深度学习 - 模型的保存与部署方式汇总
深度学习模型保存和加载格式科普
在深度学习中,模型的保存和加载是非常重要的环节。不同的格式有不同的特点和适用场景。本文将为新手朋友们介绍几种常见的模型格式,包括它们的简介、保存方式、加载方式、优缺点以及应用场景。
1. PyTorch (.pth, .pt)
简介:PyTorch 的默认保存格式,灵活支持保存整个模型、模型的权重和优化器状态。
保存方式:
import torch
torch.save(model.state_dict(), 'model.pth')
加载方式:
model.load_state_dict(torch.load('model.pth'))
model.eval()
部署代码:
from flask import Flask, request, jsonifyapp = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.jsontext = data['text']inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=512)with torch.no_grad():outputs = model(**inputs)logits = outputs.logitspredictions = torch.argmax(logits, dim=-1)return jsonify({'prediction': predictions.item()})if __name__ == '__main__':from transformers import BertTokenizer, BertForSequenceClassificationtokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertForSequenceClassification.from_pretrained('bert-base-uncased')model.load_state_dict(torch.load('model.pth'))model.eval()app.run(host='0.0.0.0', port=5000)
优点:
- 高度灵活:支持复杂的模型和训练过程,因为 PyTorch 允许使用 Python 语言编写任意代码来定义模型。
- 与 PyTorch 框架紧密集成:保存和加载模型非常方便,因为
.pth和.pt是 PyTorch 的原生格式。
缺点:
- 只能在 PyTorch 环境中加载和使用:这限制了跨平台和跨框架的兼容性,因为其他框架无法直接读取这种格式。
应用场景:
- 研究和开发环境。
- 需要频繁保存和加载模型的场景。
2. TensorFlow/Keras (.h5, SavedModel)
简介:TensorFlow 和 Keras 的保存格式,支持保存模型的权重、架构和优化器状态。
保存方式:
model.save('model.h5')
加载方式:
from tensorflow.keras.models import load_model
model = load_model('model.h5')
部署代码:
from flask import Flask, request, jsonify
import tensorflow as tfapp = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.jsontext = data['text']inputs = tokenizer(text, return_tensors='tf', truncation=True, padding=True, max_length=512)outputs = model(inputs)logits = outputs.logitspredictions = tf.argmax(logits, axis=-1)return jsonify({'prediction': int(predictions.numpy()[0])})if __name__ == '__main__':from transformers import BertTokenizer, TFBertForSequenceClassificationtokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased')model.load_weights('model.h5')app.run(host='0.0.0.0', port=5000)
优点:
- 适用于 TensorFlow 和 Keras 环境:模型文件可以直接在这些框架中加载和使用,方便开发和部署。
- 支持多种部署方式:包括 TensorFlow Serving,这使得在生产环境中的部署更加灵活和高效。
缺点:
- 模型文件较大:可能影响加载速度,因为
.h5文件包含了完整的模型架构和权重。
应用场景:
- 生产环境中的模型部署。
- 需要与 TensorFlow 生态系统集成的应用。
3. ONNX (Open Neural Network Exchange)
简介:开放格式,旨在实现不同深度学习框架之间的互操作性。
保存方式:
import torch.onnx
torch.onnx.export(model, dummy_input, 'model.onnx')
加载方式:
import onnx
import onnxruntime as ort
onnx_model = onnx.load('model.onnx')
ort_session = ort.InferenceSession('model.onnx')def to_numpy(tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()outputs = ort_session.run(None, {ort_session.get_inputs()[0].name: to_numpy(dummy_input)})
部署代码:
from flask import Flask, request, jsonify
import onnxruntime as ort
