RDNet实战:使用RDNet实现图像分类任务(一)
论文提出的模型主要基于对传统DenseNet架构的改进和复兴,通过一系列创新设计,旨在提升模型性能并优化其计算效率,提出了RDNet模型。该模型的主要特点和改进点:
1. 强调并优化连接操作(Concatenation)
论文首先强调了DenseNet中连接操作(Concatenation)的重要性,并通过广泛的实验验证了连接操作在性能上能够超越传统的加法快捷连接(Additive Shortcut)。这一发现促使研究者们重新审视并优化DenseNet的连接机制。
2. 扩大中间通道维度
为了进一步提升模型性能,论文提出通过调整扩展比(Expansion Ratio, ER)来增大中间张量(Tensor)的尺寸,使其超过输入维度。传统方法中,ER主要用于调整输入和输出维度,但在这篇论文中,ER被重新设计为与输入维度成比例,即ER与增长率(Growth Rate, GR)解耦。这种设计使得在非线性处理之前能够更充分地丰富特征,同时为了管理由此产生的计算需求,将GR减半(例如从120减少到60),从而在不影响准确性的前提下控制计算量。
3. 记忆高效的DenseNet设计
为了优化DenseNet的架构设计,论文采用了更加内存高效的设计策略,通过丢弃无效组件并增强架构和块设计,同时保持DenseNet的核心连接机制不变。这种设计使得模型在保持高性能的同时,也减少了内存占用,提升了处理大规模数据集的能力。

