【PYG】GNN和全连接层(FC)分别在不同的类中,使用反向传播联合训练,实现端到端的训练过程
文章目录
- 基本步骤
- GNN和全连接层(FC)联合训练
- 1. 定义GNN模型类
- 2. 定义FC模型类
- 3. 训练循环中的联合优化
- 解释
- 完整代码
- GNN和全连接层(FC)分别使用不同的优化器和学习率分别进行参数更新
- 解释
基本步骤
要从GNN(图神经网络)中提取特征,并使用全连接层(FC,Fully Connected Layer)进行后续处理,可以按照以下步骤进行:
-
构建图神经网络模型:选择一种GNN架构,例如GCN(Graph Convolutional Network)、GAT(Graph Attention Network)等。你可以使用深度学习框架(如PyTorch、TensorFlow)来实现。
-
获取节点特征和图结构:准备好节点特征矩阵和邻接矩阵,这些是GNN模型的输入。
-
通过GNN提取特征:
- 设计GNN模型的前向传播过程,将节点特征和邻接矩阵输入GNN层。
- 从GNN层的输出中提取节点的嵌入特征。
-
连接全连接层进行分类或回归:
- 将GNN提取的节点特征作为输入传递给一个或多个全连接层。
- 通过全连接层进行后续的分类、回归等任务。
GNN和全连接层(FC)联合训练
如果GNN和全连接层(FC)分别在不同的类中,并且你希望它们可以联合训练,你可以通过以下步骤实现端到端的训练过程,并确保反向传播能够正确进行:
- 定义GNN和FC模型:分别定义GNN和FC模型类。
- 特征提取与分类:在训练循环中,将GNN提取的特征传递给FC进行分类。
- 联合优化:使用一个优化器来更新两个模型的参数。
以下是具体的实现步骤和代码示例:
1. 定义GNN模型类
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.data import Data, Batch
from sklearn.preprocessing import StandardScalerclass GNN(nn.Module):def __init__(self, in_channels, hidden_channels, out_channels):super(GNN, self).__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, out_channels)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = self.conv2(x, edge_index)gnn_features = F.relu(x)return gnn_features
2. 定义FC模型类
class FC(nn.Module):def __init__(self, in_features, num_classes):super(FC, self).__init__()self.fc = nn.Linear(in_features, num_classes)def forward(self, x):out = self.fc(x)return out
3. 训练循环中的联合优化
# 假设我们有一些数据
num_nodes_per_graph = 10
num_graphs = 5
num_node_features = 16
num_classes = 3# 创建多个图数据
graphs = []
for _ in range(num_graphs):x = torch.randn((num_nodes_per_graph, num_node_features))scaler = StandardScaler()x = torch.tensor(scaler.fit_transform(x), dtype=torch.float) # 标准化edge_index = torch_geometric.utils.grid(num_nodes_per_graph)graphs.append(Data(x=x, edge_index=edge_index))# 批处理数据
batch = Batch.from_data_list(graphs)# 创建模型
gnn_model = GNN(in_channels=num_node_features, hidden_channels=32, out_channels=64)
fc_model = FC(in_features=64, num_classes=num_classes)# 使用一个优化器来联合优化两个模型的参数
optimizer = torch.optim.Adam(list(gnn_model.parameters()) + list(fc_model.parameters()), lr=1e-4)
criterion = nn.CrossEntropyLoss()# 生成一些随机目标
target = torch.randint(0, num_classes, (num_nodes_per_graph * num_graphs,))# 训练模型
for epoch in range(100):gnn_model.train()fc_model.train()optimizer.zero_grad()# 前向传播通过GNN模型gnn_features = gnn_model(batch)# 前向传播通过FC模型output = fc_model(gnn_features)# 计算损失loss = criterion(output, target)# 反向传播loss.backward()# 优化器步optimizer.step()print(f'Epoch {epoch+1}, Loss: {loss.item()}')# 查看特征
print("Extracted GNN features:", gnn_features)
解释
- GNN模型类:
GNN类定义了一个简单的两层GCN模型,用于特征提取。 - FC模型类:
FC类定义了一个全连接层模型,用于分类。 - 联合优化:
- 在训练循环中,首先通过GNN模型提取特征,然后将提取的特征传递给FC模型进行分类。
- 使用一个优化器来同时优化GNN和FC模型的参数。
- 通过调用
optimizer.zero_grad()清除梯度,调用loss.backward()进行反向传播,最后调用optimizer.step()更新参数。
通过这种方式,尽管GNN和FC模型分别在不同的类中,它们仍然可以端到端地进行联合训练,并确保梯度正确地传播到整个模型的每一部分。
使用正确的参数来生成随机图。torch_geometric.utils.erdos_renyi_graph需要使用num_nodes和edge_prob参数
完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.data import Data, Batch
from torch_geometric.nn import GCNConv
from torch_geometric.utils import erdos_renyi_graph
from sklearn.preprocessing import StandardScalerclass GNN(nn.Module):def __init__(self, in_channels, hidden_channels, out_channels):super(GNN, self).__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, out_channels)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = self.conv2(x, edge_index)gnn_features = F.relu(x)return gnn_featuresclass FC(nn.Module):def __init__(self, in_features, num_classes):super(FC, self).__init__()self.fc = nn.Linear(in_features, num_classes)def forward(self, x):out = self.fc(x)return out# 假设我们有一些数据
num_nodes_per_graph = 10
num_graphs = 5
num_node_features = 16
num_classes = 3# 创建多个图数据
graphs = []
