Python excel知识库批量模糊匹配的3种方法实例(fuzzywuzzy\Gensim)
前言
当然,基于排序的模糊匹配(类似于Excel的VLOOKUP函数的模糊匹配模式)也属于模糊匹配的范畴,但那种过于简单,不是本文讨论的范畴。
本文主要讨论的是以公司名称或地址为主的字符串的模糊匹配。
使用编辑距离算法进行模糊匹配
进行模糊匹配的基本思路就是,计算每个字符串与目标字符串的相似度,取相似度最高的字符串作为与目标字符串的模糊匹配结果。
对于计算字符串之间的相似度,最常见的思路便是使用编辑距离算法。
下面我们有28条名称需要从数据库(390条数据)中找出最相似的名称:
| 1 2 3 4 5 6 7 8 9 |
|

编辑距离算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
一般来说,编辑距离越小,表示操作次数越少,两个字符串的相似度越大。
创建计算编辑距离的函数:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
关于上述代码的解析可参考力扣题解:https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-by-leetcode-solution/
遍历每个被查找的名称,计算它与数据库所有客户名称的编辑距离,并取编辑距离最小的客户名称:
| 1 2 3 4 5 6 7 |
|
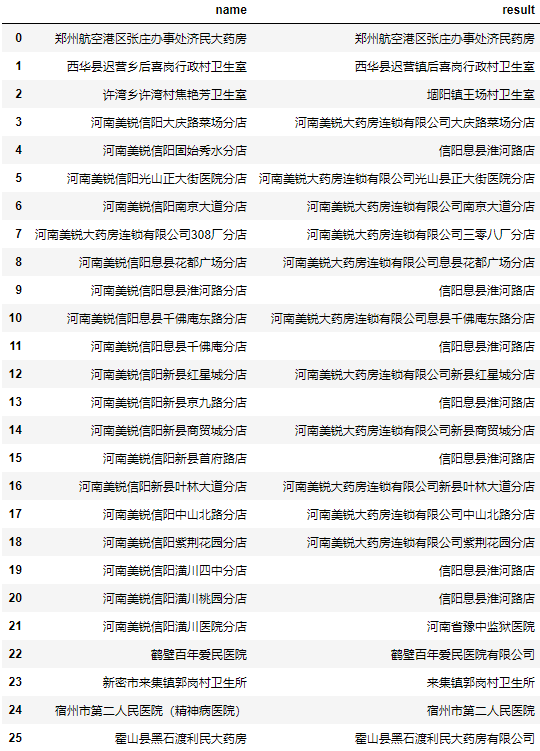
测试后发现部分地址的效果不佳。
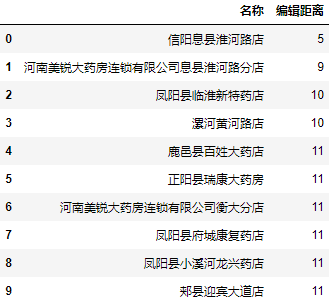
我们任取2个结果为信阳息县淮河路店地址看看编辑距离最小的前10个地址和编辑距离:
| 1 2 3 4 5 |
|
| 1 2 3 4 5 |
|

可以看到,在前十个编辑距离最小的名称中还是存在我们想要的结果。
使用fuzzywuzzy进行批量模糊匹配
通过上面的代码,我们已经基本了解了通过编辑距离算法进行批量模糊匹配的基本原理。不过自己编写编辑距离算法的代码较为复杂,转换为相似度进行分析也比较麻烦,如果已经有现成的轮子就不用自己写了。
而fuzzywuzzy库就是基于编辑距离算法开发的库,而且将数值量化为相似度评分,会比我们写的没有针对性优化的算法效果要好很多,可以通过pip install FuzzyWuzzy来安装。
对于fuzzywuzzy库,主要包含fuzz模块和process模块,fuzz模块用于计算两个字符串之间的相似度,相当于对上面的代码的封装和优化。而process模块则可以直接提取需要的结果。
fuzz模块
| 1 |
|
简单匹配(Ratio):
| 1 2 3 4 5 |
|
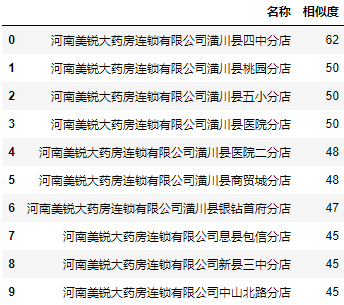
非完全匹配(Partial Ratio):
| 1 2 3 4 5 |
|