import numpy as npapp = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.jsontext = data['text']inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=512)ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(inputs['input_ids'])}ort_outs = ort_session.run(None, ort_inputs)predictions = np.argmax(ort_outs[0], axis=1)return jsonify({'prediction': int(predictions[0])})if __name__ == '__main__':import onnxfrom transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained('bert-base-uncased')ort_session = ort.InferenceSession('model.onnx')app.run(host='0.0.0.0', port=5000)
优点:
- 跨平台兼容:支持多种深度学习框架,如 PyTorch、TensorFlow、Caffe2 等,使得模型可以在不同平台之间迁移。
- 统一格式:简化了在不同框架之间转换模型的复杂性。
缺点:
- 需要额外的工具链:需要使用 ONNX 工具来转换和部署模型,增加了一定的复杂性。
应用场景:
- 跨平台模型部署。
- 在不同框架之间转换模型。
4. TensorFlow Lite
简介:专门为移动和嵌入式设备设计的轻量级模型格式。
保存方式:
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open('model.tflite', 'wb') as f:f.write(tflite_model)
加载方式:
import tensorflow as tf
interpreter = tf.lite.Interpreter(model_path='model.tflite')
interpreter.allocate_tensors()
部署代码:
TensorFlow Lite 模型主要用于移动设备和嵌入式设备,下面是一个简化的示例,展示如何在 Python 环境中进行推理:
import tensorflow as tf
import numpy as np# 加载模型
interpreter = tf.lite.Interpreter(model_path='model.tflite')
interpreter.allocate_tensors()# 获取模型输入和输出的详细信息
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()# 准备输入数据
input_data = np.array([...], dtype=np.float32) # 根据模型输入需求准备数据# 设置模型输入
interpreter.set_tensor(input_details[0]['index'], input_data)# 推理
interpreter.invoke()# 获取输出数据
output_data = interpreter.get_tensor(output_details[0]['index'])
print(output_data)
优点:
- 轻量级:适合资源受限的设备,因为 TensorFlow Lite 模型被优化为更小、更高效。
- 快速加载和推理:由于优化了模型结构,推理速度更快。
缺点:
- 支持的操作有限:不支持所有 TensorFlow 操作,可能需要调整模型架构以适应 TensorFlow Lite 的限制。
应用场景:
- 移动设备上的应用。
- 物联网和嵌入式设备。
5. CoreML
简介:苹果公司为 iOS 和 macOS 设备提供的模型格式。
保存方式:
import coremltools as ct
coreml_model = ct.convert(model)
coreml_model.save('model.mlmodel')
加载方式:
在 iOS/macOS 应用中使用 CoreML 框架加载。
部署代码:
CoreML 模型主要用于 iOS 和 macOS 应用开发,下面是一个简化的示例,展示如何在 Swift 中使用 CoreML 模型进行推理:
import CoreML
import Foundation// 加载模型
let model = try! MyCoreMLModel(configuration: MLModelConfiguration())// 准备输入数据
let input = MyCoreMLModelInput(text: "your input text")// 获取模型预测结果
let prediction = try! model.prediction(input: input)
print(prediction.label)
优点:
- 与苹果生态系统深度集成:在 iOS 和 macOS 设备上运行非常高效,且与其他苹果生态系统的服务无缝集成。
- 易于部署:CoreML 模型可以直接在 Xcode 中使用,非常适合苹果开发者。
缺点:
- 仅限于苹果设备:无法在其他平台上运行,这限制了跨平台应用的开发。
应用场景:
- iOS 应用开发。
- macOS 应用开发。
6. PaddlePaddle (.pdparams)
简介:百度开发的深度学习框架 PaddlePaddle 的保存格式。
保存方式:
import paddle
paddle.save(model.state_dict(), 'model.pdparams')
加载方式:
model.set_state_dict(paddle.load('model.pdparams'))
部署代码:
