当需要对大量数据进行排序操作时,怎样优化内存使用和性能?
文章目录
- 一、选择合适的排序算法
- 1. 快速排序
- 2. 归并排序
- 3. 堆排序
- 二、数据结构优化
- 1. 使用索引
- 2. 压缩数据
- 3. 分块排序
- 三、外部排序
- 1. 多路归并排序
- 四、利用多核和并行计算
- 1. 多线程排序
- 2. 使用并行流
- 五、性能调优技巧
- 1. 避免不必要的内存复制
- 2. 缓存友好性
- 3. 基准测试和性能分析


在处理大量数据的排序操作时,优化内存使用和性能是至关重要的。这不仅可以提高程序的运行效率,还可以避免因内存不足导致的崩溃或错误。下面我们将详细探讨一些优化的方法,并提供相应的示例代码来帮助理解。
一、选择合适的排序算法
不同的排序算法在时间和空间复杂度上有所不同,因此根据数据的特点选择合适的排序算法是优化的第一步。
1. 快速排序
快速排序是一种分治的排序算法,平均情况下它的时间复杂度为 O ( n log n ) O(n \log n) O(nlogn),空间复杂度为 O ( log n ) O(\log n) O(logn) 到 O ( n ) O(n) O(n)。在大多数情况下,快速排序的性能都非常出色,特别是对于随机分布的数据。
public class QuickSort {public static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = (low - 1);for (int j = low; j <= high - 1; j++) {if (arr[j] <= pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return (i + 1);}public static void quickSort(int[] arr, int low, int high) {if (low < high) {int pi = partition(arr, low, high);quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};int n = arr.length;System.out.println("排序前的数组为:");for (int num : arr) {System.out.print(num + " ");}quickSort(arr, 0, n - 1);System.out.println("\n 排序后的数组为:");for (int num : arr) {System.out.print(num + " ");}}
}
2. 归并排序
归并排序的时间复杂度始终为 O ( n log n ) O(n \log n) O(nlogn),空间复杂度为 O ( n ) O(n) O(n)。它在处理数据量较大且对稳定性有要求的情况下表现良好。
public class MergeSort {public static void merge(int[] arr, int l, int m, int r) {int n1 = m - l + 1;int n2 = r - m;int[] L = new int[n1];int[] R = new int[n2];for (int i = 0; i < n1; i++) {L[i] = arr[l + i];}for (int j = 0; j < n2; j++) {R[j] = arr[m + 1 + j];}int i = 0, j = 0, k = l;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k++] = L[i++];} else {arr[k++] = R[j++];}}while (i < n1) {arr[k++] = L[i++];}while (j < n2) {arr[k++] = R[j++];}}public static void mergeSort(int[] arr, int l, int r) {if (l < r) {int m = l + (r - l) / 2;mergeSort(arr, l, m);mergeSort(arr, m + 1, r);merge(arr, l, m, r);}}public static void main(String[] args) {int[] arr = {12, 11, 13, 5, 6};System.out.println("排序前的数组为:");for (int num : arr) {System.out.print(num + " ");}mergeSort(arr, 0, arr.length - 1);System.out.println("\n 排序后的数组为:");for (int num : arr) {System.out.print(num + " ");}}
}
3. 堆排序
堆排序的时间复杂度为 O ( n log n ) O(n \log n) O(nlogn),空间复杂度为 O ( 1 ) O(1) O(1)。它不需要额外的存储空间,但相对来说实现较为复杂。
public class HeapSort {public static void heapify(int[] arr, int n, int i) {int largest = i;int l = 2 * i + 1;int r = 2 * i + 2;if (l < n && arr[i] < arr[l]) {largest = l;}if (r < n && arr[largest] < arr[r]) {largest = r;}if (largest!= i) {int swap = arr[i];arr[i] = arr[largest];arr[largest] = swap;heapify(arr, n, largest);}}public static void heapSort(int[] arr) {int n = arr.length;for (int i = n / 2 - 1; i >= 0; i--) {heapify(arr, n, i);}for (int i = n - 1; i >= 0; i--) {int temp = arr[0];arr[0] = arr[i];arr[i] = temp;heapify(arr, i, 0);}}public static void main(String[] args) {int[] arr = {12, 11, 13, 5, 6};System.out.println("排序前的数组为:");for (int num : arr) {System.out.print(num + " ");}heapSort(arr);System.out.println("\n 排序后的数组为:");for (int num : arr) {System.out.print(num + " ");}}
}
二、数据结构优化
除了选择合适的排序算法,还可以通过优化数据结构来提高排序的性能和内存使用。
1. 使用索引
如果数据本身具有一定的特征,例如按照某个特定字段有序存储,可以通过建立索引来加速排序过程。在数据库中,索引常用于快速定位和排序数据。
