【论文精读】Deep Residual Learning for Image Recognition
1 Degradation Problem💦
- 深度卷积神经网络在图像分类方面取得了一系列突破。深度网络自然地将低/中/高级特征和分类器以端到端的多层方式集成在一起,特征的“层次”可以通过堆叠层数(深度)来丰富。最近的研究揭示了网络深度是至关重要的,在具有挑战性的ImageNet数据集上的主要结果都利用了“非常深的”模型。许多其他重要的视觉识别任务也极大地受益于非常深度的模型。
- 在深度重要性的驱动下,一个问题出现了:学习更好的网络就像堆叠更多层一样简单吗?回答这个问题的一个障碍是臭名昭著的梯度消失/爆炸问题,它从一开始就阻碍了收敛。目前针对这种问题已经有了解决的方法:对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。
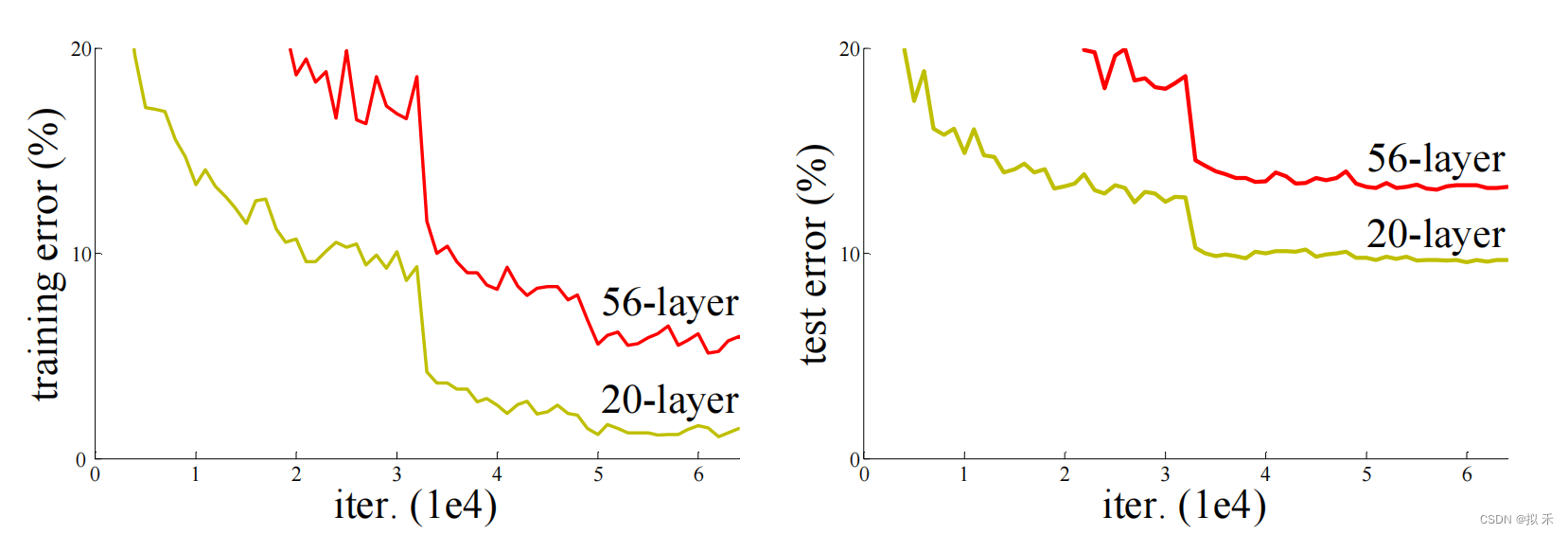
- 上图是使用20层和56层“普通”网络(plain network)的CIFAR-10上的训练误差(左)和测试误差(右)。网络越深,训练误差越大,测试误差越大。在ImageNet上的也有类似现象。
- 网络层数不是太多的时候,模型的正确率确实会随着网络层数的增加而提升,但随着网络层数的增加,正确率也会达到饱和,这个时候如果再继续增加网络的层数,那么正确率就会下降。论文中把这种现象称为退化问题(Degradation Problem),出乎意料的是,这种退化并不是由过拟合引起的,并且在适当深度的模型中增加更多的层会导致更高的训练误差。如果是overfitting的话,则会出现训练误差小,测试误差大的现象,但是二者的结果都相较于浅层网络的误差较大。
2 Residual Block🔥
ResNet 之所以叫残差网络(Residual Network),是因为 ResNet 是由很多残差块(Residual Block)组成的。而残差块的使用,可以解决前面说到的退化问题。残差块如下图所示。
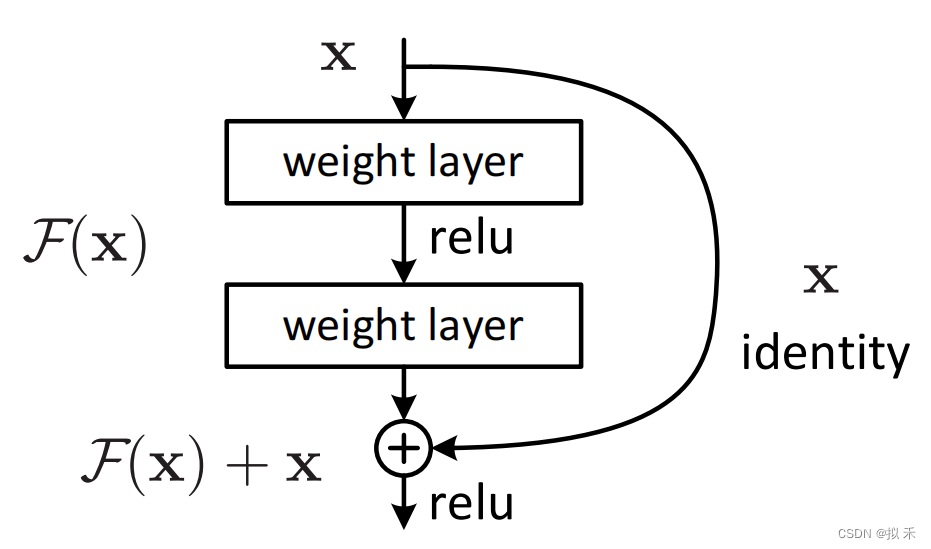
- 残差(residual)在数理统计中是指实际观察值(观测值)与估计值(拟合值)之间的差。
- 假设上图中的 weight layer 是 3×3 的卷积层;F(x) 表示经过两个卷积层计算后得到的结果;identity x 表示恒等映射(identity
mapping),也称为shortcut connections。- 其实就是把 x 的值是不做任何处理直接传过去。最后计算 F(x)+x,这里的 F(x) 跟 x 是种类相同的信号,所以将其对应位置进行相加。
- 我们让 H(x) = F(x)+x ,所以 H(x) 就是观测值(实际的特征映射,就是真实的输出),x 就是估计值(也就是上一层ResNet输出的特征映射)。
- 我们如果使用plain networks(一般的卷积神经网络)那么 H(x) = F(x) ,这样某一层达到最优之后在加深就会出现退化问题。
- 残差就体现在:F(x) = H(x)-x ,我们假设优化残差映射比优化原始的、未引用残差的映射更容易。在极端情况下,如果一个恒等映射 x 是最优的,那么将残差 F(x) 推到 0 比通过一堆非线性层来拟合一个恒等映射要容易得多。
- 进一步理解:因为 x 是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的真实输出 H(x)=x 的话,只要让 F(x)=0 就行了,也就是为了保证下一层的网络状态仍然是最优状态,只需要令 F(x)=0 ,这也就是残差网络需要训练和学习的地方,也说明了深层网络不会变的比浅层网络差,可以选择原地踏步,但不会后退(不绝对)。如果更深层网络学习到了好的特征,整个模型的性能就会提升。
- 如果模型发现 F(x) 很难训练,或者训练没有好处的话,F(x) 就拿不到梯度,模型发现直接拿 x 过去效果就很好了,加上一个 F(x) 对我的loss下降没有什么明显作用的话,那么在梯度反传的时候就拿不到什么梯度,所以 F(x) 的权重就不会被更新了,权重就有可能变得很小,梯度甚至可能变为零,所以ResNet在加深的时候通常不会使模型的效果变坏。
- Identity shortcut connections既不会增加额外的参数,也不会增加计算复杂度。
- 我们在ImageNet上进行了全面的实验,以显示退化问题并评估我们的方法。结果表明:我们的深度残差网络很容易优化,但对应的“普通”网络(简单地堆叠层)在深度增加时表现出更高的训练误差;我们的深度残差网络可以很容易地从深度的大幅增加中获得精度收益,产生的结果比以前的网络要好得多。