from flask import Flask, request, jsonifyapp = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.jsontext = data['text']inputs = tokenizer(text, return_tensors='pd', truncation=True, padding=True, max_length=512)with paddle.no_grad():outputs = model(**inputs)logits = outputs.logitspredictions = paddle.argmax(logits, axis=-1)return jsonify({'prediction': predictions.item()})if __name__ == '__main__':from paddlenlp.transformers import BertTokenizer, BertForSequenceClassificationtokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertForSequenceClassification.from_pretrained('bert-base-uncased')model.set_state_dict(paddle.load('model.pdparams'))model.eval()app.run(host='0.0.0.0', port=5000)
优点:
- 与 PaddlePaddle 框架集成:适用于使用 PaddlePaddle 进行开发和部署的项目,提供了百度生态系统的支持。
- 优化的中国市场支持:PaddlePaddle 在中国市场有良好的支持和资源。
缺点:
- 只能在 PaddlePaddle 环境中加载和使用:这限制了在其他深度学习框架中的兼容性。
应用场景:
- 需要使用百度深度学习工具的项目。
- 在中国市场的应用。
7. HDF5 (.h5)
简介:一种用于存储大型数据集的文件格式,Keras 默认支持这种格式。
保存方式:
model.save('model.h5')
加载方式:
from tensorflow.keras.models import load_model
model = load_model('model.h5')
部署代码:
与 TensorFlow/Keras 的 .h5 部署代码相同,参考 TensorFlow/Keras 部分的部署代码。
优点:
- 方便存储和管理大型数据集:HDF5 格式擅长处理大规模数据,并支持压缩和并行 I/O 操作。
- 与 Keras 深度集成:Keras 默认支持这种格式,保存和加载模型非常方便。
缺点:
- 模型文件较大:包含了完整的模型架构和权重,导致文件较大,加载速度可能较慢。
应用场景:
- Keras 环境下的模型存储和加载。
- 需要保存大型模型的场景。
8. SafeTensors
简介:一种新型的格式,旨在提高模型保存和加载的安全性和速度。
保存方式:
from safetensors.torch import save_file
save_file(model.state_dict(), 'model.safetensors')
加载方式:
from safetensors.torch import load_file
state_dict = load_file('model.safetensors')
model.load_state_dict(state_dict)
部署代码:
与 PyTorch 部署代码类似,可使用 Flask 或其他框架创建 API 服务。
优点:
- 安全性高:消除潜在执行代码风险,因为
safetensors格式不允许在加载模型时执行任意代码。 - 加载速度快:优化了模型的加载速度,特别适用于大型模型。
缺点:
- 需要额外的库支持:必须安装
safetensors库才能使用这种格式。
应用场景:
- 需要高安全性和快速加载的环境。
- 大型模型的存储和部署。
汇总
下面是各深度学习模型保存和加载格式的汇总表,包括格式、简介、优点、缺点和应用场景:
| 格式 | 简介 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| PyTorch (.pth, .pt) | PyTorch 的默认保存格式,支持保存整个模型、权重和优化器状态 | 高度灵活,支持复杂的模型和训练过程。与 PyTorch 框架紧密集成。 | 只能在 PyTorch 环境中加载和使用,限制了跨平台和跨框架的兼容性。 | 研究和开发环境,频繁保存和加载模型的场景 |
| TensorFlow/Keras (.h5, SavedModel) | TensorFlow 和 Keras 的保存格式,支持保存模型的权重、架构和优化器状态 | 适用于 TensorFlow 和 Keras 环境,支持多种部署方式(如 TensorFlow Serving)。 | 模型文件较大,可能影响加载速度。 | 生产环境中的模型部署,与 TensorFlow 生态系统集成的应用 |
| ONNX | 开放格式,实现不同深度学习框架之间的互操作性 | 跨平台兼容,支持多种深度学习框架。统一格式,简化了在不同框架之间转换模型的复杂性。 | 需要额外的工具链来转换和部署模型。 | 跨平台模型部署,在不同框架之间转换模型 |
| TensorFlow Lite | 专为移动和嵌入式设备设计的轻量级模型格式 | 轻量级,适合资源受限的设备。快速加载和推理。 | 支持的操作有限,可能需要调整模型架构以适应 TensorFlow Lite 的限制。 | 移动设备上的应用,物联网和嵌入式设备 |
| CoreML | 苹果公司为 iOS 和 macOS 设备提供的模型格式 | 与苹果生态系统深度集成,在 iOS 和 macOS 设备上运行非常高效。易于部署,适合苹果开发者。 | 仅限于苹果设备,无法在其他平台上运行。 | iOS 应用开发,macOS 应用开发 |
| PaddlePaddle (.pdparams) | 百度开发的深度学习框架 PaddlePaddle 的保存格式 | 与 PaddlePaddle 框架集成,适用于百度生态系统。优化的中国市场支持。 | 只能在 PaddlePaddle 环境中加载和使用,限制了在其他深度学习框架中的兼容性。 | 使用百度深度学习工具的项目,在中国市场的应用 |
| HDF5 (.h5) | 一种用于存储大型数据集的文件格式,Keras 默认支持这种格式 | 方便存储和管理大型数据集,HDF5 格式擅长处理大规模数据,并支持压缩和并行 I/O 操作。与 Keras 深度集成。 | 模型文件较大,包含了完整的模型架构和权重,加载速度可能较慢。 | Keras 环境下的模型存储和加载,需要保存大型模型的场景 |
| SafeTensors | 一种新型格式,提高模型保存和加载的安全性和速度 | 安全性高,消除潜在执行代码风险。加载速度快,特别适用于大型模型。 | 需要额外的库支持,必须安装 safetensors 库才能使用这种格式。 | 需要高安全性和快速加载的环境,大型模型的存储和部署 |
希望这张表格能够帮助新手朋友们更好地理解不同格式的特点,并根据自己的需求选择合适的格式来保存和部署模型。
相关文章:

