在卷积神经网络(CNN)中为什么可以使用多个较小的卷积核替代一个较大的卷积核,以达到相同的感受野
在卷积神经网络(CNN)中为什么可以使用多个较小的卷积核替代一个较大的卷积核,以达到相同的感受野
flyfish
在卷积神经网络(CNN)中,可以使用多个较小的卷积核替代一个较大的卷积核,以达到相同的感受野。具体来说:
-
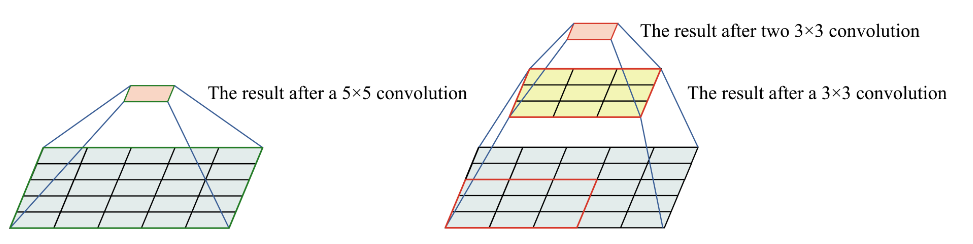
两个3x3的卷积核堆叠可以替代一个5x5的卷积核。这样,每个输出单元都能够感受到一个5x5区域的输入信息。
-
三个3x3的卷积核堆叠可以替代一个7x7的卷积核。这意味着,通过三层3x3卷积,最终的输出单元可以感受到一个7x7区域的输入信息。
-
四个3x3的卷积核堆叠可以替代一个9x9的卷积核。通过四层3x3卷积,输出单元能够覆盖一个9x9区域的输入信息。
import numpy as np# 输入特征图
input_feature_map = np.array([[1, 2, 3, 0, 1],[4, 5, 6, 1, 2],[7, 8, 9, 2, 3],[1, 2, 3, 0, 1],[4, 5, 6, 1, 2]
])# 卷积核
kernel = np.array([[1, 0, -1],[1, 0, -1],[1, 0, -1]
])# 输出特征图的大小
output_height = input_feature_map.shape[0] - kernel.shape[0] + 1
output_width = input_feature_map.shape[1] - kernel.shape[1] + 1
output_feature_map = np.zeros((output_height, output_width))# 计算总计算量
total_computations = 0# 进行卷积操作
for i in range(output_height):for j in range(output_width):# 提取当前窗口的子矩阵current_window = input_feature_map[i:i+kernel.shape[0], j:j+kernel.shape[1]]# 进行逐元素乘法并求和output_feature_map[i, j] = np.sum(current_window * kernel)# 计算当前窗口的计算量total_computations += np.prod(kernel.shape) # 3x3 次乘法print("输出特征图:")
print(output_feature_map)
print("总计算量 (乘法次数):", total_computations)
在进行卷积操作时,对于输入特征图大小 5 × 5 5 \times 5 5×5 和卷积核大小 3 × 3 3 \times 3 3×3,输出特征图的大小是 ( 5 − 3 + 1 ) × ( 5 − 3 + 1 ) = 3 × 3 (5 - 3 + 1) \times (5 - 3 + 1) = 3 \times 3 (5−3+1)×(5−3+1)=3×3。在每个输出位置,我们需要进行 3 × 3 = 9 3 \times 3 = 9 3×3=9 次乘法计算,总的计算量是 3 × 3 × 9 = 81 3 \times 3 \times 9 = 81 3×3×9=81 次乘法。
1 2 3 0 1 1 2 3 2 3 0 3 0 1
4 5 6 1 2 4 5 6 5 6 1 6 1 2
7 8 9 2 3 7 8 9 8 9 2 9 2 34 5 6 1 2 4 5 6 5 6 1 6 1 2
7 8 9 2 3 7 8 9 8 9 2 9 2 3
1 2 3 0 1 1 2 3 2 3 0 3 0 17 8 9 2 3 7 8 9 8 9 2 9 2 3
1 2 3 0 1 1 2 3 2 3 0 3 0 1
4 5 6 1 2 4 5 6 5 6 1 6 1 2
计算卷积操作的计算量
在计算卷积操作的总计算量时,可以使用以下公式:
总计算量 (乘法次数) = ( H − K + 1 ) × ( W − K + 1 ) × K × K × C i n × C o u t \text{总计算量 (乘法次数)} = (H - K + 1) \times (W - K + 1) \times K \times K \times C_{in} \times C_{out} 总计算量 (乘法次数)=(H−K+1)×(W−K+1)×K×K×Cin×Cout
其中:
-
H H H 和 W W W 是输入特征图的高度和宽度。
-
K K K 是卷积核的大小(假设为方形,即 K × K K \times K K×K)。
-
C i n C_{in} Cin 是输入通道数。
-
C o u t C_{out} Cout 是输出通道数。
应用公式计算示例
对于一个 5x5 的输入特征图和 3x3 的卷积核,假设输入通道数和输出通道数都为 1:
