原作者带队,LSTM卷土重来之Vision-LSTM出世
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。
AI 领域的研究者应该还记得,在 Transformer 诞生后的三年,谷歌将这一自然语言处理届的重要研究扩展到了视觉领域,也就是 Vision Transformer。后来,ViT 被广泛用作计算机视觉中的通用骨干。
这种跨界,对于前不久发布的 xLSTM 来说同样可以实现。最近,享誉数十年的 LSTM 被扩展到一个可扩展且性能良好的架构 ——xLSTM,通过指数门控和可并行化的矩阵内存结构克服了长期存在的 LSTM 限制。现在,这一成果已经扩展到视觉领域。

xLSTM和 Vision-LSTM 两项研究均由 LSTM 原作者带队,也就是 LSTM 的提出者和奠基者 Sepp Hochreiter。
在最近的这篇论文中,Sepp Hochreiter 等人推出了 Vision-LSTM(ViL)。ViL 包含一堆 xLSTM 块,其中奇数块从上到下、偶数块则从下到上处理补丁 token 序列。

- 论文题目:Vision-LSTM: xLSTM as Generic Vision Backbone
- 论文链接:arxiv.org/abs/2406.04…
- 项目链接: nx-ai.github.io/vision-lstm…
正如 xLSTM 诞生之时,作者希望新架构能够撼动 Transformer 在语言模型领域的江山。这一次,闯入视觉领域的 Vision-LSTM 也被寄予厚望。
研究者在论文中表示:「我们的新架构优于基于 SSM 的视觉架构,也优于 ImageNet-1K 分类中的优化 ViT 模型。值得注意的是,在公平的比较中,ViL 的表现优于经过多年超参数调整和 Transformer 改进的 ViT 训练 pipeline。」
对于需要高分辨率图像以获得最佳性能的任务,如语义分割或医学成像, ViL 极具应用潜力。在这些情况下,Transformer 因自注意力的二次复杂性而导致计算成本较高,而 ViL 的线性复杂性不存在这种问题。研究者还表示,改进预训练方案(如通过自监督学习)、探索更好的超参数设置或从 Transformer 中迁移技术(如 LayerScale )都是 ViL 的可探索方向。
ViT 与 ViL
语言建模架构 —— 如 Transformer 或最近的状态空间模型 Mamba,通常被应用到计算机视觉领域,以利用它们强大的建模能力。
然而,在自然语言处理中,通过离散词汇表(Discrete vocabulary),输入的句子通常被编码成代表词或常见子词的 token。
为了将图像编码成一组 token,Vision Transformer(ViT)提出将输入图像分组成非重叠的补丁(例如 16x16 像素),将它们线性投影成所谓的补丁 token 序列,并向这些 token 添加位置信息。
然后,这个序列就可以被语言建模架构处理了。
扩展长短期记忆(xLSTM)最近被引入作为一种新的语言建模架构,可以说是 LSTM 在 LLM 时代的复兴,与 Transformer 和状态空间模型(SSMs)等相媲美。
现有的 Transformer 或状态空间模型的视觉版本,例如 ViT 或 Vision Mamba,已经在各种计算机视觉任务中取得了巨大成果。
使用 xLSTM 作为核心组建的 ViL 使用简单的交替设计,从而可以有效地处理非序列输入(如图像),而无需引入额外的计算。
类似于 SSMs 的视觉适应,ViL 展示了关于序列长度的线性计算和内存复杂度,这使得它在高分辨率图像的任务中展现极佳的作用,如医学成像、分割或物理模拟。
相比之下,ViT 的计算复杂度由于自注意力机制而呈二次方增长,使得它们在应用于高分辨率任务时成本高昂。
交替 mLSTM 块并行
Vision-LSTM(ViL)是一个用于计算机视觉任务的通用骨干,它从 xLSTM 块残差构建,如图 1 所示。

与 ViT 类似,ViL 首先通过共享线性投影将图像分割成非重叠的补丁,然后向每个补丁 token 添加可学习的定位嵌入。ViL 的核心是交替的 mLSTM 块,它们是可完全并行化的,并配备了矩阵内存和协方差更新规则。
奇数 mLSTM 块从左上到右下处理补丁 token,而偶数块则从右下到左上。
ImageNet-1K 实验
研究团队在 ImageNet-1K 上进行了实验:它包含 130 万张训练图像和 5 万张验证图像,每张图像属于 1000 个类别之一。
对比实验集中在使用序列建模骨干的模型上,而该模型在大致相当的参数数量上是可比较的。
他们在 224x224 分辨率上训练 ViL 模型,使用余弦衰减调度,1e-3 的学习率训练了 800 个周期(tiny, tiny+)或 400 个周期(small, small+, base),具体见下方表 5.

