《数据仓库与数据挖掘》 总复习
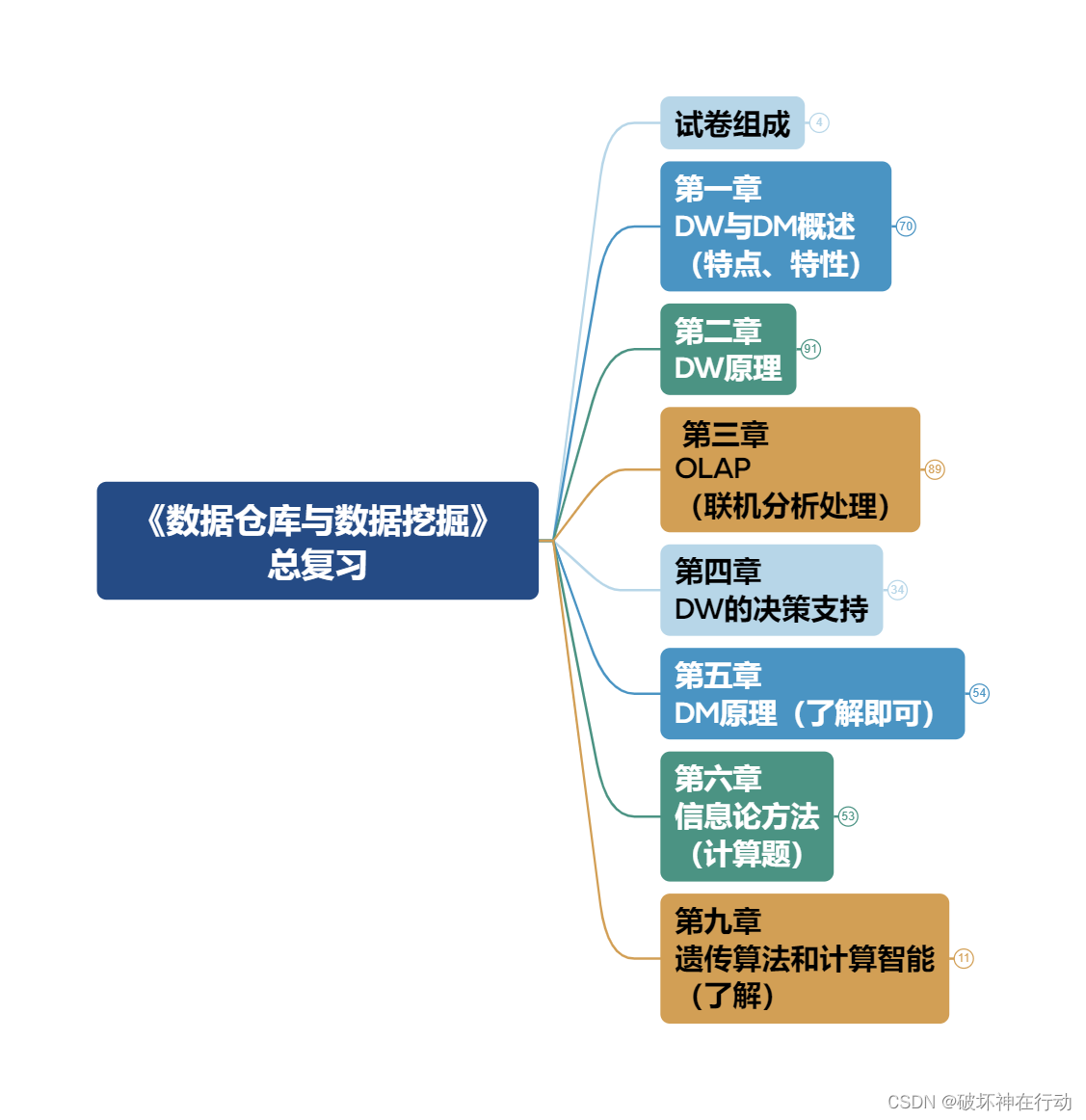
试卷组成

第一章图
 第二章图
第二章图
第三章图

第四章图
第五章图
第六章图
第九章图
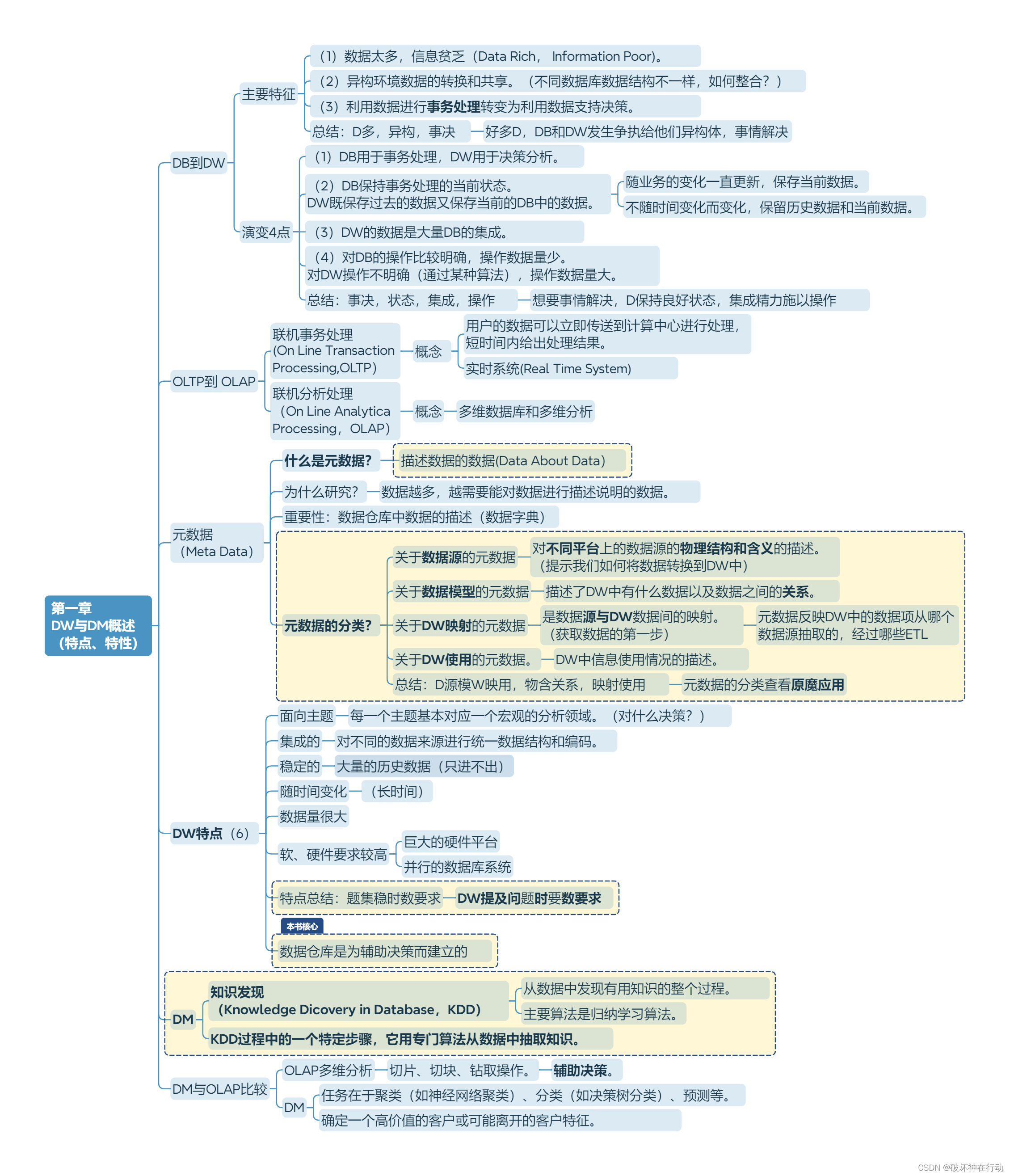
第一章 DW与DM概述 (特点、特性)
DB到DW
主要特征
(1)数据太多,信息贫乏(Data Rich, Information Poor)。
(2)异构环境数据的转换和共享。(不同数据库数据结构不一样,如何整合?)
(3)利用数据进行事务处理转变为利用数据支持决策。
总结:D多,异构,事决
好多D,DB和DW发生争执给他们异构体,事情解决
演变4点
(1)DB用于事务处理,DW用于决策分析。
(2)DB保持事务处理的当前状态。 DW既保存过去的数据又保存当前的DB中的数据。
随业务的变化一直更新,保存当前数据。
不随时间变化而变化,保留历史数据和当前数据。
(3)DW的数据是大量DB的集成。
(4)对DB的操作比较明确,操作数据量少。 对DW操作不明确(通过某种算法),操作数据量大。
总结:事决,状态,集成,操作
想要事情解决,D保持良好状态,集成精力施以操作
OLTP到 OLAP
联机事务处理 (On Line Transaction Processing,OLTP)
概念:用户的数据可以立即传送到计算中心进行处理,短时间内给出处理结果。
实时系统(Real Time System)
联机分析处理 (On Line Analytica Processing,OLAP)
概念:多维数据库和多维分析
元数据 (Meta Data)
什么是元数据?
描述数据的数据(Data About Data)
为什么研究?
数据越多,越需要能对数据进行描述说明的数据。
重要性:数据仓库中数据的描述(数据字典)
元数据的分类?
- 关于数据源的元数据
对不同平台上的数据源的物理结构和含义的描述。(提示我们如何将数据转换到DW中)- 关于数据模型的元数据
描述了DW中有什么数据以及数据之间的关系。- 关于DW映射的元数据
是数据源与DW数据间的映射。 (获取数据的第一步)- 元数据反映DW中的数据项从哪个数据源抽取的,经过哪些ETL
关于DW使用的元数据。- DW中信息使用情况的描述。
总结:D源模W映用,物含关系,映射使用
元数据的分类查看原魔应用
DW特点(6)
- 面向主题
每一个主题基本对应一个宏观的分析领域。(对什么决策?)- 集成的
对不同的数据来源进行统一数据结构和编码。- 稳定的
大量的历史数据(只进不出)- 随时间变化(长时间)
- 数据量很大
- 软、硬件要求较高
巨大的硬件平台
并行的数据库系统特点总结:题集稳时数要求
DW提及问题时要数要求
本书核心
数据仓库是为辅助决策而建立的
DM
- 知识发现 (Knowledge Dicovery in Database,KDD):从数据中发现有用知识的整个过程。主要算法是归纳学习算法。
