引领未来:在【PyCharm】中利用【机器学习】与【支持向量机】实现高效【图像识别】
目录
一、数据准备
1. 获取数据集
2. 数据可视化
3. 数据清洗
二、特征提取
1. 数据标准化
2. 图像增强
三、模型训练
1. 划分训练集和测试集
2. 训练 SVM 模型
3. 参数调优
四、模型评估
1. 评估模型性能
2. 可视化结果
五、预测新图像
1. 加载和预处理新图像
编辑
完整代码
总结


专栏:机器学习笔记
总篇:学习路线
第一卷:线性回归模型
第二卷:逻辑回归模型
第三卷:决策树
一、数据准备
数据准备是机器学习项目的基础步骤。数据的质量直接影响模型的性能和最终结果。在图像识别任务中,数据通常是大量的图像文件,我们需要将这些图像转化为适合模型处理的格式。我们将使用 MNIST 数据集,这是一个包含手写数字图像的标准数据集。
1. 获取数据集
MNIST 数据集包含 70,000 个 28x28 像素的灰度图像,每个图像表示一个 0-9 的数字。这个数据集非常适合初学者进行机器学习和图像识别的练习。
首先,我们需要从公开数据源下载 MNIST 数据集。我们可以使用 fetch_openml 函数从 OpenML 平台下载该数据集:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml# 下载 MNIST 数据集
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]# 将标签转换为整数
y = y.astype(int)# 将 X 转换为 NumPy 数组
X = X.values
上述代码使用 fetch_openml 函数从 OpenML 平台下载 MNIST 数据集。数据存储在 X 和 y 中,X 包含图像数据,y 包含对应的标签。X 是一个包含 70,000 个样本的数组,每个样本是一个 784 维(28x28)的向量。y 是对应的标签,表示图像中的数字。
小李的理解:数据准备是整个过程的基础。就像建房子一样,地基要打好。如果数据质量不好,后续的模型训练和评估都可能会出问题。MNIST 数据集很好用,因为它已经预处理好了,但在实际应用中,可能需要更多的数据清洗和预处理工作。
2. 数据可视化
为了更好地理解数据,我们可以可视化一些样本图像。这有助于直观地了解数据的分布和特征。
def plot_digit(data):image = data.reshape(28, 28)plt.imshow(image, cmap=plt.cm.binary, interpolation='nearest')plt.axis("off")# 显示前十个图像
plt.figure(figsize=(12, 8))
for i in range(10):plt.subplot(2, 5, i + 1)plot_digit(X[i])
plt.show()
通过这些代码,我们将展平的向量重新转换为 28x28 的图像,并使用 Matplotlib 绘制出来。这样可以直观地看到手写数字的样本图像。

