# Sharding-JDBC 从入门到精通(10)- 综合案例(三)查询商品与测试及统计商品和总结
Sharding-JDBC 从入门到精通(10)- 综合案例(三)查询商品与测试及统计商品和总结
一、Sharding-JDBC 综合案例-查询商品-dao
1、查询商品:Dao 实现:在 ProductDao 中定义商品查询方法:
//查询商品@Select("select i.*, d.descript, r.region_name placeOfOrigin " +"from product_info i join product_descript d on i.product_info_id = d.product_info_id " +"join region r on i.region_code = r.region_code order by i.product_info_id desc limit #{start}, #{pageSize}")List<ProductInfo> selectProductList( @Param("start") int start, @Param("pageSize") int pageSize);
2、在 shopping 子工程(子模块)中,修改 dao 接口类 ProductDao.java,添加查询商品的方法。
/*** dbsharding\shopping\src\main\java\djh\it\shopping\dao\ProductDao.java** 2024-7-3 创建 dao 接口类 ProductDao.java*/
package djh.it.shopping.dao;import djh.it.shopping.entity.ProductDescript;
import djh.it.shopping.entity.ProductInfo;
import org.apache.ibatis.annotations.*;
import org.springframework.stereotype.Component;import java.util.List;
import java.util.Map;@Mapper
@Component
public interface ProductDao {//添加商品基本信息@Insert("insert into product_info(store_info_id, product_name, spec, region_code, price) " +" values(#{storeInfoId},#{productName},#{spec},#{regionCode},#{price})")@Options(useGeneratedKeys = true, keyProperty = "productInfoId", keyColumn = "product_info_id")int insertProductInfo( ProductInfo productInfo );//添加商品描述信息@Insert("insert into product_descript(product_info_id, descript, store_info_id) " +" values(#{productInfoId}, #{descript}, #{storeInfoId})")@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")int insertProductDescript( ProductDescript productDescript );//查询商品@Select("select i.*, d.descript, r.region_name placeOfOrigin " +"from product_info i join product_descript d on i.product_info_id = d.product_info_id " +"join region r on i.region_code = r.region_code order by i.product_info_id desc limit #{start}, #{pageSize}")List<ProductInfo> selectProductList( @Param("start") int start, @Param("pageSize") int pageSize);}
二、Sharding-JDBC 综合案例-查询商品-service 及测试
1、在 shopping 子工程(子模块)中,修改 service 接口类 ProductService.java 添加查询方法。
/*** dbsharding\shopping\src\main\java\djh\it\shopping\service\ProductService.java** 2024-7-3 创建 service 接口类 ProductService.java*/
package djh.it.shopping.service;import djh.it.shopping.entity.ProductInfo;import java.util.List;public interface ProductService {//添加商品public void createProduct( ProductInfo productInfo );//查询商品public List<ProductInfo> queryProduct( int page, int pageSize);
}2、在 shopping 子工程(子模块)中,修改 service 实现类 ProductServiceImpl.java 添加查询方法。
/*** dbsharding\shopping\src\main\java\djh\it\shopping\service\impl\ProductServiceImpl.java** 2024-7-3 创建 service 实现类 ProductServiceImpl.java*/
package djh.it.shopping.service.impl;import djh.it.shopping.dao.ProductDao;
import djh.it.shopping.entity.ProductDescript;
import djh.it.shopping.entity.ProductInfo;
import djh.it.shopping.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.util.List;@Service
public class ProductServiceImpl implements ProductService {@AutowiredProductDao productDao;@Override@Transactionalpublic void createProduct( ProductInfo productInfo ) {ProductDescript productDescript = new ProductDescript();//设置商品描述信息productDescript.setDescript(productInfo.getDescript());//调用dao 向商品信息表productDao.insertProductInfo(productInfo);//将商品信息id设置到 productDescript
// productDescript.setId(productInfo.getProductInfoId()); //errorproductDescript.setProductInfoId(productInfo.getProductInfoId());//设置店铺idproductDescript.setStoreInfoId(productInfo.getStoreInfoId());//向商品描述信息表插入数据productDao.insertProductDescript(productDescript);}@Overridepublic List<ProductInfo> queryProduct( int page, int pageSize ) {int start = (page - 1) * pageSize;return productDao.selectProductList(start, pageSize);}
}3、在 shopping 子工程(子模块)中,修改 测试类 ShardingTest.java 添加查询方法。
/*** dbsharding\shopping\src\test\java\djh\it\shopping\ShardingTest.java** 2024-7-3 创建 测试类 ShardingTest.java*/
package djh.it.shopping;import djh.it.shopping.entity.ProductInfo;
import djh.it.shopping.service.ProductService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.math.BigDecimal;
import java.util.List;@RunWith(SpringRunner.class)
@SpringBootTest(classes = ShoppingBootstrap.class)
public class ShardingTest {@AutowiredProductService productService;@Test //添加商品public void testCreateProduct(){for(int i=1; i<10; i++){ProductInfo productInfo = new ProductInfo();//productInfo.setStoreInfoId(1L); //店铺id(向 product_db_2 中插入数据)productInfo.setStoreInfoId(2L); //店铺id(向 product_db_1 中插入数据)productInfo.setProductName("Java编程思想"); //商品名称productInfo.setSpec("大号"); //商品规格productInfo.setPrice(new BigDecimal(60)); //商品价格productInfo.setRegionCode("110100"); //商品产地productInfo.setDescript("《java编程思想》这本书不错!!!"); //商品描述productService.createProduct(productInfo);}}@Test //查询商品public void testQueryProduct(){List<ProductInfo> productInfos = productService.queryProduct(1, 10);System.out.println(productInfos);}