for _ in range(num_graphs):x = torch.randn((num_nodes_per_graph, num_node_features))scaler = StandardScaler()x = torch.tensor(scaler.fit_transform(x), dtype=torch.float) # 标准化edge_index = erdos_renyi_graph(num_nodes=num_nodes_per_graph, edge_prob=0.5) # 生成随机图graphs.append(Data(x=x, edge_index=edge_index))# 批处理数据
batch = Batch.from_data_list(graphs)# 创建模型
gnn_model = GNN(in_channels=num_node_features, hidden_channels=32, out_channels=64)
fc_model = FC(in_features=64, num_classes=num_classes)# 使用一个优化器来联合优化两个模型的参数
optimizer = torch.optim.Adam(list(gnn_model.parameters()) + list(fc_model.parameters()), lr=1e-4)
criterion = nn.CrossEntropyLoss()# 生成一些随机目标
target = torch.randint(0, num_classes, (num_nodes_per_graph * num_graphs,))# 训练模型
for epoch in range(100):gnn_model.train()fc_model.train()optimizer.zero_grad()# 前向传播通过GNN模型gnn_features = gnn_model(batch)# 前向传播通过FC模型output = fc_model(gnn_features)# 计算损失loss = criterion(output, target)# 反向传播loss.backward()# 优化器步optimizer.step()print(f'Epoch {epoch+1}, Loss: {loss.item()}')# 查看特征
print("Extracted GNN features:", gnn_features)GNN和全连接层(FC)分别使用不同的优化器和学习率分别进行参数更新
如果你想为GNN和全连接层(FC)分别使用不同的优化器和学习率,可以按照以下步骤进行:
- 定义两个优化器:一个用于GNN模型,另一个用于FC模型。
- 分别进行参数更新:在训练循环中,分别对两个模型进行前向传播、损失计算和反向传播,然后使用各自的优化器更新参数。
以下是实现代码示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.data import Data, Batch
from torch_geometric.nn import GCNConv
from torch_geometric.utils import erdos_renyi_graph
from sklearn.preprocessing import StandardScalerclass GNN(nn.Module):def __init__(self, in_channels, hidden_channels, out_channels):super(GNN, self).__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, out_channels)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = self.conv2(x, edge_index)gnn_features = F.relu(x)return gnn_featuresclass FC(nn.Module):def __init__(self, in_features, num_classes):super(FC, self).__init__()self.fc = nn.Linear(in_features, num_classes)def forward(self, x):out = self.fc(x)return out# 假设我们有一些数据
num_nodes_per_graph = 10
num_graphs = 5
num_node_features = 16
num_classes = 3# 创建多个图数据
graphs = []
for _ in range(num_graphs):x = torch.randn((num_nodes_per_graph, num_node_features))scaler = StandardScaler()x = torch.tensor(scaler.fit_transform(x), dtype=torch.float) # 标准化edge_index = erdos_renyi_graph(num_nodes=num_nodes_per_graph, edge_prob=0.5) # 生成随机图graphs.append(Data(x=x, edge_index=edge_index))# 批处理数据
batch = Batch.from_data_list(graphs)# 创建模型
gnn_model = GNN(in_channels=num_node_features, hidden_channels=32, out_channels=64)
fc_model = FC(in_features=64, num_classes=num_classes)# 使用两个优化器分别优化GNN和FC模型的参数
optimizer_gnn = torch.optim.Adam(gnn_model.parameters(), lr=1e-3) # GNN使用较高的学习率
optimizer_fc = torch.optim.Adam(fc_model.parameters(), lr=1e-4) # FC使用较低的学习率
criterion = nn.CrossEntropyLoss()# 生成一些随机目标
target = torch.randint(0, num_classes, (num_nodes_per_graph * num_graphs,))# 训练模型
for epoch in range(100):gnn_model.train()fc_model.train()optimizer_gnn.zero_grad()optimizer_fc.zero_grad()# 前向传播通过GNN模型gnn_features = gnn_model(batch)# 前向传播通过FC模型output = fc_model(gnn_features)# 计算损失loss = criterion(output, target)# 反向传播loss.backward()# 使用各自的优化器更新参数optimizer_gnn.step()optimizer_fc.step()print(f'Epoch {epoch+1}, Loss: {loss.item()}')# 查看特征
print("Extracted GNN features:", gnn_features)
解释
- GNN模型类:
GNN类定义了一个简单的两层GCN模型,用于特征提取。 - FC模型类:
FC类定义了一个全连接层模型,用于分类。 - 数据生成:使用
torch_geometric.utils.erdos_renyi_graph生成随机图数据,并确保参数正确。 - 联合优化:
- 定义两个优化器,分别用于GNN和FC模型,并为它们设置不同的学习率。
- 在训练循环中,首先通过GNN模型提取特征,然后将提取的特征传递给FC模型进行分类。
- 使用各自的优化器来分别清除梯度、进行反向传播和更新参数。
通过这种方式,尽管GNN和FC模型分别在不同的类中,并使用不同的优化器和学习率,它们仍然可以端到端地进行联合训练,并确保梯度正确地传播到整个模型的每一部分。
相关文章:
分别在不同的类中,使用反向传播联合训练,实现端到端的训练过程)
【PYG】GNN和全连接层(FC)分别在不同的类中,使用反向传播联合训练,实现端到端的训练过程
文章目录 基本步骤GNN和全连接层(FC)联合训练1. 定义GNN模型类2. 定义FC模型类3. 训练循环中的联合优化解释完整代码 GNN和全连接层(FC)分别使用不同的优化器和学习率分别进行参数更新解释 基本步骤 要从GNN(图神经网…...