残差块可以有多种设计方式,如改变残差块中卷积层的数量,或者残差块中卷积窗口的大小,或者卷积计算后先 ReLU 后 BN,就像搭积木一样,我们可以随意设置。ResNet 研究团队经过很多的测试最终定下了两种他们觉得最好的残差块的结构,如上图所示。
3 Architecture💑
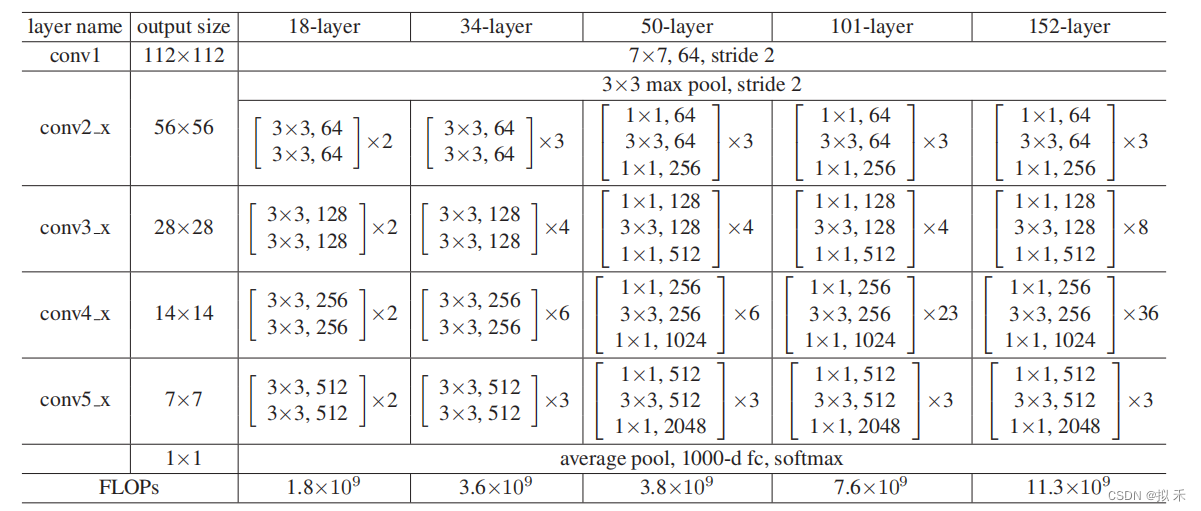
上图是论文中提出的五种ResNet网络结构。若残差映射 F(x) 的结果的维度与跳跃连接 x 的维度不同时,就必须对 x 进行维度变换,维度相同时二者才能进行相加运算。具体方法有:
- Zero-Padding
- 1 * 1卷积(Projection Shortcut)

