Bert入门-使用BERT(transformers库)对推特灾难文本二分类
Kaggle入门竞赛-对推特灾难文本二分类
这个是二月份学习的,最近整理资料所以上传到博客备份一下
数据在这里:https://www.kaggle.com/competitions/nlp-getting-started/data
github(jupyter notebook):https://github.com/ziggystardust-pop/bert-bi-classification.git
使用BERT(transformers库)对推特灾难文本二分类
xxx着火了(灾难)
火烧云像是燃烧的火焰(非灾难)
import os
import pandas
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
# 用于加载bert模型的分词器
from transformers import AutoTokenizer
# 用于加载bert模型
from transformers import AutoModel
from pathlib import Path
from tqdm.notebook import tqdmbatch_size = 16
# 文本的最大长度
text_max_length = 128
epochs = 100
# 取多少训练集的数据作为验证集
validation_ratio = 0.1
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 每多少步,打印一次loss
log_per_step = 50# 数据集所在位置
dataset_dir = Path("/kaggle/input/nlp-getting-started/")
os.makedirs(dataset_dir) if not os.path.exists(dataset_dir) else ''# 模型存储路径
model_dir = Path("/kaggle/working/")
# 如果模型目录不存在,则创建一个
os.makedirs(model_dir) if not os.path.exists(model_dir) else ''print("Device:", device)Device: cuda
数据处理
加载数据集,查看文本最大长度
pd_data = pandas.read_csv(dataset_dir / 'train.csv')
pd_data
| id | keyword | location | text | target | |
|---|---|---|---|---|---|
| 0 | 1 | NaN | NaN | Our Deeds are the Reason of this #earthquake M... | 1 |
| 1 | 4 | NaN | NaN | Forest fire near La Ronge Sask. Canada | 1 |
| 2 | 5 | NaN | NaN | All residents asked to 'shelter in place' are ... | 1 |
| 3 | 6 | NaN | NaN | 13,000 people receive #wildfires evacuation or... | 1 |
| 4 | 7 | NaN | NaN | Just got sent this photo from Ruby #Alaska as ... | 1 |
| ... | ... | ... | ... | ... | ... |
| 7608 | 10869 | NaN | NaN | Two giant cranes holding a bridge collapse int... | 1 |
| 7609 | 10870 | NaN | NaN | @aria_ahrary @TheTawniest The out of control w... | 1 |
| 7610 | 10871 | NaN | NaN | M1.94 [01:04 UTC]?5km S of Volcano Hawaii. htt... | 1 |
| 7611 | 10872 | NaN | NaN | Police investigating after an e-bike collided ... | 1 |
| 7612 | 10873 | NaN | NaN | The Latest: More Homes Razed by Northern Calif... | 1 |
7613 rows × 5 columns
pd_data = pandas.read_csv(dataset_dir / 'train.csv')[['text', 'target']]
pd_data
| text | target | |
|---|---|---|
| 0 | Our Deeds are the Reason of this #earthquake M... | 1 |
| 1 | Forest fire near La Ronge Sask. Canada | 1 |
| 2 | All residents asked to 'shelter in place' are ... | 1 |
| 3 | 13,000 people receive #wildfires evacuation or... | 1 |
| 4 | Just got sent this photo from Ruby #Alaska as ... | 1 |
| ... | ... | ... |
| 7608 | Two giant cranes holding a bridge collapse int... | 1 |
| 7609 | @aria_ahrary @TheTawniest The out of control w... | 1 |
| 7610 | M1.94 [01:04 UTC]?5km S of Volcano Hawaii. htt... | 1 |
| 7611 | Police investigating after an e-bike collided ... | 1 |
| 7612 | The Latest: More Homes Razed by Northern Calif... | 1 |
7613 rows × 2 columns
在使用BERT进行文本分类时,文本序列会被分段成较小的片段,每个片段的长度不能超过BERT模型的最大输入长度。BERT-base模型的最大输入长度为512个token。但是,实际上,通常不会使用整个512个token的长度,因为这会导致模型的计算和内存消耗过高,尤其是在GPU内存有限的情况下。
因此,为了在保持模型性能的同时有效利用计算资源,常见的做法是将文本序列截断或填充到一个较小的长度,通常是128或者256。在这个设置下,大多数文本序列都可以被完整地处理,而且不会导致过多的计算资源消耗。
选择128作为文本最大长度的原因可能是出于以下考虑:
大多数文本序列可以在128个token的长度内完整表示,因此不会丢失太多信息。
128是一个相对合理的长度,可以平衡模型性能和计算资源的消耗。
在实际应用中,较长的文本序列很少出现,因此选择128不会对大多数样本产生太大影响。
max_length = pd_data['text'].str.len().max()
print(max_length)