深度学习 - 模型的保存与部署方式汇总
深度学习模型保存和加载格式科普 在深度学习中,模型的保存和加载是非常重要的环节。不同的格式有不同的特点和适用场景。本文将为新手朋友们介绍几种常见的模型格式,包括它们的简介、保存方式、加载方式、优缺点以及应用场景。 1. PyTorch (.pth, .pt)…...

人工智能对网络安全有何影响?
人工智能网络安全在短期、中期和长期如何变化 当今数字时代网络安全的重要性 在谈论人工智能在网络安全中的作用时,必须首先考虑短期影响,因为它们是最明显的,而且它是一个未知的领域,需要超越直接炒作的能力。 因此࿰…...

Oracle的RECYCLEBIN回收站:轻松恢复误删对象
目录 Oracle的RECYCLEBIN回收站:轻松恢复误删对象一、概念二、工作原理三、使用方法1 查看回收站中的对象2 恢复回收站中的对象2.1 恢复表(TABLE)2.2 恢复索引(INDEX)2.3 恢复视图(VIEW)2.4 恢复…...
)
Android 内存原理详解以及优化(二)
上一篇讲了内存原理,如果还没看可以先看上一篇:Android 内存原理详解以及优化(一) 这一篇我总结一下我们经常遇到的内存优化问题: 1.内存抖动 自定义view的ondraw是会被频繁调用的,那在这个方法里面就不能频…...

Shell学习——Shell变量
文章目录 Shell变量使用变量只读变量删除变量变量类型字符串变量: 在 Shell中,变量通常被视为字符串。整数变量: 在一些Shell中,你可以使用 declare 或 typeset 命令来声明整数变量。数组变量: Shell 也支持数组&#…...
)
Java中的持续集成与持续部署(CI/CD)
Java中的持续集成与持续部署(CI/CD) 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨Java中的持续集成(Co…...

极狐GitLab 将亮相2024空天信息大会暨数字地球生态峰会,携手中科星图赋能空天行业开发者
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab :https://gitlab.cn/install?channelcontent&utm_sourcecsdn 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署…...

