python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据。正好之前学了python,练练手。
编码问题
因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了。
Unicode是一种编码方案,又称万国码,可见其包含之广。但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用。你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机上。UTF-8或者GB也可以进行解码(decode)还原为Unicode。
在python中Unicode是一类对象,表现为以u打头的,比如u'中文',而string又是一类对象,是在具体编码方式下的实际存在计算机上的字符串。比如utf-8编码下的'中文'和gbk编码下的'中文',并不相同。可以看如下代码:
| 1 2 3 4 5 6 7 8 9 |
|
可以看到,其实存储在计算机中的只是这样的编码,而不是一个一个的汉字,在print的时候要知道当时是用的什么样的编码方式,才能正确的print出来。有一个说法提得很好,python中的Unicode才是真正的字符串,而string是字节串
更多爬取数据分析项目实战点击下方领取↓
项目案例腾讯文档-在线文档 https://docs.qq.com/doc/DU1B0ZHlva0hQQVNa
https://docs.qq.com/doc/DU1B0ZHlva0hQQVNa
文件编码
既然有不同的编码,那么如果在代码文件中直接写string的话,那么它到底是哪一种编码呢?这个就是由文件的编码所决定的。文件总是以一定的编码方式保存的。而python文件可以写上coding的声明语句,用来说明这个文件是用什么编码方式保存的。如果声明的编码方式和实际保存的编码方式不一致就会出现异常。可以见下面例子: 以utf-8保存的文件声明为gbk
| 1 2 3 4 5 6 7 8 9 |
|
提示错误 File "test.py", line 1 SyntaxError: Non-ASCII character '\xe6' in file test.py on line 1, but no encodi ng declared; see PEP 263 – Defining Python Source Code Encodings | peps.python.org for details 改为
| 1 2 3 4 5 6 7 8 9 |
|
输出正常结果 u'\u6c49' '\xe6\xb1\x89' '\xba\xba' '\xe6\xb1\x89'
更多内容可参见这篇文章Python字符编码详解 - AstralWind - 博客园
基本方法
其实用python爬取网页很简单,只有简单的几句话
| 1 2 |
|
这样就可以获得到页面的内容。接下来再用正则匹配去匹配所需要的内容就行了。
但是,真正要做起来,就会有各种各样的细节问题。
登录
这是一个需要登录认证的网站。也不太难,只要导入cookielib和urllib库就行。
| 1 2 3 |
|
这样就装载进一个cookie,用urlOpener去open登录以后就可以记住信息。
断线重连
如果只是做到上面的程度,不对open进行包装的话,只要网络状况有些起伏,就直接抛出异常,退出整个程序,是个很不好的程序。这个时候,只要对异常进行处理,多试几次就行了:
| 1 2 3 4 5 6 7 8 9 |
|
正则匹配
其实正则匹配并不算是一个特别好的方法,因为它的容错性很不好,网页要完全统一。如果有稍微的不统一,就会失败。后来看到说有根据xpath来进行选取的,下次可以尝试一下。
写正则其实是有一定技巧的:
- 非贪婪匹配。比如这样一个标签:<span class='a'>hello</span>,要取出a来,如果写成这样的表达式,就不行了:<span class=.*>hello</span>。因为*进行了贪婪匹配。这是要用.?:<span class=.?>hello</span>。
