【PYG】dataloader和densedataloader
DenseDataLoader 是专门用于处理稠密图数据的,而 DataLoader 通常用于处理稀疏图数据。两者的主要区别在于它们的输入数据格式和处理方式。DenseDataLoader 适合处理固定大小的邻接矩阵和节点特征矩阵的数据,而 DataLoader 更加灵活,可以处理稀疏表示的图数据。
主要区别
-
DataLoader:- 适合处理稀疏图数据。
- 通常与
torch_geometric.data.Data一起使用,其中边索引是稀疏表示的。 - 更加灵活,适合处理各种不同形状和大小的图。
-
DenseDataLoader:- 适合处理稠密图数据。
- 通常与固定大小的邻接矩阵和节点特征矩阵一起使用。
- 更高效地处理固定大小的图数据。
使用示例
使用 DenseDataLoader
如果你有固定大小的邻接矩阵和节点特征矩阵,可以直接使用 DenseDataLoader 加载数据:
1. 导入必要的库
import torch
from torch_geometric.data import Data
from torch_geometric.loader import DenseDataLoader
2. 定义数据集类
class MyDenseDataset(torch.utils.data.Dataset):def __init__(self, num_samples, num_nodes, num_node_features):self.num_samples = num_samplesself.num_nodes = num_nodesself.num_node_features = num_node_featuresself.adj_matrix = self.create_adj_matrix(num_nodes)def create_adj_matrix(self, num_nodes):# 创建环形图的邻接矩阵adj_matrix = torch.zeros((num_nodes, num_nodes), dtype=torch.float)for i in range(num_nodes):adj_matrix[i, (i + 1) % num_nodes] = 1adj_matrix[(i + 1) % num_nodes, i] = 1return adj_matrixdef __len__(self):return self.num_samplesdef __getitem__(self, idx):# 创建随机特征和标签x = torch.randn((self.num_nodes, self.num_node_features))y = torch.randn((self.num_nodes, 1)) # 每个节点一个标签return Data(x=x, adj=self.adj_matrix, y=y)
3. 创建数据集和封装数据
# 参数设置
num_samples = 100 # 样本数
num_nodes = 10 # 每个图中的节点数
num_node_features = 8 # 每个节点的特征数# 创建数据集
dataset = MyDenseDataset(num_samples, num_nodes, num_node_features)
4. 使用 DenseDataLoader
# 使用 DenseDataLoader 加载数据
loader = DenseDataLoader(dataset, batch_size=32, shuffle=True)# 从 DenseDataLoader 中获取一个批次的数据并查看其形状
for data in loader:print("Batch node features shape:", data.x.shape) # 期望输出形状为 (32, 10, 8)print("Batch adjacency matrix shape:", data.adj.shape) # 期望输出形状为 (32, 10, 10)print("Batch labels shape:", data.y.shape) # 期望输出形状为 (32, 10, 1)break # 仅查看第一个批次的形状解释
-
导入库:
- 导入
torch、torch_geometric.data中的Data和torch_geometric.loader中的DenseDataLoader。
- 导入
-
定义
MyDenseDataset类:__init__方法初始化数据集参数,并创建邻接矩阵。create_adj_matrix方法创建环形图的邻接矩阵。__len__方法返回数据集的样本数量。__getitem__方法生成每个样本的随机节点特征和标签,并返回节点特征矩阵、邻接矩阵和标签。
-
创建数据集:
- 使用
MyDenseDataset类创建一个包含 100 个样本的数据集,每个样本包含 10 个节点,每个节点有 8 个特征。
- 使用
-
使用
DenseDataLoader:- 使用
DenseDataLoader加载dataset,设置批次大小为 32,并进行随机打乱。 - 在获取一个批次的数据时,检查
x、adj和y的形状,以确保其符合期望的三维形状。
- 使用
通过这个完整的示例代码,你可以生成、封装和加载稠密图数据,并确保每个批次的数据形状保持正确。这种方法适合处理节点数和边数固定的图数据,提高数据加载和处理的效率。
定义数据集类并使用 DenseDataLoader
import torch
from torch_geometric.data import Data
from torch_geometric.loader import DenseDataLoader # 更新导入路径class MyDenseDataset(torch.utils.data.Dataset):def __init__(self, num_samples, num_nodes, num_node_features):self.num_samples = num_samplesself.num_nodes = num_nodesself.num_node_features = num_node_featuresself.adj_matrix = self.create_adj_matrix(num_nodes)def create_adj_matrix(self, num_nodes):# 创建环形图的邻接矩阵adj_matrix = torch.zeros((num_nodes, num_nodes), dtype=torch.float)for i in range(num_nodes):adj_matrix[i, (i + 1) % num_nodes] = 1adj_matrix[(i + 1) % num_nodes, i] = 1print(adj_matrix)return adj_matrixdef __len__(self):return self.num_samplesdef __getitem__(self, idx):# 创建随机特征和标签x = torch.randn((self.num_nodes, self.num_node_features))y = torch.randn((self.num_nodes, 1)) # 每个节点一个标签return Data(x, self.adj_matrix, y=y)# 创建数据集
num_samples = 100 # 样本数
num_nodes = 10 # 每个图中的节点数
num_node_features = 8 # 每个节点的特征数
dataset = MyDenseDataset(num_samples, num_nodes, num_node_features)# 使用 DenseDataLoader 加载数据
loader = DenseDataLoader(dataset, batch_size=32, shuffle=True)# 从 DenseDataLoader 中获取一个批次的数据并查看其形状
for data in loader:print("Batch node features shape:", data.x.shape) # 期望输出形状为 (32, 10, 8)# print("Batch adjacency matrix shape:", data.adj.shape) # 期望输出形状为 (32, 10, 10)print("Batch labels shape:", data.y.shape) # 期望输出形状为 (32, 10, 1)break # 仅查看第一个批次的形状使用 DataLoader
如果你使用的是 DataLoader,则数据应当是 torch_geometric.data.Data 对象,并将数据封装在列表中:
import torch
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader # 更新导入路径class MyDataset(torch.utils.data.Dataset):def __init__(self, num_samples, num_nodes, num_node_features):self.num_samples = num_samplesself.num_nodes = num_nodesself.num_node_features = num_node_featuresdef __len__(self):return self.num_samplesdef __getitem__(self, idx):x = torch.randn(self.num_nodes, self.num_node_features)edge_index = torch.tensor([[i, (i + 1) % self.num_nodes] for i in range(self.num_nodes)], dtype=torch.long).t().contiguous()y = torch.randn(self.num_nodes, 1)return Data(x=x, edge_index=edge_index, y=y)# 创建数据集
num_samples = 100 # 样本数
num_nodes = 10 # 每个图中的节点数
num_node_features = 8 # 每个节点的特征数
dataset = MyDataset(num_samples, num_nodes, num_node_features)# 使用 DataLoader 加载数据
loader = DataLoader(dataset, batch_size=32, shuffle=True)# 迭代加载数据
for batch in loader:print("Batch node features shape:", batch.x.shape) # 期望输出形状为 (320, 8)print("Batch edge index shape:", batch.edge_index.shape)
总结
DenseDataLoader:处理固定大小的邻接矩阵和节点特征矩阵的数据,__getitem__返回Data(x, adj, y)。DataLoader:处理torch_geometric.data.Data对象,__getitem__返回一个Data对象。
确保数据格式与使用的加载器相匹配,以避免属性错误和其他兼容性问题。
相关文章:

【PYG】dataloader和densedataloader
DenseDataLoader 是专门用于处理稠密图数据的,而 DataLoader 通常用于处理稀疏图数据。两者的主要区别在于它们的输入数据格式和处理方式。DenseDataLoader 适合处理固定大小的邻接矩阵和节点特征矩阵的数据,而 DataLoader 更加灵活,可以处理…...
: Access denied for user ‘root‘@‘localhost‘ (using password: NO))
完美解决ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: NO)
已解决ERROR 1045 (28000): Access denied for user ‘root‘‘localhost‘ (using password: NO) 下滑查看解决方法 文章目录 报错问题解决思路解决方法交流 报错问题 ERROR 1045 (28000): Access denied for user ‘root‘‘localhost‘ (using password: NO) 解决思路 对…...

ForkJoinPool 简介
引言 在现代并行编程中,处理大规模任务时将任务分割成更小的子任务并行执行是一种常见的策略。Java 提供了 Fork/Join 框架来支持这一模式,其中 ForkJoinPool 是其核心组件。本文将详细介绍 ForkJoinPool 的概念、使用方法和实际应用。 1. ForkJoinPoo…...

复现YOLO_ORB_SLAM3_with_pointcloud_map项目记录
文章目录 1.环境问题2.遇到的问题2.1编译问题1 monotonic_clock2.2 associate.py2.3 associate.py问题 3.运行问题 1.环境问题 首先环境大家就按照github上的指定环境安装即可 环境怎么安装网上大把的资源,自己去找。 2.遇到的问题 2.1编译问题1 monotonic_cloc…...

Docker:Docker网络
Docker Network 是 Docker 平台中的一项功能,允许容器相互通信以及与外界通信。它提供了一种在 Docker 环境中创建和管理虚拟网络的方法。Docker 网络使容器能够连接到一个或多个网络,从而使它们能够安全地共享信息和资源。 预备知识 推荐先看视频先有…...
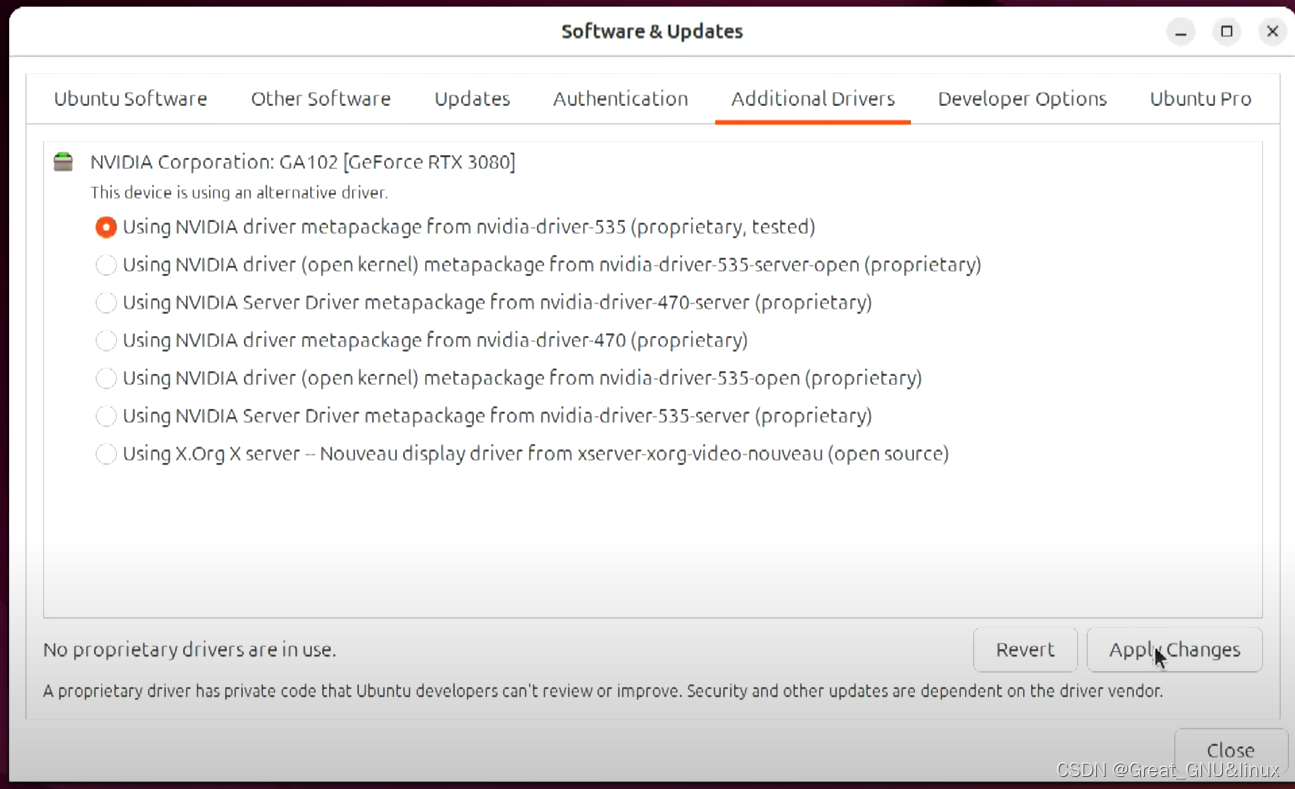
Ubuntu 24.04-自动安装-Nvidia驱动
教程 但在安全启动模式下可能会报错。 先在Nvidia官网找到GPU对应的驱动版, 1. 在软件与更新中选择合适的驱动 2. ubuntu自动安装驱动 sudo ubuntu-drivers autoinstall显示驱动 ubuntu-drivers devices3. 安装你想要的驱动 sudo apt install nvidia-driver-ve…...