上图表明ResNet的效果要优于相同深度的plain network。
4 Supplement💋

- 这里的 f(x) 表示深层网络,g(x) 表示浅层网络。
- 对于一般的卷积神经网络,随着网络加深,梯度反向传播时由于多次乘法(如上图的Plain)变得很小,即使有Batch Normalization等手段,但是最后还是会出现梯度消失,导致模型过早的收敛,因为没有梯度,学不动了,最后的结果就会较差。
- 而对于ResNet(如上图的ResNet),即使左边的梯度值很小,但是右边的梯度值比较大,小数加大数,总的梯度还是会比较大的,模型就能训练的动,所以训练速度也较快,不管你后面的网络有多深,我的浅层网络 g(x) 的梯度总是有用的,最后的结果就会变好。残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,很多时候甚至可以提高效率,因此创建类似残差网络可以提升网络性能。
5 Conclusion☀️
- 残差结构的主要作用是传递信号,把深度学习浅层的网络信号直接传给深层的网络。深度学习中不同的层所包含的信息是不同的,一般我们认为深层的网络所包含的特征可能对最后模型的预测更有帮助,但是并不是说浅层的网络所包含的信息就没用,深层网络的特征就是从浅层网络中不断提取而得到的。现在我们给网络提供一个捷径,也就是Shortcut Connections,它可以直接将浅层信号传递给深层网络,跟深层网络的信号结合,从而帮助网络得到更好的效果。
- 从 ResNet 的设计和发展过程中我们可以知道,深度学习是一门非常注重实验的学科,我们需要有创新的好想法,同时也需要大量的实验来支撑和证明我们的想法。有些时候我们无法从理论上推断哪种模型设计或优化方法是最好的,这个时候我们可能就需要做大量的实验来不断尝试,找到最好的结果。如今 ResNet 已经得到广泛的应用和肯定,对深度学习和计算机视觉做出了卓越贡献。
相关文章:
【论文精读】Deep Residual Learning for Image Recognition
1 Degradation Problem💦 深度卷积神经网络在图像分类方面取得了一系列突破。深度网络自然地将低/中/高级特征和分类器以端到端的多层方式集成在一起,特征的“层次”可以通过堆叠层数(深度)来丰富。最近的研究揭示了网络深度是至关重要的,在具…...

