ComfyUI+MuseV+MuseTalk图片数字人
电脑配置
GPU12G+,如果自己电脑配置不够,选择云gpu,我就是用的这个,自己电脑太老配置跟不上
环境:
Python 3.11.8
torch 2.2.1
cuda_12.1
资源提供:
链接:https://pan.baidu.com/s/1_idZbFSl4W12ZooBaRJOpA
提取码:7x21
muse/data:数据支持防止到models中对应位置
muse/ComfyUI.ZIP:完整包(包括 ComfyUI+ComfyUI-Manager+MuseV资源+MuseTalk资源),差不多就是直接用这个资源就行了,包含了所有
一、ComfyUI
https://github.com/comfyanonymous/ComfyUI.git
安装:
pip install -r requirements.txt启动服务:
python main.py --listen=0.0.0.0 --port=8080二、ComfyUI-Manager
https://github.com/ltdrdata/ComfyUI-Manager.git
将ComfyUI-Manager移动到ComfyUI/custom_nodes下
三、ComfyUI-MuseV
GitHub - chaojie/ComfyUI-MuseV
通过ComfyUI-Manager安装musev

下载MuseV需要的models
huggingface-cli download --resume-download TMElyralab/MuseV --local-dir ComfyUI/models/diffusers/TMElyralab/MuseV四、ComfyUI-MuseTalk
GitHub - chaojie/ComfyUI-MuseTalk
安装ComfyUI-MuseTalk

下载Talk相关model:
-
Download our trained weights.
-
Download the weights of other components:
- sd-vae-ft-mse
- whisper
- dwpose
- face-parse-bisent
- resnet18
文件列表:
ComfyUI/models/diffusers/TMElyralab/MuseTalk/
├── musetalk
│ └── musetalk.json
│ └── pytorch_model.bin
├── dwpose
│ └── dw-ll_ucoco_384.pth
├── face-parse-bisent
│ ├── 79999_iter.pth
│ └── resnet18-5c106cde.pth
├── sd-vae-ft-mse
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── whisper└── tiny.pt安装完后会提示web页面会提示重启,不过会有很多其它的问题,后面有各种问题的解决方案。
通过右边菜单load加载从https://github.com/chaojie/ComfyUI-MuseTalk/blob/main/wf.json 下载的文件。
并且上传视频和音频,视频可以从浏览器上传,但是音频需要手动上传到服务器的后台,填写绝对路径。
最后点击Queue Prompt