}4、在 shopping 子工程(子模块)中,修改 application.properties 配置文件,完善绑定表。
# dbsharding\shopping\src\main\resources\application.propertiesserver.port = 56082spring.application.name = shopping
spring.profiles.active = localserver.servlet.context-path = /shopping
spring.http.encoding.enabled = true
spring.http.encoding.charset = utf-8
spring.http.encoding.force = truespring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true# sharding-jdbc 分片规则配置:# 1)配置数据源:真实数据源定义 m为主库,s为从库。m0, m1, m2, s0, s1, s2
spring.shardingsphere.datasource.names = m0,m1,m2,s0,s1,s2
#spring.shardingsphere.datasource.names = m0,m1,m2spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/store_db?useUnicode=true
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = 12311spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/product_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12311spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/product_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 12311spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url = jdbc:mysql://localhost:3307/store_db?useUnicode=true
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = 12311spring.shardingsphere.datasource.s1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s1.url = jdbc:mysql://localhost:3307/product_db_1?useUnicode=true
spring.shardingsphere.datasource.s1.username = root
spring.shardingsphere.datasource.s1.password = 12311spring.shardingsphere.datasource.s2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s2.url = jdbc:mysql://localhost:3307/product_db_2?useUnicode=true
spring.shardingsphere.datasource.s2.username = root
spring.shardingsphere.datasource.s2.password = 12311# 2)配置主、从关系数据库:
# 主库从库逻辑数据源定义 ds0为store_db ds1为product_db_1 ds2为product_db_2
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=m1
spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=s1
spring.shardingsphere.sharding.master-slave-rules.ds2.master-data-source-name=m2
spring.shardingsphere.sharding.master-slave-rules.ds2.slave-data-source-names=s2# 3)配置 分库策略(水平分库):
# 默认分库策略,以store_info_id为分片键,分片策略为store_info_id % 2 + 1,也就是store_info_id为双数的数据进入ds1, 为单数的进入ds2
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = store_info_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{store_info_id % 2 + 1}# 4)配置 分表策略(水平分表)
# 4.1) store_info 分表策略,固定分配至ds0的store_info真实表
spring.shardingsphere.sharding.tables.store_info.actual-data-nodes = ds$->{0}.store_info
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.algorithm-expression = store_info# 4.2) product_info 分表策略
# 数据结点包括:ds1.product_info_1, ds1.product_info_2, ds2.product_info_1, ds2.product_info_2 四个节点。
spring.shardingsphere.sharding.tables.product_info.actual-data-nodes = ds$->{1..2}.product_info_$->{1..2}
# 分片策略(水平分表):分片策略为product_info_id % 2 + 1
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.algorithm-expression = product_info_$->{product_info_id % 2 + 1}
# 主键策略(product_info_id 生成为雪花算法,为双数的数据进入 product_info_1表,为单数的进入 product_info_2表)
spring.shardingsphere.sharding.tables.product_info.key-generator.column = product_info_id
spring.shardingsphere.sharding.tables.product_info.key-generator.type = SNOWFLAKE# 4.3) product descript 分表策略
# 分布在 ds1,ds2 的 product_descript_1 product_descript_2表,分片策略为 product_info_id % 2 + 1,
# id 生成为雪花算法, product_info_id 为双数的数据进入 product_descript_1表,为单数的进入 product_descript_2表
spring.shardingsphere.sharding.tables.product_descript.actual-data-nodes = ds$->{1..2}.product_descript_$->{1..2}
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.sharding-column =product_info_id
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.algorithm-expression = product_descript_$->{product_info_id % 2 + 1}
spring.shardingsphere.sharding.tables.product_descript.key-generator.column=id
spring.shardingsphere.sharding.tables.product_descript.key-generator.type=SNOWFLAKE# 5)设置 product_info,product_descript为绑定表
#spring.shardingsphere.sharding.binding-tables = product_info,product_descript
# 修改绑定表(以数组方式显示)
spring.shardingsphere.sharding.binding-tables[0] = product_info,product_descript# 6)设置region为广播表(公共表),每次更新操作会发送至所有数据源
spring.shardingsphere.sharding.broadcast-tables=region# 7)打开 sql 输出日志
spring.shardingsphere.props.sql.show = trueswagger.enable = truelogging.level.root = info
logging.level.org.springframework.web = info
logging.level.djh.it.dbsharding = debug
logging.level.druid.sql = debug5、在 shopping 子工程(子模块)中, 测试类 ShardingTest.java 打断点,进行查询方法测试。

