Qwen1.5-1.8b部署
仿照ChatGLM3部署,参考了Qwen模型的文档,模型地址https://modelscope.cn/models/qwen/Qwen1.5-1.8B-Chat/summary
http接口
- 服务端代码
api.py
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import uvicorn
import json
import datetime
import torch# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/qwen/Qwen1.5-1.8B-Chat'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16)# 清理GPU内存函数
def torch_gc():if torch.cuda.is_available(): # 检查是否可用CUDAwith torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备torch.cuda.empty_cache() # 清空CUDA缓存torch.cuda.ipc_collect() # 收集CUDA内存碎片# 创建FastAPI应用
app = FastAPI()# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器json_post_raw = await request.json() # 获取POST请求的JSON数据json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串json_post_list = json.loads(json_post) # 将字符串转换为Python对象prompt = json_post_list.get('prompt') # 获取请求中的提示messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}]# 调用模型进行对话生成input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]now = datetime.datetime.now() # 获取当前时间time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串# 构建响应JSONanswer = {"response": response,"status": 200,"time": time}# 构建日志信息log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'print(log) # 打印日志torch_gc() # 执行GPU内存清理return answer # 返回响应# 主函数入口
if __name__ == '__main__':# 启动FastAPI应用# 用6006端口可以将autodl的端口映射到本地,从而在本地使用apiuvicorn.run("api:app", host='127.0.0.1', port=6006, workers=2) # 在指定端口和主机上启动应用# gunicorn api:app -w 3 -k uvicorn.workers.UvicornWorker -b 127.0.0.1:6006
- 客户端代码
clientapi.py
import requests
import jsondef get_completion(prompt):headers = {'Content-Type': 'application/json'}data = {"prompt": prompt}response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))return response.json()['response']if __name__ == '__main__':print(get_completion('你可以记录之前说过的内容吗'))
- 压测代码
locusthttp.py,运行locust -f locusthttp.py(有UI),使用vmstat或top查看进程、内存、CPU等情况。
import jsonfrom locust import HttpUser, TaskSet, task# 定义用户行为
class UserBehavior(TaskSet):# 任一测试用例执行前均会执行一次def on_start(self):print('开始性能测试')# 表示一个用户为行,访问百度首页。使用 @task装饰该方法为一个事务。client.get()用于指请求的路径“ / ”,因为是百度首页,所以指定为根路径。@task(1)def index(self):self.client.get("/")@task(2) # task()参数用于指定该行为的执行权重。参数越大每次被虚拟用户执行的概率越高。如果不设置默认为1。def index2(self):headers = {'Content-Type': 'application/json'}data = {'prompt': '你知道珠穆朗玛峰吗'}self.client.post(url='/index2', headers=headers, data=json.dumps(data))@task(2) # task()参数用于指定该行为的执行权重。参数越大每次被虚拟用户执行的概率越高。如果不设置默认为1。def index3(self):headers = {'Content-Type': 'application/json'}data = {'prompt': '你是谁'}self.client.post(url='/index3', headers=headers, data=json.dumps(data))@task(2) # task()参数用于指定该行为的执行权重。参数越大每次被虚拟用户执行的概率越高。如果不设置默认为1。def index4(self):headers = {'Content-Type': 'application/json'}data = {'prompt': '西红柿炒番茄怎么做'}self.client.post(url='/index4', headers=headers, data=json.dumps(data))# 用于设置性能测试
class WebsiteUser(HttpUser):# 指向一个定义的用户行为类。tasks = [UserBehavior]# 执行事务之间用户等待时间的下界(单位:毫秒)。如果TaskSet类中有覆盖,以TaskSet 中的定义为准。min_wait = 3000# 执行事务之间用户等待时间的上界(单位:毫秒)。如果TaskSet类中有覆盖,以TaskSet中的定义为准。max_wait = 6000# 设置 Locust 多少秒后超时,如果为 None ,则不会超时。stop_timeout = 5# 一个Locust实例被挑选执行的权重,数值越大,执行频率越高。在一个 locustfile.py 文件中可以同时定义多个 HttpUser 子类,然后分配他们的执行权重weight = 3# 脚本指定host执行测试时则不在需要指定host = "http://127.0.0.1:6006"
WebSocket长连接
- 服务端代码
websocketapi.py
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from fastapi.middleware.cors import CORSMiddleware
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import uvicorn
import torchpretrained = "/root/autodl-tmp/qwen/Qwen1.5-1.8B-Chat"
tokenizer = AutoTokenizer.from_pretrained(pretrained, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(pretrained, device_map="auto", torch_dtype=torch.bfloat16)
model = model.eval()
app = FastAPI()app.add_middleware(CORSMiddleware
)with open('websocket_demo.html') as f:html = f.read()@app.get("/")
async def get():return HTMLResponse(html)@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):"""input: JSON String of {"prompt": ""}output: JSON String of {"response": "", "status": 200}status 200 stand for response ended, else not"""await websocket.accept()try:while True:json_request = await websocket.receive_json()prompt = json_request['prompt']messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}]input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]await websocket.send_json({"response": response,"status": 202,})await websocket.send_json({"status": 200})except WebSocketDisconnect:passdef main():uvicorn.run(f"{__name__}:app", host='127.0.0.1', port=6006, workers=2)if __name__ == '__main__':main()# gunicorn websocket_api_qwen:app -w 3 -k uvicorn.workers.UvicornWorker -b 127.0.0.1:6006
- 前端代码
websocket.html
<!DOCTYPE html>
<html lang="en">
<head><title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="return false;" id="form"><label for="messageText"></label><input type="text" id="messageText" autocomplete="off"/><button type="submit">Send</button>
</form>
<ul id='messageBox'>
</ul>
<script>let ws = new WebSocket("ws://" + location.host + "/ws");let history = [];let last_message_element = null;function appendMessage(text, sender, dom = null) {if (dom === null) {let messageBox = document.getElementById('messageBox');dom = document.createElement('li');messageBox.appendChild(dom);}dom.innerText = sender + ':' + text;return dom}function sendMessage(event) {if (last_message_element !== null) { // 如果机器人还没回复完return;}let input = document.getElementById("messageText");if (input.value === "") {return;}let body = {"prompt": input.value};ws.send(JSON.stringify(body));appendMessage(input.value, '用户')input.value = '';event.preventDefault();}document.getElementById("form").addEventListener('submit', sendMessage)ws.onmessage = function (event) {let body = JSON.parse(event.data);let status = body['status']if (status === 200) { // 如果回答结束了last_message_element = null;} else {history = body['history']last_message_element = appendMessage(body['response'], 'Qwen1.5-1.8B-chat', last_message_element)}};
</script>
</body>
</html>
- 运行结果

