【深度学习】pytorch的基础操作
import torch
import numpy as np
# 1.1 根据已有的数据创建张量
def test01():
# 1.1 创建标量
data = torch.tensor(10)
print(data)
# 1.2 使用numpy数组来创建张量
data = np.random.randn(2,3)
data = torch.tensor(data)
print(data)
# 1.3使用list列表创建张量
data = [[10., 20., 30.], [40., 50., 60.]]
print(data)
test01()
# 2. 创建指定形状的张量
def test02():
# 2.1 创建一个2行3列的张量
data = torch.Tensor(2,3)
print(data)
# 2.2 可以创建指定值得张量
# 注意传递列表
data = torch.Tensor([2, 3])
print(data)
data = torch.Tensor([10])
print(data)
test02()
# 3.创建指定类型的张量
def tensor03():
# 前面创建的张量都是使用默认类型或者元素类型
# 创建一个 int32类型的张量
data = torch.IntTensor(2,3)
print(data)
torch.ShortTensor(2,3) # 表示创建的是int16张量
torch.LongTensor(2,3) # 表示创建int32张量
torch.FloatTensor(2,3) # 表示创建Float32张量
# 注意:如果创建指定类型的张量,但是传递的数据不匹配,会发生类型转换
data = torch.IntTensor([2.5, 3.5])
print(data)
tensor03()
## 创建线性和随机张量
1. torch.arange 和 torch.linspace 创建线性张量
2. torch.random int_seed 和 torch.random.manual_seed 随机种子设置
3. torch.randn 创建随机张量
import torch
# 1. 创建线性空间的张量
def test01():
# 1.在指定区间按照步长生成元素[start, end, step]
data = torch.arange(0,10,2)
print(data)
test01()
# 在指定区间按照元素个数生成
torch.linspace(0,11,10)
# 创建随机张量
torch.randn(2,3)
# 随机数种子设置
torch.random.initial_seed()
# 必须在同一段代码前提下,可以这样使用,能够浮现结果
torch.random.manual_seed(100)
torch.randn(2,3)
torch.randn(2,3)
## 创建01张量
torch.ones, torch.ones_like
torch.zeros, torch.zeros_like
torch.full, torch.full_like
a = torch.ones(3,2)
a
torch.zeros_like(a)
ccc = torch.full((2,3),5)
torch.full_like(ccc,10)
## 张量的指定类型转换
tensor.type(torch.DoubleTensor)
torch.double()
data = torch.full([2,3],10)
data
print(data.dtype)
## 类型转换
data = torch.full([2,3], 10)
data.dtype
data
# 转化后需要承接一下
data = data.type(torch.DoubleTensor)
data.dtype
# 使用具体类型的函数进行转换
data = torch.full([2,3],10)
data.dtype
# 这种方式更加便捷
data = data.double()
data.dtype
data.int(), data.short(), data.long(), data.float()
# int 32 int 16 int 64 float 32
### 张量的基本运算 add, sub, mul, div, neg等函数, 以及这些函数的带下划线的版本 add_ 、 sub_ 、 mul_ 、 div_ 、 neg_, 其中带下划线的版本为修改原数据
import numpy as np
data = torch.randint(0,10,[2,3])
data
# 1. 不修改原数据
new_data = data.add(10)
new_data
new_data = data.add(10)
new_data
data.add_(10)
# 其它函数
data.sub(100)
data.mul(100)
data.div(100)
data.neg()
### 阿达玛积运算
阿达玛积是指矩阵对应位置的元素相乘
data1 = torch.tensor([[1,2],[3,4]])
data2 = torch.tensor([[5,6],[7,8]])
data = torch.mul(data1, data2)
data
data = data1 * data2
data
### 点集运算
(m,n) * (n,p) = (m,p)
1.运算符用 @ 用于进行两矩阵的点乘运算
2. torch.mm 2维度 torch.bmm 3维度 torch.matmul 多维度
data1 = torch.tensor([[1,2],[3,4],[5,6]])
data2 = torch.tensor([[5,6],[7,8]])
# 第一种方法
data = data1 @ data2
data
data = torch.mm(data1,data2)
data
# 第三种方式
data = torch.matmul(data1, data2)
data
data1 = torch.randn(3,4,5)
data2 = torch.randn(3,5,8)
# b = batch
data = torch.bmm(data1, data2)
data
data1 = torch.randn(3,4,5)
data2 = torch.randn(3,5,8)
torch.matmul(data1,data2).shape
## 指定运算设备
Pytorch 默认会将张量创建在CPU控制的内存中.
1. 使用cuda方法
2. 直接将张量创建在指定设备上
3. 使用to方法
data = torch.tensor([10,20,30])
data,data.device
data = data.cuda()
data,data.device
data = data.cpu()
data,data.device
data = torch.tensor([10,20,30], device="cuda:0")
data.device
data = data.cpu()
data
## 张量的类型转换
张量和numpy的相互转换
data_tensor = torch.tensor([2,3,4])
data_tensor
data_numpy = data_tensor.numpy()
data_numpy
type(data_tensor), type(data_numpy)
注意此时data_tensor和data_numpy 共享内存, 修改其中一个,另外一个也会跟着改变,可以使用copy函数避免共享
data_numpy[0] = 100
data_numpy,data_tensor
data_tensor = torch.tensor([2,3,4])
data_numpy = data_tensor.numpy().copy()
data_numpy[0] = 222
data_numpy
data_tensor
### numpy 转换成张量
1. 使用 from_numpy 可以将ndarray数组转换为Tensor, 默认共享内存,使用copy函数避免共享
2. 使用torch.tensor可以将ndarray数组转换为Tensor. 默认不共享内存
data_numpy = np.array([2,3,4])
data_numpy
# 浅拷贝
data_tensor = torch.from_numpy(data_numpy)
data_tensor
data_tensor = torch.from_numpy(data_numpy.copy())
data_tensor
data_numpy[0] = 100
data_numpy, data_tensor
# 2. 使用torch.tensor 函数
data_numpy = np.array([2,3,4])
data_tensor = torch.tensor(data_numpy)
data_numpy,data_tensor
data_numpy[0] = 100
data_numpy,data_tensor
### 标量张量和数字的转换
对于只有一个元素的张量,使用item方法将该值从张量中提取出来
# 当张量只包含一个元素时,可以通过使用item函数提取出该值
data = torch.tensor([30.])
print(data.item(),data)
data = torch.tensor(30)
data,data.item()
t1 = torch.tensor(30)
t2 = torch.tensor([30])
t3 = torch.tensor([[30]])
print(t1, t2, t3, t1.shape, t2.shape, t3.shape)
# t1 是标量, t2 是一维张量, t2 是二维
## 注意:张量中只有一个元素,如果有多个元素的化,使用item函数可能就会报错
t4 = torch.tensor([30,40])
t4
t4[0].item()
t4.item()
相关文章:

【深度学习】pytorch的基础操作
import torch import numpy as np # 1.1 根据已有的数据创建张量 def test01(): # 1.1 创建标量 data torch.tensor(10) print(data) # 1.2 使用numpy数组来创建张量 data np.random.randn(2,3) data torch.tensor(data) print(data) # 1.3使用list…...
MWORKS--同元软控MWORKS介绍、安装与使用
MWORKS--同元软控MWORKS介绍、安装与使用1 同元软控介绍1.1 同元软控简介1.2 同元软控发展历史2 MWORKS介绍2.1 MWORKS简介2.2 MWORKS产品描述3 装备数字化3.1 发展3.2 内涵3.3 系统模型发展成为产品的一部分3.4 MWORKS系统模型数据管理3.4 MWORKS为装备数字化提供的套件4 下载…...
Python 解决dilb和face_recognition第三方包安装失败
目录 dilb和face_recognition第三方包安装失败 亲测有效的解决方法:whl安装方式 dilb和face_recognition第三方包安装失败 场景复现:因为需要用到dlibface_recognition,基于OpenCV做一些人脸识别的项目,在Pycharm中进行pip清华…...

Mac系统Mysql的8.0.22版本安装笔记和密码重置修改密码等问题方法
忘记密码官网教程地址:https://dev.mysql.com/doc/refman/5.7/en/resetting-permissions.html 5.7数据库安装指南参考:https://jingyan.baidu.com/article/fa4125ac0e3c2928ac709204.html 初次安装8.0.22遇到许多坑,密码修改失败;…...
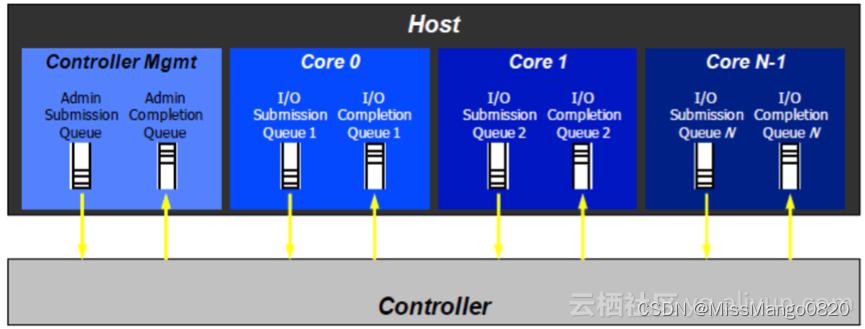
驱动 | Linux | NVMe 不完全总结
本文主要参考这里 1’ 2 的解析和 linux 源码 3。 此处推荐一个可以便捷查看 linux 源码的网站 bootlin 4。 更新:2022 / 02 / 11 驱动 | Linux | NVMe 不完全总结NVMe 的前世今生从系统角度看 NVMe 驱动NVMe CommandPCI 总线从架构角度看 NVMe 驱动NVMe 驱动的文件…...
一个测试人员,在现阶段的环境下如何在测试行业发展和自我价值。
前言周末和几个测试圈子里的大佬饭局上聊了一些职场和测试职业发展相关的话题,我将聊天的内容做了整理和阐述。。朋友圈有测试同学对这篇文章提了比较深刻的建议,下面是他的评价和建议:评价:据说是大佬饭桌总结,有两点…...
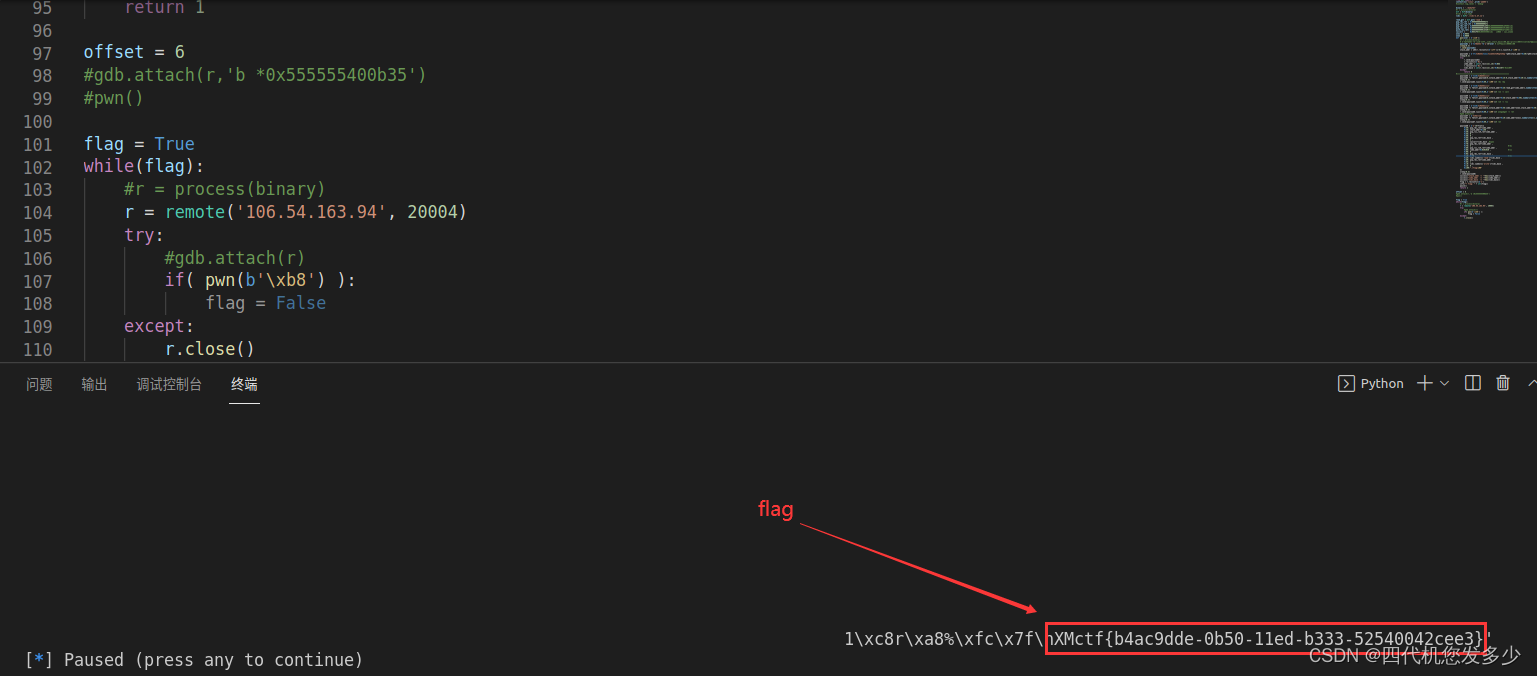
pwn手记录题2
fastbin_reverse_into_tcache(2.34) 本题所使用的libc版本为2.34;(最新版 libc2.34版本已经没有了所谓的hook函数,甚至exit_hook(实际为某个函数指针)也已经不能够使用;能够利用的手法已经很少了; 高版本glibc堆的几…...