【CSAPP】-attacklab实验
目录 实验目的与要求 实验原理与内容 实验设备与软件环境 实验过程与结果(可贴图) 实验总结 实验目的与要求 1. 强化机器级表示、汇编语言、调试器和逆向工程等方面基础知识,并结合栈帧工作原理实现简单的栈溢出攻击,掌握其基…...

docker部署onlyoffice,开启JWT权限校验Token
原来的部署方式 之前的方式是禁用了JWT: docker run -itd -p 8080:80 --name docserver --network host -e JWT_ENABLEDfalse --restartalways onlyoffice/documentserver:8 新的部署方式 参考文档:https://helpcenter.onlyoffice.com/installation/…...

Hive排序字段解析
Hive排序字段解析 在Hive中,CLUSTER BY、DISTRIBUTE BY、SORT BY和ORDER BY是用于数据分发和排序的关键子句,它们各自有不同的用途和性能特点。让我们逐一解析这些子句: 1. DISTRIBUTE BY 用途: 主要用于控制如何将数据分发到Reducer。它可…...

3101.力扣每日一题7/6 Java(接近100%解法)
博客主页:音符犹如代码系列专栏:算法练习关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 目录 思路 解题方法 时间复杂度 空间复杂度 Code 思路 主要是基于对…...

virtualbox窗口和win10窗口的切换
1、问题: 从windows切换到虚拟机可以用快捷键 ALTTAB,但是从虚拟机到windows使用 ALTTAB 无法成功切换 2、解决方法: 按下图操作 按上面步骤设置之后,每次要从虚拟机窗口切换到windows窗口 只需要先按 CtrlAlt 跳出虚拟机窗口&…...

卫星轨道平面简单认识
目录 一、轨道平面 1.1 轨道根数 1.2 应用考虑 二、分类 2.1 根据运行高度 2.2 根据运行轨迹偏心率 2.3 根据倾角大小 三、卫星星座中的轨道平面 四、设计轨道平面的考虑因素 一、轨道平面 1.1 轨道根数 轨道平面是定义卫星或其他天体绕行另一天体运动的平面。这个平…...

IP-Guard定制函数配置说明
设置客户端配置屏蔽: 关键字:disfunc_austascrtrd 内容:1 策略效果:屏幕整个屏幕监控模块。会导致屏幕历史查询这个功能也不能使用。 security_proxy1 安全代理参数 safe_enforce_authproc进程 强制软件上 安全代理网关…...