本文使用RDNet模型实现图像分类任务,模型选择rdnet_tiny,在植物幼苗分类任务ACC达到了97%+。


通过这篇文章能让你学到:
- 如何使用数据增强,包括transforms的增强、CutOut、MixUp、CutMix等增强手段?
- 如何实现RDNet模型实现训练?
- 如何使用pytorch自带混合精度?
- 如何使用梯度裁剪防止梯度爆炸?
- 如何使用DP多显卡训练?
- 如何绘制loss和acc曲线?
- 如何生成val的测评报告?
- 如何编写测试脚本测试测试集?
- 如何使用余弦退火策略调整学习率?
- 如何使用AverageMeter类统计ACC和loss等自定义变量?
- 如何理解和统计ACC1和ACC5?
- 如何使用EMA?
如果基础薄弱,对上面的这些功能难以理解可以看我的专栏:经典主干网络精讲与实战
这个专栏,从零开始时,一步一步的讲解这些,让大家更容易接受。
安装包
安装timm
使用pip就行,命令:
pip install timm
mixup增强和EMA用到了timm
数据增强Cutout和Mixup
为了提高成绩我在代码中加入Cutout和Mixup这两种增强方式。实现这两种增强需要安装torchtoolbox。安装命令:
pip install torchtoolbox
Cutout实现,在transforms中。
from torchtoolbox.transform import Cutout
# 数据预处理
transform = transforms.Compose([transforms.Resize((224, 224)),Cutout(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
需要导入包:from timm.data.mixup import Mixup,
定义Mixup,和SoftTargetCrossEntropy
mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=12)criterion_train = SoftTargetCrossEntropy()
Mixup 是一种在图像分类任务中常用的数据增强技术,它通过将两张图像以及其对应的标签进行线性组合来生成新的数据和标签。
参数详解:
mixup_alpha (float): mixup alpha 值,如果 > 0,则 mixup 处于活动状态。
cutmix_alpha (float):cutmix alpha 值,如果 > 0,cutmix 处于活动状态。
cutmix_minmax (List[float]):cutmix 最小/最大图像比率,cutmix 处于活动状态,如果不是 None,则使用这个 vs alpha。
如果设置了 cutmix_minmax 则cutmix_alpha 默认为1.0
prob (float): 每批次或元素应用 mixup 或 cutmix 的概率。
switch_prob (float): 当两者都处于活动状态时切换cutmix 和mixup 的概率 。
mode (str): 如何应用 mixup/cutmix 参数(每个’batch’,‘pair’(元素对),‘elem’(元素)。
correct_lam (bool): 当 cutmix bbox 被图像边框剪裁时应用。 lambda 校正
label_smoothing (float):将标签平滑应用于混合目标张量。
num_classes (int): 目标的类数。
EMA
EMA(Exponential Moving Average)是指数移动平均值。在深度学习中的做法是保存历史的一份参数,在一定训练阶段后,拿历史的参数给目前学习的参数做一次平滑。具体实现如下:
import logging
from collections import OrderedDict
from copy import deepcopy
import torch
import torch.nn as nn_logger = logging.getLogger(__name__)class ModelEma:def __init__(self, model, decay=0.9999, device='', resume=''):# make a copy of the model for accumulating moving average of weightsself.ema = deepcopy(model)self.ema.eval()self.decay = decayself.device = device # perform ema on different device from model if setif device:self.ema.to(device=device)self.ema_has_module = hasattr(self.ema, 'module')if resume:self._load_checkpoint(resume)for p in self.ema.parameters():p.requires_grad_(False)def _load_checkpoint(self, checkpoint_path):checkpoint = torch.load(checkpoint_path, map_location='cpu')assert isinstance(checkpoint, dict)if 'state_dict_ema' in checkpoint:new_state_dict = OrderedDict()for k, v in checkpoint['state_dict_ema'].items():# ema model may have been wrapped by DataParallel, and need module prefixif self.ema_has_module:name = 'module.' + k if not k.startswith('module') else kelse:name = knew_state_dict[name] = vself.ema.load_state_dict(new_state_dict)_logger.info("Loaded state_dict_ema")else:_logger.warning("Failed to find state_dict_ema, starting from loaded model weights")def update(self, model):# correct a mismatch in state dict keysneeds_module = hasattr(model, 'module') and not self.ema_has_modulewith torch.no_grad():msd = model.state_dict()for k, ema_v in self.ema.state_dict().items():if needs_module:k = 'module.' + kmodel_v = msd[k].detach()if self.device:model_v = model_v.to(device=self.device)ema_v.copy_(ema_v * self.decay + (1. - self.decay) * model_v)加入到模型中。
#初始化
if use_ema:model_ema = ModelEma(model_ft,decay=model_ema_decay,device='cpu',resume=resume)# 训练过程中,更新完参数后,同步update shadow weights
def train():optimizer.step()if model_ema is not None:model_ema.update(model)# 将model_ema传入验证函数中
val(model_ema.ema, DEVICE, test_loader)
针对没有预训练的模型,容易出现EMA不上分的情况,这点大家要注意啊!
项目结构
RDNet_Demo
├─data1
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
├─models
│ └─rdnet.py
├─mean_std.py
├─makedata.py
├─train.py
└─test.py
mean_std.py:计算mean和std的值。
makedata.py:生成数据集。
train.py:训练RDNet模型
models:来源官方代码。
计算mean和std
为了使模型更加快速的收敛,我们需要计算出mean和std的值,新建mean_std.py,插入代码:
from torchvision.datasets import ImageFolder
import torch
from torchvision import transformsdef get_mean_and_std(train_data):train_loader = torch.utils.data.DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for X, _ in train_loader:for d in range(3):mean[d] += X[:, d, :, :].mean()std[d] += X[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())if __name__ == '__main__':train_dataset = ImageFolder(root=r'data1', transform=transforms.ToTensor())print(get_mean_and_std(train_dataset))
数据集结构:

运行结果:
([0.3281186, 0.28937867, 0.20702125], [0.09407319, 0.09732835, 0.106712654])
把这个结果记录下来,后面要用!
生成数据集
我们整理还的图像分类的数据集结构是这样的
data
├─Black-grass
├─Charlock
├─Cleavers
├─Common Chickweed
├─Common wheat
├─Fat Hen
├─Loose Silky-bent
├─Maize
├─Scentless Mayweed
├─Shepherds Purse
├─Small-flowered Cranesbill
└─Sugar beet
pytorch和keras默认加载方式是ImageNet数据集格式,格式是
├─data
│ ├─val
│ │ ├─Black-grass
│ │ ├─Charlock
│ │ ├─Cleavers
│ │ ├─Common Chickweed
│ │ ├─Common wheat
│ │ ├─Fat Hen
│ │ ├─Loose Silky-bent
│ │ ├─Maize
│ │ ├─Scentless Mayweed
│ │ ├─Shepherds Purse
│ │ ├─Small-flowered Cranesbill
│ │ └─Sugar beet
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
新增格式转化脚本makedata.py,插入代码:
import glob
import os
import shutilimage_list=glob.glob('data1/*/*.png')
print(image_list)
file_dir='data'
if os.path.exists(file_dir):print('true')#os.rmdir(file_dir)shutil.rmtree(file_dir)#删除再建立os.makedirs(file_dir)
else:os.makedirs(file_dir)from sklearn.model_selection import train_test_split
trainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)
train_dir='train'
val_dir='val'
train_root=os.path.join(file_dir,train_dir)
val_root=os.path.join(file_dir,val_dir)
for file in trainval_files:file_class=file.replace("\\","/").split('/')[-2]file_name=file.replace("\\","/").split('/')[-1]file_class=os.path.join(train_root,file_class)if not os.path.isdir(file_class):os.makedirs(file_class)shutil.copy(file, file_class + '/' + file_name)for file in val_files:file_class=file.replace("\\","/").split('/')[-2]file_name=file.replace("\\","/").split('/')[-1]file_class=os.path.join(val_root,file_class)if not os.path.isdir(file_class):os.makedirs(file_class)shutil.copy(file, file_class + '/' + file_name)
完成上面的内容就可以开启训练和测试了。
相关文章:
RDNet实战:使用RDNet实现图像分类任务(一)
论文提出的模型主要基于对传统DenseNet架构的改进和复兴,通过一系列创新设计,旨在提升模型性能并优化其计算效率,提出了RDNet模型。该模型的主要特点和改进点: 1. 强调并优化连接操作(Concatenation) 论文…...

