【项目实战】32G的电脑启动IDEA一个后端服务要2min!谁忍的了?
一、背景
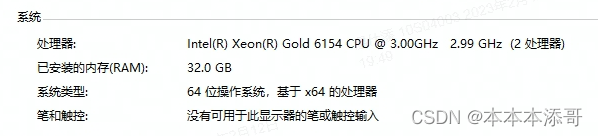
本人电脑性能一般,但是拥有着一台高性能的VDI(虚拟桌面基础架构),以下是具体的配置
二、问题描述
但是,即便是拥有这么高的性能,每次运行基于Dubbo微服务架构下的微服务都贼久,以下是启动一次所消耗的时长

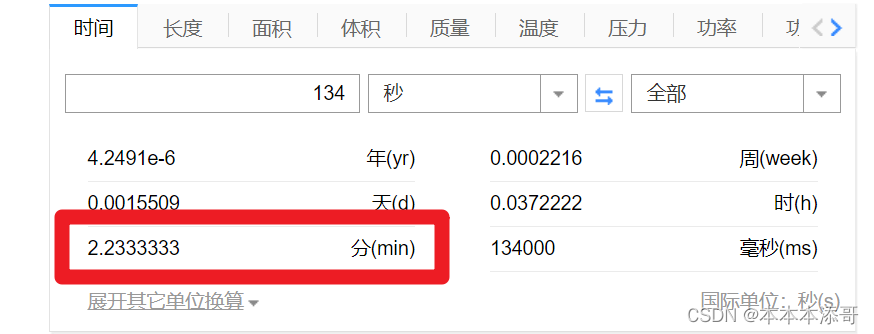
使用百度的时间转换的计算耗时,好家伙,启动一次竟然要耗时2.2min分钟
跟同事讨论了这个项目的启动时长,同事A说是我的IDEA的问题,同事B说是我电脑的问题。
本着一探究竟的精神,耗时了一个下午,我倒要看看究竟是那个应用在拖后腿!
三、问题跟踪与解决
3.1 重启IDEA和VDI
重新启动了IDEA。关闭了所有的IDEA中的进程,以确保不是IDEA在拖后腿。
重新启动了VDI,VDI如果在定期杀毒的话,也会拖后进程的。
3.2 关闭devtools模式
热部署一般是开发过程中使用:开发者不想因为修改内容后重启server浪费大量的时间,而是希望修改代码后能够快速加载自己修改的方法或者类。节省开发时间,为开发者提供改好的开发体验。使用热部署之后,它会监督spring项目修改点,把修改点的java文件编译成class文件,然后替换掉修改前的class文件,不用再去重新部署。
之前有尝试过,但是各种限制总是不顺利,尤其现在有了JRebel,这个基本上用不了,于是考虑不再使用。
找到POM文件,直接注释掉devtools的使用。
关闭devtools模式后的效果并不明显。
3.3 关闭项目启动时,初始化字典到缓存的打印
查看打印日志,发现总是会输出以下的脚本,什么鬼?启动一次就打印一次,这不是浪费时间吗?去掉!
JDBC Connection [org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection@537236d3] will not be managed by Spring
==> Preparing: select dict_id, dict_name, dict_type, status, create_by, create_time, remark from sys_dict_type
==> Parameters:
<== Columns: dict_id, dict_name, dict_type, status, create_by, create_time, remark
<== Row: 1, 系统开关, sys_normal_disable, 0, admin, 2018-03-16 11:33:00, 系统开关列表
<== Row: 123, 数据状态, ipds_data_status, 0, admin, 2020-08-11 16:38:25, null
<== Row: 125, 漏洞类型, idps_loophole_type, 0, admin, 2020-08-12 16:30:22, null
<== Row: 127, 严重等级, idps_loophole_grade, 0, admin, 2020-08-12 16:34:24, 漏洞严重等级
<== Total: 4
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@636226a9]