- KDD过程中的一个特定步骤,它用专门算法从数据中抽取知识。
DM与OLAP比较
- OLAP多维分析:切片、切块、钻取操作。辅助决策。
- DM:任务在于聚类(如神经网络聚类)、分类(如决策树分类)、预测等。
确定一个高价值的客户或可能离开的客户特征。
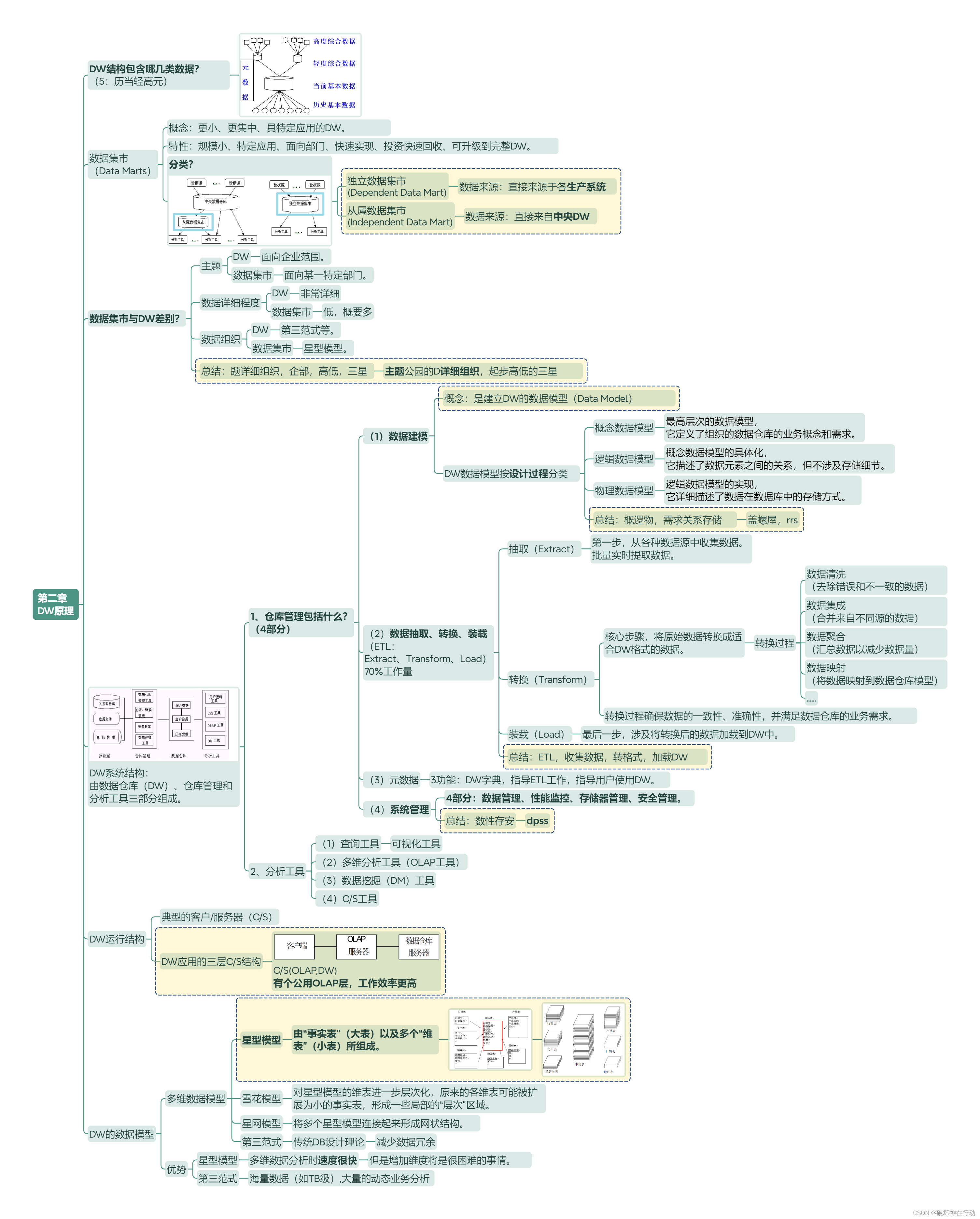
第二章 DW原理
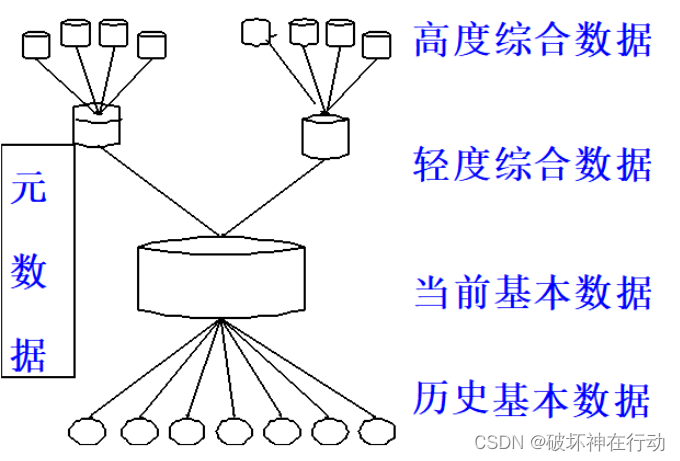
DW结构包含哪几类数据?
(5:历当轻高元)
数据集市 (Data Marts)
概念:更小、更集中、具特定应用的DW。
特性:规模小、特定应用、面向部门、快速实现、投资快速回收、可升级到完整DW。
分类?
独立数据集市 (Dependent Data Mart)
数据来源:直接来源于各生产系统
从属数据集市 (Independent Data Mart)
数据来源:直接来自中央DW
数据集市与DW差别?
- 主题
DW:面向企业范围。
数据集市:面向某一特定部门。- 数据详细程度
DW:非常详细
数据集市:低,概要多- 数据组织
DW:第三范式等。
数据集市:星型模型。总结:题详细组织,企部,高低,三星
主题公园的D详细组织,起步高低的三星
DW系统结构
由数据仓库(DW)、仓库管理和分析工具三部分组成。
1、仓库管理包括什么? (4部分)
(1)数据建模:是建立DW的数据模型(Data Model)
DW数据模型按设计过程分类?
概念数据模型
最高层次的数据模型, 它定义了组织的数据仓库的业务概念和需求。
逻辑数据模型
概念数据模型的具体化, 它描述了数据元素之间的关系,但不涉及存储细节。
物理数据模型
逻辑数据模型的实现, 它详细描述了数据在数据库中的存储方式。
总结:概逻物,需求关系存储
盖螺屋,rrs
(2)数据抽取、转换、装载 (ETL: Extract、Transform、Load) 70%工作量
抽取(Extract)
第一步,从各种数据源中收集数据。 批量实时提取数据。
转换(Transform)
核心步骤,将原始数据转换成适合DW格式的数据。
转换过程
数据清洗 (去除错误和不一致的数据)
数据集成 (合并来自不同源的数据)
数据聚合 (汇总数据以减少数据量)
数据映射 (将数据映射到数据仓库模型)
......
转换过程确保数据的一致性、准确性,并满足数据仓库的业务需求。
装载(Load)
最后一步,涉及将转换后的数据加载到DW中。
总结:ETL,收集数据,转格式,加载DW
(3)元数据
3功能:DW字典,指导ETL工作,指导用户使用DW。
(4)系统管理
4部分:数据管理、性能监控、存储器管理、安全管理。
总结:数性存安
dpss
2、分析工具
(1)查询工具:可视化工具
(2)多维分析工具(OLAP工具)
(3)数据挖掘(DM)工具
(4)C/S工具
DW运行结构
- 典型的客户/服务器(C/S)
- DW应用的三层C/S结构
C/S(OLAP,DW) 有个公用OLAP层,工作效率更高

