昇思25天学习打卡营第16天 | 文本解码原理-以MindNLP为例

基于 MindSpore 实现 BERT 对话情绪识别
上几章我们学习过了基于MindSpore来实现计算机视觉的一些应用,那么从这期开始要开始一个新的领域——LLM
首先了解一下什么是LLM
LLM 是 “大型语言模型”(Large Language Model)的缩写。LLM 是一种人工智能模型,通常基于深度学习技术,特别是使用Transformer架构,经过在大规模文本数据上训练,能够理解和生成自然语言文本。这些模型在处理各种自然语言处理任务方面表现出色,例如文本生成、翻译、问答、摘要和对话。
以下是关于 LLM 的一些关键点:
-
规模:
- LLM 通常具有数十亿到数百亿个参数。这些参数量级使得模型能够捕捉语言中的复杂模式和语义关系。
-
训练数据:
- LLM 使用大量文本数据进行训练,包括书籍、文章、网站内容和其他形式的书面语言。这些数据可以覆盖各种主题和风格,使得模型具有广泛的知识和多样的语言能力。
-
应用:
- 生成文本:创建高质量的文章、故事、对话等。
- 语言翻译:将文本从一种语言翻译到另一种语言。
- 问答系统:回答用户提出的问题。
- 文本摘要:从长文中提取关键信息并生成摘要。
- 对话系统:与用户进行自然的对话交流。
-
模型架构:
- 大多数 LLM 基于 Transformer 架构,特别是它的自注意力机制,使模型能够处理序列数据并捕捉长距离依赖关系。
-
知名模型:
- 一些知名的 LLM 包括 OpenAI 的 GPT-3、GPT-4,Google 的 BERT 和 T5,以及 Facebook 的 RoBERTa。
-
挑战和考虑:
- 计算资源:训练和运行 LLM 需要大量的计算资源和存储空间。
- 偏见和伦理:由于训练数据可能包含偏见,模型输出也可能反映这些偏见。因此,在使用 LLM 时需要注意伦理问题和偏见风险。
- 可解释性:大型模型通常被认为是“黑箱”,难以理解其内部决策过程。
LLM 在人工智能和自然语言处理领域有着广泛的应用前景,但也伴随着技术、伦理和社会挑战。
在自然语言处理(NLP)中,文本解码是生成自然语言文本的重要步骤。本文将介绍文本解码的基本原理,并结合MindNLP框架,提供具体的代码实例和详细注释,帮助大家更好地理解文本解码的实现过程。
什么是文本解码
文本解码是将模型的输出(通常是概率分布或词汇索引)转换为可读的自然语言文本的过程。在生成文本时,常见的解码方法包括贪心解码、束搜索(Beam Search)、随机采样等。
MindNLP简介
MindNLP是昇思(MindSpore)提供的一个用于自然语言处理的工具包,旨在简化NLP模型的开发和部署。本文将通过MindNLP实现文本解码过程,并展示如何利用该工具包进行文本生成任务。
实验环境
首先,我们需要安装MindNLP及其依赖库。
!pip install mindnlp
文本解码实现
以下是一个使用MindNLP实现文本解码的实例代码:
import mindspore as ms
import mindnlp
from mindnlp.modules import RNNDecoder
from mindnlp.models import Seq2SeqModel
from mindspore import nn
from mindspore import Tensor# 设置随机种子以确保结果可复现
ms.set_seed(42)# 定义解码器
class GreedyDecoder(RNNDecoder):def __init__(self, rnn, out_proj):super(GreedyDecoder, self).__init__(rnn, out_proj)def decode(self, encoder_outputs, max_length, start_token, end_token):batch_size = encoder_outputs.shape[0]decoder_input = Tensor([[start_token]] * batch_size, dtype=ms.int32)decoder_hidden = Nonedecoded_sentences = []for _ in range(max_length):decoder_output, decoder_hidden = self.forward(decoder_input, decoder_hidden, encoder_outputs)topv, topi = decoder_output.topk(1)decoder_input = topi.squeeze().detach()decoded_sentences.append(decoder_input.asnumpy())if (decoder_input == end_token).all():breakreturn decoded_sentences# 定义编码器和解码器
encoder = nn.LSTM(input_size=10, hidden_size=20, num_layers=2, batch_first=True)
decoder = GreedyDecoder(nn.LSTM(input_size=10, hidden_size=20, num_layers=2, batch_first=True), nn.Dense(20, 10))# 定义序列到序列模型
model = Seq2SeqModel(encoder, decoder)# 模拟输入数据
encoder_outputs = Tensor(ms.numpy.random.randn(5, 7, 20), dtype=ms.float32)
start_token = 0
end_token = 9
max_length = 10# 进行解码
decoded_sentences = decoder.decode(encoder_outputs, max_length, start_token, end_token)# 打印解码结果
for i, sentence in enumerate(decoded_sentences):print(f"Sentence {i + 1}: {sentence}")
代码解释
-
导入必要的库:
首先,导入MindSpore和MindNLP的相关模块。RNNDecoder是用于解码RNN模型输出的模块,Seq2SeqModel是用于构建序列到序列模型的类。 -
设置随机种子:
使用ms.set_seed(42)确保结果的可复现性。 -
定义解码器:
GreedyDecoder类继承自RNNDecoder,实现贪心解码算法。在解码过程中,依次选取每个时间步概率最大的词作为输出。 -
定义编码器和解码器:
使用LSTM定义编码器和解码器,并将解码器封装在GreedyDecoder中。 -
定义序列到序列模型:
使用Seq2SeqModel类将编码器和解码器封装在一起。 -
模拟输入数据:
创建一个随机的编码器输出,作为解码器的输入。定义起始标记和结束标记,以及最大解码长度。 -
进行解码:
调用解码器的decode方法,执行解码过程。 -
打印解码结果:
打印解码得到的句子,展示每个时间步的预测结果。
通过本文的介绍,我们了解了文本解码的基本原理,并结合MindNLP框架,详细讲解了如何实现一个简单的贪心解码器。希望这篇文章能帮助大家更好地理解文本生成任务中的解码过程。如果有任何问题或建议,欢迎在评论区留言讨论。