为了对 Vision Mamba(Vim)进行公平比较,研究人员向模型内添加了额外的块以匹配 tiny 和小型变体(分别表示为 ViL-T + 和 ViL-S+)的参数数量。
需要注意的是,由于 ViL 以交替的方式遍历序列,而 Vim 则在每个块中遍历序列两次,因此 ViL 所需的计算量远少于 Vim。
尽管 Vim 使用了优化的 CUDA 内核(而 mLSTM 目前还没有这样的内核),但这仍然成立,并且会进一步加速 ViL 的速度。
如表 4 所示的运行时间对比,在其中两项的比较重,ViL 比 Vim 快了 69%。

新秀 ViL 相比于 ViTs 如何?
虽然 ViL 首次出场,但仍是展现了极佳的潜力。
由于 ViTs 在视觉社区中已经得到了广泛的认可,它们在过去几年经历了多次优化周期。
因为这项工作是首次将 xLSTM 应用于计算机视觉,研究人员并不期望在所有情况下都超过 ViTs 多年的超参数调整。
即便如此,表 1 中的结果显示,ViL 在小规模上相比于经过大量优化的 ViT 协议(DeiT, DeiT-II, DeiT-III)仍是显示出较良好的结果,其中只有训练时间是 ViL-S 两倍的 DeiT-III-S 表现略好一点。
在「base」规模上,ViL 超越了最初的 ViT 模型,并取得了与 DeiT 相当的结果。
需要注意的是:由于在这个规模上训练模型的成本很高,ViL-B 的超参数远非最佳。作为参考,训练 ViL-B 大约需要 600 个 A100 GPU 小时或在 32 个 A100 GPU 上的 19 个小时。

通过在「长序列微调」设置中微调模型,性能可以进一步提高,该设置通过使用连续补丁 token 之间 50% 的重叠,将序列长度增加到 729,对模型进行 30 个周期的微调。
尽管没有利用卷积固有的归纳偏置,ViL 还是展现出了与基于 CNN 的模型(如 ConvNeXt)相当的性能。
块设计
该团队研究了设计 ViL 块的不同方式,如图 2 所示。
- 普通且单向的 xLSTM 块未能达到期待的性能,因为 xLSTM 的自回归性质并不适合图像分类。
- 以双向方式遍历块 —— 即在每个块中引入第二个 mLSTM 层,该层向后遍历序列(类似于 Vim),提高了性能,但也需要更多的参数和 FLOPS。
- 共享前向和后向 mLSTM 的参数使模型在参数上更高效,但仍然需要更多的计算并超载这些参数,而这最终也会导致性能下降。
- 使用交替块在保持计算和参数效率的同时提高了性能。
该团队还探索了四向设计,这指的是按行(两个方向)和按列(两个方向)遍历序列。双向仅按行遍历序列(两个方向)。
图 2 可视化了不同的遍历路径。

由于双向和四向块的成本增加,这项研究是在设置大幅减少的条件中进行的。
研究人员在 128x128 分辨率下,对包含仅来自 100 个类别的样本的 ImageNet-1K 的一个子集进行 400 个周期的训练。这是特别必要的,因为四向实现方法与 torch.compile(来自 PyTorch 的一个通用速度优化方法)不兼容,这会导致更长的运行时间,如表 2 最后一列所示。
由于此技术限制,该团队最终了选择交替双向块作为核心设计。

分类设计
为了使用 ViT 进行分类,需要将 token 序列汇集成一个 token,然后将其作为分类头的输入。
最常见的汇集方法是:(i) 在序列的开头添加一个可学习的 [CLS] token,或 (ii) 平均所有补丁 token,生成一个 [AVG] token。使用 [CLS] 还是 [AVG] token 通常是一个超参数,两种变体的性能相当。相反,自回归模型通常需要专门的分类设计。例如,Vim 要求 [CLS] token 位于序列的中间,如果采用其他分类设计,如 [AVG] token 或在序列的开始和结束处使用两个 [CLS] token,则会造成严重的性能损失。
基于 ViL 的自回归特性,研究者在表 3 中探讨了不同的分类设计。