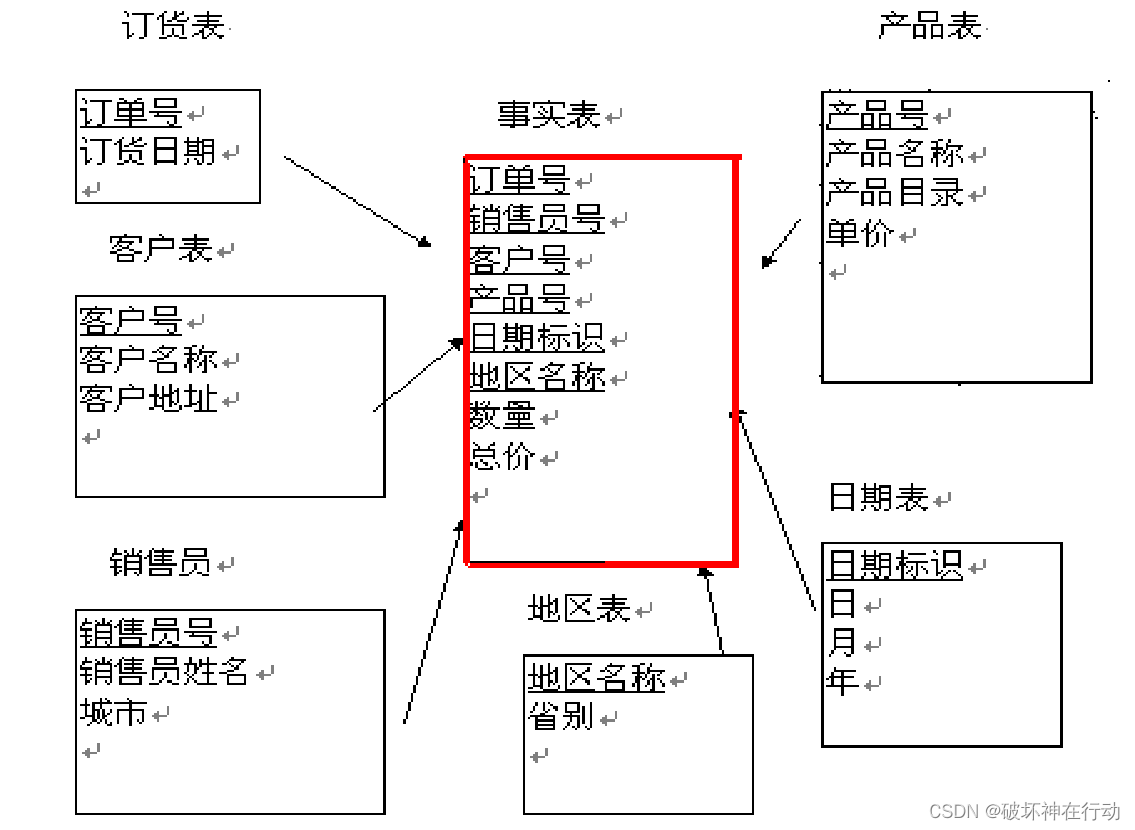
DW的数据模型
多维数据模型
星型模型
由“事实表”(大表)以及多个“维表”(小表)所组成。
雪花模型
对星型模型的维表进一步层次化,原来的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域。
星网模型
将多个星型模型连接起来形成网状结构。
第三范式
传统DB设计理论
减少数据冗余
优势
星型模型
多维数据分析时速度很快
但是增加维度将是很困难的事情。
第三范式
海量数据(如TB级),大量的动态业务分析
第三章 OLAP (联机分析处理)
概念
定义
OLAP是共享多维信息的快速分析。
4个特征
1、快速性
2、可分析性
3、多维性
4、信息性
总结:快可多信
快速的多维分析信息值得信赖
特点
1.线性(On Line),由网络上的C/S结构完成。
2.多维分析,OLAP的核心所在。
准则 (主要4条)
(1)多维数据分析;
(2)客户/服务器结构;
(3)多用户支持;
(4)一致的报表性能等。
数据维数和数据的综合层次增加时, 提供的报表能力和响应速度不应该有明显的降低。 (即便D量,维度增加,速度不应该下降)
OLAP的数据模型
-
分类
-
MOLAP数据模型
-
Multidimensional Online Analytical Processing
-
基于多维数据库存储方式建立的OLAP
-
表现为“超立方”结构,采用类似于多维数组的结构。
-
-
ROLAP数据模型
-
Relational Online Analytical Processing
-
是基于关系数据库的OLAP。
-
是一个平面结构,用关系数据库表示多维数据时,采用星型模型。
-
-
-
比较
-
1.数据存取速度(MOLAP的响应速度快 )
-
M
-
R需要转化SQL语句
-
-
2.数据存储的容量( ROLAP存储容量上没有限制)
-
R
-
M立体方式存放数据,数据量级不大
-
-
3.多维计算的能力(MOLAP能够支持高性能计算 )
-
M
-
R无法多行/维计算
-
-
4.维度变化的适应性(ROLAP对于维表的变更有很好的适应性 )
-
R
-
M增维需重建DB
-
-
5.数据变化的适应性( ROLAP对于数据变化的适应性高 )
-
R
-
M在数据频繁变化时需要大量重新计算
-
-
6.软硬件平台的适应性(ROLAP适应性很好 )
-
R
-
-
7.元数据管理
-
均无成形标准。
-
-
总结:as计维变适管,多关多关关关无
-
存计为多,其余为关
-
-
多维数组的表示
(维1,维2,……,维n,变量)
一个4维的结构,即(产品,地区,时间,销售渠道,销售额)。(元组)
多维数据的显示
多维数据的显示只能在平面上展现出来。
多维数据的分析视图
平面显示多维数据,利用行、列和页面三个显示组表示。(页面,行,列,指标维)
页面:商店3(商店维) 行:月份(时间维:1月,2月,3月) 列:产品(产品维:上衣,裤子,帽子) 指标维:固定成本,直接销售
多维数据分析的基本操作分别是怎么执行的?
