【Python实战因果推断】23_倾向分3
目录
Propensity Score Matching
Inverse Propensity Weighting
Propensity Score Matching
另一种控制倾向得分的常用方法是匹配估计法。这种方法搜索具有相似可观测特征的单位对,并比较接受干预与未接受干预的单位的结果。如果您有数据科学背景,您可以将匹配视为一种简单的 K 最近邻(KNN)算法,其中 K=1 。首先,使用倾向得分作为唯一特征,在接受治疗的单位上拟合一个 KNN 模型,并用它来推算对照组的 Y1。然后,在未治疗单位上拟合一个 KNN 模型,用它来推算治疗单位的 Y0。在这两种情况下,推算值都只是匹配单位的结果,而匹配是基于倾向得分的:
from sklearn.neighbors import KNeighborsRegressorT = "intervention"X = "propensity_score"Y = "engagement_score"treated = data_ps.query(f"{T}==1")untreated = data_ps.query(f"{T}==0")mt0 = KNeighborsRegressor(n_neighbors=1).fit(untreated[[X]],untreated[Y])mt1 = KNeighborsRegressor(n_neighbors=1).fit(treated[[X]], treated[Y])predicted = pd.concat([# find matches for the treated looking at the untreated knn modeltreated.assign(match=mt0.predict(treated[[X]])),# find matches for the untreated looking at the treated knn modeluntreated.assign(match=mt1.predict(untreated[[X]]))])predicted.head()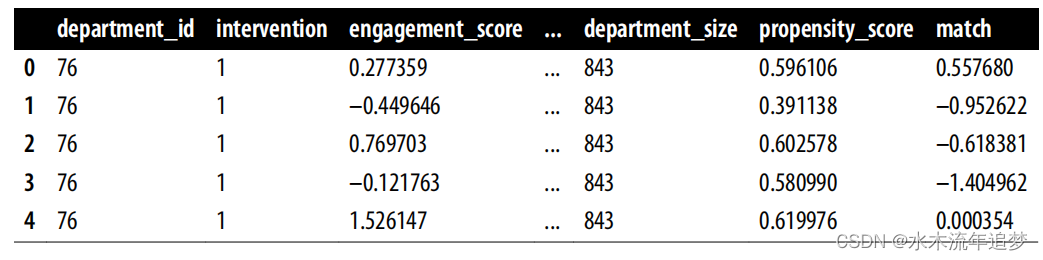
一旦你有了一个匹配的每个单位,你可以估计的ATE:
其中是治疗组不同于i的单位i的匹配值:
np.mean((predicted[Y] - predicted["match"])*predicted[T]+ (predicted["match"] - predicted[Y])*(1-predicted[T]))0.28777443474045966老实说,我不是这个估计器的忠实粉丝,第一,因为它有偏差;第二,因为它的方差很难推导;第三,因为我在数据科学方面的经验让我对 KNN 产生了怀疑,主要是因为它在处理高维 X 时效率很低。我在这里教授这种方法,主要是因为它非常有名,你可能会在这里或那里看到它。
Inverse Propensity Weighting
还有一种被广泛使用的倾向得分利用方法,我认为它更可取--反倾向加权法(IPW)。这种方法根据干预的反概率对数据重新加权,可以使干预在重新加权的数据中看起来像是随机分配的。为此,我们通过 对样本进行重新加权,以创建一个伪人群,近似于如果每个人都接受了 t 治疗会发生的情况:
再说一遍,证明这一点并不复杂,但这不是重点。因此,让我们坚持直觉。假设你想知道 Y1 的期望值,即如果所有经理都参加了培训,平均参与度会是多少。为了得到这个期望值,你需要将所有接受干预的经理人按照接受干预的反概率进行排序。这样,那些接受干预的概率很低,但还是接受了培训的人的权重就会很高。从本质上讲,你是在提高罕见干预案例的权重。
这很有道理,对吗?如果一个接受干预的个体接受治疗的概率很低,那么这个个体看起来就很像未接受干预的个体。这一定很有趣!如果未接受治疗的个体接受了治疗,,那么这个看起来像未接受治疗的个体很可能对未接受治疗的个体会发生的情况有很大的参考价值。对照组也是如此。如果对照组看起来很像治疗组,那么它很可能是
的良好估计值,所以你要给它更大的权重。
以下是管理培训数据的处理过程,权重表示为每个点的大小:
请注意,当 较低时,接受过培训的经理人(T = 1)的权重较高。你给予了那些看起来像未接受过培训的经理人很高的权重。相反,当
较高或
较低时,未接受培训的经理人的权重较高。在这种情况下,您就会高度重视与已治疗者相似的未治疗者。
如果您可以使用倾向得分来恢复平均潜在结果,这也意味着您可以使用倾向得分来恢复 ATE:
这两种期望都可以用非常简单的代码从数据中估计出来:
weight_t = 1/data_ps.query("intervention==1")["propensity_score"]weight_nt = 1/(1-data_ps.query("intervention==0")["propensity_score"])t1 = data_ps.query("intervention==1")["engagement_score"]t0 = data_ps.query("intervention==0")["engagement_score"]y1 = sum(t1*weight_t)/len(data_ps)y0 = sum(t0*weight_nt)/len(data_ps)print("E[Y1]:", y1)print("E[Y0]:", y0)print("ATE", y1 - y0)E[Y1]: 0.11656317232946772E[Y0]: -0.1494155364781444ATE 0.2659787088076121此外,这个结果看起来与使用 OLS 得到的结果非常相似,这可以很好地检查您是否做错了什么。还值得注意的是,ATE 表达式可以简化如下:
果然,它产生的结果与以前完全相同:
np.mean(data_ps["engagement_score"]* (data_ps["intervention"] - data_ps["propensity_score"])/ (data_ps["propensity_score"]*(1-data_ps["propensity_score"])))0.26597870880761226相关文章:
【Python实战因果推断】23_倾向分3
目录 Propensity Score Matching Inverse Propensity Weighting Propensity Score Matching 另一种控制倾向得分的常用方法是匹配估计法。这种方法搜索具有相似可观测特征的单位对,并比较接受干预与未接受干预的单位的结果。如果您有数据科学背景,您可…...