Java小白入门到实战应用教程-介绍篇
writer:eleven 介绍 编程语言介绍 编程语言按照抽象层次和硬件交互的方式划分为低级编程语言和高级编程语言。 低级编程语言更接近计算机硬件层面,通常具有执行效率高的特点,但是由于注重计算机底层交互,所以编程难度相对较大。 高级编程…...

python脚本“文档”撰写——“诱骗”ai撰写“火火的动态”python“自动”脚本文档
“火火的动态”python“自动”脚本文档,又从ai学习搭子那儿“套”来,可谓良心质量👍👍。 (笔记模板由python脚本于2024年07月07日 15:15:33创建,本篇笔记适合喜欢钻研python和页面源码的coder翻阅) 【学习的细节是欢悦…...

若依 / ruoyi-ui:执行yarn dev 报错 esnext.set.difference.v2.js in ./src/utils/index.js
一、报错信息 These dependencies were not found: * core-js/modules/esnext.set.difference.v2.js in ./src/utils/index.js * core-js/modules/esnext.set.intersection.v2.js in ./src/utils/index.js * core-js/modules/esnext.set.is-disjoint-from.v2.js in ./src/utils…...

移动端Vant-list的二次封装,查询参数重置
Vant-list的二次封装 场景:在写项目需求的时候,移动端有用到vant-list组件。后续需求更新说要对列表数据页加搜索和筛选的功能。发现每次筛选完得在页面内手动重置一次查询参数。不方便,所以封了一层。 二次封装代码 <template><…...

SMU Summer 2024 Contest Round 2
[ABC357C] Sierpinski carpet - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 思路:通过因为图形的生成过程是完全一样的。可以通过递归,不断分形。函数process(x,y,k)定义为以坐标(x,y)为左上角,填充sqrt3(k)级的地毯。 int n; int c[800][800]; 默认全为…...

Qt:11.输入类控件(QLineEdit-单行文本输入控件、QTextEdit-多行文本输入控件、QComboBox-下拉列表的控件)
一、QLineEdit-单行文本输入控件: 1.1QLineEdit介绍: QLineEdit 是 Qt 库中的一个单行文本输入控件,不能换行。允许用户输入和编辑单行文本。 1.2属性介绍: inputMask 设置输入掩码,以限定输入格式。setInputMask(con…...

Qt 音频编程实战项目
一Qt 音频基础知识 QT multimediaQMediaPlayer 类:媒体播放器,主要用于播放歌曲、网络收音 机等功能。QMediaPlaylist 类:专用于播放媒体内容的列表。 二 音频项目实战程序 //版本5.12.8 .proQT core gui QT multimedia greate…...
C#委托事件的实现
1、事件 在C#中事件是一种特殊的委托类型,用于在对象之间提供一种基于观察者模式的通知机制。 1.1、事件的发送方定义了一个委托,委托类型的声明包含了事件的签名,即事件处理器方法的签名。 1.2、事件的订阅者可以通过运算符来注册事件处理器…...

Java策略模式在动态数据验证中的应用
在软件开发中,数据验证是一项至关重要的任务,它确保了数据的完整性和准确性,为后续的业务逻辑处理奠定了坚实的基础。然而,不同的数据来源往往需要不同的验证规则,如何在不破坏代码的整洁性和可维护性的同时࿰…...
)
【Linux】shell基础知识点(updating)
1.输出重定向2.多命令批量执行(; 、&&、 ||)3.脚本不同方式执行的区别(source、bash、sh、./)4.理解环境变量5.export6.引号的使用last.命令相关 1.输出重定向 3种数据流: stdin:标准输入…...