CSS ~ 从入门到入坑。
CSS ~ 从入门到入坑。 文章目录CSS ~ 从入门到入坑。what。css 三种实现方式。选择器。id 选择器 > class 选择器 > 标签选择器。标签选择器。类选择器。id 选择器。层次选择器。后代选择器。子选择器。相邻兄弟选择器。通用选择器。结构伪类选择器。属性选择器。字体风格…...

成都哪家机构的Java培训比较好,求一个不坑的?
关于这个问题,相信你会得到很多条答案,以及很多家机构的自荐。既然如此,不如也了解一下老牌IT职业教育机构:有足够丰富的教学经验,丰富的教学产品资源以及成熟的就业保障体系,还有就是承担风险的能力。 很…...

《爆肝整理》保姆级系列教程python接口自动化(十二)--https请求(SSL)(详解)
简介 本来最新的requests库V2.13.0是支持https请求的,但是一般写脚本时候,我们会用抓包工具fiddler,这时候会 报:requests.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590) 小编…...

离线数据仓库
1 数据仓库建模 1.1 建模工具 PowerDesigner/SQLYog/EZDML… 1.2 ODS层 (1)保持数据原貌不做任何修改,起到备份数据的作用。 (2)数据采用压缩,减少磁盘存储空间(例如:压缩采用LZO&…...
【前端】Vue项目:旅游App-(23)detail:房东介绍、热门评论、预定须知组件
文章目录目标过程与代码房东介绍landlord热门评论HotComment预定须知Book效果总代码修改或添加的文件detail.vuedetail-book.vuedetail-hotComment.vuedetail-landlord.vue参考本项目博客总结:【前端】Vue项目:旅游App-博客总结 目标 根据detail页面获…...

