openmetadata1.3.1 自定义连接器 开发教程
openmetadata自定义连接器开发教程
一、开发通用自定义连接器教程
官网教程链接:
1.https://docs.open-metadata.org/v1.3.x/connectors/custom-connectors
2.https://github.com/open-metadata/openmetadata-demo/tree/main/custom-connector
(一)创建服务类型自定义连接器类
参考文档:https://docs.open-metadata.org/v1.3.x/sdk/python/build-connector/source#for-consumers-of-openmetadata-ingestion-to-define-custom-connectors-in-their-own-package-with-same-namespace
1.创建自定义连接器
示例:my_csv_connector.py
"""
自定义Database Service 从 CSV 文件中提取元数据
"""
import csv
import tracebackfrom pydantic import BaseModel, ValidationError, validator
from pathlib import Path
from typing import Iterable, Optional, List, Dict, Anyfrom metadata.ingestion.api.common import Entity
from metadata.ingestion.api.models import Either
from metadata.generated.schema.entity.services.ingestionPipelines.status import StackTraceError
from metadata.ingestion.api.steps import Source, InvalidSourceException
from metadata.generated.schema.entity.services.connections.metadata.openMetadataConnection import (OpenMetadataConnection,
)
from metadata.generated.schema.entity.services.connections.database.customDatabaseConnection import (CustomDatabaseConnection,
)
from metadata.generated.schema.entity.data.database import Database
from metadata.generated.schema.entity.data.databaseSchema import DatabaseSchema
from metadata.generated.schema.api.data.createDatabaseSchema import (CreateDatabaseSchemaRequest,
)
from metadata.generated.schema.api.data.createDatabase import CreateDatabaseRequest
from metadata.generated.schema.entity.services.databaseService import (DatabaseService,
)
from metadata.generated.schema.entity.data.table import (Column,
)
from metadata.generated.schema.metadataIngestion.workflow import (Source as WorkflowSource,
)
from metadata.generated.schema.api.data.createTable import CreateTableRequest
from metadata.ingestion.ometa.ometa_api import OpenMetadata
from metadata.utils.logger import ingestion_loggerlogger = ingestion_logger()class InvalidCsvConnectorException(Exception):"""Sample data is not valid to be ingested"""class CsvModel(BaseModel):name: strcolumn_names: List[str]column_types: List[str]@validator("column_names", "column_types", pre=True)def str_to_list(cls, value):"""Suppose that the internal split is in ;"""return value.split(";")class CsvConnector(Source):"""Custom connector to ingest Database metadata.We'll suppose that we can read metadata from a CSVwith a custom database name from a business_unit connection option."""# 内置方法def __init__(self, config: WorkflowSource, metadata: OpenMetadata):self.config = configself.metadata = metadata# 获取配置信息self.service_connection = config.serviceConnection.__root__.configself.source_directory: str = (# 获取CSV文件路径self.service_connection.connectionOptions.__root__.get("source_directory"))if not self.source_directory:raise InvalidCsvConnectorException("未获取到source_directory配置信息")self.business_unit: str = (# 获取自定义的数据库名称self.service_connection.connectionOptions.__root__.get("business_unit"))if not self.business_unit:raise InvalidCsvConnectorException("未获取到business_unit配置信息")self.data: Optional[List[CsvModel]] = Nonesuper().__init__()# 内置函数@classmethoddef create(cls, config_dict: dict, metadata_config: OpenMetadataConnection) -> "CsvConnector":config: WorkflowSource = WorkflowSource.parse_obj(config_dict)connection: CustomDatabaseConnection = config.serviceConnection.__root__.configif not isinstance(connection, CustomDatabaseConnection):raise InvalidSourceException(f"Expected CustomDatabaseConnection, but got {connection}")return cls(config, metadata_config)# 静态方法:按行读取@staticmethoddef read_row_safe(row: Dict[str, Any]):try:return CsvModel.parse_obj(row)except ValidationError:logger.warning(f"Error parsing row {row}. Skipping it.")# 预处理:读取文件及数据def prepare(self):# Validate that the file existssource_data = Path(self.source_directory)if not source_data.exists():raise InvalidCsvConnectorException("Source Data path does not exist")try:with open(source_data, "r", encoding="utf-8") as file:reader = csv.DictReader(file)# 读取数据self.data = [self.read_row_safe(row) for row in reader]except Exception as exc:logger.error("Unknown error reading the source file")raise excdef yield_create_request_database_service(self):yield Either(# 串讲元数据读取服务right=self.metadata.get_create_service_from_source(entity=DatabaseService, config=self.config))# 业务原数据库名处理方法def yield_business_unit_db(self):# 选择我们刚刚创建的服务(如果不是UI)# 获取提取服务对象service_entity: DatabaseService = self.metadata.get_by_name(entity=DatabaseService, fqn=self.config.serviceName)yield Either(right=CreateDatabaseRequest(name=self.business_unit,service=service_entity.fullyQualifiedName,))# chems处理方法def yield_default_schema(self):# Pick up the service we just created (if not UI)database_entity: Database = self.metadata.get_by_name(entity=Database, fqn=f"{self.config.serviceName}.{self.business_unit}")yield Either(right=CreateDatabaseSchemaRequest(name="default",database=database_entity.fullyQualifiedName,))# 业务元数据处理方法def yield_data(self):"""Iterate over the data list to create tables"""database_schema: DatabaseSchema = self.metadata.get_by_name(entity=DatabaseSchema,fqn=f"{self.config.serviceName}.{self.business_unit}.default",)# 异常处理# 假设我们有一个要跟踪的故障# try:# 1/0# except Exception:# yield Either(# left=StackTraceError(# name="My Error",# error="Demoing one error",# stackTrace=traceback.format_exc(),# )# )# 解析csv元数据信息(获取列名和类型)for row in self.data:yield Either(right=CreateTableRequest(name=row.name,databaseSchema=database_schema.fullyQualifiedName,columns=[Column(name=model_col[0],dataType=model_col[1],)for model_col in zip(row.column_names, row.column_types)],))# 迭代器:元数据迭代返回def _iter(self) -> Iterable[Entity]:# 数据库元数据信息存储yield from self.yield_create_request_database_service()# 业务源数据库yield from self.yield_business_unit_db()# 业务schemayield from self.yield_default_schema()# 业务数据yield from self.yield_data()# 测试数据库连接def test_connection(self) -> None:pass# 连接关闭def close(self):pass
(二)将自定义连接器方法打包编译进ingestion镜像
项目目录:

Dockerfile:
FROM openmetadata/ingestion:1.3.1# Let's use the same workdir as the ingestion image
WORKDIR ingestion
USER airflow# Install our custom connector
COPY connector connector
COPY setup.py .
COPY sample.csv .
#COPY person_info.proto .
RUN pip install --no-deps .
编译服务镜像
docker build -t om-ingestion:build -f Dockerfile .
(三)部署新版ingestion服务()
docker-compose up -d
docker-compose-ingestion.yml
version: "3.9"
volumes:ingestion-volume-dag-airflow:ingestion-volume-dags:ingestion-volume-tmp:es-data:
services: ingestion:container_name: om_ingestionimage: om-ingestion:buildenvironment:AIRFLOW__API__AUTH_BACKENDS: "airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session"AIRFLOW__CORE__EXECUTOR: LocalExecutorAIRFLOW__OPENMETADATA_AIRFLOW_APIS__DAG_GENERATED_CONFIGS: "/opt/airflow/dag_generated_configs"DB_SCHEME: ${AIRFLOW_DB_SCHEME:-postgresql+psycopg2}DB_HOST: ${AIRFLOW_DB_HOST:-host.docker.internal}DB_PORT: ${AIRFLOW_DB_PORT:-5432}AIRFLOW_DB: ${AIRFLOW_DB:-airflow_db}DB_USER: ${AIRFLOW_DB_USER:-airflow_user}DB_PASSWORD: ${AIRFLOW_DB_PASSWORD:-airflow_pass}# extra connection-string properties for the database# EXAMPLE# require SSL (only for Postgres)# properties: "?sslmode=require"DB_PROPERTIES: ${AIRFLOW_DB_PROPERTIES:-}# To test the lineage backend# AIRFLOW__LINEAGE__BACKEND: airflow_provider_openmetadata.lineage.backend.OpenMetadataLineageBackend# AIRFLOW__LINEAGE__AIRFLOW_SERVICE_NAME: local_airflowAIRFLOW__LINEAGE__OPENMETADATA_API_ENDPOINT: http://host.docker.internal:8585/apiAIRFLOW__LINEAGE__JWT_TOKEN: eyJraWQiOiJHYjM4OWEtOWY3Ni1nZGpzLWE5MmotMDI0MmJrOTQzNTYiLCJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJvcGVuLW1ldGFkYXRhLm9yZyIsInN1YiI6ImluZ2VzdGlvbi1ib3QiLCJlbWFpbCI6ImluZ2VzdGlvbi1ib3RAb3Blbm1ldGFkYXRhLm9yZyIsImlzQm90Ijp0cnVlLCJ0b2tlblR5cGUiOiJCT1QiLCJpYXQiOjE3MDk3MDkyNDMsImV4cCI6bnVsbH0.U7XIYZjJAmJ-p3WTy4rTGGSzUxZeNpjOsHzrWRz7n-zAl-GZvznZWMKX5nSX_KwRHAK3UYuO1UX2-ZbeZxdpzhyumycNFyWzwMs8G6iEGoaM6doGhqCgHileco8wcAoaTXKHTnwa80ddWHt4dqZmikP7cIhLg9etKAepQNQibefewHbaLOoCrFyo9BqFeZzNaVBo1rogNtslWaDO6Wnk_rx0jxRLTy57Thq7R7YS_nZd-JVfYf72BEFHJ_WDZym4k-dusV0PWGzMPYIXq3s1KbpPBt_tUSz4cUrXbLuI5-ZsOWIvUhsLeHJDU-35-RymylhMrQ92kZjsy7v2nl6apQentrypoint: /bin/bashcommand:- "/opt/airflow/ingestion_dependency.sh"expose:- 8080ports:- "8080:8080"networks:- app_net_ingestionvolumes:- ingestion-volume-dag-airflow:/opt/airflow/dag_generated_configs- ingestion-volume-dags:/opt/airflow/dags- ingestion-volume-tmp:/tmpnetworks:app_net_ingestion:ipam:driver: defaultconfig:- subnet: "172.16.240.0/24"
(四)根据服务类型选择对应类型的custom服务创建采集器测试
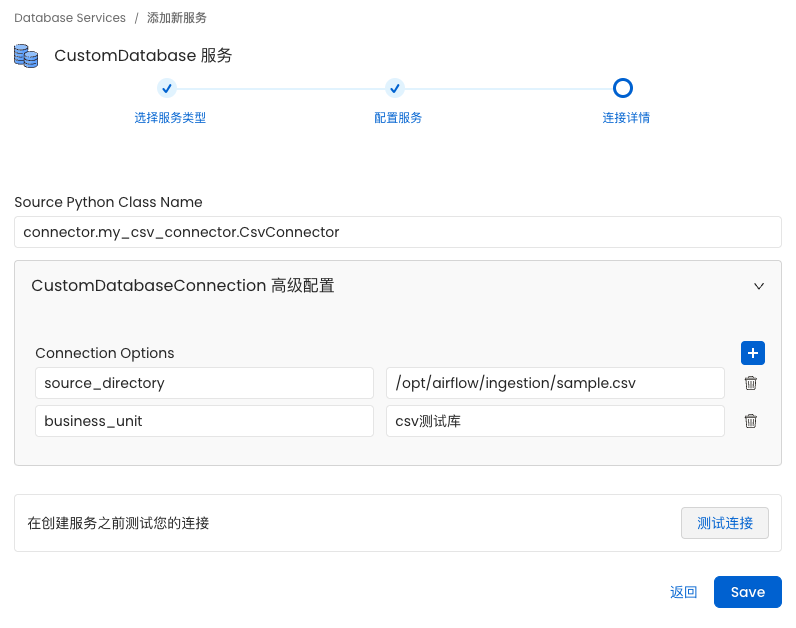
点击保存添加元数据提取器:


二、开发内置连接器教程(Streamsets)
官网教程链接:https://docs.open-metadata.org/v1.3.x/developers/contribute/developing-a-new-connector
(一)定义连接器class类json模版(streamSetsConnection.json)
目录:openmetadata-spec/src/main/resources/json/schema/entity/services/connections/pipeline/streamSetsConnection.json
{"$id": "https://open-metadata.org/schema/entity/services/connections/pipeline/streamSetsConnection.json","$schema": "http://json-schema.org/draft-07/schema#","title": "StreamSetsConnection","description": "StreamSets Metadata Pipeline Connection Config","type": "object","javaType": "org.openmetadata.schema.services.connections.pipeline.StreamSetsConnection","definitions": {"StreamSetsType": {"description": "Service type.","type": "string","enum": ["StreamSets"],"default": "StreamSets"},"basicAuthentication": {"title": "Username Authentication","description": "Login username","type":"object","properties": {"username": {"title": "Username","description": "StreamSets user to authenticate to the API.","type": "string"}},"additionalProperties": false}},"properties": {"type": {"title": "Service Type","description": "Service Type","$ref": "#/definitions/StreamSetsType","default": "StreamSets"},"hostPort": {"expose": true,"title": "Host And Port","description": "Pipeline Service Management/UI URI.","type": "string","format": "uri"},"streamSetsConfig": {"title": "StreamSets Credentials Configuration","description": "We support username authentication","oneOf": [{"$ref": "#/definitions/basicAuthentication"}]},"supportsMetadataExtraction": {"title": "Supports Metadata Extraction","$ref": "../connectionBasicType.json#/definitions/supportsMetadataExtraction"}},"additionalProperties": false,"required": ["hostPort", "streamSetsConfig"]
}(二)开发采集器源码:
目录:ingestion/src/metadata/ingestion/source/pipeline/streamsets/*