小李的理解:数据可视化有助于我们直观地了解数据。如果我们能看到图像,就更容易理解模型为什么会做出某些预测。
3. 数据清洗
虽然 MNIST 数据集已经经过了预处理,但在实际应用中,数据可能需要进行进一步清洗。数据清洗的目的是去除或修正数据中的错误和异常值。常见的数据清洗方法包括去除重复数据、填补缺失值和纠正数据格式等。在图像数据中,清洗过程可能包括去除模糊或损坏的图像。
二、特征提取
在机器学习中,特征提取是将原始数据转换为模型能够处理的特征向量的过程。对于 MNIST 数据集,每个图像已经是 784 维的向量,因此我们不需要额外的特征提取步骤。
1. 数据标准化
标准化是将数据的特征缩放到相同的尺度上,这有助于加快训练速度并提高模型的性能。在这里,我们使用 StandardScaler 对数据进行标准化处理。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
StandardScaler 会将每个特征调整为均值为 0,标准差为 1 的分布,这样可以避免某些特征由于数值范围较大而对模型产生过大的影响。
小李的理解:标准化有助于确保模型不会被某些特征的数量级所主导。它让所有特征在同一个尺度上,更加公平地影响模型。
2. 图像增强
虽然在这次任务中我们不需要进行复杂的图像处理,但在实际应用中,图像增强是常见的步骤。图像增强技术可以通过旋转、缩放、裁剪、颜色变换等方式增加数据集的多样性,从而提升模型的泛化能力。例如,我们可以使用 OpenCV 或其他图像处理库进行数据增强。
import cv2def augment_image(image):# 随机旋转图像angle = np.random.randint(-15, 15)M = cv2.getRotationMatrix2D((14, 14), angle, 1)rotated = cv2.warpAffine(image, M, (28, 28))# 随机缩放图像scale = np.random.uniform(0.9, 1.1)scaled = cv2.resize(rotated, None, fx=scale, fy=scale)return scaled# 应用图像增强
augmented_images = np.array([augment_image(img.reshape(28, 28)).flatten() for img in X])
小李的理解:图像增强技术可以增加数据的多样性,有助于提高模型的泛化能力。在实际项目中,合理地使用图像增强技术是非常有必要的。
三、模型训练
模型训练是机器学习过程中的关键步骤。在这个过程中,我们将使用支持向量机(SVM)来训练模型。SVM 是一种强大的分类算法,特别适用于高维数据。
1. 划分训练集和测试集
首先,我们需要将数据集划分为训练集和测试集。训练集用于训练模型,测试集用于评估模型性能。
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
上述代码将数据集划分为训练集(80%)和测试集(20%)。random_state 参数用于确保结果的可重复性。
小李的理解:将数据划分为训练集和测试集是为了能够评估模型的泛化能力。如果不划分数据,模型可能会过拟合,无法在新数据上表现良好。
2. 训练 SVM 模型
接下来,我们使用线性核的 SVM 进行模型训练。线性核适用于数据线性可分的情况。
from sklearn.svm import SVC# 创建 SVM 分类器
svm_clf = SVC(kernel='linear', C=1)# 训练模型
svm_clf.fit(X_train, y_train)
在这段代码中,我们创建了一个线性核的 SVM 分类器,并使用训练集的数据训练模型。C 参数是正则化参数,控制模型的复杂度。较小的 C 值会使模型更简单,但可能欠拟合;较大的 C 值会使模型更复杂,但可能过拟合。
小李的理解:SVM 的目标是找到一个最佳的决策边界,将不同类别的样本分开。C 参数可以调节模型的复杂度,适当的 C 值可以避免过拟合或欠拟合。
3. 参数调优
在训练模型时,选择合适的参数是非常重要的。除了 C 参数外,SVM 的核函数也可以选择不同的类型,如多项式核、RBF 核等。我们可以使用网格搜索(Grid Search)来自动化选择最佳参数组合。
from sklearn.model_selection import GridSearchCVparam_grid = [{'C': [0.1, 1, 10, 100], 'kernel': ['linear']},{'C': [0.1, 1, 10, 100], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]grid_search = GridSearchCV(SVC(), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)print("Best parameters:", grid_search.best_params_)