- 跨行匹配。实现跨行有一种思路是运用DOTALL标志位,这样.就会匹配到换行。但是这样一来,整个匹配过程就会变得很慢。本来的匹配是以行为单位的。整个过程最多就是O(nc2),n是行数,c是平均列数。现在极有可能变为O((nc)2)。我的实现方案是运用\n来匹配换行,这样可以明确指出匹配最多跨跃多少行。比如:abc\s*\n\s*def,就指出查找的是隔一行的。(.\n)?就可以指定是匹配尽可能少的行。
- 这里其实还要注意一个点。有的行末是带有\r的。也就是说一行是以\r\n结尾的。当初不知道这一点,正则就调试了很久。现在直接用\s,表示行末空格和\r。
- 无捕获分组。为了不对捕获的分组造成影响,上面的(.\n)可以改为(?:.\n),这样捕获分组时,就会忽略它。
- 单括号要进行转义。因为单括号在正则里是用来表示分组的,所以为了匹配单括号就进行转义。正则字符串最好用的是带有r前缀的字符串,如果不是的话,则要对\再进行转义。
- 快速正则。写了那么多模式,也总结出一规律出来。先把要匹配的字符相关的段落拿出来。要匹配的东西用(.?)代替。把换行\n替换为字符串\s\n\s*,再去掉行首行末的空格。整个过程在vim中可以很快就写好。
Excel操作
这次的数据是放进Excel的。到后面才意识到如果放进数据库的话,可能就没有那么多事了。但是已经写到一半,难以回头了。
搜索Excel,可以得出几个方案来,一个是用xlrt/xlwt库,这个不管电脑上是否安装了Excel,都可以运行,但只能是xls格式的。还有一个是直接包装了com,需要电脑上安装了软件才行。我采用的是前一种。
基本的读写没有问题。但是数据量一大起来,就有问题了。
- 内存不够。程序一跑起来,内存占用就一点一点往上涨。后面再查了一下,知道要用flush_row_data。但是还是会出错。一看内存占用,没有什么问题,一直很平稳。但最后还是会出现memory error。这真是见鬼了。又是反复地查, 反复地运行。一点结果都没有。要命的是bug只在数据量大起来才出现,而等数据量大起来往往要好几个小时,这debug的成本实在是太高了。一个偶然的机会,突然发现内存占用,虽然总体平稳,但是会规律性的出现小的高涨,而这规律性,会不会和flush_row_data,有关。一直疑惑的是data被flush到了哪里。原来xlwt的作法是很蛋疼的作法。把数据存在内存里,或者flush到一个temp,到save的时候,再一次性写入。而问题正出在这一次性写入,内存猛涨。那我要flush_row_data何用?为什么不一开始就flush进要写入的地方。
- 行数限制。这个是xls格式本身决定的,最多行数只能是65536。而且数据一大,文件打开也不方便。
结合以上两点,最终采取了这么一个策略,如果行数是1000的倍数,进行一次flush,如果行数超过65536,新开一个sheet,如果超过3个sheet,则新建一个文件。为了方便,把xlwt包装了一下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
|
转换网页特殊字符
由于网页也有自己独特的转义字符,在进行正则匹配的时候就有些麻烦。在官方文档中查到一个用字典替换的方案,私以为不错,拿来做了一些扩充。其中有一些是为保持正则的正确性。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
结
得出的经验差不多就是这些了。不过最后写出来的程序自已也不忍再看。风格很不好。一开始想着先写着试试。然后试着试着就不想改了。
最终的程序要跑很久,其中网络通信时间占了大部分。是不是可以考虑用多线程重构一下?想想,还是就这样吧。
相关文章:
python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据。正好之前学了python,练练手。 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了。 Unicode是一种编码方案,又称万国码…...