Beats:使用 Filebeat 从 Python 应用程序中提取日志
本指南演示了如何从 Python 应用程序中提取日志并将其安全地传送到 Elasticsearch Service 部署中。你将设置 Filebeat 来监控具有标准 Elastic Common Schema (ECS) 格式字段的 JSON 结构日志文件,然后你将在 Kibana 中查看日志事件发生的实时可视化。虽然此示例使…...
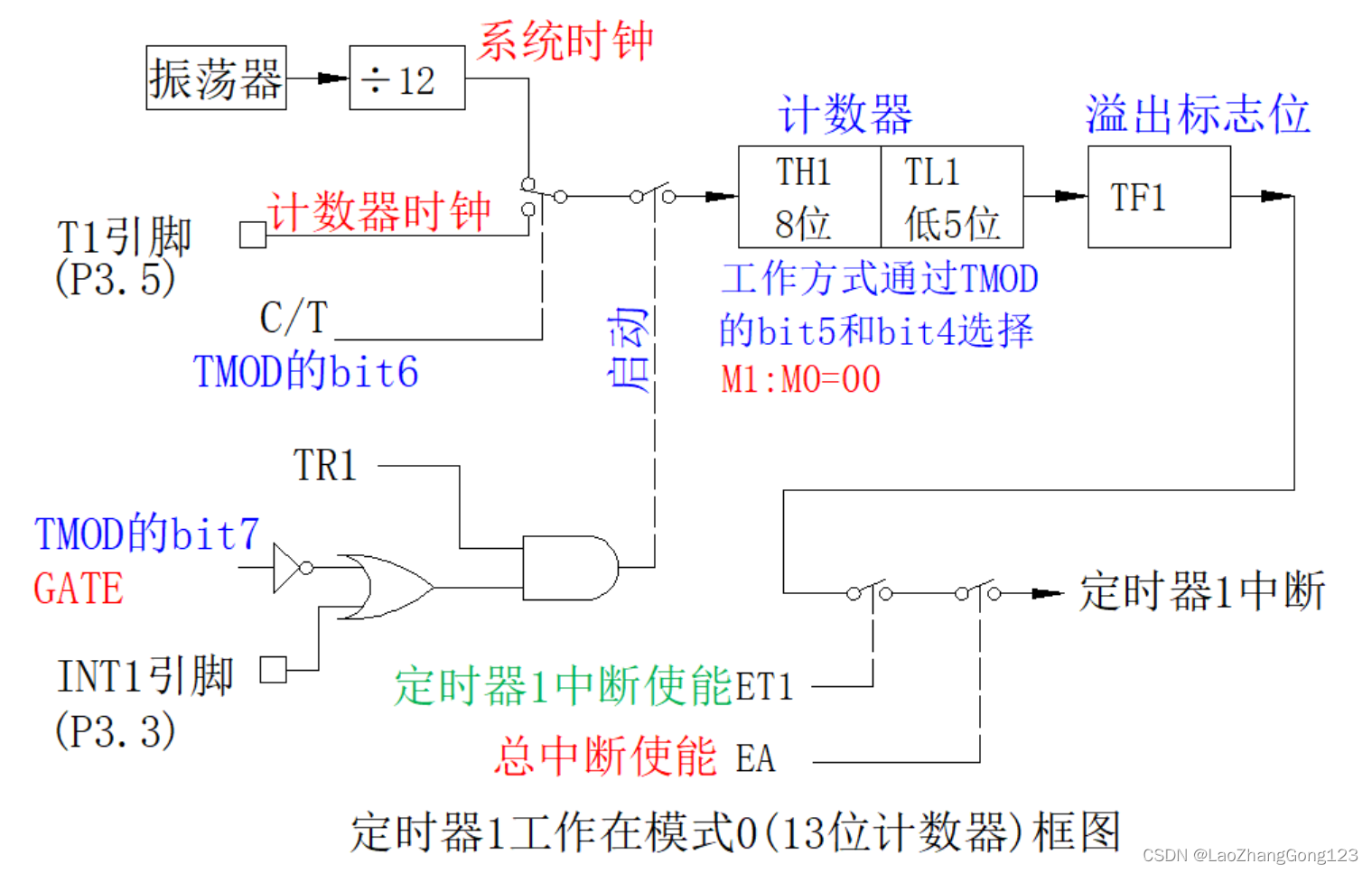
51单片机第23步_定时器1工作在模式0(13位定时器)
重点学习51单片机定时器1工作在模式0的应用。 在51单片机中,定时器1工作在模式0,它和定时器0一样,TL1占低5位,TH1占高8位,合计13位,也是向上计数。 1、定时器1工作在模式0 1)、定时器1工作在模式0的框图…...