小李的理解:参数调优是提高模型性能的重要步骤。通过网格搜索,我们可以系统地测试不同的参数组合,找到最佳的模型配置。
四、模型评估
在模型训练完成后,我们需要评估其性能。常用的评估指标包括准确率、精确率、召回率和 F1 值。此外,我们还可以使用混淆矩阵来进一步分析模型的表现。
1. 评估模型性能
我们使用测试集数据进行预测,并计算模型的评估指标。
from sklearn.metrics import accuracy_score, classification_report, confusion_matrixy_pred = grid_search.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")# 打印分类报告
print("Classification Report:\n", classification_report(y_test, y_pred))# 打印混淆矩阵
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
上述代码首先使用测试集的数据进行预测,然后计算并打印了模型的准确率、分类报告和混淆矩阵。准确率是正确分类的样本数与总样本数的比值。分类报告包含了每个类别的精确率、召回率和 F1 值。混淆矩阵显示了分类器在每个类别上的表现情况。
小李的理解:评估模型就像考试后的成绩单,不仅要看总分(准确率),还要看单科成绩(精确率、召回率等)。混淆矩阵对分析模型的分类能力特别有用,能看出哪些类别容易混淆。
2. 可视化结果
为了更直观地理解模型的性能,我们可以可视化一些预测结果。
def plot_digits(images, labels, predictions, start_idx, num):plt.figure(figsize=(12, 8))for i in range(num):plt.subplot(2, num//2, i + 1)plot_digit(images[start_idx + i])plt.title(f"True: {labels[start_idx + i]}\nPred: {predictions[start_idx + i]}")plt.show()# 显示前十个预测结果
plot_digits(X_test, y_test, y_pred, 0, 10)
这段代码定义了一个函数 plot_digits,用于绘制图像并显示真实标签和预测标签。我们使用它来可视化前十个预测结果。
小李的理解:可视化结果能直观地看到模型的预测效果,特别是可以发现哪些图像被错误分类,并分析其原因。
五、预测新图像
最后,我们来看一下如何使用训练好的模型来预测新图像的类别。
1. 加载和预处理新图像
假设我们有一张新的手写数字图像,存储在文件 new_digit.png 中。我们需要加载这张图像,并将其转换为模型可以处理的格式。
import cv2# 加载图像
img = cv2.imread('new_digit.png', cv2.IMREAD_GRAYSCALE)# 调整图像大小为 28x28
img_resized = cv2.resize(img, (28, 28))# 展平图像为 784 维向量
img_flattened = img_resized.flatten()# 归一化图像
img_normalized = img_flattened / 255.0# 标准化图像
img_standardized = scaler.transform([img_normalized])# 预测图像类别
prediction = grid_search.predict(img_standardized)
print(f"Predicted class: {prediction[0]}")
在这段代码中,我们使用 OpenCV 加载灰度图像,并将其调整为 28x28 的大小。然后展平图像为 784 维的向量,并归一化处理。接着,我们使用之前的标准化器对图像进行标准化处理。最后,我们使用训练好的 SVM 模型预测图像的类别。
小李的理解:预测新图像时,需要将图像转换为与训练数据相同的格式。这包括调整图像大小、展平成向量、归一化和标准化。这样,模型就可以理解并进行预测了。
完整代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import cv2# 一、数据准备# 1. 获取数据集