-
输入特征图大小: H = 5 H = 5 H=5, W = 5 W = 5 W=5
-
卷积核大小: K = 3 K = 3 K=3
-
输入通道数: C i n = 1 C_{in} = 1 Cin=1
-
输出通道数: C o u t = 1 C_{out} = 1 Cout=1
将这些值代入公式中:
总计算量 (乘法次数) = ( 5 − 3 + 1 ) × ( 5 − 3 + 1 ) × 3 × 3 × 1 × 1 \text{总计算量 (乘法次数)} = (5 - 3 + 1) \times (5 - 3 + 1) \times 3 \times 3 \times 1 \times 1 总计算量 (乘法次数)=(5−3+1)×(5−3+1)×3×3×1×1
计算:
总计算量 (乘法次数) = 3 × 3 × 3 × 3 = 81 \text{总计算量 (乘法次数)} = 3 \times 3 \times 3 \times 3 = 81 总计算量 (乘法次数)=3×3×3×3=81
( H − K + 1 ) × ( W − K + 1 ) (H - K + 1) \times (W - K + 1) (H−K+1)×(W−K+1) 计算的是输出特征图的大小,这里是 3 × 3 3 \times 3 3×3。
每个输出特征图的位置上,进行 K × K × C i n K \times K \times C_{in} K×K×Cin 次乘法计算,这里是 3 × 3 × 1 = 9 3 \times 3 \times 1 = 9 3×3×1=9 次乘法。
计算量是输出特征图的元素数量乘以每个元素的计算量,即 9 × 9 = 81 9 \times 9 = 81 9×9=81 次乘法。
例子
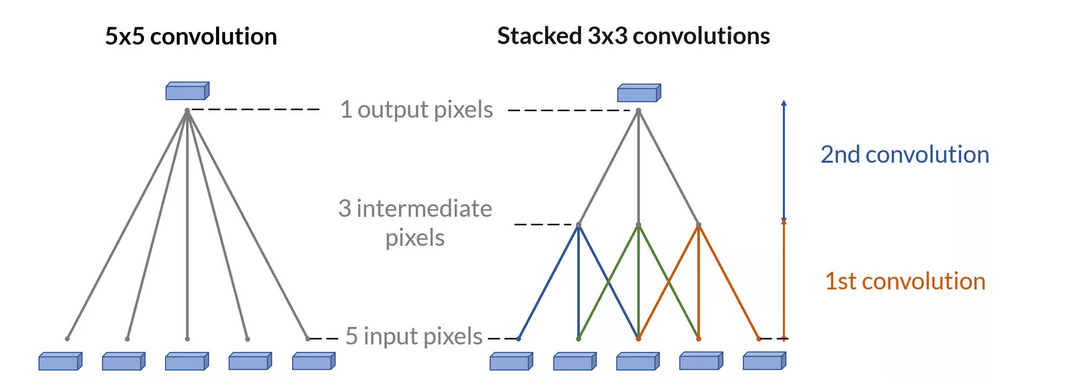
如果输入特征图是 28 × 28 28 \times 28 28×28,计算两个 3x3 卷积核堆叠和一个 5x5 卷积核的计算量,并比较它们。
情况 1:两个 3x3 卷积核堆叠
- 第一个 3x3 卷积核 :
-
输入特征图大小: 28 × 28 28 \times 28 28×28
-
输出特征图大小: ( 28 − 3 + 1 ) × ( 28 − 3 + 1 ) = 26 × 26 (28 - 3 + 1) \times (28 - 3 + 1) = 26 \times 26 (28−3+1)×(28−3+1)=26×26
-
计算量: 26 × 26 × 3 × 3 × C i n × C m i d 26 \times 26 \times 3 \times 3 \times C_{in} \times C_{mid} 26×26×3×3×Cin×Cmid
- 第二个 3x3 卷积核 :
-
输入特征图大小: 26 × 26 26 \times 26 26×26
-
输出特征图大小: ( 26 − 3 + 1 ) × ( 26 − 3 + 1 ) = 24 × 24 (26 - 3 + 1) \times (26 - 3 + 1) = 24 \times 24 (26−3+1)×(26−3+1)=24×24
-
计算量: 24 × 24 × 3 × 3 × C m i d × C o u t 24 \times 24 \times 3 \times 3 \times C_{mid} \times C_{out} 24×24×3×3×Cmid×Cout
计算量 3 × 3 = 26 × 26 × 9 × C i n × C m i d + 24 × 24 × 9 × C m i d × C o u t \text{计算量}_{3\times3} = 26 \times 26 \times 9 \times C_{in} \times C_{mid} + 24 \times 24 \times 9 \times C_{mid} \times C_{out} 计算量3×3=26×26×9×Cin×Cmid+24×24×9×Cmid×Cout
情况 2:一个 5x5 卷积核
-
输入特征图大小: 28 × 28 28 \times 28 28×28
-
输出特征图大小: ( 28 − 5 + 1 ) × ( 28 − 5 + 1 ) = 24 × 24 (28 - 5 + 1) \times (28 - 5 + 1) = 24 \times 24 (28−5+1)×(28−5+1)=24×24
-
计算量: 24 × 24 × 5 × 5 × C i n × C o u t 24 \times 24 \times 5 \times 5 \times C_{in} \times C_{out} 24×24×5×5×Cin×Cout
示例计算
假设输入和输出通道数都为 1:
- 第一个 3x3 卷积核 :
-
输出特征图大小: 26 × 26 26 \times 26 26×26
-