相关文章:
昇思25天学习打卡营第16天 | 文本解码原理-以MindNLP为例
基于 MindSpore 实现 BERT 对话情绪识别 上几章我们学习过了基于MindSpore来实现计算机视觉的一些应用,那么从这期开始要开始一个新的领域——LLM 首先了解一下什么是LLM LLM 是 “大型语言模型”(Large Language Model)的缩写。LLM 是一种…...

Unity之Text组件换行\n没有实现+动态中英互换
前因:文本中的换行 \n没有换行而是打印出来了,解决方式 因为unity会默认把\n替换成\\n 面板中使用富文本这个选项啊 没有用 m_text.text m_text.text.Replace("\\n", "\n"); ###动态中英文互译 using System.Collections; using…...

vue3+ el-tree 展开和折叠,默认展开第一项
默认第一项展开: 展开所有项: 折叠所有项: <template><el-treestyle"max-width: 600px":data"treeData"node-key"id":default-expanded-keys"defaultExpandedKey":props"defaultProps"…...

ProFormList --复杂数据联动ProFormDependency
需求: (1)数据联动:测试数据1、2互相依赖,测试数据1<测试数据2,测试数据2>测试数据1。 (2)点击添加按钮,添加一行。 (3)自定义操作按钮。 ࿰…...

Git、Github、tortoiseGit下载安装调试全套教程
一、Git 1.下载安装Git 编辑器可默认Vim,可换成别的,此处换成VScode,换成VScode或别的都需要单独下载和调用 (1)Git安装:https://www.cnblogs.com/xiuxingzhe/p/9300905.html 超级完整的 Git的下载、安…...

老师怎么快速发布成绩?
期末考试的钟声刚刚敲响,成绩单的发放却成了老师们的一大难题。每当期末成绩揭晓,老师们便要开始一项繁琐的任务——将每一份成绩单逐一私信给家长。这不仅耗费了大量的时间和精力,也让本就忙碌的期末工作变得更加繁重。然而,随着…...

央视揭露:上百元的AI填报高考志愿真的靠谱吗?阿里云新增两位AI圈“代言人”!|AI日报
文章推荐 MiniMax闫俊杰:国内模型远不及GPT-4;OpenAI隐瞒黑客曾入侵其内部系统|AI日报 今日热点 月之暗面、智联招聘成为阿里云新“代言人”,使用阿里云强大算力和大模型服务平台提升模型推理效率 7月8日,阿里云官…...

TPM管理咨询公司甄选指南
在竞争激烈的市场环境中,TPM(全面生产维护)管理咨询公司的重要性日益凸显。然而,如何在众多咨询公司中筛选出最适合自己企业的合作伙伴,成为了许多企业决策者面临的难题。本文将从专业度、行业经验、服务质量和性价比等…...

