数据结构/作业/2024/7/7
搭建个场景:
将学生的信息,以顺序表的方式存储(堆区),并且实现封装函数︰1】顺序表的创建,
2】判满、
3】判空、
4】往顺序表里增加学生、5】遍历、
6】任意位置插入学生、7】任意位置删除学生、8】修改、
9】查找(按学生的学号查找)、10】去重、
11】销毁顺序表
main.c
#include "head.h"
int main(int argc,const char *argv[])
{//创建学生的顺序表seqlist_ptr p=create_list();//判断顺序表是否为满int p1=full_doubt(p);//判断顺序表是否为空int p2=empty_doubt(p);//顺序表中添加学生数据add(p,6666);add(p,1001);add(p,1002);add(p,1003);add(p,1004);//顺序表中输出学生数据 output(p);//在任意位置插入学生insert(p,3,1111); output(p);//删除任意位置的学生del(p,3);output(p);//更改学生IDchange_index(p,3,6666);output(p);//查找学生IDfind(p,6666);//去重del_same(p);output(p);//释放my_free(p);return 0;
}
fun.c
1 #include "head.h" 2 3 4 //1.创建学生的顺序表 5 seqlist_ptr create_list() 6 { 7 //申请堆区的空间 8 seqlist_ptr p=(seqlist_ptr)malloc(sizeof(seqlist)); 9 if(NULL==p) 10 { 11 printf("顺序表创建失败\n"); 12 return NULL; 13 } 14 15 p->len=0;//将顺序表中的长度清零 16 //将数组的长度清零 17 memset(p->ID,0,sizeof(p->ID)); 18 printf("创建顺序表成功\n"); 19 return p; 20 } 21 22 23 //2.判断顺序表是否为满 24 int full_doubt(seqlist_ptr p) 25 { 26 if(NULL==p) 27 { 28 printf("顺序表不合法,无法判断"); 29 return -1; 30 } 31 else if(p->len==MAX) 32 { 33 printf("顺序表满\n"); 34 return 1; 35 } 36 37 return 0; 38 } 39 40 41 //3.判断顺序表是否为空 42 int empty_doubt(seqlist_ptr p) 43 { 44 if(NULL==p) 45 { 46 printf("顺序表不合法,无法判断"); 47 } 48 else if(p->len==0) 49 { 50 printf("顺序表为空\n"); 51 return 1; 52 } 53 return 0; 54 } 55 56 57 //4.顺序表数据的增加(添加学生的id号) 58 int add(seqlist_ptr p,datatype a) 59 { 60 if(NULL==p || full_doubt(p)) 61 { 62 printf("无法增加\n"); 63 return 0; 64 } 65 p->ID[p->len]=a; 66 p->len++; 67 return 1; 68 } 69 70 71 //5.顺序表中输出学生数据 72 int output(seqlist_ptr p) 73 { 74 if(NULL==p || empty_doubt(p)) 75 { 76 printf("无法输出i\n"); 77 return 0; 78 } 79 for(int i=0;i<p->len;i++) 80 { 81 printf("%d ",p->ID[i]); 82 } 83 printf("\n"); 84 return 1; 85 } 86 87 88 //6.在任意位置插入学生数据 89 int insert(seqlist_ptr p,int index,datatype e) 90 { 91 if(NULL==p || index>=MAX || index<=0 || empty_doubt(p)) 92 { 93 printf("插入失败\n"); 94 return -1; 95 } 96 //此时的index表示数组的下标 97 index-=1; 98 for(int i=0;i<p->len-index;i++) 99 { //p->len表示未赋值的那个元素
100 p->ID[p->len-i]=p->ID[p->len-1-i];
101 }
102 //赋值
103 p->ID[index]=e;
104 //长度+1
105 p->len++;
106 return 1;
107 }
108
109
110 //7.删除任意位置的学生
111 int del(seqlist_ptr p,int index)
112 {
113 if(NULL==p || index>MAX || index<=0 || empty_doubt(p))
114 {
115 printf("删除失败\n");
116 return -1;
117 }
118 //此时index表示数组的下标
119 index-=1;
120 for(int i=index;i<p->len;i++)
121 {
122 p->ID[index]=p->ID[index+1];
123 }
124 p->len--;
125 return 1;
126 }
127
128
129 //8.任意位置更改学生ID
130 int change_index(seqlist_ptr p,int index,datatype e)
131 {
132 if(NULL==p || index>MAX || index <=0 || empty_doubt(p))
133 {
134 printf("更改失败\n");
135 return -1;
136 }
137 index-=1;
138 p->ID[index]=e;
139 return 1;
140 }
141
142
143 //9.查找学生ID
144 int find(seqlist_ptr p,datatype e)
145 {
146 if(NULL==p || empty_doubt(p))
147 {
148 printf("查找失败\n");
149 return -1;
150 }
151 int flag=0;
152 for(int i=0;i<p->len;i++)
153 {
154 if(p->ID[i]==e)
155 {
156 flag=1;
157 printf("查找的学生是第%d位学生\n",i+1);
158 return i;
159 }
160
161 if(flag=0)
162 {
163 printf("未查找到学生ID\n");
164 return 0;
165 }
166 }
167 }
168
169
170 //10.去重
171 int del_same(seqlist_ptr p)
172 {
173 if(NULL==p || empty_doubt(p))
174 {
175 printf("去重失败\n");
176 return -1;
177 }
178 for(int i=0;i<p->len;i++)
179 {
180 for(int j=i+1;j<p->len;j++)
181 {
182 if(p->ID[i]==p->ID[j])
183 {
184 del(p,j+1);
185 j--;
186 }
187 }
188 }
189 return 1;
190 }
191
192
193 //11 释放
194 int my_free(seqlist_ptr p)
195 {
196 if(NULL==p)
197 {
198 printf("释放失败\n");
199 return -1;
200 }
201 free(p);
202 printf("释放成功\n");
203 return 1;
204
205 }
~
head.h
#ifndef __HEAD_H__
#define __HEAD_H__
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//顺序标容器存储学生个数的最大值
#define MAX 30
//宏替换ID的数据类型
typedef int datatype;
//创建顺序表用于存储学生的信息
typedef struct sequence
{ datatype ID[MAX]; //存储学生的个数 int len;
}seqlist,*seqlist_ptr; //1.创建学生的顺序表
seqlist_ptr create_list();
//2.判断顺序表是否为满
int full_doubt(seqlist_ptr p);
//3.判断顺序表是否为空
int empty_doubt(seqlist_ptr p);
//4.顺序表数据的增加(添加学生的id号)
int add(seqlist_ptr p,datatype a);
//5.顺序表中输出学生数据
int output(seqlist_ptr p);
//6.在任意位置插入学生数据
int insert(seqlist_ptr p,int index,datatype e);
//7.删除任意位置的学生
int del(seqlist_ptr p,int index);
//8.任意位置更改学生ID
int change_index(seqlist_ptr p,int index,datatype e);
//9.查找学生ID
int find(seqlist_ptr p,datatype e);
//10.去重
int del_same(seqlist_ptr p);
//11 释放
int my_free(seqlist_ptr p);
#endif