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@1a9a2c28] was not registered for synchronization because synchronization is not active
JDBC Connection [org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection@1287e60e] will not be managed by Spring
==> Preparing: select dict_code, dict_sort, dict_label, dict_value, dict_type, css_class, list_class, is_default, status, create_by, create_time, remark from sys_dict_data where status = '0' and dict_type = ? order by dict_sort asc
==> Parameters: sys_normal_disable(String)
<== Columns: dict_code, dict_sort, dict_label, dict_value, dict_type, css_class, list_class, is_default, status, create_by, create_time, remark
<== Row: 6, 1, 正常, 0, sys_normal_disable, , primary, Y, 0, admin, 2018-03-16 11:33:00, 正常状态
<== Row: 7, 2, 停用, 1, sys_normal_disable, , danger, N, 0, admin, 2018-03-16 11:33:00, 停用状态
<== Total: 2
因为模块涉及到dict,所以很快定位到是数据字典模块的功能。
/**
* 项目启动时,初始化字典到缓存
*/
@PostConstruct
public void init() {List<SysDictType> dictTypeList = dictTypeMapper.selectDictTypeAll();for (SysDictType dictType : dictTypeList) {List<SysDictData> dictDataList = dictDataMapper.selectDictDataByType(dictType.getDictType());DictUtils.setDictCache(dictType.getDictType(), dictDataList);}
}
这一段代码中,使用了@PostConstruct,这个注解的介绍如下
从Java EE5规范开始,Servlet中增加了两个影响Servlet生命周期的注解,@PostConstruct和@PreDestroy,这两个注解被用来修饰一个非静态的void()方法。@PostConstruct是Java自带的注解,在方法上加该注解会在项目启动时执行该方法,也可以理解为在spring容器初始化的时候执行该方法。
注意:在方法上加@PostConstruct注解会在项目启动时执行该方法