vue3使用方式汇总
1、引入iconfont阿里图库图标: 1.1 进入阿里图标网站: iconfont阿里:https://www.iconfont.cn/ 1.2 添加图标: 1.3 下载代码: 1.4 在vue3中配置代码: 将其代码复制到src/assets/fonts/目录下࿱…...
Turborepo简易教程
参考官网:https://turbo.build/repo/docs 开始 安装全新的项目 pnpm dlx create-turbolatest测试应用包含: 两个可部署的应用三个共享库 运行: pnpm install pnpm dev会启动两个应用web(http://localhost:3000/)、docs(http://localhost…...

初中物理知识点总结(人教版)
初中物理知识点大全 声现象知识归纳 1 .声音的发生:由物体的振动而产生。振动停止,发声也停止。 2.声音的传播:声音靠介质传播。真空不能传声。通常我们听到的声音是靠空气传来的。 3.声速:在空气中传播速度是:340…...
ChatGPT-4o大语言模型优化、本地私有化部署、从0-1搭建、智能体构建等高级进阶
目录 第一章 ChatGPT-4o使用进阶 第二章 大语言模型原理详解 第三章 大语言模型优化 第四章 开源大语言模型及本地部署 第五章 从0到1搭建第一个大语言模型 第六章 智能体(Agent)构建 第七章 大语言模型发展趋势 第八章 总结与答疑讨论 更多应用…...
【开源项目】LocalSend 局域网文件传输工具
【开源项目】LocalSend 局域网文件传输工具 一个免费、开源、跨平台的局域网传输工具 LocalSend 简介 LocalSend 是一个免费的开源跨平台的应用程序,允许用户在不需要互联网连接的情况下,通过本地网络安全地与附近设备共享文件和消息。 项目地址&…...
:地平线嵌入式实习)
ARM/Linux嵌入式面经(十一):地平线嵌入式实习
地平线嵌入式实习面经 1.自我介绍 等着,在给大哥们准备了。 2.spi与iic协议可以连接多个设备吗?最多多少个?通讯时序。 这是几个问题,在回答的时候。不要一问就开口,花几秒钟沉吟思考整理一下自己的思路。 这个问题问了几个点?每个点的回答步骤。 是我的话,我会采用以…...

