Java版Flink使用指南——定制RabbitMQ数据源的序列化器
大纲
- 新建工程
- 新增依赖
- 数据对象
- 序列化器
- 接入数据源
- 测试
- 修改Slot个数
- 打包、提交、运行
- 工程代码
在《Java版Flink使用指南——从RabbitMQ中队列中接入消息流》一文中,我们从RabbitMQ队列中读取了字符串型数据。如果我们希望读取的数据被自动化转换为一个对象,则需要定制序列化器。本文我们就将讲解数据源序列化器的定制方法。
新建工程
我们在IntelliJ中新建一个工程SourceSerializer。
Archetype填入:org.apache.flink:flink-quickstart-java
版本填入与Flink的版本:1.19.1

新增依赖
在pom.xml中新增RabbitMQ连接器
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-rabbitmq</artifactId><version>3.0.1-1.17</version></dependency>
新增Json库依赖
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.17.1</version></dependency>
新增lombok库,主要是为了使用它的一些注解
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.32</version><scope>provided</scope></dependency>
数据对象
我们新建一个简单的数据对象SampleData
src/main/java/org/example/vo/SampleData.java
package org.example.vo;import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
@AllArgsConstructor
public class SampleData {private Long id;private String name;private int age;private Boolean married;private Double salary;public String toJson() throws JsonProcessingException {ObjectMapper mapper = new ObjectMapper();return mapper.writeValueAsString(this);}public static SampleData fromJson(String json) throws JsonProcessingException {ObjectMapper mapper = new ObjectMapper();return mapper.readValue(json, SampleData.class);}
}
这个方法包含两个方法,一个是将SampleData 转换成字符串,另一个是将字符串转成SampleData 对象。
序列化器
我们定义的数据源序列化器要实现AbstractDeserializationSchema接口,主要是通过deserialize方法将二进制数组转换成SampleData 对象。
src/main/java/org/example/serializer/SampleDataRabbitMQSourceSerializer.java
package org.example.serializer;import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.example.vo.SampleData;import java.io.IOException;public class SampleDataRabbitMQSourceSerializer extends AbstractDeserializationSchema<SampleData> {@Overridepublic SampleData deserialize(byte[] message) throws IOException {return SampleData.fromJson(new String(message));}@Overridepublic boolean isEndOfStream(SampleData nextElement) {return false;}@Overridepublic TypeInformation<SampleData> getProducedType() {return TypeInformation.of(SampleData.class);}
