【3】迁移学习模型
【3】迁移学习模型
文章目录
- 前言
- 一、安装相关模块
- 二、训练代码
- 2.1. 管理预训练模型
- 2.2. 模型训练代码
- 2.3. 可视化结果
- 2.4. 类别函数
- 总结
前言
主要简述一下训练代码
三叶青图像识别研究简概
一、安装相关模块
#xingyun的笔记本
print('============================xingyun的笔记本=============================')
%pip install d2l
%pip install Ipython
%pip install efficientnet_pytorch #(可选)
%pip install timm
二、训练代码
整段代码大致分为四块: 管理预训练模型、模型训练、可视化结果、类别函数调用。
2.1. 管理预训练模型
用于管理要使用的迁移学习模型(可添加),这里主要是对EfficientNet系列模型 、ResNet系列模型、MobileNet系列模型进行迁移学习。
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
import timm
from torch import nn
from d2l import torch as d2l
import re
from itertools import product
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
from efficientnet_pytorch import EfficientNet
from sklearn.model_selection import KFold
from torchvision.models import resnet101, resnet152, resnet18, resnet34, resnet50,mobilenet,mobilenet_v2,mobilenet_v3_large, mobilenet_v3_small, mobilenetv2, mobilenetv3class FineTuneModel:"""管理预训练模型:1. EfficientNet系列模型 3. ResNet系列模型4. MobileNet系列模型"""def __init__(self, devices, num_classes,model_name):self.devices = devicesself.num_classes = num_classesself.model_name = model_namedef get_efficientnet(self):"""微调EfficientNet模型。:param model_name: EfficientNet模型的版本,如'efficientnet-b0'到'efficientnet-b7'。:return: 微调后的模型。"""# 加载预训练的EfficientNet模型finetune_net = EfficientNet.from_pretrained(self.model_name)# 替换输出层num_ftrs = finetune_net._fc.in_featuresfinetune_net._fc = nn.Linear(num_ftrs, self.num_classes)# 将模型参数分配到设备上finetune_net = finetune_net.to(self.devices[0])# 冻结所有层(除了最后的全连接层)for name, param in finetune_net.named_parameters():if 'fc' not in name: # 不冻结全连接层param.requires_grad = False# 确保全连接层的参数可训练for param in finetune_net._fc.parameters():param.requires_grad = Truereturn finetune_netdef get_mobilenet(self):"""加载预训练的MobileNet模型并进行微调设置。'mobilenet','mobilenet_v2','mobilenet_v3_large', 'mobilenet_v3_small', 'mobilenetv2', 'mobilenetv3',"""# 加载预训练的MobileNetV2模型base_model_func = getattr(torchvision.models, self.model_name)base_model = base_model_func(pretrained=True)if self.model_name == "mobilenet_v2":num_features = base_model.classifier[-1].in_features# 定义一个新的分类头classifier = nn.Sequential(nn.Linear(num_features, 256),nn.ReLU(),nn.Linear(256, self.num_classes))# 替换原有的分类头base_model.classifier = classifierelse:# 获取最后一个卷积层的输出通道数量num_features = base_model.features[-1].out_channels# 定义一个新的分类头classifier = nn.Sequential(nn.Linear(num_features, 256),nn.ReLU(),nn.Linear(256, self.num_classes))# 替换原有的分类头base_model.classifier = classifier# 将模型参数分配到指定设备base_model = base_model.to(self.devices[0])# 冻结特征提取器的参数for name, param in base_model.named_parameters():if 'classifier' not in name: # 确保只冻结特征提取部分的参数param.requires_grad = Falsereturn base_modeldef get_resnet(self):#加载预训练的resnet模型"""resnet101, resnet152, resnet18, resnet34, resnet50"""# 从torchvision.models模块中动态获取模型base_model_func = getattr(torchvision.models, self.model_name)base_model = base_model_func(pretrained=True)num_features = base_model.fc.in_features# 定义一个新的分类头classifier = nn.Sequential(nn.Linear(num_features, 256),nn.ReLU(),nn.Linear(256,self.num_classes))# 替换原有的全连接层(分类头)base_model.fc = classifier# 将模型参数分配到指定设备base_model = base_model.to(self.devices[0])# 冻结特征提取器的参数for name, param in base_model.named_parameters():if 'fc' not in name: # 确保只冻结特征提取部分的参数param.requires_grad = Falsereturn base_model2.2. 模型训练代码
包括数据处理、模型训练、参数调优、模型保存等。
class MyImageClassifier:"""1. 数据处理2. 模型训练3. 参数调优4. 模型保存"""def __init__(self, data_dir, target_dir, batch_size, valid_ratio,train_folder,test_folder):self.data_dir = data_dirself.target_dir = target_dirself.batch_size = batch_sizeself.valid_ratio = valid_ratioself.train_folder = train_folderself.test_folder = test_folderdef read_csv_labels(self, fname):"""读取fname来给标签字典返回一个文件名"""with open(fname, 'r') as f:# 跳过文件头行(列名)lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]return dict(((name, label) for name, label in tokens))def copyfile(self,filename, target_dir):"""将文件复制到目标目录"""os.makedirs(target_dir, exist_ok=True)shutil.copy(filename, target_dir)def reorg_train_valid(self,labels):"""将验证集从原始的训练集中拆分出来"""# 训练数据集中样本最少的类别中的样本数n = collections.Counter(labels.values()).most_common()[-1][1]# 验证集中每个类别的样本数n_valid_per_label = max(1, math.floor(n * self.valid_ratio))label_count = {}for train_file in os.listdir(os.path.join(self.data_dir, self.train_folder)):label = labels[train_file.split('.')