6、注意事项:
1)绑定表配置注意事项
# 5)设置 product_info,product_descript为绑定表
#spring.shardingsphere.sharding.binding-tables = product_info,product_descript
# 修改绑定表(以数组方式显示)
spring.shardingsphere.sharding.binding-tables[0] = product_info,product_descript
2)分页查询是业务中最常见的场景
-
Sharding:jdbc 支持常用关系数据库的分页查询,不过 Sharding-jdbc 的分页功能比较容易让使用者误解,用户通常认为分页归并会占用大量内存。
-
在分布式的场景中,将 LIMIT 1088880010 改写为 LIMIT 8,10000010,才能保证其数据的正确性。
-
用户非常容易产生 Shardingsphere 会将大量无意义的数据加载至内存中,造成内存溢出风险的错觉。
-
其实大部分情况都通过流式归并获取数据结果集,因此 ShardingSphere 会通过结果集的 next 方法将无需取出的数据全部跳过,并不会将其存入内存。
3)排序功能注意事项
-
同时需要注意的是,由于排序的需要,大量的数据仍然需要传输到 Sharding-Jdbc 的内存空间。 因此,采用LIMIT这种方式分页,并非最佳实践。
-
由于 LIMIT 并不能通过索引查询数据,因此如果可以保证 ID 的连续性,通过 ID 进行分页是比较好的解决方案,例如:
SELECT *FROM t_order WHERE id >100000 AND id<= 100010 ORDER BY id;
- 或通过记录上次查询结果的最后一条记录的ID进行下一页的查询,例如:
SELECT *FROM t_order WHERE id >10000000 LIMIT 10;
-
排序功能是由 Sharding-jdbc 的排序归并来完成,由于在 SQL 中存在 ORDER BY 语句,因此每个数据结果集自身是有序的,因此只需要将数据结果集当前游标指向的数据值进行排序即可。
-
这相当于对多个有序的数组进行排序,归并排序是最适合此场景的排序算法。
三、Sharding-JDBC 综合案例-统计商品
1、在 shopping 子工程(子模块)中,修改 dao 接口类 ProductDao.java 添加统计方法。
/*** dbsharding\shopping\src\main\java\djh\it\shopping\dao\ProductDao.java** 2024-7-3 创建 dao 接口类 ProductDao.java*/
package djh.it.shopping.dao;import djh.it.shopping.entity.ProductDescript;
import djh.it.shopping.entity.ProductInfo;
import org.apache.ibatis.annotations.*;
import org.springframework.stereotype.Component;import java.util.List;
import java.util.Map;@Mapper
@Component
public interface ProductDao {//添加商品基本信息@Insert("insert into product_info(store_info_id, product_name, spec, region_code, price) " +" values(#{storeInfoId},#{productName},#{spec},#{regionCode},#{price})")@Options(useGeneratedKeys = true, keyProperty = "productInfoId", keyColumn = "product_info_id")int insertProductInfo( ProductInfo productInfo );//添加商品描述信息@Insert("insert into product_descript(product_info_id, descript, store_info_id) " +" values(#{productInfoId}, #{descript}, #{storeInfoId})")@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")int insertProductDescript( ProductDescript productDescript );//查询商品@Select("select i.