NLP入门——前馈词袋分类模型的搭建、训练与预测
模型的搭建
线性层
>>> import torch
>>> from torch import nn
>>> class DBG(nn.Module):
... def forward(self,x):
... print(x.size())
... return x
...
>>> tmod = nn.Sequential(nn.Linear(3,4),DBG(),nn.Linear(4,5),DBG())
>>> tmod(torch.randn(2,3))
torch.Size([2, 4])
torch.Size([2, 5])
tensor([[-0.0408, 0.3847, 0.0409, -0.6591, -0.0459],[-0.0791, 0.2998, 0.3464, -0.7436, -0.2738]],grad_fn=<AddmmBackward0>)
通过以上代码,输入一个2x3的矩阵,在第一个线性层会变化为一个2x4的矩阵,随后使用DBG类输出当前矩阵的形状。在第二次线性层的变换后,矩阵变成2x5。
设置丢弃率
>>> import torch
>>> from torch import nn
>>> h = torch.randn(5)
>>> td = nn.Dropout(0.2)
>>> td(h)
tensor([-0.7068, 0.8269, -1.1000, -0.2249, 0.0000])
>>> h
tensor([-0.5654, 0.6615, -0.8800, -0.1799, 0.7755])
我们设置丢弃率为0.2,结果打印丢弃后的张量,发现张量的第五个值被舍弃为0,但其他的值均发生了变化。
原因是丢弃值置0后向量的模长会发生很大变化,在我们线性层输入计算特征值时,模长的变化会造成结果的变化,在测试时我们是用原始不丢弃值的张量测试的,为了平衡丢弃前后张量的模长相近,Dropout函数对丢弃后的张量的其余值做了缩放。
>>> h/0.8
tensor([-0.7068, 0.8269, -1.1000, -0.2249, 0.9693])
>>> td(h)
tensor([-0.7068, 0.8269, -1.1000, -0.2249, 0.0000])
我们丢弃率是0.2,Dropout函数就用其余值/0.8后保留。因此Dropout函数做了两件事:1.按照给定概率p丢掉值。2.用剩下其余值/(1-p),从而保持前后模长一致。
>>> td.eval()
Dropout(p=0.2, inplace=False)
>>> td.training #eval()函数使此值为False,不丢弃
False
>>> td(h)
tensor([-0.5654, 0.6615, -0.8800, -0.1799, 0.7755])
>>> td.train()
Dropout(p=0.2, inplace=False)
>>> td.training #train()函数使此值为True,丢弃
True
>>> td(h)
tensor([-0.7068, 0.0000, -1.1000, -0.2249, 0.0000])
以上是Dropout函数的两种模式。
归一化层
在神经网络训练中,可能产生张量的某些参数值过大或过小,这样的极端值不利于产生合适的预测值。在优化过程中,如果我们设置学习率很小,则很小的参数值就变化很慢;如果学习率过大,则大的参数值变化过慢。
因此我们需要用nn.LayerNorm来进行归一化处理:
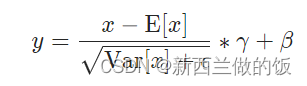
归一化的公式如上,E(x)是向量的均值。 x − E [ x ] x-E[x] x−E[x]的作用是将向量移到0的附近:
>>> a = torch.randn(5)*100
>>> a
tensor([ -61.7625, 16.2004, -117.4248, 84.3843, -54.4913])
>>> m = a.mean(-1,keepdim=True)
>>> m
tensor([-26.6188])
>>> a-m
tensor([-35.1437, 42.8192, -90.8060, 111.0031, -27.8725])
>>> (a-m).mean(-1)
tensor(0.)
分母上 V a r [ x ] Var[x] Var[x]是标准差,有可能为0,因此加一个很小的数来避免除以0异常。
>>> s=a.std(-1,keepdim=True)#标准差
>>> s
tensor([78.1231])
>>> h=(a-m)/(s+1e-5)
>>> h
tensor([-0.4499, 0.5481, -1.1623, 1.4209, -0.3568])
模型代码
#NNModel.py
#encoding: utf-8from torch import nnclass BoWLayer(nn.Module):def __init__(self, isize, hsize, dropout,norm_residual=True,**kwargs):super(BoWLayer, self,).__init__() ##调用父类的初始化函数self.net = nn.Sequential(nn.Linear(isize, hsize),nn.ReLU(inplace=True), #设置relu激活函数,inplace=True在原始张量上进行nn.Dropout(p=dropout, inplace=False),#设置丢弃率防止过拟合,同时创建一个新的张量nn.Linear(hsize, isize, bias=False), nn.Dropout(p=dropout, inplace=True))self.normer = nn.LayerNorm(isize) #做归一化self.norm_residual = norm_residual #设置变量存储做判断def forward(self, input):_ = self.normer(input) #稳定之后的结果 return (_ if self.norm_residual else input) + self.net(_)#如果参数初始化做的好,就用LayerNorm后的值,否则用原始值class NNBoW(nn.Module):def __init__(self, vcb_size, nclass, isize, hsize, dropout,nlayer, **kwargs):super(NNBoW, self).__init__()self.emb = nn.Embedding(vcb_size, isize,padding_idx=0) #<pad>的索引为0self.drop = nn.Dropout(p=dropout, inplace=True) #embedding后dropoutself.nets = nn.Sequential(*[BoWLayer(isize, hsize, dropout)for _ in range(nlayer)])self.classifier = nn.Linear(isize, nclass)self.normer = nn.LayerNorm(isize)self.out_normer = nn.LayerNorm(isize)# input: (bsize, seql) 句数、句长def forward(self, input):mask = input.eq(0) #找到<pad>的位置# mask: (bsize, seql)out = self.emb(input)# out: (bsize, seql, isize)out = out.masked_fill(mask.unsqueeze(-1), 0.0) #将out中<pad>的位置置为0out = self.drop(out)out = out.sum(1) #对序列求和,在第一维度求和 #求和后out: (bsize, seql, isize) -> out: (bsize, isize)out = self.normer(out) #使用归一化,使模长均匀out = self.nets(out) #特征提取out = self.out_normer(out) #特征提取后,分类前再做一次归一化out = self.classifier(out) #分类产生参数#out: (bsize, isize) -> out: (bsize, nclass)return out
模型的训练
从h5文件中取值
我们上节存储h5文件时,特别存储了nword的Dataset,来保存总词数以及总类别数:
:~/nlp/tnews$ h5ls -d train.h5/nword
nword Dataset {2}Data:15379, 15
如果我们直接写是无法得到其中的具体值的
>>> from h5py import File as h5File
>>> t_data = h5File("train.h5","r")
>>> t_data["nword"]
<HDF5 dataset "nword": shape (2,), type "<i4">
我们如果从中取值,要这样写t_data["nword"][()],传一个空的tuple,表示取所有值。
>>> t_data["nword"][()]
array([15379, 15], dtype=int32)
>>> type(t_data["nword"][()])
<class 'numpy.ndarray'>
我们可以看到,取出的类型为numpy的ndarray,我们需要使用tolist()转成list后取出。
>>> vsize,nclass=t_data["nword"][()].tolist()
>>> vsize,nclass
(15379, 15)
损失函数优化
使用torch.nn.CrossEntropyLoss:
CLASStorch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean', label_smoothing=0.0):

