大数据基础:Hadoop之MapReduce重点架构原理

文章目录
Hadoop之MapReduce重点架构原理
一、MapReduce概念
二、MapReduce 编程思想
2.1、Map阶段
2.2、Reduce阶段
三、MapReduce处理数据流程
四、MapReduce Shuffle
五、MapReduce注意点
六、MapReduce的三次排序
Hadoop之MapReduce重点架构原理
一、MapReduce概念
MapReduce是Hadoop生态中的计算框架,用于大规模数据集的并行计算。
二、MapReduce 编程思想
2.1、Map阶段
在Map阶段中,输入数据被分割成若干个独立的块,并由多个Mapper任务并行处理,每个Mapper任务都会执行用户定义的map函数,将输入数据转换成一系列键-值对的形式(Key-Value Pairs),这些键-值对被中间存储,以供Reduce阶段使用。
Map阶段主要是对数据进行映射变换,读取一条数据可以返回一条或者多条K,V格式数据。
2.2、Reduce阶段
在Reduce阶段中,所有具有相同键的键-值对会被分配到同一个Reducer任务上,Reducer任务会执行用户定义的reduce函数,对相同键的值进行聚合、汇总或其他操作,生成最终的输出结果,Reduce阶段也可以由多个Reduce Task并行执行。
Reduce阶段主要对相同key的数据进行聚合,最终对相同key的数据生成一个结果,最终写出到磁盘文件中。
三、MapReduce处理数据流程
-
首先MapReduce会将处理的数据集划分成多个split,split划分是逻辑上进行划分,而非物理上的切分,每个split默认与Block块大小相同,每个split由1个map task进行处理。
-
map task以行为单位读取split中的数据,将数据转换成K,V格式数据,根据Key计算出本条数据应该写出的分区号,最终在内部得到(K,V,P)格式数据写入到当前map task 所在的物理节点磁盘,便于后续reduce task的处理。
-
为了避免每条数据都产生一次IO,MapReduce 引入了“环形缓冲区”内存数据结构,默认大小100M。先将处理好的每条数据写入到“环形缓冲区”,当环形缓冲区使用达到80%时,会将数据溢写到磁盘文件。根据split大小不同,可能会发生多次溢写磁盘过程。
-
每次溢写磁盘时会对数据进行二次排序:按照数据(K,V,P)中的P(分区)进行排序并在每个P(分区)中按照K进行排序,这样能保证相同的分区数据放在一起并能保证每个分区内的数据按照key有序。
-
最终多次溢写的磁盘文件数据会根据归并排序算法合并成一个完整的磁盘文件,此刻,该磁盘文件特点是分区有序且分区内部数据按照key有序。
-
Reduce端每个Reduce task会从每个map task所在的节点上拉取落地的磁盘文件对应的分区数据,对于每个Reduce task来说,从各个节点上拉取到多个分区数据后,每个分区内的数据按照key分组有序,但是总体来看这些分区文件中key数据不是全局有序状态(分区数据内部有序,外部无序)。
-
每个Reduce task需要再通过一次归并排序进行数据merge,将每个分区内的数据变成分区内按照key有序状态,然后通过Reduce task处理将结果写出到HDFS磁盘。
四、MapReduce Shuffle
-
分区(Partitioning):根据键值对的键,将中间键值对划分到不同的分区。每个分区对应一个Reduce任务,这样可以确保相同键的键值对被发送到同一个Reduce任务上进行处理。
-
排序(Sorting):对每个分区内的中间键值对按键进行排序(快排)。通过排序,相同键的键值对会相邻存放,以便后续的合并操作更高效。
-
合并(Merging):对多次溢写的结果按照分区进行归并排序合并溢写文件,每个maptask最终形成一个磁盘一些文件,减少后续Reduce阶段的输入数据量。
-
Combiner(局部合并器):Combiner是一个可选的优化步骤,在Map任务输出结果后、Reduce输入前执行。其作用是对Map任务的输出进行局部合并,将具有相同键的键值对合并为一个,以减少需要传输到Reduce节点的数据量,降低网络开销,并提高整体性能。Combiner实际上是一种轻量级的Reduce操作,用于减少数据在网络传输过程中的负担。需要注意的是,Combiner的执行并不是强制的,而是由开发人员根据具体情况决定是否使用。
-
拷贝(Copying):将各分区内的数据复制到各自对应的Reduce任务节点上,会先向内存缓冲区中存放数据,内存不够再溢写磁盘,当所有数据复制完毕后,Reduce Task统一对内存和磁盘数据进行归并排序并交由Redcue方法并行处理。
五、MapReduce注意点
-
MapReduce Job 中Map Task并行度由split切片决定。
-
Split切片默认与一个block大小相等,block是物理切分,split是逻辑切分,也就是说split大小是通过offset范围来决定每个split大小,而非真正的文件切分。
-
读取数据源时,如果数据源头包括多个文件,会针对每个文件单独进行split切片,而不会考虑数据整体。
六、MapReduce的三次排序
-
第一次排序发生在Map阶段的磁盘溢写时:当MapReduce的环形缓冲区达到溢写阈值时,在数据刷写到磁盘之前,会对数据按照key的字典序进行快速排序,以确保每个分区内的数据有序。
-
第二次排序发生在多个溢写磁盘小文件合并的过程中:经过多次溢写后,Map端会生成多个磁盘文件,这些文件会被合并成一个分区有序且内部数据有序的输出文件,从而确保输出文件整体有序。
-
第三次排序发生在Reduce端:Reduce任务在获取来自多个Map任务输出文件后,进行合并操作并通过归并排序生成每个Reduce Task处理的分区文件整体有序。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
相关文章:
大数据基础:Hadoop之MapReduce重点架构原理
文章目录 Hadoop之MapReduce重点架构原理 一、MapReduce概念 二、MapReduce 编程思想 2.1、Map阶段 2.2、Reduce阶段 三、MapReduce处理数据流程 四、MapReduce Shuffle 五、MapReduce注意点 六、MapReduce的三次排序 Hadoop之MapReduce重点架构原理 一、MapReduce概…...