*, d.descript, r.region_name placeOfOrigin " +"from product_info i join product_descript d on i.product_info_id = d.product_info_id " +"join region r on i.region_code = r.region_code order by i.product_info_id desc limit #{start}, #{pageSize}")List<ProductInfo> selectProductList( @Param("start") int start, @Param("pageSize") int pageSize);//统计商品总数@Select("select count(1) from product_info")int selectCount();//商品分组统计@Select("select t.region_code, count(1) as num from product_info t group by t.region_code having num > 1 order by region_code")List<Map> selectProductGroupList();
}2、在 shopping 子工程(子模块)中,修改 测试类 ShardingTest.java 添加统计方法。
/*** dbsharding\shopping\src\test\java\djh\it\shopping\ShardingTest.java** 2024-7-3 创建 测试类 ShardingTest.java*/
package djh.it.shopping;import djh.it.shopping.dao.ProductDao;
import djh.it.shopping.entity.ProductInfo;
import djh.it.shopping.service.ProductService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.math.BigDecimal;
import java.util.List;
import java.util.Map;@RunWith(SpringRunner.class)
@SpringBootTest(classes = ShoppingBootstrap.class)
public class ShardingTest {@AutowiredProductService productService;@AutowiredProductDao productDao;@Test //添加商品public void testCreateProduct(){for(int i=1; i<10; i++){ProductInfo productInfo = new ProductInfo();//productInfo.setStoreInfoId(1L); //店铺id(向 product_db_2 中插入数据)productInfo.setStoreInfoId(2L); //店铺id(向 product_db_1 中插入数据)productInfo.setProductName("Java编程思想"); //商品名称productInfo.setSpec("大号"); //商品规格productInfo.setPrice(new BigDecimal(60)); //商品价格productInfo.setRegionCode("110100"); //商品产地productInfo.setDescript("《java编程思想》这本书不错!!!"); //商品描述productService.createProduct(productInfo);}}@Test //查询商品public void testQueryProduct(){List<ProductInfo> productInfos = productService.queryProduct(1, 10);System.out.println(productInfos);}@Test //统计商品总数public void testSelectCount(){int i = productDao.selectCount();System.out.println(i);}@Test //分组统计商品public void testSelectProductGroupList(){List<Map> maps = productDao.selectProductGroupList();System.out.println(maps);}}3、在 shopping 子工程(子模块)中, 运行 测试类 ShardingTest.java 进行统计商品方法测试。
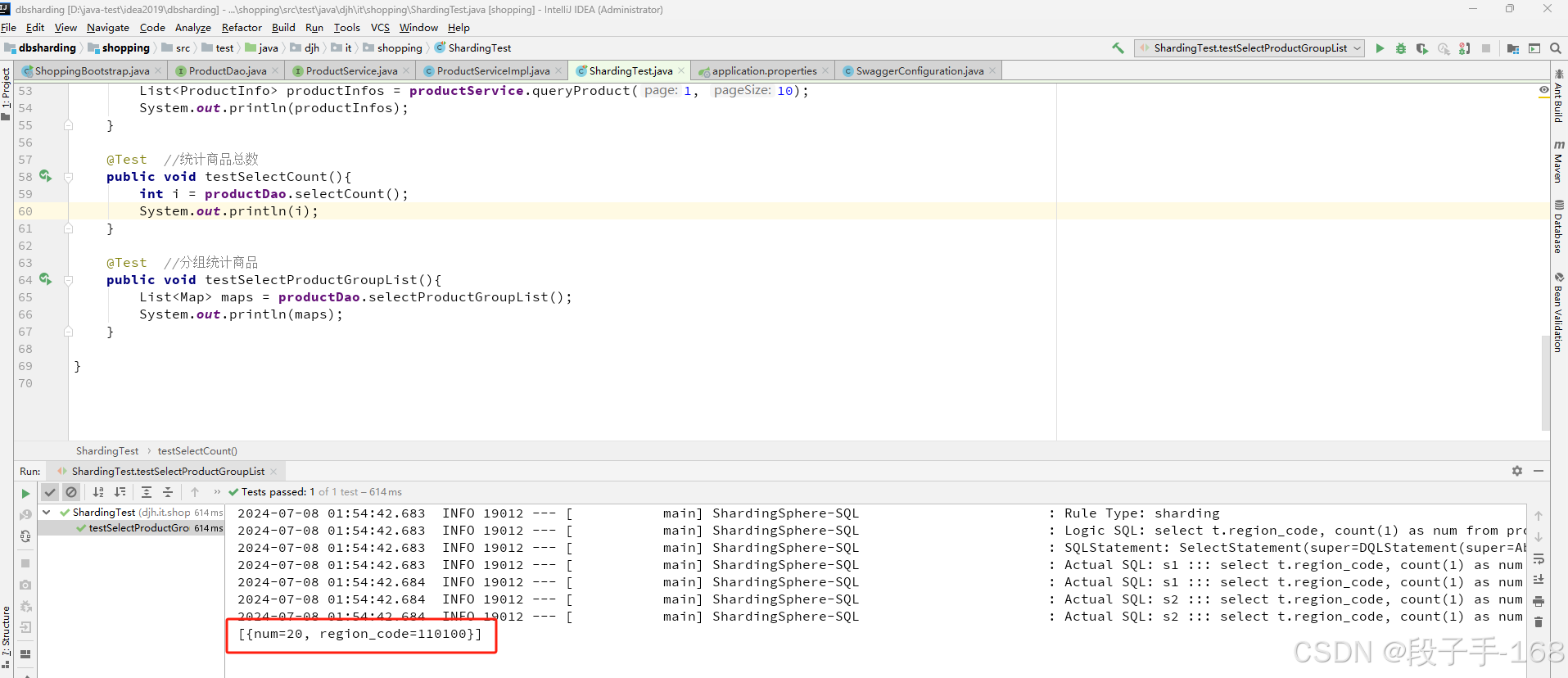
4、综合案例-统计商品 总结:
- 1)分组统计
分组统计也是业务中常见的场景,分组功能的实现由Sharding-jdbc分组归并完成。分组归并的情况最为复杂,它分为流式分组归并和内存分组归并。流式分组归并要求SQL的排序项与分组项的字段必须保持一致,否则只能通过内存归并才能保证其数据的正确性。
- 2)举例说明,假设根据科目分片,表结构中包含考生的姓名(为了简单起见,不考虑重名的情况)和分数。通过SQL获取每位考生的总分,可通过如下 SOL:
SELECT name, SuM(score)FROM t score GROup BY name ORDER BY name;
- 3)在分组项与排序项完全一致的情况下,取得的数据是连续的,分组所需的数据全数存在于各个数据结果集的当前游标所指向的数据值,因此可以采用流式归并。
四、Sharding-JDBC 总结
1、为什么分库分表?
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
2、分库分表方式:
垂直分表、垂直分库、水平分库、水平分表。
3、分库分表带来问题:
由于数据分散在多个数据库,服务器导致了事务一致性问题、跨节点 join 问题、跨节点分页排序、函数,主键需要全局唯一,公共表。
4、Sharding-JDBC 基础概念:
逻辑表,真实表,数据节点,绑定表,广播表,分片键,分片算法,分片策略,主键生成策略。
5、Sharding-JDBC 核心功能:
数据分片,读写分离。
6、Sharding-JDBC 执行流程:
SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并。
7、Sharding-JDBC 最佳实践:
系统在设计之初就应该对业务数据的耦合松紧进行考量,从而进行垂直分库、垂直分表,使数据层架构清晰明了。若非必要,无需进行水平切分,,应先从缓存技术着手降低对数据库的访问压力。如果缓存使用过后,数据库访问量还是非常大,可以考虑数据库读、写分离原则。若当前数据库压力依然大,且业务数据持续增长无法估量最后可考虑水平分库、分表,单表拆分数据控制在1000万以内。
8、Sharding-JDBC 对 SQL 支持说明 详细参考:
https://shardingsphere.apache.org/document/current/cn/features/sharding/appendix/
SgardubgSogere 概览:
https://shardingsphere.apache.org/document/current/cn/overview/
上一节关联链接请点击
# Sharding-JDBC 从入门到精通(9)- 综合案例(二)添加商品
相关文章:
# Sharding-JDBC 从入门到精通(10)- 综合案例(三)查询商品与测试及统计商品和总结
Sharding-JDBC 从入门到精通(10)- 综合案例(三)查询商品与测试及统计商品和总结 一、Sharding-JDBC 综合案例-查询商品-dao 1、查询商品:Dao 实现:在 ProductDao 中定义商品查询方法: //查询商…...