>>> import torch
>>> a=torch.randn(4)
>>> a
tensor([0.7171, 0.0033, 1.3289, 1.5256])
>>> a.softmax(-1)
tensor([0.1793, 0.0878, 0.3305, 0.4024])
>>> p=a.softmax(-1)
>>> p.sum()
tensor(1.0000)
>>> _ = a.exp()
>>> _
tensor([2.0485, 1.0033, 3.7768, 4.5980])
>>> _/_.sum(-1,keepdim=True)
tensor([0.1793, 0.0878, 0.3305, 0.4024])
softmax函数是将输入的分数先求指数后再除以求指数后的和。经过softmax函数之后,再对结果值求负对数。由于经过softmax函数后张量中的值均是0到1的分数,则分数越接近于1,求负对数后值越接近于0。
>>> p
tensor([0.1793, 0.0878, 0.3305, 0.4024])
>>> -p.log()
tensor([1.7188, 2.4327, 1.1071, 0.9103])
在以上代码中,p[-1]值最大,则取负对数后值就越小。
label_smoothing参数的设置
若我们有四个类别{0, 1, 2, 3},softmax函数处理后得到的[P1, P2, P3, P4]. 若正确的类别是2。则交叉熵损失函数得到的分数为: − l o g ( P 2 ) -log(P_2) −log(P2).
我们设置 label_smoothing=0.1,则会分配权重:
W 2 = 1 − 0.1 = 0.9 W_2 = 1 - 0.1 = 0.9 W2=1−0.1=0.9,
W 0 = W 1 = W 3 = 0.1 / 3 = 1 30 W_0 = W_1 = W_3=0.1/3 = \frac{1}{30} W0=W1=W3=0.1/3=301
则 label_smoothing = 0.1得到的分数为:
l s l o s s = 1 30 ∗ s u m ( − l o g ( P 0 P 1 P 3 ) + 0.9 ∗ ( − l o g ( P 2 ) ) ) ls loss = \frac{1}{30} * sum(-log(P_0P_1P_3)+0.9*(-log(P_2))) lsloss=301∗sum(−log(P0P1P3)+0.9∗(−log(P2)))
如果我们只使用CrossEntropyLoss,我们可能会使模型向一个极端方向走,容易忽略其他参数的影响。而设置label_smoothing,它会分配权重来承认正确类别足够重要,但也不能忽视其他类别。
学习率调度
class StepLR(LRScheduler):
def __init__(self, optimizer, step_size, gamma=0.1, last_epoch=-1, verbose="deprecated"):self.step_size = step_sizeself.gamma = gammasuper().__init__(optimizer, last_epoch, verbose)def get_lr(self):if not self._get_lr_called_within_step:warnings.warn("To get the last learning rate computed by the scheduler, ""please use `get_last_lr()`.", UserWarning)if (self.last_epoch == 0) or (self.last_epoch % self.step_size != 0):return [group['lr'] for group in self.optimizer.param_groups]return [group['lr'] * self.gammafor group in self.optimizer.param_groups]
我们需要写两个函数分别用来初始化和更新当前学习率。我们用初始学习率除以步数开根号来做学习率的下降:
#lrsch.py
#encoding: utf-8from torch.optim.lr_scheduler import _LRScheduler
from math import sqrtclass SqrtDecayLR(_LRScheduler):#base_lr / sqrt(step)def __init__(self, optimizer, base_lr, min_lr=1e-8, step=1,last_epoch=-1, **kwargs):self.base_lr, self.min_lr, self._step = base_lr, min_lr, step#设置最小的学习率super().__init__(optimizer, last_epoch)def get_lr(self):_lr = max(self.base_lr / sqrt(self._step), self.min_lr)self._step += 1#每次计算学习率return [_lr for _ in range(len(self.base_lrs))]
训练模型
#train.py
#encoding: utf-8import torch
from torch import nn
from NNModel import NNBoW #导入模型
from h5py import File as h5File #读训练数据
from math import sqrt
from random import shuffle #使输入数据乱序,使模型更均衡
from lrsch import SqrtDecayLRtrain_data = "train.h5"
dev_data = "dev.h5" #之前已经张量转文本的h5文件
isize = 64
hsize = isize * 2 #设置初始参数
dropout = 0.3 #设置丢弃率
nlayer = 4 #设置层数
gpu_id = -1 #设置是否使用gpu
lr = 1e-3 #设置初始学习率
max_run = 512 #设置训练轮数
early_stop = 16 #设置早停轮数def init_model_parameters(modin): #初始化模型参数with torch.no_grad(): #不是训练不用求导for para in modin.parameters():if para.dim() > 1: #若维度大于1,说明是权重参数_ = 1.0 / sqrt(para.size(-1))para.uniform_(-_,_) #均匀分布初始化for _m in modin.modules(): #遍历所有小模型if isinstance(_m, nn.Linear):#如果小模型是linear类型if _m.bias is not None: #初始化bias_m.bias.zero_()elif isinstance(_m, nn.LayerNorm):#初始化LayerNorm参数_m.weight.fill_(1.0)_m.bias.zero_()return modindef train(train_data, tl, model, lossf, optm, cuda_device):model.train() #设置模型在训练的模式src_grp, tgt_grp = train_data["src"], train_data["tgt"] #从输入数据中取出句子和标签_l = 0.0 #_l用来存当前loss_t = 0 #_t用来存句子数for _id in tl:seq_batch = torch.from_numpy(src_grp[_id][()])seq_o = torch.from_numpy(tgt_grp[_id][()]) #取出句子和标签转化成torch类型if cuda_device is not None:seq_batch = seq_batch.to(cuda_device, non_blocking=True)seq_o = seq_o.to(cuda_device, non_blocking=True) #将数据放在同一gpu上seq_batch, seq_o = seq_batch.long(), seq_o.long() #数据转换为long类型out = model(seq_batch) #获得模型结果loss = lossf(out, seq_o) #获得损失函数_l += loss.item() #获得浮点数_t += seq_batch.size(0) #累加获得当前句数loss.backward() #反向传播求导optm.step() #参数的更新optm.zero_grad(set_to_none=True)#清空梯度return _l / _t #返回当前lossdef eva(vd, nd, model, lossf, cuda_device):model.eval() #设置模型在验证方式src_grp, tgt_grp = vd["src"], vd["tgt"]_loss = 0.0_t = _err = 0 #_err记录错误的句数with torch.no_grad(): #禁用求导,节省计算开销for i in range(nd):_ = str(i) #获取字符串形式的keyseq_batch = torch.from_numpy(src_grp[_][()])seq_o = torch.from_numpy(tgt_grp[_][()]) #取句子和标签if cuda_device is not None:seq_batch = seq_batch.to(cuda_device, non_blocking=True)seq_o = seq_o.to(cuda_device, non_blocking=True) #放在同一设备上seq_batch, seq_o = seq_batch.long(), seq_o.long() #数据类型转换out = model(seq_batch)loss = lossf(out, seq_o)_loss += loss.item() #loss累加_t += seq_batch.size(0) #记录数据总量_err += out.argmax(-1).ne(seq_o).int().sum().item() #argmax获取最大值的位置,当做预测的类别位置#ne()判断和正确类别是否不等,不等为T相等为F,转成0和1后累加得到的值就是错的总数model.train() #模型恢复为训练方式return _loss / _t, float(_err) / _t *100.0 #返回平均的loss和错误率def save_model(modin, fname): #保存模型所有内容 权重、偏移、优化torch.save({name: para.cpu() for name, para inmodel.named_parameters()}, fname)t_data = h5File(train_data, "r")
d_data = h5File(dev_data, "r") #以读的方式打开训练以及验证数据vcb_size, nclass = t_data["nword"][()].tolist() #将返回的numpy的ndarray转为list
#在我们的h5文件中存储了nword:(总词数,总类别数)model = NNBoW(vcb_size, nclass, isize, hsize, dropout, nlayer)
model = init_model_parameters(model) #在cpu上初始化模型
lossf = nn.CrossEntropyLoss(reduction='sum', label_smoothing=0.1)
#设置损失函数优化,由于句长不一致,我们使用sum而非mean方式if (gpu_id >= 0) and torch.cuda.is_available(): #如果使用gpu且设备支持cudacuda_device = torch.device("cuda", gpu_id) #配置gputorch.set_default_device(cuda_device)
else:cuda_device = Noneif cuda_device is not None: #如果要用gpumodel.to(cuda_device) #将模型和损失函数放在gpu上lossf.to(cuda_device)optm = torch.optim.Adam(model.parameters(), lr=lr,
betas=(0.9, 0.98), eps=1e-08)
#使用model.parameters()返回模型所有参数,
lrm = SqrtDecayLR(optm, lr) #将优化器和初始学习率传入tl = [str(_) for _ in range(t_data["ndata"][()].item())] #获得字符串构成的训练数据的list
nvalid = d_data["ndata"][()].item()min_loss, min_err = eva(d_data, nvalid, model, lossf,
cuda_device)
print("Init dev_loss %.2f, error %.2f" % (min_loss, min_err,))#打印一下初始状态namin = 0
for i in range(1, max_run + 1):shuffle(tl) #使数据乱序_tloss = train(t_data, tl, model, lossf, optm,cuda_device) #获取每轮训练的损失_dloss, _derr = eva(d_data, nvalid, model, lossf, cuda_device) #获取每轮验证的损失和错误率print("Epoch %d: train loss %.2f, dev loss %.2f, error %.2f"%(i, _tloss, _dloss, _derr)) #打印日志_save_model = False #模型的保存,保存在验证集上表现最好的模型if _dloss < min_loss:_save_model = Truemin_loss = _dlossif _derr < min_err:_save_model = Truemin_err = _derr #保存在loss和err指标上最好的模型if _save_model: #如果需要保存模型save_model(model, "eva.pt")namin = 0else:namin += 1if namin >= early_stop: #早停逻辑breaklrm.step() #每轮训练后更新学习率t_data.close()
d_data.close() #最后关闭这两个文件
在命令行输入python train.py运行文件,我们可以看到:
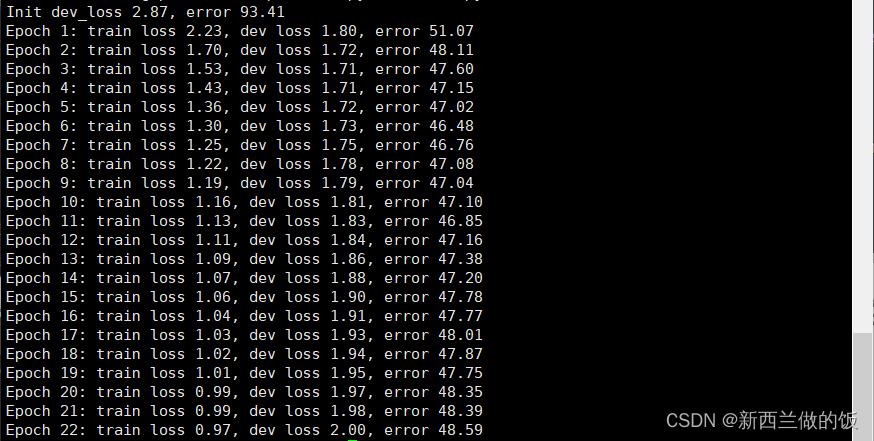
训练进行了22轮出现早停,在训练集上验证的错误率在48%左右。
模型的解码
解码首先我们需要对验证集做排序:
#sorti.py
#encoding: utf-8
import sysdef handle(srcf, srts, max_len=1048576):# {length: {(src, label)}} 外层dict,中层set,内层tupledata = {}with open(srcf, "rb") as fsrc:for ls in fsrc:ls = ls.strip()if ls:ls = ls.decode("utf-8")_ = len(ls.split()) #获取句子的分词个数if _ <= max_len:if _ in data: #若已有这个长度在data中if ls not in data[_]: #去重,重复的跳过data[_].add(ls) #不重复的添加else:data[_] = set([ls]) #转化成set去重ens = "\n".encode("utf-8")with open(srts, "wb") as fsrc: #写入for _l in sorted(data.keys()): #按照句子长度从小到大排lset = data[_l] #取出句长对应的setfsrc.write("\n".join(lset).encode("utf-8")) #在每个句子间插入换行符fsrc.write(ens) #每个句子后插入换行if __name__ == "__main__":handle(*sys.argv[1:3])
在命令行执行:
:~/nlp/tnews$ python sorti.py src.dev.bpe.txt src.dev.bpe.txt.srt
查看排序后的.srt文件:
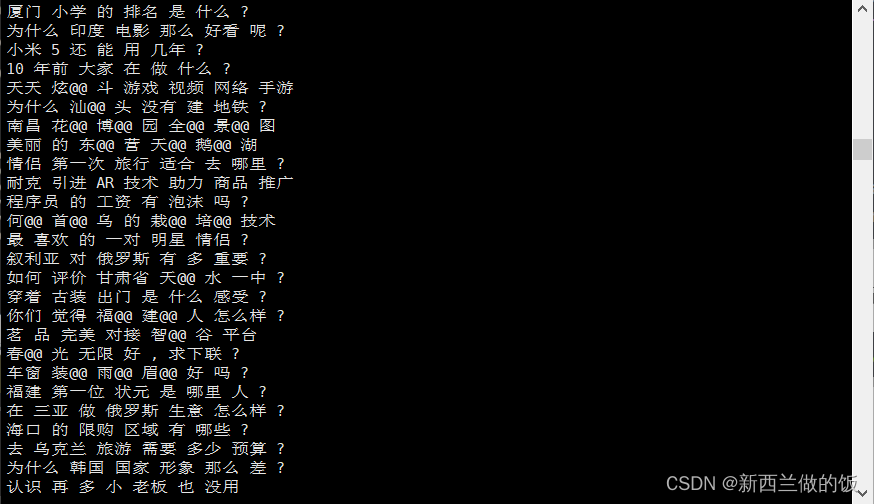
可以看到已经按照句子长度(即分词个数)升序排序并存储。
存储为h5文件
#mktesth5.py
#encoding: utf-8
import sys
from h5py import File as h5File
import numpy