JUC并发编程与源码分析
一、本课程前置知识及要求说明 二、线程基础知识复习 三、CompletableFuture 四、说说Java"锁"事 8锁案例原理解释: 五、LockSupport与线程中断 六、 Java内存模型之JMM 七、volatile与JMM 八、CAS 九、原子操作类之18罗汉增强 十、聊聊ThreadLocal 十一、Java对…...
Spark09: Spark之checkpoint
一、checkpoint概述 checkpoint,是Spark提供的一个比较高级的功能。有时候,我们的Spark任务,比较复杂,从初始化RDD开始,到最后整个任务完成,有比较多的步骤,比如超过10个transformation算子。而…...

《剑指offer》:数组部分
一、数组中重复的数字题目描述:在一个长度为n的数组里的所有数字都在0到n-1的范围内。 数组中某些数字是重复的,但不知道有几个数字是重复的。也不知道每个数字重复几次。请找出数组中任意一个重复的数字。 例如,如果输入长度为7的数组{2,3,1…...
基于微信小程序图书馆座位预约管理系统
开发工具:IDEA、微信小程序服务器:Tomcat9.0, jdk1.8项目构建:maven数据库:mysql5.7前端技术:vue、uniapp服务端技术:springbootmybatis本系统分微信小程序和管理后台两部分,项目采用…...
)
剑指 Offer Day1——栈与队列(简单)
本专栏将记录《剑指 Offer》的刷题,传送门:https://leetcode.cn/study-plan/lcof/。 目录剑指 Offer 09. 用两个栈实现队列剑指 Offer 30. 包含min函数的栈剑指 Offer 09. 用两个栈实现队列 原题链接:09. 用两个栈实现队列 class CQueue { pu…...
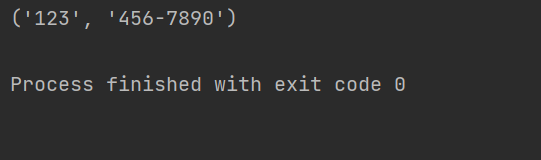
详解Python正则表达式中group与groups的用法
在Python中,正则表达式的group和groups方法是非常有用的函数,用于处理匹配结果的分组信息。 group方法是re.MatchObject类中的一个函数,用于返回匹配对象的整个匹配结果或特定的分组匹配结果。而groups方法同样是re.MatchObject类中的函数&am…...

Spring面试重点(三)——AOP循环依赖
Spring面试重点 AOP 前置通知(Before):在⽬标⽅法运行之前运行;后置通知(After):在⽬标⽅法运行结束之后运行;返回通知(AfterReturning):在⽬标…...
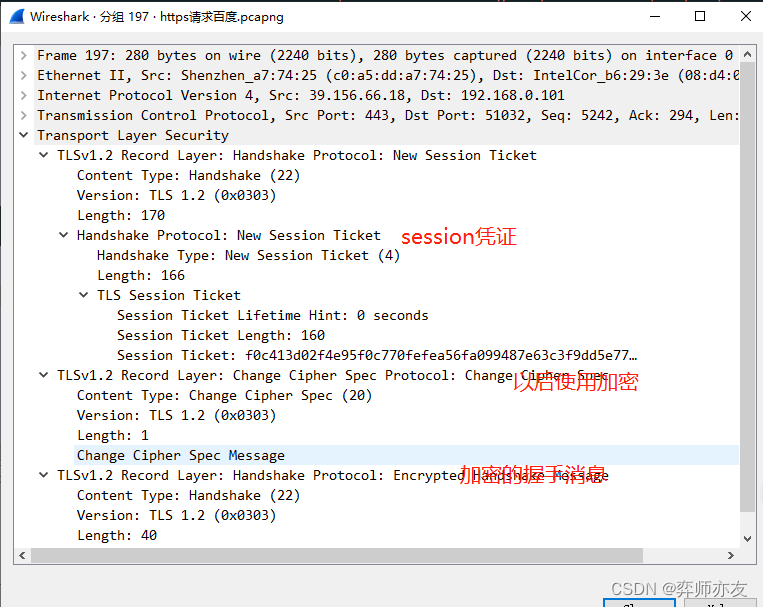
计算机网络之HTTP04ECDHE握手解析
DH算法 离散读对数问题是DH算法的数学基础 (1)计算公钥 (2)交换公钥,并计算 对方公钥^我的私钥 mod p 离散对数的交换幂运算交换律使二者算出来的值一样,都为K k就是对称加密的秘钥 2. DHE算法 E&#…...