等待几分钟最终得到如图结果:
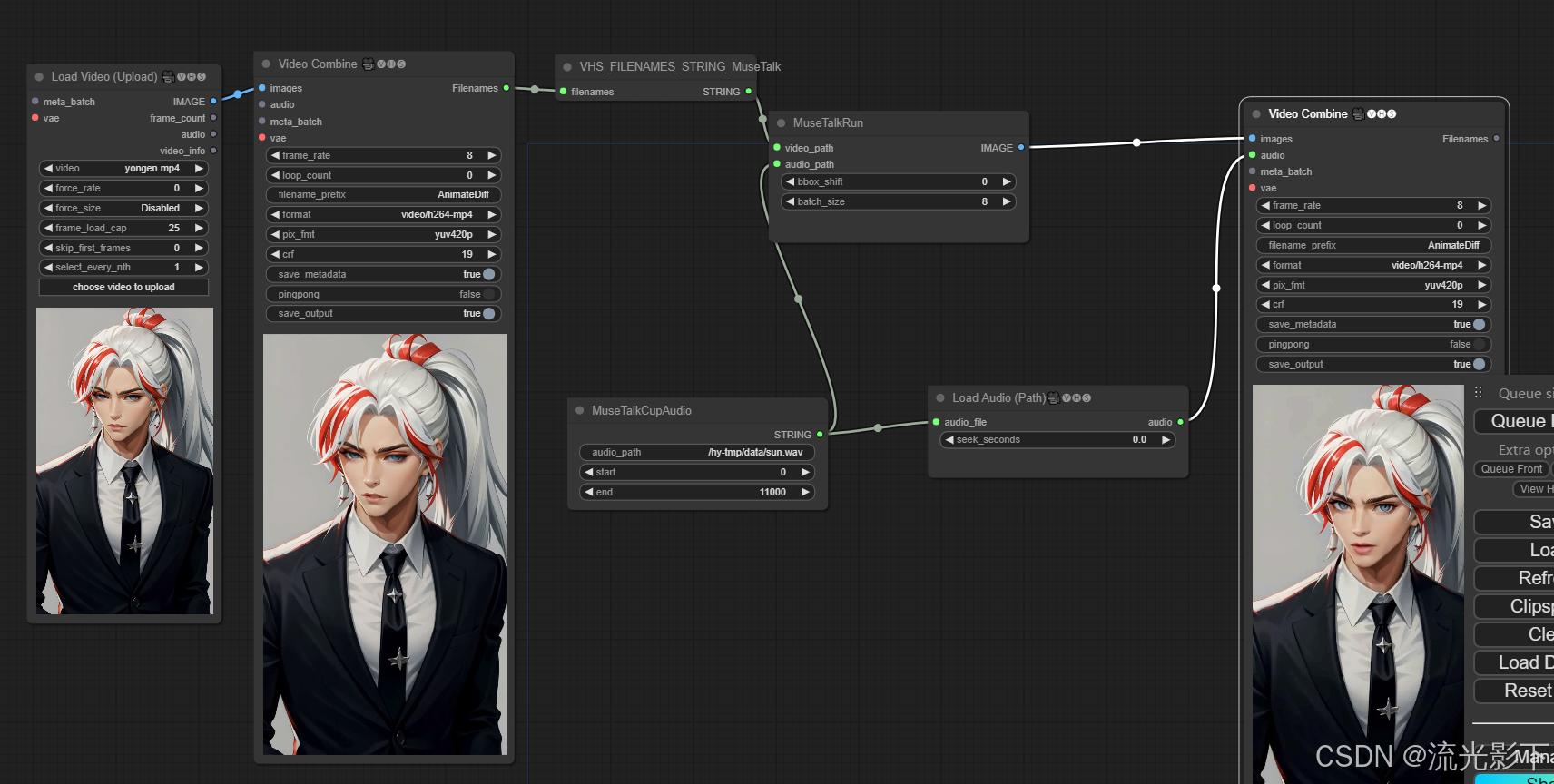
这里有点意思是需要把frame_rate设置成8,并且需要设置音频文件的end时间
五、使用总结
Musev使用部分还行,有的会出现shutterstock水印,有的会出现视频中多一只手,视频中人物换成另一个,体验下来并不是有多好多好,感觉离github上效果还是蛮大的
MuseTalk比Wav2lip效果好点吧,下巴位置模糊一些,给人的感觉像是wav2lip的升级版,由底部透明方框变成了把方框模糊的感觉
最后,这两个工具如果想直接用,个人感觉不太现实,如果想在AI上研究还是可以的,如果想做自媒体,还是去找国外的平台吧,可能需要点钱,不过比用开源的好多的。测试了几款开源数字人,还没遇到好用的,包括最新出来的Hallo
错误解决:
musev出现问题
1 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'omegaconf'
pip install omegaconf2 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'pandas'
pip install pandas3 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'sklearn'
pip install scikit-learn4 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'librosa'
pip install librosa5 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'ffmpeg'
pip install ffmpeg6 Cannot import /hy-tmp/ComfyUI/custom_nodes/ComfyUI-MuseV module for custom nodes: No module named 'easydict'
pip install easydict7 ModuleNotFoundError: No module named 'ip_adapter'
pip install ip_adapter8 ImportError: cannot import name 'StableDiffusionPipeline' from 'diffusers' (unknown location)
pip install diffusers
9 ModuleNotFoundError: No module named 'xformers'
pip install xformers10 RuntimeError: operator torchvision::nms does not exist
pip install torch torchvision --upgrade11 ImportError: cannot import name 'ProjPlusModel' from 'ip_adapter.ip_adapter_faceid'
pip uninstall ip_adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git12 ModuleNotFoundError: No module named 'skimage'
pip install scikit-image13 ModuleNotFoundError: No module named 'timm'
pip install timmmusetalk问题
1 ModuleNotFoundError: No module named 'mmcv'
pip install 'mmcv>=2.0.0rc4,<2.2.0'
2 ModuleNotFoundError: No module named 'mmdet'
pip install mmdet3 RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work
warn("Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work", RuntimeWarning)
sudo apt install ffmpeg4 AttributeError: module 'ffmpeg' has no attribute 'Error'
卸载低版本的ffmpeg
pip uninstall ffmpeg
pip uninstall ffmpeg_python重新安装
pip install ffmpeg-python参考文档:
版本匹配:Installation — mmcv 2.2.0 文档
训练数据:https://civitai.com/user/impactframes
听说最近又出了一款比较好的图片数字人的开源工具,不过还没有测试
GitHub - fudan-generative-vision/hallo: Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
相关文章:
ComfyUI+MuseV+MuseTalk图片数字人
电脑配置 GPU12G,如果自己电脑配置不够,选择云gpu,我就是用的这个,自己电脑太老配置跟不上 环境: Python 3.11.8 torch 2.2.1 cuda_12.1 资源提供: 链接:https://pan.baidu.com/s/1_idZbF…...