from vcb import load_vcb
#导入加载词典的函数def batch_loader(fsrc, max_tokens = 2048, **kwargs):#返回一批一batch的数据,设置每个batch最多存放2048个子词ri = []mlen = n = 0 #n记录当前收集了多少条句子,mlen记录当前收集的句子长度with open(fsrc, "rb") as fs:for ls in fs:ls = ls.strip() if ls:ls =ls.decode("utf-8").split()_l = len(ls) #当前行中的分词个数_mlen = max(_l, mlen) #当前行或当前batch中句子的长度_n = n + 1if (_n * _mlen) > max_tokens: #如果把添加了这句话的 句数*分词数量 大于最大值则不能放if ri: #如果ri,rt不为空yield ri, mlen #返回ri,rt和原来的句子长度ri, mlen, n = [ls], _l, 1 #返回后重新初始化,将本句加入新的batchelse: #如果不超过当前长度,则将此句添加到batch中ri.append(ls)mlen, n = _mlen, _n #更新句子长度与句子数量if ri: #最后若仍然有数据,则返回为一个新的batchyield ri, mlendef batch_mapper(fsrc, vcbs, **kwargs): #将分词变索引for ri, mlen in batch_loader(fsrc, **kwargs):yield [[vcbs[_word] for _word in _s if _word in vcbs]for _s in ri], mlen#遍历每个batch中的句子,返回每个batch中每个分词的个数、标签、batch长度def pad_batch(lin, mlen, pad_id = 0):#补<pad>的函数rs = []for lu in lin: #每个batch中的每句_d = mlen - len(lu) #当前此句需要补<pad>的个数if _d > 0:lu.extend([pad_id for _ in range(_d)])#extend函数用来拼接两个列表。补_d个<pad>的索引0rs.append(lu)return rs #返回的是均已对齐的每个batchdef batch_padder(fsrc, vcbs, **kwargs):for ri, mlen in batch_mapper(fsrc, vcbs, **kwargs):yield pad_batch(ri, mlen) #返回的是每个已补齐的batch,以及batch中的标签def handle(fsrc, fvcbs, frs, **kwargs):vcbs = load_vcb(fvcbs, vanilla = False)with h5File(frs, "w", libver = 'latest', track_order = False) as h5f:#libver使用最新的,track_order表示无需记录顺序src_grp = h5f.create_group("src", track_order=False) #创建两个组,分别放句子和标签 for i, ri in enumerate(batch_padder(fsrc, vcbs, **kwargs)):ri = numpy.array(ri, dtype = numpy.int32) #转化成numpy数组并设置数据类型,target的数据很小,所以我们只需要int16存储src_grp.create_dataset(str(i), data=ri, compression="gzip",compression_opts=9, shuffle=True ) #设置压缩存储节省空间,压缩等级设置为最大压缩代价9h5f["nword"] = numpy.array([len(vcbs)], dtype=numpy.int32) #存储总词数、总标签数h5f["ndata"] = numpy.array([i + 1], dtype=numpy.int32) #存储总batch数if __name__ == "__main__":handle(*sys.argv[1:4])
在命令行执行:
:~/nlp/tnews$ python mktesth5.py src.dev.bpe.txt.srt src.vcb test.h5
查看存储后的h5文件,可以看到验证集的总词数为15379,总batch数为78:
:~/nlp/tnews$ h5ls test.h5
ndata Dataset {1}
nword Dataset {1}
src Group
:~/nlp/tnews$ h5ls -d test.h5/ndata
ndata Dataset {1}Data:78
:~/nlp/tnews$ h5ls -d test.h5/nword
nword Dataset {1}Data:15379
模型的预测
#predict1.py
#encoding: utf-8import sys
import torch
from NNModel import NNBoW #读模型
from h5py import File as h5File #读文件
from vcb import load_vcb, reverse_vcb #获取词表isize = 64
hsize = isize * 2
dropout = 0.3
nlayer = 4
gpu_id = -1 #模型的初始化参数test_data = sys.argv[1]
test_file = h5File(test_data, "r") #读验证集
vcb_size = test_file["nword"][()].tolist()[0] #获取总词数tgt_vcb = reverse_vcb(load_vcb(sys.argv[2], vanilla=True))
nclass = len(tgt_vcb) #获取总类别数model = NNBoW(vcb_size, nclass, isize, hsize, dropout, nlayer)
model_file = sys.argv[-1] #获取模型
with torch.no_grad(): #避免求导_ = torch.load(model_file) #加载词典for name, para in model.named_parameters():if name in _:para.copy_(_[name]) #从词典里取出name的参数if (gpu_id >= 0) and torch.cuda.is_available():cuda_device = torch.device("cuda", gpu_id)torch.set_default_device(cuda_device)
else:cuda_device = Noneif cuda_device is not None:model.to(cuda_device) #判断是否使用cudasrc_grp = test_file["src"]
ens = "\n".encode("utf-8")
with torch.no_grad(), open(sys.argv[3],"wb") as f: #解码避免求导,将预测标签按行写入文件for _ in range(test_file["ndata"][()].item()):#每个batch上遍历seq_batch = torch.from_numpy(src_grp[str(_)][()])if cuda_device is not None:seq_batch = seq_batch.to(cuda_device, non_blocking=True)seq_batch = seq_batch.long() #s数据类型转换out = model(seq_batch).argmax(-1).tolist() #将每个batch的预测下标转列表out = "\n".join([tgt_vcb[_i] for _i in out]) #将预测下标转为对应的类别,类别间按行隔开f.write(out.encode("utf-8"))f.write(ens) #每个batch间还应有换行test_file.close()
我们将预测类别存入out.txt,eva.pt是模型文件。在命令行输入:
:~/nlp/tnews$ python predict1.py test.h5 tgt.vcb out.txt eva.pt
:~/nlp/tnews$ less out.txt