显然fuzzywuzzy库的 ratio()函数比前面自己写的编辑距离算法,准确度高了很多。
process模块
process模块则是进一步的封装,可以直接获取相似度最高的值和相似度:
| 1 |
|
extract提取多条数据:
| 1 2 3 4 |
|

从结果看,process模块似乎同时综合了fuzz模块简单匹配(Ratio)和非完全匹配(Partial Ratio)的结果。
当我们只需要返回一条数据时,使用extractOne会更加方便:
| 1 2 3 |
|
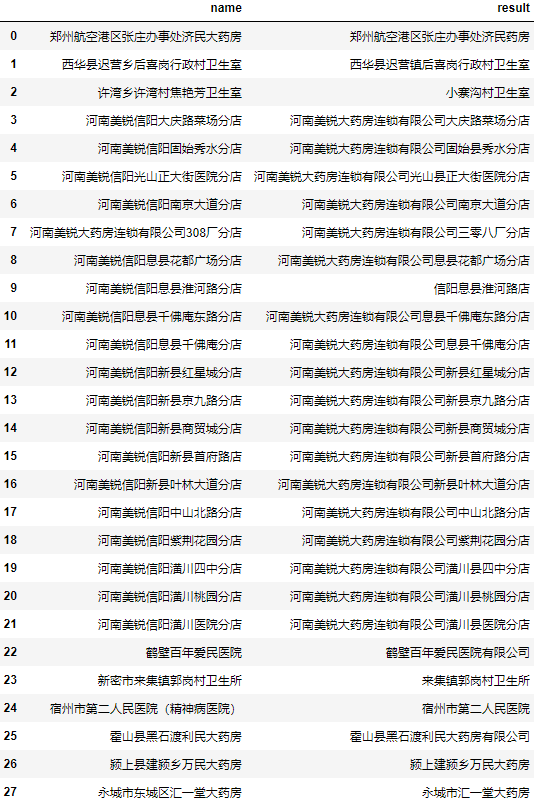
可以看到准确率相对前面自写的编辑距离算法有了大幅度提升,但个别名称匹配结果依然不佳。
查看这两个匹配不准确的地址:
| 1 |
|
[('小寨沟村卫生室', 51),
('周口城乡一体化焦艳芳一体化卫生室', 50),