人工智能算法工程师(中级)课程3-sklearn机器学习之数据处理与代码详解
大家好,我是微学AI,今天给大家分享一下人工智能算法工程师(中级)课程3-sklearn机器学习之数据处理与代码详解。 Sklearn(Scikit-learn)是一个基于Python的开源机器学习库,它提供了简单有效的数据挖掘和数据分析工具。Sklearn包含了…...

华为机考真题 -- 螺旋数字矩阵
题目描述: 疫情期间,小明隔离在家,百无聊赖,在纸上写数字玩。他发明了一种写法:给出数字 个数 n 和行数 m(0 < n ≤ 999,0 < m ≤ 999),从左上角的 1 开始&#x…...

防御笔记第四天(持续更新)
1.状态检测技术 检测数据包是否符合协议的逻辑顺序;检查是否是逻辑上的首包,只有首包才会创建会话表。 状态检测机制可以选择关闭或则开启 [USG6000V1]firewall session link-state tcp ? check Indicate link state check [USG6000V1]firewall ses…...

HUAWEI VRRP 实验
实验要求:在汇聚交换机上SW1和SW2中实施VRRP以保证终端网关的高可靠性(当某一个网关设备失效时,其他网关设备依旧可以实现业务数据的转发。) 1.在SW1和SW2之间配置链路聚合,以提高带宽速度。 2.PC1 访问远端网络8.8.8.8 ,优先走…...
领取serv00免费虚拟主机
参考 教程地址【免费serv00虚拟机SSH登录搭建网站】 领取地址 领到了 SSH登录要魔法,网页登录不用 轻松搭建自己的静态网站 soulio.serv00.net 网页加载速度还可以。 ...