Qt源码解析之QObject
省去大部分virtual和public方法后,Qobject主要剩下以下成员: //qobject.h class Q_CORE_EXPORT Qobject{Q_OBJECTQ_PROPERTY(QString objectName READ objectName WRITE setObjectName NOTIFY objectNameChanged)Q_DECLARE_PRIVATE(QObject) public:Q_I…...

【算法专题】模拟算法题
模拟算法题往往不涉及复杂的数据结构或算法,而是侧重于对特定情景的代码实现,关键在于理解题目所描述的情境,并能够将其转化为代码逻辑。所以我们在处理这种类型的题目时,最好要现在演草纸上把情况理清楚,再动手编写代…...
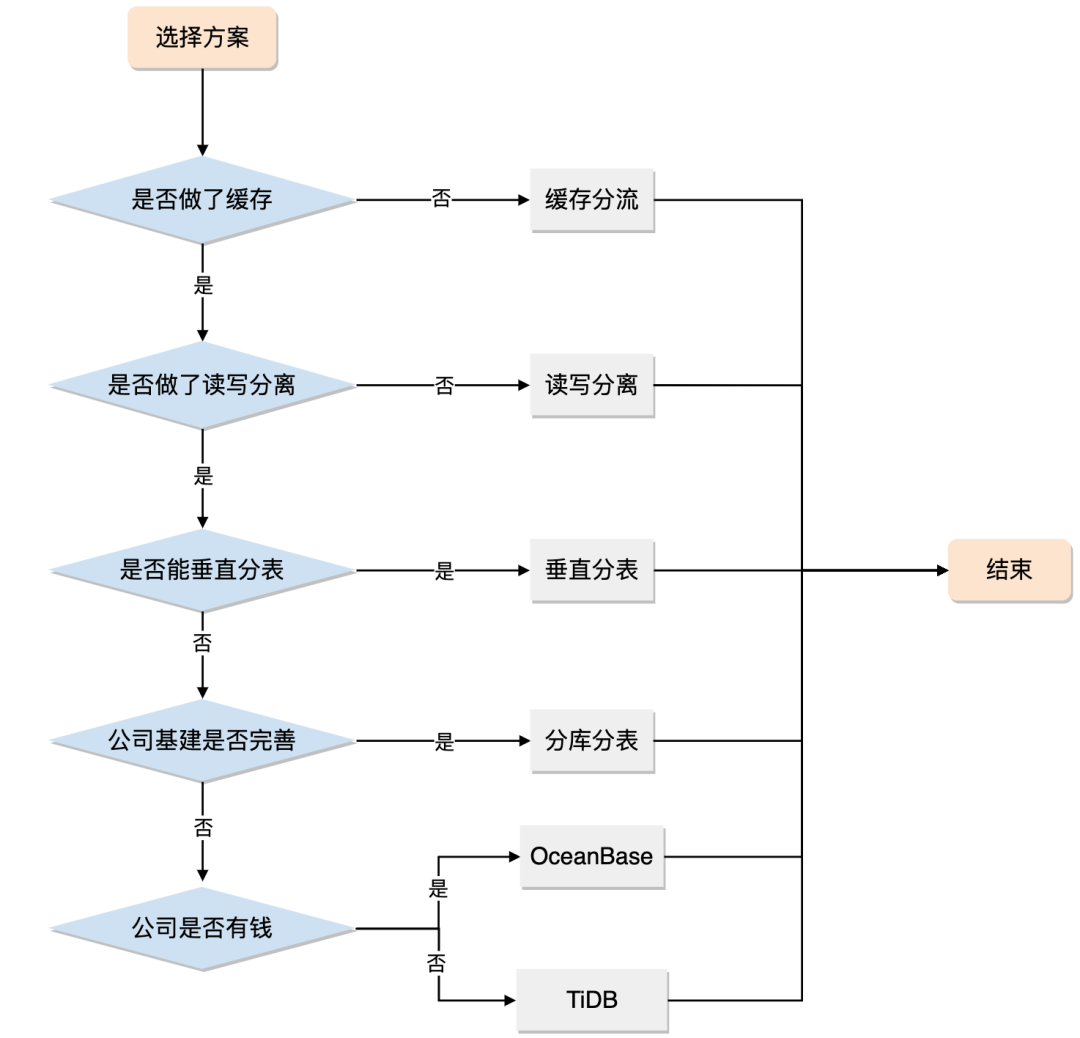
分库分表真的适合你的系统吗?
曾几何时,“并发高就分库,数据大就分表”已经成了处理 MySQL 数据增长问题的圣经。 面试官喜欢问,博主喜欢写,候选人也喜欢背,似乎已经形成了一个闭环。 但你有没有思考过,分库分表真的适合你的系统吗&am…...

9 redis,memcached,nginx网络组件
课程目标: 1.网络模块要处理哪些事情 2.reactor是怎么处理这些事情的 3.reactor怎么封装 4.网络模块与业务逻辑的关系 5.怎么优化reactor? io函数 函数调用 都有两个作用:io检测 是否就绪 io操作 1. int clientfd = accept(listenfd, &addr, &len); 检测 全连接队列…...

【MySQL】事务四大特性以及实现原理
