Fast R-CNN(论文阅读)
论文名:Fast R-CNN
论文作者:Ross Girshick
期刊/会议名:ICCV 2015
发表时间:2015-9
论文地址:https://arxiv.org/pdf/1504.08083
源码:https://github.com/rbgirshick/fast-rcnn摘要
这篇论文提出了一个快速的R-CNN网络,也就是Fast R-CNN用于目标检测任务。Fast R-CNN使用了深度卷积神经网络来高效地对候选区域进行分类。并且与之前的工作相比,Fast R-CNN既能提高训练和测试时的速度,又能增加检测的精度。在当时比较典型的目标检测算法就是R-CNN和SPPnet,所以接下来就举了R-CNN和SPPnet这两个例子,来对比说明Fast R-CNN速度有多快。比如与R-CNN相比,Fast R-CNN在训练时能够快9倍,在测试时快了213倍。与SPPnet相比,Fast R-CNN训练时快了3倍,测试时快了10倍。所以说Fast R-CNN在当时与其他的目标点这模型相比,速度又快,精度又高,在当时是一个比较优秀的算法。
1.引言
1.1.R-CNN and SPPnet
分别写了R-CNN和SPPnet的缺点。
比如在这里先是R-CNN有一些缺点,然后在下面这里又写了SPPnet也有一些缺点。因此作者提出了一种新的训练方法来解决R-CNN和SPPnet的这个缺点,这个新的方法也被称为Fast R-CNN。

先来看一下R-CNN具体的这三个缺点,其中前两条都是在算法训练时的缺点,第三条是算法测试时的缺点。我们之前在讲R-CNN论文的时候,有提到AlexNet的算法在训练时是分了不同的多个阶段的。首先是训练了一个CNN用来提取候选区域的特征。等这个cnn训练好后再提取整个数据集上所有区域的特征,然后利用特征来额外训练一个SVM网络来对候选区域进行分类。如果是R-CNN BB算法的话,它还会有第三个阶段,也就是训练一个框回归的模型用来回归出候选框的精确位置。所以说整个网络的训练过程是一个多阶段的训练过程,因为它要先训练CNN再训练SVM,最后还要训练一个框回归器,在训练svm和框回归模型的时候,是不是需要把每一张图片上的每一个候选框的这个特征都给它去提取出来,等这些特征都被提取出来后才能训练后续的模型,所以利用CNN提取到这个特征需要先把它写到磁盘里,供后续训练使用。所以在训练过程中会耗费大量的空间来存特征,会耗费大量的时间来提取特征。
R-CNN测试流程:
对于一张测试图片,R-CNN也需要先产生2000个候选区域,每个候选区域都需要通过这个CNN的前向传播来提特征,因此测试一张图片的速度也会特别慢,导致一张图的测试时间可能会达到47秒。通过刚刚对这三条的分析,我们可以看出来,R-CNN它之所以慢,是不是很大程度上都是因为它需要使用一个CNN来前向传播,提取每一个候选区域的特征,没有用到共享计算。因此后续提出的SPPnet这个网络,就尝试通过共享计算来加速R-CNN的训练和测试过程。

SPPnet的改进思路:

这里是SPPnet论文里的一个网络结构图。它的核心其实就是引入了一个这个spp层,也叫空间金字塔池化层。R-CNN里的CNN它其实就是AlexNet或者VGG这种图像分类网络,它本质上就是几个CNN跟上一个最大尺化层,几个CNN跟上一个最大石化层,然后这样不断堆叠的这种形式,最后再跟上几个全连接层的形式,然后在这里是横着把这个网络画出来了。然后在SPPnet这里它是竖着画了一个网络,在这里也是这种卷积层加上最大石化层,不断的堆叠,...,在最后再跟上了几个全连接层的形式。所以说SPPnet的这个网络结构跟R-CNN里的CNN其实几乎是一样的,它们唯一的区别就是R-CNN里的这个CNN,它在原先的这个全连接层的前面是一个最大值化层,但是在SPPnet这个网络里,全连接层前面的最后一个最大石化给替换成了一个空间金字塔池化层,这个空间金字塔纸化层的优点就是当你传入一张图片,通过一些卷积层和池化层,在最后通过一个卷积层的时候,假如得到了一个13x13x256通道的这么一个特征图,在这里只画了其中的一个通道。