2. 压缩数据
对于某些数据,如果其中存在大量重复值或者可以进行有效的压缩编码,通过压缩数据可以减少内存占用。
3. 分块排序
将大量数据分成较小的块进行排序,然后再对块进行合并。这样可以在有限的内存中逐步处理数据,避免一次性加载和处理全部数据。
public class BlockSort {public static void sortBlock(int[] arr, int blockSize) {int numBlocks = (arr.length + blockSize - 1) / blockSize;for (int i = 0; i < numBlocks; i++) {int start = i * blockSize;int end = Math.min(start + blockSize, arr.length);Arrays.sort(arr, start, end);}int[] sorted = new int[arr.length];int index = 0;for (int i = 0; i < numBlocks - 1; i++) {int[] block = Arrays.copyOfRange(arr, i * blockSize, (i + 1) * blockSize);for (int num : block) {sorted[index++] = num;}}int[] lastBlock = Arrays.copyOfRange(arr, (numBlocks - 1) * blockSize, arr.length);for (int num : lastBlock) {sorted[index++] = num;}System.arraycopy(sorted, 0, arr, 0, arr.length);}public static void main(String[] args) {int[] arr = {9, 1, 5, 3, 7, 2, 8, 6, 4};int blockSize = 3;System.out.println("排序前的数组为:");for (int num : arr) {System.out.print(num + " ");}sortBlock(arr, blockSize);System.out.println("\n 排序后的数组为:");for (int num : arr) {System.out.print(num + " ");}}
}
三、外部排序
当数据量过大,无法一次性加载到内存中时,就需要使用外部排序算法。外部排序通常基于磁盘存储,通过多次读写数据来完成排序过程。
1. 多路归并排序
将数据分成多个子文件进行排序,然后逐步将这些已排序的子文件合并成最终的排序结果。
public class ExternalSort {public static void mergeFiles(String[] fileNames) {// 实现多路归并的逻辑}public static void createSubFiles(int[] arr, int numSubFiles) {// 将数据分成子文件}public static void externalSort(int[] arr) {createSubFiles(arr, 5); String[] fileNames = new String[5]; // 为每个子文件命名mergeFiles(fileNames);}public static void main(String[] args) {int[] arr = {9, 1, 5, 3, 7, 2, 8, 6, 4};externalSort(arr);}
}
四、利用多核和并行计算
在现代计算机系统中,通常具有多核处理器,可以利用并行计算的能力来加速排序过程。
1. 多线程排序
通过创建多个线程同时对不同的数据部分进行排序,最后合并排序结果。
public class MultiThreadSort {private static int[] arr;private static int numThreads;public static class SortThread extends Thread {private int start;private int end;public SortThread(int start, int end) {this.start = start;this.end = end;}@Overridepublic void run() {Arrays.sort(arr, start, end);}}public static void parallelQuickSort(int[] arr, int numThreads) {MultiThreadSort.arr = arr;MultiThreadSort.numThreads = numThreads;int chunkSize = arr.length / numThreads;Thread[] threads = new Thread[numThreads];for (int i = 0; i < numThreads; i++) {int start = i * chunkSize;int end = (i == numThreads - 1)? arr.length : (i + 1) * chunkSize;threads[i] = new SortThread(start, end);threads[i].start();}for (Thread thread : threads) {try {thread.join();} catch (InterruptedException e) {e.printStackTrace();}}// 合并排序结果}public static void main(String[] args) {int[] arr = {9, 1, 5, 3, 7, 2, 8, 6, 4};int numThreads = 4;parallelQuickSort(arr, numThreads);}
}
2. 使用并行流
Java 8 引入的并行流可以方便地实现并行计算。
public class ParallelSortExample {public static void main(String[] args) {int[] arr = {9, 1, 5, 3, 7, 2, 8, 6, 4};Arrays.parallelSort(arr);for (int num : arr) {System.out.print(num + " ");}}
}
五、性能调优技巧
除了上述的方法,还有一些通用的性能调优技巧可以应用于排序操作。
1. 避免不必要的内存复制
在数据处理过程中,尽量减少数据的复制操作,以降低内存开销和提高性能。
2. 缓存友好性
合理安排数据的存储和访问方式,以使其更符合 CPU 的缓存机制,提高缓存命中率。
3. 基准测试和性能分析
通过对不同的排序实现进行基准测试和性能分析,找出瓶颈所在,并针对性地进行优化。
总之,在面对大量数据的排序问题时,需要综合考虑以上提到的各种方法和技巧,根据具体的应用场景和数据特点选择最合适的方案。同时,不断地进行实验和优化,以达到最佳的性能和内存使用效果。