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.int)# 2. 数据可视化
def plot_digit(data):image = data.reshape(28, 28)plt.imshow(image, cmap=plt.cm.binary, interpolation='nearest')plt.axis("off")plt.figure(figsize=(12, 8))
for i in range(10):plt.subplot(2, 5, i + 1)plot_digit(X[i])
plt.show()# 二、特征提取# 1. 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 三、模型训练# 1. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 2. 训练 SVM 模型
param_grid = [{'C': [0.1, 1, 10, 100], 'kernel': ['linear']},{'C': [0.1, 1, 10, 100], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
grid_search = GridSearchCV(SVC(), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
print("Best parameters:", grid_search.best_params_)# 四、模型评估# 1. 评估模型性能
y_pred = grid_search.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:\n", classification_report(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))# 2. 可视化结果
def plot_digits(images, labels, predictions, start_idx, num):plt.figure(figsize=(12, 8))for i in range(num):plt.subplot(2, num//2, i + 1)plot_digit(images[start_idx + i])plt.title(f"True: {labels[start_idx + i]}\nPred: {predictions[start_idx + i]}")plt.show()plot_digits(X_test, y_test, y_pred, 0, 10)# 五、预测新图像# 1. 加载和预处理新图像
img = cv2.imread('new_digit.png', cv2.IMREAD_GRAYSCALE)
img_resized = cv2.resize(img, (28, 28))
img_flattened = img_resized.flatten()
img_normalized = img_flattened / 255.0
img_standardized = scaler.transform([img_normalized])
prediction = grid_search.predict(img_standardized)
print(f"Predicted class: {prediction[0]}")
- 数据准备:数据准备是整个过程的基础。如果数据质量不好,后续的模型训练和评估都可能会出问题。MNIST 数据集很好用,因为它已经预处理好了。
- 特征提取:标准化有助于确保模型不会被某些特征的数量级所主导。它让所有特征在同一个尺度上,更加公平地影响模型。
- 模型训练:SVM 的目标是找到一个最佳的决策边界,将不同类别的样本分开。C 参数可以调节模型的复杂度,适当的 C 值可以避免过拟合或欠拟合。参数调优是提高模型性能的重要步骤。
- 模型评估:评估模型就像考试后的成绩单,不仅要看总分(准确率),还要看单科成绩(精确率、召回率等)。混淆矩阵对分析模型的分类能力特别有用,能看出哪些类别容易混淆。可视化结果能直观地看到模型的预测效果,特别是可以发现哪些图像被错误分类,并分析其原因。
- 预测新图像:预测新图像时,需要将图像转换为与训练数据相同的格式。这包括调整图像大小、展平成向量、归一化和标准化。这样,模型就可以理解并进行预测了。
总结
支持向量机(SVM)进行图像识别的完整过程,包括从获取并可视化MNIST数据集、进行数据标准化、划分训练和测试集、通过网格搜索优化SVM模型、评估模型性能到预测新图像的各个步骤,并在代码中添加了调试输出和计时器以便更好地跟踪和优化整个过程。
相关文章:

引领未来:在【PyCharm】中利用【机器学习】与【支持向量机】实现高效【图像识别】
目录 一、数据准备 1. 获取数据集 2. 数据可视化 3. 数据清洗 二、特征提取 1. 数据标准化 2. 图像增强 三、模型训练 1. 划分训练集和测试集 2. 训练 SVM 模型 3. 参数调优 四、模型评估 1. 评估模型性能 2. 可视化结果 五、预测新图像 1. 加载和预处理新图像…...
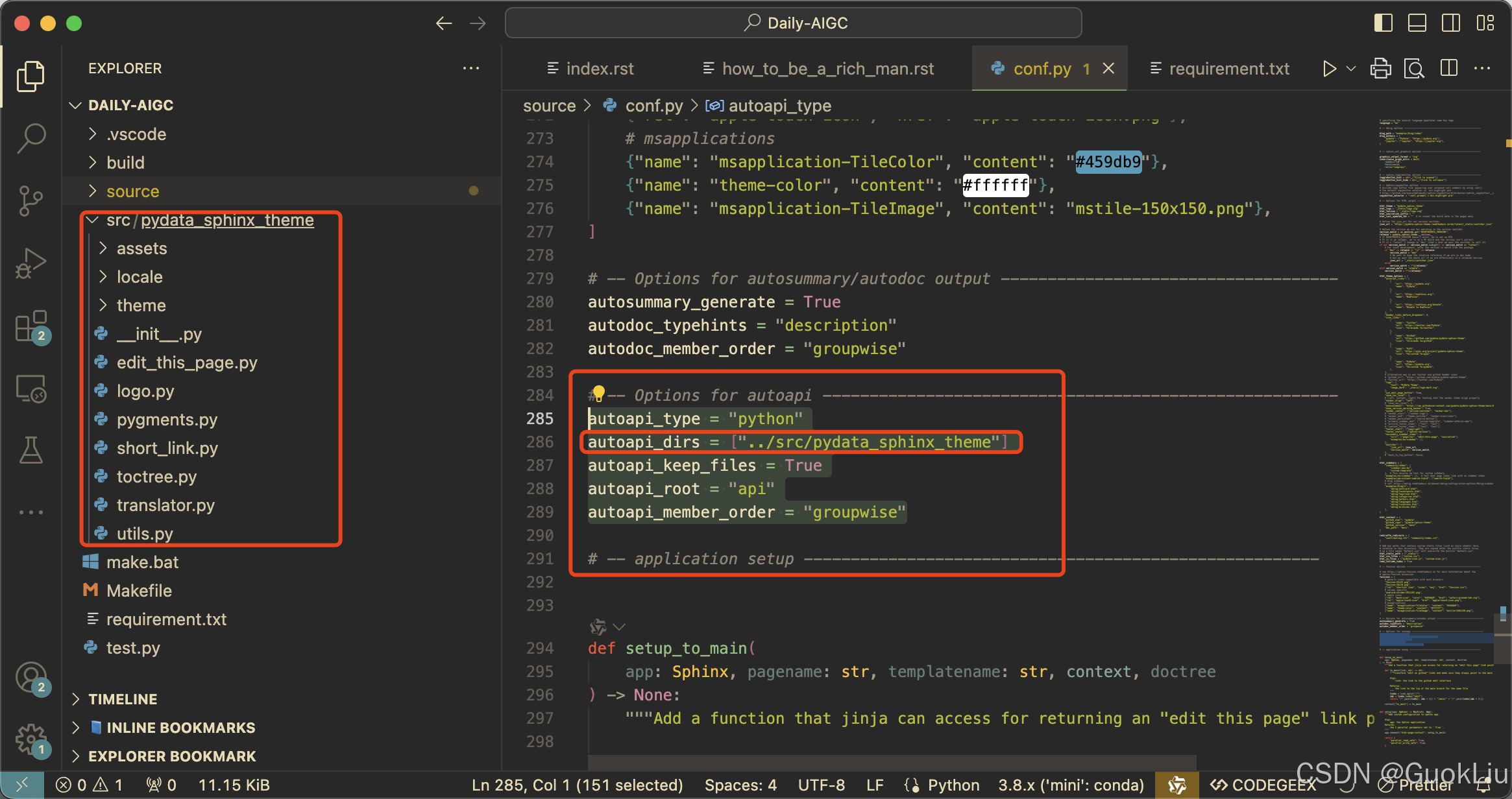
240707-Sphinx配置Pydata-Sphinx-Theme
Step A. 最终效果 Step B. 为什么选择Pydata-Sphinx-Theme主题 Gallery of sites using this theme — PyData Theme 0.15.4 documentation Step 1. 创建并激活Conda环境 conda create -n rtd_pydata python3.10 conda activate rtd_pydataStep 2. 安装默认的工具包 pip in…...