请注意此时,我们存储预测的类别是对验证集排序后每句预测的类别,我们要对比原验证集的标签,需要将顺序恢复:
#restore.py
#encoding: utf-8
#python restore.py srti.txt srtp.txt srci.txt rs.txtimport sysdef load(srcf, tgtf):rs = {}with open(srcf, "rb") as fsrc,open(tgtf, "rb") as ftgt:for ls, lt in zip(fsrc, ftgt):ls, lt = ls.strip(), lt.strip()if ls and lt:ls, lt =ls.decode("utf-8"), lt.decode("utf-8")rs[ls] = lt #将每句话及其对应的预测类别存入字典rsreturn rsdef lookup(srcf, rsf, mapd):ens = "\n".encode("utf-8")with open(srcf, "rb") as frd,open(rsf, "wb") as fwrt:for line in frd:line = line.strip()if line:line = line.decode("utf-8")fwrt.write(mapd[line].encode("utf-8"))#按照排序前文件的顺序将预测的类别写入新文件fwrt.write(ens) if __name__ == "__main__":lookup(*sys.argv[3:5], load(*sys.argv[1:3]))#将load处理后的字典传入lookup中
在命令行执行:
:~/nlp/tnews$ python restore.py src.dev.bpe.txt.srt out.txt src.dev.bpe.txt pred.dev.txt
:~/nlp/tnews$ less pred.dev.txt