- 压测代码
locustwebsocket.py
import json
import timeimport websocket
from locust import User, TaskSet, task, events
import randomclass WebSocketClient(object):def __init__(self, host):self.host = hostself.ws = websocket.WebSocket()def connect(self, burl):start_time = time.time()try:self.conn = self.ws.connect(url=burl)except websocket.WebSocketTimeoutException as e:total_time = int((time.time() - start_time) * 1000)events.request_failure.fire(request_type="websocket", name='urllib', response_time=total_time, exception=e)else:total_time = int((time.time() - start_time) * 1000)events.request_success.fire(request_type="websocket", name='urllib', response_time=total_time, response_length=0)return self.conndef recv(self):return self.ws.recv()def send(self, msg):self.ws.send(msg)class WebsocketLocust(User):def __init__(self, *args, **kwargs):super(WebsocketLocust, self).__init__(*args, **kwargs)self.client = WebSocketClient(self.host)class SupperDianCan(TaskSet):@taskdef test(self):self.url = 'http://127.0.0.1:6006'self.data = {}self.client.connect(self.url)while True:recv = self.client.recv()print(recv)if eval(recv)['type'] == 'keepalive':self.client.send(recv)else:self.client.send(self.data)
class WebsocketUser(TaskSet):host = "http://127.0.0.1:6006"client = Nonedef on_start(self):self.client = WebSocketClient("ws://127.0.0.1:6006/ws")self.client.connect()@taskdef send_message(self):# 发送的订阅请求num = random.randint(0, 10)prompt = f"世界上第{num}高的山峰是什么"self.client.send(json.dumps({'prompt': prompt}))response = self.client.recv()print(json.loads(response))class WebsiteUser(User):tasks = [WebsocketUser]min_wait = 3000max_wait = 6000stop_timeout = 5
相关文章:
Qwen1.5-1.8b部署
仿照ChatGLM3部署,参考了Qwen模型的文档,模型地址https://modelscope.cn/models/qwen/Qwen1.5-1.8B-Chat/summary http接口 服务端代码api.py from fastapi import FastAPI, Request from transformers import AutoTokenizer, AutoModelForCausalLM, …...

关于7月1号centos官方停止维护7系列版本导致centos7+版本的机器yum等命令无法使用的解决教程
更换yum源两种方式 第一种 在还能使用yum等命令的情况是执行下面的命令 注意:阿里云和腾讯云二选一即可 一丶 yum源 腾讯云: wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.cloud.tencent.com/repo/centos7_base.repo curl -o /etc/yum.…...