ASRock Creator系列GPU:为AI推理及多GPU系统打造,采用16针电源接口的Radeon RX 7900系列显卡
ASRock 正在筹备推出专为人工智能推理和多GPU系统设计的AMD GPU——Creator系列显卡。这一系列显卡采用双槽位、吹风式设计,并配备16针电源连接器,首发产品包括基于Navi 31架构的AMD Radeon RX 7900XTX和RX 7900 XT型号。这些原属于WS系列的显卡最初在20…...
AntV X6 图编辑引擎速通
前言:参考 [AntV X6 官网](https://x6.antv.antgroup.com/) 一、简介 X6 可以快速搭建 DAG 图、ER 图、流程图、血缘图等应用。 二、快速上手 1. 安装 npm install antv/x6 --save# oryarn add antv/x6# orpnpm add antv/x6 2. 使用 2.1 初始画布 在页面中创…...

【若依前后端分离】通过输入用户编号自动带出部门名称(部门树)
一、部门树 使用 <treeselect v-model"form.deptId" :options"deptOptions" :show-count"true" placeholder"请选择归属部门"/> <el-col :span"12"><el-form-item label"归属部门" prop"dept…...

AIGC时代程序员的跃迁——编程高手的密码武器
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

园区智慧能源可视化:智能监控与优化能源管理
通过图扑可视化技术,搭建智慧光伏园区,实时监控园区光伏系统的运行状态,分析数据并优化能源管理,提高发电效率和维护效率,助力园区实现绿色可持续发展。...
Linux内网端口转公网端口映射
由于服务商做安全演练,把原先服务器内网的端口映射到外网端口全都关闭了,每次维护服务器特别麻烦,像数据库查询如果用原生的mysql 去连接,查询返回的结果乱了,非常不方便。 查了服务还是可以正常访问部分外网的&#x…...
安装和编译指定的python3版本)
银河麒麟高级服务器操作系统(通用)安装和编译指定的python3版本
银河麒麟高级服务器操作系统(通用)安装和编译指定的python3版本 一 系统环境二 安装python3.12.42.1 安装编译需要的依赖包2.2 下载官网目前最新的python源码包2.3 解压Python-3.12.4.tar.xz2.4 配置python-3.12.42.5 编译安装2.6 配置环境变量使其生效2…...