(切片、切块、旋转、钻取)
1.切片
选定多维数组的一个二维子集的操作。
2. 切块
多维数组的某个维上选定某一区间的维成员的操作。
选定多维数组的一个三维子集的操作。
3. 钻取
维度的细分。
向上钻取(drill up )
向上钻取获取概括性的数据。
缩小地图:区-市-省-国
向下钻取(drill down )
向下钻取是使用户在多层数据中能通过导航信息而获得更多的细节性数据。
放大地图:国-省-市-区
4.旋转
得到不同视角的数据。 相当于平面数据将坐标轴旋转。
总结:片块上下转,二三概细多视角。
数据立方体
概述:实际为数据仓库结构图中的综合数据层(轻度和高度)。
多维数据集的属性分类?
维属性
度量属性
典型的压缩型数据立方体
(1)冰山立方体
数据的筛选:在冰山立方体的生成计算中,仅聚集高于(或低于)某个阈值的子立方体。
(2)紧凑数据立方体
用一条数据来代表之前表中的多条数据元组压缩如(产品,地区,时间,销售渠道,销售额)
(3)外壳片段立方体
(4)流式数据立方体
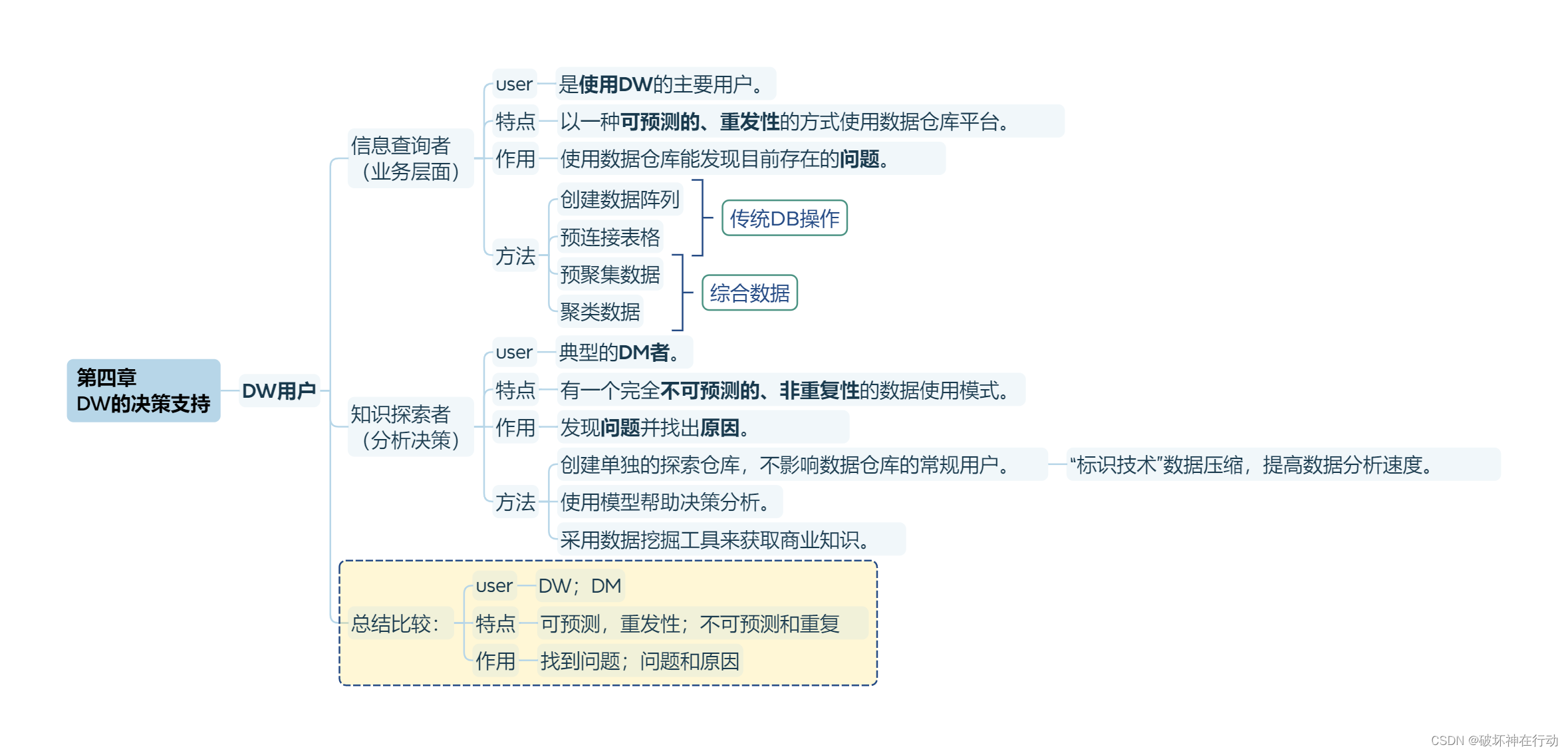
第四章 DW的决策支持
DW用户
信息查询者 (业务层面)
user
是使用DW的主要用户。
特点
以一种可预测的、重发性的方式使用数据仓库平台。
作用
使用数据仓库能发现目前存在的问题。
方法
创建数据阵列
预连接表格
预聚集数据
聚类数据
知识探索者 (分析决策)
user
典型的DM者。
特点
有一个完全不可预测的、非重复性的数据使用模式。
作用
发现问题并找出原因。
方法
创建单独的探索仓库,不影响数据仓库的常规用户。
“标识技术”数据压缩,提高数据分析速度。
使用模型帮助决策分析。
采用数据挖掘工具来获取商业知识。
总结比较:
user
DW;DM
特点
可预测,重发性;不可预测和重复
作用
找到问题;问题和原因
第五章 DM原理(了解即可)
KDD
概念:从数据中发现有用知识的整个过程。
过程
数据准备、DM、结果评估
数据准备的三个步骤?
数据选择,数据预处理,数据转换
DM
KDD过程中的一个特定步骤,它用专门算法从数据中抽取模式(patterns)。
按照DM任务采取不同方法
聚类方法 (结果未知)
在没有类别的数据中,按照”距离“远近聚集若干类别。
典型方法:k均值聚类算法,统计分析方法,机器学习方法,神经网络方法等
分类方法 (结果已知)
对有类别的数据,找出各类别的描述知识。
典型方法:ID3、C4.5、IBLE等分类算法
总结
有无类别
结果评估
数据质量好坏的两个影响因素?
DM技术的有效性
挖掘数据的质量和数量
总结:技术和数据
DM任务和分类
DM任务
(1)关联分析
两个或多个数据项的取值之间重复出现且概率很高时,它就存在某种关联,可以建立起这些数据项的关联规则。
(2)时序模式
通过时间序列搜索出重复发生概率较高的模式
(3)聚类
在没有类的数据中,按“距离”概念聚集成若干类。
距离
同一类别中个体之间的距离较小
而不同类别上的个体之间的距离偏大
(4)分类