1.streamsets连接客户端(client.py)
import logging
import traceback
from typing import Any, Iterable, Optionalimport requests
from requests import HTTPError
from requests.auth import HTTPBasicAuth# 设置日志记录器
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)REQUESTS_TIMEOUT = 60 * 5def clean_uri(uri: str) -> str:"""清理URI,确保它以HTTP或HTTPS开头"""if not uri.startswith(("http://", "https://")):return "http://" + urireturn uriclass StreamSetsClient:"""在StreamSets Data Collector REST API之上的包装器"""def __init__(self,host_port: str,username: Optional[str] = None,password: Optional[str] = None,verify: bool = False,):self.api_endpoint = clean_uri(host_port) + "/rest"self.username = usernameself.password = passwordself.verify = verifyself.headers = {"Content-Type": "application/json"}def get(self, path: str) -> Optional[Any]:"""GET方法包装器"""try:res = requests.get(f"{self.api_endpoint}/{path}",verify=self.verify,headers=self.headers,timeout=REQUESTS_TIMEOUT,auth=HTTPBasicAuth(self.username, self.password),)res.raise_for_status()return res.json()except HTTPError as err:logger.warning(f"Connection error calling the StreamSets API - {err}")raise errexcept ValueError as err:logger.warning(f"Cannot pick up the JSON from API response - {err}")raise errexcept Exception as err:logger.warning(f"Unknown error calling StreamSets API - {err}")raise errdef list_pipelines(self) -> Iterable[dict]:"""List all pipelines"""try:return self.get("v1/pipelines")except Exception as err:logger.error(traceback.format_exc())raise errdef get_pipeline_details(self, pipeline_id: str) -> dict:"""Get a specific pipeline by ID"""return self.get(f"v1/pipeline/{pipeline_id}?rev=0&get=pipeline")def test_list_pipeline_detail(self) -> Iterable[dict]:"""Test API access for listing pipelines"""return self.list_pipelines()
2.连接器和测试连接器(connection.py)
"""
源连接处理程序
"""
from typing import Optionalfrom metadata.generated.schema.entity.automations.workflow import (Workflow as AutomationWorkflow,
)
from metadata.generated.schema.entity.services.connections.pipeline.streamSetsConnection import (BasicAuthentication,StreamSetsConnection,
)
from metadata.ingestion.connections.test_connections import test_connection_steps
from metadata.ingestion.ometa.ometa_api import OpenMetadata
from metadata.ingestion.source.pipeline.streamsets.client import StreamSetsClientdef get_connection(connection: StreamSetsConnection) -> StreamSetsClient:"""Create connection"""if isinstance(connection.streamSetsConfig, BasicAuthentication):return StreamSetsClient(host_port=connection.hostPort,username=connection.streamSetsConfig.username,password="95bd7977208bc935cac3656f4a9eea3a",verify=False,)def test_connection(metadata: OpenMetadata,client: StreamSetsClient,service_connection: StreamSetsConnection,automation_workflow: Optional[AutomationWorkflow] = None,
) -> None:"""元数据工作流或自动化工作流期间测试连接。这可以作为一部分执行"""def custom_executor():list(client.list_pipelines())test_fn = {"GetPipelines": custom_executor}test_connection_steps(metadata=metadata,test_fn=test_fn,service_type=service_connection.type.value,automation_workflow=automation_workflow,)
3.元数据提取器(metadata.py)
"""
提取StreamSets 源的元数据
"""
import traceback
from typing import Iterable, List, Optional, Anyfrom metadata.generated.schema.entity.services.ingestionPipelines.status import StackTraceError
from pydantic import BaseModel, ValidationErrorfrom metadata.generated.schema.api.data.createPipeline import CreatePipelineRequest
from metadata.generated.schema.api.lineage.addLineage import AddLineageRequest
from metadata.generated.schema.entity.data.pipeline import Task
from metadata.generated.schema.entity.services.connections.pipeline.streamSetsConnection import (StreamSetsConnection,
)
from metadata.generated.schema.metadataIngestion.workflow import (Source as WorkflowSource,
)
from metadata.ingestion.api.models import Either
from metadata.ingestion.api.steps import InvalidSourceException
from metadata.ingestion.models.pipeline_status import OMetaPipelineStatus
from metadata.ingestion.ometa.ometa_api import OpenMetadata
from metadata.ingestion.source.pipeline.pipeline_service import PipelineServiceSource
from metadata.utils.helpers import clean_uri
from metadata.utils.logger import ingestion_loggerlogger = ingestion_logger()class StagesDetails(BaseModel):instanceName: strlabel:strstageType: strstageName: strdescription: strinputLanes: List[str]outputLanes: List[str]downstream_task_names: set[str] = set()class StreamSetsPipelineDetails(BaseModel):"""Defines the necessary StreamSets information"""uuid: strpipelineId: strtitle: strname: strcreated: intcreator: strdescription: strclass StreamsetsSource(PipelineServiceSource):"""执行必要的方法,从 Airflow 的元数据数据库中提取管道元数据"""@classmethoddef create(cls, config_dict: dict, metadata: OpenMetadata):logger.info("create..........")config: WorkflowSource = WorkflowSource.parse_obj(config_dict)logger.info(f"WorkflowSource: {config}")connection: StreamSetsConnection = config.serviceConnection.__root__.configlogger.info(f"StreamSetsConnection: {connection}")if not isinstance(connection, StreamSetsConnection):raise InvalidSourceException(f"Expected StreamSetsConnection, but got {connection}")return cls(config, metadata)def yield_pipeline(self, pipeline_details: StreamSetsPipelineDetails) -> Iterable[Either[CreatePipelineRequest]]:logger.info("yield_pipeline.......")try:connection_url = Noneif self.service_connection.hostPort:connection_url = (f"{clean_uri(self.service_connection.hostPort)}/rest/v1/pipelines")logger.info(f"pipeline_details:{pipeline_details}")logger.info(f"connection_url:{connection_url}")pipeline_request = CreatePipelineRequest(name=pipeline_details.name,displayName=pipeline_details.title,sourceUrl=f"{clean_uri(self.service_connection.hostPort)}/collector/pipeline/{pipeline_details.pipelineId}",tasks=self._get_tasks_from_details(pipeline_details),service=self.context.pipeline_service,)yield Either(right=pipeline_request)self.register_record(pipeline_request=pipeline_request)except TypeError as err:self.context.task_names = set()yield Either(left=StackTraceError(name=pipeline_details.dag_id,error=(f"Error building DAG information from {pipeline_details}. There might be Airflow version"f" incompatibilities - {err}"),stackTrace=traceback.format_exc(),))except ValidationError as err:self.context.task_names = set()yield Either(left=StackTraceError(name=pipeline_details.dag_id,error=f"Error building pydantic model for {pipeline_details} - {err}",stackTrace=traceback.format_exc(),))except Exception as err:self.context.task_names = set()yield Either(left=StackTraceError(name=pipeline_details.dag_id,error=f"Wild error ingesting pipeline {pipeline_details} - {err}",stackTrace=traceback.format_exc(),))# 获取解析管道详情def _get_tasks_from_details(self, pipeline_details: StreamSetsPipelineDetails) -> Optional[List[Task]]:logger.info("_get_tasks_from_details.......")logger.info(f"StreamSetsPipelineDetails:{pipeline_details}")try:stages = self.get_stages_by_pipline(pipeline_details)return [Task(name=stage.instanceName,displayName=stage.label,sourceUrl=f"{clean_uri(self.service_connection.hostPort)}/collector/pipeline/{pipeline_details.pipelineId}",taskType=stage.stageType,description=stage.description,downstreamTasks=list(stage.downstream_task_names)if stage.downstream_task_nameselse [],)for stage in stages]except Exception as err:logger.debug(traceback.format_exc())logger.warning(f"Wild error encountered when trying to get tasks from Pipeline Details {pipeline_details} - {err}.")return Nonedef yield_pipeline_lineage_details(self, pipeline_details: StreamSetsPipelineDetails) -> Iterable[Either[AddLineageRequest]]:logger.info("yield_pipeline_lineage_details..........")"""将连接转换为管道实体:param pipeline_details: 来自 StreamSets的pipeline_details对象return:使用任务创建管道请求"""passdef get_pipelines_list(self) -> Optional[List[StreamSetsPipelineDetails]]:logger.info("get_pipelines_list..........")"""Get List of all pipelines"""if self.connection.list_pipelines() is not None:for list_pipeline in self.connection.list_pipelines():logger.info(f"pipeline:{list_pipeline}")try:yield StreamSetsPipelineDetails(uuid=list_pipeline.get("uuid"),pipelineId=list_pipeline.get("pipelineId"),title=list_pipeline.get("title"),name=list_pipeline.get("name"),created=list_pipeline.get("created"),creator=list_pipeline.get("creator"),description=list_pipeline.get("description"),)except (ValueError, KeyError, ValidationError) as err:logger.debug(traceback.format_exc())logger.warning(f"Cannot create StreamSetsPipelineDetails from {list_pipeline} - {err}")except Exception as err:logger.debug(traceback.format_exc())logger.warning(f"Wild error encountered when trying to get pipelines from Process Group {list_pipeline} - {err}.")else:return None# 获取上下关联关系def get_stages_lane(self, stages: Optional[List[StagesDetails]]) -> {}:logger.info("get_stages_lane......")input_lane_to_stage_map = {}for stage in stages:logger.info(f"stage_info:{stage}")for input_lane in stage.get("inputLanes", []):try:if input_lane_to_stage_map.get(input_lane) is None:input_lane_to_stage_map[input_lane] = set()input_lane_to_stage_map[input_lane].add(stage.get("instanceName"))else:input_lane_to_stage_map[input_lane].add(stage.get("instanceName"))except Exception as err:logger.debug(traceback.format_exc())logger.warning(f"Wild error encountered when trying to get stages from Pipeline Details {stages} - {err}.")logger.info(f"input_lane_to_stage_map:{input_lane_to_stage_map}")return input_lane_to_stage_mapdef get_stages_by_pipline(self, pipeline_details: StreamSetsPipelineDetails) -> Optional[List[StagesDetails]]:logger.info("get_stages_by_pipline")pipeline_detail = self.connection.get_pipeline_details(pipeline_details.pipelineId)stages = []if pipeline_detail.get("stages"):stages = pipeline_detail.get("stages")input_lane_to_stage_map = self.get_stages_lane(stages)for stage in stages:logger.info(f"stage:{stage}")try:input_lanes = stage.get("inputLanes", [])output_lanes = stage.get("outputLanes", [])downstream_stage_names = set()for output_lane in stage.get("outputLanes", []):if output_lane in input_lane_to_stage_map.keys():for down_stage in input_lane_to_stage_map.get(output_lane, []):downstream_stage_names.add(down_stage)yield StagesDetails(instanceName=stage.get("instanceName"),label=stage["uiInfo"].get("label"),stageType=stage["uiInfo"].get("stageType"),stageName=stage.get("stageName"),description=stage["uiInfo"].get("description"),inputLanes=input_lanes,outputLanes=output_lanes,downstream_task_names=downstream_stage_names)except (ValueError, KeyError, ValidationError) as err:logger.debug(traceback.format_exc())logger.warning(f"Cannot create StagesDetails from {stage} - {err}")except Exception as err:logger.debug(traceback.format_exc())logger.warning(f"Wild error encountered when trying to get pipelines from Process Group {stage} - {err}.")def get_pipeline_name(self, pipeline_details: StreamSetsPipelineDetails) -> str:return pipeline_details.namedef yield_pipeline_status(self, pipeline_details: StreamSetsPipelineDetails) -> Iterable[Either[OMetaPipelineStatus]]:pass