}
接入数据源
我们在《Java版Flink使用指南——定制RabbitMQ的Sink序列化器》一文中,往data.to.rbtmq对了写入了大量SampleData 数据。这次我们将其作为数据源来做测试
这次我们在创建RMQSource时传入序列化器SampleDataRabbitMQSourceSerializer。它会将从RabbitMQ获取的数据转换成SampleData对象。
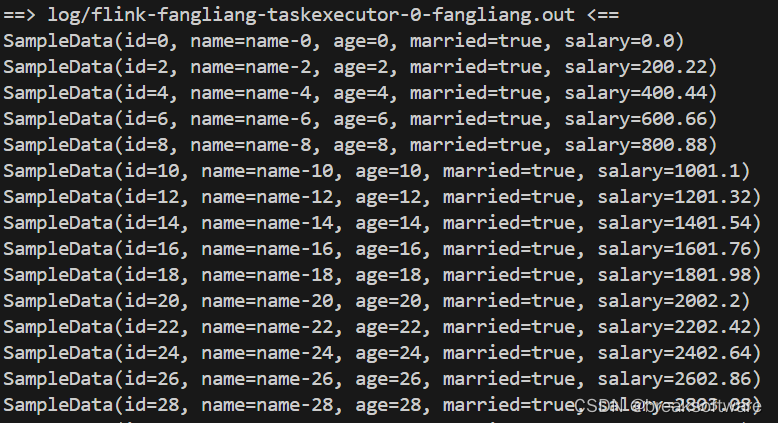
然后我们获取所有“已婚”(filter.getMarried() == true)的数据,将其打印到日志中。
String queueName = "data.to.rbtmq";String host = "172.21.112.140"; // IP of the rabbitmq serverint port = 5672;String username = "admin";String password = "fangliang";String virtualHost = "/";int parallelism = 1;// create a RabbitMQ sourceRMQConnectionConfig rmqConnectionConfig = new RMQConnectionConfig.Builder().setHost(host).setPort(port).setUserName(username).setPassword(password).setVirtualHost(virtualHost).build();RMQSource<SampleData> rmqSource = new RMQSource<>(rmqConnectionConfig, queueName, true, new SampleDataRabbitMQSourceSerializer());final DataStream<SampleData> stream = env.addSource(rmqSource).name(username + "'s source from " + queueName).setParallelism(parallelism);stream.filter(filter -> filter.getMarried() == true).print().name(username + "'s sink to stdout").setParallelism(parallelism);
测试
修改Slot个数
由于我们要运行两个流式计算任务,于是需要两个Slot。
vim conf/config.yaml
将numberOfTaskSlots的值改成2。
打包、提交、运行
我们将本例和《Java版Flink使用指南——定制RabbitMQ的Sink序列化器》中的包都提交运行
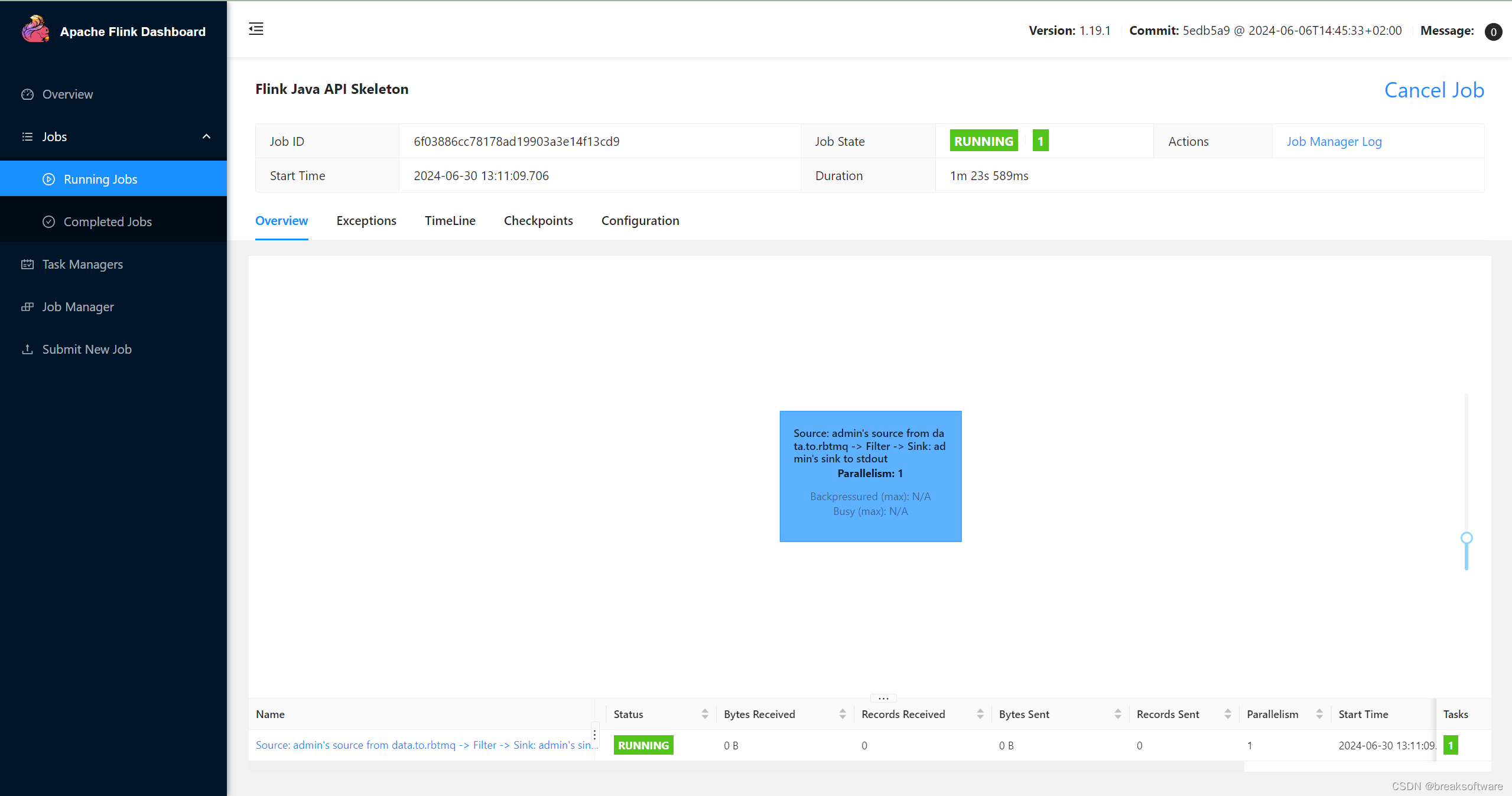
然后在日志中可以看到“已婚”的数据都在输出
tail -f log/*
工程代码
https://github.com/f304646673/FlinkDemo
相关文章:
Java版Flink使用指南——定制RabbitMQ数据源的序列化器
大纲 新建工程新增依赖数据对象序列化器接入数据源 测试修改Slot个数打包、提交、运行 工程代码 在《Java版Flink使用指南——从RabbitMQ中队列中接入消息流》一文中,我们从RabbitMQ队列中读取了字符串型数据。如果我们希望读取的数据被自动化转换为一个对象&#x…...