cs231n 作业3
使用普通RNN进行图像标注 单个RNN神经元行为 前向传播: 反向传播: def rnn_step_backward(dnext_h, cache):dx, dprev_h, dWx, dWh, db None, None, None, None, Nonex, Wx, Wh, prev_h, next_h cachedtanh 1 - next_h**2dx (dnext_h*dtanh).dot(…...
HarmonyOS Next系列之Echarts图表组件(折线图、柱状图、饼图等)实现(八)
系列文章目录 HarmonyOS Next 系列之省市区弹窗选择器实现(一) HarmonyOS Next 系列之验证码输入组件实现(二) HarmonyOS Next 系列之底部标签栏TabBar实现(三) HarmonyOS Next 系列之HTTP请求封装和Token…...

网上怎么样可以挣钱,分享几种可以让你在家赚钱的兼职项目
当今社会,压力越来越大,工作、家庭、生活等等,方方面面都需要钱,仅靠一份工作赚钱,已经很难满足我们的需求。所以很多人都会尝试做一些副业,兼职来补贴家用。 现在呢,有很多人都想在网上赚钱&am…...
)
【DevOps】运维过程中经常遇到的Http错误码问题分析(二)
目录 一、HTTP 错误400 Bad Request 1、理解 400 Bad Request 错误 2、排查 400 Bad Request 错误 3、常见的解决方法 二、HTTP 错误401 Unauthorized 1、理解 401 Unauthorized 错误 2、排查 401 Unauthorized 错误 3、常见的解决方法 一、HTTP 错误400 Bad Request …...
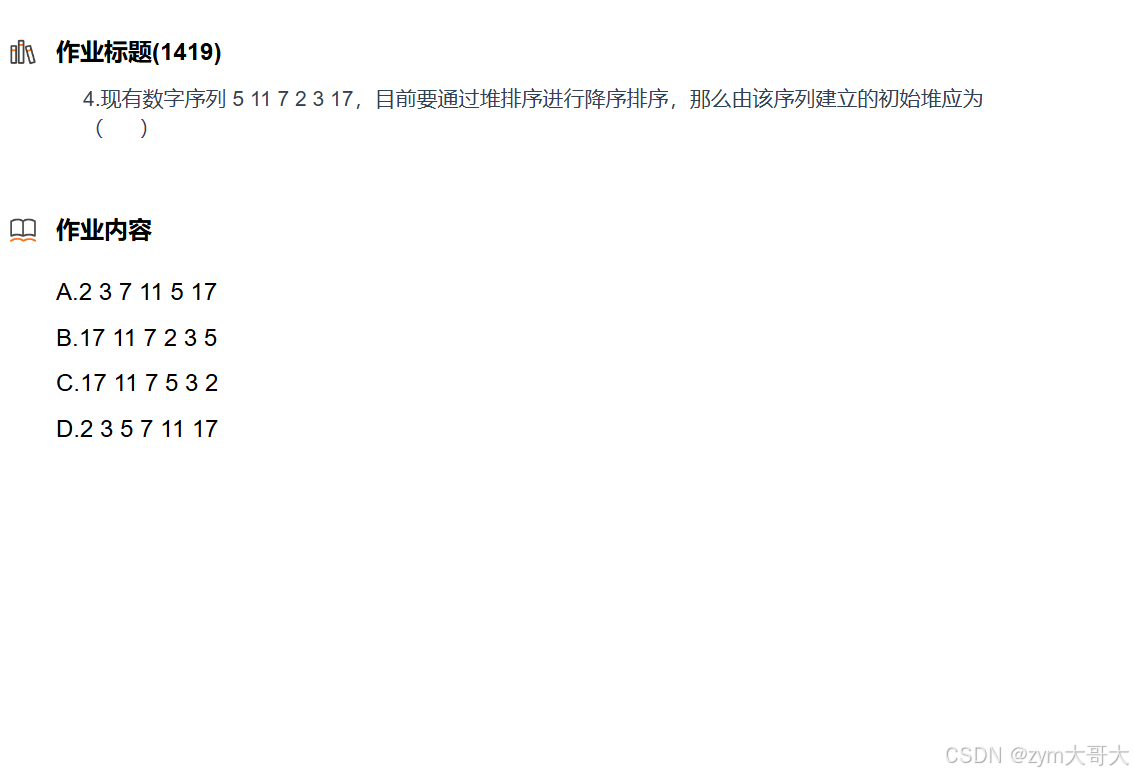
数据结构练习
1. 快速排序的非递归是通过栈来实现的,则前序与层次可以通过控制入栈的顺序来实现,因为递归是会一直开辟栈区空间,所以非递归的实现只需要一个栈的大小,而这个大小是小于递归所要的, 非递归与递归的时间复杂度是一样的…...