[0]]fname = os.path.join(self.data_dir, self.train_folder, train_file)self.copyfile(fname, os.path.join(self.target_dir, 'train_valid_test','train_valid', label))if label not in label_count or label_count[label] < n_valid_per_label:self.copyfile(fname, os.path.join(self.target_dir, 'train_valid_test','valid', label))label_count[label] = label_count.get(label, 0) + 1else:self.copyfile(fname, os.path.join(self.target_dir, 'train_valid_test','train', label))return n_valid_per_labeldef reorg_test(self):"""在预测期间整理测试集,以方便读取"""for test_file in os.listdir(os.path.join(self.data_dir, self.test_folder)):self.copyfile(os.path.join(self.data_dir, self.test_folder, test_file),os.path.join(self.target_dir, 'train_valid_test', 'test','unknown'))def reorg_san_data(self,labels_csv):labels = self.read_csv_labels(os.path.join(self.data_dir,labels_csv))self.reorg_train_valid(labels)self.reorg_test()print('# 训练样本 :', len(labels))print('# 类别 :', len(set(labels.values())))"""以上为数据整理函数"""def classes(self):class_to_idx = {}# 遍历数据集文件夹中的子文件夹(每个子文件夹代表一个类别)for idx, class_name in enumerate(sorted(os.listdir(os.path.join(self.target_dir, 'train_valid_test', 'valid')))):if class_name.startswith('.'):continueclass_dir = os.path.join(os.path.join(self.target_dir, 'train_valid_test', 'valid'), class_name) # 类别文件夹路径if os.path.isdir(class_dir):class_to_idx[idx] = class_nameprint(class_to_idx)print("============================")return class_to_idx#统计划分的训练集、验证集数量def count_samples(self):"""统计每个类别训练集和验证集的数量"""train_valid_test_dirs = ['train', 'valid']data_counts = {'class': []}for dir_name in train_valid_test_dirs:class_dir = os.path.join(self.target_dir, 'train_valid_test', dir_name)if dir_name not in data_counts:data_counts[dir_name] = []for class_name in os.listdir(class_dir):if class_name.startswith('.'):continueclass_sub_dir = os.path.join(class_dir, class_name)if os.path.isdir(class_sub_dir):if class_name not in data_counts['class']:data_counts['class'].append(class_name)for key in train_valid_test_dirs:if key not in data_counts:data_counts[key] = [0] * len(data_counts['class'])else:data_counts[key].append(0)data_counts[dir_name][data_counts['class'].index(class_name)] += len(os.listdir(class_sub_dir))df = pd.DataFrame(data_counts)return dfdef shuju_zq_jz(self,batch_size):#数据增强transform_train = torchvision.transforms.Compose([# 随机裁剪图像,所得图像为原始面积的0.08~1之间,高宽比在3/4和4/3之间。# 然后,缩放图像以创建224x224的新图像torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0),ratio=(3.0/4.0, 4.0/3.0)),torchvision.transforms.RandomHorizontalFlip(),# 随机更改亮度,对比度和饱和度torchvision.transforms.ColorJitter(brightness=0.4,contrast=0.4,saturation=0.4),#转换为张量格式torchvision.transforms.ToTensor(),# 标准化图像的每个通道torchvision.transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])#测试时,我们只使用确定性的图像预处理操作transform_test = torchvision.transforms.Compose([torchvision.transforms.Resize(256),# 从图像中心裁切224x224大小的图片torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])#读取整理后的含原始图像文件的数据集train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(os.path.join(self.target_dir, 'train_valid_test', folder),transform=transform_train) for folder in ['train', 'train_valid']]valid_ds, test_ds = [torchvision.datasets.ImageFolder(os.path.join(self.target_dir, 'train_valid_test', folder),transform=transform_test) for folder in ['valid', 'test']]train_iter, train_valid_iter = [torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, drop_last=True)for dataset in (train_ds, train_valid_ds)]valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,drop_last=False)test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,drop_last=False)return train_iter,valid_iter,test_iter,train_valid_iter"""以上为数据处理函数"""#微调预训练模型def get_net(self,devices,num_classes,model_name,model_leibie):fine_tune_model = FineTuneModel(d2l.try_all_gpus(), num_classes=num_classes,model_name = model_name) # 使用微调模型if model_leibie == 'get_efficientnet':base_model = fine_tune_model.get_efficientnet()elif model_leibie == 'get_mobilenet':base_model = fine_tune_model.get_mobilenet()elif model_leibie == 'get_resnet':base_model = fine_tune_model.get_resnet()return base_modeldef evaluate_loss(self,data_iter, net, devices):loss = nn.CrossEntropyLoss(reduction='none') #reduction='none'表示不对损失进行平均或求和,而是返回每个样本的损失值。