CV每日论文--2024.7.8
1、DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents 中文标题:DisCo-Diff:利用离散潜伏增强连续扩散模型 简介:这篇文章提出了一种新型的离散-连续潜变量扩散模型(DisCo-Diff),旨在改善传统扩散模型(DMs)存在的问…...

【AI大模型】赋能儿童安全:楼层与室内定位实践与未来发展
文章目录 引言第一章:AI与室内定位技术1.1 AI技术概述1.2 室内定位技术概述1.3 楼层定位的挑战与解决方案 第二章:儿童定位与安全监控的需求2.1 儿童安全问题的现状2.2 智能穿戴设备的兴起 第三章:技术实现细节3.1 硬件设计与选择传感器选择与…...

云服务器linux系统安装配置docker
在我们拿到一个纯净的linux系统时,我需要进行一些基础环境的配置 (如果是云服务器可以用XShell远程连接,如果连接不上可能是服务器没开放22端口) 下面是配置环境的步骤 sudo -s进入root权限:退出使用exit sudo -i进入…...
泰勒雷达图2
matplotlib绘制泰勒雷达图 import matplotlib.pyplot as plt import numpy as np from numpy.core.fromnumeric import shape import pandas as pd import dask.dataframe as dd from matplotlib.projections import PolarAxes import mpl_toolkits.axisartist.floating_axes a…...

数据库容灾 | MySQL MGR与阿里云PolarDB-X Paxos的深度对比
开源生态 众所周知,MySQL主备库(两节点)一般通过异步复制、半同步复制(Semi-Sync)来实现数据高可用,但主备架构在机房网络故障、主机hang住等异常场景下,HA切换后大概率就会出现数据不一致的问…...

react根据后端返回数据动态添加路由
以下代码都为部分核心代码 一.根据不同的登录用户,返回不同的权限列表 ,以下是三种不同用户限权列表 const pression { //超级管理员BigAdmin: [{key: "screen",icon: "FileOutlined",label: "数据图表",},{key: "…...

机器学习中的可解释性
「AI秘籍」系列课程: 人工智能应用数学基础 人工智能Python基础 人工智能基础核心知识 人工智能BI核心知识 人工智能CV核心知识 为什么我们需要了解模型如何进行预测 我们是否应该始终信任表现良好的模型?模型可能会拒绝你的抵押贷款申请或诊断你患…...

上海慕尼黑电子展开展,启明智显携物联网前沿方案亮相
随着科技创新的浪潮不断涌来,上海慕尼黑电子展在万众瞩目中盛大开幕。本次展会汇聚了全球顶尖的电子产品与技术解决方案,成为业界瞩目的焦点。启明智显作为物联网彩屏显示领域的佼佼者携产品亮相展会,为参展者带来了RTOS、LINUX全系列方案及A…...