事务四大特性 原子性(Atomicity) 事务中的所有操作要么全部完成,要么全部不执行。如果事务中的任何一步失败,整个事务都会被回滚,以保持数据的完整性。 一致性(Consistency) 事务应确保数据库…...

【控制Android.bp的编译】
1.首先Android.bp的语法是不支持if 条件语句的 2.查到可以用enabled来控制Android.bp中的模块是否参与编译,但是并不能实现动态的控制,比如你需要根据获取到的安卓版本来控制一个Android.bp是否编译,是无法做到的。enabled只能是固定的true或…...
【车载开发系列】J-Link/JFlash 简介与驱动安装方法
【车载开发系列】J-Link/JFlash 简介与驱动安装方法 【车载开发系列】J-Link/JFlash 简介与驱动安装方法 【车载开发系列】J-Link/JFlash 简介与驱动安装方法一. 软件介绍二. 下载安装包二. 开始安装三. 确认安装四. J-Flash的使用 一. 软件介绍 J-Link是SEGGER公司为支持仿真…...

207 课程表
题目 你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。 在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。 …...

罗剑锋的C++实战笔记学习(一):const、智能指针、lambda表达式
1、const 1)、常量 const一般的用法就是修饰变量、引用、指针,修饰之后它们就变成了常量,需要注意的是const并未区分出编译期常量和运行期常量,并且const只保证了运行时不直接被修改 一般的情况,const放在左边&…...