在聚类的基础上,对已确定的类找出该类别的概念描述,它代表了这类数据的整体信息。
类的内涵描述
特征描述
对类中对象的共同特征的描述。
辨别性描述
对两个或多个类之间的区别的描述
(5)偏差检测
从数据分析中发现异常情况
(6)预测
利用历史数据找出变化规律,建立模型,并用此模型来预测未来数据的种类,特征等
什么是聚类和分类?
决策树知识
ps:在其基础上考计算题 (信息熵和信息增益)
决策树是一种常用的机器学习算法,用于分类和回归任务。
基本概念
决策树通过一系列的问题将数据分割成不同的分支,最终达到一个结论或决策。
构建过程
从根节点开始,选择一个特征和阈值进行分割,递归地在子节点上重复这个过程,直到满足停止条件。
特征选择
特征选择是决策树构建中的关键步骤,用于决定在每个节点上使用哪个特征进行分割。常见的特征选择方法包括信息增益、信息增益率和基尼不纯度。
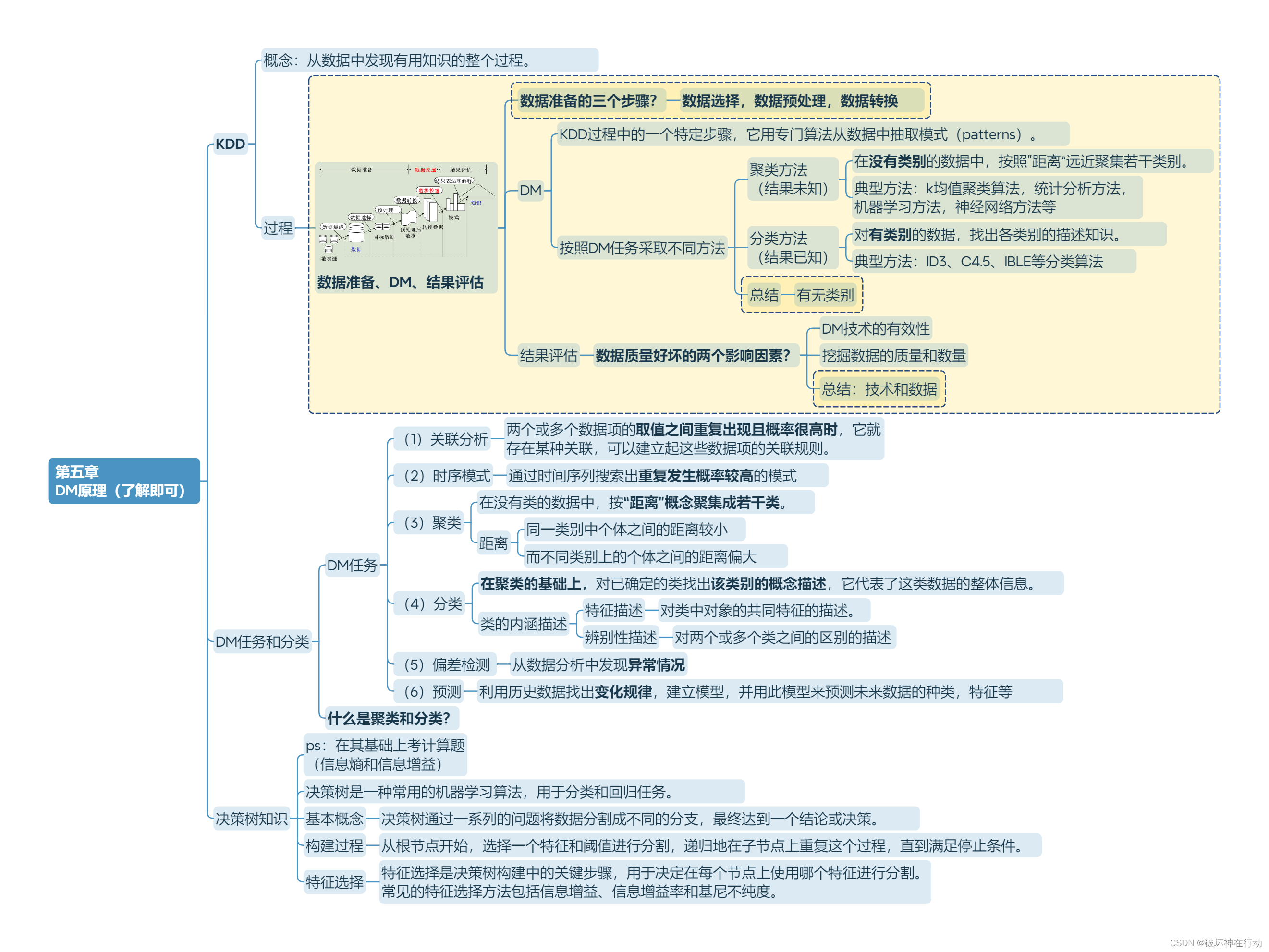
第六章 信息论方法 (计算题)
-
决策树方法 (了解即可)
-
决策树是一种知识表示形式,它是对所有样本数据的高度概括。
-
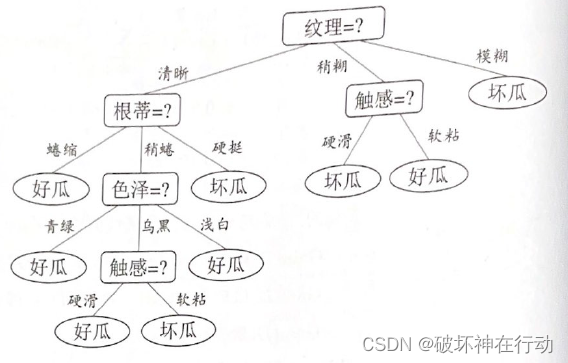
决策树,如ID3、C4.5方法,是把信息量最大的属性作为树或子树的根结点,属性的取值作为分枝。
-
ID3决策树
-
结点
-
根结点
-
是所有样本中信息量最大的属性。
-
-
中间结点
-
是该结点为根的子树所包含的样本子集中信息量最大的属性。
-
-
叶结点
-
是样本的类别值。
-
-
信息熵和信息增益
-
信息传递系统 (信道模型)
-
发送端(信源)
-
接收端(信宿)
-
连接两者的通道(信道)
-
-
概念
-
1、信息熵 H(U) 也称为先验熵
-
先验不确定性
-
先验不确定性不能全部被消除,只能部分地消除
-
-
接收端(信宿)不确定发送端(信源)状态。
-
是信源输出前的平均不确定性,也称先验熵。
-
-
总结
-
P(U):所有例子中的正例和反例在总例的占比
-
H(U):(-占比log占比)二者相加
-
-
-
2、条件熵H(U/V) 也称为后验熵
-
后验不确定性
-
通信结束之后,信宿仍然具有一定程度的不确定性。
-
后验不确定性总要小于先验不确定性 H(U/V)< H(U)
-
相等,表示信宿没收到信息。
-
后验不确定性为0,表示信宿收到全部信息。
-
-
总结
-
P(V):属性某一取值在总例的占比
-
P(U/V):属性某一取值的正反例占比
-
H(U/V):(-总例占比×(属性取值占比log属性取值占比)之和)之和
-
-
-
3、信息量用互信息来表示,也称为信息增益=先验熵-后验熵 I(U,V)=H(U)- H(U/V)
-
信息是用来消除(随机)不确定性的度量。
-
总结
-
计算所有属性的互信息量I
-
-
-
4、建决策树树根和分支
-
树根
-
选择互信息量I最大的特征值
-
-
分支
-
划分特征子集F
-
-
-
5、递归建树
-
继续求剩余特征的互信息量,找互信息量最大的一个作为分支的根结点向下分支,最后标记正反例(分类)
-
-
计算