【Python】从基础到进阶(三):深入了解Python中的运算符与表达式
🔥 个人主页:空白诗 文章目录 一、引言二、运算符1. 算术运算符2. 比较运算符3. 逻辑运算符4. 位运算符5. 赋值运算符6. 其他运算符 三、表达式1. 表达式的定义2. 运算符的优先级3. 使用括号提升可读性4. 组合运算符与复合表达式 四、案例:计…...

C#的DllImport使用方法
1. 托管代码与非托管代码 托管代码:我们编写的C#代码(也包括.net平台上的其他语言,如VB,J#等),首先经过编译器把代码编译成中间语言(IL),当方法被调用时,公共…...
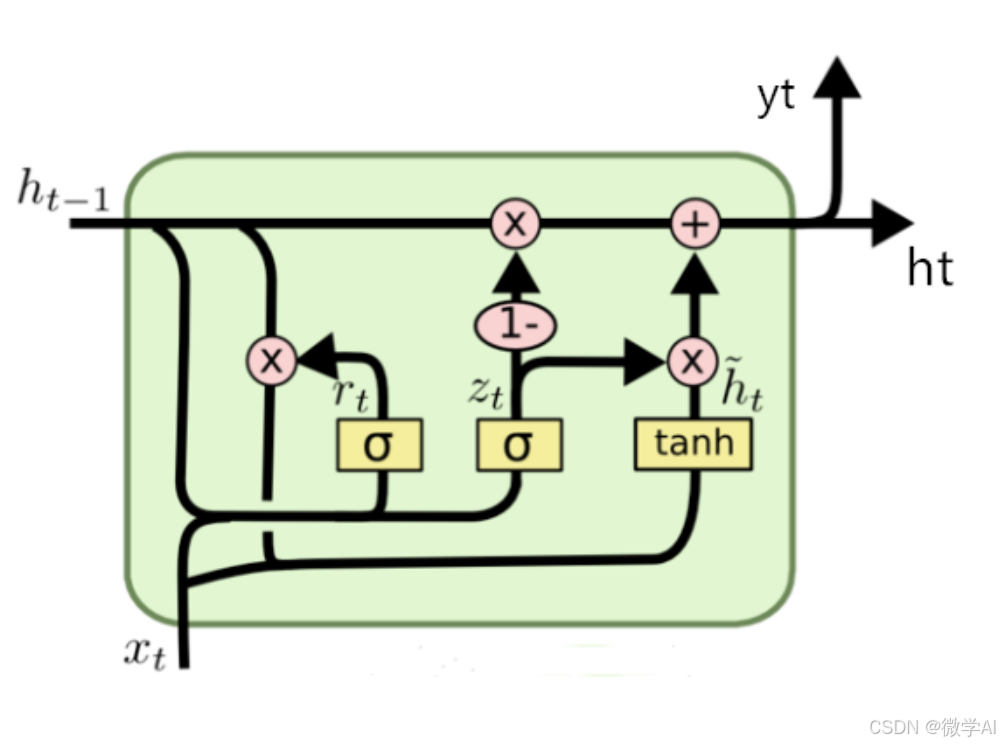
人工智能算法工程师(中级)课程11-PyTorch神经网络之循环神经网络RNN与代码详解
大家好,我是微学AI,今天给大家介绍一下人工智能算法工程师(中级)课程11-PyTorch神经网络之循环神经网络RNN与代码详解。循环神经网络(Recurrent Neural Network,RNN)是一种处理序列数据的神经网络。本文将详细介绍RNN网…...