C++常用类
C常用类 1. std::string类2. std::vector 类2.1 特性2.2 用法 1. std::string类 std::string 是 C 标准库中的一个类,用于处理字符串。它提供了许多方法来创建、操作和管理字符串,如连接、查找、比较、替换和分割等操作。std::string 类定义在 头文件中…...
)
React Hooks --- 分享自己开发中常用的自定义的Hooks (1)
为什么要使用自定义 Hooks 自定义 Hooks 是 React 中一种复用逻辑的机制,通过它们可以抽离组件中的逻辑,使代码更加简洁、易读、易维护。它们可以在多个组件中复用相同的逻辑,减少重复代码。 1、useThrottle 代码 import React,{ useRef,…...
uniapp H5页面设置跨域请求
记录一下本地服务在uniapp H5页面访问请求报跨域的错误 这是我在本地起的服务端口号为8088 ip大家可打开cmd 输入ipconfig 查看 第一种方法 在源码视图中配置 "devServer": {"https": false, // 是否启用 https 协议,默认false"port&q…...
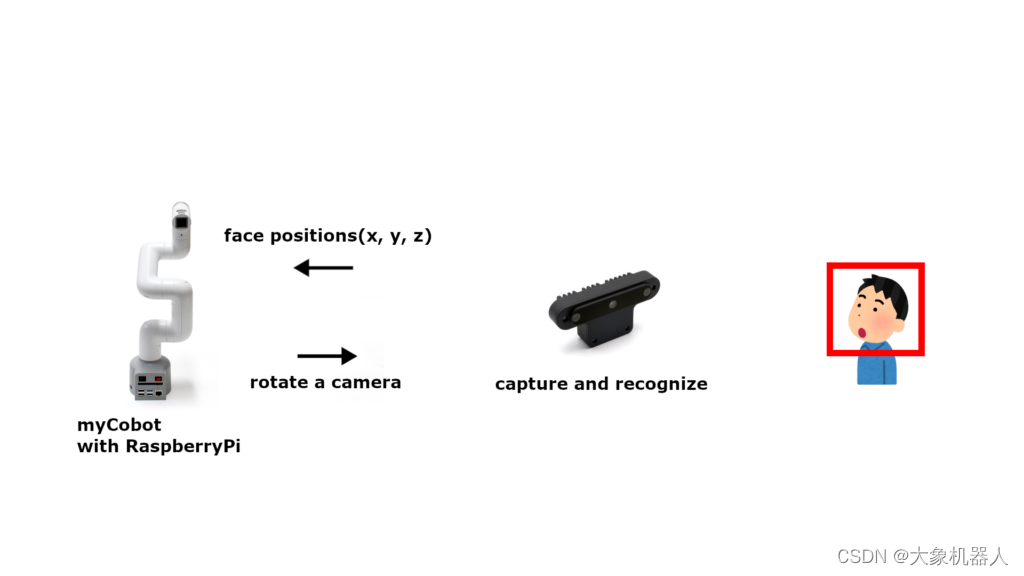
使用myCobot280和OAK-D OpenCV DepthAI摄像头制作一个实时脸部跟踪的手机支架!
引言 由于YouTube和Netflix的出现,我们开始躺着看手机。然而,长时间用手拿着手机会让人感到疲劳。这次我们制作了一个可以在你眼前保持适当距离并调整位置的自动移动手机支架,让你无需用手拿着手机。请务必试试! 准备工作 这次我们…...
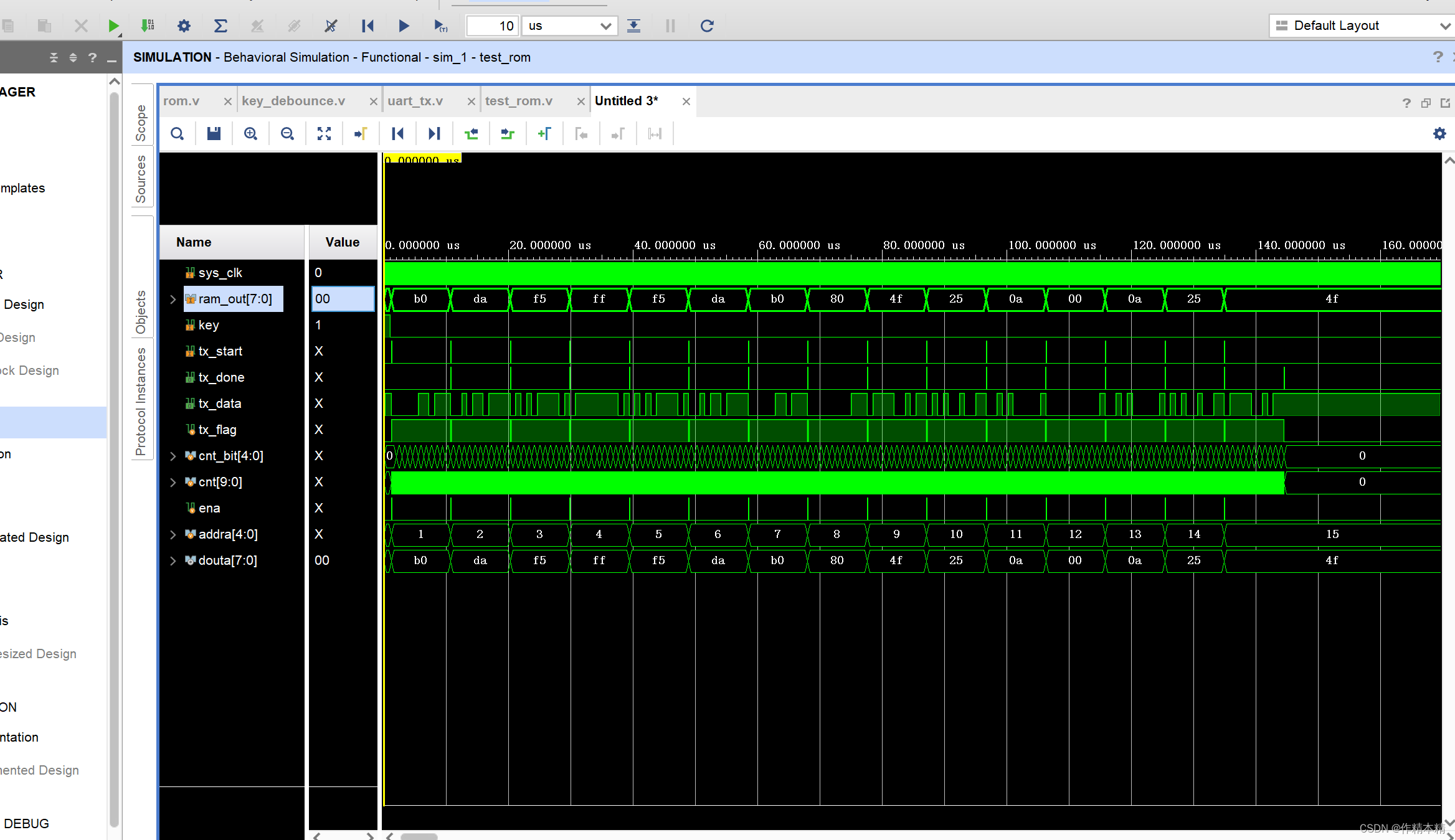
Xilinx FPGA:vivado关于单端ROM的一个只读小实验
一、实验要求 将生成好的voe文件里的数据使用rom读取出来,采用串口工具发送给电脑(当按键来临时)。 二、程序设计 按键消抖模块: timescale 1ns / 1ps module key_debounce(input sys_clk ,input rst_n…...