因此解决方案也很简单,直接注释掉这个注解即可。
3.4 给XXL-job增加一个开关
看以下截图,发现每次都会进行XXL-job的init的动作。
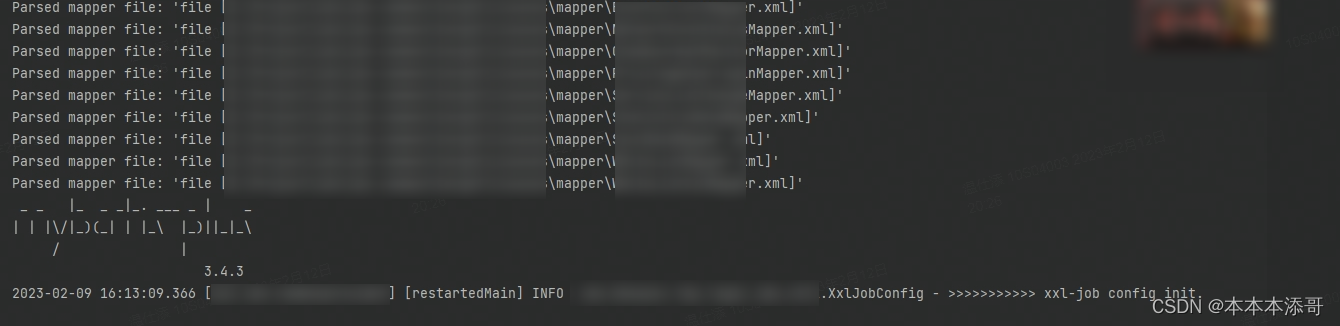
溯源这个的打印处,发现了如下代码
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {log.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;
}
难怪了,本机每次启动都会把自己注册到XXL-job的服务端。
因此,是否可以设计一个开关,让本机的服务不注册到XXL-job的服务端呢。于是有了以下的代码改善。
3.4.1 新增一个enabled字段,用于动态控制注册动作。
@Configuration
@Slf4j
public class {@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;/*** 开关,默认关闭*/@Value("${xxl.job.enabled}")private Boolean enabled;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {if (enabled) {log.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}return null;}
}
3.4.2 配置文件中新增开关的配置
xxl.job.enabled=true
3.5 关闭断点(最重要的点)
大家都知道在项目Debug过程中,使用Debug模式运行项目会太慢,往往会比正常直接运行要慢上将近三倍的时间
但是其中的原因却很少人说的清楚,其实是因为使用Debug模式运行时,我们会在某些方法上打了断点(像我,就往往会忘记关闭这些断点),而这种情况会出现Method breakpoints may dramatically slow down debugging的提示,这类提示有时会提示你,有时不会提示你。
解决方案:
3.5.1 返选取消所有断点
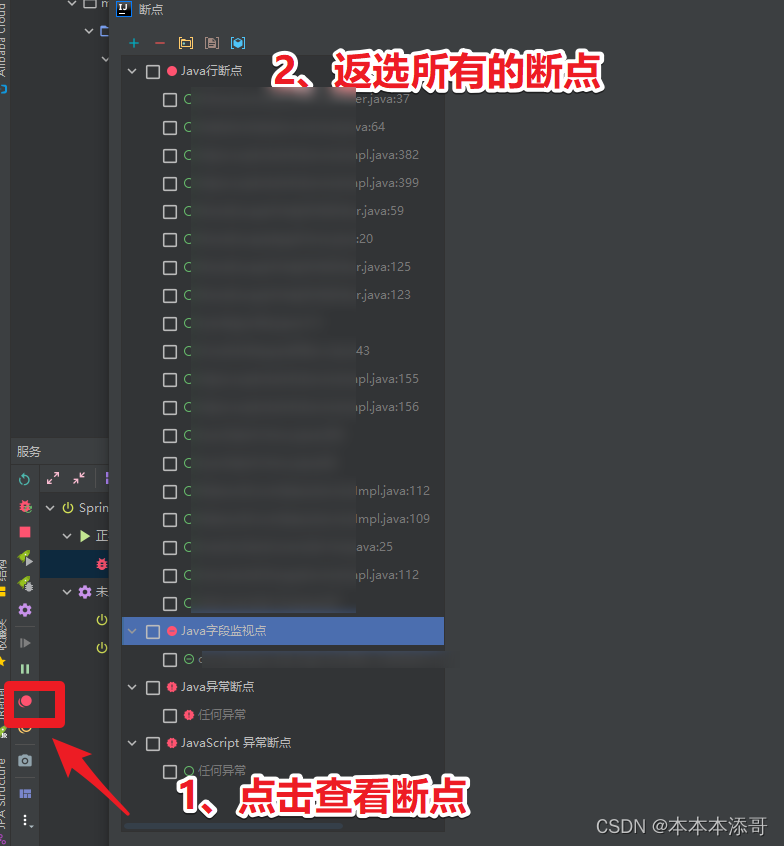
将Java Method Breakpoints下的选项的勾都去掉。
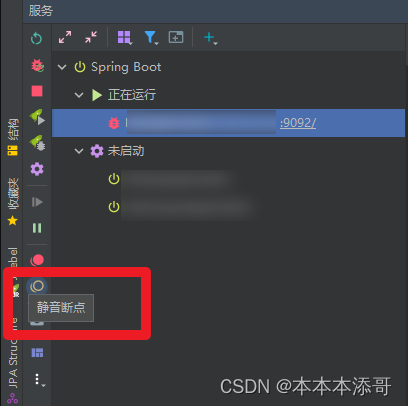
3.5.2 直接点击静音断点
四、问题验证
Started Application in 19.06 seconds
解决后,重新使用debug模式启动,发现启动时间直接降低下拉啦,撒花。
相关文章:
【项目实战】32G的电脑启动IDEA一个后端服务要2min!谁忍的了?
一、背景 本人电脑性能一般,但是拥有着一台高性能的VDI(虚拟桌面基础架构),以下是具体的配置 二、问题描述 但是,即便是拥有这么高的性能,每次运行基于Dubbo微服务架构下的微服务都贼久,以下…...
2022年山东省中职组“网络安全”赛项比赛任务书正式赛题
2022年山东省中职组“网络安全”赛项 比赛任务书 一、竞赛时间 总计:360分钟 竞赛阶段竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 A模块 A-1 登录安全加固 180分钟 200分 A-2 Nginx安全策略 A-3 日志监控 A-4 中间件服务加固 A-5 本地安全策略…...