(三)修改前端ui源码,添加连接器对象
目录:openmetadata-ui/src/main/resources/ui/src/utils/PipelineServiceUtils.ts
/** Copyright 2022 Collate.* Licensed under the Apache License, Version 2.0 (the "License");* you may not use this file except in compliance with the License.* You may obtain a copy of the License at* http://www.apache.org/licenses/LICENSE-2.0* Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/import { cloneDeep } from 'lodash';
import { COMMON_UI_SCHEMA } from '../constants/Services.constant';
import { PipelineServiceType } from '../generated/entity/services/pipelineService';
import airbyteConnection from '../jsons/connectionSchemas/connections/pipeline/airbyteConnection.json';
import airflowConnection from '../jsons/connectionSchemas/connections/pipeline/airflowConnection.json';
import customPipelineConnection from '../jsons/connectionSchemas/connections/pipeline/customPipelineConnection.json';
import dagsterConnection from '../jsons/connectionSchemas/connections/pipeline/dagsterConnection.json';
import databricksPipelineConnection from '../jsons/connectionSchemas/connections/pipeline/databricksPipelineConnection.json';
import domoPipelineConnection from '../jsons/connectionSchemas/connections/pipeline/domoPipelineConnection.json';
import fivetranConnection from '../jsons/connectionSchemas/connections/pipeline/fivetranConnection.json';
import gluePipelineConnection from '../jsons/connectionSchemas/connections/pipeline/gluePipelineConnection.json';
import nifiConnection from '../jsons/connectionSchemas/connections/pipeline/nifiConnection.json';
import splineConnection from '../jsons/connectionSchemas/connections/pipeline/splineConnection.json';
import streamSetsConnection from '../jsons/connectionSchemas/connections/pipeline/streamSetsConnection.json';export const getPipelineConfig = (type: PipelineServiceType) => {let schema = {};const uiSchema = { ...COMMON_UI_SCHEMA };switch (type) {case PipelineServiceType.Airbyte: {schema = airbyteConnection;break;}case PipelineServiceType.Airflow: {schema = airflowConnection;break;}case PipelineServiceType.GluePipeline: {schema = gluePipelineConnection;break;}case PipelineServiceType.Fivetran: {schema = fivetranConnection;break;}case PipelineServiceType.Dagster: {schema = dagsterConnection;break;}case PipelineServiceType.Nifi: {schema = nifiConnection;break;}case PipelineServiceType.StreamSets: {schema = streamSetsConnection;break;}case PipelineServiceType.DomoPipeline: {schema = domoPipelineConnection;break;}case PipelineServiceType.CustomPipeline: {schema = customPipelineConnection;break;}case PipelineServiceType.DatabricksPipeline: {schema = databricksPipelineConnection;break;}case PipelineServiceType.Spline: {schema = splineConnection;break;}default:break;}return cloneDeep({ schema, uiSchema });
};
(四)前端ui源码,添加MD说明文档
路径:openmetadata-ui/src/main/resources/ui/public/locales/en-US/Pipeline/StreamSets.md
# StreamSets
在本节中,我们将提供使用 StreamSets 连接器的指南和参考。## 要求
系统 支持 StreamSets 连接器的 1 种连接类型:
- **基本认证**:使用用户名对 StreamSets 进行登陆。您可以在 [docs](https://docs.open-metadata.org/connectors/pipeline/StreamSets) 中找到有关 StreamSets 连接器的详细信息。## 连接详细信息
$$section
### Host and Port $(id="hostPort")
管道服务管理 URI。这应指定为格式为"scheme://hostname:port"的 URI 字符串。例如,“http://localhost:8443”、“http://host.docker.internal:8443”。
$$$$section
### StreamSets Config $(id="StreamSetsConfig")
OpenMetadata 支持基本身份验证(用户名/密码身份验证。有关详细信息,请参阅要求部分。
$$$$section
### Username $(id="username")
用于连接到 StreamSets 的用户名。此用户应该能够向 StreamSets API 发送请求并访问“资源”终结点。
$$(五)创建 Java ClassConverter(可选)
无
(六)构建dockefile重新构建镜像
server服务Dockerfile
# Build stage
FROM alpine:3.19 AS buildCOPY openmetadata-dist/target/openmetadata-*.tar.gz /
#COPY docker/openmetadata-start.sh /RUN mkdir -p /opt/openmetadata && \tar zxvf openmetadata-*.tar.gz -C /opt/openmetadata --strip-components 1 && \rm openmetadata-*.tar.gz# Final stage
FROM alpine:3.19EXPOSE 8585RUN adduser -D openmetadata && \apk update && \apk upgrade && \apk add --update --no-cache bash openjdk17-jre tzdata
ENV TZ=Asia/ShanghaiCOPY --chown=openmetadata:openmetadata --from=build /opt/openmetadata /opt/openmetadata
COPY --chmod=755 docker/openmetadata-start.sh /USER openmetadataWORKDIR /opt/openmetadata
ENTRYPOINT [ "/bin/bash" ]
CMD ["/openmetadata-start.sh"]
ingestion服务Dockerfile
路径:ingestion/Dockerfile
FROM apache/airflow:2.7.3-python3.10#FROM docker-compose-ingestion-ingestion:latest
USER root
RUN curl -sS https://packages.microsoft.com/keys/microsoft.asc | apt-key add -
RUN curl -sS https://packages.microsoft.com/config/debian/11/prod.list > /etc/apt/sources.list.d/mssql-release.list
# Install Dependencies (listed in alphabetical order)
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get -qq update \&& apt-get -qq install -y \tzdata \alien \build-essential \default-libmysqlclient-dev \freetds-bin \freetds-dev \gcc \gnupg \libaio1 \libevent-dev \libffi-dev \libpq-dev \librdkafka-dev \libsasl2-dev \libsasl2-2 \libsasl2-modules \libsasl2-modules-gssapi-mit \libssl-dev \libxml2 \libkrb5-dev \openjdk-11-jre \openssl \postgresql \postgresql-contrib \tdsodbc \unixodbc \unixodbc-dev \unzip \vim \git \wget --no-install-recommends \# Accept MSSQL ODBC License&& ACCEPT_EULA=Y apt-get install -y msodbcsql18 \&& rm -rf /var/lib/apt/lists/*RUN if [[ $(uname -m) == "arm64" || $(uname -m) == "aarch64" ]]; \then \wget -q https://download.oracle.com/otn_software/linux/instantclient/191000/instantclient-basic-linux.arm64-19.10.0.0.0dbru.zip -O /oracle-instantclient.zip && \unzip -qq -d /instantclient -j /oracle-instantclient.zip && rm -f /oracle-instantclient.zip; \else \wget -q https://download.oracle.com/otn_software/linux/instantclient/1917000/instantclient-basic-linux.x64-19.17.0.0.0dbru.zip -O /oracle-instantclient.zip && \unzip -qq -d /instantclient -j /oracle-instantclient.zip && rm -f /oracle-instantclient.zip; \fiENV LD_LIBRARY_PATH=/instantclient# Security patches for base image
# monitor no fixed version for
# https://security.snyk.io/vuln/SNYK-DEBIAN11-LIBTASN16-3061097
# https://security.snyk.io/vuln/SNYK-DEBIAN11-MARIADB105-2940589
# https://security.snyk.io/vuln/SNYK-DEBIAN11-BIND9-3027852
# https://security.snyk.io/vuln/SNYK-DEBIAN11-EXPAT-3023031 we are already installed the latest
RUN echo "deb http://deb.debian.org/debian bullseye-backports main" > /etc/apt/sources.list.d/backports.list
RUN apt-get -qq update \&& apt-get -qq install -t bullseye-backports -y \curl \libpcre2-8-0 \postgresql-common \expat \bind9# Required for Starting Ingestion Container in Docker Compose
# Provide Execute Permissions to shell script
COPY --chown=airflow:0 --chmod=775 ingestion/ingestion_dependency.sh /opt/airflow
# Required for Ingesting Sample Data
COPY --chown=airflow:0 --chmod=775 ingestion /home/airflow/ingestionCOPY --chown=airflow:0 --chmod=775 openmetadata-airflow-apis /home/airflow/openmetadata-airflow-apis# Required for Airflow DAGs of Sample Data
#COPY --chown=airflow:0 ingestion/examples/airflow/dags /opt/airflow/dagsUSER airflow
ARG AIRFLOW_CONSTRAINTS_LOCATION="https://raw.githubusercontent.com/apache/airflow/constraints-2.7.3/constraints-3.10.txt"
ENV TZ=Asia/Shanghai# Disable pip cache dir
# https://pip.pypa.io/en/stable/topics/caching/#avoiding-caching
ENV PIP_NO_CACHE_DIR=1
# Make pip silent
ENV PIP_QUIET=1RUN pip install --upgrade pipWORKDIR /home/airflow/openmetadata-airflow-apis
RUN pip install "."WORKDIR /home/airflow/ingestion# 提供要安装的引入依赖项的参数。默认为全部提供要安装的引入依赖项的参数。默认为全部
ARG INGESTION_DEPENDENCY="all"
RUN pip install ".[${INGESTION_DEPENDENCY}]"# Temporary workaround for https://github.com/open-metadata/OpenMetadata/issues/9593
RUN echo "Image built for $(uname -m)"
RUN if [[ $(uname -m) != "aarch64" ]]; \then \pip install "ibm-db-sa~=0.4"; \fi# bump python-daemon for https://github.com/apache/airflow/pull/29916
RUN pip install "python-daemon>=3.0.0"
# remove all airflow providers except for docker and cncf kubernetes
RUN pip freeze | grep "apache-airflow-providers" | grep --invert-match -E "docker|http|cncf" | xargs pip uninstall -y
# Uninstalling psycopg2-binary and installing psycopg2 instead
# because the psycopg2-binary generates a architecture specific error
# while authenticating connection with the airflow, psycopg2 solves this error
RUN pip uninstall psycopg2-binary -y
RUN pip install psycopg2 mysqlclient==2.1.1
# Make required folders for openmetadata-airflow-apis
RUN mkdir -p /opt/airflow/dag_generated_configsEXPOSE 8080
# This is required as it's responsible to create airflow.cfg file
RUN airflow db init && rm -f /opt/airflow/airflow.db
(七)构建服务镜像
根目录下执行构建server:
docker build -t om-server:build -f docker/development/Dockerfile .
根目录下执行构建ingestion:
docker build -t om-ingestion:build -f ingestion/Dockerfile .
(八)部署新版服务
docker-compose -f docker/development/docker-compose-postgres.yml up -d
(九)访问服务,创建streamsets元数据采集