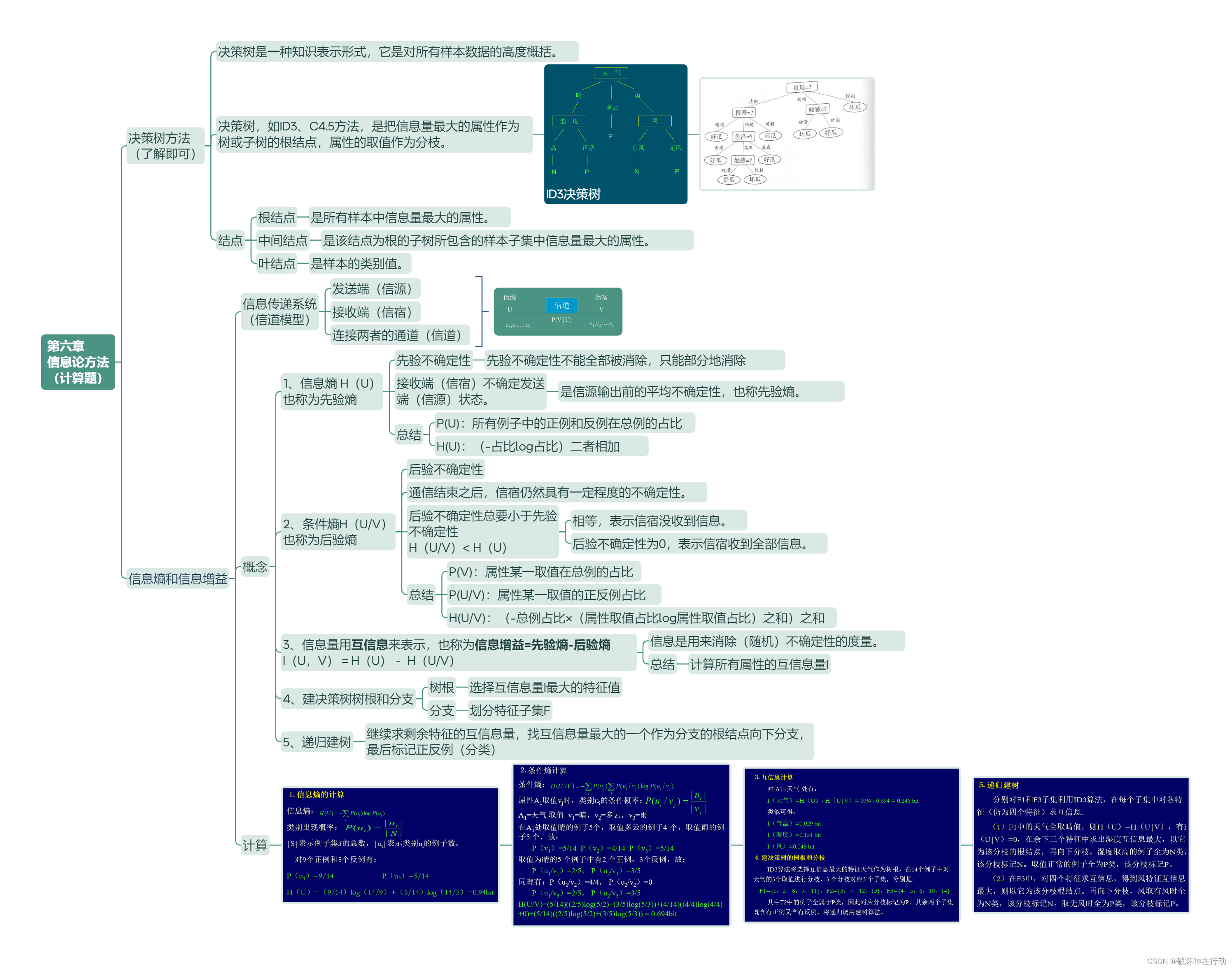
第九章 遗传算法和计算智能 (了解)
遗传算法 (Genetic Algorithms,GA)
是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化搜索算法。
遗传算子
选择 (Selection)
依据每个染色体的适应值大小,适应值越大,被选中的概率就越大,其子孙在下一代产生的个数就越多。
选择操作是建立在群体中个体的适应值评估基础上的,目前常用的选择算子有适应值比例法、最佳个体保存法、期望值方法等。
交叉(重组) (Crossover)
通过染色体重组来产生新一代染色体。
变异 (Mutation)
变异增加了遗传算法找到接近最优解的能力。
变异就是以很小的概率,随机地改变字符串某个位置上的值。把某一位的内容进行变异。
相关文章:
《数据仓库与数据挖掘》 总复习
试卷组成 第一章图 第二章图 第三章图 第四章图 第五章图 第六章图 第九章图 第一章 DW与DM概述 (特点、特性) DB到DW 主要特征 (1)数据太多,信息贫乏(Data Rich, Information Poor)。 &a…...