华为如何做成数字化转型?
目录 企业数字化转型是什么? 华为如何定义数字化转型? 为什么做数字化转型? 怎么做数字化转型? 华为IPD的最佳实践之“金蝶云” 企业数字化转型是什么? 先看一下案例,华为经历了多次战略转型…...

Python | Leetcode Python题解之第229题多数元素II
题目: 题解: class Solution:def majorityElement(self, nums: List[int]) -> List[int]:cnt {}ans []for v in nums:if v in cnt:cnt[v] 1else:cnt[v] 1for item in cnt.keys():if cnt[item] > len(nums)//3:ans.append(item)return ans...
)
TCP/IP模型和OSI模型的区别(面试题)
OSI模型,是国际标准化组织ISO制定的用于计算机或通讯系统间互联的标准化体系,主要分为7个层级: 物理层数据链路层网络层传输层会话层表示层应用层 虽然OSI模型在理论上更全面,但是在实际网络通讯中,TCP/IP模型更加实…...

UML建模工具Draw.io简介
新书速览|《UML 2.5基础、建模与设计实践 Draw.io是一个非常出色的免费、开源、简洁、方便的绘图软件,利用这款软件可以绘制出生动有趣的图形,包括流程图、地图、网络架构图、UML用例图、流程图等。它支持各种快捷键,免费提供了1000多张画图…...

qt udp 协议 详解
1.qt udp 协议链接举例 在Qt框架中,使用UDP协议进行通信主要依赖于QUdpSocket类。以下是一个基于Qt的UDP通信示例,包括UDP套接字的创建、绑定端口、发送和接收数据报的步骤。 1. 创建UDP套接字 首先,需要创建一个QUdpSocket对象。这通常在…...

ubuntu 换源
sudo apt update 错误如下 Ign:1 http://security.ubuntu.com/ubuntu focal-security InRelease Ign:2 http://us.archive.ubuntu.com/ubuntu focal InRelease Err:3 http://security.ubuntu.com/ubuntu focal-security Release SECURITY: URL redirect target…...

基于ssm的图书管理系统的设计与实现
摘 要 在当今信息技术日新月异的时代背景下,图书管理领域正经历着深刻的变革,传统的管理模式已难以适应现代社会的快节奏和高要求,逐渐向数字化、智能化的方向演进。本论文聚焦于这一转变趋势,致力于设计并成功实现一个基于 SSM&…...
)
python压缩PDF方案(Ghostscript+pdfc)
第一步:安装Ghostscript Ghostscript是一套建基于Adobe、PostScript及可移植文档格式(PDF)的页面描述语言等而编译成的免费软件。它可以作为文件格式转换器,如PostScript和PDF转换器,也为编程提供API。[1]PDF压缩本质…...

kotlin 基础
文章目录 1、安装 Java 和 Kotlin 环境2、程序代码基本结构3、变量的声明与使用4、数据类型5、数字类型的运算1)布尔类型2)字符类型3)字符串类型 6、 选择结构1)(if - else)2) 选择结构(when&am…...

Spring中的适配器模式和策略模式
1. 适配器模式的应用 1.1适配器模式(Adapter Pattern)的原始定义是:将一个类的接口转换为客户期望的另一个接口,适配器可以让不兼容的两个类一起协同工作。 1.2 AOP中的适配器模式 在Spring的AOP中,使用Advice&#…...

书生浦语大模型实战营---Python task
任务一 请实现一个wordcount函数,统计英文字符串中每个单词出现的次数,通过构建defaultdict字典,可以避免插入值时需要判断值是否存在 from collections import defaultdictdef word_count(text):#构建缓存reval defaultdict(int)words t…...

Chrome 127内置AI大模型攻略
Chrome 127 集成Gemini:本地AI功能 Google将Gemini大模型整合进Chrome浏览器,带来全新免费的本地AI体验: 完全免费、无限制使用支持离线运行,摆脱网络依赖功能涵盖图像识别、自然语言处理、智能推荐等中国大陆需要借助魔法,懂都懂。 安装部署步骤: 1. Chrome V127 dev …...

Yolo的离线运行
Yolo 的离线运行 运行环境准备 比较简单的办法是通过官方的github获取到对应的yolo运行需要的python环境-requirement.txt.通过如下地址可以获取到对应的文件和相应的说明以及实例。 Yolov5 git地址 为了让程序能本地话运行,我们还需要获取相应的模型权重文件&…...

【矿井知识】煤矿动火作业
简介 煤矿动火作业是指在煤矿环境下进行的任何形式的使用火源的工作。这些工作可能包括焊接、切割、加热、打磨等操作,这些操作都可能产生火花、火焰或高温,因此被称为动火作业。 动火作业的主要类型 焊接:包括电弧焊、气焊等,…...
)
设计模式使用场景实现示例及优缺点(结构型模式——享元模式)
结构型模式 享元模式(Flyweight Pattern) 享元模式,作为软件设计模式中的一员,其核心目标在于通过共享来有效地支持大量细粒度对象的使用。在内存使用优化方面,享元模式提供了一种极为高效的路径,尤其在处…...

开放式耳机哪款比较好?五款开放式耳机测评推荐
开放式耳机真的越来越火了,真的好多人问我,开放式耳机应该怎么选啊,所以这次我亲自测评了几款开放式耳机,作为数码博主这一篇文章就教大家如何挑选开放式耳机,当然最后还有五款开放式耳机的推荐给到大家,话…...