l_sum, n = 0.0, 0for features, labels in data_iter:features, labels = features.to(devices[0]), labels.to(devices[0])outputs = net(features)l = loss(outputs, labels)l_sum += l.sum()n += labels.numel() #累加样本数量到n中,labels.numel()返回标签张量中元素的个数return (l_sum / n).to('cpu') #计算所有样本的平均损失值,并将其移动到CPU上返回def train(self, net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay):net = nn.DataParallel(net, device_ids=devices).to(devices[0])trainer = torch.optim.SGD((param for param in net.parameters() if param.requires_grad), lr=lr, momentum=0.9, weight_decay=wd)scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)num_batches, timer = len(train_iter), d2l.Timer()legend = ['train loss', 'train acc', 'valid loss', 'valid acc'] # Add valid loss and accanimator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=legend)loss = nn.CrossEntropyLoss(reduction='none')best_acc = 0best_model_path = ""measures_list = []examples_sec_list = []for epoch in range(num_epochs):metric = d2l.Accumulator(3)net.train() # Switch to training modefor i, (features, labels) in enumerate(train_iter):timer.start()features, labels = features.to(devices[0]), labels.to(devices[0])trainer.zero_grad()output = net(features)l = loss(output, labels).sum()l.backward()trainer.step()metric.add(l, labels.shape[0], d2l.accuracy(output, labels))timer.stop()if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches, (metric[0] / metric[1], metric[2] / metric[1], None, None))measures = f'train loss {metric[0] / metric[1]:.3f}, train acc {metric[2] / metric[1]:.3f}'if valid_iter is not None:net.eval() # Switch to evaluation modevalid_metric = d2l.Accumulator(3)with torch.no_grad():for valid_features, valid_labels in valid_iter:valid_features, valid_labels = valid_features.to(devices[0]), valid_labels.to(devices[0])valid_output = net(valid_features)valid_l = loss(valid_output, valid_labels).sum()valid_metric.add(valid_l, valid_labels.shape[0], d2l.accuracy(valid_output, valid_labels))valid_acc = valid_metric[2] / valid_metric[1]animator.add(epoch + 1, (None, None, valid_metric[0] / valid_metric[1], valid_acc))measures += f', valid loss {valid_metric[0] / valid_metric[1]:.3f}, valid acc {valid_acc:.3f}'if valid_acc > best_acc:best_acc = valid_accbest_model_path = f'model_bests.pth'torch.save(net, best_model_path)print(f"Best model saved to {best_model_path} with accuracy {best_acc:.3f}")measures_list.append(measures)examples_sec = f'epoch {epoch}, {metric[1] * num_epochs / timer.sum():.1f} examples/sec on {str(devices)}'examples_sec_list.append(examples_sec)print(f'epoch {epoch}, ' + measures + f'\n{metric[1] * num_epochs / timer.sum():.1f} examples/sec on {str(devices)}')scheduler.step()for i, measure in enumerate(measures_list):print(f"Epoch {(i+1)}: {measure}")print(examples_sec_list)return measures_list, examples_sec_listdef get_valid_acc(self,measures):return float(re.search(r'valid acc (\d+\.\d+)', measures).group(1))# 训练参数调优def train_parameter_tuning(self, param_grid,num_classes,batch_size,model_name,model_leibie):# 使用网格搜索来搜索最佳超参数组合best_accuracy = 0best_params = None# 初始化列表,用于存储包含验证准确率和参数的元组 acc_param_list = [] measures_lt = []for params in product(*param_grid.values()):param_dict = dict(zip(param_grid.keys(), params))print("Training with params:", param_dict)# 创建和训练模型net = self.get_net(d2l.try_all_gpus(),num_classes,model_name,model_leibie)train_iter,valid_iter = self.shuju_zq_jz(batch_size)[0],self.shuju_zq_jz(batch_size)[1]measures_list,examples_sec_list = self.train(net, train_iter, valid_iter, **param_dict,devices = d2l.try_all_gpus())# 在验证集上评估模型性能# 使用正则表达式提取valid acc对应的数值best_measures = max(measures_list, key=self.get_valid_acc)valid_acc = float(re.search(r'valid acc (\d+\.\d+)', best_measures).group(1))print(best_measures)# 将验证准确率和参数字典合并为一个元组,并添加到列表中 acc_param_list.append((valid_acc, param_dict)) measures_lt.append(best_measures)# net.load_state_dict(torch.load("model_best.pth")) # 加载最佳模型net = torch.load('model_bests.pth')if valid_acc > best_accuracy:best_accuracy = valid_accbest_params = param_dictbest_net = net # 这里的最佳网络是从最佳模型加载的for i,measure in enumerate(measures_lt):print(f"Trial {i+1}:")print(measure)print("========================================================")print()best_acc_index = max(range(len(acc_param_list)), key=lambda i: acc_param_list[i][0]) best_accuracy = acc_param_list[best_acc_index][0] best_params = acc_param_list[best_acc_index][1] print("================================================")print("Best accuracy:", best_accuracy) print("Best params:", best_params) print()for i, (acc, params) in enumerate(acc_param_list): print(f"Trial {i+1}: valid acc {acc}, params {params}")return best_net # 这是从最佳模型加载的网络"""以上为模型训练以及参数调优函数"""#保存训练得到的模型权重文件def save_model(self,model_path,model_path_zheng,best_net):torch.save(best_net.state_dict(), model_path) #只保存模型的参数torch.save(best_net, model_path_zheng) #保存整个模型print(f"Model saved to {model_path}")2.3. 可视化结果
包括查看模型在验证集上的每一类的准确率、分类报告、混淆矩阵、AUC-ROC曲线