CSS的三大特性
🌟所属专栏:前端只因变凤凰之路🐔作者简介:rchjr——五带信管菜只因一枚😮前言:该系列将持续更新前端的相关学习笔记,欢迎和我一样的小白订阅,一起学习共同进步~👉文章简…...
Linux-scheduler之负载均衡(二)
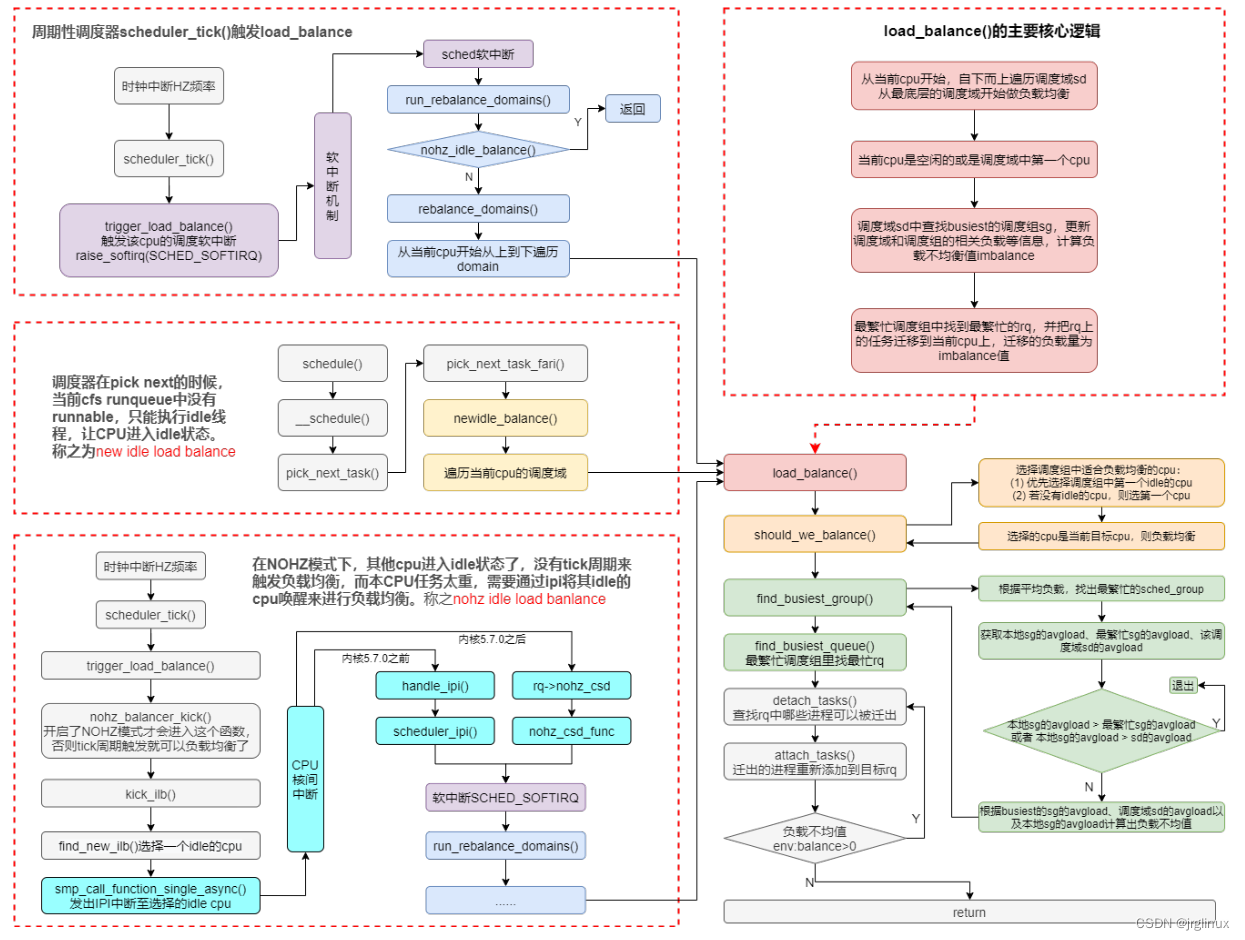
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sched_domain_topology_level {sched_domain_mask_f