基于Redis的分布式锁
分布式场景下并发安全问题的引发 前面通过加锁解决了单机状态下一人一单的问题,但是当出现了分布式,前面的加锁形式不再适用 ,每个jvm有一个自己的锁监视器,只能被内部线程获取,其他jvm无法使用,那么多台j…...

如何将 Apifox 的自动化测试与 Jenkins 集成?
CI/CD (持续集成/持续交付) 在 API 测试 中的主要目的是为了自动化 API 的验证流程,确保 API 发布到生产环境前的可用性。通过持续集成,我们可以在 API 定义变更时自动执行功能测试,以及时发现潜在问题。 Apifox 支持…...

【FFmpeg】av_write_frame函数
目录 1.av_write_frame1.1 写入pkt(write_packets_common)1.1.1 检查pkt的信息(check_packet)1.1.2 准备输入的pkt(prepare_input_packet)1.1.3 检查码流(check_bitstream)1.1.4 写入…...

【算法专题】双指针算法
1. 移动零 题目分析 对于这类数组分块的问题,我们应该首先想到用双指针的思路来进行处理,因为数组可以通过下标进行访问,所以说我们不用真的定义指针,用下标即可。比如本题就要求将数组划分为零区域和非零区域,我们不…...

Lock与ReentrantLock
在 Java 中,Lock 接口和 ReentrantLock 类提供了比使用 synchronized 方法和代码块更广泛的锁定机制。 简单示例: import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock;public class ReentrantLockExample {pr…...
:紫光同芯嵌入式)
ARM/Linux嵌入式面经(十三):紫光同芯嵌入式
static关键字 static关键字一文搞懂这个知识点,真的是喜欢考!!! stm32启动时如何配置栈的地址 在STM32启动时配置栈的地址是一个关键步骤,这通常是在启动文件(如startup_stm32fxxx.s,其中xxx代表具体的STM32型号)中完成的。 面试者回答: STM32启动时配置栈的地址主…...
—— 说说你空窗期做了什么?)
名企面试必问30题(二十四)—— 说说你空窗期做了什么?
回答示例一 在空窗期这段时间,我主要进行了两方面的活动。 一方面,我持续提升自己的专业技能。我系统地学习了最新的软件测试理论和方法,深入研究了自动化测试工具和框架,例如 Selenium、Appium 等,并通过在线课程和实…...

基础权限储存
一、要求: 1、建立用户组shengcan,其id为2000工 2、建立用户组 caiwu,其id为2001 3、建立用户组 jishu,其id 为 2002 4、建立目录/sc,此目录是 shengchan 部门的存储目录,只能被 shengchan 组的成员操作,其他用户没有…...

Could not find a package configuration file provided by “roscpp“ 的参考解决方法
文章目录 写在前面一、问题描述二、解决方法参考链接 写在前面 自己的测试环境: Ubuntu20.04 ROS-Noetic 一、问题描述 编译程序时出现如下报错: -- Could NOT find roscpp (missing: roscpp_DIR) -- Could not find the required component roscpp.…...

运维系列.Nginx配置中的高级指令和流程控制
运维专题 Nginx配置中的高级指令和流程控制 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/…...

Virtualbox和ubuntu之间的关系
1、什么是ubuntu Ubuntu 是一个类似于 Windows 的操作系统,但它是基于 Linux 内核开发的开源操作系统 2、什么是Virtualbox VirtualBox 是一款虚拟机软件,使我们可以物理机上创建和运行虚拟机 也就是说,VirtualBox 提供了一个可以安装和运行其他操作系…...