集成学习(一)Bagging
前边学习了:十大集成学习模型(简单版)-CSDN博客 Bagging又称为“装袋法”,它是所有集成学习方法当中最为著名、最为简单、也最为有效的操作之一。 在Bagging集成当中,我们并行建立多个弱评估器(通常是决策…...

Docker 中查看及修改 Redis 容器密码的实用指南
在使用 Docker 部署 Redis 容器时,有时我们需要查看或修改 Redis 的密码。本文将详细介绍如何在 Docker 中查看和修改 Redis 容器的密码,帮助你更好地管理和维护你的 Redis 实例。 一、查看 Redis 容器密码 通常在启动 Redis 容器时,我们会…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

【Midjourney霓虹效果终极指南】:20年AI视觉工程师亲授5大参数组合+3类光源建模公式,97%新手一周内复刻赛博朋克海报
更多请点击: https://kaifayun.com 第一章:霓虹美学的视觉原理与Midjourney适配性解析 霓虹美学源于20世纪都市夜景中的荧光灯管、电子广告与赛博朋克文化,其核心视觉特征包括高饱和度冷暖对比、边缘辉光(glow)、深色…...

Unity动态植被系统:实时天气与自然现象耦合方案
1. 这不是“贴图堆砌”,而是一套可交互的自然系统你有没有试过在Unity里拖进几棵树、铺点草地,结果运行起来——风一吹,所有树叶像被钉在空中一样纹丝不动;下雨时,雨滴垂直砸进地面,连个水花都没有…...

中兴新支点NewStartOS初体验:从激活到日常使用,聊聊这个国产Linux桌面的真实感受
中兴新支点NewStartOS深度体验:一个技术爱好者的真实使用笔记第一次启动中兴新支点NewStartOS时,那个简洁的登录界面就给我留下了不错的印象。作为一个长期在Windows和macOS之间切换的用户,这次尝试国产Linux桌面系统,更像是一次充…...

Python之encode-cli包语法、参数和实际应用案例
Python encode-cli包完整使用指南 encode-cli 是Python生态中轻量、高效的命令行编码/解码工具包,专注于提供主流编码格式的快速转换,支持命令行直接调用,无需编写复杂Python代码,适用于数据加密、文本转码、URL处理、Base64转换等…...

Wand-Enhancer:3步解锁WeMod专业版功能的完整用户指南
Wand-Enhancer:3步解锁WeMod专业版功能的完整用户指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否厌倦了WeMod免费版的种种限制&a…...