Lesson2:基础语法、输出输入
一、基础语法 1、行结构 一个Python程序可分为许多逻辑行,一般来说:一个语句就是一行代码,不会跨越多行。 """比如下面的Python程序,一共有3个逻辑行,每一行都通过print()输出一个结果。""…...

android 9.0去掉前置摄像头闪光灯功能
1.1概述 在9.0的系统rom定制化开发中,在系统中camera2也是非常重要的一部分功能,在很多场合会用到camera2拍照视频,等等功能, 但是在使用过程中发现系统camera2在使用的时候,在前置摄像头进行拍照的时候,会出现闪光灯的情况,对于产品来说,者就是一个大问题,所以产品要求…...

静态分析工具Cppcheck在Windows上的使用
之前在https://blog.csdn.net/fengbingchun/article/details/8887843 介绍过Cppcheck,那时还是1.x版本,现在已到2.x版本,这里再总结下。 Cppcheck是一个用于C/C代码的静态分析工具,源码地址为https://github.com/danmar/cppcheck …...

用一年时间脱胎换骨
生活习惯篇早睡早起11点30之前必须睡觉按时吃饭特别是早餐控糖,少吃甜食早起刷牙后,喝一杯温水保持身材,养成运动健身的习惯养成持续写作的习惯记录选题,金句,素材断舍离,定期整理,把不用的东西…...

全景拼接python旗舰版
前言在这个项目中,您将构建一个管道,将几幅图像拼接成一个全景图。您还将捕获一组您自己的图像来报告最终的结果。步骤1 特征检测与描述本项目的第一步是对序列中的每幅图像分别进行特征检测。回想一下我们在这个类中介绍过的一些特征探测器:…...
常见的字符串与内存操作函数)
(C语言)常见的字符串与内存操作函数
问:1. Solve the problems:我想用三种方法求字符串的长度怎么办?2. strlen处理的字符串中有什么时需要注意:什么只记为什么?当什么不起什么作用时,什么不计算在内,编译器会把什么,什…...

Linux基础笔记总结
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...

R语言学习笔记
1.R语言介绍 2.R语言安装 官网:https://www.r-project.org/ CARN → 选择China中任意镜像站点 → Download R for Windows → base(二进制版本R基础软件)→ Download R-4.2.2 for Windows (76 megabytes, 64 bit) 3.Rstudio安装 https://po…...
【软件测试】企业测试面试题9道,从自我介绍到项目考察+回答......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 1、自我介绍 您好&a…...

《Spring源码深度分析》第8章 数据库连接JDBC
目录标题前言一、数据库连接方式1.JDBC连接数据库2.Spring Jdbc连接数据库(JdbcTemplate)二、JdbcTemplate源码分析1.update/save功能的实现源码分析入口(关键)基础方法execute1.获取数据库连接池2.应用用户设定的输入参数3. 调用回调函数处理4. 资源释放Update中的回调函数2.q…...