服务端生成RSA密钥实例
RSA非对称加密算法的一种,这里分享一下服务端生成公钥和私钥的实例,并打印出来。 一:实例代码 package mainimport ("bufio""crypto/rand""crypto/rsa""crypto/x509""encoding/pem"&quo…...
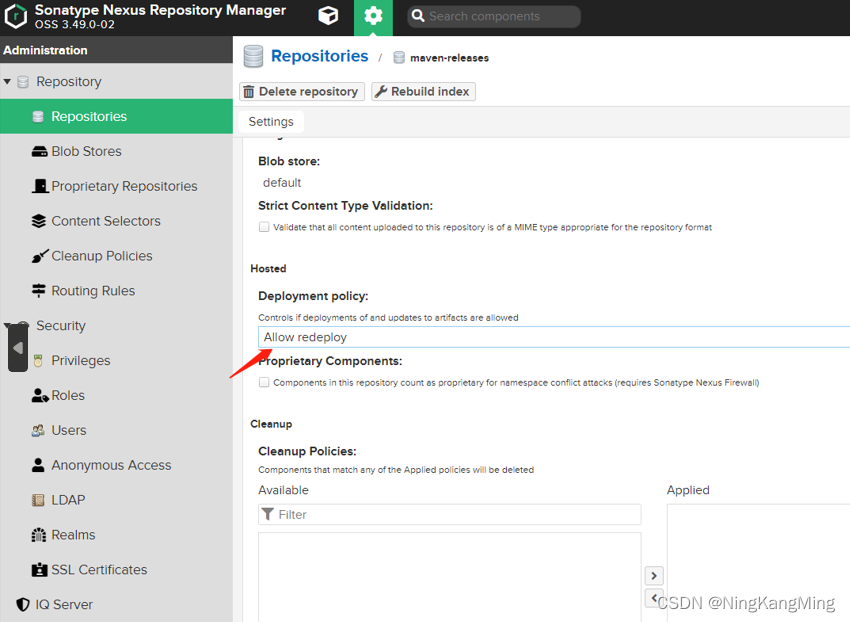
Maven Nexus3 私服搭建、配置、项目发布指南
maven nexus私服搭建 访问nexus3官方镜像库,选择需要的版本下载:Docker Nexus docker pull sonatype/nexus3:3.49.0 创建数据目录并赋权 sudo mkdir /nexus-data && sudo chown -R 200 /nexus-data 运行(数据目录选择硬盘大的卷进行挂载) …...
)
东方博宜1627 - 暑期的旅游计划(2)
问题描述 期末考试结束了,小华语文、数学、英语三门功课分别考了 x、y、z 分,小华的家长说,如果小华三门功课中有一门考到 90 分或者 90 分以上,那么就去北京旅游,如果都没考到,那么就去南京玩。 请从键盘…...
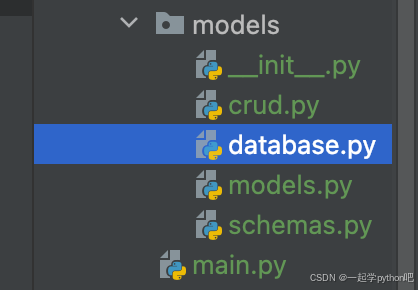