# 按ratio随机划分训练集和验证集
pd_validation_data = pd_data.sample(frac = validation_ratio)
pd_train_data = pd_data[~pd_data.index.isin(pd_validation_data.index)]
pd_train_data
"""
输出:157
"""
| text | target | |
|---|---|---|
| 0 | Our Deeds are the Reason of this #earthquake M... | 1 |
| 1 | Forest fire near La Ronge Sask. Canada | 1 |
| 2 | All residents asked to 'shelter in place' are ... | 1 |
| 4 | Just got sent this photo from Ruby #Alaska as ... | 1 |
| 5 | #RockyFire Update => California Hwy. 20 closed... | 1 |
| ... | ... | ... |
| 7607 | #stormchase Violent Record Breaking EF-5 El Re... | 1 |
| 7608 | Two giant cranes holding a bridge collapse int... | 1 |
| 7610 | M1.94 [01:04 UTC]?5km S of Volcano Hawaii. htt... | 1 |
| 7611 | Police investigating after an e-bike collided ... | 1 |
| 7612 | The Latest: More Homes Razed by Northern Calif... | 1 |
6852 rows × 2 columns
#定义数据类
class MyDataset(Dataset):def __init__(self,mode = 'train'):super(MyDataset,self).__init__()self.mode = modeif mode == 'train':self.dataset = pd_train_dataelif mode == 'validation':self.dataset = pd_validation_dataelif mode == 'test':# 如果是测试模式,则返回推文和id。拿id做target主要是方便后面写入结果。self.dataset = pandas.read_csv(dataset_dir / 'test.csv')[['text', 'id']]else:raise Exception("Unknown mode {}".format(mode))def __getitem__(self, index):# 取第index条data = self.dataset.iloc[index]# 取其推文,做个简单的数据清理source = data['text'].replace("#", "").replace("@", "")# 取对应的推文if self.mode == 'test':# 如果是test,将id做为targettarget = data['id']else:target = data['target']# 返回推文和targetreturn source, targetdef __len__(self):return len(self.dataset)
train_dataset = MyDataset('train')
validation_dataset = MyDataset('validation')
train_dataset.__getitem__(0)
"""
('Our Deeds are the Reason of this earthquake May ALLAH Forgive us all', 1)
"""
#使用分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokenizer("I'm learning deep learning", return_tensors='pt')"""
tokenizer_config.json: 0%| | 0.00/48.0 [00:00<?, ?B/s]
config.json: 0%| | 0.00/570 [00:00<?, ?B/s]
vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/466k [00:00<?, ?B/s]{'input_ids': tensor([[ 101, 1045, 1005, 1049, 4083, 2784, 4083, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
"""
下面这个collate_fn函数用于对一个batch的文本数据进行处理,将文本句子转换为tensor,并组成一个batch。下面是函数的具体功能和输入输出:
输入参数 batch:一个batch的句子,每个句子是一个元组,包含文本和目标标签,例如:[(‘推文1’, 目标1), (‘推文2’, 目标2), …]
输出:处理后的结果,包含两部分:
src:是要送给BERT模型的输入,包含两个tensor:
input_ids:经过分词和映射后的输入文本的token id序列。
attention_mask:用于指示BERT模型在进行自注意力机制时哪些部分是padding的,需要被忽略。1表示有效token,0表示padding。
target:目标标签的tensor序列,即对应每个文本的标签。
这个函数首先将输入的batch分成两个列表,一个是文本列表 text,一个是目标标签列表 target。然后使用 tokenizer 对文本进行分词、映射、padding和裁剪等预处理操作,得到模型的输入 src。最后将处理后的输入 src 和目标标签 target 组合成输出。
collate_fn函数在数据加载器每次取出一个batch的样本时被调用,用于对这个batch的样本进行预处理、转换成模型所需的格式。
def collate_fn(batch):"""将一个batch的文本句子转成tensor,并组成batch。:param batch: 一个batch的句子,例如: [('推文', target), ('推文', target), ...]:return: 处理后的结果,例如:src: {'input_ids': tensor([[ 101, ..., 102, 0, 0, ...], ...]), 'attention_mask': tensor([[1, ..., 1, 0, ...], ...])}target:[1, 1, 0, ...]"""text, target = zip(*batch)text, target = list(text), list(target)# src是要送给bert的,所以不需要特殊处理,直接用tokenizer的结果即可# padding='max_length' 不够长度的进行填充# truncation=True 长度过长的进行裁剪src = tokenizer(text, padding='max_length', max_length=text_max_length, return_tensors='pt', truncation=True)return src, torch.LongTensor(target)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