计算量: 26 × 26 × 9 × 1 × 1 = 6084 26 \times 26 \times 9 \times 1 \times 1 = 6084 26×26×9×1×1=6084
- 第二个 3x3 卷积核 :
-
输出特征图大小: 24 × 24 24 \times 24 24×24
-
计算量: 24 × 24 × 9 × 1 × 1 = 5184 24 \times 24 \times 9 \times 1 \times 1 = 5184 24×24×9×1×1=5184
总计算量:
计算量 3 x 3 = 6084 + 5184 = 11268 \text{计算量}_{3x3} = 6084 + 5184 = 11268 计算量3x3=6084+5184=11268
- 一个 5x5 卷积核 :
-
输出特征图大小: 24 × 24 24 \times 24 24×24
-
计算量: 24 × 24 × 25 × 1 × 1 = 14400 24 \times 24 \times 25 \times 1 \times 1 = 14400 24×24×25×1×1=14400
def compute_3x3_stack_computation(H, W, C_in, C_out):# 第一个 3x3 卷积核output_height1 = H - 3 + 1output_width1 = W - 3 + 1computation_3x3_1 = output_height1 * output_width1 * 3 * 3 * C_in * C_out# 第二个 3x3 卷积核output_height2 = output_height1 - 3 + 1output_width2 = output_width1 - 3 + 1computation_3x3_2 = output_height2 * output_width2 * 3 * 3 * C_out * C_outtotal_computation_3x3 = computation_3x3_1 + computation_3x3_2return total_computation_3x3def compute_5x5_computation(H, W, C_in, C_out):# 一个 5x5 卷积核output_height = H - 5 + 1output_width = W - 5 + 1computation_5x5 = output_height * output_width * 5 * 5 * C_in * C_outreturn computation_5x5# 示例参数
H, W, C_in, C_out = 28, 28, 1, 1# 计算
computation_3x3 = compute_3x3_stack_computation(H, W, C_in, C_out)
computation_5x5 = compute_5x5_computation(H, W, C_in, C_out)# 减少的计算量百分比
reduction_percentage = (1 - computation_3x3 / computation_5x5) * 100print("两个 3x3 卷积核堆叠的计算量:", computation_3x3)
print("一个 5x5 卷积核的计算量:", computation_5x5)
print("减少的计算量百分比:", reduction_percentage)
两个 3x3 卷积核堆叠的计算量: 11268
一个 5x5 卷积核的计算量: 14400
减少的计算量百分比: 21.750000000000004
参考论文《Rethinking the Inception Architecture for Computer Vision》
相关文章:
在卷积神经网络(CNN)中为什么可以使用多个较小的卷积核替代一个较大的卷积核,以达到相同的感受野
在卷积神经网络(CNN)中为什么可以使用多个较小的卷积核替代一个较大的卷积核,以达到相同的感受野 flyfish 在卷积神经网络(CNN)中,可以使用多个较小的卷积核替代一个较大的卷积核,以达到相同的…...
:MP中内置的插件)
【学习笔记】Mybatis-Plus(四):MP中内置的插件
内置插件 目前MP已经存在的内部插件包括如下: 插件类名作用PaginationInnerInterceptor分页插件。可以代替以前的PageHelperOptimisticLockerInnerInterceptor乐观锁插件。用于幂等性操作,采用版本更新记录DynamicTableNameInnerInterceptor动态表名Te…...
GlusterFS分布式存储系统
GlusterFS分布式存储系统 一,分布式文件系统理论基础 1.1 分布式文件系统出现 计算机通过文件系统管理,存储数据,而现在数据信息爆炸的时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储…...