FastAPI 学习之路(三十五)项目结构优化
之前我们创建的文件都是在一个目录中,但是在我们的实际开发中,肯定不能这样设计,那么我们去创建一个目录,叫models,大致如下。 主要目录是: __init__.py 是一个空文件,说明models是一个package…...
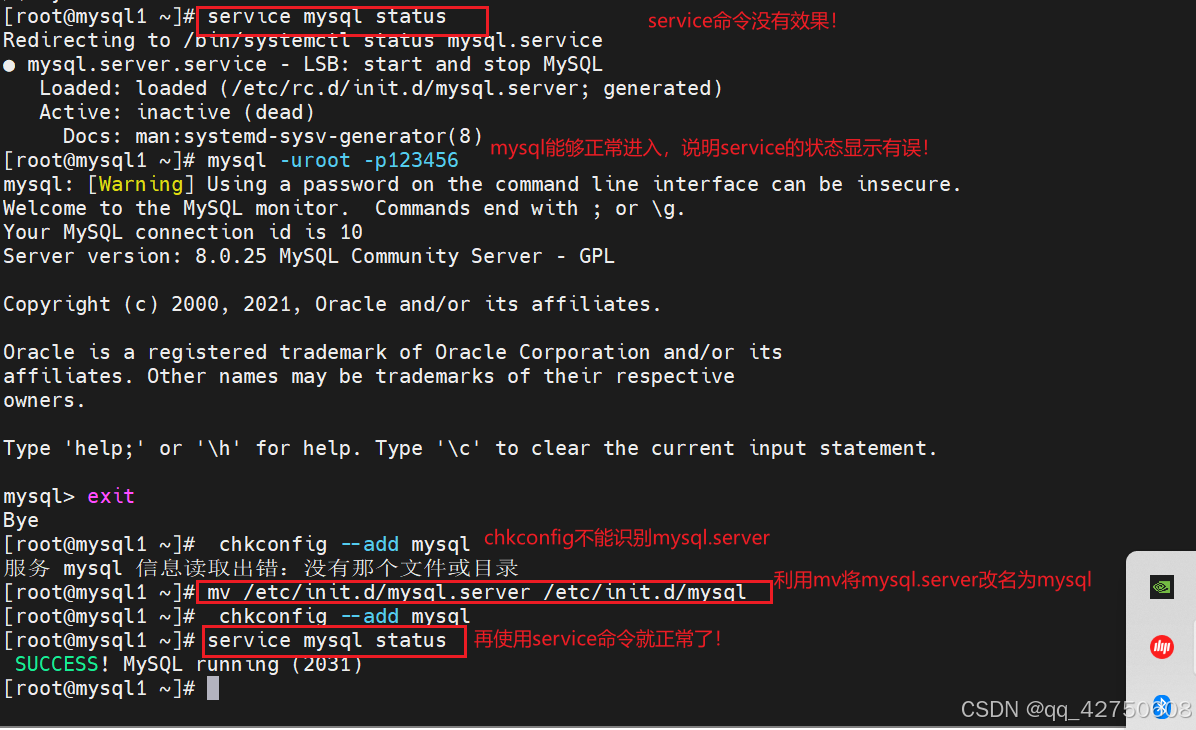
linux源码安装mysql8.0的小白教程
1.下载8.x版本的mysql MySQL :: Download MySQL Community Server (Archived Versions) 2.安装linux 我安装的是Rocky Linux8.6 3.设置ip地址,方便远程连接 使用nmcli或者nmtui设置或修改ip地址 4.使用远程连接工具MobaXterm操作: (1)将mysql8版本的压缩包上传到mybaxterm…...
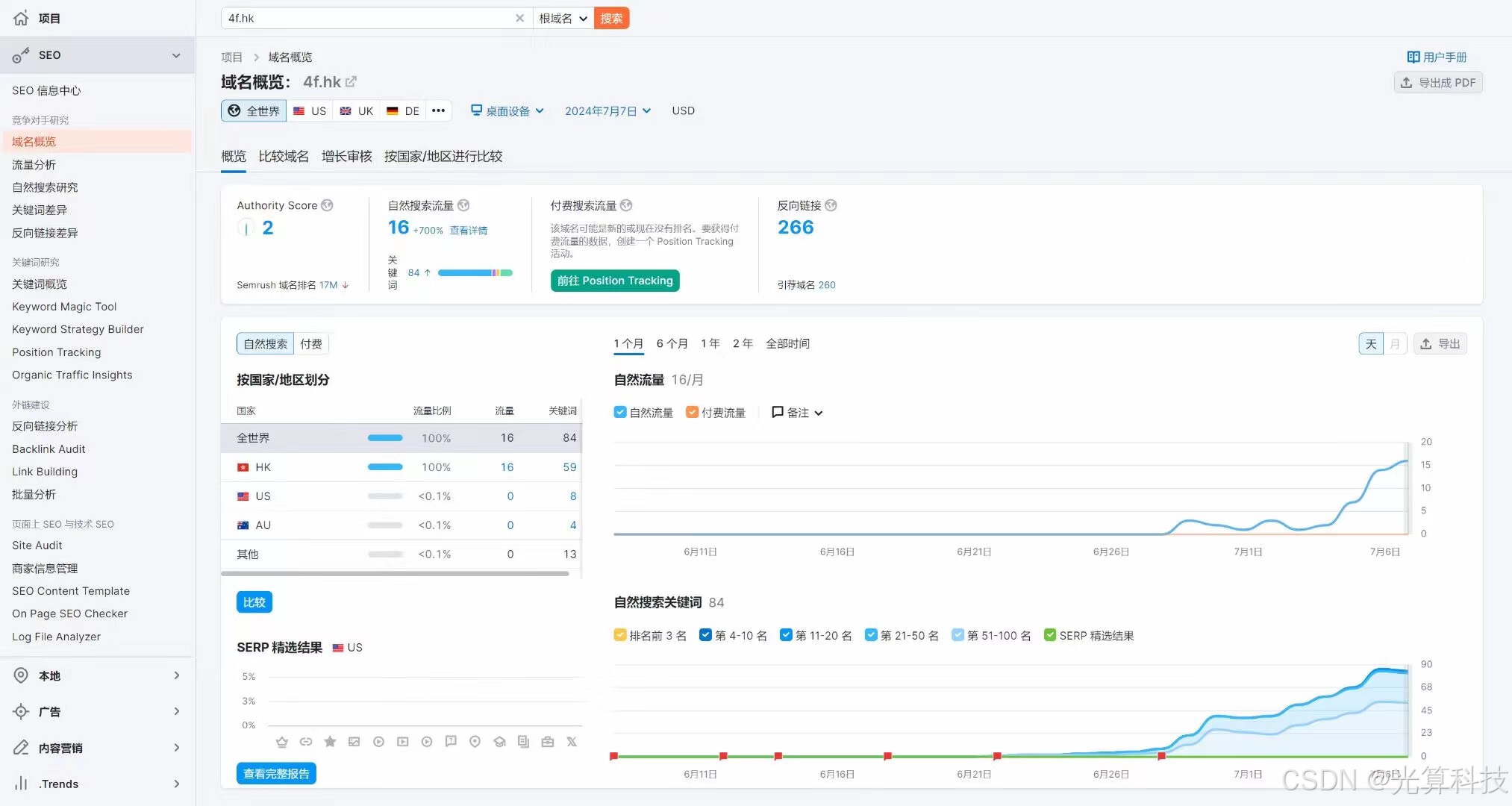
如何评估独立站的外链质量?
要评估独立站的外链质量时,首先要看的不是别的,而是内容,跟你网站相关的文章内容才是最重要的,其他的一切其实都不重要。什么网站的DA,评级,网站的主要内容跟你的文章内容是否相关其实都不重要,…...