正常在R-CNN的情况下,它会使用一个3x3大小,步长为2的一个最大池化层把13x13x256通道的特征图变成6x6大小的一个特征图,然后再把最后池化的这个结果拉平后,传给全连接层,获取最终的一个图片特征。这个SPP层它本质上就是限制了输出尺寸,也就是说它采用了一个动态的池化和尺寸。比如想从13x13的这个图中得到4x4大小的特征图,那么只需要使用13÷4,再向上取整的这么一个值来作为池化合的一个尺寸,也就是43÷4,再向下取整的这个值也就是三来作为池化后的步长,然后以这个尺寸为4,步长为3的一个池化后去在13x13的特征图上做池化运算,最后就会产生一个4x4大小的输出特征图,这个2x2和1x11大小的输出特征图也是同理,通过这种方法可以算出来。所以说这个空间金字塔池化层的池化后的尺寸和步长是一个动态变化的过程,它会根据输出特征图的尺寸来动态的改变池化合的尺寸和步长,在得到4x4大小,2x2大小和1x1大小的一个特征图之后,再把这些特征给拼接起来,就形成了一个固定长度的一个特征了,然后再把这个特征给传给后续的全连接层来形成最终的一个候选区域的图片特征。所以说有了这种空间金字塔池化层,就可以输入任意大小的图片了,因为输入任意大小的图片后,不管最后得到这个特征图是多少,都可以通过这一层来把它产生一个固定大小的一个输出,最后得到一个固定大小的一个特征。
既然不需要像R-CNN这样去限制cnn的输入尺寸了,那是不是可以换个思路就是不传候选区域进去而是直接把整幅图片给传到CNN当中,比如在原图上候选区域是这一部分区域,原图最后产生的这个特征图,它这个候选区域的特征也就是这一部分的区域,因此就可以直接把候选区域的特征图抠出来就可以了,由于不同位置最后得到的候选区域的这个尺寸是不一样的,但是正好可以利用这个SPP层把不同尺寸的特征图给转换成特定大小的一个输出,就可以只用把一整张图传进去给CNN,然后在CNN里只使用这一整张图进行一次前向传播,然后计算整张图的一个特征图,最后再把各个候选区域的特征给抠出来就可以了,也就是在整张图上共享计算了,这就是SPPnet最终采用的一个方法。
SPPnet不是像R-CNN一样把每一个候选区抠出来后再传给CNN去进行一次前向传播提取特征。这就解决了R-CNN的第三个问题,也就是在测试图片的时候不需要把每个区域都给传入到CNN中进行预测了,只需要传一整张图进去就就可以了。虽然解决了第三个问题,但是SPPnet还是有一些缺点的,首先像R-CNN一样,SPPnet的训练过程还是一个多阶段的过程,因为在最后利用全连接层提取到特征之后还是像R-CNN一样额外单独训练一个分类器或者训练一个回归模型。所以它还是一个多阶段的训练过程,并没有解决R-CNN的第一个问题。既然是多阶段的,那么所有特征还是需要先存下来,写到磁盘里,以便后续训练使用,所以R-CNN的第二个问题也没有得到解决,并且虽然第三个问题通过特征共享解决了,但是它又引入了一个新的问题就是SPPnet的微调算法很难去更新这个卷积层。
因此本文就提出了Fast R-CNN的方法来尝试解决上述R-CNN和SPPnet的缺点,Fast R-CNN有非常多的优点:
1.2.Fast R-CNN的贡献
第一,它比R-CNN和SPPnet具有更高的一个检测精度。第二,它的训练过程是一个单阶段的过程而不再是多阶段了。第三,训练能更新所有的网络层而不是像SPPnet的第三个缺点不能更新卷积层。第四,由于训练过程变成单阶段了,所以说他也就不需要额外的磁盘空间来缓存特征了。