计算准确率
利用我们前面写的脚本来预测准确率,在命令行执行:
:~/nlp/tnews$ python acc.py pred.dev.txt tgt.dev.s.txt
51.59
:~/nlp/tnews$ python acc.py pred/pred.learnw.dev.txt tgt.dev.s.txt
46.92
相较于前面的将函数做非线性变换前的模型,我们前馈词袋分类模型预测准确率上升了5个百分点。
相关文章:
NLP入门——前馈词袋分类模型的搭建、训练与预测
模型的搭建 线性层 >>> import torch >>> from torch import nn >>> class DBG(nn.Module): ... def forward(self,x): ... print(x.size()) ... return x ... >>> tmod nn.Sequential(nn.Linear(3,4),DB…...

GD32F303RET6读取SGM58031电压值
1、SGM58031芯片详解 (1)SGM58031是一款低功耗,16位精度,delta-sigma (ΔΣ)模数转换器(ADC)。它从3V到5.5V供电。 (2)SGM58031包含一个片上参考和振荡器。它有一个I2C兼容接口,可以选择四个I2…...
函数深度解析与高效应用)
Pandas实战指南:any()函数深度解析与高效应用
Pandas实战指南:any()函数深度解析与高效应用 引言 在数据分析和处理过程中,经常需要快速检查数据集中是否存在满足特定条件的元素。Pandas库中的any()函数正是这样一个强大的工具,它可以帮助我们沿着指定的轴检查是否至少有一个元素满足某…...