mask; //函数指针,用于指定某个SDTL的cpumask位图sched_domain_flags_f sd_flags; //函数指针,用于指定某个SD…...
VScode第三方插件打开sqlite数据库
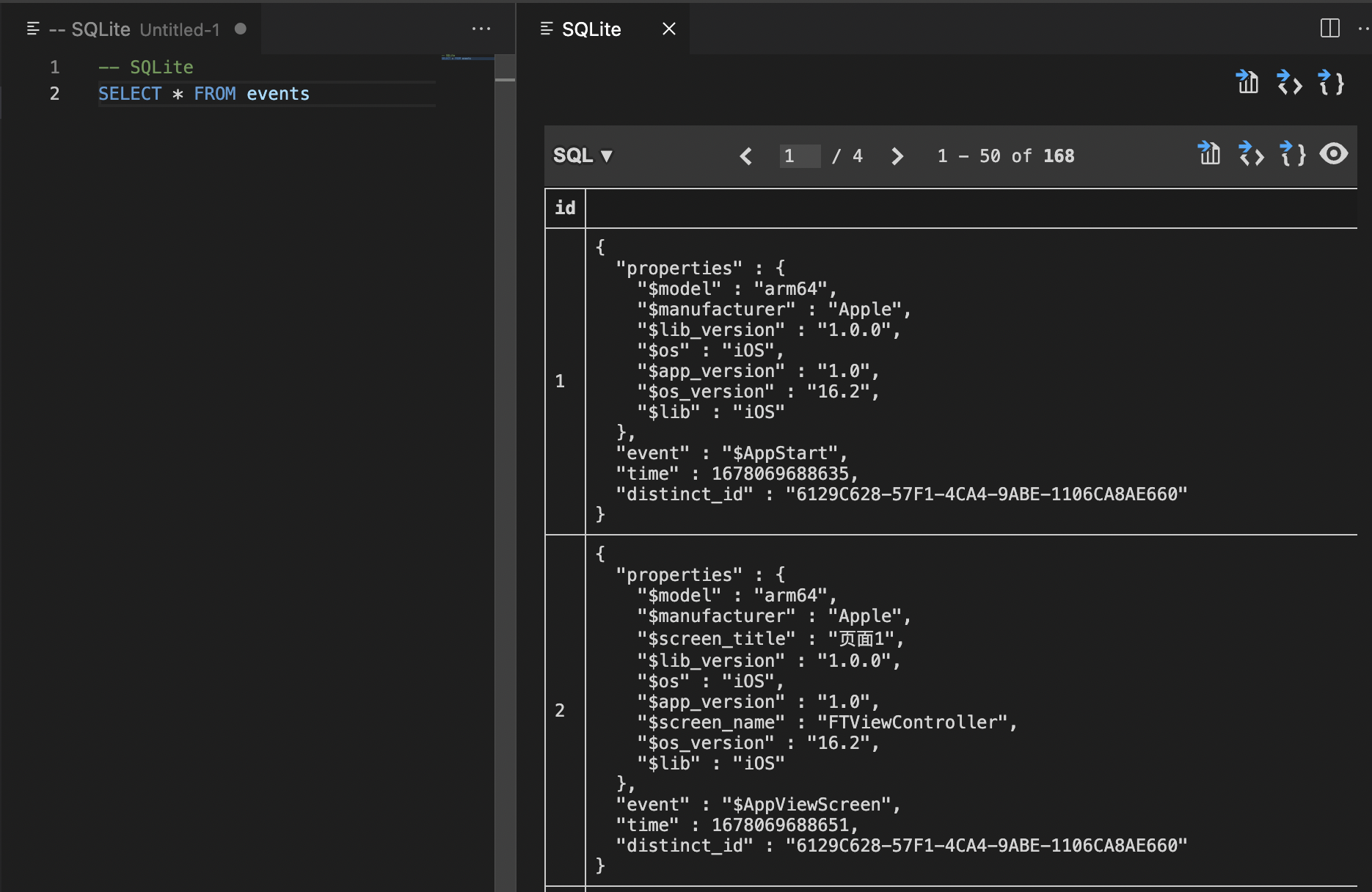
文章目录前言对比1.文本文件、表格软件打开2.专业软件3.pythonVScode 第三方库打开数据库1. 下载第三方库插件2.打开sqlite新建查询3.输入查询内容前言 最近在做的东西涉及SQLite数据库(一种常用在移动端的数据库类型,和mysql这些主流数据库也差不多&am…...