2.Fast R-CNN的模型结构和训练流程

图一展示了Fast R-CNN的模型结构,图一对于一整张输入图片,Fast R-CNN会先通过一个深度卷积神经网络来得到整张图片的一个图片特征,根据候选区域在原图上的一个图片位置,可以使用RoI投影来获取到候选区域在特征图上的这个候选区域特征,有了候选区域的特征图之后再通过RoI池化层来把这个尺寸不固定的候选区域特征图给转换成特定尺寸的一个特征图,然后再接上两个全连接层来得到每一个区域的特征向量,有了每一个候选区域的特征后再额外接上两个并行的全连接层,其中一个利用softmax函数负责预测类别,另一个直接预测和框的坐标相关的一个框回归,这个预测类别的分支,输出k+1个类别,也就是数据集的类别加上一个背景类。另一个预测坐标的分支直接输出4乘以(k+1)个值,也就是每个类别对应的坐标。
回顾SPPnet的网络结构,就可以发现他们两个的区别是不是就两点,第一点区别是SPPnet在最后一个卷积层后面跟上的是一个空间金字塔池化,但是Fast R-CNN在最后一个卷积层后面跟上的是一个RoI池化层。第二点区别就是SPPnet在提取到候选区域的特征之后会像R-CNN一样额外训练支持向量机进行分类或回归,但是Fast R-CNN在这里是后面直接接了两个并行的全连接层实现分类和回归。
2.1.RoI池化层
RoI池化层能将任意有效的候选区域内的这个特征给转化成一个小的特征图,并且这个小的特征图具有特定的一个空间范围,这不就是SPPnet的这个空间金字塔池化层所干的事吗。因为它本质上就是使用最大池化把不规则的一个特征图给转换成一个特定尺寸的输出,只不过在这个空间金字塔池化层这里,它是分别使用了三个不同的池化来得到三个不同大小的一个输出。但是在Fast R-CNN这里,作者只用了一个池化来得到一个输出,所以作者才在最后这里写到RoI池化层仅仅是空间金字塔池化层的一种特殊情况,因为金字塔池化层是有三个输出,但是RoI池化层在这里它只有一个输出。


2.2.从预训练的模型中初始化一个Fast R-CNN模型
作者试验了三个预训练的Imagenet网络,每个网络都具有五个最大池化层并且具有5到13个卷积层。这三个预训练模型的具体结构会在4.1小节给详细列出。

所以这个就是预训练网络,它其实指的就是在Imagenet上预训练好的一个图像分类模型,预训练的分类模型它一般都是这种结构,也就是说先传入一整张图片,给一个深度卷积网络然后这个深度卷积网络会得到这一整张图片的一个特征图,然后接上一个固定尺寸的最大值化层来对这一个特征图做最大池化,再接上几个全连接层,最后再跟上一个全连接层和softmax函数来输出Imagenet数据集上的1000个图像类别。这里的这个初始化指的其实就是把一个预训练的一个图像分类网络给变成Fast R-CNN网络的这么一个过程。

也就是从上面这个模型变成下面这个模型的过程,在变换的过程中一共经历了三个变换阶段。第一步先把最后的一个最大池化层给替换成RoI池化层。第二步是把最后的一个全连接层和softmax层给替换成了两个并行的全连接层,其中一个分支用来预测k+1个类别,另一个分支用来预测边界框回归。第三步是把网络给修改成了两个数据输入,除了输入图片外还需要输入图片中的一系列候选区域坐标以便于在最终的这个特征图中把这个根据这个候选区域的坐标,把这个候选区域的特征给提取出来。
2.3.在检测任务上进行微调
在初始化好模型之后就需要开始微调这个检测模型了。微调模型其实就是使用反向传播来训练整个网络的一个权重,Fast R-CNN具有很好的训练权重的能力,但是SPPnet却不能很好的更新网络权重,为什么呢?这就需要涉及到训练过程中样本的一个采样方法。