validation_loader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
inputs, targets = next(iter(train_loader))
print("inputs:", inputs)
print(inputs['input_ids'].shape)
print("targets:", targets)
#batch_size = 16"""
inputs: {'input_ids': tensor([[ 101, 10482, 6591, ..., 0, 0, 0],[ 101, 4911, 2474, ..., 0, 0, 0],[ 101, 5916, 6340, ..., 0, 0, 0],...,[ 101, 21318, 2571, ..., 0, 0, 0],[ 101, 20010, 21149, ..., 0, 0, 0],[ 101, 26934, 5315, ..., 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],...,[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0]])}
torch.Size([16, 128])
targets: tensor([0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1])"""
768是BERT模型中隐藏层的维度大小。BERT模型使用了12层或者24层的Transformer编码器,每一层的隐藏层输出的维度大小为768
nn.Linear(768, 256):将输入的维度从768降到256,这是一个线性变换(全连接层),将BERT模型输出的768维隐藏表示转换为更低维度的表示。
nn.ReLU():ReLU激活函数,用于引入非线性。在降维后的表示上应用ReLU激活函数,以增加模型的非线性能力。
nn.Linear(256, 1):将256维的表示进一步映射到一个单一的值,用于二分类问题中的概率预测。
nn.Sigmoid():Sigmoid激活函数,将输出值压缩到0到1之间,表示概率值。
因此,整个self.predictor模块的作用是将BERT模型的输出映射到一个单一的概率值,用于二分类问题的预测。
#构建模型
class TextClassificationModel(nn.Module):def __init__(self):super(TextClassificationModel, self).__init__()# 加载bert模型self.bert = AutoModel.from_pretrained("bert-base-uncased")# 最后的预测层self.predictor = nn.Sequential(nn.Linear(768, 256),nn.ReLU(),nn.Linear(256, 1),nn.Sigmoid())def forward(self, src):""":param src: 分词后的推文数据"""# 将src直接序列解包传入bert,因为bert和tokenizer是一套的,所以可以这么做。# 得到encoder的输出,用最前面[CLS]的输出作为最终线性层的输入outputs = self.bert(**src).last_hidden_state[:, 0, :]# 使用线性层来做最终的预测return self.predictor(outputs)"""last_hidden_state 的形状是 (batch_size, sequence_length, hidden_size),其中:batch_size 是当前批次中样本的数量。
sequence_length 是输入序列的长度。
hidden_size 是隐藏状态的维度,通常等于BERT模型的隐藏层大小,例如在BERT-base中是768。
"""
model = TextClassificationModel()
model = model.to(device)
model(inputs.to(device))
criteria = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=3e-5)
# 由于inputs是字典类型的,定义一个辅助函数帮助to(device)
def to_device(dict_tensors):result_tensors = {}for key, value in dict_tensors.items():result_tensors[key] = value.to(device)return result_tensors
"""
将字典中的张量转移到指定的设备(如GPU)。它接受一个字典,其中键是张量的名称,值是张量本身。
然后,它迭代字典中的每个键值对,并将值转移到设备上,最后返回一个具有相同键但值位于指定设备上的新字典
"""def validate():model.eval()total_loss = 0.total_correct = 0for inputs, targets in validation_loader:inputs, targets = to_device(inputs), targets.to(device)outputs = model(inputs)loss = criteria(outputs.view(-1), targets.float())total_loss += float(loss)correct_num = (((outputs >= 0.5).float() * 1).flatten() == targets).sum()total_correct += correct_numreturn total_correct / len(validation_dataset), total_loss / len(validation_dataset)
"""
model.safetensors: 0%| | 0.00/440M [00:00<?, ?B/s]
"""
# 首先将模型调成训练模式
model.train()# 清空一下cuda缓存
if torch.cuda.is_available():torch.cuda.empty_cache()# 定义几个变量,帮助打印loss
total_loss = 0.
# 记录步数
step = 0# 记录在验证集上最好的准确率
best_accuracy = 0# 开始训练