RibbitMQ 入门到应用 ( 二 ) 安装
3.安装基本操作 3.1.下载安装 3.1.1.官网 下载地址 https://rabbitmq.com/download.html 与Erlang语言对应版本 https://rabbitmq.com/which-erlang.html 3.1.2.安装 Erlang 在确定了RabbitMQ版本号后,先下载安装Erlang环境 Erlang下载链接 https://packa…...

提取DataFrame中每一行的DataFrame.itertuples()方法
【小白从小学Python、C、Java】【计算机等级考试500强双证书】【Python-数据分析】提取DataFrame中的每一行DataFrame.itertuples()选择题关于以下python代码说法错误的一项是?import pandas as pddf pd.DataFrame({A:[a1,a2],B:[b1,b2]},index[i1,i2])print("【显示】d…...
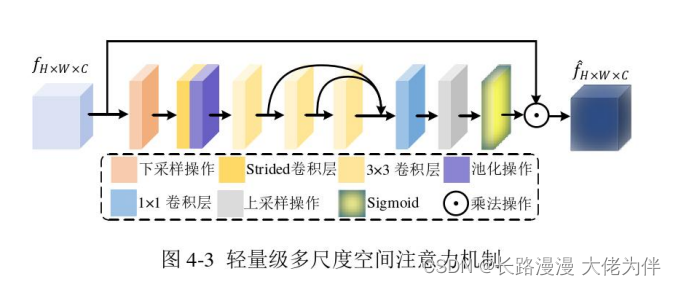
基于卷积神经网络的立体视频编码质量增强方法_余伟杰
基于卷积神经网络的立体视频编码质量增强方法_余伟杰提出的基于TSAN的合成视点质量增强方法全局信息提取流像素重组局部信息提取流多尺度空间注意力机制提出的基于RDEN的轻量级合成视点质量增强方法特征蒸馏注意力块轻量级多尺度空间注意力机制概念扭曲失真孔洞问题失真和伪影提…...
【2023unity游戏制作-mango的冒险】-3.基础动作和动画API实现
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 收录于专栏:unity游戏制作 ⭐mango的基础动作动画的添加⭐ 文章目录⭐mango的基础动作动画的添加⭐…...

跨域的几种解决方案?
1-jsonp 【前端后端实现】jsonp: 利用 <script> 标签没有跨域限制的漏洞,网页可以得到从其他来源动态产生的 JSON 数据。JSONP请求一定需要对方的服务器做支持才可以。JSONP优点是简单兼容性好,可用于解决主流浏览器的跨域数据访问的问题。缺点是仅…...