宁德时代天行发布,商用车超充时代来临
近日,宁德时代正式推出商用动力电池品牌——“宁德时代天行”,同时发布“宁德时代天行轻型商用车(L)-超充版”和“宁德时代天行轻型商用车(L)-长续航版”两款产品,可实现4C超充能力和500km的实况…...
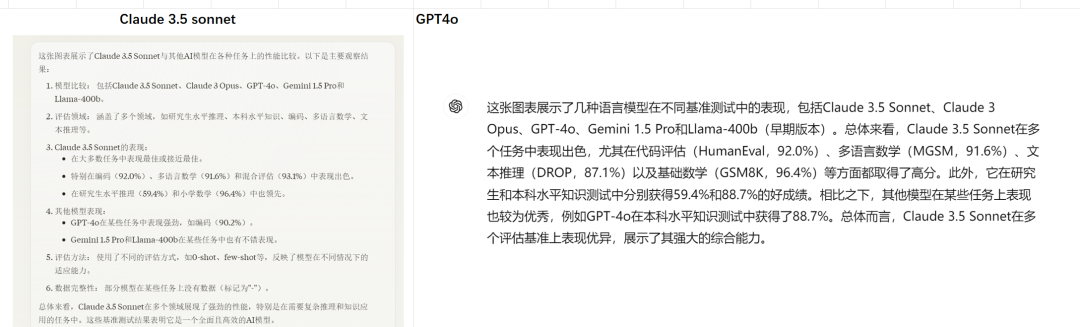
硅纪元应用评测 | 弱智吧大战GPT4o和Claude 3.5 Sonnet
"硅纪元AI应用测评"栏目,深入解析和评测最新的人工智能应用,提供专业见解和实用建议。不论您是AI专家还是科技爱好者,都能找到权威、详尽的测评,帮助您在快速发展的AI领域中做出最佳选择。一起探索AI的真实潜力…...