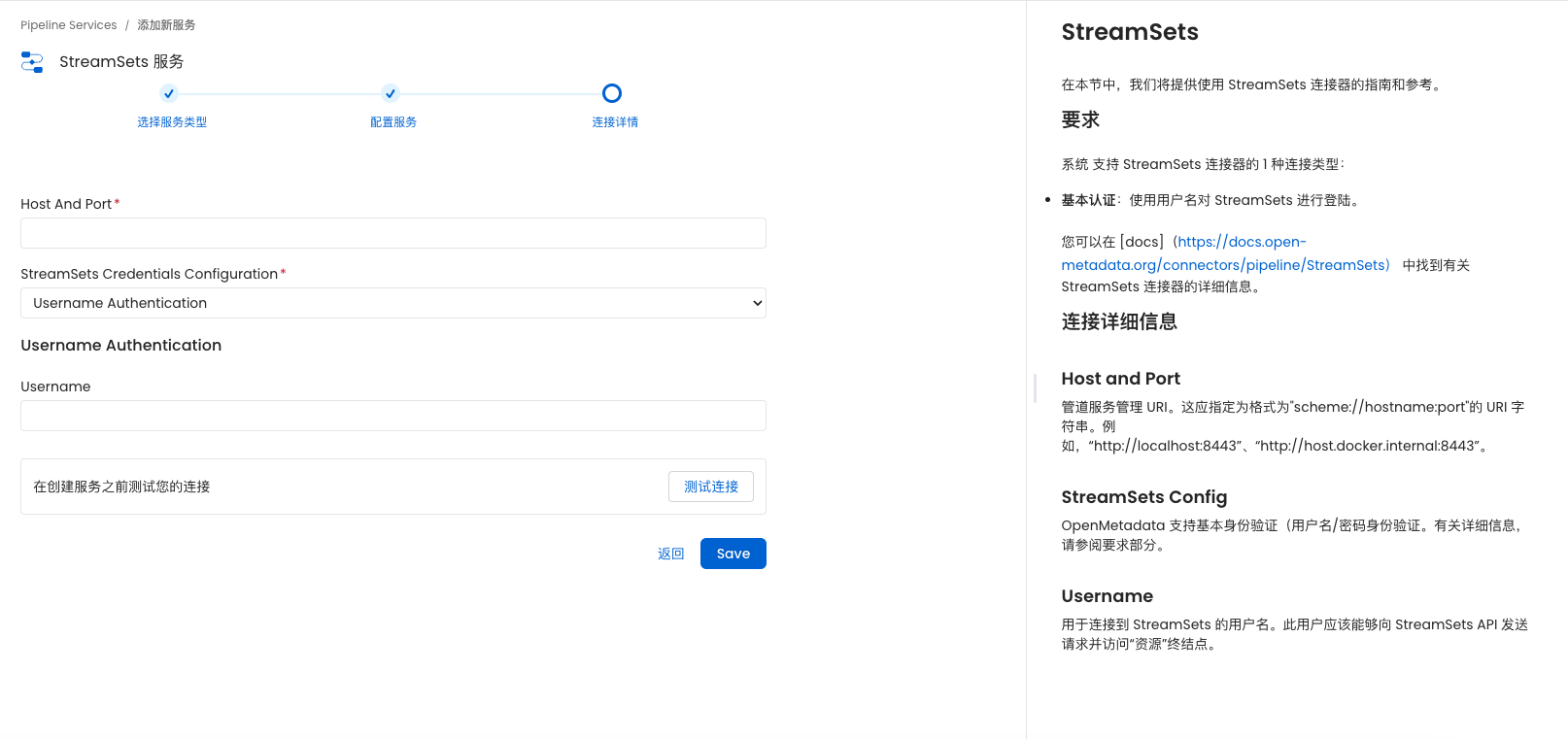
相关文章:
openmetadata1.3.1 自定义连接器 开发教程
openmetadata自定义连接器开发教程 一、开发通用自定义连接器教程 官网教程链接: 1.https://docs.open-metadata.org/v1.3.x/connectors/custom-connectors 2.https://github.com/open-metadata/openmetadata-demo/tree/main/custom-connector (一&…...