[AVG] 是所有补丁 token 的平均值,「Middle Patch 」使用中间的补丁 token,「Middle [CLS]」使用序列中间的一个 [CLS] token,「Bilateral [AVG]」使用第一个和最后一个补丁 token 的平均值。
可以发现的是, ViL 分类设计相对稳健,所有性能都在 0.6% 以内。之所以选择 「Bilateral [AVG]」而不是 「Middle [CLS]」,因为 ImageNet-1K 有中心偏差,即物体通常位于图片的中间。通过使用 「Bilateral [AVG]」,研究者尽量避免了利用这种偏差,从而使模型更具通用性。
为了与之前使用单个 token 作为分类头输入的架构保持可比性,研究者对第一个和最后一个 token 进行了平均处理。为了达到最佳性能,建议将两个标记合并(「Bilateral Concat」),而不是取平均值。
这类似于 DINOv2 等自监督 ViT 的常见做法,这些是通过分别附加在 [CLS] 和 [AVG] token 的两个目标来进行训练的,因此可以从连接 [CLS] 和 [AVG] token 的表征中获益。视觉 SSM 模型也探索了这一方向,即在序列中分散多个 [CLS] token,然后将其作为分类器的输入。此外,类似的方向也可以提高 ViL 的性能。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
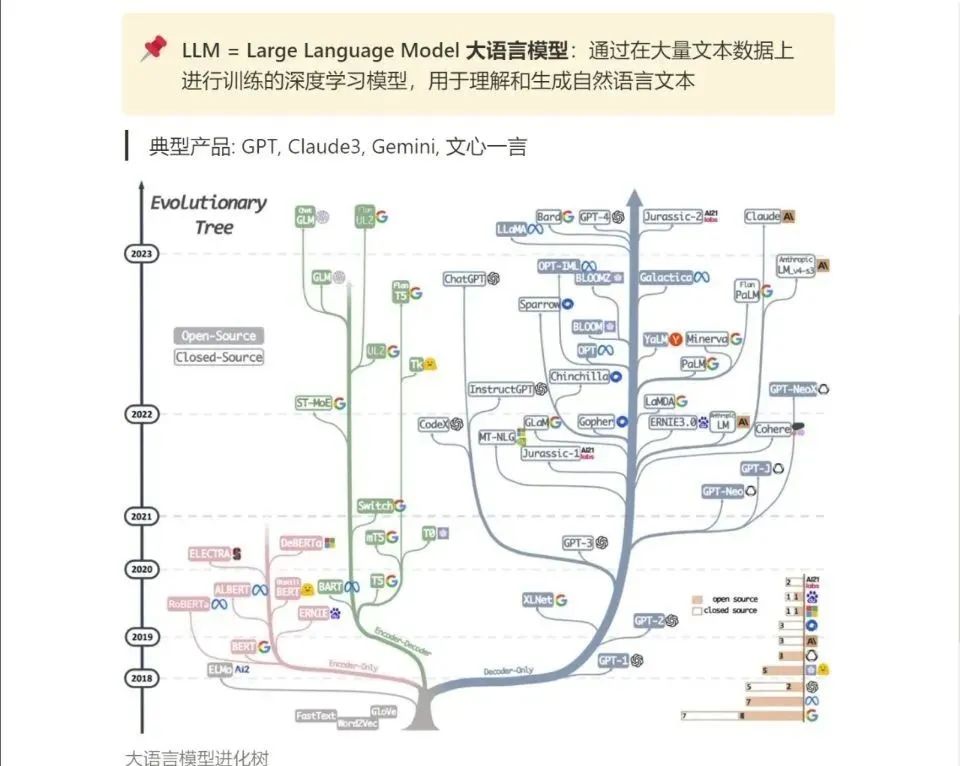
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!
相关文章:
原作者带队,LSTM卷土重来之Vision-LSTM出世
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。 AI 领域的研究者应该还记得,在 Transformer 诞生后的三年,谷歌将这一自然语言处理届的重要研究扩展到了视觉领域,也就是 Vision Transformer。后来…...

Fiddler 抓包工具抓https
Fiddler 抓包工具抓https...
详细谈谈负载均衡的startupProbe探针、livenessProbe探针、readnessProbe探针如何使用以及使用差异化
文章目录 startupProbe探针startupProbe说明示例配置参数解释 使用场景说明实例——要求: 容器在8秒内完成启动,否则杀死对应容器工作流程说明timeoutSeconds: 和 periodSeconds: 参数顺序说明 livenessProbe探针livenessProbe说明示例配置参数解释 使用…...