EtherCAT主站IGH-- 8 -- IGH之domain.h/c文件解析
EtherCAT主站IGH-- 8 -- IGH之domain.h/c文件解析 0 预览一 该文件功能`domain.c` 文件功能函数预览二 函数功能介绍1. `ec_domain_init`2. `ec_domain_clear`3. `ec_domain_add_fmmu_config`4. `ec_domain_add_datagram_pair`5. `ec_domain_finish`6. `ecrt_domain_reg_pdo_en…...

《昇思25天学习打卡营第10天|使用静态图加速》
文章目录 今日所学:一、背景介绍1. 动态图模式2. 静态图模式 三、静态图模式的使用场景四、静态图模式开启方式1. 基于装饰器的开启方式2. 基于context的开启方式 总结: 今日所学: 在上一集中,我学习了保存与加载的方法ÿ…...
【HarmonyOS4学习笔记】《HarmonyOS4+NEXT星河版入门到企业级实战教程》课程学习笔记(二十二)
课程地址: 黑马程序员HarmonyOS4NEXT星河版入门到企业级实战教程,一套精通鸿蒙应用开发 (本篇笔记对应课程第 32 节) P32《31.通知-基础通知》 基础文本类型通知:briefText 没有用,写了也白写。 长文本类型…...

六西格玛绿带培训如何告别“走过场”?落地生根
近年来,六西格玛绿带培训已经成为了众多企业提升管理水平和员工技能的重要途径。然而,不少企业在实施六西格玛绿带培训时,往往陷入形式主义的泥潭,导致培训效果大打折扣。那么,如何避免六西格玛绿带培训变成“走过场”…...