相关文章:
数据结构/作业/2024/7/7
搭建个场景: 将学生的信息,以顺序表的方式存储(堆区),并且实现封装函数︰1】顺序表的创建, 2】判满、 3】判空、 4】往顺序表里增加学生、5】遍历、 6】任意位置插入学生、7】任意位置删除学生、8】修改、 9】查找(按学生的学号查…...

隔离级别-隔离级别中的锁协议、隔离级别类型、隔离级别的设置、隔离级别应用
一、引言 1、DBMS除了采用严格的两阶段封锁协议来保证并发事务的可串行化,实现事务的隔离性,也可允许用户选择一个可以保证应用程序正确执行并且能够使并发度最大的隔离性等级 2、通常用隔离级别来描述隔离性等级,以下将主要介绍ANSI 92标准…...

【数据结构与算法】希尔排序
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法》 期待您的关注 ...

【机器学习】(基础篇一) —— 什么是机器学习
什么是机器学习 本系列博客为你从机器学习的介绍开始,使用大量的代码实战和验证,最终帮助你完全掌握什么是机器学习 人工智能、机器学习和深度学习的关系 人工智能(Artificial Intelligence,AI):是一门研…...

VitePress安装部署
VitePress安装部署 VitePress安装步骤 安装 Node环境 官网下载:https://nodejs.org/zh-cn 傻瓜式安装到完成 npm环境 安装完Node环境之后,可以直接运行下面的命令安装npm npm install -g pnpm关于pnpm源: 有时候需要国内源,…...

Spring的事务传播机制和隔离级别
Spring 提供了强大的事务管理机制,通过 @Transactional 注解或程序化事务管理方式,开发者可以轻松地在应用中启用事务特性。事务传播机制和隔离级别是 Spring 事务管理中的两个重要方面,了解它们有助于更好地控制事务的行为,确保数据的一致性和完整性。 1. 事务传播机制(…...
华为路由器静态路由配置(eNSP模拟实验)
实验目标 如图下所示,让PC1ping通PC2 具体操作 配置PC设备ip 先配置PC1的ip、掩码、网关。PC2也做这样的配置 配置路由器ip 配置G0/0/0的ip信息 #进入系统 <Huawei>system-view #进入GigabitEthernet0/0/0接口 [Huawei]int G0/0/0 #设置接口的ip和掩码 […...

antd实现简易相册,zdppy+vue3+antd实现前后端分离相册
前端代码 <template><a-image:preview"{ visible: false }":width"200"src"http://localhost:8889/download/1.jpg"click"visible true"/><div style"display: none"><a-image-preview-group:previe…...