ModuleNotFoundError的解决方案【已解决】
问题描述 有包却提示ModuleNotFoundError 在正常情况下,你使用pip或者conda检查是否有相应包的时候,显示的是有的。但是一旦运行程序就会报这个ModuleNotFoundError错误。 问题可能是程序运行环境不对。 解决方案 (1)进入正确…...
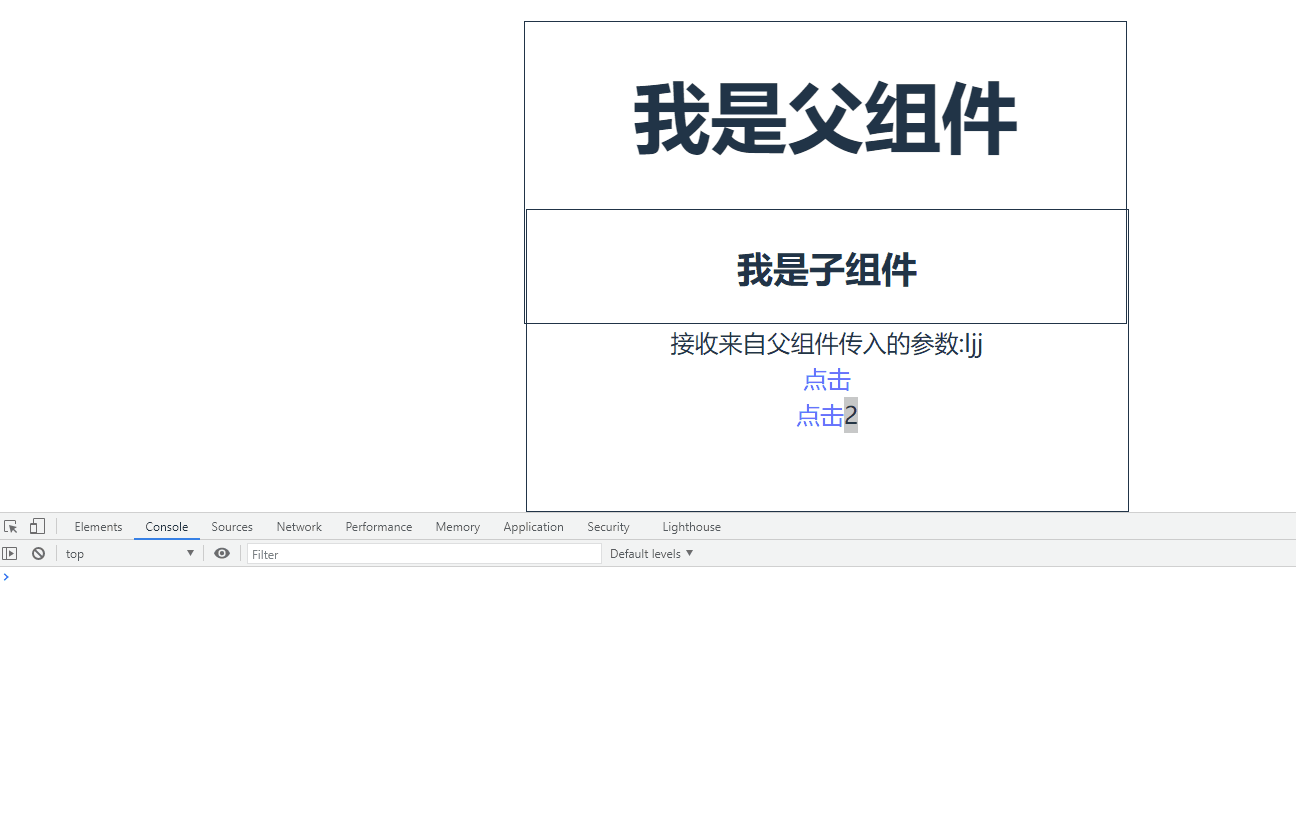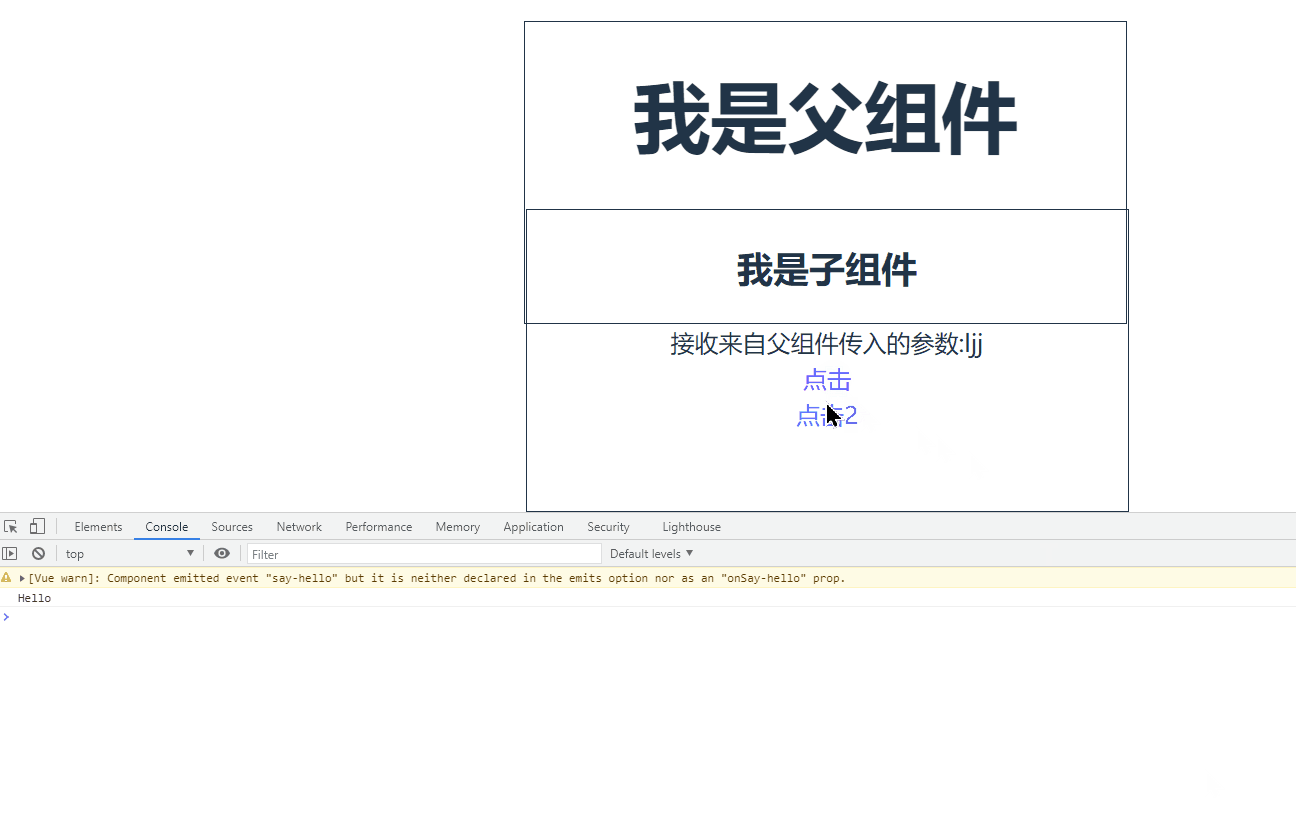