C++_03
1、构造函数
1.1 什么是构造函数
类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。
每次构造的是构造成员变量的初始化值,内存空间等。
构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用于为某些成员变量设置初始值。
#include <iostream>
#include <string>using namespace std; // 使用std命名空间class Car {
public:string brand; // 不需要使用std::stringint year;// 无参构造函数Car() {brand = "未知";year = 0;cout << "无参构造函数被调用" << endl; // 不需要使用std::cout和std::endl}void display() {cout << "Brand: " << brand << ", Year: " << year << endl;}
};int main() {Car myCar; // 创建Car对象myCar.display(); // 显示车辆信息return 0;
}1.2 带参数的构造函数
默认的构造函数没有任何参数,但如果需要,构造函数也可以带有参数。这样在创建对象时就会给对象赋初始值。
#include <iostream>
#include <string>using namespace std;class Car {
public:string brand;int year;// 带参数的构造函数,使用常规的赋值方式Car(string b, int y) {brand = b;year = y;}void display() {cout << "Brand: " << brand << ", Year: " << year << endl;}
};int main() {Car myCar("Toyota", 2020); // 使用带参数的构造函数创建Car对象myCar.display(); // 显示车辆信息return 0;
}1.3 使用初始化列表
在C++中,使用初始化列表来初始化类的字段是一种高效的初始化方式,尤其在构造函数中。初始化列表直接在对象的构造过程中初始化成员变量,而不是先创建成员变量后再赋值。这对于提高性能尤其重要,特别是在涉及到复杂对象或引用和常量成员的情况下。
初始化列表紧跟在构造函数参数列表后面,以冒号( : )开始,后跟一个或多个初始化表达式,每个表达式通常用逗号分隔。下面是使用初始化列表初始化字段的例子:
class MyClass {
private:int a;double b;std::string c;public:// 使用初始化列表来初始化字段MyClass(int x, double y, const std::string& z) : a(x), b(y), c(z) {// 构造函数体}
};在这个例子中, MyClass 有三个成员变量: a ( int 类型)、 b ( double 类型)和 c
(1) 效率 :对于非基本类型的对象,使用初始化列表比在构造函数体内赋值更高效,因为它避免了先默 认构造然后再赋值的额外开销;
使用初始化列表是C++中推荐的初始化类成员变量的方式,因为它提供了更好的性能和灵活性。
1.4 拷贝构造函数
1.4.1 基本概念及发生条件
//其中, other 是对同类型对象的引用,通常是常量引用。
class MyClass {
public:MyClass(const MyClass& other);
};#include <iostream>
#include <string>using namespace std;class Car {
public:string brand;int year;// 常规构造函数Car(string b, int y) : brand(b), year(y) {}// 拷贝构造函数Car(const Car& other) {brand = other.brand;year = other.year;cout << "拷贝构造函数被调用" << endl;}void display() {cout << "Brand: " << brand << ", Year: " << year << endl;}
};int main() {Car car1("Toyota", 2020); // 使用常规构造函数Car car2 = car1; // 使用拷贝构造函数car1.display();car2.display();return 0;
}1.4.2 浅拷贝
浅拷贝只复制对象的成员变量的值。如果成员变量是指针,则复制指针的值(即内存地址),而不是指针所指向的实际数据。这会导致多个对象共享相同的内存地址。
#include <iostream>using namespace std;class Shallow {
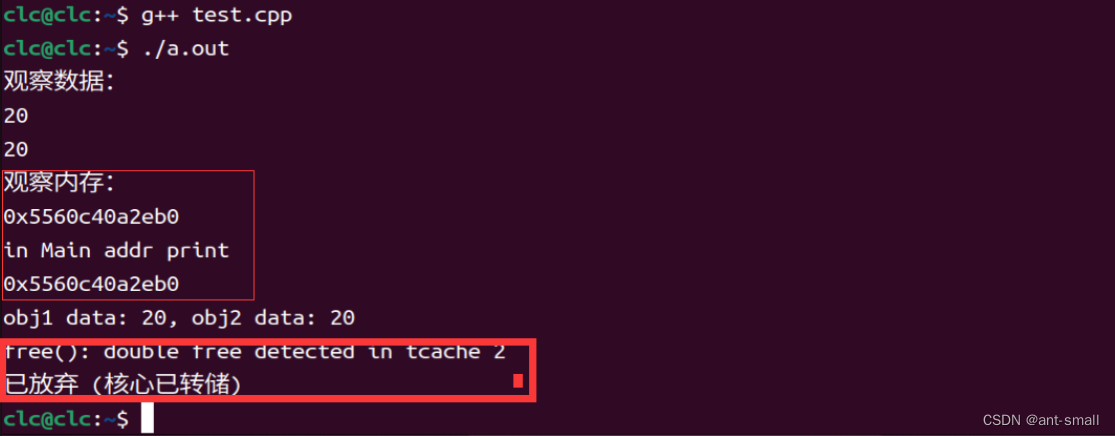
public:int* data;Shallow(int d) {//(d):这是初始化表达式。在这里,分配的 int 类型内存被初始化为 d 的值。如果 d 的值是20,那么分配的内存将被初始化为 20。data = new int(d); // 动态分配内存cout << "观察数据:" << endl;cout << d << endl;cout << *data << endl;cout << "观察内存在构造函数中:" << endl;cout << data << endl;}// 默认的拷贝构造函数是浅拷贝~Shallow() {delete data; // 释放内存}
};int main() {Shallow obj1(20);Shallow obj2 = obj1; // 浅拷贝cout << "观察内存在main函数obj2的data地址:" << endl;cout << obj2.data << endl;cout << "obj1 data: " << *obj1.data << ", obj2 data: " << *obj2.data << endl;return 0;
}在这个例子中, obj2 是通过浅拷贝 obj1 创建的。这意味着 obj1.data 和 obj2.data 指向相同的内存地址。当 obj1 和 obj2 被销毁时,同一内存地址会被尝试释放两次,导致潜在的运行时错误。 在Linux中我们获得如下运行结果:
1.4.3 深拷贝
深拷贝复制对象的成员变量的值以及指针所指向的实际数据。这意味着创建新的独立副本,避免了共享内存地址的问题。
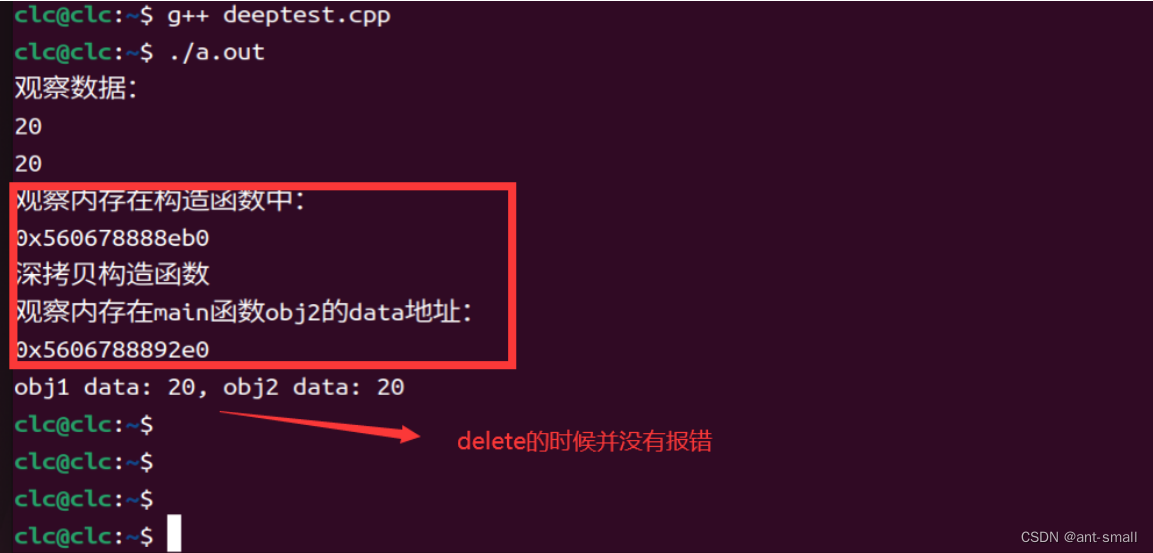
#include <iostream>using namespace std;class Deep {
public:int* data;Deep(int d) {data = new int(d); // 动态分配内存cout << "观察数据:" << endl;cout << d << endl;cout << *data << endl;cout << "观察内存在构造函数中:" << endl;cout << data << endl;}// 显式定义深拷贝的拷贝构造函数Deep(const Deep& source) {data = new int(*source.data); // 复制数据,而不是地址cout << "深拷贝构造函数\n";}~Deep() {delete data; // 释放内存}
};int main() {Deep obj1(20);Deep obj2 = obj1; // 深拷贝cout << "观察内存在main函数obj2的data地址:" << endl;cout << obj2.data << endl;cout << "obj1 data: " << *obj1.data << ", obj2 data: " << *obj2.data << endl;return 0;
}在这个例子中, obj2 是通过深拷贝 obj1 创建的。这意味着 obj1.data 和 obj2.data 指向不同的内存地址。每个对象有自己的内存副本,因此不会相互影响,避免了潜在的运行时错误。
1.4.4 规则三则
在C++中,规则三则(Rule of Three)是一个面向对象编程原则,它涉及到类的拷贝控制。规则三则指出,如果你需要显式地定义或重载类的任何一个拷贝控制操作(拷贝构造函数、拷贝赋值运算符、析构函数),那么你几乎肯定需要显式地定义或重载所有三个。这是因为这三个功能通常都是用于管理动态分配的资源,比如在堆上分配的内存。
#include <iostream>
#include <cstring>class MyClass {
private:char* buffer;public:// 构造函数MyClass(const char* str) {if (str) {buffer = new char[strlen(str) + 1];strcpy(buffer, str);} else {buffer = nullptr;}}// 析构函数~MyClass() {delete[] buffer;}// 拷贝构造函数MyClass(const MyClass& other) {if (other.buffer) {buffer = new char[strlen(other.buffer) + 1];strcpy(buffer, other.buffer);} else {buffer = nullptr;}}// 拷贝赋值运算符MyClass& operator=(const MyClass& other) {if (this != &other) {delete[] buffer; // 首先删除当前对象的资源if (other.buffer) {buffer = new char[strlen(other.buffer) + 1];strcpy(buffer, other.buffer);} else {buffer = nullptr;}}return *this;}
};int main() {MyClass obj1("Hello");MyClass obj2 = obj1; // 调用拷贝构造函数MyClass obj3("World");obj3 = obj1; // 调用拷贝赋值运算符return 0;
}在这个例子中,构造函数为成员变量 buffer 分配内存,并复制给定的字符串;析构函数释放 buffer 所占用的内存,以避免内存泄露;拷贝构造函数创建一个新对象作为另一个现有对象的副本,并为其分配新的内存,以避免多个对象共享同一内存;拷贝赋值运算符更新对象时,首先释放原有资源,然后根据新对象的状态分配新资源。
这个类遵循规则三则,确保了动态分配资源的正确管理,避免了内存泄露和浅拷贝问题。
1.4.5 避免不必要的拷贝
避免不必要的拷贝是 C++ 程序设计中的一个重要原则,尤其是在处理大型对象或资源密集型对象时。使用引用(包括常量引用)和移动语义(C++11 引入)是实现这一目标的两种常见方法。
1.4.5.1 使用引用传递对象
通过使用引用(尤其是常量引用)来传递对象,可以避免在函数调用时创建对象的副本。
#include <iostream>
#include <vector>using namespace std;class LargeObject {// 假设这是一个占用大量内存的大型对象
};void processLargeObject(const LargeObject& obj) {// 处理对象,但不修改它cout << "Processing object..." << endl;
}int main() {LargeObject myLargeObject;processLargeObject(myLargeObject); // 通过引用传递,避免拷贝return 0;
}在这个例子中, processLargeObject 函数接受一个对 LargeObject 类型的常量引用,避免了在函数调用时复制整个 LargeObject 。
1.4.5.2 使用移动语义
C++11 引入了移动语义,允许资源(如动态分配的内存)的所有权从一个对象转移到另一个对象,这避免了不必要的拷贝。
#include <iostream>
#include <utility> // 对于 std::moveusing namespace std;class MovableObject {
public:MovableObject() {// 构造函数}MovableObject(const MovableObject& other) {// 拷贝构造函数(可能很昂贵)}MovableObject(MovableObject&& other) noexcept {// 移动构造函数(轻量级)// 转移资源的所有权}MovableObject& operator=(MovableObject&& other) noexcept {// 移动赋值运算符// 转移资源的所有权return *this;}