class ViewResult:"""查看训练效果:1. 查看每一类在验证集上的准确率2. 查看precision,recall和f1-score(即分类报告)3. 查看混淆矩阵4. 查看AUC-ROC曲线"""def __init__(self, best_net, valid_iter, devices, classes):self.net = best_netself.valid_iter = valid_iterself.devices = devicesself.classes = classesself.num_classes = len(classes)def view_result(self):print(self.num_classes)class_correct = [0.] * self.num_classesclass_total = [0.] * self.num_classesy_test, y_pred = [], []X_test = []with torch.no_grad():for images, labels in self.valid_iter:X_test.extend([_ for _ in images])outputs = self.net(images.to(self.devices[0]))_, predicted = torch.max(outputs, 1)predicted = predicted.cpu()c = (predicted == labels).squeeze()for i, label in enumerate(labels):class_correct[label] += c[i].item()class_total[label] += 1y_pred.extend(predicted.numpy())y_test.extend(labels.cpu().numpy())for i in range(self.num_classes):if class_total[i] != 0:accuracy = 100 * class_correct[i] / class_total[i]else:accuracy = 0print(f"Accuracy of {self.classes[i]:5s}: {accuracy:2.0f}%")#分类报告try:cr = classification_report(y_test, y_pred, target_names=list(self.classes.values()))print(cr)except Exception as e:print("An error occurred while generating the classification report:", str(e))#混淆矩阵cm = confusion_matrix(y_test, y_pred)labels = pd.DataFrame(cm).applymap(lambda v: f"{v}" if v != 0 else f"")plt.figure(figsize=(25, 20))sns.heatmap(cm, annot=labels, fmt='s', xticklabels=self.classes.items(), yticklabels=self.classes.items(), linewidths=0.1)plt.show()def evaluate_roc(self, num_classes):self.net.eval()y_true = []y_score = []for X, y in self.valid_iter:X, y = X.to(self.devices[0]), y.to(self.devices[0])y_true.append(y.cpu().numpy())y_score.append(self.net(X).detach().cpu().numpy())y_true = np.concatenate(y_true)y_score = np.concatenate(y_score)fpr = dict()tpr = dict()roc_auc = dict()for i in range(num_classes):y_true_i = np.where(y_true == i, 1, 0)y_score_i = y_score[:, i]fpr[i], tpr[i], _ = roc_curve(y_true_i, y_score_i)roc_auc[i] = auc(fpr[i], tpr[i])plt.figure(figsize=(15, 15))colors = list(mcolors.CSS4_COLORS.values())colors = colors[:num_classes]for i in range(num_classes):plt.plot(fpr[i], tpr[i], color=colors[i], lw=2, label=f'Class {i}, AUC = {roc_auc[i]:.2f}')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver Operating Characteristic for Multi-class Classification')plt.legend(loc="lower right")plt.show()
2.4. 类别函数
调用之前所定义的类,实现不同分类类别的模型的训练
def leibie_class(leibie,num_classes,batch_size,valid_ratio,param_grid,model_path,target_dir,model_name,model_leibie,train_folder,test_folder,model_path_zheng):"""leibie: #填写是几分类的标签文件,如要进行十分类,则填写labels.csv;要进行五分类,则填写labels_5.csv;要进行二分类,填写labels_2.csv.num_classes : #填写与leibie对应的类别数字,如要进行十分类,填写数字10,以此类推。batch_size : #批量大小,即每次处理的样本数量。valid_ratio : #验证集所占比例,如为0.3,则代表验证集占比为30%;即验证集:训练集==3:7。以此类推param_grid : #定义要调整的参数范围,通过网格搜索,遍历出最佳模型,获取对应的参数。model_path : #最佳模型权重文件保存路径,如'/kaggle/working/model_xcy_shi_1.pth',可以更改'/model_xcy_shi_1.pth',前面的‘/kaggle/working/’不能改变。target_dir : #整理后目标文件存放的目录,如‘/kaggle/working/my_directory_shi’,代表是按十分类整理的文件;‘/kaggle/working/my_directory_wu’则代表是按五分类整理的文件。以此类推。model_name : #加载模型的名字。例如:'resnet34'model_leibie : #加载模型所属类别函数。例如: 'get_resnet'train_folder : #原始训练集存放文件夹test_folder : #原始测试集存放文件夹model_path_zheng : #完整模型存放路径"""data_dir = "/kaggle/input/sanyeqing/" #存放原始数据的目录image_classifier = MyImageClassifier(data_dir, target_dir, batch_size, valid_ratio,train_folder,test_folder) #图像分类训练模型类的实例化#调用类中的函数:image_classifier.reorg_san_data(leibie) #十分类(labels.csv为十分类,labels_5.csv为五分类......)valid_iter=image_classifier.shuju_zq_jz(batch_size)[1] #数据增强处理函数,class_to_idx=image_classifier.classes() #返回分类标签与索引对应函数print(class_to_idx)best_net = image_classifier.train_parameter_tuning(param_grid,num_classes,batch_size,model_name,model_leibie) #十分类(10为十分类,5则为五分类......)# print("===================================================")
# print("最终的保存模型:")
# image_classifier.save_model(model_path,model_path_zheng,best_net)
# print();print()#训练结果可视化:
# result_viewer = ViewResult(best_net, valid_iter, devices=d2l.try_all_gpus(), classes=class_to_idx)
# result_viewer.view_result()
# result_viewer.evaluate_roc(num_classes)# 使用示例
if __name__ == '__main__':# 定义要调整的参数范围param_grid = {'num_epochs': [201],'lr': [1e-4],'wd': [1e-4],'lr_period': [2],'lr_decay': [1]}print("这是省份分类:")leibie_class("labels_hun_finally_2.csv",num_classes=3,batch_size=128,valid_ratio=0.2,param_grid=param_grid,
# model_path='/kaggle/working/model_wht_wu.pth',model_path=None,target_dir='/kaggle/working/my_directory_er',model_name='mobilenet_v3_large',model_leibie='get_mobilenet',train_folder = 'train_hun_finally',test_folder='test_hun_finally',model_path_zheng=None) #省份分类
总结
主要是运用迁移学习的方法,将预训练模型在自定义的数据集上进行训练。
2024/6/12
相关文章:

【3】迁移学习模型
【3】迁移学习模型 文章目录 前言一、安装相关模块二、训练代码2.1. 管理预训练模型2.2. 模型训练代码2.3. 可视化结果2.4. 类别函数 总结 前言 主要简述一下训练代码 三叶青图像识别研究简概 一、安装相关模块 #xingyun的笔记本 print(xingyun的笔记本) %pip install d2l %…...

【工具分享】FOFA——网络空间测绘搜索引擎
文章目录 FOFA介绍FOFA语法其他引擎 FOFA介绍 FOFA官网:https://fofa.info/ FOFA(Fingerprinting Organizations with Advanced Tools)是一款网络空间测绘的搜索引擎,它专注于帮助用户收集和分析互联网上的设备和服务信息。FOFA…...

[嵌入式 C 语言] 按位与、或、取反、异或
若协议中如下图所示: 注意: 长度为1,表示1个字节,也就是0xFF,也就是 1111 1111 (这里0xFF只是单纯表示一个数,也可以是其他数,这里需要注意的是1个字节的意思) 一、按位…...

Android --- 运行时Fragment如何获取Activity中的数据,又如何将数据传递到Activity中呢?
1.通过 getActivity() 方法获取 Activity 实例: 在 Fragment 中,可以通过 getActivity() 方法获取当前 Fragment 所依附的 Activity 实例。然后可以调用 Activity 的公共方法或者直接访问 Activity 的字段来获取数据。 // 在 Fragment 中获取 Activity…...
-- Java8 stream的 orElse(null) 和 orElseGet(null))
Java后端开发(十三)-- Java8 stream的 orElse(null) 和 orElseGet(null)
orElse(null)表示如果一个都没找到返回null。【orElse()中可以塞默认值。如果找不到就会返回orElse中你自己设置的默认值。】 orElseGet(null)表示如果一个都没找到返回null。【orElseGet()中可以塞默认值。如果找不到就会返回orElseGet中你自己设置的默认值。】 区别就…...