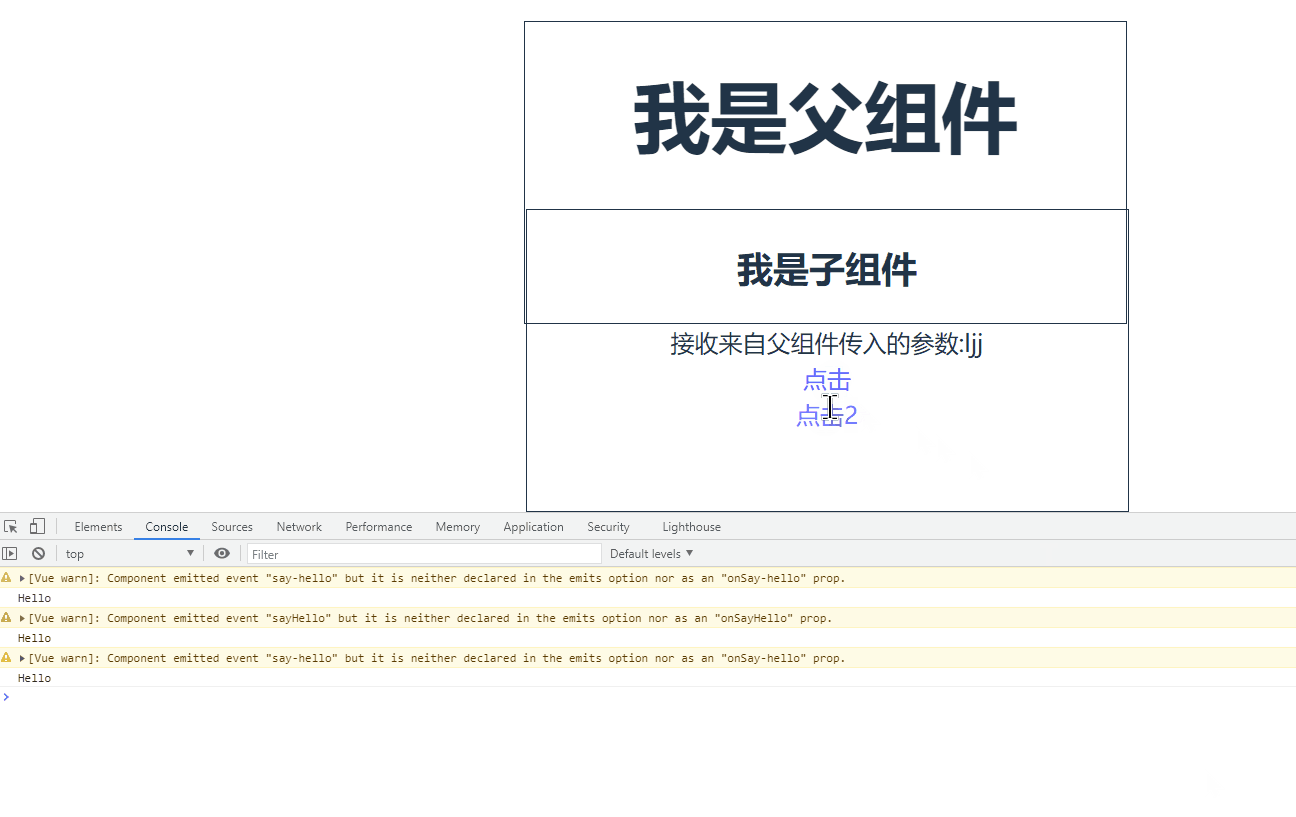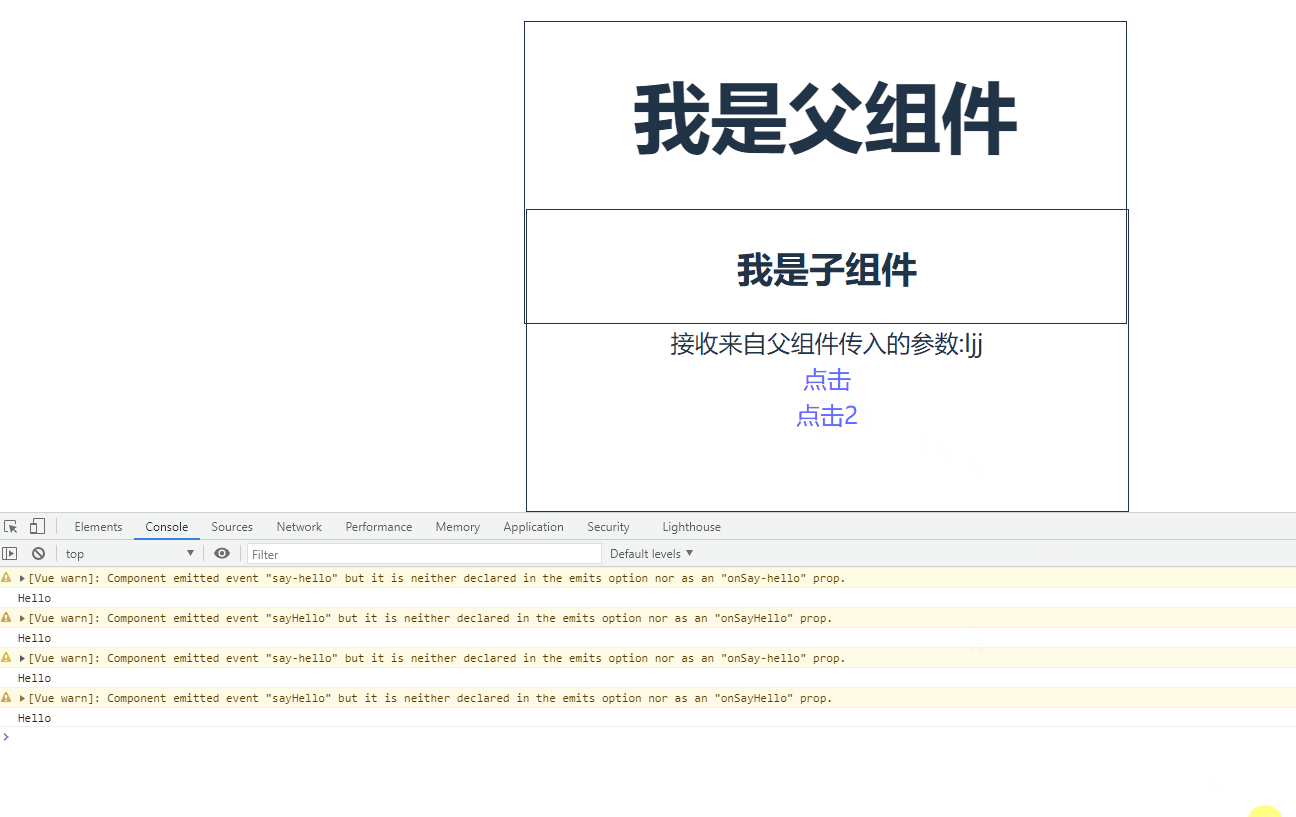
Vue驼峰与短横线分割命名中有哪些坑
目录 0.前言 驼峰和短横线分割命名注意事项 组件注册命名 父子组件数据传递时命名 父子组件函数传递 0.前言 Vue驼峰命名法指的是将变量以驼峰形式命名,例如 userName、userId 等,而短横线分隔符法则指的是用短横线分隔变量名,例如 user…...