2022年山东省职业院校技能大赛网络搭建与应用赛项正式赛题
2022年山东省职业院校技能大赛 网络搭建与应用赛项 第二部分 网络搭建与安全部署&服务器配置及应用 竞赛说明: 一、竞赛内容分布 竞赛共分二个模块,其中: 第一模块:网络搭建及安全部署项目 第二模块:服务…...
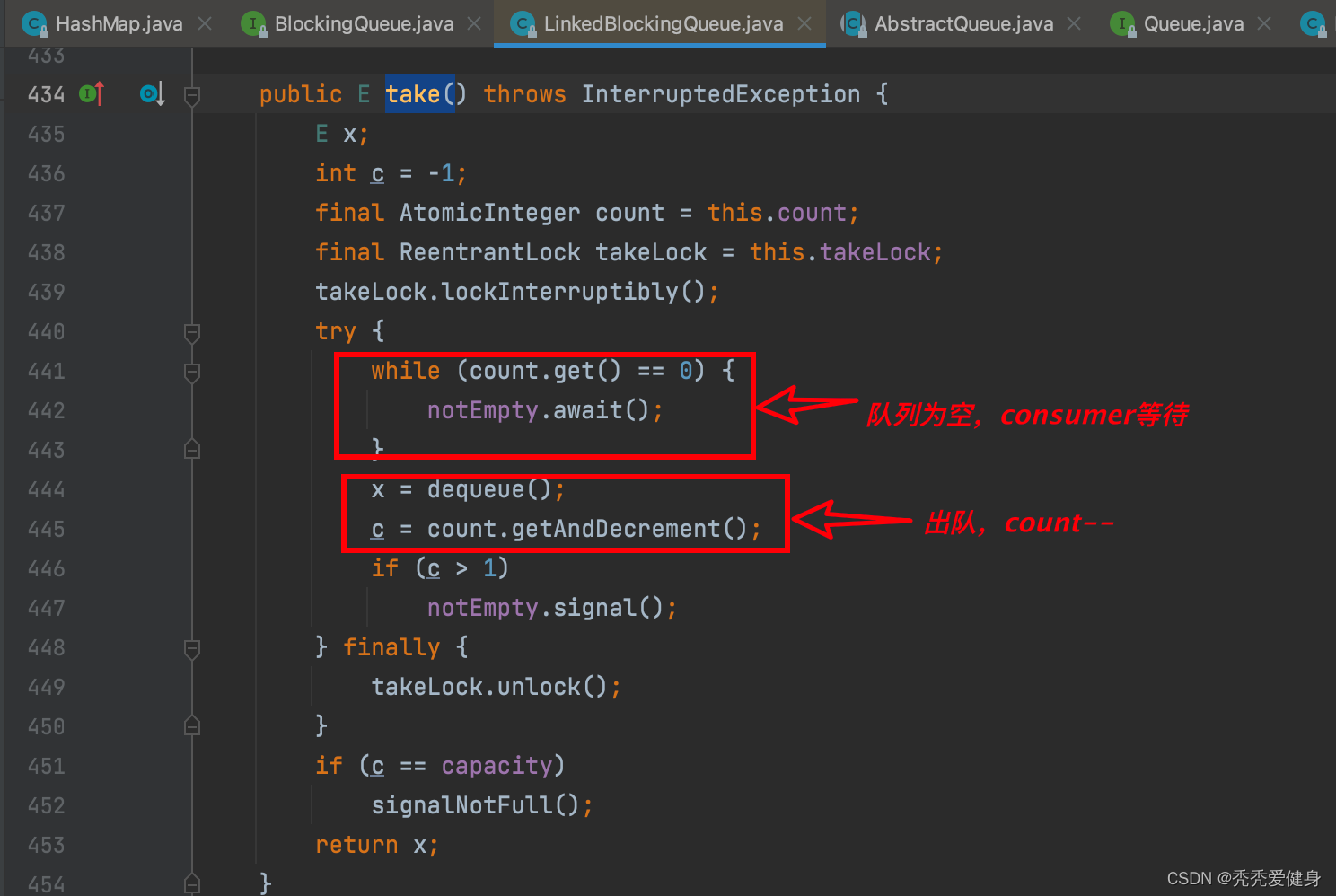
【JUC并发编程】ArrayBlockingQueue和LinkedBlockingQueue源码2分钟看完
文章目录1、BlockingQueue1)接口方法2)阻塞队列分类2、ArrayBlockingQueue1)构造函数2)put()入队3)take()出队3、LinkedBlockingQueue1)构造函数2)put()入队3)take()出队1、Blocking…...
GitHub个人资料自述与管理主题设置
目录 关于您的个人资料自述文件 先决条件 添加个人资料自述文件 删除个人资料自述文件 管理主题设置 补充:建立一个空白文件夹 关于您的个人资料自述文件 可以通过创建个人资料 README,在 GitHub.com 上与社区分享有关你自己的信息。 GitHub 在个…...