};MovableObject createObject() {MovableObject obj;return obj; // 返回时使用移动语义,而非拷贝
}int main() {MovableObject obj = createObject(); // 使用移动构造函数return 0;
}在这个例子中, MovableObject 类有一个移动构造函数和一个移动赋值运算符,它们允许对象的资源(如动态分配的内存)在赋值或返回时被“移动”而非复制。这减少了对资源的不必要拷贝,提高了效率。通过这些方法,可以在 C++ 程序中有效地减少不必要的对象拷贝,尤其是对于大型或资源密集型的对象。
1.4.6 拷贝构造函数的隐式调用
在C++ 中,拷贝构造函数可能会在几种不明显的情况下被隐式调用。这种隐式调用通常发生在对象需要被复制时,但代码中并没有明显的赋值或构造函数调用。了解这些情况对于高效和正确地管理资源非常重要。
1.4.6.1 作为函数参数传递(按值传递)
当对象作为函数参数按值传递时,会调用拷贝构造函数来创建参数的本地副本。
#include <iostream>using namespace std;class MyClass {
public:MyClass() {}MyClass(const MyClass &) {cout << "拷贝构造函数被隐式调用" << endl;}
};void function(MyClass obj) {// 对 obj 的操作
}int main() {MyClass myObject;function(myObject); // 调用 function 时,拷贝构造函数被隐式调用return 0;
}1.4.6.2 从函数返回对象(按值返回)
当函数返回一个对象时,拷贝构造函数会被用于创建返回值的副本。
MyClass function() {MyClass tempObject;return tempObject; // 返回时,拷贝构造函数被隐式调用
}int main() {MyClass myObject = function(); // 接收返回值时可能还会有一次拷贝(或移动)return 0;
}1.4.6.3 初始化另一个对象
当用一个对象初始化另一个同类型的新对象时,会使用拷贝构造函数。
int main() {MyClass obj1;MyClass obj2 = obj1; // 初始化时,拷贝构造函数被隐式调用return 0;
}在所有这些情况下,如果类包含资源管理(例如,动态内存分配),那么正确地实现拷贝构造函数是非常重要的,以确保资源的正确复制和管理,防止潜在的内存泄漏或其他问题。此外,随着 C++11 的引入,移动语义提供了对资源的高效管理方式,可以减少这些场景中的资源复制。
1.4.7 禁用拷贝构造函数
在C++ 中,禁用拷贝构造函数是一种常用的做法,尤其是在设计那些不应该被复制的类时。这可以通过将拷贝构造函数声明为 private 或使用 C++11 引入的 delete 关键字来实现。这样做的目的是防止类的对象被拷贝,从而避免可能导致的问题,如资源重复释放、无意义的资源复制等。
1.4.7.1 使用 delete 关键字
在 C++11 及更高版本中,可以使用 delete 关键字明确指定不允许拷贝构造,这种方法清晰明了,它向编译器和其他程序员直接表明该类的对象不能被拷贝。
class NonCopyable {
public:NonCopyable() = default; // 使用默认构造函数// 禁用拷贝构造函数NonCopyable(const NonCopyable&) = delete;// 禁用拷贝赋值运算符NonCopyable& operator=(const NonCopyable&) = delete;
};int main() {NonCopyable obj1;// NonCopyable obj2 = obj1; // 编译错误,拷贝构造函数被禁用return 0;
}1.4.7.2 使用 private 声明(C++98/03)
在C++11 之前,常见的做法是将拷贝构造函数和拷贝赋值运算符声明为 private ,并且不提供实现:
class NonCopyable {
private:// 将拷贝构造函数和拷贝赋值运算符设为私有NonCopyable(const NonCopyable&);NonCopyable& operator=(const NonCopyable&);public:NonCopyable() {}
};int main() {NonCopyable obj1;// NonCopyable obj2 = obj1; // 编译错误,因为无法访问私有的拷贝构造函数return 0;
}在这个例子中,任何尝试拷贝 NonCopyable 类型对象的操作都会导致编译错误,因为拷贝构造函数和拷贝赋值运算符是私有的,外部代码无法访问它们。
通过这些方法,可以确保类的对象不会被意外地拷贝,从而避免可能出现的资源管理相关的错误。
1.4.8 小结
在C++ 中拷贝构造函数需要注意的要点:
| 要点 | 描述 |
| 定义和作用 | 拷贝构造函数在创建对象作为另一个现有对象副本时调用, 通常有一个对同 类型对象的常量引用参数。 |
| 语法 | 典型声明为 ClassName(const ClassName &other) 。 |
| 深拷贝与浅拷贝 | 浅拷贝复制值,深拷贝创建资源的独立副本。对于包含指针的类,深拷贝通常必要。 |
| 规则三则 (Rule of Three) | 如果实现了拷贝构造函数、拷贝赋值运算符或析构函数中的任何一个,通常应该实现所有三个。 |
| 避免不必要的拷贝 | 对于大型对象,使用移动语义避免不必要的拷贝,并在传递对象时使用引用或指针。 |
| 拷贝构造函数的隐 式调用 | 不仅在显式复制时调用,也可能在将对象作为函数参数传递、从函数返回对象时隐式调用。 |
| 禁用拷贝构造函数 | 对于某些类,可以通过将拷贝构造函数声明为私有或使用 delete 关键字 禁用拷贝。 |
1.5 this 关键字
在C++ 中, this 关键字是一个指向调用对象的指针。它在成员函数内部使用,用于引用调用该函数的对象。使用 this 可以明确指出成员函数正在操作的是哪个对象的数据成员。下面是一个使用 Car 类来展示 this 关键字用法的示例:
#include <iostream>
#include <string>using namespace std;class Car {
private:string brand;int year;public:Car(string brand, int year) {this->brand = brand;this->year = year;// cout << "构造函数中:" << endl;// cout << this << endl;}void display() const {cout << "Brand: " << this->brand << ", Year: " << this->year << endl;// 也可以不使用 this->,直接写 brand 和 year}Car& setYear(int year) {this->year = year; // 更新年份return *this; // 返回调用对象的引用}
};int main()
{Car car("宝马",2024);car.display();// 链式调用car.setYear(2023).display();// cout << "main函数中:" << endl;// cout << &car << endl;// Car car2("宝马",2024);// cout << "main函数中:" << endl;// cout << &car2 << endl;return 0;
}在这个例子中, Car 类的构造函数使用 this 指针来区分成员变量和构造函数参数。同样, setYear成员函数使用 this 指针来返回调用该函数的对象的引用,这允许链式调用,如myCar.setYear(2021).display(); 。在 main 函数中创建了 Car 类型的对象,并展示了如何使用这些成员函数。
1.6 new/delete 关键字
在C++中, new 关键字用于动态分配内存。它是C++中处理动态内存分配的主要工具之一,允许在程序运行时根据需要分配内存。
基本用法:
(1)分配单个对象:使用 new 可以在堆上动态分配一个对象。例如, new int 会分配一个 int 类型的空间,并返回一个指向该空间的指针。
int* ptr = new int; //C语言中,int *p = (int *)malloc(sizeof(int));(2)分配对象数组: new 也可以用来分配一个对象数组。例如, new int[10] 会分配一个包含10个整数的 数组。
int* arr = new int[10]; //C语言中,int *arr = (int *)malloc(sizeof(int)*10);(3)初始化:可以在 new 表达式中使用初始化。对于单个对象,可以使用构造函数的参数。
MyClass* obj = new MyClass(arg1, arg2);在使用 new 分配的内存必须显式地通过 delete (对于单个对象)或 delete[] (对于数组)来释放,以避免内存泄露:
(1)释放单个对象:
delete ptr; // 释放 ptr 指向的对象(2)释放数组:
delete[] arr; // 释放 arr 指向的数组注:(1)异常安全:如果 new 分配内存失败,它会抛出 std::bad_alloc 异常(除非使用了 nothrow 版本);
(2)内存泄露:忘记释放使用 new 分配的内存会导致内存泄露;
(3)匹配使用 delete 和 delete[] :为避免未定义行为,使用 new 分配的单个对象应该使用delete 释放,使用 new[] 分配的数组应该使用 delete[] 释放。
class MyClass {
public:MyClass() {std::cout << "Object created" << std::endl;}
};int main() {// 分配单个对象MyClass* myObject = new MyClass();// 分配对象数组int* myArray = new int[5]{1, 2, 3, 4, 5};// 使用对象和数组...// 释放内存delete myObject;delete[] myArray;return 0;
}在这个例子中, new 被用来分配一个 MyClass 类型的对象和一个整数数组,然后使用 delete 和delete[] 来释放内存。每个 new 都对应一个 delete ,保证了动态分配的内存被适当管理。
2、析构函数
析构函数是C++中的一个特殊的成员函数,它在对象生命周期结束时被自动调用,用于执行对象销毁前的清理工作。析构函数特别重要,尤其是在涉及动态分配的资源(如内存、文件句柄、网络连接等)的情况下。
基本特性:
(1)名称:析构函数的名称由波浪号( ~ )后跟类名构成,如 ~MyClass() 。
(2)无返回值和参数:析构函数不接受任何参数,也不返回任何值。
(3)自动调用:当对象的生命周期结束时(例如,一个局部对象的作用域结束,或者使用 delete 删除一个动态分配的对象),析构函数会被自动调用。
(4)不可重载:每个类只能有一个析构函数。
(5)继承和多态:如果一个类是多态基类,其析构函数应该是虚的。
#include <iostream>using namespace std;class MyClass{
private:int* datas;public:MyClass(int size){datas = new int[size];}~MyClass(){cout << "析构函数被调用" << endl;delete[] datas;}
};int main()
{MyClass m1(5);MyClass *m2 = new MyClass(10);delete m2;return 0;
}在这个示例中, MyClass 的构造函数分配了一块内存,而析构函数释放了这块内存。当 obj 的生命周期结束时(即离开了它的作用域), MyClass 的析构函数被自动调用,负责清理资源,防止内存泄露。
析构函数在管理资源方面非常重要。没有正确实现析构函数,可能导致资源泄露或其他问题。在基于RAII(资源获取即初始化)原则的C++编程实践中,确保资源在对象析构时被适当释放是非常关键的。当使用智能指针和其他自动资源管理技术时,可以减少显式编写析构函数的需要,但了解析构函数的工作原理仍然很重要。
关于析构函数的要点:
| 要点 | 描述 |
| 定义和作 用 | 析构函数在对象生命周期结束时自动调用,用于清理对象可能持有的资源。 |
| 语法 | 析构函数名称由波浪线 (~) 后跟类名构成,例如 MyClass 的析构函数为~MyClass() 。 |
| 资源管理 | 用于释放对象在生命周期中分配的资源,如动态内存、文件句柄、网络连接等。 |
| 自动调用机制 | 当对象离开其作用域或通过 delete 删除时,将自动调用其析构函数。 |
| 防止资源 泄露 | 正确实现析构函数对防止资源泄露至关重要,特别是在涉及动态资源分配的情况。 |
| 虚析构函数 | 如果类作为基类设计,应有一个虚析构函数,以确保正确调用派生类的析构函数。 |
| 析构函数与异常 | 析构函数不应抛出异常,如果可能抛出,应在函数内捕获。 |
| 删除的析构函数 | 可以通过将析构函数声明为删除( ~MyClass() = delete; )来禁止删除某类对象。 |
| 与构造函 数的关系 | 每个类只能有一个析构函数,不可重载,与构造函数相比。 |
| 规则三则/ 五则 | 如果类需要自定义析构函数、拷贝构造函数或拷贝赋值运算符,可能也需要自定义另外两个(规则三则)。在 C++11 后还包括移动构造函数和移动赋值运算符(规则五则)。 |
3、静态成员
3.1 静态成员的定义
静态成员在C++类中是一个重要的概念,它包括静态成员变量和静态成员函数。静态成员的特点和存在的意义如下:
静态成员变量:
(1)定义:静态成员变量是类的所有对象共享的变量。与普通成员变量相比,无论创建了多少个类的实例,静态成员变量只有一份拷贝。
(2)初始化:静态成员变量需要在类外进行初始化,通常在类的实现文件中。
(3)访问:静态成员变量可以通过类名直接访问,不需要创建类的对象。也可以通过类的对象访问。
(4)用途:常用于存储类级别的信息(例如,计数类的实例数量)或全局数据需要被类的所有实例共享。
静态成员函数:
(1)定义:静态成员函数是可以不依赖于类的实例而被调用的函数。它不能访问类的非静态成员变量和非静态成员函数。
(2)访问:类似于静态成员变量,静态成员函数可以通过类名直接调用,也可以通过类的实例调用。
(3)用途:常用于实现与具体对象无关的功能,或访问静态成员变量。
class MyClass {
public:static int staticValue; // 静态成员变量MyClass() {// 每创建一个对象,静态变量增加1staticValue++;}static int getStaticValue() {// 静态成员函数return staticValue;}
};// 类外初始化静态成员变量
int MyClass::staticValue = 0;int main() {MyClass obj1, obj2;std::cout << MyClass::getStaticValue(); // 输出2
}静态成员的优点:
(1)共享数据:允许对象之间共享数据,而不需要每个对象都有一份拷贝。
(2)节省内存:对于频繁使用的类,使用静态成员可以节省内存。
(3)独立于对象的功能:静态成员函数提供了一种在不创建对象的情况下执行操作的方法,这对于实现工具函数或管理类级别状态很有用。
3.2 静态成员变量的作用
静态成员变量在C++中的一个典型应用是用于跟踪类的实例数量。这个案例体现了静态成员变量的特性:它们在类的所有实例之间共享,因此适合于存储所有实例共有的信息。
#include <iostream>using namespace std;class Myclass{
private:static int staticNumofInstance;public:Myclass(){staticNumofInstance++;}~Myclass(){staticNumofInstance--;}static int getNunofInstance(){return staticNumofInstance;}
};int Myclass::staticNumofInstance = 0;int main()
{Myclass m1;cout << Myclass::getNunofInstance() << endl;Myclass m2;cout << m2.getNunofInstance() << endl;{Myclass m3;cout << Myclass::getNunofInstance() << endl;Myclass m4;cout << Myclass::getNunofInstance() << endl;}cout << Myclass::getNunofInstance() << endl;Myclass *m5 = new Myclass;cout << Myclass::getNunofInstance() << endl;delete m5;cout << Myclass::getNunofInstance() << endl;return 0;
}在这个例子中: Myclass 类有一个静态成员变量 staticNumofInstance ,用来跟踪该类的实例数量。每当创建 Myclass 的新实例时,构造函数会增加 staticNumofInstance 。每当一个 Myclass 实例被销毁时,析构函数会减少 staticNumofInstance 。通过静态成员函数 getNunofInstance 可以随时获取当前的实例数量。静态成员变量 staticNumofInstance 在类外初始化为0。
这个案例展示了静态成员变量如何在类的所有实例之间共享,并为所有实例提供了一个共同的状态(在这个例子中是实例的数量)。这种技术在需要跟踪对象数量或实现某种形式的资源管理时特别有用。
相关文章:
C++_03
1、构造函数 1.1 什么是构造函数 类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。 每次构造的是构造成员变量的初始化值,内存空间等。 构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不…...
强化学习中的Double DQN、Dueling DQN和PER DQN算法详解及实战
1. 深度Q网络(DQN)回顾 DQN通过神经网络近似状态-动作值函数(Q函数),在训练过程中使用经验回放(Experience Replay)和固定目标网络(Fixed Target Network)来稳定训练过程…...