Kafka 监控
Kafka 监控主机监控JVM 监控集群监控监控 Kafka 客户端主机监控 主机监控 : 监控 Kafka 集群 Broker 所在的节点机器的性能 主机监控指标 : 机器负载 (Load) , CPU 使用率内存使用率 (空闲内存 , 已使用内存 (Used Memory) )磁盘 I/O 使用率 (读使用率/ 写使用率) , 网络 I/…...
MultipartFile与File的互转
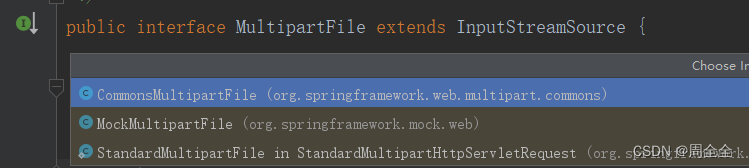
MultipartFile与File的互转前言MultipartFile转File1.FileUtils.copyInputStreamToFile转换2.multipartFile.transferTo(tempFile);3. (推荐)FileUtils.writeByteArrayToFile(file, multipartFile.getBytes());File转MultipartFile前言 需求是上传Excel文件并读取E…...
数据结构与算法基础-学习-15-二叉树
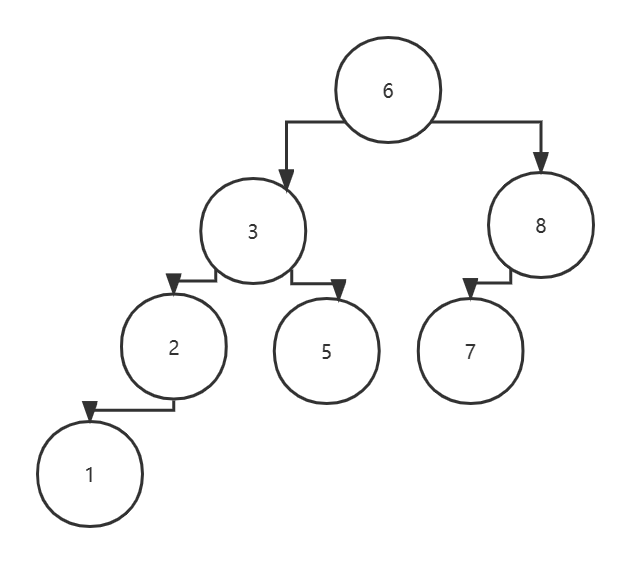
一、二叉树定义二叉树是N(N>0)个节点的有限集,它可能是空集或者由一个根节点及两棵互不相交的分别称作这个根的左子树和右子树的二叉树组成。二、二叉树特点1、每个节点最多两个孩子。(也就是二叉树的度小于等于2)2…...
接口测试要测试什么?
一. 什么是接口测试?为什么要做接口测试? 接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互…...