2024人工智能大会_强化学习论坛相关记录
求解大规模数学优化问题 规划也称为优化 四要素:数据、变量、目标、约束 将一个简单的数学规划问题项gpt进行提问,GPT给了一个近似解,但不是确切的解。 大模型的训练本身就是一个优化问题。 大模型是如何训练的?大模型训练通常使…...
)
Android SurfaceFlinger——创建EGLContext(二十五)
前面文章我们获取了 EGL 的最优配置,创建了 EGLSurface 并与 Surface 进行了关联,然后还需要获取 OpenGL ES 的上下文 Context,这也是 EGL 控制接口的三要素(Displays、Contexts 和 Surfaces)之一。 1)getInternalDisplayToken:获取显示屏的 SurfaceControl 令牌(Token…...

python 10个自动化脚本
目录 🌟 引言 📚 理论基础 🛠️ 使用场景与代码示例 场景一:批量重命名文件 场景二:自动下载网页内容 场景三:数据清洗 场景四:定时执行任务 场景五:自动化邮件发送 场景六…...
填报高考志愿,怎样正确地选择大学专业?
大学专业的选择,会关系到未来几年甚至一辈子的发展方向。这也是为什么很多人结束高考之后就开始愁眉苦脸,因为他们不知道应该如何选择大学专业,生怕一个错误的决定会影响自己一生。 毋庸置疑,在面对这种选择的时候,我…...

Java 使用sql查询mongodb
在现代应用开发中,关系型数据库和NoSQL数据库各有千秋。MongoDB作为一种流行的NoSQL数据库,以其灵活的文档模型和强大的扩展能力,受到广泛欢迎。然而,有时开发者可能更熟悉SQL查询语法,或者需要在现有系统中复用SQL查询…...
 同步互斥)
WIN32核心编程 - 线程操作(二) 同步互斥
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 竞态条件 CriticalSection Mutex CriticalSection & Mutex Semaphore Event 竞态条件 多线程环境下,当多个线程同时访问或者修改同一个数据时,最终结果为线程执…...

web自动化(六)unittest 四大组件实战(京东登录搜索加入购物车)
Unittest框架 Unittest框架:框架测试模块测试管理模块测试统计模块,python的内置模块 import unittest Unittest框架四大组件: 1、TestCase 测试用例 2.TestFixture 测试用例夹具 测试用例需要执行的前置和后置 3.TestSuite 测试套件 把需要执行的测试用例汇总在一…...

鸿蒙语言基础类库:【@ohos.process (获取进程相关的信息)】
获取进程相关的信息 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。…...

华为笔试题
文章目录 1、数的分解2、字符串判断子串 1、数的分解 给定一个正整数n,如果能够分解为m(m > 1)个连续正整数之和, 请输出所有分解中,m最小的分解。 如果给定整数无法分解为连续正整数,则输出字符串"N"。 输入描述&a…...
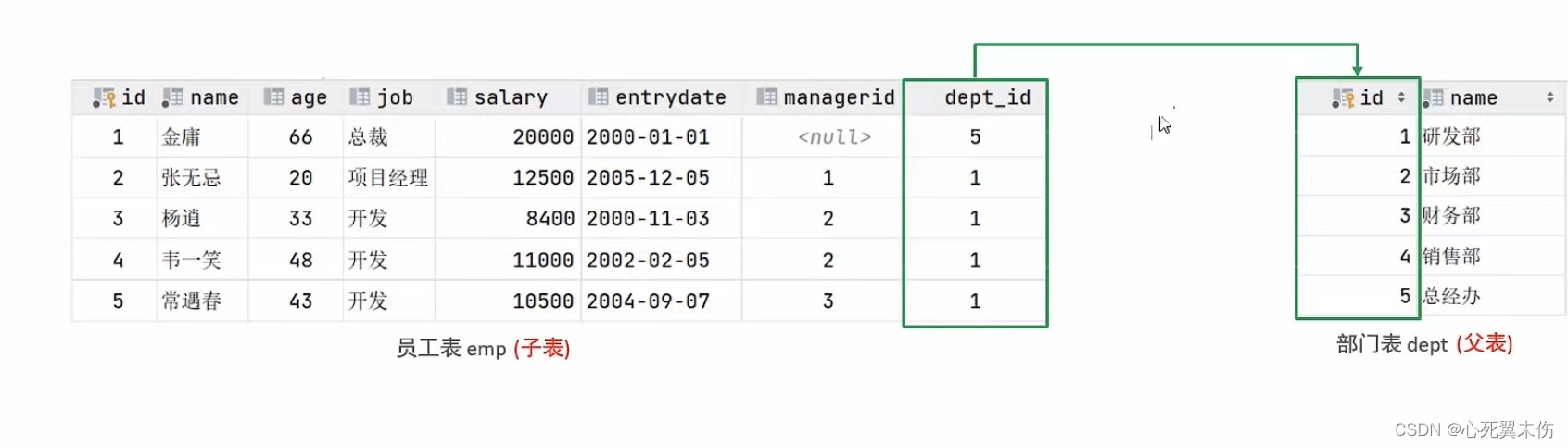
【MySQL基础篇】函数及约束
1、函数 函数是指一段可以直接被另一段程序程序调用的程序或代码。 函数 - 字符串函数 MySQL中内置了很多字符串函数,常用的几个如下: 函数功能CONCAT(S1,S2,...,Sn)字符串拼接,将S1,S2,...,Sn拼接成一个字符串LOWER(str)将字符串str全部…...