('西华县皮营乡楼陈村卫生室', 42),
('叶县邓李乡杜杨村第二卫生室', 40),
('汤阴县瓦岗乡龙虎村东卫生室', 40)]
| 1 |
|
[('信阳息县淮河路店', 79),
('河南美锐大药房连锁有限公司息县淮河路分店', 67),
('河南美锐大药房连锁有限公司息县大河文锦分店', 53),
('河南美锐大药房连锁有限公司息县千佛庵东路分店', 51),
('河南美锐大药房连锁有限公司息县包信分店', 50)]
对于这样的问题,个人并没有一个很完美的解决方案,个人建议是将相似度最高的n个名称都加入结果列表中,后期再人工筛选:
| 1 2 3 4 |
|
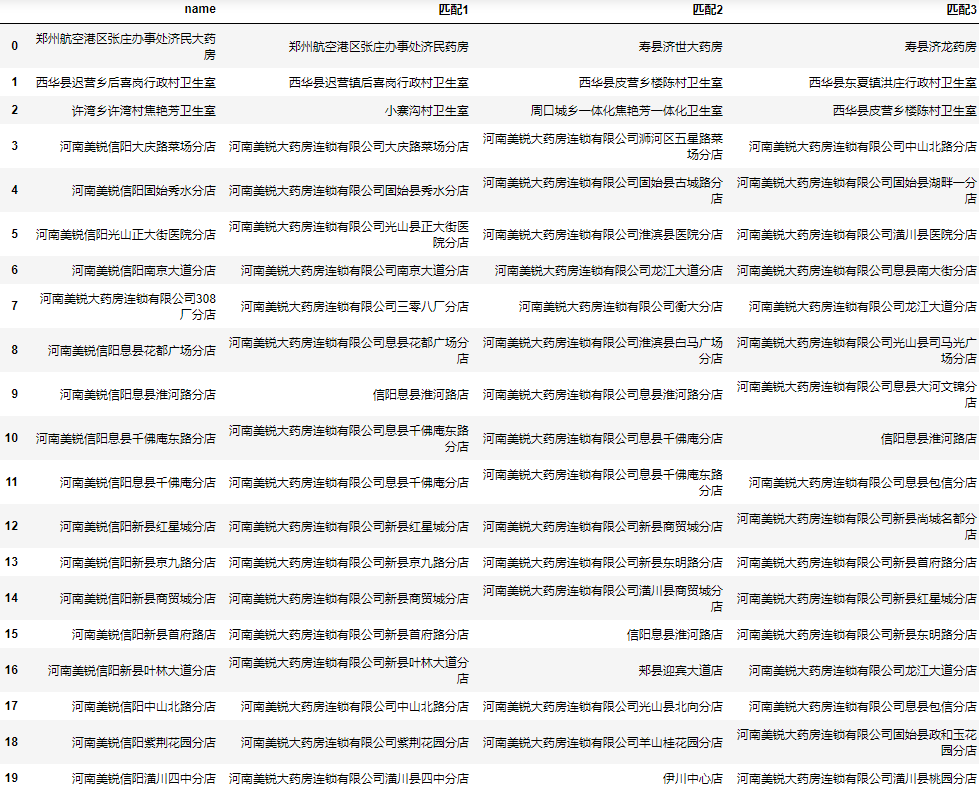
虽然可能有个别正确结果这5个都不是,但整体来说为人工筛查节省了大量时间。