2023.03.12学习总结
项目部分写了内外菜单栏的伸缩,更新了导航栏,新增配置,scss变量 提交记录 学习了scss的使用和配置 ,设置了scss全局变量,组件样式 给element-plus配置了主题颜色,配置到了全局 http://t.csdn.cn/FhZYa …...

数据结构入门6-1(图)
目录 注 图的定义 图的基本术语 图的类型定义 图的存储结构 邻接矩阵 1. 邻接矩阵表示法 2. 使用邻接矩阵表示法创建无向网 3. 邻接矩阵表示法的优缺点 邻接表 1. 邻接表表示法 2. 通过邻接表表示法创建无向图 3. 邻接表表示法的优缺点 十字链表(有向…...
把C#代码上传到NuGet,大佬竟是我自己!!!
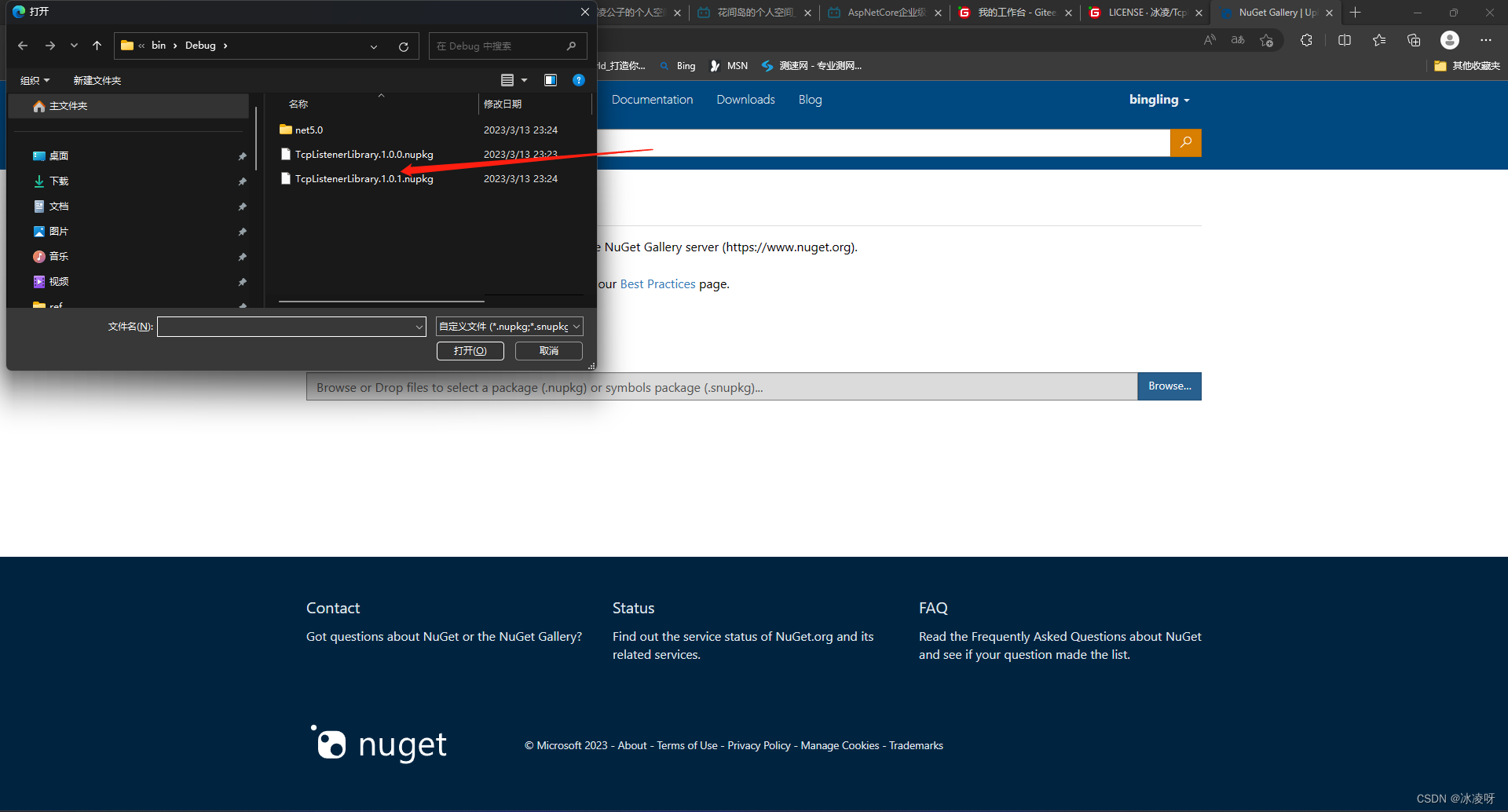
背景 刚发表完一篇博客总结自己写标准化C#代码的心历路程,立马就产生一个问题,就是我写好标准化代码后,一直存放磁盘的话,随着年月增加,代码越来越多,项目和版本的管理就会成为一个令我十分头疼的难题&…...