YOLOv9报错:AttributeError: ‘list‘ object has no attribute ‘view‘
报错信息如下: red_distri, pred_scores torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split( AttributeError: ‘list’ object has no attribute ‘view’ 解决方法: 去yolov9/utils/loss_tal.py把167行代码更改&#…...

Bert入门-使用BERT(transformers库)对推特灾难文本二分类
Kaggle入门竞赛-对推特灾难文本二分类 这个是二月份学习的,最近整理资料所以上传到博客备份一下 数据在这里:https://www.kaggle.com/competitions/nlp-getting-started/data github(jupyter notebook):https://gith…...

【DFS(深度优先搜索)详解】看这一篇就够啦
【DFS详解】看这一篇就够啦 🍃1. 算法思想🍃2. 三种枚举方式🍃2.1 指数型枚举🍃2.2 排列型枚举🍃2.3 组合型枚举 🍃3. 剪枝优化🍃4. 图的搜索🍃5. 来几道题试试手🍃5.1 选…...

java-spring boot光速入门教程(超详细!!)
目录 一、引言 1.1 初始化配置 1.2 整合第三方框架 1.3 后期维护 1.4 部署工程 1.5 敏捷式开发 二、SpringBoot介绍 spring boot 2.1 搭建一个spring boot工程 2.2 使用idea创建项目 2.3 在线创建姿势 2.4 项目的目录结构 2.5 项目的运行方式 2.6 yml文件格式 2…...

一、Prometheus和Grafana搭建
一、服务端Prometheus二进制安装 https://prometheus.io/下载过慢可使用迅雷下载 tar -zxvf prometheus-2.53.0.linux-amd64.tar.gz启动 ./prometheus --config.fileprometheus.yml将其配置为系统服务: vim /usr/lib/systemd/system/prometheus.service[Unit] D…...

从零开始的python学习生活
pycharm部分好用快捷键 变量名的定义 与之前学习过的语言有所不同的是,python中变量名的定义更加的简洁 such as 整形。浮点型和字符串的定义 money50 haha13.14 gaga"hello"字符串的定义依然是需要加上引号,也不需要写;了 字符…...

MSP学习
一、迁移资源调研 完成导入,类似完成选型分析 离线工具调研 账单 二、迁移计划 1、 ecs 确认开始构建迁移环境后,平台将锁定当前标记的迁移资源范围及源端、目标端资源配置信息,并以此为迁移环境构建及迁移实施的数据依据 目标账号…...

生产力工具|Endnote X9如何自动更新文件信息
一、以EndNote X9.2版本为例,打开EndNote文献管理软件。 二、在菜单栏找到“Edit→Preferences...”,点击打开,弹出一个“EndNote Preferences”窗口。 三、进行设置 在打开的窗口左侧选择“PDF Handing”,右边会出现自动导入文献…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹
Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹 在三维地理信息系统中,实时数据可视化一直是开发者面临的挑战之一。想象一下,当我们需要在地球表面追踪一架正在飞行的无人机,或者监控城市中数百辆出…...

基于ESP8266与RGBDigit的Wi-Fi网络时钟:硬件设计、物联网集成与DIY实践
1. 项目概述:一个能感知环境的网络时钟如果你和我一样,对复古又带点科技感的显示设备没有抵抗力,同时又是个喜欢动手折腾的极客,那么这个项目绝对能让你在工作室或家里多一个既实用又炫酷的玩意儿。我说的就是这款基于RGBDigit数码…...

5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南
5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了…...

通过Taotoken用量看板清晰追踪各模型的Token消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰追踪各模型的Token消耗情况 对于依赖大模型API进行开发的个人或团队而言,成本控制与预算规划…...

基于Shapley值与随机森林的印度CPI通胀预测与特征重要性分析
1. 项目概述与核心价值在宏观经济预测领域,通胀预测的准确性直接关系到货币政策制定、市场预期管理乃至社会民生稳定。传统的计量经济学模型,如基于菲利普斯曲线的线性回归,虽然具有良好的可解释性,但在捕捉现实世界中复杂、非线性…...