Linux——提取包文件到指定目录,命令解释器-shell,type 命令
- 提取包文件到指定目录 bash tar xf/-xf/-xzf 文件名.tar.gz [-C 目标路径] tar xf/-xf/-xjf 文件名.tar.bz2 [-C 目标路径] tar xf/-xf/-xJf 文件名.tar.xz [-C 目标路径] ### 示例 - 将/etc下所有内容打包压缩到/root目录中 bash [rootserver ~]# tar -cvf taretc…...

【最详细】PhotoScan(MetaShape)全流程教程
愿天下心诚士子,人人会PhotoScan! 愿天下惊艳后辈,人人可剑开天门! 本教程由CSDN用户CV_X.Wang撰写,所用数据均来自山东科技大学视觉测量研究团队,特此鸣谢!盗版必究! 一、引子 Ph…...

Excel多表格合并
我这里一共有25张表格: 所有表的表头和格式都一样,但是内容不一样: 现在我要做的是把所有表格的内容合并到一起,研究了一下发现WPS的这项功能要开会员的,本来想用代码撸出来的,但是后来想想还是找其他办法,后来找到"易用宝"这个插件,这个插件可以从如下地址下载:ht…...
)
AI作画工具深度剖析:Midjourney vs. Stable Diffusion (SD)
在人工智能技术的推动下,艺术创作的边界被不断拓宽,AI作画工具成为数字艺术家与创意人士的新宠。其中,Midjourney与Stable Diffusion(SD)作为当前领域的佼佼者,以其独特的算法机制、丰富的功能特性及高质量…...
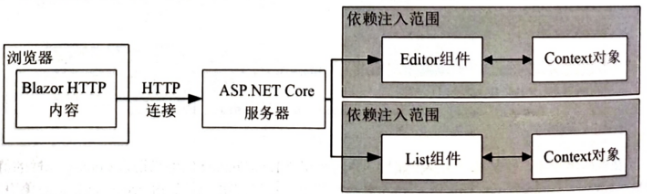
ASP.NET Core Blazor 5:Blazor表单和数据
本章将描述 Blazor 为处理 HTML 表单提供的特性,包括对数据验证的支持。 1 准备工作 继续使用上一章项目。 创建 Blazor/Forms 文件夹并添加一个名为 EmptyLayout.razor 的 Razor 组件。本章使用这个组件作为主要的布局。 inherits LayoutComponentBase<div …...

C++ 仿QT信号槽二
// 实现原理 // 每个signal映射到bitset位,全集 // 每个slot做为signal的bitset子集 // signal全集触发,标志位有效 // flip将触发事件队列前置 // slot检测智能指针全集触发的标志位,主动运行子集绑定的函数 // 下一帧对bitset全集进行触发清…...

联合概率密度函数
目录 1. 什么是概率密度由联合概率密度求概率参考链接 1. 什么是概率密度 概率密度到底在表达什么? 外卖在20-40分钟内送达的概率 随机变量落在[20,40]之间的概率。下图中,对总面积做规范化处理,令总面积1, f ( x ) f(x) f(x)则成…...

【Java10】成员变量与局部变量
Java中的变量只有两种:成员变量和局部变量。 和C不同,没有全局变量了。 成员变量,field,我习惯称之为**”属性“**(但这些年,因为attribute更适合被叫做属性,所以渐渐不这么叫了)。 …...

Spring Session与分布式会话管理详解
随着微服务架构的普及,分布式系统中的会话管理变得尤为重要。传统的单点会话管理已经不能满足现代应用的需求。本文将深入探讨Spring Session及其在分布式会话管理中的应用。 什么是Spring Session? Spring Session是一个用于管理HttpSession的Spring框…...

从0开始学习pyspark--Spark DataFrame数据的选取与访问[第5节]
在PySpark中,选择和访问数据是处理Spark DataFrame的基本操作。以下是一些常用的方法来选择和访问DataFrame中的数据。 选择列(Selecting Columns): select: 用于选择DataFrame中的特定列。selectExpr: 用于通过SQL表达式选择列。 df.select…...

Fastjson首字母大小写问题
1、问题 使用Fastjson转json之后发现首字母小写。实体类如下: Data public class DataIdentity {private String BYDBSM;private String SNWRSSJSJ;private Integer CJFS 20; } 测试代码如下: public static void main(String[] args) {DataIdentit…...

GuLi商城-商品服务-API-品牌管理-效果优化与快速显示开关
<template><div class"mod-config"><el-form :inline"true" :model"dataForm" keyup.enter.native"getDataList()"><el-form-item><el-input v-model"dataForm.key" placeholder"参数名&qu…...

如何成为C#编程高手?
成为C#编程高手需要时间、实践和持续的学习。以下是一些建议,可以帮助你提升C#编程技能: 深入理解基础知识: 确保你对C#的基本语法、数据类型、控制结构、面向对象编程(OOP)原则有深刻的理解。学习如何使用Visual Stud…...
SpringBoot学习06-[SpringBoot与AOP、SpringBoot自定义starter]
SpringBoot自定义starter SpringBoot与AOPSpringBoot集成Mybatis-整合druid在不使用启动器的情况下,手动写配置类进行整合使用启动器的情况下,进行整合 SpringBoot启动原理源码解析创建SpringApplication初始化SpringApplication总结 启动 SpringBoot自定义Starter定…...

Maven - 在没有网络的情况下强制使用本地jar包
文章目录 问题解决思路解决办法删除 _remote.repositories 文件代码手动操作步骤验证 问题 非互联网环境,无法从中央仓库or镜像里拉取jar包。 服务器上搭建了一套Nexus私服。 Nexus私服故障,无法连接。 工程里新增了一个Jar的依赖, 本地仓…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...
)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理(附dpkg/apt组合拳)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理 在UOS系统日常使用中,WPS Office作为常用办公软件,有时因版本更新或功能调整需要彻底卸载。但不少用户发现,通过图形界面或简单命令卸载后,系统中仍残留配置文件、…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...

如何高效实现前端文件下载:FileSaver.js完整实用指南
如何高效实现前端文件下载:FileSaver.js完整实用指南 【免费下载链接】FileSaver.js An HTML5 saveAs() FileSaver implementation 项目地址: https://gitcode.com/gh_mirrors/fi/FileSaver.js FileSaver.js是一款轻量级的HTML5文件保存解决方案,…...

别再只会用spline了!MATLAB csape函数详解:从自然边界到夹持边界的实战选择
MATLAB csape函数深度解析:从自然边界到夹持边界的工程实践 在工程仿真和科学计算领域,数据插值是一个永恒的话题。当我们面对一组离散的实验数据或仿真结果时,如何构建一条光滑的曲线来准确反映数据背后的物理规律?这个问题困扰…...