看一下模型结构,这里因为是测试一张图片,所以只有一张图片,但是在模型训练时它是需要一批一批的图片给这个卷积神经网络的一次会传入多张图片。在反向传播更新权重的时候是需要利用正向传播得到的中间每一层的值去更新权重的。假如是SPPnet在训练时,它传入的多张图片,一批样本是通过随机采样得到的,比如说需要128个候选区,这128个区域它可能是来自不同的图片,也就是说需要传入128张这种类似的原图进去,然后在128个特征图中各自提取各自所需要的这个后面区域。在前向传播和反馈传播的过程中会占用大量的显存,降低模型的训练效率,但是Fast R-CNN采用的是另一种方法。
在Fast R-CNN的训练过程中,随机梯度下降的这个mini batch它是通过一种按层抽样的方法,这里以n=2,r=128为例,它会首先采样两张图片然后在每张图片上各自采样64个候选区域,这样做的好处就是每次在前会传播的时候只传两张图片进去就可以了。因为每张图片的64个区域都是在一张图上去得到的,所以说只需要两张原图传进去,然后在两张原图的特征图上各自提取64个候选区域就可以了,而不是像SPPnet一样需要去传入128个原图。这就大大提升了训练效率,这也就是作者他为什么提到SPPnet不能够更新空间,金字塔池化层之前的一个网络权重,因为它因为它更新权重的效率实在太低了。
2.4.多任务损失函数
Fast R-CNN网络是有两个并行的输出层的。这第一个输出用来产生k+1个类别,其中p0 就表示某个候选区域是背景类的概率,p1-pk就表示属于k数据集类别的概率。第二个分支输出的就是一个框回归的一个偏移量,它预测出来的tx和ty就表示框的中心点归一化后的偏移量,tw和th就表示跟边界框的宽和高相关的一个值,它们四个的具体含义跟R-CNN中的定义是一样的。

求损失函数的时候除了要有预测值之外,还需要有一个提前标注好的一个目标值,也就是ground truth。作者在这里把标注好的候选区域类别给用u这个符号给表示出来,把边界框回归的这个目标值给定义成v这个符号。多任务损失的公式就可以写成这种形式,也就是类别损失和框回归损失相加的一个形式
![]()
在求类别损失的时候,它用到了类别的预测值和类别的一个目标值,类别损失的具体公式就写成了这种形式,它相当于是求了du类预测概率的log损失来作为分类的一个损失,在求框回归损失的时候,用到了du类目标的一个坐标,预测值和目标值,它的具体公式就写成了这种形式

通过求x y w h这四个值的预测值和目标值之间的一个smooth L1损失来作为框回归的一个损失公式,smooth L1的一个具体的公式就是下面的这种形式,在这里也回顾一下R-CNN中使用的L2 损失,L2损失是这种形式就是x平方,看一下它们的图像:

如果使用L2 损失,就这条曲线它是可以向两端无限延伸的。如果你预测出来的这个预测值和目标值偏差过大的话,就会导致这个x过大,这x过大的话就会导致你这个值一直无限的往上延伸,然后在这个图像上,它的这个斜率其实就是梯度,当无限往上延伸的时候这个梯度就会趋向于无穷大,就会产生梯度爆炸现象,没法训练。所以这个smooth L1损失在x大于等于1的时候把它写成了这种形式