微信公众平台测试账号本地微信功能测试说明
使用场景 在本地测试微信登录功能时,因为微信需要可以互联网访问的域名接口,所以本地使用花生壳做内网穿透,将前端服务的端口和后端服务端口进行绑定,获得花生壳提供的两个外网域名。 微信测试账号入口 绑定回调接口 回调接口的…...

Lua语言入门
目录 Lua语言1 搭建Lua开发环境1.1 安装Lua解释器WindowsLinux 1.2 IntelliJ安装Lua插件在线安装本地安装 2 Lua语法2.1 数据类型2.2 变量全局变量局部变量命名规范局部变量作用域 2.3 注释单行注释多行注释 2.4 赋值2.5 操作符数学操作符比较操作符逻辑操作符连接操作符取长度…...

卷积神经网络有哪些应用场景
卷积神经网络(Convolutional Neural Networks,简称CNN)的应用场景非常广泛,尤其是在处理具有网格结构的数据(如图像、视频)时表现出色。以下是一些主要的应用场景: 1. 图像识别与分类 图像分类…...

std::unordered_map和std::map在性能上有何不同
std::unordered_map和std::map在性能上的不同主要体现在以下几个方面: 1. 底层数据结构 std::unordered_map:基于哈希表实现,通过哈希函数计算元素的存储位置。哈希表能够直接通过哈希值快速定位到元素的位置,从而实现高效的查找…...

C++20中的基于范围的for循环(range-based for loop)
C11中引入了对基于范围的for循环(range-based for loop)的支持:该循环对一系列值(例如容器中的所有元素)进行操作。代码段如下: const std::vector<int> vec{ 1,2,3,4,5 }; for (const auto& i : vec)std::cout << i << ", …...

