[单master节点k8s部署]20.监控系统构建(五)Alertmanager
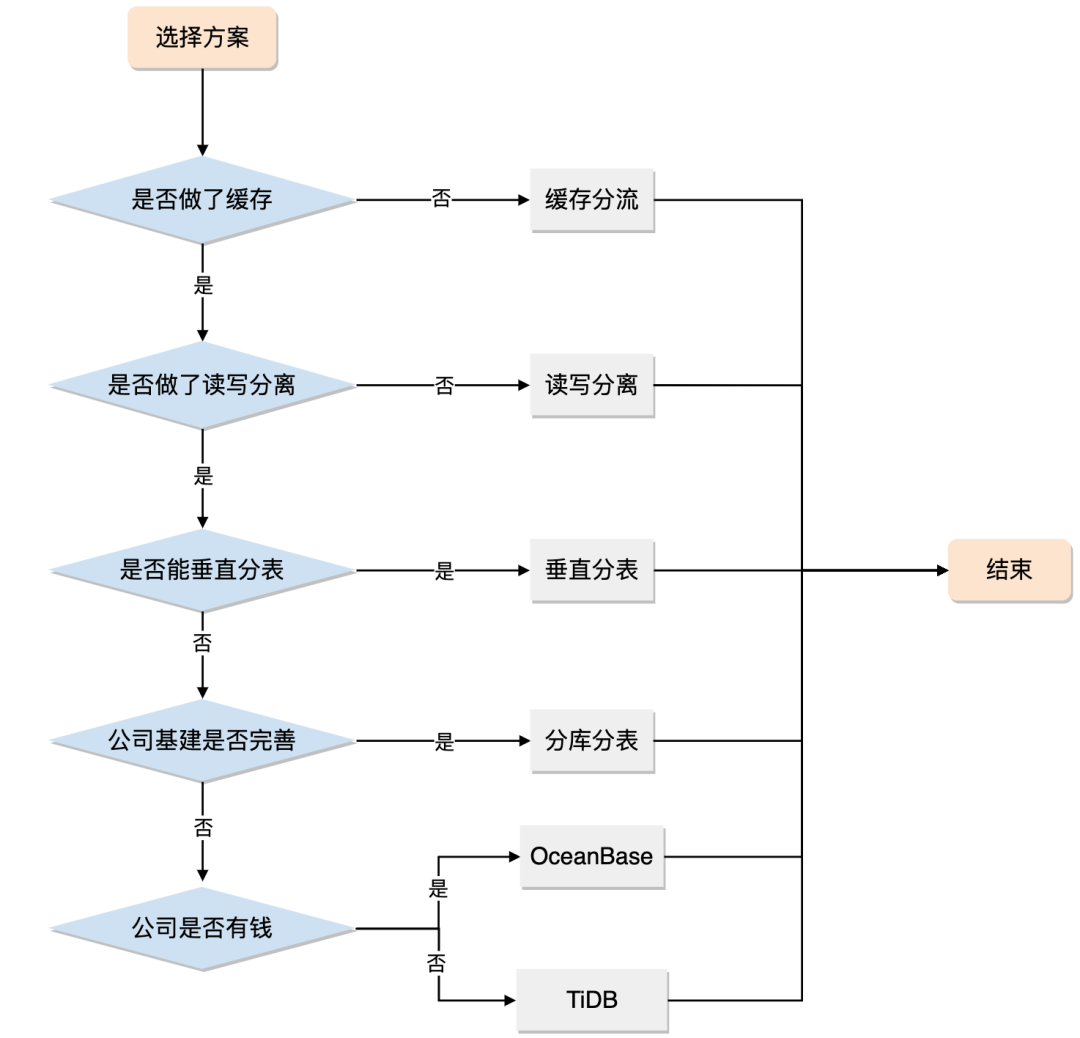
prometheus将监控到的异常事件发送给Alertmanager,然后Alertmanager将报警信息发送到邮箱等设备。可以从下图看出,push alerts是由Prometheus发起的。