Express篇-连接mysql
创建数据库配置文件config/sqlconfig.jsconst sqlconfig {host: localhost, // 连接地址user: root, //用户名password: ****, //密码port: 3306 , //端口号database: mysql01_dbbooks //数据库名 } module.exports sqlconfig封装数据库管理工具 utils/mysqlUtils.…...
win10 安装rabbitMQ详细步骤
win10 安装rabbitMQ详细步骤 win10 安装rabbitMQ详细步骤win10 安装rabbitMQ详细步骤一、下载安装程序二、安装配置erlang三、安装rabbitMQ四、验证初始可以通过用户名:guest 密码guest来登录。报错:安装RabbitMQ出现Plugin configuration unchanged.问题…...
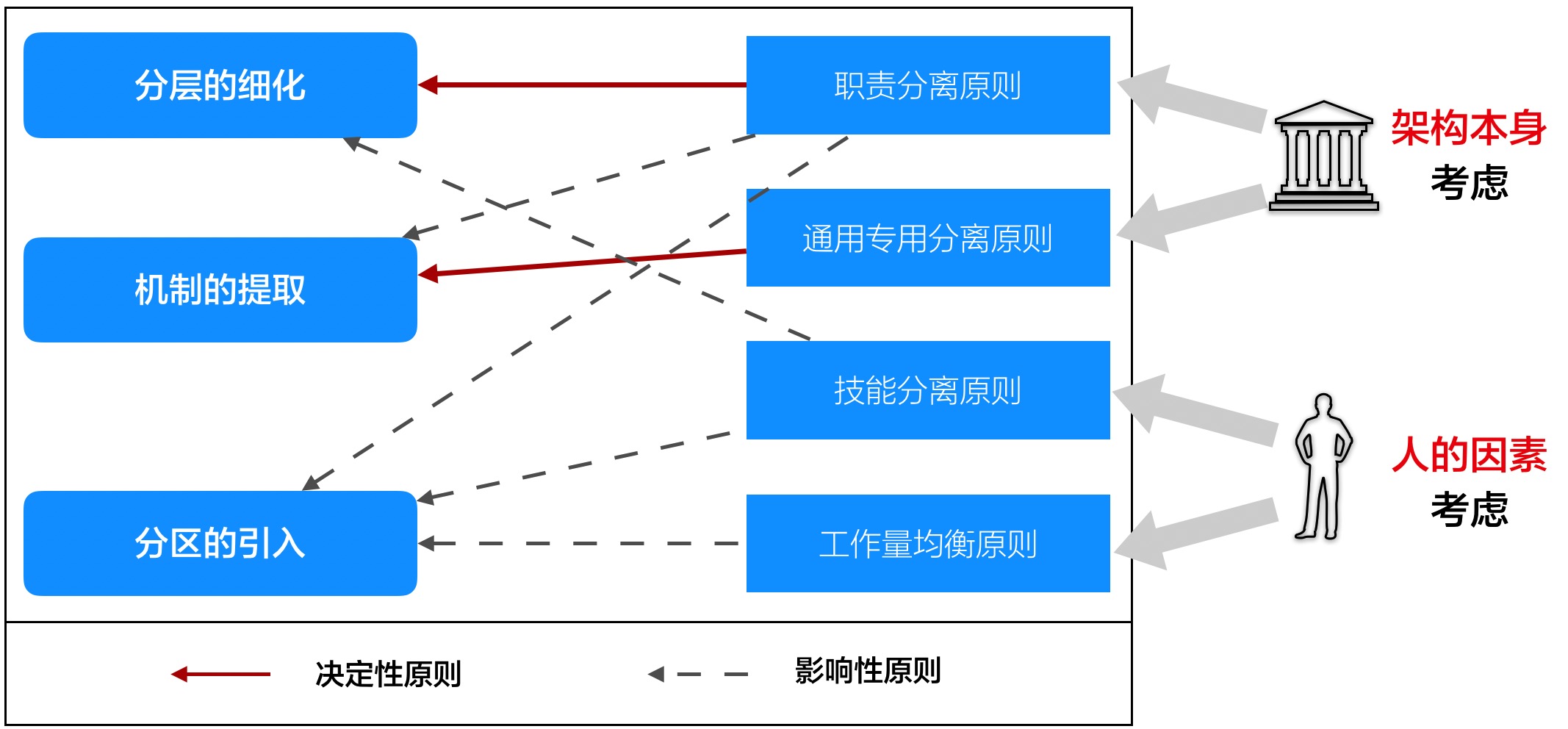
【成为架构师课程系列】一线架构师:6个经典困惑及其解法
目录 一线架构师:6个经典困惑及其解法 多阶段还是多视图? 内置最佳实践 架构方法论:3个阶段,一个贯穿 Pre-architecture阶段:ADMEMS矩阵方法 Conceptual Architecture阶段:重大需求塑造做概念架构 Refined Architecture…...
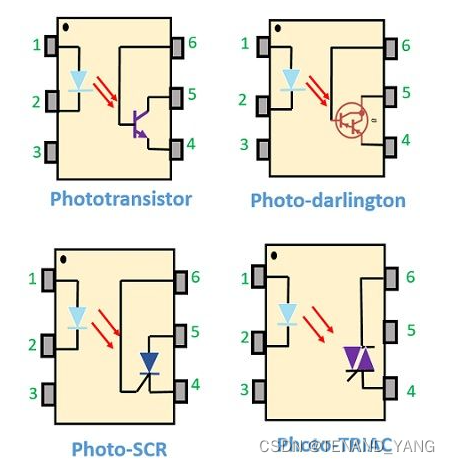
光耦合器的定义与概述
光耦合器或光电耦合器是一种电子元件,基本上充当具有不同电压电平的两个独立电路之间的接口。光耦合器是可在输入和输出源之间提供电气隔离的常用元件。它是一个 6 引脚器件,可以有任意数量的光电探测器。 在这里,光源发出的光束作为输入和输…...
谷粒商城--品牌管理详情
目录 1.简单上传测试 2.Aliyun Spring Boot OSS 3.模块mall-third-service 4.前端 5.数据校验 6.JSR303数据校验 7.分组校验功能 8.自定义校验功能 9.完善代码 1.简单上传测试 OSS是对象存储服务,有什么用呢?把图片存储到云服务器上能让所有人…...