PostgreSQL 如何优化存储过程的执行效率?
文章目录 一、查询优化1. 正确使用索引2. 避免不必要的全表扫描3. 使用合适的连接方式4. 优化子查询 二、参数传递1. 避免传递大对象2. 参数类型匹配 三、减少数据量处理1. 限制返回结果集2. 提前筛选数据 四、优化逻辑结构1. 分解复杂的存储过程2. 避免过度使用游标 五、事务处…...

普中51单片机:数码管显示原理与实现详解(四)
文章目录 引言数码管的结构数码管的工作原理静态数码管电路图开发板IO连接图代码演示 动态数码管实现步骤数码管驱动方式电路图开发板IO连接图真值表代码演示1代码演示2代码演示3 引言 数码管(Seven-Segment Display)是一种常见的显示设备,广…...
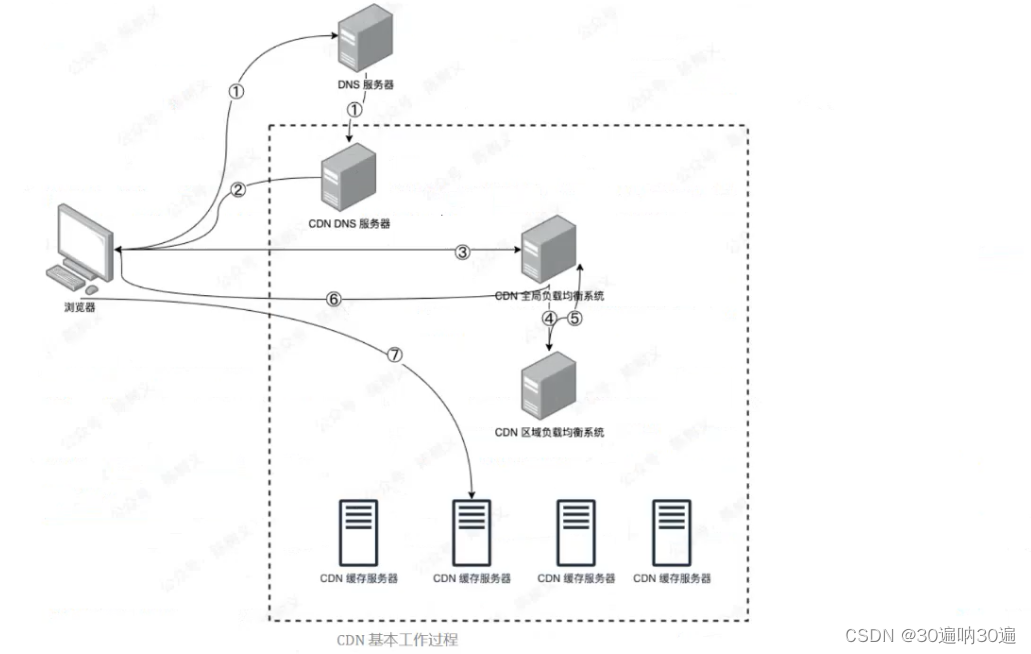
web缓存代理服务器
一、web缓存代理 web代理的工作机制 代理服务器是一个位于客户端和原始(资源)服务器之间的服务器,为了从原始服务器取得内容,客户端向代理服务器发送一个请求,并指定目标原始服务器,然后代理服务器向原始…...