安装Alertmanager
config文件
[root@master prometheus]# cat alertmanager-cm.yaml
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: monitor-sa
data:alertmanager.yml: |-global:resolve_timeout: 1msmtp_smarthost: 'smtp.qq.com:465'smtp_from: '147359****@qq.com'smtp_auth_username: '1123345555'smtp_auth_password: 'pytoinoomgvxiaag'smtp_require_tls: falseroute:group_by: [alertname]group_wait: 10sgroup_interval: 10srepeat_interval: 10mreceiver: default-receiverreceivers:- name: 'default-receiver'email_configs:- to: 'xisdgsgs@163.com'send_resolved: true
随后生效,可以查看configmap清单。
[root@master prometheus]# kubectl get configmap -n monitor-sa
NAME DATA AGE
alertmanager 1 2m8s
kube-root-ca.crt 1 2d10h
prometheus-config 1 36h
报警流程
Prometheus的处理:
- 数据采集:Prometheus Server 定期从配置的监控目标(比如某个 HTTP 接口)采集数据。采集间隔由
scrape_interval控制。 - Pending 状态:当警报条件首次被满足时,警报会进入“Pending”状态。这是一个预备状态,用于确保问题是持续存在的,而不是暂时性的或偶然的。
for语句在警报规则中定义了需要持续触发该条件多长时间后,警报才会进入下一个状态。 - Firing 状态:如果问题在设定的
for时间内持续存在,警报状态会转变为“Firing”。这意味着警报被认为是有效的,需要通知到相关人员或系统。 - 报警发送:进入“Firing”状态后,警报信息会发送到 Alertmanager。
Alertmanager 的处理:
- Alertmanager 接收到 FIRING 状态的报警后,会根据报警信息进行分组,并根据配置的
group_wait延迟一段时间后开始处理报警。
Prometheus报警规则
从上面的流程可以看出来,报警规则是Prometheus设置的。设置一个config文件
[root@master ~]# cat prometheus-alertmanager-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |rule_files:- /etc/prometheus/rules.ymlalerting:alertmanagers:- static_configs:- targets: ["localhost:9093"]global:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name - job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- job_name: 'kubernetes-schedule'scrape_interval: 5sstatic_configs:- targets: ['192.168.40.180:10251']- job_name: 'kubernetes-controller-manager'scrape_interval: 5sstatic_configs:- targets: ['192.168.40.180:10252']- job_name: 'kubernetes-kube-proxy'scrape_interval: 5sstatic_configs:- targets: ['192.168.40.180:10249','192.168.40.181:10249']- job_name: 'kubernetes-etcd'scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crtcert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crtkey_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.keyscrape_interval: 5sstatic_configs:- targets: ['192.168.40.180:2379']
data:
prometheus.yml: |
rule_files:
- /etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
这一段是基本配置信息,配置Prometheus的文件路径,以及在报警的时候,prometheus是向localhost的9093端口报警,我们将会把alartManager安装到与Prometheus相同的pod,因此使用localhost就可以通信。
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.180:10251']
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.180:10252']
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.180:10249','192.168.40.181:10249']
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
- targets: ['192.168.40.180:2379']
相比于CSDN 中的Prometheus 规则,这里新增了一些关于kube-controller和scheduler的规则,但是需要查看具体的开放端口,还要把这里的地址改为本机地址。
但是由于现在controller和scheduler已经不开放metrics端口,所以现在无法通过Prometheus监听。
这里需要额外的精力解决。
rules.yml: |groups:- name: examplerules:- alert: kube-proxy的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: kube-proxy的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: scheduler的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: scheduler的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: controller-manager的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: controller-manager的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: apiserver的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: apiserver的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: etcd的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: etcd的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: kube-state-metrics的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: coredns的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: coredns的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: kube-proxy打开句柄数>600expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kube-proxy打开句柄数>1000expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>600expr: process_open_fds{job=~"kubernetes-schedule"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>1000expr: process_open_fds{job=~"kubernetes-schedule"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>600expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>1000expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>600expr: process_open_fds{job=~"kubernetes-apiserver"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>1000expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>600expr: process_open_fds{job=~"kubernetes-etcd"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>1000expr: process_open_fds{job=~"kubernetes-etcd"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 600for: 2slabels:severity: warnning annotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 1000for: 2slabels:severity: criticalannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"value: "{{ $value }}"- alert: kube-proxyexpr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: schedulerexpr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-controller-managerexpr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-apiserverexpr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-etcdexpr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kube-dnsexpr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000for: 2slabels:severity: warnningannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: HttpRequestsAvgexpr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"value: "{{ $value }}"threshold: "1000" - alert: Pod_restartsexpr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0for: 2slabels:severity: warnningannotations:description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"value: "{{ $value }}"threshold: "0"- alert: Pod_waitingexpr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"value: "{{ $value }}"threshold: "1" - alert: Pod_terminatedexpr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"value: "{{ $value }}"threshold: "1"- alert: Etcd_leaderexpr: etcd_server_has_leader{job="kubernetes-etcd"} == 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"value: "{{ $value }}"threshold: "0"- alert: Etcd_leader_changesexpr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"value: "{{ $value }}"threshold: "0"- alert: Etcd_failedexpr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"value: "{{ $value }}"threshold: "0"- alert: Etcd_db_total_sizeexpr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"value: "{{ $value }}"threshold: "10G"- alert: Endpoint_readyexpr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"value: "{{ $value }}"threshold: "1"- name: 物理节点状态-监控告警rules:- alert: 物理节点cpu使用率expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90for: 2slabels:severity: ccriticalannotations:summary: "{{ $labels.instance }}cpu使用率过高"description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 2slabels:severity: criticalannotations:summary: "{{ $labels.instance }}内存使用率过高"description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"- alert: InstanceDownexpr: up == 0for: 2slabels:severity: criticalannotations: summary: "{{ $labels.instance }}: 服务器宕机"description: "{{ $labels.instance }}: 服务器延时超过2分钟"- alert: 物理节点磁盘的IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 入网流量带宽expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入网络带宽过高!"description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: 出网流量带宽expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
可以看到报警信息有critical和warning两种。这里面的指标都来自于Prometheus监控到的指标。
相关文章:
[单master节点k8s部署]20.监控系统构建(五)Alertmanager
prometheus将监控到的异常事件发送给Alertmanager,然后Alertmanager将报警信息发送到邮箱等设备。可以从下图看出,push alerts是由Prometheus发起的。 安装Alertmanager config文件 [rootmaster prometheus]# cat alertmanager-cm.yaml kind: ConfigMa…...