for epoch in range(epochs):model.train()for i, (inputs, targets) in enumerate(train_loader):# 从batch中拿到训练数据inputs, targets = to_device(inputs), targets.to(device)# 传入模型进行前向传递outputs = model(inputs)# 计算损失loss = criteria(outputs.view(-1), targets.float())loss.backward()optimizer.step()optimizer.zero_grad()total_loss += float(loss)step += 1if step % log_per_step == 0:print("Epoch {}/{}, Step: {}/{}, total loss:{:.4f}".format(epoch+1, epochs, i, len(train_loader), total_loss))total_loss = 0del inputs, targets# 一个epoch后,使用过验证集进行验证accuracy, validation_loss = validate()print("Epoch {}, accuracy: {:.4f}, validation loss: {:.4f}".format(epoch+1, accuracy, validation_loss))torch.save(model, model_dir / f"model_{epoch}.pt")# 保存最好的模型if accuracy > best_accuracy:torch.save(model, model_dir / f"model_best.pt")best_accuracy = accuracyEpoch 1/100, Step: 49/429, total loss:27.0852
Epoch 1/100, Step: 99/429, total loss:21.9039
Epoch 1/100, Step: 149/429, total loss:22.6578
Epoch 1/100, Step: 199/429, total loss:21.1815
Epoch 1/100, Step: 249/429, total loss:20.3617
Epoch 1/100, Step: 299/429, total loss:18.9497
Epoch 1/100, Step: 349/429, total loss:20.8270
Epoch 1/100, Step: 399/429, total loss:20.0272
Epoch 1, accuracy: 0.8279, validation loss: 0.0247
Epoch 2/100, Step: 20/429, total loss:18.0542
Epoch 2/100, Step: 70/429, total loss:14.7096
Epoch 2/100, Step: 120/429, total loss:15.0193
Epoch 2/100, Step: 170/429, total loss:14.2937
Epoch 2/100, Step: 220/429, total loss:14.1752
Epoch 2/100, Step: 270/429, total loss:14.2685
Epoch 2/100, Step: 320/429, total loss:14.0682
Epoch 2/100, Step: 370/429, total loss:16.1425
Epoch 2/100, Step: 420/429, total loss:17.1818
Epoch 2, accuracy: 0.8397, validation loss: 0.0279
Epoch 3/100, Step: 41/429, total loss:8.0204
Epoch 3/100, Step: 91/429, total loss:9.5614
Epoch 3/100, Step: 141/429, total loss:9.2036
Epoch 3/100, Step: 191/429, total loss:8.9964
Epoch 3/100, Step: 241/429, total loss:10.7305
Epoch 3/100, Step: 291/429, total loss:10.5000
Epoch 3/100, Step: 341/429, total loss:11.3632
Epoch 3/100, Step: 391/429, total loss:10.3103
Epoch 3, accuracy: 0.8252, validation loss: 0.0339
Epoch 4/100, Step: 12/429, total loss:8.1302
Epoch 4/100, Step: 62/429, total loss:5.9590
Epoch 4/100, Step: 112/429, total loss:6.9333
Epoch 4/100, Step: 162/429, total loss:6.4659
Epoch 4/100, Step: 212/429, total loss:6.3636
Epoch 4/100, Step: 262/429, total loss:6.6609
Epoch 4/100, Step: 312/429, total loss:6.3064
Epoch 4/100, Step: 362/429, total loss:5.7218
Epoch 4/100, Step: 412/429, total loss:6.8676
Epoch 4, accuracy: 0.8042, validation loss: 0.0370
Epoch 5/100, Step: 33/429, total loss:4.4049
Epoch 5/100, Step: 83/429, total loss:3.0673
Epoch 5/100, Step: 133/429, total loss:4.1351
Epoch 5/100, Step: 183/429, total loss:3.8803
Epoch 5/100, Step: 233/429, total loss:3.2633
Epoch 5/100, Step: 283/429, total loss:4.6513
Epoch 5/100, Step: 333/429, total loss:4.3888
Epoch 5/100, Step: 383/429, total loss:5.1710
Epoch 5, accuracy: 0.8055, validation loss: 0.0484
model = torch.load(model_dir / f"model_best.pt")
model = model.eval()
test_dataset = MyDataset('test')
#构造测试集的dataloader。测试集是不包含target的
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
results = []
for inputs, ids in tqdm(test_loader):outputs = model(inputs.to(device))outputs = (outputs >= 0.5).int().flatten().tolist()ids = ids.tolist()results = results + [(id, result) for result, id in zip(outputs, ids)]
with open('/kaggle/working/results.csv', 'w', encoding='utf-8') as f:f.write('id,target\n')for id, result in results:f.write(f"{id},{result}\n")
print("Finished!")"""0%| | 0/204 [00:00<?, ?it/s]Finished!
"""
提交后的结果:

相关文章:
Bert入门-使用BERT(transformers库)对推特灾难文本二分类
Kaggle入门竞赛-对推特灾难文本二分类 这个是二月份学习的,最近整理资料所以上传到博客备份一下 数据在这里:https://www.kaggle.com/competitions/nlp-getting-started/data github(jupyter notebook):https://gith…...

【DFS(深度优先搜索)详解】看这一篇就够啦
【DFS详解】看这一篇就够啦 🍃1. 算法思想🍃2. 三种枚举方式🍃2.1 指数型枚举🍃2.2 排列型枚举🍃2.3 组合型枚举 🍃3. 剪枝优化🍃4. 图的搜索🍃5. 来几道题试试手🍃5.1 选…...

java-spring boot光速入门教程(超详细!!)
目录 一、引言 1.1 初始化配置 1.2 整合第三方框架 1.3 后期维护 1.4 部署工程 1.5 敏捷式开发 二、SpringBoot介绍 spring boot 2.1 搭建一个spring boot工程 2.2 使用idea创建项目 2.3 在线创建姿势 2.4 项目的目录结构 2.5 项目的运行方式 2.6 yml文件格式 2…...

一、Prometheus和Grafana搭建
一、服务端Prometheus二进制安装 https://prometheus.io/下载过慢可使用迅雷下载 tar -zxvf prometheus-2.53.0.linux-amd64.tar.gz启动 ./prometheus --config.fileprometheus.yml将其配置为系统服务: vim /usr/lib/systemd/system/prometheus.service[Unit] D…...

从零开始的python学习生活
pycharm部分好用快捷键 变量名的定义 与之前学习过的语言有所不同的是,python中变量名的定义更加的简洁 such as 整形。浮点型和字符串的定义 money50 haha13.14 gaga"hello"字符串的定义依然是需要加上引号,也不需要写;了 字符…...

MSP学习
一、迁移资源调研 完成导入,类似完成选型分析 离线工具调研 账单 二、迁移计划 1、 ecs 确认开始构建迁移环境后,平台将锁定当前标记的迁移资源范围及源端、目标端资源配置信息,并以此为迁移环境构建及迁移实施的数据依据 目标账号…...

生产力工具|Endnote X9如何自动更新文件信息
一、以EndNote X9.2版本为例,打开EndNote文献管理软件。 二、在菜单栏找到“Edit→Preferences...”,点击打开,弹出一个“EndNote Preferences”窗口。 三、进行设置 在打开的窗口左侧选择“PDF Handing”,右边会出现自动导入文献…...

【python】字典、列表、集合综合练习
1、练习1(字典) 字典dic,dic {‘k1’:‘v1’, ‘k2’: ‘v2’, ‘k3’: [11,22,33]} (1). 请循环输出所有的key dic {"k1": "v1", "k2": "v2", "k3": [11, 22, 33]} for k in dic.keys():print(k)k1 k2 k3(2). 请循环输…...
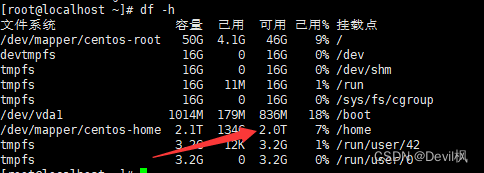
超融合服务器挂载硬盘--linux系统
项目中需要增加服务器的硬盘容量,通过超融合挂载了硬盘后,还需要添加到指定的路径下,这里记录一下操作步骤。 一:通过管理界面挂载硬盘 这一步都是界面操作,登录超融合控制云台后,找到对应的服务器&#…...

Kafka如何防止消息重复发送
Kafka 提供了几种方式来防止消息重复发送和处理。这些方式通常取决于生产者和消费者的设置和实现方式: 生产者端幂等性(什么是幂等性): 幂等性生产者:从 Kafka 0.11 版本开始引入了生产者端的幂等性支持。生产者可以通…...

数据库设计原则介绍
数据库设计是一个重要的过程,它涉及到创建一个逻辑结构来存储和管理数据。良好的数据库设计可以确保数据的完整性、一致性、性能和安全性。以下是一些关键的数据库设计原则: 1. 数据规范化 (Normalization) 目的:减少数据冗余、提高数据一致…...

