能对话钉钉:宜搭+实在Agent,AI时代的工作方式
比起一个需求需要等产品、技术排期,越来越多的人开始追求把自己武装成「全能战士」,通过低代码工具一搭,一个高效的工作平台便产生了。 宜搭是钉钉自研的低代码应用构建平台,无论是专业开发者还是没有代码基础的业务人员…...

MySQL的Docker部署方式
说明:Docker部署MySQL主要是简单快速,不会对电脑系统造成污染。假如你的本地没有Docker,或者你不会使用Docker,则使用PyCharm去启动MySQL,或者直接在本机安装MySQL都是可以的。最重要的是,你要有一个MySQL环境…...

光伏电站数据采集方案(基于工业路由器部署)
一、方案概述 本方案采用星创易联SR500工业路由器作为核心网关设备,实现对光伏电站现场数据的实时采集、安全传输和远程监控。SR500具备多接口、多功能、高可靠性等特点,能够满足光伏电站数据采集的各种需求。(key-iot.com/iotlist/sr500…...

一文让你彻底搞懂什么是CDN
一、引言 在当今互联网时代,网站的加载速度和稳定性是用户体验的关键因素之一。而CDN(Content Delivery Network,内容分发网络)作为提升网站性能的重要技术手段,受到了广泛的关注和应用。本篇博客将深入探讨CDN的工作…...

1023记录
米哈游二面 自动化测试中自动化驱动的能力? pytest的驱动能力: 1,自动发现测试用例:以"test_"开头的Python文件、以"Test"开头的类和以"test_"开头的函数,将它们识别为测试用例 2&…...

【并发编程JUC】AQS详解
定义理解 AQS,全称为AbstractQueuedSynchronizer,是Java并发包(java.util.concurrent)中的一个框架级别的工具类,用于构建锁和同步器。它是许多同步类的基础,如ReentrantLock、Semaphore、CountDownLatch等…...
如何找BMS算法、BMS软件的实习
之前一直忙,好久没有更新了,今天就来写一篇文章来介绍如何找BMS方向的实习,以及需要具备哪些条件,我的实习经历都是在读研阶段找的,读研期间两段的实习经历再加上最高影响因子9.4分的论文,我的秋招可以说是…...
AR视频技术与EasyDSS流媒体视频管理平台:打造沉浸式视频体验
随着增强现实(AR)技术的飞速发展,其在各个领域的应用日益广泛。这项技术通过实时计算摄影机影像的位置及角度,将虚拟信息叠加到真实世界中,为用户带来超越现实的感官体验。AR视频技术不仅极大地丰富了我们的视觉体验&a…...
- 逻辑回归)
每天一个数据分析题(三百九十九)- 逻辑回归
逻辑回归中,若选0.5作为阈值区分正负样本,其决策平面是( ) A. wxb= 0 B. wxb= 1 C. wxb= -1 D. wxb= 2 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点…...

【ARMv8/v9 GIC 系列 5.2 -- GIC 分组介绍:Group 0 |Group 1| Non-Secure Group 1】
请阅读【ARM GICv3/v4 实战学习 】 文章目录 GIC Interrupt grouping中断分组配置寄存器GIC 中断分组介绍Group 0(安全组0)Group 1(安全组1)Non-Secure Group 1(非安全组1)总结及例子GIC Interrupt grouping ARM GICv3 通过中断分组机制,与ARMv8异常模型和安全模型进行…...

前端代码规范 - 日志打印规范
在前端开发中,随着项目迭代升级,日志打印逐渐风格不一,合理的日志输出是监控应用状态、调试代码和跟踪用户行为的重要手段。一个好的日志系统能够帮助开发者快速定位问题,提高开发效率。本文将介绍如何在前端项目中制定日志输出规…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...