AIGC专栏12——EasyAnimateV3发布详解 支持图文生视频 最大支持960x960x144帧视频生成
AIGC专栏12——EasyAnimateV3发布详解 支持图&文生视频 最大支持960x960x144帧视频生成
- 学习前言
- 项目特点
- 生成效果
- 相关地址汇总
- 项目主页
- Huggingface体验地址
- Modelscope体验地址
- 源码下载地址
- EasyAnimate V3详解
- 技术储备
- Diffusion Transformer (DiT)
- Hybrid Motion Module
- U-VIT
- Lora
- 算法细节
- 算法组成
- Slice VAE
- Hybrid Motion Module
- 图生视频技术路线
- 项目使用
- 项目启动
- 文生视频
- 图生视频
- 超长视频生成
学习前言
研究了好长时间的文生视频,EasyAnimate到了V3版本,我们将vae修改从MagVIT替换成了Slice VAE,同时支持图生视频,扩大了生成的分辨率。
现在EasyAnimate支持 图 和 文 生视频 同时最大支持960x960 144帧的视频生成,FPS为24,另外通过图生视频的能力,我们还可以进行视频续写,生成无限长视频。
本文主要进行EasyAnimateV3的算法详解,并且介绍一下EasyAnimateV3的使用。

项目特点
- 支持 图 和 文 生视频;
- 支持 首尾图 生成视频
- 最大支持720p 144帧视频生成;
- 最低支持12G显存使用(3060 12G可用);
- 无限长视频生成;
- 数据处理到训练完整pipeline代码开源。
生成效果
EasyAnimateV3的生成效果如下,分别支持图生视频和文生视频。
通过图生视频的能力,我们还可以进行视频续写,生成无限长视频。

下面是一些比较好,有意思的生成结果,通过图生视频实现。
人像:





动物:





火焰:



水:




名画:




其它:




相关地址汇总
项目主页
https://easyanimate.github.io/
Huggingface体验地址
https://modelscope.cn/studios/PAI/EasyAnimate/summary
Modelscope体验地址
https://huggingface.co/spaces/alibaba-pai/EasyAnimate
源码下载地址
https://github.com/aigc-apps/EasyAnimate
感谢大家的关注。
EasyAnimate V3详解
技术储备
Diffusion Transformer (DiT)
DiT基于扩散模型,所以不免包含不断去噪的过程,如果是图生图的话,还有不断加噪的过程,此时离不开DDPM那张老图,如下:
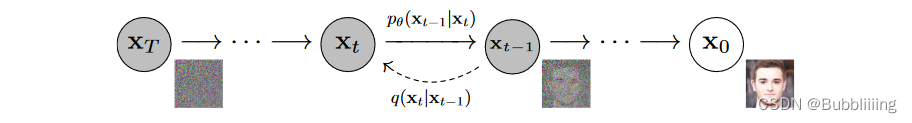
DiT相比于DDPM,使用了更快的采样器,也使用了更大的分辨率,与Stable Diffusion一样使用了隐空间的扩散,但可能更偏研究性质一些,没有使用非常大的数据集进行预训练,只使用了imagenet进行预训练。
与Stable Diffusion不同的是,DiT的网络结构完全由Transformer组成,没有Unet中大量的上下采样,结构更为简单清晰。
在EasyAnimateV3中,我们设计了一个独特的混合Motion Module加入到DiT中,在Motion Module中引入了全局信息,借助DIT的强大生成能力进行视频生成。
Hybrid Motion Module
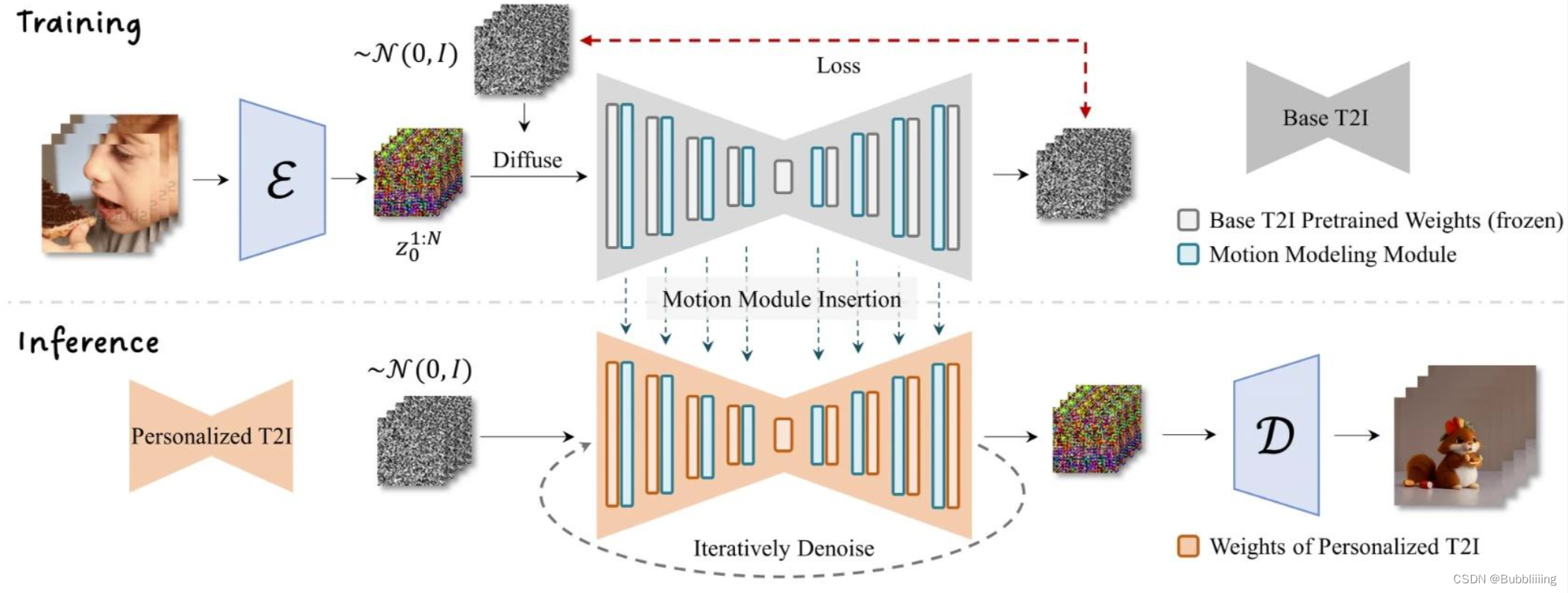
AnimateDiff是一个可以对文生图模型进行动画处理的实用框架,其内部设计的Motion Module无需进行特定模型调整,即可一次性为大多数现有的个性化文本转图像模型提供动画化能力。
EasyAnimate参考AnimateDiff使用Motion Module保证视频的连续性。原始的Motion Module只关注特征点在时间轴上的特征信息,以提炼出合理的运动先验,在AnimateDiff中只更新了运动模块的参数,所以Motion Module是一个可插入的结构,可以用在不同的微调backbone中。
相比于原始的Motion Module,我们引入了全局Attention信息,提出了Hybrid Motion Module,Hybrid Motion Module在偶数层上只关注时间轴上的特征信息,在奇数层上关注全局信息。通过奇偶不同的处理方法,既实现了计算量的缩减,也提高了全局的信息感受能力。
在EasyAnimate中,为了更好的生成效果,我们将Backbone连同Motion Module一起Finetune,同时联合图片和视频一起Finetune。在一个Pipeline中即实现了图片的生成,也实现了视频的生成。
U-VIT

在训练过程中,我们发现纯DIT结构在训练视频时不算稳定,经常存在损失突然上升的情况,并且由于视频的特征层较大,拟合速度较慢。
参考U-vit,我们将跳连接结构引入到EasyAnimate当中,通过引入浅层特征进一步优化深层特征,并且我们0初始化了一个全连接层给每一个跳连接结构,使其可以作为一个可插入模块应用到之前已经训练的还不错的DIT中。
Lora
由《LoRA: Low-Rank Adaptation of Large Language Models》 提出的一种基于低秩矩阵的对大参数模型进行少量参数微调训练的方法,广泛引用在各种大模型的下游使用中。
EasyAnimate有良好的拓展性,我们可以对文生图模型训练Lora后应用到文生视频模型中。
算法细节
算法组成
我们使用了PixArt-alpha作为基础模型,并在此基础上引入额外的混合运动模块(Hybrid Motion Module)结合时间轴信息和全局信息进行视频的生成。
EasyAnimateV3包括Text Encoder、Slice VAE(用于作为视频编码器和视频解码器)和 视频Diffusion Transformer(基于Hybrid Motion Module的DiT)。T5 Encoder用作文本编码器。整体架构图如下:

Slice VAE
在早期的研究中,基于图像的VAE已被广泛用于视频帧的编码和解码,如AnimateDiff、ModelScopeT2V和OpenSora。在Stable Dif fusion使用VAE实现将每个视频帧编码为单独的潜在特征,从而将帧的空间维度显著缩小到宽度和高度的八分之一。但这种编码技术忽略了时间信息,将视频降级为静态图像表示。
传统的基于图像的VAE的一个显著问题是它无法在时间维度上进行压缩,这不仅无法关注到细微的帧间信息,并且导致潜在的latent的shape很大,进一步导致GPU VRAM的激增。这些挑战严重阻碍了这种方法在长视频创作中的实用性。因此,视频VAE的挑战在于如何有效地压缩时间维度。
此外,我们的同时需要使用图像和视频对VAE进行训练。先前的研究表明,将图像集成到视频训练Pipeline中可以更有效地优化模型架构,从而改进其文本对齐并提高输出质量。
在EasyAnimateV2中,我们采取了MagViT作为视频VAE。它采用Casual 3D Conv。在使用普通3D Conv之前,该块在时间轴前引入填充,从而确保每一帧可以利用它先前的信息来增强因果关系,同时不考虑到后帧的影响。但由于GPU VRAM的限制。当视频增大时,MagViT所需的内存往往甚至超过A100 GPU的可用内存,这个问题突出了分批处理的必要性,它有助于增量解码,而不是试图一步解码整个序列**。分批处理两种方式如下:

但MagViT并不适合进行时间轴上的分批处理,因为MagViT的独特机制,3D Conv前需要进行前向填充,对应的潜在latent中,每个部分的第一个latent由于填充特征仅包含较少的信息。这种不均匀的信息分布是一个可能阻碍模型优化的方面。此外,MagViT使用这种批处理策略还影响处理过程中视频的压缩率。
这促使我们在EasyAnimateV3中引入Slice VAE,该VAE在面临不同输入时使用不同的处理策略,当输入的是视频帧时,则在高宽与时间轴上进行压缩,当输入为512x512x8的视频帧时,将其压缩为64x64x2的潜在latent;当输入的是图片时,则仅仅在高宽上进行压缩,当输入为512x512的图片时,将其压缩为64x64x1的潜在latent。

为了进一步提高解码的性能,我们在不同的时间轴批次之间实现特征共享,如图中所示。在解码过程中,特征与它们的前一个和后一个特征相连,从而产生更一致的特征并实现比MagViT更高的压缩率。通过这种方式,编码的特征封装了时间信息,这反过来又节省了计算资源,同时提高了生成结果的质量。
Hybrid Motion Module
我们设计了一个独特的运动模块,命名为Hybrid Motion Module,混合运动模块专门设计用于嵌入时间信息并引入全局信息。
通过我们在偶数层上,在时间维度上集成注意力机制,使得模型获得了时间轴上的先验知识,而在奇数层上,我们在全局序列中进行全局注意力,提高模型的全局感受野。如下图(b)所示。

图生视频技术路线

图生视频记录路线如上图所示,我们提供双流的信息注入:
- 需要重建的部分和重建的参考图分别通过VAE进行编码,上图黑色的部分代表需要重建的部分,白色的部分代表首图,然后和随机初始化的latent进行concat,假设我们期待生成一个384x672x144的视频,此时的初始latent就是4x36x48x84,需要重建的部分和重建的参考图编码后也是4x36x48x84,三个向量concat到一起后便是12x36x48x84,传入DiT模型中进行噪声预测。
- 在文本侧,我们使用CLIP Image对输入图片Encoder之后,使用一个Proj进行映射,然后将结果与T5编码后的文本进行concat,然后在DiT中进行Cross Attention。
通过图生视频的能力,我们还可以通过上一段视频的尾帧进行视频续写,生成无限长视频。
项目使用
项目启动
推荐在docker中使用EasyAnimateV3:
# pull image
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate# enter image
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate# clone code
git clone https://github.com/aigc-apps/EasyAnimate.git# enter EasyAnimate's dir
cd EasyAnimate# download weights
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Modelwget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tar -O models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tarcd models/Diffusion_Transformer/
tar -xvf EasyAnimateV3-XL-2-InP-512x512.tar
cd ../../python app.py
到这里已经可以打开gradio网站了。
文生视频
首先进入gradio网站:

选择对应的预训练模型,如"models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512"。
然后在下方填写提示词。

然后调整视频高宽和生成帧数,最后进行生成;
- 512x512模型常用生成高宽为384x672。
- 768x768模型常用生成高宽为576x1008。
- 960x960模型常用生成高宽为720x1248。

图生视频
图生视频与文生视频有两个不同点:
- 1、需要指定参考图;
- 2、指定与参考图类似的高宽;
EasyAnimateV3的ui已经提供了自适应的按钮Resize to the Start Image,打开后可以自动根据输入的首图调整高宽。

超长视频生成
EasyAnimateV3支持超长视频生成,通过图生视频的能力,我们还可以进行视频尾帧续写,生成无限长视频。

相关文章:
AIGC专栏12——EasyAnimateV3发布详解 支持图文生视频 最大支持960x960x144帧视频生成
AIGC专栏12——EasyAnimateV3发布详解 支持图&文生视频 最大支持960x960x144帧视频生成 学习前言项目特点生成效果相关地址汇总项目主页Huggingface体验地址Modelscope体验地址源码下载地址 EasyAnimate V3详解技术储备Diffusion Transformer (DiT)Hybrid Motion ModuleU-V…...

【python】python猫眼电影数据抓取分析可视化(源码+数据集+论文)【独一无二】
👉博__主👈:米码收割机 👉技__能👈:C/Python语言 👉公众号👈:测试开发自动化【获取源码商业合作】 👉荣__誉👈:阿里云博客专家博主、5…...

Android 四大组件
1. Activity 应用程序中,一个Activity通常是一个单独的屏幕,它上面可以显示一些控件,也可以监听并对用户的事件做出响应。 Activity之间通过Intent进行通信,在Intent 的描述结构中,有两个最重要的部分:动…...

【Python】已解决:ModuleNotFoundError: No module named ‘nltk’
文章目录 一、分析问题背景二、可能出错的原因三、错误代码示例四、正确代码示例五、注意事项 已解决:ModuleNotFoundError: No module named ‘nltk’ 一、分析问题背景 在使用Python进行自然语言处理或文本分析时,我们经常会用到各种库来辅助我们的工…...

【Docker系列】Docker 命令行输出格式化指南
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

使用Netty构建高性能的网络应用
使用Netty构建高性能的网络应用 大家好,我是微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! Netty是一个基于Java NIO的异步事件驱动的网络应用框架,专为快速开发高性能、高可靠性的网络服务器和客户…...

C++11新特性【下】{lambda表达式、可变模板参数、包装器}
一、lambda表达式 在C98中,如果想要对一个数据集合中的元素进行排序,可以使用std::sort方法。如果待排序元素为自定义类型,需要用户定义排序时的比较规则,随着C语法的发展,人们开始觉得上面的写法太复杂了,…...

SpringBoot使用手册
SpringBoot使用手册 1、自动装配 1.1、创建spring Boot项目 在之前的文章中已经专门写过,这里不做赘述。 1.2、pom.xml 1.2.1、版本管理 在学习完maven项目后,我们学习框架时首先阅读的就是pom.xml文件,这里是管理自己该项目中所用到的…...

HTML CSS 基础复习笔记 - 列表使用
用于自己复习 自定义列表 示例代码 <!DOCTYPE html> <html> <head><title>Definition List Example</title> </head> <body><h1>古诗</h1><dl><dt>静夜思</dt><dd>床前明月光,疑…...
017-GeoGebra基础篇-微积分函数求解圆弧面积问题
基础篇慢慢的走进尾声,今天给大家带来一个小项目,是关于高中数学微积分部分的展示,这个项目主要包含了函数的介绍、函数与图形绘制的区别、区域函数图像的绘制、积分函数的应用、动态文本的调用、嵌套滑动条的应用等等,以及其他常…...
Element中的选择器组件Select (一级选择组件el-select)
简述:在 Element UI 中,ElSelect(或简称为 Select)是一个非常常用的选择器组件,它提供了丰富的功能来帮助用户从一组预定义的选项中选择一个或多个值。这里来简单记录一下 一. 组件和属性配置 <el-selectv-model&q…...