探索 Scikit-Learn:机器学习的强大工具库
Scikit-Learn 探索 Scikit-Learn:机器学习的强大工具库主要功能模块分类(Classification)回归(Regression)聚类(Clustering)降维(Dimensionality Reduction)模型选择&…...

音视频质量评判标准
一、实时通信延时指标 通过图中表格可以看到,如果端到端延迟在200ms以内,说明整个通话是优质的,通话效果就像大家在同一个房间里聊天一样;300ms以内,大多数人很满意,400ms以内,有小部分人可以感…...

如何在vue3中使用scss
一 要使用scss首先需要下载相关的包 可以在终端使用下面的命令下载相关包 npm install -D sass 二 在src文件下新建一个文件夹叫做styles 在文件夹下创建三个文件 index.scss主要用来引用其他文件 reset.scss用来清除默认的样式 variable.scss用来配置全局属性 三 需要在v…...

Gartner发布采用美国防部模型实施零信任的方法指南:七大支柱落地方法
零信任是网络安全计划的关键要素,但制定策略可能会很困难。安全和风险管理领导者应使用美国国防部模型的七大支柱以及 Gartner 研究来设计零信任策略。 战略规划假设 到 2026 年,10% 的大型企业将拥有全面、成熟且可衡量的零信任计划,而 202…...
Flutter——最详细(Badge)使用教程
背景 主要常用于组件叠加上圆点提示; 使用场景,消息数量提示,消息红点提示 属性作用backgroundColor红点背景色smallSize设置红点大小isLabelVisible是否显示offset设置红点位置alignment设置红点位置child设置底部组件 代码块 class Badge…...

SQLServer的系统数据库用别的服务器上的系统数据库替换后做跨服务器连接时出现凭证、非对称金钥或私密金钥的资料无效
出错作业背景: 公司的某个sqlserver服务器要做迁移,由于该sqlserver服务器上数据库很多,并且做了很多的job和维护计划,重新安装的sqlserver这些都是空的,于是就想到了把系统4个系统数据库进行替换,然后也把…...

vue前端面试
一 .v-if和v-show的区别 v-if 和 v-show 是 Vue.js 中两个常用的条件渲染指令,它们都可以根据条件决定是否渲染某个元素。但是它们之间存在一些区别。 语法:v-if 和 v-show 的语法相同,都接收一个布尔值作为参数。 <div v-if"show…...

【网络安全】Host碰撞漏洞原理+工具+脚本
文章目录 漏洞原理虚拟主机配置Host头部字段Host碰撞漏洞漏洞场景工具漏洞原理 Host 碰撞漏洞,也称为主机名冲突漏洞,是一种网络攻击手段。常见危害有:绕过访问控制,通过公网访问一些未经授权的资源等。 虚拟主机配置 在Web服务器(如Nginx或Apache)上,多个网站可以共…...

unattended-upgrade进程介绍
unattended-upgrade 是一个用于自动更新 Debian 和 Ubuntu 系统的软件包。这个进程通常用于定期下载并安装安全更新,以保持系统的安全性和稳定性。 具体来说,这个命令 /usr/bin/python3 /usr/bin/unattended-upgrade --download-only 表示运行 unattend…...

SpringBoot 中多例模式的神秘世界:用法区别以及应用场景,最后的灵魂拷问会吗?- 第519篇
历史文章(文章累计500) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 《…...
_2024升级版_180)
基于STM32设计的智能婴儿床(ESP8266局域网)_2024升级版_180
基于STM32设计的智能婴儿床(采用STM32F103C8T6)(180) 文章目录 一、设计需求【1】项目功能介绍【2】程序最终的运行逻辑【3】硬件模块组成【4】ESP8266模块配置【5】上位机开发思路【6】系统功能模块划分1.2 项目开发背景1.3 开发工具的选择1.4 系统框架图1.5 系统原理图1.6 硬…...
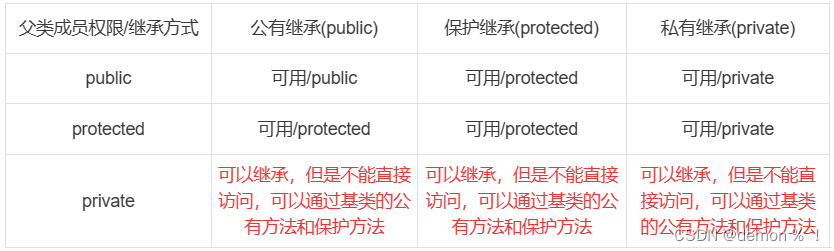
C++(第四天----拷贝函数、类的组合、类的继承)
一、拷贝构造函数(复制构造函数) 1、概念 拷贝构造函数,它只有一个参数,参数类型是本类的引用。如果类的设计者不写拷贝构造函数,编译器就会自动生成拷贝构造函数。大多数情况下,其作用是实现从源对象到目…...