整体代码
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
使用Gensim进行批量模糊匹配
Gensim简介
Gensim支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
基本概念:
- 语料(Corpus):一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。
- 向量(Vector):由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
- 稀疏向量(SparseVector):可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(key, value)的元组
- 模型(Model):是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
安装:pip install gensim
官网:https://radimrehurek.com/gensim/
什么情况下需要使用NLP来进行批量模糊匹配呢?那就是数据库数据过于庞大时,例如达到几万级别:
| 1 2 3 4 5 6 7 8 |
|

此时如果依然用编辑距离或fuzzywuzzy暴力遍历计算,预计1小时也无法计算出结果,但使用NLP神器Gensim仅需几秒钟,即可计算出结果。
使用词袋模型直接进行批量相似度匹配
首先,我们需要先对原始的文本进行分词,得到每一篇名称的特征列表:
| 1 2 3 4 |
|
0 [珠海, 广药, 康鸣, 医药, 有限公司]
1 [深圳市, 宝安区, 中心医院]
2 [中山, 火炬, 开发区, 伴康, 药店]
3 [中山市, 同方, 医药, 有限公司]
4 [广州市, 天河区, 元岗金, 健民, 医药, 店]
5 [广州市, 天河区, 元岗居, 健堂, 药房]
6 [广州市, 天河区, 元岗润佰, 药店]
7 [广州市, 天河区, 元岗, 协心, 药房]
8 [广州市, 天河区, 元岗, 心怡, 药店]
9 [广州市, 天河区, 元岗永亨堂, 药店]
Name: user, dtype: object
接下来,建立语料特征的索引字典,并将文本特征的原始表达转化成词袋模型对应的稀疏向量的表达:
| 1 2 3 4 5 |
|
0 [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)]
1 [(5, 1), (6, 1), (7, 1)]
2 [(8, 1), (9, 1), (10, 1), (11, 1), (12, 1)]
3 [(0, 1), (3, 1), (13, 1), (14, 1)]
4 [(0, 1), (15, 1), (16, 1), (17, 1), (18, 1), (...
Name: user, dtype: object
这样得到了每一个名称对应的稀疏向量(这里是bow向量),向量的每一个元素代表了一个词在这个名称中出现的次数。
至此我们就可以构建相似度矩阵:
| 1 2 3 |
|
再对被查找的名称作相同的处理,即可进行相似度批量匹配:
| 1 2 3 4 |
|
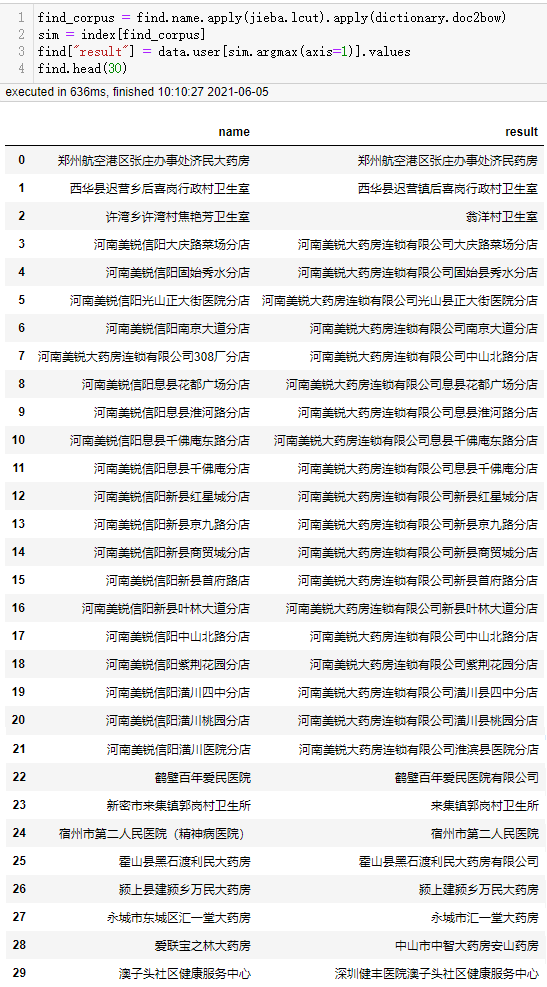
可以看到该模型计算速度非常快,准确率似乎整体上比fuzzywuzzy更高,但fuzzywuzzy对河南美锐大药房连锁有限公司308厂分店的匹配结果是正确的。
使用TF-IDF主题向量变换后进行批量相似度匹配
之前我们使用的Corpus都是词频向量的稀疏矩阵,现在将其转换为TF-IDF模型后再构建相似度矩阵:
| 1 2 3 4 5 |
|
被查找的名称也作相同的处理:
| 1 2 3 |
|

可以看到许湾乡许湾村焦艳芳卫生室匹配正确了,但河南美锐信阳息县淮河路分店又匹配错误了,这是因为在TF-IDF模型中,由于美锐在很多条数据中都出现被降权。
假如只对数据库做TF-IDF转换,被查找的名称只使用词频向量,匹配效果又如何呢?
| 1 2 3 4 5 6 7 8 |
|