前端八股文 说一说样式优先级的规则是什么?
标准的回答 CSS样式的优先级应该分成四大类 第一类 !important: 😄无论引入方式是什么,选择器是什么,它的优先级都是最高的。 第二类 引入方式: 😄行内样式的优先级要高于嵌入和外链,嵌入和外链…...

洞察国内 AI 绘画行业的璀璨前景
在科技的浪潮中,AI 绘画如同一颗璀璨的新星,正在国内的艺术与技术领域绽放出耀眼的光芒。 近年来,国内 AI 绘画行业发展迅猛,展现出巨大的潜力。随着人工智能技术的不断突破,AI 绘画算法日益精进,能够生成…...

socket编程
文章目录 套接字网路字节序列TCP和UDP套接字 本文章主要介绍Linux下套接字的相关接口,和一些基础知识。 套接字 所有网络通信的行为本质都是进程间进行通信,网络通信也是进程间通信,只不过是不同主机上的两个进程之间的通信。网络通信对于双…...
)
python自动移除excel文件密码(升级v2版本)
欢迎查看第一版 https://blog.csdn.net/weixin_45631815/article/details/140013476?spm1001.2014.3001.5502 一功能改进 此版本主要改进功能有以下: 直接可以调用函数实现可以尝试多个密码没有加密的文件进行保存,可以按实际业务进行改进.思路来源:java 面向对象设计模式.…...