linux的服务管理
systemd systemd 是一个系统和服务管理器,用于Linux操作系统中,旨在替代传统的Unix系统V初始化系统(SysV init)。 不一定所有使用 yum 安装的软件都可以通过 systemctl start 来管理。能否通过 systemctl start 管理取决于软件包…...

动手学深度学习(Pytorch版)代码实践 -循环神经网络-53语言模型和数据集
53语言模型和数据集 1.自然语言统计 引入库和读取数据: import random import torch from d2l import torch as d2l import liliPytorch as lp import numpy as np import matplotlib.pyplot as plttokens lp.tokenize(lp.read_time_machine())一元语法…...
)
Python 学习之自动化运维技术(八)
Python 的自动化运维技术 Python的自动化运维技术是指利用Python编程语言和相关工具实现运维工作的自动化,以提高效率、减轻工作负担。以下是对Python自动化运维技术的清晰归纳和详细介绍: 一、自动化运维的核心优势 ● 提高效率:通过自动化脚…...

【python】PyQt5可视化开发,如何设计鼠标显示的形状?
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

利用大模型知识库,优化智能客服问答效果 | 创新场景
ITValue 痛点 SSC( Share Service Center ,共享服务中心)是企业日常接触最多的场景之一,更多是对内服务,包括 HR 、财务、IT 等。该场景对专业度要求非常高,知识点非常多,对于知识的使用者或者查…...

物联网协议都包含哪些协议?
物联网协议是物联网生态系统中不可或缺的组成部分,它们负责处理和协调物联网设备之间的通信。具体介绍如下: Ethernet:以太网是一种有线网络协议,广泛应用于局域网络(LAN)中,提供稳定的高速数据传输。Wi-Fi࿱…...
】)
面试专区|【52道微服务架构高频题整理(附答案背诵版)】
简述什么是微服务? 微服务是一种软件架构风格,它将应用程序拆分成一系列小型、独立的服务,每个服务都运行在其自己的进程中,通过轻量级通信机制进行通信。每个服务都具有明确的业务能力,并且可以独立开发、测试、部署…...

数据结构之算法的时间复杂度
1.时间复杂度的定义 在计算机科学中,算法的时间复杂度是一个函数,它定量描述了算法的运行时间。一个算法所花费的时间与其中语句的执行次数成正比列,算法中的基本操作的执行次数,为算法的时间复杂度 例1: 计算Func1…...

unity中物体被激活自动执行挂载代码
在Unity中,如果希望当物体被激活时自动执行特定的函数,可以利用 MonoBehaviour 的生命周期函数 OnEnable()。这个方法会在对象被激活时调用,可以用来执行初始化或者处理其他逻辑。以下是如何在脚本中使用 OnEnable() 方法: using UnityEngine;public class ActivateFuncti…...

Pandas数据可视化详解:大案例解析(第27天)
系列文章目录 Pandas数据可视化解决不显示中文和负号问题matplotlib数据可视化seaborn数据可视化pyecharts数据可视化优衣库数据分析案例 文章目录 系列文章目录前言1. Pandas数据可视化1.1 案例解析:代码实现 2. 解决不显示中文和负号问题3. matplotlib数据可视化…...

Redis基础教程(七):redis列表(List)
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝Ὁ…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...