【在Linux世界中追寻伟大的One Piece】HTTPS协议原理
目录 1 -> HTTPS是什么? 2 -> 相关概念 2.1 -> 什么是"加密" 2.2 -> 为什么要加密 2.3 -> 常见的加密方式 2.4 -> 数据摘要 && 数据指纹 2.5 -> 数字签名 3 -> HTTPS的工作过程 3.1 -> 只使用对称加密 3.2 …...
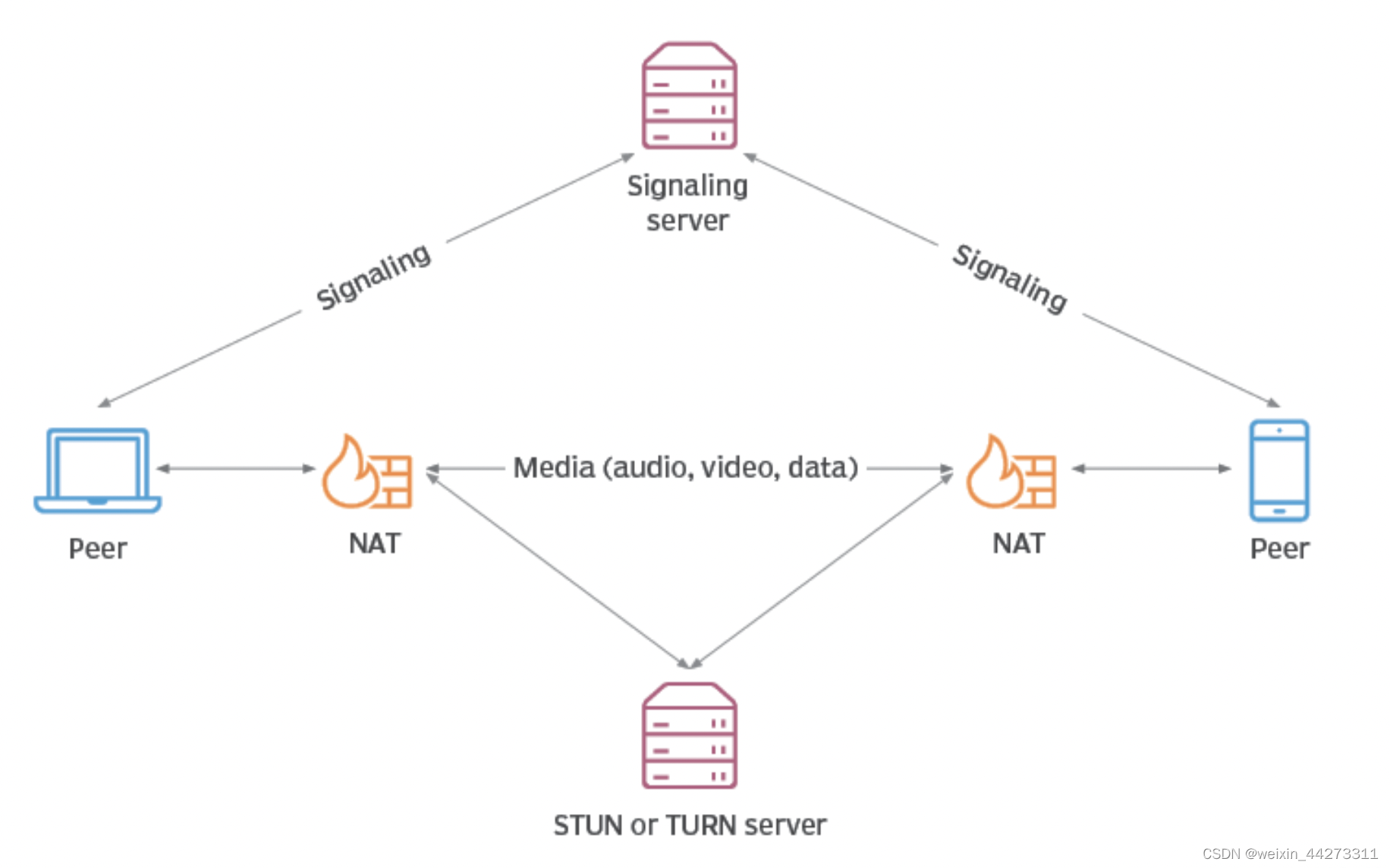
【WebRTC实现点对点视频通话】
介绍 WebRTC (Web Real-Time Communications) 是一个实时通讯技术,也是实时音视频技术的标准和框架。简单来说WebRTC是一个集大成的实时音视频技术集,包含了各种客户端api、音视频编/解码lib、流媒体传输协议、回声消除、安全传输等。对于开发者来说可以…...