可以看到除了数据库本来不包含正确名称的爱联宝之林大药房外还剩下河南美锐大药房连锁有限公司308厂分店匹配不正确。这是因为不能识别出308的语义等于三零八。如果这类数据较多,我们可以先将被查找的数据统一由小写数字转换为大写数字(保持与数据库一致)后,再分词处理:
| 1 2 3 4 5 6 |
|
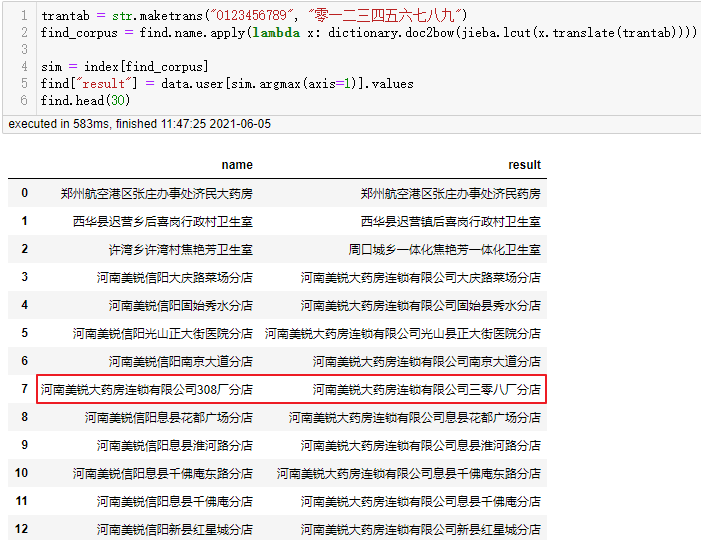
经过这样处理后,308厂分店也被正确匹配上了,其他类似的问题都可以使用该思路进行转换。
虽然经过上面的处理,匹配准确率几乎达到100%,但不代表其他类型的数据也会有如此高的准确率,还需根据数据的情况具体去分析转换。并没有一个很完美的批量模糊匹配的处理办法,对于这类问题,我们不能完全信任程序匹配的结果,都需要人工的二次检查,除非能够接受一定的错误率。
为了我们人工筛选的方便,我们可以将前N个相似度最高的数据都保存到结果中,这里我们以三个为例:
同时获取最大的3个结果
下面我们将相似度最高的3个值都添加到结果中:
| 1 2 3 4 5 6 7 8 |
|
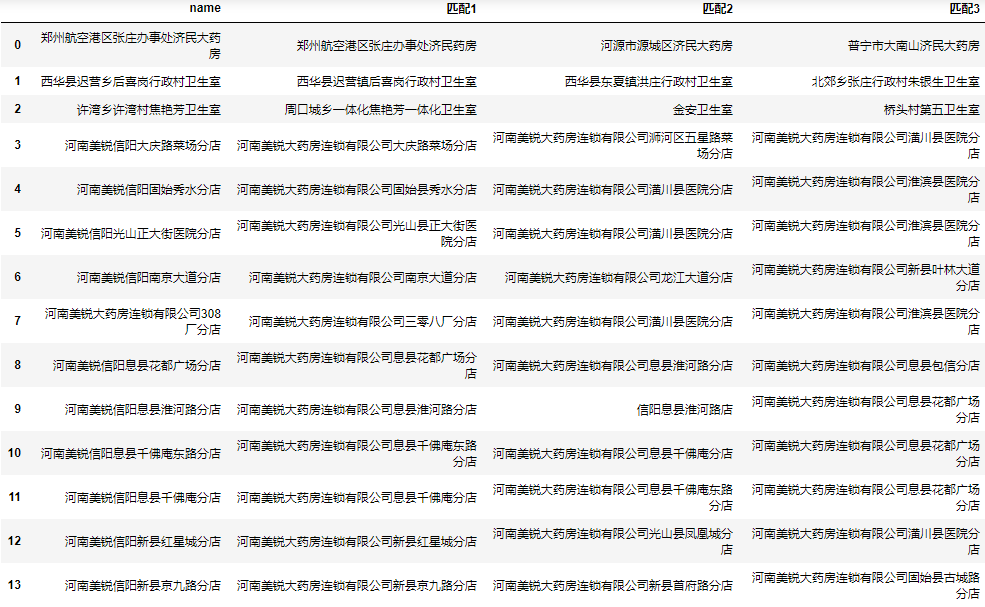
完整代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
总结
本文首先分享了编辑距离的概念,以及如何使用编辑距离进行相似度模糊匹配。然后介绍了基于该算法的轮子fuzzwuzzy,封装的较好,使用起来也很方便,但是当数据库量级达到万条以上时,效率极度下降,特别是数据量达到10万级别以上时,跑一整天也出不了结果。于是通过Gensim计算分词后对应的tf-idf向量来计算相似度,计算时间由几小时降低到几秒,而且准确率也有了较大提升,能应对大部分批量相似度模糊匹配问题。
到此这篇关于Python批量模糊匹配的3种方法的文章就介绍到这了,更多相关Python批量模糊匹配内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章:
Python excel知识库批量模糊匹配的3种方法实例(fuzzywuzzy\Gensim)
前言 当然,基于排序的模糊匹配(类似于Excel的VLOOKUP函数的模糊匹配模式)也属于模糊匹配的范畴,但那种过于简单,不是本文讨论的范畴。 本文主要讨论的是以公司名称或地址为主的字符串的模糊匹配。 使用编辑距离算法进…...