守望数据边界:sklearn中的离群点检测技术
守望数据边界:sklearn中的离群点检测技术 在数据分析和机器学习项目中,离群点检测是一项关键任务。离群点,又称异常值或离群点,是指那些与其他数据显著不同的观测值。这些点可能由测量误差、数据录入错误或真实的变异性造成。正确…...

python工作中遇到的坑
1. 字典拷贝 有些场景下,需要对字典拷贝一个副本。这个副本用于保存原始数据,然后原来的字典去参与其他运算,或者作为参数传递给一些函数。 例如, >>> dict_a {"name": "John", "address&q…...

中职网络安全wire0077数据包分析
从靶机服务器的FTP上下载wire0077.pcap,分析该文件,找出黑客入侵使用的协议,提交协议名称 SMTP 分析该文件,找出黑客入侵获取的zip压缩包,提交压缩包文件名 DESKTOP-M1JC4XX_2020_09_24_22_43_12.zip 分析该文件&…...

引领未来:在【PyCharm】中利用【机器学习】与【支持向量机】实现高效【图像识别】
目录 一、数据准备 1. 获取数据集 2. 数据可视化 3. 数据清洗 二、特征提取 1. 数据标准化 2. 图像增强 三、模型训练 1. 划分训练集和测试集 2. 训练 SVM 模型 3. 参数调优 四、模型评估 1. 评估模型性能 2. 可视化结果 五、预测新图像 1. 加载和预处理新图像…...
240707-Sphinx配置Pydata-Sphinx-Theme
Step A. 最终效果 Step B. 为什么选择Pydata-Sphinx-Theme主题 Gallery of sites using this theme — PyData Theme 0.15.4 documentation Step 1. 创建并激活Conda环境 conda create -n rtd_pydata python3.10 conda activate rtd_pydataStep 2. 安装默认的工具包 pip in…...

华为如何做成数字化转型?
目录 企业数字化转型是什么? 华为如何定义数字化转型? 为什么做数字化转型? 怎么做数字化转型? 华为IPD的最佳实践之“金蝶云” 企业数字化转型是什么? 先看一下案例,华为经历了多次战略转型…...

Python | Leetcode Python题解之第229题多数元素II
题目: 题解: class Solution:def majorityElement(self, nums: List[int]) -> List[int]:cnt {}ans []for v in nums:if v in cnt:cnt[v] 1else:cnt[v] 1for item in cnt.keys():if cnt[item] > len(nums)//3:ans.append(item)return ans...
)
TCP/IP模型和OSI模型的区别(面试题)
OSI模型,是国际标准化组织ISO制定的用于计算机或通讯系统间互联的标准化体系,主要分为7个层级: 物理层数据链路层网络层传输层会话层表示层应用层 虽然OSI模型在理论上更全面,但是在实际网络通讯中,TCP/IP模型更加实…...

UML建模工具Draw.io简介
新书速览|《UML 2.5基础、建模与设计实践 Draw.io是一个非常出色的免费、开源、简洁、方便的绘图软件,利用这款软件可以绘制出生动有趣的图形,包括流程图、地图、网络架构图、UML用例图、流程图等。它支持各种快捷键,免费提供了1000多张画图…...

qt udp 协议 详解
1.qt udp 协议链接举例 在Qt框架中,使用UDP协议进行通信主要依赖于QUdpSocket类。以下是一个基于Qt的UDP通信示例,包括UDP套接字的创建、绑定端口、发送和接收数据报的步骤。 1. 创建UDP套接字 首先,需要创建一个QUdpSocket对象。这通常在…...

ubuntu 换源
sudo apt update 错误如下 Ign:1 http://security.ubuntu.com/ubuntu focal-security InRelease Ign:2 http://us.archive.ubuntu.com/ubuntu focal InRelease Err:3 http://security.ubuntu.com/ubuntu focal-security Release SECURITY: URL redirect target…...

基于ssm的图书管理系统的设计与实现
摘 要 在当今信息技术日新月异的时代背景下,图书管理领域正经历着深刻的变革,传统的管理模式已难以适应现代社会的快节奏和高要求,逐渐向数字化、智能化的方向演进。本论文聚焦于这一转变趋势,致力于设计并成功实现一个基于 SSM&…...
)
python压缩PDF方案(Ghostscript+pdfc)
第一步:安装Ghostscript Ghostscript是一套建基于Adobe、PostScript及可移植文档格式(PDF)的页面描述语言等而编译成的免费软件。它可以作为文件格式转换器,如PostScript和PDF转换器,也为编程提供API。[1]PDF压缩本质…...

kotlin 基础
文章目录 1、安装 Java 和 Kotlin 环境2、程序代码基本结构3、变量的声明与使用4、数据类型5、数字类型的运算1)布尔类型2)字符类型3)字符串类型 6、 选择结构1)(if - else)2) 选择结构(when&am…...