深入MOJO编程语言的单元测试世界
引言 在软件开发的历程中,单元测试扮演着至关重要的角色。单元测试不仅帮助开发者确保代码的每个部分都按预期工作,而且也是代码质量和维护性的关键保障。本文将引导读者了解如何在MOJO这一假想编程语言中编写单元测试,尽管MOJO并非真实存在…...

Canvas:掌握颜色线条与图像文字设置
想象一下,用几行代码就能创造出如此逼真的图像和动画,仿佛将艺术与科技完美融合,前端开发的Canvas技术正是这个数字化时代中最具魔力的一环,它不仅仅是网页的一部分,更是一个无限创意的画布,一个让你的想象…...

打包导入pyzbar的脚本时的注意事项
目录 前言问题问题的出现解决 总结 本文由Jzwalliser原创,发布在CSDN平台上,遵循CC 4.0 BY-SA协议。 因此,若需转载/引用本文,请注明作者并附原文链接,且禁止删除/修改本段文字。 违者必究,谢谢配合。 个人…...
02-android studio实现下拉列表+单选框+年月日功能
一、下拉列表功能 1.效果图 2.实现过程 1)添加组件 <LinearLayoutandroid:layout_width"match_parent"android:layout_height"wrap_content"android:layout_marginLeft"20dp"android:layout_marginRight"20dp"android…...
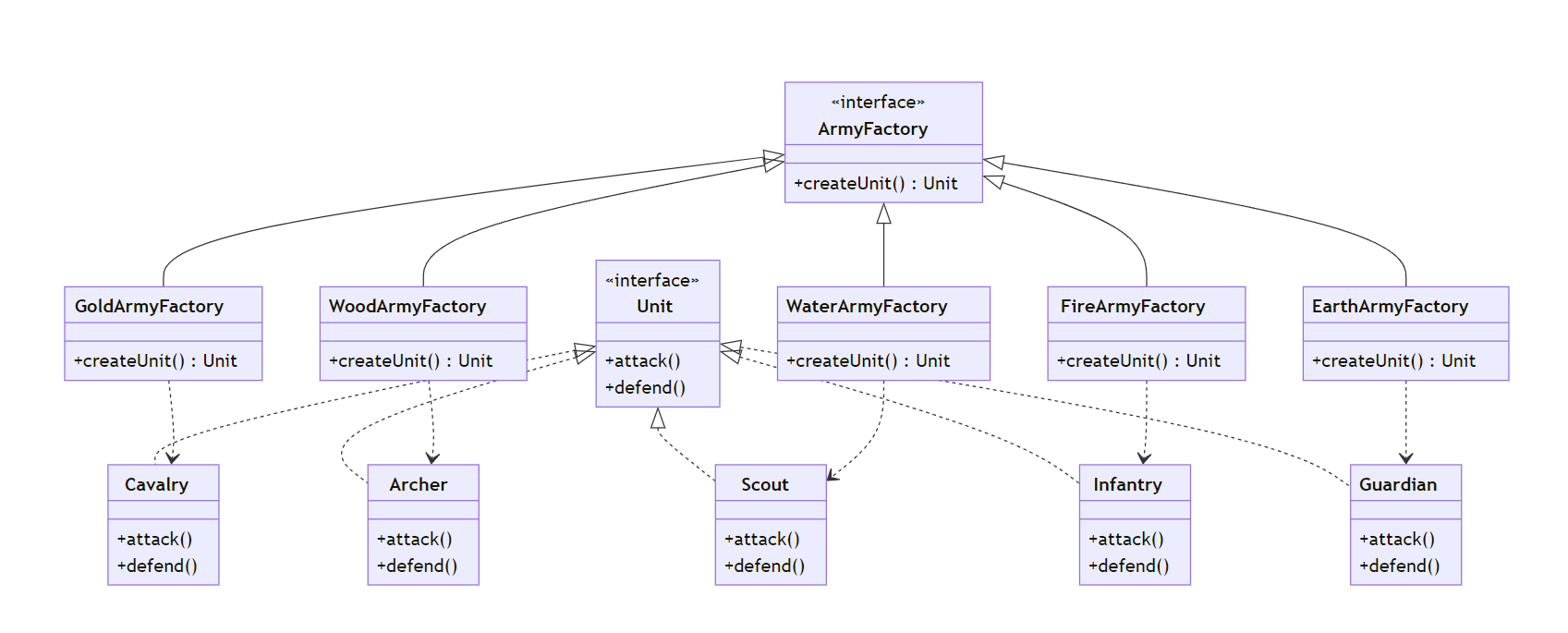
曹操的五色棋布阵 - 工厂方法模式
定场诗 “兵无常势,水无常形,能因敌变化而取胜者,谓之神。” 在三国的战场上,兵法如棋,布阵如画。曹操的五色棋布阵,不正是今日软件设计中工厂方法模式的绝妙写照吗?让我们从这个神奇的布阵之…...

谷粒商城学习笔记-逆向工程错误记录
文章目录 1,Since Maven 3.8.1 http repositories are blocked.1.1 在maven的settings.xml文件中,新增如下配置:1.2,执行clean命令刷新maven配置 2,internal java compiler error3,启动逆向工程报错&#x…...

FastAPI+SQLAlchemy数据库连接
FastAPISQLAlchemy数据库连接 目录 FastAPISQLAlchemy数据库连接配置数据库连接创建表模型创建alembic迁移文件安装初始化编辑env.py编辑alembic.ini迁移数据库 视图函数查询 配置数据库连接 # db.py from sqlalchemy import create_engine from sqlalchemy.orm import sessio…...

Android中的适配器,你知道是做什么的吗?
😄作者简介: 小曾同学.com,一个致力于测试开发的博主⛽️,主要职责:测试开发、CI/CD,日常还会涉及Android开发工作。 如果文章知识点有错误的地方,还请大家指正,让我们一起学习,一起…...