云开发技术的壁纸小程序源码,无需服务期无需域名
1、本款小程序为云开发版本,不需要服务器域名 2、文件内有图文搭建教程,小白也不用担心不会搭建。 3、本程序反应速度极快,拥有用户投稿、积分系统帮助各位老板更多盈利。 4、独家动态壁纸在线下载,给用户更多的选择 5、最新版套图…...
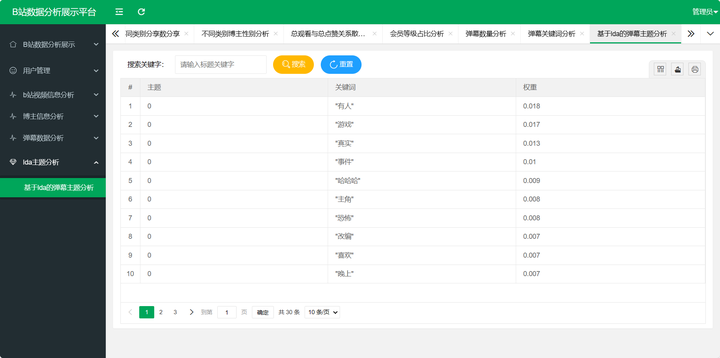
基于Python的哔哩哔哩数据分析系统设计实现过程,技术使用flask、MySQL、echarts,前端使用Layui
背景和意义 随着互联网和数字媒体行业的快速发展,视频网站作为重要的内容传播平台之一,用户量和内容丰富度呈现爆发式增长。本研究旨在设计并实现一种基于Python的哔哩哔哩数据分析系统,采用Flask框架、MySQL数据库以及echarts数据可视化技术…...

顺序结构 ( 四 ) —— 标准数据类型 【互三互三】
序 C语言提供了丰富的数据类型,本节介绍几种基本的数据类型:整型、实型、字符型。它们都是系统定义的简单数据类型,称为标准数据类型。 整型(integer) 在C语言中,整型类型标识符为int。根据整型变量的取值范…...

科普文:jvm笔记
一、JVM概述# 1. JVM内部结构# 跨语言的平台,只要遵循编译出来的字节码的规范,都可以由JVM运行 虚拟机 系统虚拟机 VMvare 程序虚拟机 JVM JVM结构 HotSpot虚拟机 详细结构图 前端编译器是编译为字节码文件 执行引擎中的JIT Compiler编译器是把字节…...

springboot对象参数赋值变化
java springboot 项目, 通过接口修改Person类 name值, 在别的类中,注入Person类 Resource Person person, 为什么拿不到 接口修改的 name的值,是Person类 不同的对象造成的 吗 参数对象和注入对象区别 Person类&…...

树形结构的一种便捷实现方案
背景 在开发过程中经常需要把平铺的数据结构转为树形的数据结构,例如多级菜单、组织机构等。 实现方案有很多种。 1、可以使用递归查询,但是这样数据一多会导致频繁的多次查询数据库,产生很多额外的IO开销,总体的响应时间会比较…...

探索AI数字人的开源解决方案
引言 随着人工智能(AI)技术的迅猛发展,AI数字人(或虚拟人)正逐渐走进我们的生活,从虚拟助手到虚拟主播,再到虚拟客服,AI数字人在各个领域展现出巨大的潜力。开源解决方案的出现&…...

科普文:深入理解负载均衡(四层负载均衡、七层负载均衡)
概叙 网络模型:OSI七层模型、TCP/IP四层模型、现实的五层模型 应用层:对软件提供接口以使程序能使用网络服务,如事务处理程序、文件传送协议和网络管理等。(HTTP、Telnet、FTP、SMTP) 表示层:程序和网络之…...

华为模拟器ensp中USG6000V防火墙web界面使用
防火墙需要配置 新建拓扑选择USG6000V型号 在防火墙中导包 忘记截图了 启动设备 输入用户名密码 默认用户名:admin 默认密码:Admin123 修改密码 然后他会提示你是否要修改密码,想改就改不想改就不改 进入命令行界面 进入系统视图开启web…...

使用Python绘制气泡图
使用Python绘制气泡图 气泡图效果代码 气泡图 气泡图通过气泡的大小表示数据的一个维度,用于展示三个维度的数据。例如,可以展示城市的人口、面积和GDP。 效果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mjj27sP7-1720…...