Centos7离线安装ElasticSearch7.4.2
一、官网下载相关的安装包 ElasticSearch7.4.2: elasticsearch-7.4.2-linux-x86_64.tar.gz 下载中文分词器: elasticsearch-analysis-ik-7.4.2.zip 二、上传解压文件到服务器 上传到目录:/home/data/elasticsearch 解压文件࿱…...

深入理解sklearn中的模型参数优化技术
参数优化是机器学习中的关键步骤,它直接影响模型的性能和泛化能力。在sklearn中,参数优化可以通过多种方式实现,包括网格搜索(GridSearchCV)、随机搜索(RandomizedSearchCV)和贝叶斯优化等。本文…...

【Elasticsearch】开源搜索技术的演进与选择:Elasticsearch 与 OpenSearch
开源搜索技术的演进与选择:Elasticsearch 与 OpenSearch 1.历史发展2.OpenSearch 与 Elasticsearch 相同点3.OpenSearch 与 Elasticsearch 不同点3.1 版本大不同3.2 许可证不同3.3 社区不同3.4 功能不同3.5 安全性不同3.6 性能不同3.7 价格不同3.8 两者可相互导入 4…...

欧拉openEuler 22.03 LTS-部署k8sv1.03.1
1.设置ip # vi /etc/sysconfig/network-scripts/ifcfg-ens32 TYPEEthernet PROXY_METHODnone BROWSER_ONLYno BOOTPROTOstatic DEFROUTEyes IPV4_FAILURE_FATALno #IPV6INITyes #IPV6_AUTOCONFyes #IPV6_DEFROUTEyes #IPV6_FAILURE_FATALno #IPV6_ADDR_GEN_MODEeui64 NAMEens1…...

老年生活照护实训室:为养老服务业输送专业人才
本文探讨了老年生活照护实训室在养老服务业专业人才培养中的关键作用。通过详细阐述实训室的功能、教学实践、对学生能力的培养以及面临的挑战和解决方案,强调了其在提升人才素质、满足行业需求方面的重要性,旨在为养老服务业的可持续发展提供有力的人才…...

go语言中使用WaitGroup和channel实现处理多线程问题
WaitGroup 背景 如果将一个任务分为任意个小任务,并且不关心小任务的执行顺序,并且希望等待全部的小任务执行完成后再去操作后面的逻辑,那我推荐你用sync.WaitGRoup 使用方法 比如,有一个任务需要执行 3 个子任务,…...

Open3D 计算点云的平均密度
目录 一、概述 1.1基于领域密度计算原理 1.2应用 二、代码实现 三、实现效果 2.1点云显示 2.2密度计算结果 一、概述 在点云处理中,点的密度通常表示为某个点周围一定区域内的点的数量。高密度区域表示点云较密集,低密度区域表示点云较稀疏。计算…...

C语言之数据在内存中的存储(1),整形与大小端字节序
目录 前言 一、整形数据在内存中的存储 二、大小端字节序 三、大小端字节序的判断 四、字符型数据在内存中的存储 总结 前言 本文主要讲述整型包括字符型是如何在内存中存储的,涉及到大小端字节序这一概念,还有如何判断大小端,希望对大…...
B端全局导航:左侧还是顶部?不是随随便便,有依据在。
一、什么是全局导航 B端系统的全局导航是指在B端系统中的主要导航菜单,它通常位于系统的顶部或左侧,提供了系统中各个模块和功能的入口。全局导航菜单可以帮助用户快速找到和访问系统中的各个功能模块,提高系统的可用性和用户体验。 全局导航…...

什么是海外仓管理自动化?策略及落地实施步骤指南
作为海外仓的管理者,你每天都面临提高海外仓运营效率、降低成本和满足客户需求的问题。海外仓自动化管理技术为这些问题提供了不错的解决思路,不过和任何新技术一样,从策略到落地实施,都有一个对基础逻辑的认识过程。 今天我们整…...
Paint之函数大汇总、ColorMatrix与滤镜效果、setColorFilter)
自定义控件三部曲之绘图篇(六)Paint之函数大汇总、ColorMatrix与滤镜效果、setColorFilter
在自定义控件的绘图篇中,Paint 类是核心的组成部分之一,它控制了在 Canvas 上绘制的内容的各种属性,包括颜色、风格、抗锯齿、透明度等等。下面将详细介绍 Paint 的主要功能以及如何使用 ColorMatrix 和 setColorFilter 来实现滤镜效果。 Pa…...