标书制作入门
电子标书时代来了,但很多中小企业还在用老方法踩坑🕳️ 伟发标书10年经验,今天说点大实话👇一、电子标书不是"纸质版扫描件"📄 很多人以为电子标书就是把纸质文件转成PDF,大错特错❌ 真正的电子标…...

从‘设备管理’到‘电商分类’:手把手教你封装一个uni-app万能级联选择器组件
从设备管理到电商分类:打造uni-app万能级联选择器的工程化实践 在移动应用开发中,级联选择器是一个高频出现的交互组件。无论是电商平台的三级分类筛选、组织架构的人员选择,还是多级地址录入,这类场景都需要一个灵活、可复用的解…...

全球工业3D打印标杆:Stratasys全系列产品深度盘点
作为全球工业级3D打印与增材制造解决方案的领导者,Stratasys凭借FDM、PolyJet、SAF等核心专利技术,构建了覆盖入门级、工业级、生产级的全品类设备矩阵,以极致精度、超大尺寸、稳定可靠、材料多元的核心优势,成为航空航天、汽车、…...

LLM - 2026 AI 文本转可视化工具终极指南:PicDoc.ai vs Napkin.ai 及 EdrawMax、Whimsical 等 8 大神器深度对比
文章目录概述一、PicDoc.ai vs Napkin.ai:专业全能 vs 轻快协作二、其他 6 大同类工具推荐三、8 大工具终极对比一览表(关键指标)四、 建议概述 在 2026 年的 AI 生产力浪潮中,把枯燥文字一键变成专业流程图、思维导图、信息图、…...

从零到精通的Android Kotlin实战学习旅程:50个项目带你掌握移动开发核心技能
从零到精通的Android Kotlin实战学习旅程:50个项目带你掌握移动开发核心技能 【免费下载链接】50-android-kotlin-projects-in-100-days My everyday Android practice demos with Kotlin in 100 days. 项目地址: https://gitcode.com/gh_mirrors/50/50-android-k…...

PE结构 --->8.PE对齐的概念 文件对齐VS磁盘对齐
目录 PE结构中对齐概念详解 原理 磁盘文件对齐(File Alignment, 0x200): 内存对齐(Section Alignment, 0x1000): 关系与CPU页管理: 详细步骤:PE文件加载到内存的对齐过程 读取…...

告别重复编码:用autoclaw在快马平台一键生成数据模型类提升效率
最近在开发一个Web应用时,我又遇到了那个老问题:每次新建数据表后,都要手动编写对应的模型类代码。这种重复劳动不仅耗时,还容易因为手误导致字段类型不匹配等问题。直到发现了InsCode(快马)平台的autoclaw功能,我的开…...

手把手教你用PyTorch复现Qwen2.5的GQA:从MHA到GQA的代码演进与性能对比
从零实现Qwen2.5的GQA机制:PyTorch实战与性能深度剖析 当我们在讨论现代大语言模型的高效推理时,注意力机制的优化始终是核心议题。Qwen2.5采用的Grouped Query Attention(GQA)既不是对传统多头注意力(MHA)的简单改良,也不是多查询注意力(MQA…...

@Value赋值踩的坑
Spring Boot 配置文件中的科学计数法陷阱 ⚠️ 警惕:YAML 配置中的字符串被误解析为数字的问题 📋 问题场景 1. 配置文件示例 # 测试环境配置 ✅ xunfei:appid: 0e1d789dapisecret: NzE5ZmExxxxxxxTFkNmY1ZWJjZTA1apikey: d228r7t8xxxxxxxc0bebb17e377…...

深度解析:数据挖掘核心任务与实战应用场景
深度解析:数据挖掘核心任务与实战应用场景前言一、数据挖掘核心定义二、数据挖掘标准执行流程(CRISP-DM 流程图)流程节点说明:三、数据挖掘的主要任务(6大核心分类)1. 分类分析:预测已知类别2. …...