🎉相关推荐
- 🍅关注博主🎗️ 带你畅游技术世界,不错过每一次成长机会!
- 📢学习做技术博主创收
- 📚领书:PostgreSQL 入门到精通.pdf
- 📙PostgreSQL 中文手册
- 📘PostgreSQL 技术专栏

相关文章:
当需要对大量数据进行排序操作时,怎样优化内存使用和性能?
文章目录 一、选择合适的排序算法1. 快速排序2. 归并排序3. 堆排序 二、数据结构优化1. 使用索引2. 压缩数据3. 分块排序 三、外部排序1. 多路归并排序 四、利用多核和并行计算1. 多线程排序2. 使用并行流 五、性能调优技巧1. 避免不必要的内存复制2. 缓存友好性3. 基准测试和性…...

kubernetes集群部署:node节点部署和cri-docker运行时安装(四)
安装前准备 同《kubernetes集群部署:环境准备及master节点部署(二)》 安装cri-docker 在 Kubernetes 1.20 版本之前,Docker 是 Kubernetes 默认的容器运行时。然而,Kubernetes 社区决定在 Kubernetes 1.20 及以后的…...

第五十章 Web Service URL 汇总
文章目录 第五十章 Web Service URL 汇总Web 服务 URLWeb 服务的端点WSDL 使用受密码保护的 WSDL URL 第五十章 Web Service URL 汇总 本主题总结了与 IRIS 数据平台 Web 服务相关的 URL。 Web 服务 URL 与 IRIS Web 服务相关的 URL 如下: Web 服务的端点 http…...

动态白色小幽灵404网站源码
动态白色小幽灵404网站源码,页面时单页HTML源码,将代码放到空白的html里面,鼠标双击html即可查看效果,或者上传到服务器,错误页重定向这个界面即可,喜欢的朋友可以拿去使用 <!DOCTYPE html> <ht…...

axios的使用,处理请求和响应,axios拦截器
1、axios官网 https://www.axios-http.cn/docs/interceptors 2、安装 npm install axios 3、在onMouunted钩子函数中使用axios来发送请求,接受响应 4.出现的问题: (1) 但是如果发送请求请求时间过长,回出现请求待处…...

visual studio 2017增加.cu文件
右击项目名称,选择生成依赖项>生成自定义把CUDA11.3target勾选上; 把带有cuda代码的.cpp文件和.cu文件右击属性>项类型>选择CUDA C/C 右击项目名称,C/C>命令行添加/D _CRT_SECURE_NO_WARNINGS; 选择CUDA C/C>命…...

linux 管道符 |
在Linux中,管道符(|)是一个非常重要的概念,它允许你将一个命令的输出作为另一个命令的输入。这种机制使得Linux命令可以非常灵活地进行组合,从而执行复杂的任务。 管道符的基本用法 假设你有两个命令:com…...

Android - SIP 协议
SIP 代表(会话发起协议)。 它是一种协议,可让应用程序轻松设置呼出和呼入语音呼叫,而无需直接管理会话、传输级通信或音频记录或回放。 SIP 应用程序 SIP 的一些常见应用是。 视频会议即时消息 开发要求 以下是开发 SIP 应用程序的要求 − Android 操作系…...
Python结合MobileNetV2:图像识别分类系统实战
一、目录 算法模型介绍模型使用训练模型评估项目扩展 二、算法模型介绍 图像识别是计算机视觉领域的重要研究方向,它在人脸识别、物体检测、图像分类等领域有着广泛的应用。随着移动设备的普及和计算资源的限制,设计高效的图像识别算法变得尤为重要。…...

【】AI八股-神经网络相关
Deep-Learning-Interview-Book/docs/深度学习.md at master amusi/Deep-Learning-Interview-Book GitHub 网上相关总结: 小菜鸡写一写基础深度学习的问题(复制大佬的,自己复习用) - 知乎 (zhihu.com) CV面试问题准备持续更新贴 …...