Spring中的适配器模式和策略模式
1. 适配器模式的应用 1.1适配器模式(Adapter Pattern)的原始定义是:将一个类的接口转换为客户期望的另一个接口,适配器可以让不兼容的两个类一起协同工作。 1.2 AOP中的适配器模式 在Spring的AOP中,使用Advice&#…...

书生浦语大模型实战营---Python task
任务一 请实现一个wordcount函数,统计英文字符串中每个单词出现的次数,通过构建defaultdict字典,可以避免插入值时需要判断值是否存在 from collections import defaultdictdef word_count(text):#构建缓存reval defaultdict(int)words t…...

Chrome 127内置AI大模型攻略
Chrome 127 集成Gemini:本地AI功能 Google将Gemini大模型整合进Chrome浏览器,带来全新免费的本地AI体验: 完全免费、无限制使用支持离线运行,摆脱网络依赖功能涵盖图像识别、自然语言处理、智能推荐等中国大陆需要借助魔法,懂都懂。 安装部署步骤: 1. Chrome V127 dev …...

Awesome-Awesome终极指南:如何快速找到任何技术领域的最佳资源
Awesome-Awesome终极指南:如何快速找到任何技术领域的最佳资源 【免费下载链接】awesome-awesome A curated list of awesome curated lists of many topics. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-awesome 在技术学习和开发过程中ÿ…...

Phi-4-mini-reasoning推理模型Python入门实战:3步完成环境部署与基础调用
Phi-4-mini-reasoning推理模型Python入门实战:3步完成环境部署与基础调用 1. 开篇:为什么选择Phi-4-mini-reasoning 如果你刚接触大模型推理,可能会被各种复杂的部署流程吓到。Phi-4-mini-reasoning作为一款轻量级开源推理模型,…...

医疗AI智能体:从数据到关怀人文设计:告别冰冷精准,构建有温度的诊疗交互.131
一、智能体的人文设计医疗AI智能体以大模型为核心,串联医学知识图谱、实体识别模块、风险评估模块、话术生成模块、伦理审核模块五大核心组件,最终实现精准医学判断 人性化交互的双重目标。而在医疗场景中,用户的核心需求从来不是单纯的数据…...

LSLib:从游戏资源新手到MOD制作专家的完整路径
LSLib:从游戏资源新手到MOD制作专家的完整路径 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 你是否曾经想过修改《神界原罪》系列或《博德之门3》的游…...

如何用Reset Windows Update Tool一键解决Windows更新故障的终极指南
如何用Reset Windows Update Tool一键解决Windows更新故障的终极指南 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool 你是否曾…...

XHS-Downloader:解决小红书内容高效采集难题的开源解决方案
XHS-Downloader:解决小红书内容高效采集难题的开源解决方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...
)
别再只改默认密码了!Nacos 1.x/2.x 生产环境安全加固保姆级清单(附漏洞自查脚本)
Nacos生产环境安全加固全指南:从基础配置到漏洞防御 在微服务架构盛行的今天,Nacos作为服务发现和配置管理的核心组件,其安全性直接影响整个系统的稳定性。许多团队在部署Nacos时往往只满足于修改默认密码,却忽视了完整的安全防护…...

trae中安装mcp报Cannot find package/ERR_MODULE_NOT_FOUND问题
简介 我在trae中安装高德地图的mcp和其他的mcp报出了以下错误,以此记录并分享给大家。 新的改变 node:internal/modules/esm/resolve:204 const resolvedOption FSLegacyMainResolve(pkgPath, packageConfig.main, baseStringified); ^ Error: Cannot find pack…...

SmallThinker-3B-Preview赋能Java后端:智能客服系统数据库设计
SmallThinker-3B-Preview赋能Java后端:智能客服系统数据库设计 最近在做一个Java后端的智能客服项目,核心是要接入一个轻量级的AI模型——SmallThinker-3B-Preview。模型选好了,代码逻辑也搭得差不多了,但一到数据库设计这块&…...

Unity渲染流水线中的NDC空间:从齐次裁剪到屏幕坐标的完整转换指南
Unity渲染流水线中的NDC空间:从齐次裁剪到屏幕坐标的完整转换指南 在Unity引擎的渲染流水线中,理解NDC(归一化设备坐标)空间的作用至关重要。这个看似抽象的概念,实际上决定了3D场景如何最终呈现在2D屏幕上。对于想要深…...