注意力机制 attention Transformer 笔记
动手学深度学习 这里写自定义目录标题 注意力加性注意力缩放点积注意力多头注意力自注意力Transformer 注意力 注意力汇聚的输出为值的加权和 查询的长度为q,键的长度为k,值的长度为v。 q ∈ 1 q , k ∈ 1 k , v ∈ R 1 v {\bf{q}} \in {^{1 \times…...
开始尝试从0写一个项目--后端(二)
实现学生管理 新增学生 接口设计 请求路径:/admin/student 请求方法:POST 请求参数:请求头:Headers:"Content-Type": "application/json" 请求体:Body: id 学生id …...
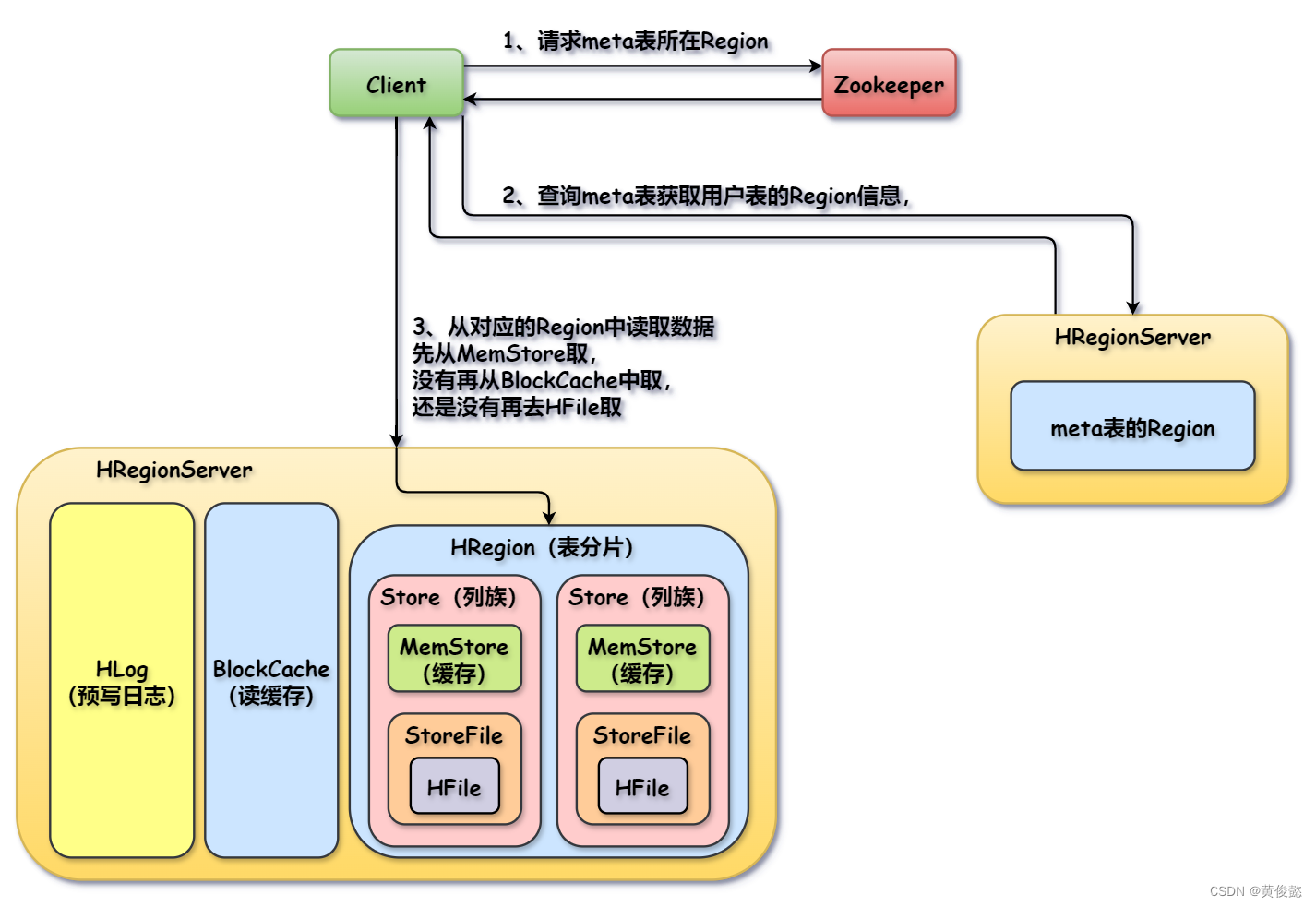
【图解大数据技术】Hive、HBase
【图解大数据技术】Hive、HBase Hive数据仓库Hive的执行流程Hive架构数据导入Hive HBaseHBase简介HBase架构HBase的列式存储HBase建表流程HBase数据写入流程HBase数据读取流程 Hive Hive是基于Hadoop的一个数据仓库工具,Hive的数据存储在HDFS上,底层基于…...
)
composables 目录下的文件(web前端)
composables 目录通常用于存放可组合的函数或逻辑,这些函数或逻辑可以在不同的组件中复用。具体来说,composables 目录下的文件通常包含以下内容: 组合式函数 (Composable Functions): 这些函数利用 Vue 3 的组合式 API࿰…...

使用Python绘制堆积柱形图
使用Python绘制堆积柱形图 堆积柱形图效果代码 堆积柱形图 堆积柱形图(Stacked Bar Chart)是一种数据可视化图表,用于显示不同类别的数值在某一变量上的累积情况。每一个柱状条显示多个子类别的数值,子类别的数值在柱状条上堆积在…...

DP:二维费用背包问题
文章目录 🎵二维费用背包问题🎶引言🎶问题定义🎶动态规划思想🎶状态定义和状态转移方程🎶初始条件和边界情况 🎵例题🎶1.一和零🎶2.盈利计划 🎵总结 …...

C语言标准库中的函数
由于C语言标准库中的函数非常多,我将按类别列出一些常见函数及其作用。请注意,这里不可能列出所有函数,但我会尽量覆盖主要的类别和函数。 ### 标准输入输出 - printf: 格式化输出到标准输出(通常是屏幕)。 - scanf: …...

Qt5.9.9 关于界面拖动导致QModbusRTU(QModbusTCP没有测试过)离线的问题
问题锁定 参考网友的思路: Qt5.9 Modbus request timeout 0x5异常解决 网友认为是Qt的bug, 我也认同;网友认为可以更新模块, 我也认同, 我也编译了Qt5.15.0的code并成功安装到Qt5.9.9中进行使用,界面拖…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...