因为这种形式它的梯度是恒等于1的,也就是说它相当于是给这个梯度它设置了一个上限就不会再像这种L2 损失是一样产生梯度爆炸的。因为这个梯度是恒等于1的,当x绝对值小于1的时候,这里多乘了一个0.5的这一个系数是为了让这个分段函数它在x等于1的这个点两端的一个梯度值是连续的。在公式中还有一个超参数就是lambda,这个lambda它其实就是用来控制你的分类损失和回归损失之间的一个平衡,这个lamba的值一般被设置为1。

在公式里面还有一个就是这个方括号,它表示只有当目标类别是大于等于1的时候,这个方框的值才等于1,表示需要去求这个回归损失。如果u等于0的话就表示这是一个背景类,这个值也就是零。所以最后求出一下这个回归损失就是0。因为背景类它是没有预测框的,也就不需要去求后边这个回归损失。
2.5.尺度不变性
尺度不变性指的就是有两个相同的目标,一个目标比较大,一个目标比较小。如果这两个目标都能够被模型识别出来,就说明这个模型具有比较好的尺度不变性。
作者实现了两种方法来实现目标检测的尺度不变性,第一种brute force,可以把它理解成单尺度训练,在单尺度训练过程中每一张图片都被处理成了一个预定义好的图片尺寸来进行训练或者是进行预测。它的目的是让网络来直接学会尺度不变形。第二种这种多尺度方法其实就是在训练期间,每一张图片都先被随机采样成一个特定的尺度而不是像第一种一样是采用一个预定义的固定尺度,然后这种多尺度的训练方法也是一种数据增强的方式。关于这两种方法哪种好,在第五章的时候会有实验结果做对比。
3.Fast R-CNN测试
一旦Fast R-CNN的网络被微调好后就可以进行目标检测了。整个网络只需要接收两个输入,分别是一张图片和这个图片中的一系列目标候选区域,就能够预测出候选区域的类别和精确坐标了。
3.1.截断SVD以便更快地检测
对于图像分类任务来说,花费在全连接层上的时间比花费在卷积层上的时间要小。相反的对于检测任务来说,由于这个RoI的数量非常非常的大,因此几乎一半的钱会传播时间都被花费在了计算全连接层上,这是因为在测试一张图片的时候只需要通过一次前向传播把这一整张图的一个特征图给提取出来就可以了。但是在后面进行全连接层运算的时候需要把这一张图上所有的候选区域抠出来后的这个候选区域特征图都给通过后面的全连接层去进行运算。所以说后面这个全连接层会占据大量的一个测试时间,所以必须要对后面这个全连接层进行加速,大的全连接层的一个加速方法就是通过这种阶段的奇异值分解方法

先理解这个SVD是什么?简单来说假如有一个u乘v大小的一个矩阵,可以通过奇异值分解把它分解成一个u乘n大小的矩阵,乘上一个n乘n大小的一个对角矩阵,再乘上一个n乘v大小的一个矩阵,并且中间的这个对角矩阵其实有一个性质就越靠近左上角的这个值越重要,越靠近右下角的这个值越不重要,既然右下角的这个值不重要,那就可以直接把这些值给去掉,让中间的这个矩阵它变成一个t乘t的一个矩阵,相当于把后面的元素都给去掉,然后只保留左上角这一部分变成一个t乘t的矩阵,相应的前面这个矩阵就把最后这几列给去掉,变成u乘t的一个矩阵,然后后面这个矩阵就把最后的这几行给去掉就变成一个t乘v的一个矩阵,相当于对原始的这么一个u乘v的矩阵做了一个压缩。我们把这个公式用字母表示就可以表示成左边的这种形式,也就是左边的这个矩阵跟你右边的这个压缩后的矩阵,其实两者是可以近似相等的。
现在回到全连接层的概念,全连接层本质上就是让参数矩阵w和一个输入特征x去进行相乘,既然左边乘x的,那么右边也可以乘上一个x,也就是说可以把单个全连接层w给替换成两个全连接层,这两个全连接层中的第一个是使用了一个权重矩阵,这个形式也就是这个来作为两个全连接层中的第一个,然后两个全连接层中的第二个就使用这个u来作为权重矩阵,也就是这个这个全中,这就可以把左边的这个和全连接层用右边两个更小的全连接层近似替换了,然后在替换前左边的这个参数是u乘w的参数,然后右边压缩后的参数其实是u乘t加上一个v乘t,并且在右边这个压缩的力度越大,最后在右边的这个参数是越小的,参数越少,模型的运行速度就会越快。所以说通过这种截断的奇异值分解法可以提高全连接层的一个推理速度。
4.实验结果