L2 LangGraph_Components
参考自https://www.deeplearning.ai/short-courses/ai-agents-in-langgraph,以下为代码的实现。 这里用LangGraph把L1的ReAct_Agent实现,可以看出用LangGraph流程化了很多。 LangGraph Components import os from dotenv import load_dotenv, find_do…...

09.C2W4.Word Embeddings with Neural Networks
往期文章请点这里 目录 OverviewBasic Word RepresentationsIntegersOne-hot vectors Word EmbeddingsMeaning as vectorsWord embedding vectors Word embedding processWord Embedding MethodsBasic word embedding methodsAdvanced word embedding methods Continuous Bag-…...
硅谷甄选二(登录)
一、登录路由静态组件 src\views\login\index.vue <template><div class"login_container"><!-- Layout 布局 --><el-row><el-col :span"12" :xs"0"></el-col><el-col :span"12" :xs"2…...

scipy库中,不同应用滤波函数的区别,以及FIR滤波器和IIR滤波器的区别
一、在 Python 中,有多种函数可以用于应用 FIR/IIR 滤波器,每个函数的使用场景和特点各不相同。以下是一些常用的 FIR /IIR滤波器应用函数及其区别: from scipy.signal import lfiltery lfilter(fir_coeff, 1.0, x)from scipy.signal impo…...

简谈设计模式之建造者模式
建造者模式是一种创建型设计模式, 旨在将复杂对象的构建过程与其表示分离, 使同样的构建过程可以构建不同的表示. 建造者模式主要用于以下情况: 需要创建的对象非常复杂: 这个对象由多个部分组成, 且这些部分需要一步步地构建不同的表示: 通过相同的构建过程可以生成不同的表示…...

力扣 hot100 -- 动态规划(下)
目录 💻最长递增子序列 AC 动态规划 AC 动态规划(贪心) 二分 🏠乘积最大子数组 AC 动规 AC 用 0 分割 🐬分割等和子集 AC 二维DP AC 一维DP ⚾最长有效括号 AC 栈 哨兵 💻最长递增子序列 300. 最长递增子序列…...
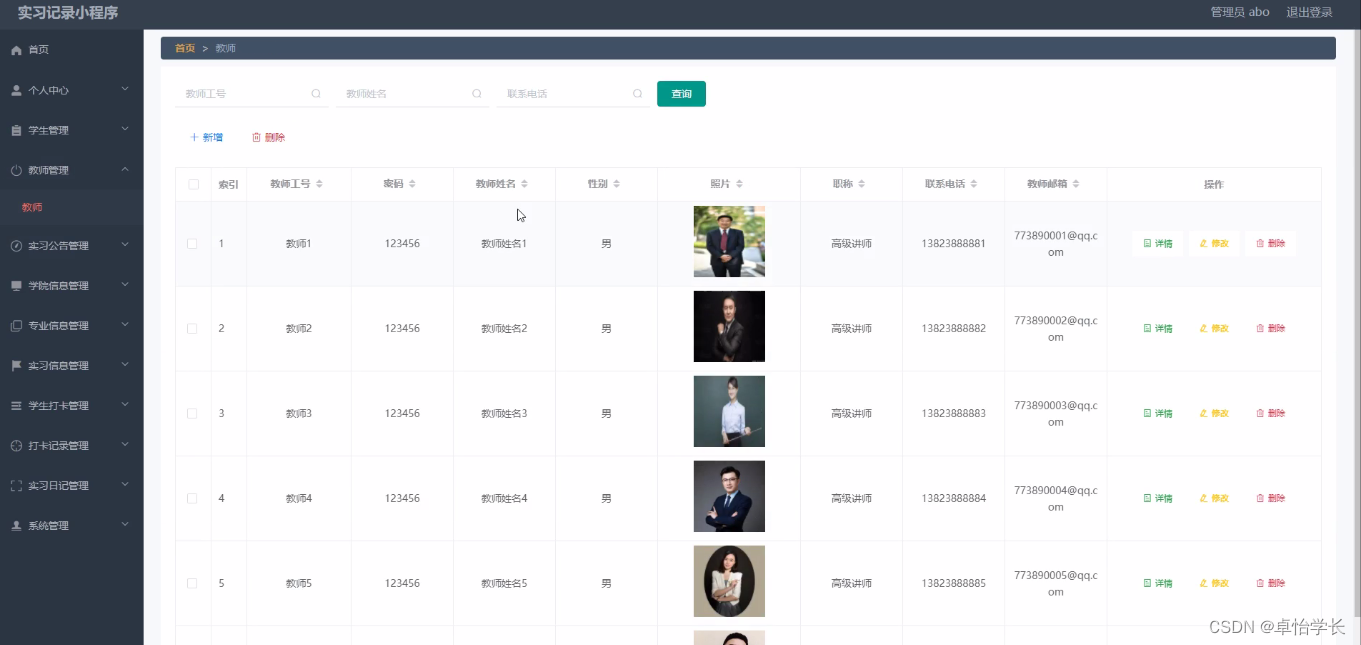
【计算机毕业设计】018基于weixin小程序实习记录
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