容器:queue(队列)
以下是关于queue容器的总结 1、构造函数:queue [queueName] 2、添加、删除元素: push() 、pop() 3、获取队头/队尾元素:front()、back() 4、获取栈的大小:size() 5、判断栈是否为空:empty() #include <iostream> #include …...

探索 WebKit 的后台同步新纪元:Web Periodic Background Synchronization 深度解析
探索 WebKit 的后台同步新纪元:Web Periodic Background Synchronization 深度解析 随着 Web 应用逐渐成为我们日常生活中不可或缺的一部分,用户对应用的响应速度和可靠性有了更高的期待。Web Periodic Background Synchronization API(周期…...

ctfshow web入门 web338--web344
web338 原型链污染 comman.js module.exports {copy:copy };function copy(object1, object2){for (let key in object2) {if (key in object2 && key in object1) {copy(object1[key], object2[key])} else {object1[key] object2[key]}}}login.js var express …...

mupdf加载PDF显示中文乱码
现象 加载PDF显示乱码,提示非嵌入字体 non-embedded font using identity encoding调式 在pdf-font.c中加载字体 调试源码发现pdf文档的字体名字居然是GBK,估计又是哪个windows下写的pdf生成工具生成pdf 字体方法: static pdf_font_desc * load_cid…...

常用的限流工具Guava RateLimiter 或Redisson RRateLimiter
在分布式系统和高并发场景中,限流是一个非常常见且重要的需求。以下是一些常用的限流工具和库,包括它们的特点和使用场景: 1. Guava RateLimiter Google 的 Guava 库中的 RateLimiter 是一个简单且高效的限流工具,适用于单节点应…...
和循环神经网络(RNN) 的区别与联系)
卷积神经网络(CNN)和循环神经网络(RNN) 的区别与联系
卷积神经网络(CNN)和循环神经网络(RNN)是两种广泛应用于深度学习的神经网络架构,它们在设计理念和应用领域上有显著区别,但也存在一些联系。 ### 卷积神经网络(CNN) #### 主要特点…...

Unity【入门】场景切换和游戏退出及准备
1、必备知识点场景切换和游戏退出 文章目录 1、必备知识点场景切换和游戏退出1、场景切换2、鼠标隐藏锁定相关3、随机数和自带委托4、模型资源的导入1、模型由什么构成2、Unity支持的模型格式3、如何指导美术同学导出模型4、学习阶段在哪里获取模型资源 2、小项目准备工作需求分…...

Python 函数递归
以下是一个使用递归计算阶乘的 Python 函数示例 : 应用场景: 1. 动态规划问题:在一些需要逐步求解子问题并利用其结果的动态规划场景中,递归可以帮助直观地表达问题的分解和求解过程。 2. 遍历具有递归结构的数据:如递…...
如何配置 MyBatis 实现打印可执行的 SQL 语句)
MyBatis(27)如何配置 MyBatis 实现打印可执行的 SQL 语句
在开发过程中,打印可执行的SQL语句对于调试和性能优化是非常有帮助的。MyBatis提供了几种方式来实现SQL语句的打印。 1. 使用日志框架 MyBatis可以通过配置其内部使用的日志框架(如Log4j、Logback等)来打印SQL语句。这是最常用的方法。 Lo…...

3.js - 裁剪平面(clipIntersection:交集、并集)
看图 代码 // ts-nocheck// 引入three.js import * as THREE from three// 导入轨道控制器 import { OrbitControls } from three/examples/jsm/controls/OrbitControls// 导入lil.gui import { GUI } from three/examples/jsm/libs/lil-gui.module.min.js// 导入tween import …...

在5G/6G应用中实现高性能放大器的建模挑战
来源:Modelling Challenges for Enabling High Performance Amplifiers in 5G/6G Applications {第28届“集成电路和系统的混合设计”(Mixed Design of Integrated Circuits and Systems)国际会议论文集,2021年6月24日至26日,波兰洛迪} 本文讨…...

Perl 数据类型
Perl 数据类型 Perl 是一种功能丰富的编程语言,广泛应用于系统管理、网络编程、GUI 开发等领域。在 Perl 中,数据类型是编程的基础,决定了变量存储信息的方式以及可以对这些信息执行的操作。本文将详细介绍 Perl 中的主要数据类型࿰…...

网络协议 -- IP、ICMP、TCP、UDP字段解析
网络协议报文解析及工具使用介绍 1. 以太网帧格式及各字段作用 -------------------------------- | Destination MAC Address (48 bits) | -------------------------------- | Source MAC Address (48 bits) …...

【工具】豆瓣自动回贴软件
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 相比于之前粗糙丑陋的黑命令框版本,这个版本新增了UI界面,从此可以不需要再挨个去翻配置文件了。 另外,升级了隐藏浏…...

初学Spring之动态代理模式
动态代理和静态代理角色一样 动态代理的代理类是动态生成的 动态代理分为两大类: 基于接口的动态代理(JDK 动态代理)、基于类的动态代理(cglib) 也可以用 Java 字节码实现(Javassist) Prox…...

Visual studio 2023下使用 installer projects 打包C#程序并创建 CustomAction 类
Visual studio 2023下使用 installer projects 打包C#程序并创建 CustomAction 类 1 安装Visual studio 20203,并安装插件1.1 下载并安装 Visual Studio1.2 步骤二:安装 installer projects 扩展插件2 创建安装项目2.1 创建Windows安装项目2.2 新建应用程序安装文件夹2.3 添加…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...

模拟调音台数字化改造:基于STM32与MOTU音频接口的智能控制方案
1. 项目概述:为老旧模拟调音台注入数字灵魂在不少社区广播电台、校园电台或是小型制作室里,你依然能看到那些服役了十几年甚至几十年的模拟调音台。它们皮实耐用,推子手感扎实,旋钮的阻尼感让人安心,但面对如今以数字文…...

工业级SCADA革命:FUXA零代码可视化平台如何重塑工业监控决策
工业级SCADA革命:FUXA零代码可视化平台如何重塑工业监控决策 【免费下载链接】FUXA Web-based Process Visualization (SCADA/HMI/Dashboard) software 项目地址: https://gitcode.com/gh_mirrors/fu/FUXA 在工业4.0和数字化转型浪潮中,传统SCADA…...