数值分析笔记(五)线性方程组解法
三角分解法 A的杜利特分解公式如下: u 1 j a 1 j ( j 1 , 2 , ⋯ , n ) , l i 1 a i 1 / u 11 ( i 2 , 3 , ⋯ , n ) , u k j a k j − ∑ m 1 k − 1 l b m u m j ⇒ a k j ( j k , k 1 , ⋯ , n ) , l i k ( a i k − ∑ m 1 k − 1 l i n u m k ) /…...
IDEA中Maven的配置
目录 1. 安装maven 2. 配置环境变量 3. IDEA中配置Maven 4. 配置仓库目录 1. 安装maven 官网下载地址:Maven – Download Apache Maven 下载后,将zip压缩包解压到某个目录即可。 2. 配置环境变量 变量名称随意,通常为M2_HOMEÿ…...

成人高考本科何时报名-深职训学校帮您规划学习之路
你有想过继续深造自己的学历吗?也许你已经工作多年,但总觉得学历是一块心病,想要通过成人高考本科来提升自己。不用着急,今天我们来聊一聊成人高考本科的报名时间,以及深职训学校如何帮助你顺利完成报名。 深圳成人高…...
)
C++ STL 协程(Coroutines)
一:什么是协程(Coroutines): 协程是轻量级线程,可以暂停和恢复执行,协程拥有自己的暂停点状态,协程暂停时,将当前状态保存起来,在恢复执行时会恢复之前保存的状态。 二:例子: #include <coroutine> #include <iostream>void doTheWork() {std::cout <…...

虚拟机下基于海思移植QT(一)——虚拟机下安装QT
0.参考资料 1.海思Hi3516DV300 移植Qt 运行并在HDMI显示器上显示 2.搭建海思3559A-Qt4.8.7Openssl开发环境 1.报错解决 通过下面命令查询 strings /lib/x86_64-linux-gnu/libc.so.6 | grep GLIBC_通过命令行没有解决: sudo apt install libc6-dev libc6参考解决…...

计算机网络部分知识点整理
停止等待协议的窗口尺寸为 1。 √以太网标准是IEEE802.3TCP/IP四层,OSI模型有7层,地址解析协议 ARP 在 OSI 参考七层协议属于数据链路层,在TCP/IP 协议属于网络层,ARP作用:将 IP 地址映射到第二层地址,交换…...

【Qt】Qt概述
目录 一. 什么是Qt 二. Qt的优势 三. Qt的应用场景 四. Qt行业发展方向 一. 什么是Qt Qt是一个跨平台的C图形用户界面应用程序框架,为应用程序开发者提供了建立艺术级图形界面所需的所有功能。 Qt是完全面向对象的,很容易扩展,同时Qt为开发…...

读书笔记-《魔鬼经济学》
这是一本非常有意思的经济学启蒙书,作者探讨了许多问题,并通过数据找到答案。 我们先来看看作者眼中的“魔鬼经济学”是什么,再选一个贴近我们生活的例子进行阐述。 01 魔鬼经济学 中心思想:假如道德代表人类对世界运转方式的期…...

2024.7.7总结
今天是惊心动魄的一天,记录一下吧! 昨天晚上害怕早上闹铃响了听不到,担心有意外出现,错过回家的车票,于是便在晚上设置了3个闹铃,6:50,7:00,7:05然后也关了静音。没想到,早上按照正…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...
)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理(附dpkg/apt组合拳)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理 在UOS系统日常使用中,WPS Office作为常用办公软件,有时因版本更新或功能调整需要彻底卸载。但不少用户发现,通过图形界面或简单命令卸载后,系统中仍残留配置文件、…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

从零开始的Linux#2 vim编辑器
介绍vi\vim是Linux中最经典的文本编辑器,vim是vi的全面升级版本,我们后面只用vim通过vim编辑器编辑文件,需要使用命令vim 文件路径如果文件路径表示的文件不存在,那么此命令会用于编辑新文件;如果存在则编辑已有文件模…...

开发者在构建多模态AI应用时如何借助TaoToken简化模型集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在构建多模态AI应用时如何借助TaoToken简化模型集成 构建一个集成了文本、图像等多模态能力的AI应用,开发者常常…...