解锁外语游戏新体验:XUnity自动翻译器完全指南 [特殊字符]
解锁外语游戏新体验:XUnity自动翻译器完全指南 🎮 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏中的生涩文本而苦恼吗?XUnity自动翻译器让你轻松打破语…...
)
保姆级教程:手把手教你为Jetson Orin Nano刷入R36.4.4系统(从下载到开机)
从零开始:Jetson Orin Nano开发者套件系统刷入全流程实战指南 当你第一次拿到NVIDIA Jetson Orin Nano开发者套件时,那种兴奋感可能很快会被"我该如何开始"的困惑所取代。这款性能强大的边缘计算设备确实令人着迷,但如果没有正确的…...

微信群消息监控系统进阶:如何用dataclass优化配置管理并实现热更新
微信群消息监控系统进阶:如何用dataclass优化配置管理并实现热更新 在开发长期运行的微信消息监控系统时,配置管理往往是后期维护的痛点。许多开发者初期会选择简单的字典或JSON文件存储配置,但随着功能迭代,硬编码的配置项、散落…...

终极Mailtrain故障排除指南:10个常见问题与快速解决方案
终极Mailtrain故障排除指南:10个常见问题与快速解决方案 【免费下载链接】mailtrain Self hosted newsletter app 项目地址: https://gitcode.com/gh_mirrors/ma/mailtrain Mailtrain作为一款自托管的 newsletter 应用,为用户提供了强大的邮件营销…...

文件日期更改器:在 Windows 上修改文件日期的完整指南
需要更改文件创建日期或编辑修改时间戳?我们的综合指南揭示了三种有效的文件日期修改方法,其中包括评价最高的文件属性日期修改工具——视频转换器的文件日期修改器。学习专业的文件日期修改技巧,同时确保数据完整性。为什么您可能需要更改文…...

5分钟部署Qwen3-VL-8B:MacBook也能跑的视觉语言模型,零基础上手
5分钟部署Qwen3-VL-8B:MacBook也能跑的视觉语言模型,零基础上手 1. 为什么选择Qwen3-VL-8B-Instruct-GGUF 1.1 轻量级多模态模型的突破 Qwen3-VL-8B-Instruct-GGUF是阿里通义实验室最新推出的视觉语言模型,它最大的特点就是小身材大能量。…...

手动侧开门款屏蔽箱 适用蓝牙 WIFI测试 无线测试屏蔽箱GX-5950A
GX-5950A屏蔽箱品名:屏蔽箱型号:GX-5950A一、主要功能及适用范围:1 该屏蔽箱适用于无线通讯测试、1 EMI测试、1 耦合测试、1 RF功能测试。适用于手机,平板计算机,蓝牙,wi-fi,天线等测试&#…...

ChatGLM3-6B部署避坑指南:解决组件冲突,实现稳定运行
ChatGLM3-6B部署避坑指南:解决组件冲突,实现稳定运行 1. 项目概述与核心优势 ChatGLM3-6B-32k是智谱AI团队推出的新一代开源对话模型,基于本地化部署方案,特别针对组件冲突问题进行了深度优化。相比传统云端方案,本方…...

一键获取B站完整评论区数据:告别数据采集烦恼的终极方案
一键获取B站完整评论区数据:告别数据采集烦恼的终极方案 【免费下载链接】BilibiliCommentScraper 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCommentScraper 还在为B站评论数据采集不完整而烦恼吗?想要批量获取视频评论区信息却无从…...

互联网舆情分析系统:基于Nanbeige 4.1-3B的情感与主题挖掘
互联网舆情分析系统:基于Nanbeige 4.1-3B的情感与主题挖掘 最近几年,大家有没有感觉网上的声音越来越复杂?一个热点出来,瞬间就是成千上万条评论,有支持的,有反对的,有理性分析的,也…...