【限时开源】FastAPI 2.0 AI流式SDK v1.0:内置token计数、流控限速、断点续传、前端SSE自动重连——仅开放首批200个GitHub Star领取资格
第一章:FastAPI 2.0 异步 AI 流式响应的核心演进与架构定位FastAPI 2.0 将原生异步流式响应能力从实验性支持升级为一级公民,彻底重构了 AI 应用服务端的实时交互范式。其核心演进体现在对 StreamingResponse 的深度重写、对 ASGI 3.0 协议的精准适配&am…...

从‘虚拟’到‘物理’:程序员视角下的内存块、页框与页到底是怎么协作的?
从‘虚拟’到‘物理’:程序员视角下的内存块、页框与页到底是怎么协作的? 当你调试程序时遇到"Segmentation fault"或"Page fault"错误,是否好奇这些术语背后究竟发生了什么?作为开发者,我们每天都…...
)
ASPICE 的起源与发展历程(二)
ASPICE 并非汽车行业原生创造,其核心底层源自通用软件过程评估体系,是汽车行业基于自身高安全、高可靠的产业特性,定制化迭代的行业专属标准。(一)底层起源:通用SPICE 准的诞生1994 年,国际标准…...

智汇云舟亮相2026中关村论坛 联合发起“通智行业大脑”联盟
3月29日,作为中关村论坛年会的重要组成部分,“迈向通用人工智能”平行论坛在中关村国家自主创新示范区展示交易中心隆重举行。本次论坛由北京市科学技术委员会、中关村科技园区管理委员会、北京市海淀区人民政府联合主办,北京通用人工智能研究…...

I2CLCD驱动库:HD44780字符屏的I²C轻量级嵌入式驱动
1. I2CLCD库概述:面向嵌入式系统的字符型LCD IC适配驱动I2CLCD是一个轻量级、高可靠性的开源驱动库,专为将标准HD44780兼容的字符型LCD(如1602、2004)通过IC总线接入嵌入式系统而设计。其核心价值在于以最小硬件资源开销实现LCD控…...
别再只调包了!用Sentence-Transformers从零训练你的专属Embedding模型(附完整代码)
从零构建领域专属Embedding模型:超越调包侠的实战指南 当你第一次调用model.encode("你的文本")就能获得一个语义向量时,是否好奇过这个黑箱背后的魔法?在电商推荐、智能客服等垂直场景中,通用Embedding模型的表现往往差…...

智能化运维实战:信息化系统自动化巡检与故障自愈方案
1. 为什么需要自动化巡检与故障自愈? 想象一下,你负责维护一个大型电商平台的后台系统。凌晨3点突然收到告警短信:数据库CPU使用率飙升到98%。这时候你需要立刻起床,手忙脚乱地登录服务器检查日志、分析原因、尝试重启服务...这样…...

小白程序员必看:收藏这份RAG大模型核心技术原理详解,轻松入门智能Agent
1. 核心流程全景图RAG 的生命周期可以严格划分为两个平行的工作流:离线数据处理流(Data Pipeline) 和 在线检索生成流(Query Pipeline)。RAG 核心工作流 1.1 离线数据处理流(Data Ingestion) 这…...

ESP8266轻量级按钮状态MQTT同步库
1. 项目概述BartOS-button-online是为 BartOS 物联网操作系统设计的轻量级按钮状态在线同步库,专用于资源受限的 ESP8266 平台(如 ESP-01、NodeMCU),并兼容 Arduino Core for ESP8266 开发环境。该库不提供独立的 UI 或 Web 服务&…...

LLM驱动的AI Agent故事生成与叙事能力
LLM驱动的AI Agent故事生成与叙事能力 关键词:LLM(大语言模型)、AI Agent、故事生成、叙事能力、自然语言处理 摘要:本文聚焦于LLM驱动的AI Agent在故事生成与叙事能力方面的技术。首先介绍了研究背景,包括目的、预期读者、文档结构和相关术语。接着阐述了核心概念,如LLM…...