NodeJs的安装与环境变量配置
Node.js的环境变量配置主要涉及设置Node.js的安装路径、npm(Node Package Manager)的全局模块安装路径和缓存路径,以及可能需要的国内镜像源配置。以下是详细的配置步骤: 一、安装Node.js 下载Node.js安装包: 访问Nod…...

进程输入输出及终端属性学习
进程的标准输入输出 当主进程fork或exec子进程,文件描述符被继承,因此0,1,2句柄也被继承,从而使得telnet等服务,可以做到间接调用别的shell或程序。比如如果是远程登录使用的zsh,那么其会重定向到相应的pts $ ps|gre…...

关于redis集群和事务
最近为了核算项目的两个架构指标(可用性和伸缩性),需要对项目中使用的Redis数据库的集群部署进行一定程度的了解,当然顺便再学习一遍它的事务细节。 既然我在上面把Redis称之为数据库,那么在我们目前的项目里…...

ctfshow-web入门-文件包含(web88、web116、web117)
目录 1、web88 2、web116 3、web117 1、web88 没有过滤冒号 : ,可以使用 data 协议,但是过滤了括号和等号,因此需要编码绕过一下。 这里有点问题,我 (ls) 后加上分号发现不行,可能是编码结果有加号,题目…...
My sql 安装,环境搭建
以下以MySQL 8.0.36为例。 一、下载软件 1.下载地址官网:https://www.mysql.com 2. 打开官网,点击DOWNLOADS 然后,点击 MySQL Community(GPL) Downloads 3. 点击 MySQL Installer for Windows 4.点击Archives选择合适版本 5.选择后下载…...

JVM原理(二十):JVM虚拟机内存的三特性详解
1. 原子性、可进行、有序性 1.1. 原子性 Java内存模型围绕着在并发过程中如何处理原子性、可见性和有序性这三个特征来建立的。 Java内存模型来直接保证的原子性变量操作包括read、load、assign、use、store和write这六个。我们大致可以认为,基本数据类型的访问、…...
(二))
Flink 窗口触发器(Trigger)(二)
Flink 窗口触发器(Trigger)(一) Flink 窗口触发器(Trigger)(二) Apache Flink 是一个开源流处理框架,用于处理无界和有界数据流。在 Flink 的时间窗口操作中,触发器(Trigger)是一个非常重要的概念,它决定了窗口何时应…...

CH12_函数和事件
第12章:Javascript的函数和事件 本章目标 函数的概念掌握常用的系统函数掌握类型转换掌握Javascript的常用事件 课程回顾 Javascript中的循环有那些?Javascript中的各个循环特点是什么?Javascript中的各个循环语法分别是什么?…...
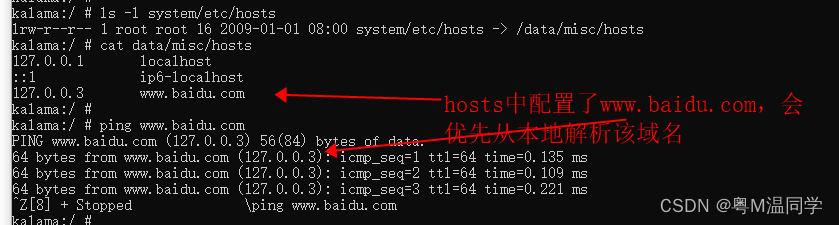
Android- Framework 非Root权限实现修改hosts
一、背景 修改system/etc/hosts,需要具备root权限,而且remount后,才能修改,本文介绍非root状态下修改system/etc/hosts方案。 环境:高通 Android 13 二、方案 非root,system/etc/hosts只有只读权限&…...
mac安装达梦数据库
参考:mac安装达梦数据库 实践如下: 1、下载达梦Docker镜像文件 同参考链接 2、导入镜像 镜像可以随便放在某个目录,相当于安装包,导入后就没有作用了。 查找达梦镜像名称:dm8_20240613_rev229704_x86…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...

Fiddler手机断网真相:TLS握手与证书固定的协议级拦截
1. 为什么Fiddler一开,手机就断网?这不是配置问题,是协议层的“信任危机”Fiddler抓包手机流量,本该是移动开发、测试、安全分析中最基础的操作之一。但几乎每个刚上手的人,都会在第二天早上发现:手机Wi-Fi…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...

<数据集>yolo高粱叶片病害识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92902223数据集格式:VOCYOLO格式 图片数量:3242张 标注数量(xml文件个数):3242 标注数量(txt文件个数):3242 标注类别数:1 使用标注工具ÿ…...