反馈神经网络与不同类型的神经网络:BP神经网络,深度感知机,CNN,LSTM
反馈神经网络与不同类型的神经网络:BP神经网络,深度感知机,CNN,LSTM 在神经网络的研究和应用中,我们经常听到BP神经网络、深度感知机(MLP)、卷积神经网络(CNN)、长短期记…...

轮播图案例
丐版轮播图 <!DOCTYPE html> <html lang"zh-cn"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title> 基础轮播图 banner 移入移出</t…...

Spring 泛型依赖注入
Spring 泛型依赖注入,是利用泛型的优点对代码时行精简,将可重复使用的代码全部放到一个类之中,方便以后的维护和修改,同时在不增加代码的情况下增加代码的复用性。 示例代码: 创建实体类 Product package test.spri…...
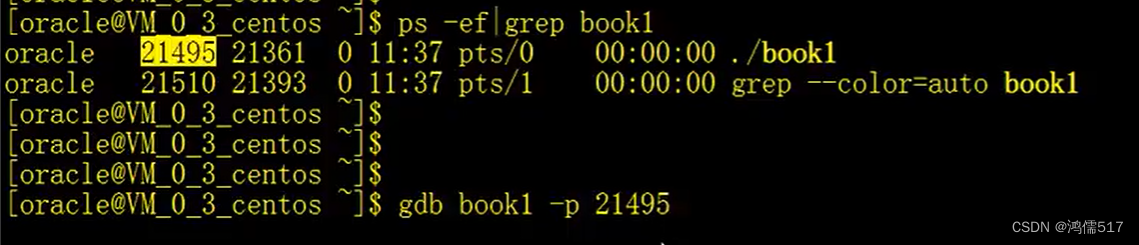
C++ Linux调试(无IDE)
跨平台IDE编译调试C很方便,如QTCreate 、VSCode、Eclipse等,但是如果只能使用Shell控制台呢,gdb调试的优势就很明显了,在没有IDE的情况下,这个方式最有效。因为上手不是很难,特此整理 参考链接 目录 1、G…...

FFmpeg——视频拼接总结
最近需要做一个关于视频拼接的内容,需要将两个视频合成一个视频,使用opencv的话需要将视频读上来然后再写到文件了,这个会很消耗时间也没有必要。两个视频的编码格式是一样的,并不需要转码操作所以想法是直接将视频流补到后面&…...

springboot项目怎么样排除自带tomcat容器使用宝蓝德bes web中间件?
前言: 由于Spring Boot 1.x和2.x不兼容,BES提供了对应的Spring Boot Starter版本。 bes‑lite‑spring‑boot‑1.x‑starter.jar,适用于Spring Boot 1.x的版本。 bes‑lite‑spring‑boot‑2.x‑starter…...
和reactive())
响应式ref()和reactive()
文章目录 ref()reactive()ref对比reactivetoRefs与toRef ref() 作用:定义响应式变量。 语法:let xxxref(初始值)。 返回值:一个RefImpl的实例对象,简称ref对象或ref,ref对象的value属性是响应式的 注意点࿱…...

运维系列.Nginx中使用HTTP压缩功能
运维专题 Nginx中使用HTTP压缩功能 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_28550…...
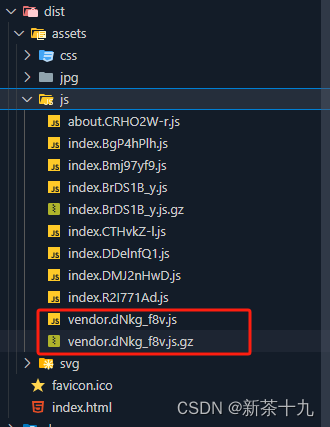
vue3项目图片压缩+rem+自动重启等plugin使用与打包配置
一、Svg配置 每次引入一张 SVG 图片都需要写一次相对路径,并且对 SVG 图片进行压缩优化也不够方便。 vite-svg-loader插件加载SVG文件作为Vue组件,使用SVGO进行优化。 插件网站https://www.npmjs.com/package/vite-svg-loader 1. 安装 pnpm i vite-svg…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...
与 NOT EXISTS 优化)
PostgreSQL Join 执行策略(Nested Loop、Hash Join、Merge Join)与 NOT EXISTS 优化
以集成数据压缩 SQL 优化为例,用大白话讲清楚 Nested Loop、Hash Join、Merge Join 三种执行策略。一、背景:一条慢 SQL 引发的思考 在对上游下发数据做压缩时,有这样一条 UPDATE SQL: -- ❌ 原始写法 UPDATE magellan_nk_order_i…...