解决前端“\n”不换行问题
在日常开发过程中,换行显示是一种很常见的应用需求,但是偶然发现,有时候使用 "\n"并不会换行显示,只会被识别为空格,如下图。 通过上图可以看出,"\n"它被识别成了一个空格显示&#…...
Python打包成exe,文件太大问题解决办法(比保姆级还保姆级)
首先我要说一下,如果你不在乎大小,此篇直接别看了,因为我写过直接打包的,就多20M而已,这篇就别看了,点击查看不在乎大小直接打包这篇我觉得简单的令人发指 不废话,照葫芦画瓢就好 第1步&#…...

CSS弹性布局flex属性整理
1.align-items align-items属性:指定弹性布局内垂直方向的对齐方向。 常用属性: center 垂直居中展示 flex-start 头部对齐 flex-end 底部对齐 2. justify-content justify-content属性:属性(水平)对齐弹…...

14个你需要知道的实用CSS技巧
让我们学习一些实用的 CSS 技巧,以提升我们的工作效率。这些 CSS 技巧将帮助我们开发人员快速高效地构建项目。 现在,让我们开始吧。 1.CSS :in-range 和 :out-of-range 伪类 这些伪类用于在指定范围限制之内和之外设置输入样式。 (a) : 在范围内 如…...

【Flutter从入门到入坑之四】构建Flutter界面的基石——Widget
【Flutter从入门到入坑】Flutter 知识体系 【Flutter从入门到入坑之一】Flutter 介绍及安装使用 【Flutter从入门到入坑之二】Dart语言基础概述 【Flutter从入门到入坑之三】Flutter 是如何工作的 WidgetWidget 是什么呢?Widget 渲染过程WidgetElementRenderObjectR…...

中职网络空间安全windows渗透
目录 B-1:Windows操作系统渗透测试 1.通过本地PC中渗透测试平台Kali对服务器场景Windows进行系统服务及版本扫描渗透测试,并将该操作显示结果中Telnet服务对应的端口号作为FLAG提交;编辑 2.通过本地PC中渗透测试平台Kali对服务器场景Wind…...
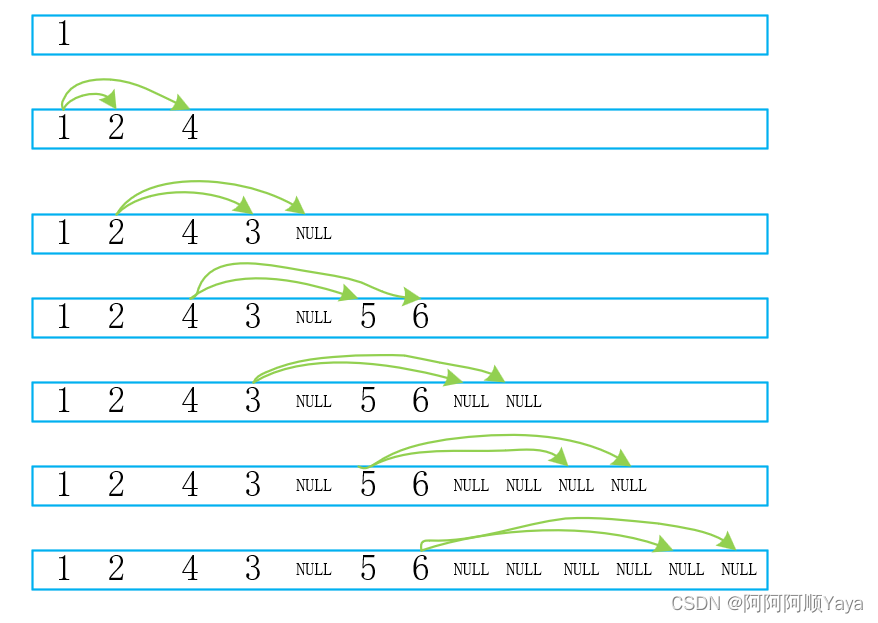
普通二叉树的操作
普通二叉树的操作1. 前情说明2. 二叉树的遍历2.1 前序、中序以及后序遍历2.1.1 前序遍历2.1.2 中序遍历、后序遍历2.2 题目练习2.2.1 求一棵二叉树的节点个数2.2.2 求一棵二叉树的叶节点个数2.2.3 求一棵二叉树第k层节点的个数2.2.4 求一棵二叉树的深度2.2.5 在一棵二叉树中查找…...