stack、queue和priority_queue
目录 一、栈(stack) 1.stack的使用 2.容器适配器 3.stack的模拟实现 二、队列(queue) 1.queue的使用 2.queue的模拟实现 三、双端队列(deque) 1.vector,list的优缺点 2.认识deque 四…...
面试题(二十二)消息队列与搜索引擎
2. 消息队列 2.1 MQ有什么用? 参考答案 消息队列有很多使用场景,比较常见的有3个:解耦、异步、削峰。 解耦:传统的软件开发模式,各个模块之间相互调用,数据共享,每个模块都要时刻关注其他模…...
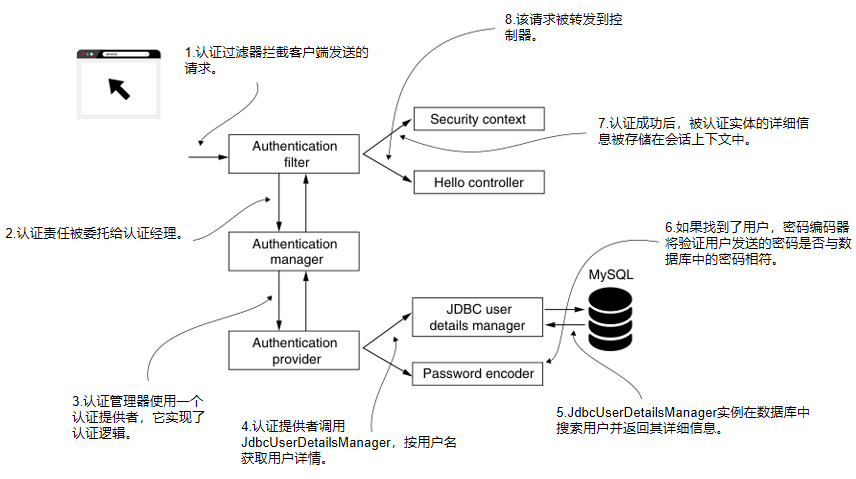
Spring Security in Action 第三章 SpringSecurity管理用户
本专栏将从基础开始,循序渐进,以实战为线索,逐步深入SpringSecurity相关知识相关知识,打造完整的SpringSecurity学习步骤,提升工程化编码能力和思维能力,写出高质量代码。希望大家都能够从中有所收获&#…...