【网络安全】实验三(基于Windows部署CA)
一、配置环境 打开两台虚拟机,并参照下图,搭建网络拓扑环境,要求两台虚拟的IP地址要按照图中的标识进行设置,并根据搭建完成情况,勾选对应选项。注:此处的学号本人学号的最后两位数字,1学号100…...

hive中reverse函数
目录 前言基本函数介绍实战 前言 reverse函数,是一个常用的字符串处理函数,很多编程语言都有。最近开发中,遇到一个reverse解决的需求,发现自己尚未总结过,遂补上。 基本函数介绍 SELECT reverse(string_column) FR…...

终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破
终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破 【免费下载链接】TexasSolver 🚀 A very efficient Texas Holdem GTO solver :spades::hearts::clubs::diamonds: 项目地址: https://gitcode.com/gh_mirrors/te/TexasSolver …...

一次性掌握Mapbox地图开发框架
又到一年毕业季,春招已经基本结束,选择不考研直接就业的同学,如果5月还没拿到offer,接下来只能等暑期实习岗位,再晚一点就只能等秋招了。想找WebGIS相关的岗位,可以通过各种企业官方招聘网站、大众招聘平台…...

视频号视频下载去水印方法全是坑?全网视频一键拿捏!2026封神玩法!
日常视频号视频,遇到优质内容总想留存下来,不管是日常收藏翻阅,还是剪辑创作取用都十分合适。可现如今各大平台管控严格,直接保存功能尽数受限,自带水印遮挡画面观感,导出画质大打折扣。网上流传的各类存视…...

曼德勃罗集的 Three.js 实现
效果预览 经典的曼德勃罗集(Mandelbrot Set)分形渲染,配合动态缩放动画探索分形边界的无限细节。使用线性插值平滑着色,呈现出彩虹般的色彩过渡。 👉 点击查看《曼德勃罗集的》完整源码与效果演示 Shader 实现原理…...

Go语言模板引擎与前端渲染实战
Go语言模板引擎与前端渲染实战 引言 模板引擎是Web开发中连接后端数据与前端展示的关键组件。Go语言标准库提供了强大的模板引擎,本文将深入探讨其使用方法和最佳实践。 一、Go模板引擎基础 1.1 text/template与html/template // text/template - 纯文本模板 import…...

2026论文必藏降AIGC软件大曝光:一键压到安全线谁最稳
2026年的学术战场已经彻底变了天,论文不再是简单的知识输出,而是一场与AI检测系统的极限博弈。过去大家还在为查重率发愁,现在却集体陷入了更深层的焦虑——如何在不牺牲论文质量的前提下,把AIGC率压到最低?随着AI检测…...

Chrome for Testing 战略深度解析:构建确定性测试环境的架构决策
Chrome for Testing 战略深度解析:构建确定性测试环境的架构决策 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing 想象一下这个场景:你的团队刚刚完成了一个重要的功能开发,CI…...

Java应用CPU飙升到900%?这套排查套路让你10分钟定位根因
在这篇文章中,我将结合最近一次真实的生产事故,分享一套经过实战检验的CPU排查方法论。这不是教科书上那些”用jstack查看线程栈”的泛泛之谈,而是我们在72小时连续作战中总结出来的血泪经验。 一、告警响应该做什么?别急着重启&…...

python足球训练营系统的足球俱乐部管理系统 球员评估系统_m211bvkc
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能模块技术实现代码示例(球员评分计算)应用场景扩展方向获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货…...

Chrome插件开发实战指南:从入门到发布的完整开发教程
随着浏览器生态不断发展,Chrome插件(Chrome Extension)已经成为提高工作效率、实现自动化操作、数据采集以及浏览器功能增强的重要工具。无论是广告拦截、网页翻译、SEO分析,还是自动化办公,背后几乎都离不开Chrome插件技术。 尤其是在AI时代,Chrome插件已经不仅仅是“浏…...