stm32使用单通道规则组ADC
Driver_ADC.c 如果需要关闭adc转换,只需要设置CNT,将其置为0,后面再转换一次就停止了。 #include "Driver_ADC.h"void Driver_ADC1_Init(void) {/* 1. 时钟配置 *//* 1.1 adc时钟 */RCC->APB2ENR | RCC_APB2ENR_ADC1EN;RCC-&g…...

[python][whl]causal-conv1d的python模块在windows上whl文件下载
【模块介绍】 causal-conv1d,即因果一维卷积(Causal 1D Convolution),是一种在深度学习特别是时序数据处理中广泛应用的卷积技术。它主要特点在于其“因果性”,即输出的每个元素仅依赖于输入序列中它之前的元素&#…...

介绍 CM3leon,一个更高效、最先进的文本和图像生成模型
近几个月来,随着让机器理解和表达语言的自然语言处理技术以及可根据文本输入生成图像的系统的进步,人们对生成式人工智能模型的兴趣和研究也在加速。今天,我们要展示的是 CM3leon(发音类似于 “变色龙”),它…...

HTTPS和HTTP有哪些区别
两者的主要区别在于安全性和数据加密: 加密层:HTTPS 在HTTP 的基础上增加了SSL/TLS 协议作为加密层,确保数据传输的安全性,即使数据被截获,没有相应的密钥也无法解读数据内容。而HTTP 数据传输是明文的,容易受到攻击。…...

Docker 安装 PostgreSQL
1. 启动 PostgreSQL 容器 docker run --name ffj-postgres -p 5432:5432 -e POSTGRES_PASSWORDCisc0123 -d postgres docker run:启动一个新的容器。--name指定容器名称为 ffj-postgres。-p 5432:5432:将主机的 5432 端口映射到容器的 5432 端口。-e P…...

实践致知第12享:如何新建一个Word并设置格式
一、背景需求 小姑电话说:要新建一个Word文档,并将每段的首行设置空2格。 二、解决方案 1、在电脑桌面上空白地方,点击鼠标右键,在下拉的功能框中选择“DOC文档”或“DOCX文档”都可以,如下图所示。 之后࿰…...

Rust vs Go: 特点与应用场景分析
目录 介绍Rust的特点Go的特点Rust的应用场景Go的应用场景总结 介绍 Rust和Go(Golang)是现代编程语言中两个非常流行的选择。凭借各自的独特优势和广泛的应用场景,吸引了大量开发者的关注。本文将详细介绍Rust和Go的特点,并探讨它…...