AI在编程领域的作用
AI(人工智能)在软件开发和许多其他领域都发挥着重要作用,但这并不意味着它在取代开发者。相反,AI更多地是在帮助开发者提高工作效率,解决复杂问题,并创造新的可能性。 探讨AI工具对开发者日常工作的影响 …...
医疗器械网络安全 | 漏洞扫描、渗透测试没有发现问题,是否说明我的设备是安全的?
尽管漏洞扫描、模糊测试和渗透测试在评估系统安全性方面是非常重要和有效的工具,但即使这些测试没有发现任何问题,也不能完全保证您的医疗器械是绝对安全的。这是因为安全性的评估是一个多维度、复杂且持续的过程,涉及多个方面和因素。以下是…...

【GameFramework扩展应用】6-4、GameFramework框架增加AB包加解密功能
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址QQ群:398291828大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 【GameFramework框架】系列教程目录: https://blog.csdn.net/q764424567/article/details/1…...
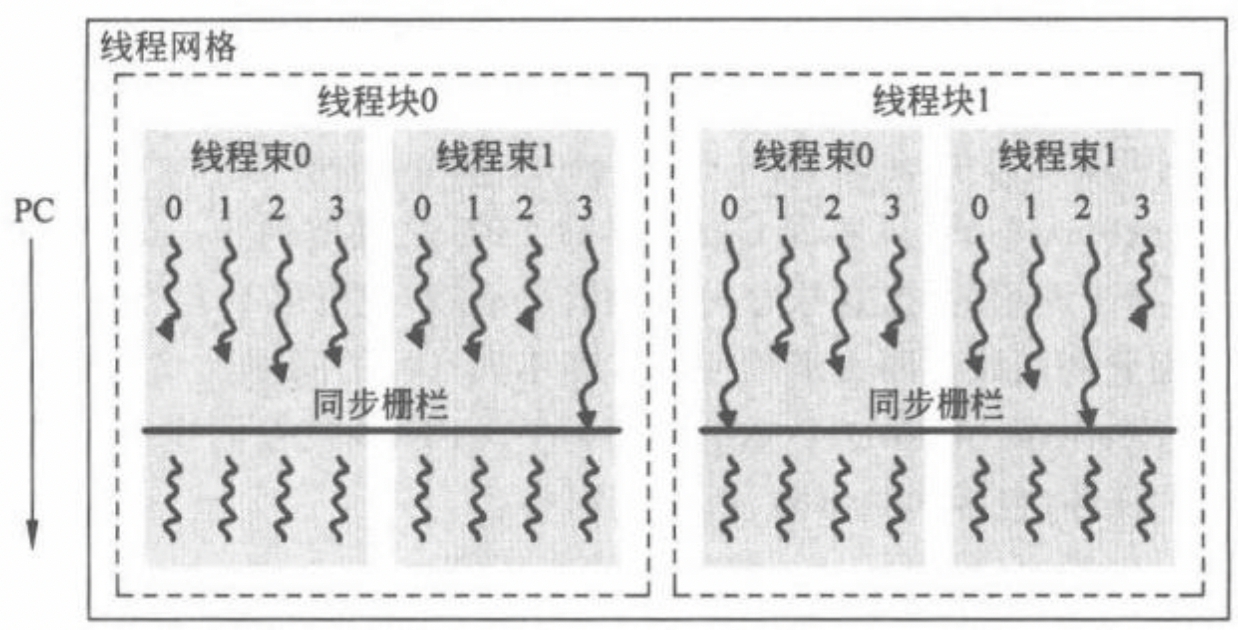
通用图形处理器设计GPGPU基础与架构(二)
一、前言 本系列旨在介绍通用图形处理器设计GPGPU的基础与架构,因此在介绍GPGPU具体架构之前,需要了解GPGPU的编程模型,了解软件层面是怎么做到并行的,硬件层面又要怎么配合软件,乃至定出合适的架构来实现软硬件协同。…...