手动安装Ruby 1.9.3并升级RubyGems
手动安装Ruby 1.9.3并升级RubyGems ###Ruby 1.9.3 p125安装 wget http://ftp.ruby-lang.org/pub/ruby/1.9/ruby-1.9.3-p125.tar.gz \ && tar -xzvf ruby-1.9.3-p125.tar.gz \ && cd ruby-1.9.3-p125 \ && ./configure --with-openssl-dir/usr/lib/op…...

go语言day11 错误 defer(),panic(),recover()
错误: 创建错误 1)fmt包下提供的方法 fmt.Errorf(" 格式化字符串信息 " , 空接口类型对象 ) 2)errors包下提供的方法 errors.New(" 字符串信息 ") 创建自定义错误 需要实现error接口,而error接口…...

构建docker镜像实战
构建docker镜像 构建基础容器镜像(Base Image)是创建容器化应用程序的第一步。基础镜像提供了一个最低限度的操作系统环境,您可以在其上安装所需的软件包和应用程序。 Dockerfile语法说明 Dockerfile 是 Docker 构建镜像的描述文件&#x…...

生信算法9 - 正则表达式匹配氨基酸序列、核型和字符串
建议在Jupyter实践。 1. 使用正则表达式匹配指定的氨基酸序列 import re# 氨基酸序列 seq VSVLTMFRYAGWLDRLYMLVGTQLAAIIHGVALPLMMLI# 正则表达式匹配 match re.search(r[A|G]W, seq)# 打印match及匹配到开始位置和结束位置 print(match) # <re.Match object; span(10, …...

linux ext2文件系统浅析
文章目录 前言ext2内容概述实验准备二进制对比分析1 super block2 group desc3 block bitmap4 inode bitmap5 inode_tableinode 1inode 2inode 11inode 12 6 dir entry7 data区8 间接块9 块组 前言 网上关于ext2文件系统的博客有很多,但看完之后还是有些云里雾里&a…...

「树莓派入门」树莓派进阶02-传感器应用与交通灯项目
传感器是树莓派实现智能化的关键。通过本教程,你可以开始尝试使用传感器来增强树莓派的功能。 一、传感器在树莓派中的作用 传感器是树莓派与外界环境交互的重要工具。它们可以检测各种物理量,如光、声音、温度等,并将这些物理量转换为电信号,供树莓派读取和处理。 二、数…...

pytorch 指定GPU设备
使用os.environ["CUDA_VISIBLE_DEVICES"] 这种方法是通过环境变量限制可见的CUDA设备,从而在多个GPU的机器上只让PyTorch看到并使用指定的GPU。这种方式的好处是所有后续的CUDA调用都会使用这个GPU,并且代码中不需要显式地指定设备索引。 im…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

国产麒麟系统上编译GDAL 3.2.1踩坑记:从PROJ6依赖缺失到Qt环境集成
麒麟系统GDAL 3.2.1编译实战:PROJ6依赖修复与Qt工程深度集成在国产操作系统生态中部署地理数据处理工具链,往往会遇到比常规Linux发行版更复杂的依赖问题。最近在麒麟系统上为北斗定位项目编译GDAL 3.2.1时,遭遇了经典的"PROJ 6 symbols…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...