2024的开放式耳机排行榜,看这六个耳机选购的小Tips
寻找一款既能聊天又能听歌的耳机并不容易,但是开放式耳机可能会是一个理想的选择。与传统的入耳式耳机相比,开放式耳机可以让你更加自然地与周围环境互动,并且不容易掉落。当然,在市场上选择一款适合自己的开放式耳机也是至关重要…...

JAVA-报表模糊搜索询易实现
背景: 一般文件报表经常会需要搜各个表头对应内容,如果支持全部类型切换搜索,操作起来就不够便捷。而且这个报表是测试自己用的,准确性可以不用太要求,所以更想要那中输入关键字命中任意表记录内容的模糊匹配功能。 方法一:解析搜…...

牛客 7.13 月赛(留 C逆元)
B-最少剩几个?_牛客小白月赛98 (nowcoder.com) 思路 奇数偶数 奇数;奇数*偶数 奇数 所以在既有奇数又有偶数时,两者结合可以同时删除 先分别统计奇数,偶数个数 若偶个数大于奇个数,答案是偶个数-奇个数 若奇个数…...

FPGA之术语
FPGA之术语 IOSTANDARDDIFF_SSTL12:LVCMOS33:sys_clk_p/n:rst_n:UART时钟JTAG:GPIOONFIPCIe IOSTANDARD 在电子工程领域,DIFF_SSTL12和LVCMOS33是两种不同的电气标准,用于定义信号的电压级别和特性。 IOSTANDARD是一个在FPGA(现场可编程门阵…...

WPF透明置顶窗口wine适配穿透问题解决
一、透明窗口全屏时,鼠标不穿透 问题描述 我有一个透明窗口,它是一个全屏置顶窗口,窗口里面有一个工具条,可以通过鼠标拖动工具条的位置,程序启动后,在不点击工具条的时候,鼠标是可以穿透的&a…...
方法的使用)
浅析Kafka Streams中KTable.aggregate()方法的使用
KTable.aggregate() 方法是 Apache Kafka Streams API 中用于对流数据进行状态化聚合的核心方法之一。这个方法允许你根据一个键值(通常是<K,V>类型)的流数据,应用一个初始值和一个聚合函数,来累积和更新一个状态࿰…...

java word转pdf、word中关键字位置插入图片 工具类
java word转pdf、word中关键字位置插入图片 工具类 1.pom依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.15</version></dependency><dependency><groupId>org.apa…...

jail内部ubuntu apt升级失败问题解决
在FreeBSD jail 里安装启动Ubuntu jammy系统,每次装好执行jexec ubjammy sh进入Ubuntu系统后,执行apt update报错。 这个问题困惑了好久,突然有一天仔细去看报错信息,查看了(man 5 apt.conf) ,才搞定问题。简单来说就是…...

迎接AI新时代:GPT-5的技术飞跃与未来展望
引言 随着人工智能技术的迅猛发展,大语言模型在过去几年取得了显著进步。OpenAI最新的声明表明,GPT-5将在一年半后发布,并将带来从高中生智力水平到博士生智力水平的飞跃。这一突破引起了科技界和公众的广泛关注。本文将从技术突破预测、智能…...

Snap Video:用于文本到视频合成的扩展时空变换器
图像生成模型的质量和多功能性的显著提升,研究界开始将其应用于视频生成领域。但是视频内容高度冗余,直接将图像模型技术应用于视频生成可能会降低运动的保真度和视觉质量,并影响可扩展性。来自 Snap 的研究团队及其合作者提出了 "Snap …...

实验8 视图创建与管理实验
一、实验目的 理解视图的概念。掌握创建、更改、删除视图的方法。掌握使用视图来访问数据的方法。 二、实验内容 在job数据库中,有聘任人员信息表:Work_lnfo表,其表结构如下表所示: 其中表中练习数据如下: 1.‘张明…...