ClickHouse中PRIMARY KEY和ORDER BY关键字的关系
在ClickHouse中,PRIMARY KEY和ORDER BY关键字在表的创建过程中扮演着重要的角色,它们共同决定了数据在物理存储上的排序方式,这对查询性能有着直接的影响。理解它们之间的关系对于设计高效的ClickHouse表结构至关重要。 ORDER BY ORDER BY定…...

android 图片轮播
在Android中,实现图片轮播(也称为图片滑动或图片轮转)通常涉及到使用ViewPager、RecyclerView配合PagerAdapter、RecyclerView.Adapter或者第三方库如Glide、Picasso来处理图片加载,以及一个定时器(如Handler、Timer、…...

进度条提示-在python程序中使用避免我误以为挂掉了
使用库tqdm 你还可以手写一点,反正只要是输出点什么东西都可以; Demo from chatgpt import time from tqdm import tqdm# 示例函数,模拟长时间运行的任务 def long_running_task():total_steps 100for step in tqdm(range(total_steps), …...

【案例】python集成OCR识别工具调研
目录 一、前言二、Tesseract_OCR2.1、安装过程2.2、python代码使用三、PaddleOCR3.1、安装过程3.2、python代码使用四、EasyOCR五、ddddOCR六、CnOCR七、总结一、前言 因项目需要OCR识别能力,且要支持私有化部署。本文将对比市场一些开源的OCR识别工具,从中选择适合项目需要…...
第一关:Linux基础知识
Linux基础知识目录 前言LinuxInternStudio 关卡1. InternStudio开发机介绍2. SSH及端口映射2.1 什么是SSH?2.2 如何使用SSH远程连接开发机?2.2.1 使用密码进行SSH远程连接2.2.2 配置SSH密钥进行SSH远程连接2.2.3 使用VScode进行SSH远程连接 2.3. 端口映射…...

qt 自定义信号和槽举例
在Qt中,自定义信号和槽是对象间通信的一种强大机制。以下是一个简单的例子,展示了如何定义和使用自定义信号和槽。 首先,我们定义一个简单的Worker类,它有一个自定义信号workCompleted,当某个任务完成时,这…...

编程语言与数据结构的关系:深度解析与探索
编程语言与数据结构的关系:深度解析与探索 在编程的世界中,编程语言和数据结构是两个不可或缺的元素。它们之间既相互依存,又各自独立,共同构成了编程的核心。本文将深入探索编程语言与数据结构之间的复杂关系,从四个…...

了解AsyncRotationController
概述 基于android 15.0, 以从强制横屏App上滑退回桌面流程来分析 frameworks/base/services/core/java/com/android/server/wm/AsyncRotationController.javaAsyncRotationController 是一种控制器,用于处理设备显示屏旋转时非活动窗口的异步更新。这种控制器通过…...

有必要找第三方软件测评公司吗?如何选择靠谱软件测评机构?
软件测试是确保软件质量的重要环节,而在进行软件测试时,是否有必要找第三方软件测评公司呢?第三方软件测评公司是指独立于软件开发公司和用户之间的中立机构,专门从事软件测试和测评工作。与自身开发团队或内部测试团队相比,选择…...

物联网系统中市电电量计量方案(一)
为什么要进行电量计量? 节约资源:电量计量可以帮助人们控制用电量,从而达到节约资源的目的。在当前严峻的资源供应形势下,节约能源是我们应该重视的问题。合理计费:电表可以帮助公共事业单位进行合理计费,…...

2024年热门无线领夹麦克风哪款好,麦克风品牌排行榜前十名推荐
在音频领域,无线领夹麦克风不断推陈出新,为我们带来了更出色的声音体验。无论你是主播、自媒体创作者、教师还是商务人士,都能从中找到适合自己的那一款。为了帮助大家轻松挑选到理想的无线领夹麦克风,我特别挑选了几款具有代表…...
IEEE顶刊“放水”?稳居1区Top,发文扩张IF稳长,CCF推荐,审稿友好!
本周投稿推荐 SCI • 能源科学类,1.5-2.0(25天来稿即录) • CCF推荐,4.5-5.0(2天见刊) • 生物医学制药类(2天逢投必中) EI • 各领域沾边均可(2天录用)…...
发布:PhonePrompter_PC(手机录视频提词器_电脑版)
PhonePrompter_PC(手机录视频提词器_电脑版) 目 录 1. 概述... 2 2. 应用手册... 3 下载地址:百度网盘 请输入提取码 提取码:8wsa 1. 概述 平时工作和生活中需要用手机竖屏或横屏模式录制造工作、科技、历史、生活等方面的一些视…...