用MySQL+node+vue做一个学生信息管理系统(四):制作增加、删除、修改的组件和对应的路由
1.下载依赖: npm install vue-router 在src目录下新建一个文件夹router,在router文件夹下新建一个文件router.js文件,在component目录下新建增加删除和修改的组件,引入router.js当中 此时的init组件为主页面((二、三&…...

磁盘就是一个超大的Byte数组,操作系统是如何管理的?
磁盘在操作系统的维度看,就是一个“超大的Byte数组”。 那么操作系统是如何对这块“超大的Byte数组”做管理的呢? 我们知道在逻辑上,上帝说是用“文件”的概念来进行管理的。于是,便有了“文件系统”。那么,文件系统…...

14-28 剑和诗人2 - 高性能编程Bend和Mojo
介绍: 在不断发展的计算世界中,软件和硬件之间的界限变得越来越模糊。随着我们不断突破技术可能性的界限,对能够利用现代硬件功能的高效、可扩展的编程语言的需求从未如此迫切。 Bend和 Mojo是编程语言领域的两种新秀,它们有望弥…...

Stable Diffusion:最全详细图解
Stable Diffusion,作为一种革命性的图像生成模型,自发布以来便因其卓越的生成质量和高效的计算性能而受到广泛关注。不同于以往的生成模型,Stable Diffusion在生成图像的过程中,采用了独特的扩散过程,结合深度学习技术…...

Apache Seata分布式事务之Seata-Client原理及流程详解
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 前言 在分布式系统中,分布式事务是一个必须要解决的问题,目前使用较多…...

Linux wget报未找到命令
wget报未找到命令需要安装wget 1、下载wget安装文件,本次于华为云资源镜像下载 地址:https://mirrors.huaweicloud.com/centos-vault/7.8.2003/os/x86_64/Packages/ 2、下载后上传到安装服务器/install_package,执行命令安装 rpm -ivh /i…...