Oracle:递归树形结构查询功能
概要树状结构通常由根节点、父节点(PID)、子节点(ID)和叶节点组成。查询语法SELECT [LEVEL],* FROM table_name START WITH 条件1 CONNECT BY PRIOR 条件2 WHERE 条件3 ORDER BY 排序字段说明:LEVEL—伪列࿰…...

MongoDB数据库性能监控详解
目录一、MongoDB启动超慢1、启动日常卡住,根本不用为了截屏而快速操作,MongoDB启动真的超级慢~~2、启动MongoDB配置服务器,间歇性失败。3、查看MongoDB日志,分析“MongoDB启动慢”的原因。4、耗时“一小时”,MongoDB启…...

从锂电池热失控到锡须短路:高可靠性系统安全工程实践
1. 从“工程恐怖故事”到系统安全文化的反思最近在整理资料时,翻到一篇十多年前的旧文,标题叫《工程恐怖:机毁人亡》。文章汇集了几位航空与国防领域工程师亲历的、令人脊背发凉的真实事故案例。这些故事没有出现在主流新闻的头条,…...

ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略
ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Aux…...

Java——Character
Character1、Unicode基础2、检查code point和char3、code point与char的转换4、按code point处理char数组或序列5、字符属性6、字符转换1、Unicode基础 Unicode给世界上每个字符分配了一个编号,编号范围为0x000000~0x10FFFF。编号范围在0x0000ÿ…...

Gmail只读命令行工具gcli:云端自动化邮件查询与SSH隧道授权方案
1. 项目概述:一个专为自动化场景设计的Gmail只读命令行工具 如果你和我一样,经常需要在没有图形界面的云服务器上处理邮件查询任务,那你一定对Gmail API的授权流程深恶痛绝。传统的OAuth流程要求你在浏览器里点来点去,但服务器上哪…...

Arm CoreLink CMN-600硬件错误解析与解决方案
1. Arm CoreLink CMN-600硬件错误深度解析在复杂SoC设计中,互连架构的质量直接决定整个系统的稳定性和性能。作为Arm Neoverse平台的核心组件,CoreLink CMN-600(Coherent Mesh Network)承担着处理器集群、内存控制器和I/O设备之间…...

别再死记公式了!用复平面几何法直观理解Biquad滤波器设计
用复平面几何法直观理解Biquad滤波器设计 当你第一次接触数字滤波器时,那些复杂的差分方程和z变换公式是否让你望而生畏?作为音频处理领域的入门者,我曾花了整整两周时间试图理解一个简单的二阶滤波器公式,直到发现了复平面几何法…...

Jellyfin.Plugin.MetaShark配置详解:10个关键设置优化你的元数据刮削体验
Jellyfin.Plugin.MetaShark配置详解:10个关键设置优化你的元数据刮削体验 【免费下载链接】jellyfin-plugin-metashark jellyfin电影元数据插件 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metashark 想要让你的Jellyfin媒体库拥有丰富的…...

Hotkey Detective:Windows快捷键冲突终极解决方案,3分钟快速定位占用程序
Hotkey Detective:Windows快捷键冲突终极解决方案,3分钟快速定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/h…...

AI图像编辑中的性别擦除现象与视觉公平性测试
1. 项目概述:当AI“擦除”男性面孔时,我们到底在测试什么?“AI Erases Men Too: A Visual Test of Bias Across Four Leading Tools”——这个标题乍看像一则科技媒体的警示快讯,但背后是一次扎实、可复现、有明确方法论支撑的视觉…...

LiteLoaderQQNT插件加载器:从简单加载到企业级插件生态的完整进化指南
LiteLoaderQQNT插件加载器:从简单加载到企业级插件生态的完整进化指南 【免费下载链接】LiteLoaderQQNT QQNT 插件加载器:LiteLoaderQQNT —— 轻量 简洁 开源 福瑞 项目地址: https://gitcode.com/gh_mirrors/li/LiteLoaderQQNT LiteLoaderQQ…...