在一个使用了 Sass 的 React Webpack 项目中安装和使用 Tailwind CSS
要在一个使用了 Sass 的 React Webpack 项目中安装和使用 Tailwind CSS,可以按照以下步骤操作: 1. 安装 Tailwind CSS 及其依赖 首先,确保你的项目根目录下有 package.json 文件,然后运行以下命令来安装 Tailwind CSS 及其所需的…...

HDMI简介
本篇主要介绍HDMI常见接口以及TMDS传输技术。 文章目录 一、HDMI简介二、TMDS传输技术1.编码(encoder)2.并转串(serializer)——OSERDESE2原语3.单端转差分——OBUFDS源语 三、常见的几种信号传输方式 一、HDMI简介 HDMI(High-Definition Multimedia I…...

原作者带队,LSTM卷土重来之Vision-LSTM出世
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。 AI 领域的研究者应该还记得,在 Transformer 诞生后的三年,谷歌将这一自然语言处理届的重要研究扩展到了视觉领域,也就是 Vision Transformer。后来…...

Fiddler 抓包工具抓https
Fiddler 抓包工具抓https...
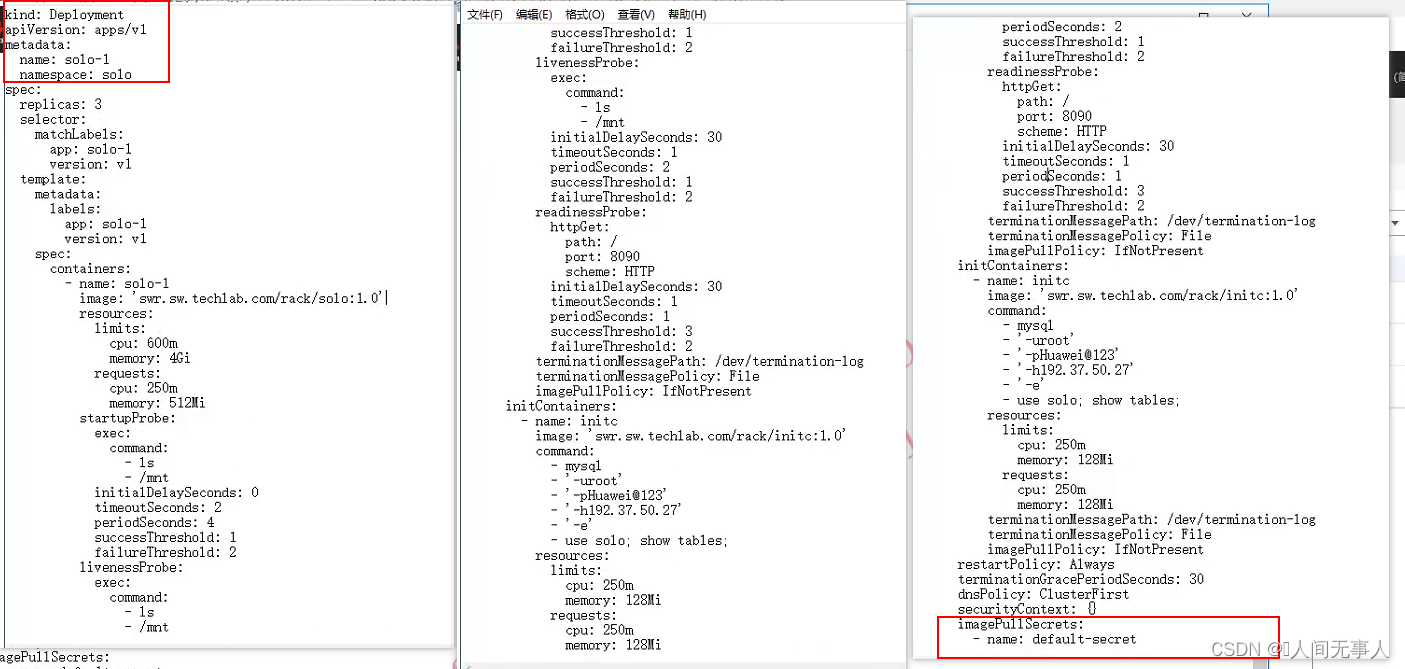
详细谈谈负载均衡的startupProbe探针、livenessProbe探针、readnessProbe探针如何使用以及使用差异化
文章目录 startupProbe探针startupProbe说明示例配置参数解释 使用场景说明实例——要求: 容器在8秒内完成启动,否则杀死对应容器工作流程说明timeoutSeconds: 和 periodSeconds: 参数顺序说明 livenessProbe探针livenessProbe说明示例配置参数解释 使用…...