PIP换源的全面指南
##概述 在Python的世界里,pip是不可或缺的包管理工具,它帮助开发者安装和管理Python软件包。然而,由于网络条件或服务器位置等因素,直接使用默认的pip源有时会遇到下载速度慢或者连接不稳定的问题。这时,更换pip源到一…...

陶建辉当选 GDOS 全球数据库及开源峰会荣誉顾问
近日,第二十三届 GOPS 全球运维大会暨 XOps 技术创新峰会在北京正式召开。本次会议重点议题方向包括开源数据库落地思考、金融数据库自主可控、云原生时代下数据库、数据库智能运维、数据库安全与隐私、开源数据库与治理。大会深入探讨这些方向,促进了数…...
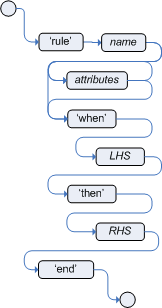
Drools开源业务规则引擎(二)- Drools规则语言(DRL)
文章目录 1.DRL文件的组成:2.package3.import4.function5.query6.declare7.global8.rule8.1.规则属性8.2.LHS8.2.1.语法格式8.2.2.运算符优先级8.2.3.特殊的运算符1.matches, not matches2.contains, not contains3.memberOf, not memberOf4.in, notin5.soundslike6…...

PTA甲级1005:Spell It Right
错误代码: #include<iostream> #include<vector> #include<unordered_map> using namespace std;int main() {unordered_map<int, string> map {{0, "zero"}, {1, "one"}, {2, "two"}, {3, "three&qu…...

Vue笔记11-Composition API的优势
Options API存在的问题 使用传统Options API中,新增或者修改一个需求,就需要分别在data,methods,computed里修改,而这些选项分布在代码的各个地方,中间还穿插着其他Optional API,如果代码量上来…...

rancher管理多个集群
一、rancher部署 单独部署到一台机器上,及独立于k8s集群之外: 删除所有yum源,重新建yum源: # 建centos7.9的yum源 # cat CentOS-Base.repo # CentOS-Base.repo # # The mirror system uses the connecting IP address of the …...

某大会的影响力正在扩大,吞噬了整个数据库世界!
1.规模空前 你是否曾被那句“上有天堂,下有苏杭”所打动,对杭州的湖光山色心驰神往?7月,正是夏意正浓的时节,也是游览杭州的最佳时期。这座古典与现代交融的城市将迎来了第13届PostgreSQL中国技术大会。作为全球数据库…...

PostgreSQL主从复制:打造高可用数据库架构的秘籍
PostgreSQL主从复制:打造高可用数据库架构的秘籍 在当今的数字化时代,数据的安全性和可靠性是企业最为关注的问题之一。PostgreSQL作为一种强大的开源关系型数据库管理系统,提供了多种高可用性解决方案,其中主从复制是最为常用的…...

Fast R-CNN(论文阅读)
论文名:Fast R-CNN 论文作者:Ross Girshick 期刊/会议名:ICCV 2015 发表时间:2015-9 论文地址:https://arxiv.org/pdf/1504.08083 源码:https://github.com/rbgirshick/fast-rcnn 摘要 这篇论文提出了一…...

视觉语言模型:融合视觉与语言的未来
1. 概述 视觉语言模型(Vision-Language Models, VLMs)是能够同时处理和理解视觉(图像)和语言(文本)两种模态信息的人工智能模型。这种模型结合了计算机视觉和自然语言处理的技术,使得它们能够在…...
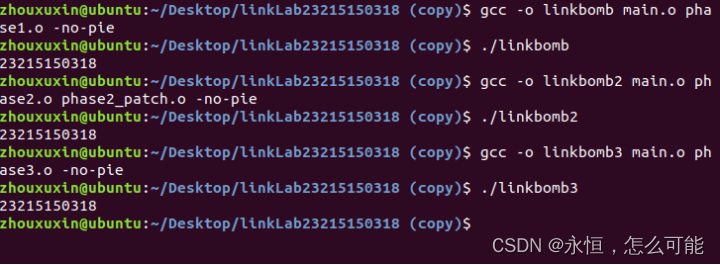
【CSAPP】-linklab实验
目录 实验目的与要求 实验原理与内容 实验步骤 实验设备与软件环境 实验过程与结果(可贴图) 实验总结 实验目的与要求 1.了解链接的基本概念和链接过程所要完成的任务。 2.理解ELF目标代码和目标代码文件的基本概念和基本构成 3.了解ELF可重定位目…...

UE C++ 多镜头设置缩放 平移
一.整体思路 首先需要在 想要控制的躯体Pawn上,生成不同相机对应的SpringArm组件。其次是在Controller上,拿到这个Pawn,并在其中设置输入响应,并定义响应事件。响应事件里有指向Pawn的指针,并把Pawn的缩放平移功能进行…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...