模块化IC设计流程:应对复杂芯片挑战的解决方案
1. 现代IC设计面临的挑战与模块化流程的价值在当今半导体行业,芯片设计团队正面临前所未有的复杂挑战。随着工艺节点不断演进至5nm及以下,设计复杂度呈指数级增长。我曾参与的一个65nm SoC项目,团队最初采用传统线性设计流程,结果…...
)
手把手教你用Gstreamer和V4L2在Zynq MPSoC上搭建视频流Pipeline(HDMI IN to DP OUT)
从HDMI到DP:Zynq MPSoC视频流处理全链路实战指南 当你的Zynq MPSoC开发板已经完成硬件设计,Petalinux系统也顺利启动,却发现HDMI输入的视频信号无法正确显示在DP接口的显示器上——这种"最后一公里"的集成问题往往最令人抓狂。本文…...

Android本地AI智能家居框架:ZeroClaw架构设计与工程实践
1. 项目缘起与核心愿景几年前,我还在为一个智能家居项目焦头烂额,试图让家里的灯光、空调和音箱能听懂人话,而不是只会执行预设的“回家模式”或“睡眠模式”。当时市面上主流的方案,要么是依赖某个封闭的云平台,所有指…...

重温DIRE:走向通用人工智能生成的图像检测
1.摘要生成模型的快速发展提高了图像质量,并使图像合成广泛可用,引起了对内容可信度的关注。为了解决这个问题,我们提出了一种称为通用重建残差分析(UR2EA)的方法来检测合成图像。我们的研究表明,当通过预训练的扩散模型重建GAN和…...

碧蓝航线Perseus补丁:零偏移设计实现全皮肤解锁的终极指南
碧蓝航线Perseus补丁:零偏移设计实现全皮肤解锁的终极指南 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 在碧蓝航线这款广受欢迎的海战游戏中,玩家们常常为那些精美的限定皮肤只…...
)
ClaudeCode入门08-Git配合(小白入门:不知道怎么写Git提交记录?让AI自动帮你写好)
🎯 本文目标 学会用 Claude Code 自动化 Git 工作流:自动写 Commit Message、管理分支、处理冲突。 😰 Git 新手的痛点 git commit -m "fix" git commit -m "update" git commit -m "修改了一些东西" 不知道 Conventional Commits 是什么 …...
自动发布神器)
Wechatsync(文章同步助手)自动发布神器
下载地址:https://www.chajianxw.com/product-tool/16773.html 安装教程:https://www.chajianxw.com/tutorial/how-to-install-chrome-plugin.html AI-Skills 技能包一键调用:https://ai-skills.ai/?inviteCode=S2JV3NCK 目录 一、引言 二、系统整体架构设计 核心技术栈…...

Windows系统mmcndmgr.dll文件丢失无法启动程序解决
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

暗黑破坏神2存档编辑终极指南:5分钟掌握免费Web修改器
暗黑破坏神2存档编辑终极指南:5分钟掌握免费Web修改器 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2中无尽的刷装备和重复练级而苦恼吗?想快速体验不同职业的build却不想投入数百小时…...

完整指南:3分钟解锁你的加密音乐文件
完整指南:3分钟解锁你的加密音乐文件 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经遇到过这样的情况:从音乐平台下载的歌曲只能在特定应…...