GitHub详解:代码托管与协作开发平台
文章目录 一、GitHub简介二、GitHub的核心功能2.1 仓库(Repository)2.2 版本控制与分支(Branch)2.3 Pull Request2.4 Issues与Projects2.5 GitHub Actions 三、GitHub的使用方法3.1 注册与登录3.2 创建和管理仓库3.3 使用Git进行代…...

【植物大战僵尸杂交版】获取+存档插件
文章目录 一、还记得《植物大战僵尸》吗?二、在哪下载,怎么安装?三、杂交版如何进行存档功能概述 一、还记得《植物大战僵尸》吗? 最近,一款曾经在15年前风靡一时的经典游戏《植物大战僵尸》似乎迎来了它的"文艺复…...

BP神经网络与反向传播算法在深度学习中的应用
BP神经网络与反向传播算法在深度学习中的应用 在神经网络的发展历史中,BP神经网络(Backpropagation Neural Network)占有重要地位。BP神经网络通过反向传播算法进行训练,这种算法在神经网络中引入了一种高效的学习方式。随着深度…...

【数据结构与算法】插入排序
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法》 期待您的关注 ...

MySQL如何实现数据排序
根据explain的执行计划来看,MySQL可以分为索引排序和filesort 索引排序 如果查询中的order by字句包含的字段已经在索引中,且索引的排列顺序和order by子句一致,则可直接利用索引进行排序,由于索引有序,所以排序效率…...

给我的 IM 系统加上监控两件套:【Prometheus + Grafana】
监控是一个系统必不可少的组成部分,实时,准确的监控,将会大大有助于我们排查问题。而当今微服务系统的话有一个监控组合很火那就是 Prometheus Grafana,嘿你别说 这俩兄弟配合的相当完美,Prometheus负责数据采集&…...
,包含: 1.MPPT模块)
光储并网直流微电网仿真模型(matlab/simulink,2018),包含: 1.MPPT模块
光储并网直流微电网仿真模型(matlab/simulink,2018),包含: 1.MPPT模块,实现光伏输入最大功率跟踪; 2.储能电池模块; 3.超级电容模块; 控制策略简介: 糸统使用…...

Elsevier投稿状态监控插件:3分钟告别手动刷新的终极解决方案
Elsevier投稿状态监控插件:3分钟告别手动刷新的终极解决方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 你是否每天都要反复登录Elsevier投稿系统,只为查看那迟迟不来的审稿状态…...

从零开始掌握小红书数据采集:xhs库的5大实战应用场景
从零开始掌握小红书数据采集:xhs库的5大实战应用场景 【免费下载链接】xhs 基于小红书 Web 端进行的请求封装。https://reajason.github.io/xhs/ 项目地址: https://gitcode.com/gh_mirrors/xh/xhs 你是否曾经想过如何批量获取小红书上的热门内容?…...

探索p5.js Web Editor:重构创意编程体验的开发平台
探索p5.js Web Editor:重构创意编程体验的开发平台 【免费下载链接】p5.js-web-editor The p5.js Editor is a website for creating p5.js sketches, with a focus on making coding accessible and inclusive for artists, designers, educators, beginners, and …...
)
GESP2025年3月认证C++三级( 第三部分编程题(2、词频统计)
一、🧙♂️ 故事背景:单词王国选举大会 在“单词王国”里 🏰 有很多单词来参加“最受欢迎单词”比赛! 👉 比如: Apple banana apple Orange banana apple二、🎯 任务 👉 找出&…...

Spring AI 助力 Java 开发者构建全功能 AI 智能体
【导语:随着人工智能的迅速发展,Java 开发者在将 AI 能力集成到基于 Spring 的应用程序方面选择有限。Spring AI 的出现改变了这一局面,本文详细介绍了如何使用 Spring AI 构建基于 Java 的全功能 AI 智能体。】Spring AI 打破 Java 集成 AI …...

5个实用技巧:掌握FastBle日志系统的完整调试指南
5个实用技巧:掌握FastBle日志系统的完整调试指南 【免费下载链接】FastBle Android Bluetooth Low Energy (BLE) Fast Development Framework. It uses simple ways to filter, scan, connect, read ,write, notify, readRssi, setMTU, and multiConnection. 项目…...

Muon最佳实践:10个提升开发效率的实用技巧
Muon最佳实践:10个提升开发效率的实用技巧 【免费下载链接】muon GPU based Electron on a diet 项目地址: https://gitcode.com/gh_mirrors/mu/muon Muon作为一款基于GPU的轻量级Electron替代方案,采用Golang开发并使用Ultralight引擎࿰…...

利用快马平台快速构建类FinalShell服务器监控Web原型
最近在折腾服务器监控工具,发现FinalShell确实好用,但有时候团队协作或者临时演示时,还是需要一个轻量级的Web版监控面板。正好发现了InsCode(快马)平台,用它快速搭建了一个原型,分享下实现思路。 整体架构设计 这个监…...

OpenClaw二次开发:修改Qwen3-4B的prompt模板提升效果
OpenClaw二次开发:修改Qwen3-4B的prompt模板提升效果 1. 为什么要修改prompt模板? 第一次使用OpenClaw对接Qwen3-4B模型时,我发现默认的prompt模板在处理复杂任务时经常出现"任务拆解不完整"或"工具调用顺序混乱"的问题…...