证明1. State-of-the-art mAP on VOC07, 2010, and 2012

证明2. Fast training and testing compared to R-CNN, SPPnet

证明3. Fine-tuning conv layers in VGG16 improves mAP

5.设计评价
5.1多任务训练有帮助吗
实验结果表明,这个多任务训练的一个结果确实是要比这个多阶段的训练效果要好的。

5.2单尺度训练和多尺度训练的一个效果对比
 5.3Fast R-CNN是否需要更多的训练数据
5.3Fast R-CNN是否需要更多的训练数据
证明了对Fast R-CNN来说,更多的训练数据确实会提高模型的精度而不会出现其他传统模型出现了这种精度饱和的情况。
5.4支持向量机是否比soft max的训练效果好

5.5候选区域是不是越多越好

参考视频
目标检测之Fast R-CNN论文精讲,Fast RCNN_哔哩哔哩_bilibili
相关文章:
Fast R-CNN(论文阅读)
论文名:Fast R-CNN 论文作者:Ross Girshick 期刊/会议名:ICCV 2015 发表时间:2015-9 论文地址:https://arxiv.org/pdf/1504.08083 源码:https://github.com/rbgirshick/fast-rcnn 摘要 这篇论文提出了一…...

视觉语言模型:融合视觉与语言的未来
1. 概述 视觉语言模型(Vision-Language Models, VLMs)是能够同时处理和理解视觉(图像)和语言(文本)两种模态信息的人工智能模型。这种模型结合了计算机视觉和自然语言处理的技术,使得它们能够在…...
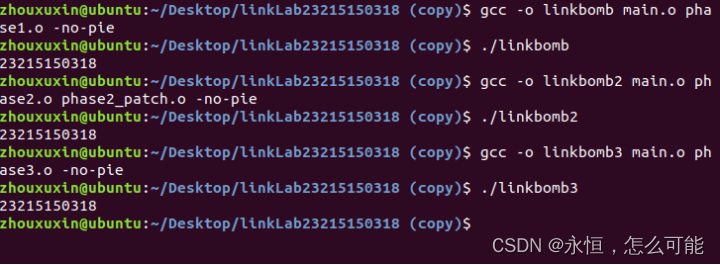
【CSAPP】-linklab实验
目录 实验目的与要求 实验原理与内容 实验步骤 实验设备与软件环境 实验过程与结果(可贴图) 实验总结 实验目的与要求 1.了解链接的基本概念和链接过程所要完成的任务。 2.理解ELF目标代码和目标代码文件的基本概念和基本构成 3.了解ELF可重定位目…...