Python基础练习•二
# ## Python编程入门作业 # # ### 选择题 # 1. 假设等号右侧变量都已知的情况下,下列哪个语句在Python中是⾮法的?( B ) # A. x y z 1 # B. x (y z 1) # C. x, y y, x # D. x y # 2. 关于Python变量,下列…...

智慧科技照亮水利未来:深入剖析智慧水利解决方案如何助力水利行业实现高效、精准、可持续的管理
目录 一、智慧水利的概念与内涵 二、智慧水利解决方案的核心要素 1. 物联网技术:构建全面感知网络 2. 大数据与云计算:实现数据高效处理与存储 3. GIS与三维可视化:提升决策支持能力 4. 人工智能与机器学习:驱动决策智能化 …...

Vue3学习笔记(n.0)
vue指令之v-for 首先创建自定义组件(practice5.vue): <!--* Author: RealRoad1083425287qq.com* Date: 2024-07-05 21:28:45* LastEditors: Mei* LastEditTime: 2024-07-05 21:35:40* FilePath: \Fighting\new_project_0705\my-vue-app\…...
基于Spring Boot的在线考试系统
您好!我是专注于计算机技术研究的码农小野。如果您对在线考试系统感兴趣或有相关开发需求,欢迎随时联系我。 开发语言:Java 数据库:MySQL 技术:Spring Boot框架,Java技术 工具:Eclipse&…...

Day65 代码随想录打卡|回溯算法篇---组合总和II
题目(leecode T40): 给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的每个数字在每个组合中只能使用 一次 。 注意:解集不能包含…...

C++ 入门03:函数与作用域
往期回顾: C 入门01:初识 C-CSDN博客C 入门02:控制结构和循环-CSDN博客 一、前言 在前面的文章学习中,我们了解了C语言的基础,包括如何定义变量来存储数据,以及如何利用输入输出流实现程序与用户之间的无缝…...

在Linux/Debian/Ubuntu中出现“Could not get lock /var/lib/dpkg/lock-frontend”问题的解决办法
在Linux/Debian/Ubuntu中出现“Could not get lock /var/lib/dpkg/lock-frontend”问题的解决办法 在使用 apt 或 apt-get 进行软件包管理时,有时会遇到以下错误提示: Could not get lock /var/lib/dpkg/lock-frontend - open (11: Resource temporari…...

odoo中的钩子 Hooks
钩子 钩子(Hooks)是一种在特定时间点或特定事件发生时执行自定义代码的机制。它们允许开发者在不修改核心代码的情况下,为Odoo添加自定义功能或扩展现有功能。以下是关于Odoo钩子的一些关键点和常见用法: 一、钩子的类型 pre_i…...

05.C1W4.Machine Translation and Document Search
往期文章请点这里 目录 OverviewWhat you’ll be able to do!Learning Objectives Transforming word vectorsOverview of TranslationTransforming vectors Align word vectorsSolving for RFrobenius normFrobenius norm squaredGradient K nearest neighborsFinding the tr…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...
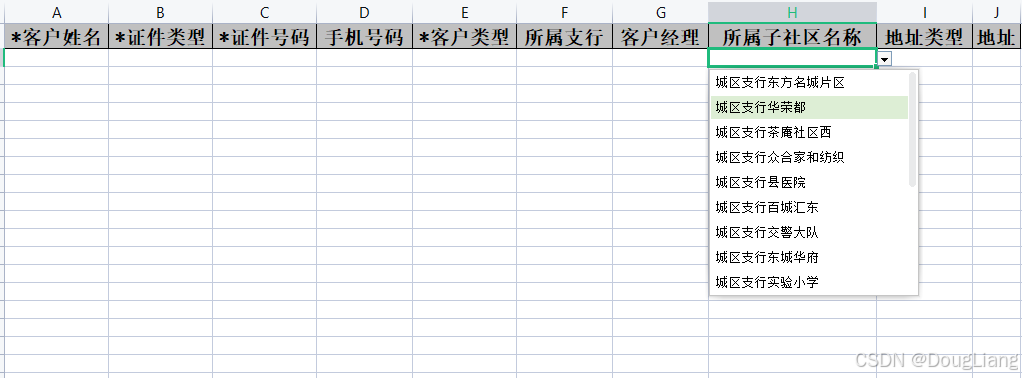
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...