Java面试——maven篇
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

基于微信小程序的游戏账号交易小程序
文末联系获取源码 开发语言:Java 框架:ssm JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏览器…...

20 - 告别“无限上下文”的幻觉:大模型知识注入的“四层矩阵”与下一场权重战争
本专题系列文章共 21 篇,前 5 篇限时免费阅读 01 - 眩晕时代的定海神针:大模型落地的“第一性原理”与算力丰裕悖论 02 - 95%的AI投资打了水漂:五大错配如何扼杀你的“第二增长曲线” 03 - 从电力到AI:标准化已死,个性化永生——大模型时代的三大商业终局 04 - 你的护城…...

模块化IC设计流程:应对复杂芯片挑战的解决方案
1. 现代IC设计面临的挑战与模块化流程的价值在当今半导体行业,芯片设计团队正面临前所未有的复杂挑战。随着工艺节点不断演进至5nm及以下,设计复杂度呈指数级增长。我曾参与的一个65nm SoC项目,团队最初采用传统线性设计流程,结果…...

量子机器学习在网络安全中的应用与性能分析
1. 量子机器学习在网络安全中的应用现状量子机器学习(Quantum Machine Learning, QML)近年来在网络安全领域引起了广泛关注。作为一名长期从事网络安全与量子计算交叉研究的从业者,我见证了这项技术从理论探讨到实际验证的发展历程。量子计算…...

为什么92%的SaaS团队在3个月内切换了语音服务商?——ElevenLabs与PlayAI在WebRTC集成、WebAssembly兼容性及低功耗端侧部署的实战踩坑全记录
更多请点击: https://intelliparadigm.com 第一章:语音合成服务商切换潮的底层动因解构 近年来,大量智能客服、有声阅读与车载交互系统密集启动 TTS(Text-to-Speech)服务商迁移项目。这一现象并非源于单一技术迭代&am…...

Arm A64指令集SIMD与浮点寄存器架构解析
1. A64指令集的SIMD与浮点寄存器架构解析在Armv8-A架构中,A64指令集引入了强大的向量处理能力,通过32个128位宽的V寄存器(V0-V31)实现了高效的SIMD(单指令多数据)和浮点运算支持。这套寄存器文件的设计巧妙…...

终极指南:如何用FanControl实现Windows系统风扇智能温控与静音优化
终极指南:如何用FanControl实现Windows系统风扇智能温控与静音优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub…...

终极指南:BepInEx 6.0插件框架如何彻底解决Unity游戏模组开发的稳定性难题
终极指南:BepInEx 6.0插件框架如何彻底解决Unity游戏模组开发的稳定性难题 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一个革命性的Unity游戏插件与模组开…...

大模型API响应延迟飙升470%,却查不到根因?SITS2026可观测性四象限诊断法,今天就落地
更多请点击: https://intelliparadigm.com 第一章:SITS2026可观测性框架的起源与核心范式 SITS2026(System Intelligence Telemetry Standard 2026)并非凭空诞生,而是源于云原生系统在超大规模微服务编排、边缘-中心协…...

别再死记硬背CTL公式了!用UPPAAL模拟器手把手带你理解A[]和E<>的区别
别再死记硬背CTL公式了!用UPPAAL模拟器手把手带你理解A[]和E<>的区别 刚接触形式化验证工具UPPAAL时,最令人头疼的莫过于那些晦涩难懂的CTL(计算树逻辑)公式。A[]、E<>这些符号组合看起来像天书,教科书上的…...
)
手把手教你用STM32和电位器,临时搭建一个TTL转485调试器(附电路图)
应急调试利器:用STM32和电位器快速搭建TTL转485监听器 在嵌入式开发现场调试时,最让人头疼的莫过于设备串口输出异常却找不到合适的调试工具。上周在客户工厂就遇到了这样的窘境——需要监控设备TTL串口数据,但手边只有RS485转换器和几根杜邦…...