UE C++ 多镜头设置缩放 平移
一.整体思路 首先需要在 想要控制的躯体Pawn上,生成不同相机对应的SpringArm组件。其次是在Controller上,拿到这个Pawn,并在其中设置输入响应,并定义响应事件。响应事件里有指向Pawn的指针,并把Pawn的缩放平移功能进行…...
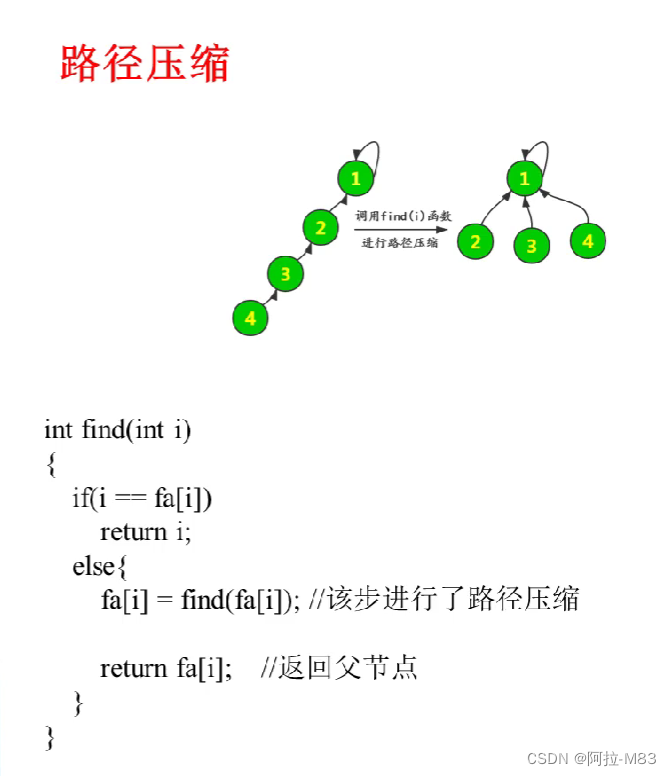
代码随想录Day69(图论Part05)
并查集 // 1.初始化 int fa[MAXN]; void init(int n) {for (int i1;i<n;i)fa[i]i; }// 2.查询 找到的祖先直接返回,未进行路径压缩 int.find(int i){if(fa[i] i)return i;// 递归出口,当到达了祖先位置,就返回祖先elsereturn find(fa[i])…...

53-1 内网代理3 - Netsh端口转发(推荐)
靶场还是用上一篇文章搭建的靶场 :52-5 内网代理2 - LCX端口转发(不推荐使用LCX)-CSDN博客 一、Netsh 实现端口转发 Netsh是Windows自带的命令行脚本工具,可用于配置端口转发。在一个典型的场景中,如果我们位于公网无法直接访问内网的Web服务器,可以利用中间的跳板机通过…...

四、(1)网络爬虫入门及准备工作(爬虫及数据可视化)
四、(1)网络爬虫入门及准备工作(爬虫及数据可视化) 1,网络爬虫入门1.1 百度指数1.2 天眼查1.3 爬虫原理1.4 搜索引擎原理 2,准备工作2.1 分析爬取页面2.2 爬虫拿到的不仅是网页还是网页的源代码2.3 爬虫就是…...
-C卷D卷-200分)
2024华为OD机试真题-分月饼-(C++/Python)-C卷D卷-200分
2024华为OD机试题库-(C卷+D卷)-(JAVA、Python、C++) 题目描述 中秋节,公司分月饼,m 个员工,买了 n 个月饼,m ≤ n,每个员工至少分 1 个月饼,但可以分多个,单人分到最多月饼的个数是 Max1 ,单人分到第二多月饼个数是 Max2 ,Max1 - Max2 ≤ 3 ,单人分到第 n - 1…...

Git 查看提交历史
Git 查看提交历史 Git 是一个强大的版本控制系统,它允许开发人员跟踪代码的变化,并与其他人协作。了解如何查看提交历史对于理解项目的发展和维护代码库至关重要。本文将详细介绍如何使用 Git 查看提交历史,包括不同的命令和选项,…...

力扣双指针算法题目:快乐数
目录 1.题目 2.思路解析 3.代码展示 1.题目 . - 力扣(LeetCode) 2.思路解析 题目意思是将一个正整数上面的每一位拿出来,然后分别求平方,最后将这些数字的平方求和得到一个数字,如此循环,如果在此循环中…...
:未来的智能体)
【Tools】了解人工通用智能 (AGI):未来的智能体
什么是人工通用智能 (AGI)? 人工通用智能(Artificial General Intelligence,AGI)是指一种能够理解、学习和应用知识,具有像人类一样广泛和通用的认知能力的智能系统。与专门处理特定任务的人工智能(AI&…...