政安晨:【Keras机器学习示例演绎】(五十四)—— 使用神经决策森林进行分类
目录 导言 数据集 设置 准备数据 定义数据集元数据 为训练和验证创建 tf_data.Dataset 对象 创建模型输入 输入特征编码 深度神经决策树 深度神经决策森林 实验 1:训练决策树模型 实验 2:训练森林模型 政安晨的个人主页:政安晨 欢…...
洞察消费者心理:Transformer模型在消费者行为分析的创新应用
洞察消费者心理:Transformer模型在消费者行为分析的创新应用 在数字化时代,消费者行为分析对于企业理解市场动态、制定营销策略至关重要。Transformer模型,以其在处理序列数据方面的优势,为消费者行为分析提供了新的视角和工具。…...

如何安全使用代理ip
1、选择可靠的代理服务提供商:选择知名的、信誉良好的代理服务提供商,避免使用免费的代理服务,因为免费的代理服务可能存在安全隐患。 2、使用HTTPS代理:使用HTTPS代理可以加密你的网络流量,保护你的隐私和安全。 3、…...

机器学习——LR、GBDT、SVM、CNN、DNN、RNN、Word2Vec等模型的原理和应用
LR(逻辑回归) 原理: 逻辑回归模型(Logistic Regression, LR)是一种广泛应用于分类问题的统计方法,尤其适用于二分类问题。其核心思想是通过Sigmoid函数将线性回归模型的输出映射到(0,1)区间,从…...

GitHubCopilot与Gemini3.1Pro协同开发实战
在 2026 年,AI 编程工具的差异已经从“谁能写代码”转向“谁能把代码写对、写稳、写得可维护”。很多团队开始采用“双引擎协作”:GitHub Copilot 负责快速生成与代码补全,而 Gemini 3.1 Pro 负责更强的推理、架构级建议、测试策略与长上下文…...

在Python项目中下载OpenAI兼容SDK并接入Taotoken聚合API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中下载OpenAI兼容SDK并接入Taotoken聚合API 对于使用Python的开发者而言,通过OpenAI官方风格的SDK接入大模…...

从零开始搭建 AI 应用时如何利用 Taotoken 简化模型选型与接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始搭建 AI 应用时如何利用 Taotoken 简化模型选型与接入 当你着手为一个新项目引入大模型能力时,面对市场上众多…...

为什么你的AI测试总在“伪自动化”?SITS 2026的3层认知跃迁:从用例驱动→意图驱动→反馈演化
AI原生测试方法革新:SITS 2026自动化测试新思路 更多请点击: https://intelliparadigm.com 第一章:为什么你的AI测试总在“伪自动化”? “伪自动化”是当前AI工程实践中最隐蔽的效率陷阱——表面看测试脚本在运行,日…...

2025届毕业生推荐的降AI率助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下的学术评价体系里头,维普AIGC检测系统被大范围地运用起来,用以…...

如何永久保存微信聊天记录?WeChatMsg本地化解决方案完整指南
如何永久保存微信聊天记录?WeChatMsg本地化解决方案完整指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...
)
用Python和STC单片机搞定AD7606八通道数据采集(附完整代码和避坑指南)
Python与STC单片机驱动AD7606八通道数据采集实战指南 AD7606作为一款16位精度的八通道模数转换器,在工业测量、医疗设备、科研实验等领域有着广泛应用。本文将带您从零开始,通过Python与STC8G系列单片机搭建完整的AD7606数据采集系统,涵盖硬件…...

终极艾尔登法环性能优化指南:3步解锁帧率限制与视野扩展
终极艾尔登法环性能优化指南:3步解锁帧率限制与视野扩展 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/E…...

ImageGlass:如何构建高效开源图像查看器,90+格式支持与模块化架构深度解析
ImageGlass:如何构建高效开源图像查看器,90格式支持与模块化架构深度解析 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 在数字图像处理日益复杂的…...

5分钟搞定iPhone网络共享:Windows驱动安装的终极避坑指南
5分钟搞定iPhone网络共享:Windows驱动安装的终极避坑指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_…...