shein测试开发会问些啥?
🏆本文收录于《CSDN问答解惑-》专栏,主要记录项目实战过程中的Bug之前因后果及提供真实有效的解决方案,希望能够助你一臂之力,帮你早日登顶实现财富自由🚀;同时,欢迎大家关注&&收藏&…...

mysql索引优化
1、不在索引列做任何操作: 函数表达式:select sum(id) from 计算:where id 1; 隐式转换:where id "" 2、尽量全值匹配(在联合索引中,where 后面的条件尽量和索引的所有列匹配…...

Linux文件编程(打开/创建写入读取移动光标)
目录 一、如何在Linux下做开发 1.vi编辑器 2.gcc编译工具 3.常用指令 二、文件打开及创建 三、写入文件 四、读取文件 五、文件“光标”位置 一、如何在Linux下做开发 所谓文件编程,就是对文件进行操作,Linux的文件和Windows系统的文件大差不差…...

集成测试技术栈
前端 浏览器操作:playwright、selenium 后端 testcontainercucumbervitestcypressmsw...

Watchify常见问题解决方案:解决监视失败的7个实用技巧
Watchify常见问题解决方案:解决监视失败的7个实用技巧 【免费下载链接】watchify watch mode for browserify builds 项目地址: https://gitcode.com/gh_mirrors/wa/watchify Watchify作为Browserify的监视模式工具,能在文件变化时自动重新构建&a…...

OmenSuperHub:让你的惠普OMEN游戏本性能全开,告别官方臃肿软件
OmenSuperHub:让你的惠普OMEN游戏本性能全开,告别官方臃肿软件 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏…...

MAA明日方舟自动化工具终极指南:如何一键解放双手轻松长草
MAA明日方舟自动化工具终极指南:如何一键解放双手轻松长草 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https:/…...
)
手把手教你用TMS320F2803x DSP实现PMBus通信(附代码下载与避坑指南)
TMS320F2803x DSP实战:PMBus通信从零搭建到波形调试全攻略 1. 工程搭建与开发环境配置 在开始PMBus通信开发前,需要准备完整的软硬件环境。以下是基于TI C2000系列DSP的典型配置流程: 硬件准备清单: TMS320F2803x开发板࿰…...

别再只会用阿里云加速了!手把手教你配置Docker daemon.json,优化日志与存储路径
深度优化Docker生产环境:daemon.json高阶配置实战指南 当Docker从开发测试环境走向生产部署时,默认配置往往成为性能瓶颈和系统隐患的源头。许多团队在遭遇磁盘爆满、日志失控或网络拥塞后,才意识到基础镜像加速只是Docker调优的冰山一角。本…...

告别重复劳动:用这个Maya Mel脚本插件,5分钟搞定Arnold材质批量调节
告别重复劳动:Maya Mel脚本插件在Arnold材质批量调节中的高效应用 在三维动画和视觉特效制作中,材质调节往往是项目后期最耗时的环节之一。当导演皱着眉头说"这个场景的金属感太强了"或者客户反馈"整体色调需要更暖一些"时…...

网站建设公司推荐:业内公认高水准网站制作公司一览
在数字化竞争日益激烈的2026年,企业官网已从单纯的信息展示窗口升级为品牌战略核心载体与业务增长引擎。面对市场上众多的网站建设服务商,企业如何精准匹配需求?本文作为第三方深度测评,从高端定制、模板建站、低成本快速上线三类…...

【亲测免费】 CISP-DSG 数据安全培训教材课件标准版
CISP-DSG 数据安全培训教材课件标准版 【下载地址】CISP-DSG数据安全培训教材课件标准版 本仓库提供的是“注册数据安全治理专业人员”(Certified Information Security Professional - Data Security Governance,简称 CISP-DSG)的培训教材课…...

【亲测免费】 探索RS485通信的利器:开源项目推荐
探索RS485通信的利器:开源项目推荐 【下载地址】RS485通信程序 本仓库提供了一个完整的RS485通信程序,经过本人亲自测试,程序注释详细,非常适合作为学习和开发的参考例程。无论你是初学者还是有经验的开发者,这个资源都…...

【亲测免费】 开启高效OCR之旅:Delphi集成Tesseract 4.0完全指南
开启高效OCR之旅:Delphi集成Tesseract 4.0完全指南 【下载地址】Delphi调用Tesseract4.0进行OCR识别已打包全部DLL 本仓库提供了通过Delphi环境调用Google的Tesseract OCR引擎4.0版本的示例代码和所有必要的DLL文件。Tesseract是一款强大的开源文字识别系统…...