华媒舍:8种网站构建推广方法全揭密!
网站构建成为了推广宣传和宣传品牌的关键一环。对于新手,搭建和营销推广网站有可能是一项全新的挑战。下面我们就为大家介绍8种网站搭建和营销推广技巧,帮助你在这些方面取得成功。 1.选择适合自己的网站构建平台选择合适的网站构建平台针对构建一个成功…...

【Scrapy】 深入了解 Scrapy 下载中间件的 process_exception 方法
准我快乐地重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 再去做没流着情泪的伊人 假装再有从前演过的戏份 重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 你纵是未明白仍夜深一人 穿起你那无言毛衣当跟你接近 🎵 陈慧娴《傻女》 Scrapy 是…...

DevEco Studio无法识别本地模拟器设备的解决方法
目录 场景 解决办法 方式1 方式2 场景 有很多小伙伴遇到过安装了手机模拟器, 但是开发工具设备栏不识别手机设备的问题, 如下图,明明模拟器都安装了,并启动, 但为什么设备栏不显示呢? 解决后的截图,应该是这样(其实跟 android 类似 )...

EN-SLAM:Implicit Event-RGBD Neural SLAM解读
论文路径:https://arxiv.org/pdf/2311.11013.pdf 目录 1 论文背景 2 论文概述 2.1 神经辐射场(NeRF) 2.2 事件相机(Event Camera) 2.3 事件时间聚合优化策略(ETA) 2.4 可微分的CRF渲染技术…...

2407C++,从构生成协议文件
原文 protobuf会根据proto文件生成c对象及其序化/反序化方法,而iguana的struct_pb则是以结构为核心,编译期反射来生成序化/反序化代码. 有人提出能不能按proto文件输出结构呢,这样就可给其它语言用了,很好建议,实现起来也比较简单. protobuf是从proto文件到c对象,而struct_p…...

遗传算法求解TSP
一、基本步骤 遗传算法求解旅行商问题(TSP)的一般步骤如下: 编码: 通常采用整数编码,将城市的访问顺序表示为一个染色体。例如,假设有 5 个城市,编码为[1, 3, 5, 2, 4],表示旅行商的…...

鸿蒙开发:Universal Keystore Kit(密钥管理服务)【明文导入密钥(C/C++)】
明文导入密钥(C/C) 以明文导入ECC密钥为例。具体的场景介绍及支持的算法规格 在CMake脚本中链接相关动态库 target_link_libraries(entry PUBLIC libhuks_ndk.z.so)开发步骤 指定密钥别名keyAlias。 密钥别名的最大长度为64字节。 封装密钥属性集和密钥材料。通过[OH_Huks_I…...

视频汇聚/安防监控/GB28181国标EasyCVR视频综合管理平台出现串流的原因排查及解决
安防视频监控系统/视频汇聚EasyCVR视频综合管理平台,采用了开放式的网络结构,能在复杂的网络环境中(专网、局域网、广域网、VPN、公网等)将前端海量的设备进行统一集中接入与视频汇聚管理,视频汇聚EasyCVR平台支持设备…...

告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境
告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境 对于嵌入式开发者来说,配置开发环境往往是个令人头疼的问题。传统虚拟机方案虽然能提供完整的Linux体验,但资源占用高、启动慢、与宿主系统交互不便等问题一直困扰着开发者。…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

集成Taotoken为OpenClaw工作流提供持久化模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 集成Taotoken为OpenClaw工作流提供持久化模型支持 在构建基于OpenClaw的自动化Agent工作流时,一个稳定且可灵活切换的模…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

3分钟终极指南:用ncmdump轻松解密网易云音乐NCM格式文件
3分钟终极指南:用ncmdump轻松解密网易云音乐NCM格式文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM格式文件无法在其他播放器播放而烦恼吗?ncmdump正是解决这个问题的神器&…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...