C++ 开源库
1 PDFium PDFium 是一个开源的 PDF 渲染和处理库,最初由 Foxit Software 开发,并于2014年捐赠给了 Chromium 项目。PDFium 旨在为各种应用程序提供高效、灵活的 PDF 渲染和操作功能。 2 代码地址 https://github.com/chromium/pdfium 主要特性 渲染…...

如何高效使用RBTray:Windows窗口管理终极解决方案
如何高效使用RBTray:Windows窗口管理终极解决方案 【免费下载链接】rbtray A fork of RBTray from http://sourceforge.net/p/rbtray/code/. 项目地址: https://gitcode.com/gh_mirrors/rb/rbtray 你是否经常被桌面上堆积如山的窗口搞得心烦意乱?…...

华为认证“以学代考”续证政策——伙伴篇
华为认证面向伙伴正式推出“以学代考”续证机制,支持华为中国区政企伙伴通过在线学习和在线考试后,即可获取续认证。当前,“以学代考”产品已上架伙伴TF基金产品兑换清单,伙伴可通过TF基金兑换相应课程,完成续认证。完…...

ChromeKeePass终极指南:如何在Chrome浏览器中实现KeePass密码自动填充
ChromeKeePass终极指南:如何在Chrome浏览器中实现KeePass密码自动填充 【免费下载链接】ChromeKeePass Chrome extensions for automatically filling credentials from KeePass 项目地址: https://gitcode.com/gh_mirrors/ch/ChromeKeePass ChromeKeePass是…...

Sunshine游戏串流服务器架构深度解析:5个高级性能调优技巧与源码设计实战
Sunshine游戏串流服务器架构深度解析:5个高级性能调优技巧与源码设计实战 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine作为一款开源的自托管游戏串流服务器…...
)
如何用1条提示生成可商用超现实IP?:Midjourney商业级输出的6道合规校验流程(含版权链存证路径)
更多请点击: https://codechina.net 第一章:超现实IP的商业价值与Midjourney生成范式跃迁 超现实IP正从边缘创意实验走向主流商业基础设施——其核心驱动力并非单纯视觉奇观,而是对用户心智注意力的结构性重构。当品牌不再依赖写实叙事建立信…...

如何在Hermes Agent项目中自定义Provider接入Taotoken多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在Hermes Agent项目中自定义Provider接入Taotoken多模型服务 Hermes Agent 是一个功能强大的AI代理框架,它允许开发…...

Camunda流程版本管理避坑指南:从Version Tag查询到迁移验证,这些细节决定成败
Camunda流程版本管理实战精要:从精准查询到安全迁移的全链路策略 在企业级流程自动化领域,Camunda作为领先的工作流引擎,其版本管理机制直接影响着业务系统的稳定性和迭代效率。本文将深入剖析版本管理的核心痛点,提供一套覆盖全…...

拆解国产FPGA的HDMI显示链路:从PGL22G的TMDS编码到MS7200接收芯片的完整信号流分析
国产FPGA的HDMI显示链路深度解析:从PGL22G的TMDS编码到MS7200接收芯片全流程 在当今国产芯片崛起的浪潮中,紫光同创PGL22G FPGA以其出色的性价比和完整的生态支持,成为许多视频处理项目的首选。本文将带您深入理解一个完整的HDMI显示链路如何…...
)
别再死记硬背公式了!用Excel+Python搞定数学建模三大评价模型(附代码)
用ExcelPython玩转数学建模三大评价模型:告别公式恐惧症 数学建模竞赛中,评价模型是绕不开的核心工具。但面对满屏的数学符号和抽象公式,很多同学的第一反应是头皮发麻——"这些矩阵运算到底怎么落地?""一致性检验…...

C++ `dynamic_cast
1. 基础 C类型转换概览为什么需要dynamic_cast 2. dynamic_cast 的使用 基本语法与其他类型转换(如 static_cast、reinterpret_cast 和 const_cast)的对比 3. RTTI (运行时类型信息) 什么是RTTI如何在C中启用和禁用RTTI 4. dynamic_cast 与多态 使用dyna…...