从文件中加载数据以及异常处理
上期学习了数据的存储,这次学习数据的加载 你可以使用把openpyxl.load_workbook() 来打开一个已经存在的工作簿 >>> from openpyxl import load_workbook >>> wb load_workbook(filename empty_book.xlsx) >>> sheet_ranges wb[ran…...
【JavaSE】方法的使用
方法的使用BIT-5-方法的使用绪论1. 方法概念及使用1.1什么是方法1.2 方法定义1.3 实参和形参的关系(重要)1.4 没有返回值的方法2. 方法重载2.1 为什么需要方法重载2.2 方法重载概念3. 递归3.1 生活中的故事3.2 递归的概念3.2 递归执行过程分析3.3 递归练…...

ModelScope 垂类检测系列模型介绍
文章目录ModelScope介绍垂类模型介绍调用方式1 Demo Service2 Notebook3 本地使用* 二次开发总结ModelScope介绍 ModelScope 是阿里达摩院推出的 中文版模型即服务(MaaS, Model as a Service)共享平台。该平台在2022年的云栖大会上发布,之前…...
Linux | Linux卸载和安装MySQL(Ubuntu版)
最近又来到了Linux学习了,原因是要接触云服务器相关知识, 所以博主整理了一些关于Linux的知识, 欢迎各位朋友点赞收藏,天天开心丫,快乐写代码! Linux系列文章请戳 Linux教程专栏 目录 一、卸载MySQL 1…...
【C1】数据类型,常量变量,输入输出,运算符,if/switch/循环,/数组,指针,/结构体,文件操作,/编译预处理,gdb,makefile,线程
文章目录1.数据类型:单双引号,char(1B),int/float(32位系统,大小一样4B,但存储方式不同),double(8B),long double…...