守望数据边界:sklearn中的离群点检测技术
守望数据边界:sklearn中的离群点检测技术 在数据分析和机器学习项目中,离群点检测是一项关键任务。离群点,又称异常值或离群点,是指那些与其他数据显著不同的观测值。这些点可能由测量误差、数据录入错误或真实的变异性造成。正确…...

如何在ComfyUI中智能合成视频序列:VHS_VideoCombine节点的专业应用方案
如何在ComfyUI中智能合成视频序列:VHS_VideoCombine节点的专业应用方案 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 面对AI生成的大量图像序列&…...
)
FPGA实战:手把手教你用Verilog给NAND Flash数据上把“安全锁”(附完整ECC代码)
FPGA实战:用Verilog为NAND Flash打造硬件级ECC防护系统 1. 为什么你的NAND Flash需要硬件ECC? NAND Flash存储芯片在工业控制、物联网终端和边缘计算设备中扮演着关键角色,但它的物理特性导致数据可靠性存在先天缺陷。想象一下,当…...

RePKG:突破动态壁纸资源壁垒的开源工具
RePKG:突破动态壁纸资源壁垒的开源工具 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 当你面对一个包含丰富素材的动态壁纸资源包(PKG文件)却无…...

Java八股文面试题,堪称2026最强!!!
1、什么是 java 序列化,如何实现 java 序列化 难度系数:⭐ 序列化是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在…...
)
SENet实战:如何在PyTorch中实现Squeeze-and-Excitation模块(附完整代码)
PyTorch实战:手把手实现SENet中的SE模块 在计算机视觉领域,注意力机制已经成为提升模型性能的重要工具。今天我们将深入探讨如何在PyTorch中实现Squeeze-and-Excitation(SE)模块——这个让ResNet-50在ImageNet上表现接近ResNet-10…...

[Android] 鲁迅全集 7.2.0
[Android] 鲁迅全集 7.2.0 链接:https://pan.xunlei.com/s/VOp2ylhHGYlTTbQ2rTOhsk3RA1?pwdh6tu# 鲁迅作品全集!!!...

iarduino_KB矩阵键盘库:硬件感知型Arduino按键驱动方案
1. 项目概述iarduino_KB是由俄罗斯嵌入式开发团队 iArduino.ru 面向 Arduino IDE 推出的专用矩阵键盘驱动库。该库并非通用型扫描抽象层,而是针对其自研四款物理形态与电气特性高度定制化的柔性/机械式矩阵键盘模块进行深度适配的固件级解决方案。其核心价值在于将底…...

springboot+vue基于web的校园电动车短租系统的设计系统
目录同行可拿货,招校园代理 ,本人源头供货商系统功能分析用户管理模块车辆管理模块租赁业务模块安全与风控模块统计与报表模块技术实现要点项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商…...

郭老师-悟性高的人,为何不合群?
悟性高的人,为何不合群? ——他们在独处中,与道同行“你以为他孤独, 其实—— 他正与万物对话。”🌿 不合群,不是缺陷, 而是—— 为悟性留出呼吸的空间。🧘 一、独处 ≠ 孤独&#x…...
万象视界灵坛基础教程:PyTorch+Transformers环境搭建与CLIP零样本推理入门
万象视界灵坛基础教程:PyTorchTransformers环境搭建与CLIP零样本推理入门 1. 环境准备与快速部署 1.1 系统要求 Python 3.8或更高版本支持CUDA的NVIDIA GPU(推荐)至少8GB显存(CLIP-ViT-L/14模型需求)10GB以上可用磁…...