38条Web测试经验分享
1. 页面链接检查 每一个链接是否都有对应的页面,并且页面之间切换正确。可以使用一些工具,如LinkBotPro、File-AIDCS、HTML Link Validater、Xenu等工具。 LinkBotPro不支持中文,中文字符显示为乱码;HTML Link Validater只能测…...

TCP报文校验和(checksum)计算
一. 原理 将TCP相关内容(TCP伪头部TCP头部TCP内容)转换成16比特的字符,然后进行累加,最后结果进行取反。TCP伪头部是固定的,下文有相关代码展示。 二. 源码 源码 #include <stdio.h> #include <stdlib.h&…...

【ue5】虚幻5同时开多个项目
正常开ue5项目我是直接在桌面点击快捷方式进入 只会打开一个项目 如果再想打开一个项目需要进入epic 再点击启动就可以再开一个项目了...
【Python实战因果推断】23_倾向分3
目录 Propensity Score Matching Inverse Propensity Weighting Propensity Score Matching 另一种控制倾向得分的常用方法是匹配估计法。这种方法搜索具有相似可观测特征的单位对,并比较接受干预与未接受干预的单位的结果。如果您有数据科学背景,您可…...

Qt源码解析之QObject
省去大部分virtual和public方法后,Qobject主要剩下以下成员: //qobject.h class Q_CORE_EXPORT Qobject{Q_OBJECTQ_PROPERTY(QString objectName READ objectName WRITE setObjectName NOTIFY objectNameChanged)Q_DECLARE_PRIVATE(QObject) public:Q_I…...

【算法专题】模拟算法题
模拟算法题往往不涉及复杂的数据结构或算法,而是侧重于对特定情景的代码实现,关键在于理解题目所描述的情境,并能够将其转化为代码逻辑。所以我们在处理这种类型的题目时,最好要现在演草纸上把情况理清楚,再动手编写代…...
分库分表真的适合你的系统吗?
曾几何时,“并发高就分库,数据大就分表”已经成了处理 MySQL 数据增长问题的圣经。 面试官喜欢问,博主喜欢写,候选人也喜欢背,似乎已经形成了一个闭环。 但你有没有思考过,分库分表真的适合你的系统吗&am…...

9 redis,memcached,nginx网络组件
课程目标: 1.网络模块要处理哪些事情 2.reactor是怎么处理这些事情的 3.reactor怎么封装 4.网络模块与业务逻辑的关系 5.怎么优化reactor? io函数 函数调用 都有两个作用:io检测 是否就绪 io操作 1. int clientfd = accept(listenfd, &addr, &len); 检测 全连接队列…...

【MySQL】事务四大特性以及实现原理
事务四大特性 原子性(Atomicity) 事务中的所有操作要么全部完成,要么全部不执行。如果事务中的任何一步失败,整个事务都会被回滚,以保持数据的完整性。 一致性(Consistency) 事务应确保数据库…...

【控制Android.bp的编译】
1.首先Android.bp的语法是不支持if 条件语句的 2.查到可以用enabled来控制Android.bp中的模块是否参与编译,但是并不能实现动态的控制,比如你需要根据获取到的安卓版本来控制一个Android.bp是否编译,是无法做到的。enabled只能是固定的true或…...
【车载开发系列】J-Link/JFlash 简介与驱动安装方法
【车载开发系列】J-Link/JFlash 简介与驱动安装方法 【车载开发系列】J-Link/JFlash 简介与驱动安装方法 【车载开发系列】J-Link/JFlash 简介与驱动安装方法一. 软件介绍二. 下载安装包二. 开始安装三. 确认安装四. J-Flash的使用 一. 软件介绍 J-Link是SEGGER公司为支持仿真…...

207 课程表
题目 你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。 在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。 …...

罗剑锋的C++实战笔记学习(一):const、智能指针、lambda表达式
1、const 1)、常量 const一般的用法就是修饰变量、引用、指针,修饰之后它们就变成了常量,需要注意的是const并未区分出编译期常量和运行期常量,并且const只保证了运行时不直接被修改 一般的情况,const放在左边&…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...