【深度学习】pytorch的基础操作
import torch import numpy as np # 1.1 根据已有的数据创建张量 def test01(): # 1.1 创建标量 data torch.tensor(10) print(data) # 1.2 使用numpy数组来创建张量 data np.random.randn(2,3) data torch.tensor(data) print(data) # 1.3使用list…...
MWORKS--同元软控MWORKS介绍、安装与使用
MWORKS--同元软控MWORKS介绍、安装与使用1 同元软控介绍1.1 同元软控简介1.2 同元软控发展历史2 MWORKS介绍2.1 MWORKS简介2.2 MWORKS产品描述3 装备数字化3.1 发展3.2 内涵3.3 系统模型发展成为产品的一部分3.4 MWORKS系统模型数据管理3.4 MWORKS为装备数字化提供的套件4 下载…...
)
别再只用memcpy了!手把手教你用memcpy_s写出更安全的C语言代码(附VS2022实战)
从memcpy到memcpy_s:现代C语言安全编程实战指南 在Visual Studio 2022的编译输出窗口中,那个刺眼的C4996警告已经成为许多C语言开发者的"老朋友"。当看到"error C4996: memcpy: This function or variable may be unsafe"时…...
中文翻译项目:打破语言壁垒,赋能中文AI社区)
AI技能(SKILL)中文翻译项目:打破语言壁垒,赋能中文AI社区
1. 项目概述:一个为中文AI社区“破壁”的翻译工程如果你和我一样,在过去一年里深度使用过Claude、ChatGPT或者各类AI Agent平台,那你一定对“SKILL”这个概念不陌生。简单来说,SKILL就是AI的“技能包”,它把特定领域的…...

动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化
动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化 项目地址: https://gitee.com/jiucenglou/jvm-tuning-lab 技术栈: Java 8 Maven 适合人群: Java 开发者、性能调优初学者、面试准备者 🤔 为什么写这个项目? 在实际开发和面试中…...
)
AI原生图计算不是“加个GNN层”那么简单:SITS 2026定义的5层工程化成熟度模型(附自测清单+迁移路线图)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

SteamAutoCrack:3步自动化破解Steam游戏的终极解决方案
SteamAutoCrack:3步自动化破解Steam游戏的终极解决方案 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 你是否厌倦了每次想离线玩游戏时都要手动破解的繁琐过程?…...

从ADI收购LTC看电源管理趋势:软件定义电源与能量收集技术解析
1. 从一笔天价收购案,看电源管理技术的未来十年2016年,模拟芯片行业发生了一场地震级的并购:模拟巨头亚德诺半导体(Analog Devices Inc., ADI)以148亿美元的天价,收购了以高性能模拟芯片闻名的凌力尔特&…...

STM32CubeMX LL库配置外部中断,从按键消抖到中断嵌套的实战避坑指南
STM32CubeMX LL库外部中断深度优化:从硬件消抖到中断嵌套的工程实践 当你的嵌入式系统需要实时响应外部事件时,外部中断(EXTI)往往是最高效的选择。但在实际项目中,简单配置EXTI只是开始——按键抖动导致的误触发、中断优先级冲突引发的死锁、…...

从SPICE到Q-SPICE:四阶累积量如何重塑阵列信号处理的超分辨能力
1. 从SPICE到Q-SPICE:为什么我们需要四阶累积量? 我第一次接触SPICE算法是在处理雷达信号的时候。当时团队遇到一个头疼的问题:在强噪声环境下,传统算法就像近视眼观察星空,明明知道那里有信号,却怎么也分辨…...

TQVaultAE终极指南:解锁泰坦之旅无限仓库与装备管理新境界
TQVaultAE终极指南:解锁泰坦之旅无限仓库与装备管理新境界 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾在泰坦之旅的冒险中,面对满仓的传…...

自研系统与Odoo ERP数据集成中间件设计与实现
1. 项目概述:连接两个世界的桥梁最近在折腾企业信息化系统集成时,遇到了一个挺典型的场景:公司内部有一套自研的、基于特定业务逻辑的微服务应用(我们内部戏称为“雾系统”),同时又在使用Odoo这套成熟的ERP…...