力扣之有序链表去重
删除链表中的重复元素,重复元素保留一个 p1 p2 1 -> 1 -> 2 -> 3 -> 3 -> null p1.val p2.val 那么删除 p2,注意 p1 此时保持不变 p1 p2 1 -> 2 -> 3 -> 3 -> null p1.val ! p2.val 那么 p1,p2 向后移动 p1 …...

Apache配置与应用(优化apache)
Apache配置解析(配置优化) Apache链接保持 KeepAlive:决定是否打开连接保持功能,后面接 OFF 表示关闭,接 ON 表示打开 KeepAliveTimeout:表示一次连接多次请求之间的最大间隔时间,即两次请求之间…...
怎么将3张照片合并成一张?这几种拼接方法很实用!
怎么将3张照片合并成一张?在我们丰富多彩的日常生活里,是否总爱捕捉那些稍纵即逝的美好瞬间,将它们定格为一张张珍贵的图片?然而,随着时间的推移,这些满载回忆的宝藏却可能逐渐演变成一项管理挑战ÿ…...
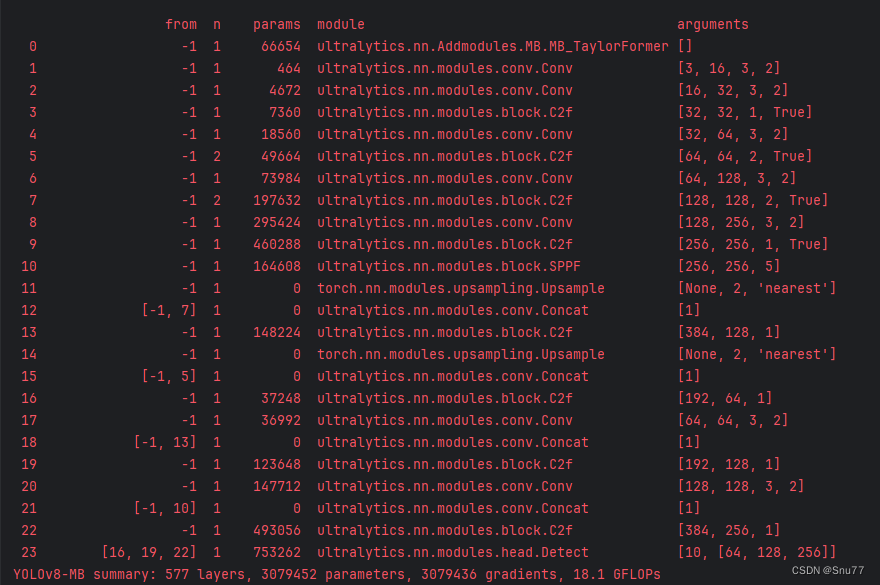
YOLOv10改进 | 图像去雾 | MB-TaylorFormer改善YOLOv10高分辨率和图像去雾检测(ICCV,全网独家首发)
一、本文介绍 本文给大家带来的改进机制是图像去雾MB-TaylorFormer,其发布于2023年的国际计算机视觉会议(ICCV)上,可以算是一遍比较权威的图像去雾网络, MB-TaylorFormer是一种为图像去雾设计的多分支高效Transformer…...
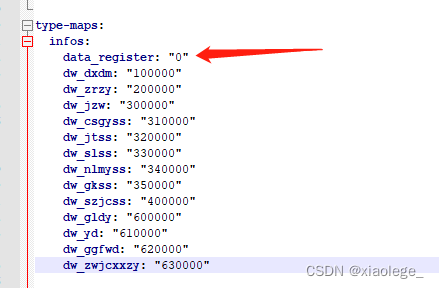
spring boot读取yml配置注意点记录
问题1:yml中配置的值加载到代码后值变了。 现场yml配置如下: type-maps:infos:data_register: 0ns_xzdy: 010000ns_zldy: 020000ns_yl: 030000ns_jzjz: 040000ns_ggglyggfwjz: 050000ns_syffyjz: 060000ns_gyjz: 070000ns_ccywljz: 080000ns_qtjz: 090…...