PCIe驱动开发(2)— 第一个简单驱动编写和测试
PCIe驱动开发(2)— 第一个简单驱动编写和测试 一、前言 教程参考:02_实战部分_PCIE设备测试 教程参考:03_PCIe设备驱动源码解析 二、驱动编写 新建hello_pcie.c文件 touch hello_pcie.c然后编写内容如下所示: #i…...

k8s-第七节-ConfigMap Secret
ConfigMap & Secret ConfigMap 数据库连接地址,这种可能根据部署环境变化的或者其他容器配置选项的包括容器更新或者扩容时可以统一配置 Kubernetes 为我们提供了 ConfigMap,可以方便的配置一些变量。 https://kubernetes.io/zh/docs/concepts/c…...

MySQL架构和工作流程
引言:MySQL执行一条sql语句期间发生了什么? 想要搞清楚这个问题,我们必须了解MySQL的体系结构和工作流程 一、MySQL体系结构 MySQL由以下几个部分组成 一、server层 1.MySQL Connnectors连接器,MySQL的连接池组件,…...

java项目总结8
1.方法引用 1.方法引用概述 注意注意: 1.引用出必须是函数式接口 2.被引用的方法必须已经存在 3.被引用方法的型参和返回值需要跟抽象方法保持一致 4.被引方法的功能要满足当前需求 Arrays.sort(arr,Main::subtraction); Main是该类的名称,:…...
【Nvidia+AI相机】涂布视觉检测方案专注提高锂电池质量把控标准
锂电池单元的质量在多个生产制造领域都至关重要,特别是在新能源汽车、高端消费电子等行业。这些领域的产品高度依赖锂电池提供持续、稳定的能量供应。优质的锂电池单元不仅能提升产品的性能和用户体验,还能确保使用安全。因此,保证锂电池单元…...

Spring Cloud Alibaba - Sentinel 分布式系统流量哨兵
目录 概述特征基本概念 安装Sentinel微服务引入Sentinel案例流控规则(流量控制)流控模式-直接流控模式-关联流控模式-链路流控效果-快速失败流控效果-预热WarmUp流控效果-排队等候 流控规则(并发线程数控制)熔断规则(熔…...

文件存储的方法一
文章目录 概念介绍实现方法示例代码 我们在上一章回中介绍了"如何实现本地存储"相关的内容,本章回中将介绍如何实现文件存储.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在上一章回中介绍的本地存储只能存储dart语言中基本类型的数值…...

数据结构/作业/2024/7/7
搭建个场景: 将学生的信息,以顺序表的方式存储(堆区),并且实现封装函数︰1】顺序表的创建, 2】判满、 3】判空、 4】往顺序表里增加学生、5】遍历、 6】任意位置插入学生、7】任意位置删除学生、8】修改、 9】查找(按学生的学号查…...

隔离级别-隔离级别中的锁协议、隔离级别类型、隔离级别的设置、隔离级别应用
一、引言 1、DBMS除了采用严格的两阶段封锁协议来保证并发事务的可串行化,实现事务的隔离性,也可允许用户选择一个可以保证应用程序正确执行并且能够使并发度最大的隔离性等级 2、通常用隔离级别来描述隔离性等级,以下将主要介绍ANSI 92标准…...

【数据结构与算法】希尔排序
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法》 期待您的关注 ...

【机器学习】(基础篇一) —— 什么是机器学习
什么是机器学习 本系列博客为你从机器学习的介绍开始,使用大量的代码实战和验证,最终帮助你完全掌握什么是机器学习 人工智能、机器学习和深度学习的关系 人工智能(Artificial Intelligence,AI):是一门研…...

VitePress安装部署
VitePress安装部署 VitePress安装步骤 安装 Node环境 官网下载:https://nodejs.org/zh-cn 傻瓜式安装到完成 npm环境 安装完Node环境之后,可以直接运行下面的命令安装npm npm install -g pnpm关于pnpm源: 有时候需要国内源,…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...