电子电气架构 --- 关于DoIP的一些闲思 下
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

Java getSuperclass和getGenericSuperclass
1.官方API对这两个方法的介绍 getSuperclass : 返回表示此 Class 所表示的实体(类、接口、基本类型或 void)的超类的 Class。如果此 Class 表示 Object 类、一个接口、一个基本类型或 void,则返回 null。如果此对象表示一个数组类ÿ…...

ARM功耗管理标准接口之ACPI
安全之安全(security)博客目录导读 思考:功耗管理有哪些标准接口?ACPI&PSCI&SCMI? Advanced Configuration and Power Interface Power State Coordination Interface System Control and Management Interface ACPI可以被理解为一…...

EDA工程师成长与验证技术演进:从算法到芯片的实践闭环
1. 从算法到芯片:一位EDA工程师的成长路径解析在半导体这个行当里待久了,你会发现,那些真正能把工具做“透”、把流程理“顺”的人,往往自己就亲手“焊”过板子、调过RTL、追过时序违例。Prakash Narain的故事,就是一个…...

CES 2016行业转向:从酷炫到实用,安全与服务成核心
1. 从“酷炫”到“实用”:CES 2016的行业转向解析每年一月的拉斯维加斯,对于科技行业而言,都像是一场盛大的朝圣。CES(国际消费电子展)不仅是新品发布的舞台,更是行业风向的晴雨表。2016年的CES,…...

开源技能图谱平台gotalab/skillport:构建可视化知识大脑的实战指南
1. 项目概述:一个技能图谱与知识管理的开源利器 在信息爆炸的时代,无论是个人学习成长,还是团队知识沉淀,我们常常面临一个核心痛点: 知识是零散的、孤立的,难以形成体系,更难以高效复用 。你…...

OpenCV Aruco码检测全流程拆解:不只是二维码,更是计算机视觉的“标尺”
OpenCV ArUco码检测全流程拆解:从原理到工程优化的视觉标尺实践 在计算机视觉领域,标记检测一直是连接虚拟信息与现实世界的重要桥梁。当我们谈论ArUco码时,很多人首先联想到的是其作为二维码近亲的身份,但它的真正价值远不止于此…...

GLM-ASR开源语音识别引擎:基于GLM架构的端到端实践指南
1. 项目概述:一个开源的、基于GLM架构的语音识别引擎最近在语音识别(ASR)这个圈子里,一个名为“GLM-ASR”的开源项目引起了我的注意。它来自zai-org组织,顾名思义,其核心是将自然语言处理领域大放异彩的GLM…...

前端自定义光标系统:从原理到工程实践
1. 项目概述:一个可深度定制的网页光标系统最近在做一个前端项目时,遇到了一个挺有意思的需求:用户希望网页上的光标不仅仅是默认的箭头或小手,而是能根据不同的交互状态、页面区域甚至用户偏好,动态切换成各种自定义的…...

SAP顾问实战笔记:手把手配置OBYC,搞定采购收货到发票校验的自动记账
SAP财务自动化实战:从采购收货到发票校验的OBYC全链路配置指南 当财务部门每月需要处理上千笔采购业务时,手工记账不仅效率低下,还容易出错。SAP系统中的OBYC配置正是解决这一痛点的关键——它能实现从采购收货到发票校验的全自动会计凭证生成…...

国电智深DCS污水处理自动控制组态与模糊PID优化【附方案】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)基于EDPF-NT的三容水箱液位模糊PID控制与改进PSO优化…...

基于Qlearning强化学习和人工势场融合算法的无人机航迹规划matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

魔兽争霸3终极优化工具:5分钟搞定所有兼容性问题
魔兽争霸3终极优化工具:5分钟搞定所有兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电脑上的各种问…...