浅析Kafka Streams中KTable.aggregate()方法的使用
KTable.aggregate() 方法是 Apache Kafka Streams API 中用于对流数据进行状态化聚合的核心方法之一。这个方法允许你根据一个键值(通常是<K,V>类型)的流数据,应用一个初始值和一个聚合函数,来累积和更新一个状态(通常是<K,AGG>类型)。下面是详细的解释和使用方法:
方法签名
KTable<K, V> 类型的 aggregate() 方法通常具有以下几种重载形式:
-
无状态聚合:
KTable<K, AGG> aggregate(Initializer<AGG> initializer,Aggregator<K, V, AGG> aggregator ); -
带状态聚合:
KTable<K, AGG> aggregate(Initializer<AGG> initializer,Aggregator<K, V, AGG> aggregator,Materialized<K, AGG, ? extends Store> materialized ); -
窗口化聚合:
KTable<Windowed<K>, AGG> aggregate(Initializer<AGG> initializer,Aggregator<K, V, AGG> aggregator,TimeWindowedKTable<Windowed<K>, V> windowed,Materialized<K, AGG, ? extends WindowStore> materialized );
参数说明
-
Initializer initializer: 一个函数,用于返回每个键的初始聚合值。这通常是一个简单的工厂方法,创建一个默认的聚合值。
-
Aggregator<K, V, AGG> aggregator: 一个函数,用于定义如何将新的流元素与当前状态聚合值进行合并。此函数接收三个参数:键(
K)、新值(V)和当前聚合值(AGG),并返回一个新的聚合值。 -
Materialized<K, AGG, ? extends Store> materialized: 可选参数,用于配置状态存储的细节,比如存储类型(如
KeyValueStore或WindowStore)、序列化器、持久化设置等。
使用示例
假设我们有一个 KTable,包含用户ID和他们购买的产品数量,我们想要计算每个用户累计的购买数量:
1. 定义 Initializer 和 Aggregator
public class PurchaseCountInitializer implements Initializer<Long> {@Overridepublic Long apply() {return 0L; // 初始购买数量为0}
}public class PurchaseAggregator implements Aggregator<String, Integer, Long> {@Overridepublic Long apply(String key, Integer value, Long aggregate) {return aggregate + value; // 累加每次购买的数量}
}
2. 调用 .aggregate()
KTable<String, Integer> purchases = ...; // 假设这里是从某个主题读取的购买记录KTable<String, Long> purchaseCounts = purchases.aggregate(new PurchaseCountInitializer(),new PurchaseAggregator(),Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("purchase-count-store").withKeySerde(Serdes.String()).withValueSerde(Serdes.Long())
);
在这个示例中,我们使用了 Materialized 参数来指定状态存储的名称,并配置了键和值的序列化器。
3. 处理窗口化数据
如果我们要处理窗口化的数据,例如计算每个用户过去5分钟内的购买数量,则需要使用窗口化版本的 aggregate() 方法:
TimeWindowedKTable<String, Integer> purchasesWindowed = purchases.windowedBy(TimeWindows.of(Duration.ofMinutes(5)));KTable<Windowed<String>, Long> purchaseCountsWindowed = purchasesWindowed.aggregate(new PurchaseCountInitializer(),new PurchaseAggregator(),Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("purchase-count-window-store").withKeySerde(Serdes.WindowedSerde(Serdes.String())).withValueSerde(Serdes.Long())
);
在这个例子中,TimeWindows.of(Duration.ofMinutes(5)) 创建了一个持续时间为5分钟的滚动窗口。
总结
KTable.aggregate() 方法是 Kafka Streams 中进行状态化聚合的关键,它允许你定义如何初始化和更新聚合状态,以及如何存储和管理这些状态。通过合理配置,你可以实现复杂的数据流处理需求,如累积计数、滑动窗口计算等。
相关文章:
方法的使用)
浅析Kafka Streams中KTable.aggregate()方法的使用
KTable.aggregate() 方法是 Apache Kafka Streams API 中用于对流数据进行状态化聚合的核心方法之一。这个方法允许你根据一个键值(通常是<K,V>类型)的流数据,应用一个初始值和一个聚合函数,来累积和更新一个状态࿰…...

java word转pdf、word中关键字位置插入图片 工具类
java word转pdf、word中关键字位置插入图片 工具类 1.pom依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.15</version></dependency><dependency><groupId>org.apa…...

jail内部ubuntu apt升级失败问题解决
在FreeBSD jail 里安装启动Ubuntu jammy系统,每次装好执行jexec ubjammy sh进入Ubuntu系统后,执行apt update报错。 这个问题困惑了好久,突然有一天仔细去看报错信息,查看了(man 5 apt.conf) ,才搞定问题。简单来说就是…...

迎接AI新时代:GPT-5的技术飞跃与未来展望
引言 随着人工智能技术的迅猛发展,大语言模型在过去几年取得了显著进步。OpenAI最新的声明表明,GPT-5将在一年半后发布,并将带来从高中生智力水平到博士生智力水平的飞跃。这一突破引起了科技界和公众的广泛关注。本文将从技术突破预测、智能…...

Snap Video:用于文本到视频合成的扩展时空变换器
图像生成模型的质量和多功能性的显著提升,研究界开始将其应用于视频生成领域。但是视频内容高度冗余,直接将图像模型技术应用于视频生成可能会降低运动的保真度和视觉质量,并影响可扩展性。来自 Snap 的研究团队及其合作者提出了 "Snap …...

实验8 视图创建与管理实验
一、实验目的 理解视图的概念。掌握创建、更改、删除视图的方法。掌握使用视图来访问数据的方法。 二、实验内容 在job数据库中,有聘任人员信息表:Work_lnfo表,其表结构如下表所示: 其中表中练习数据如下: 1.‘张明…...

C++ 开源库
1 PDFium PDFium 是一个开源的 PDF 渲染和处理库,最初由 Foxit Software 开发,并于2014年捐赠给了 Chromium 项目。PDFium 旨在为各种应用程序提供高效、灵活的 PDF 渲染和操作功能。 2 代码地址 https://github.com/chromium/pdfium 主要特性 渲染…...
LabVIEW滤波器性能研究
为了研究滤波器的滤波性能,采用LabVIEW设计了一套滤波器性能研究系统。该系统通过LabVIEW中的波形生成函数,输出幅值及频率可调的正弦波和白噪声两种信号,并将白噪声与正弦波叠加,再通过滤波器输出纯净的正弦波信号。系统通过FFT&…...

『C++成长记』vector模拟实现
🔥博客主页:小王又困了 📚系列专栏:C 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、存储结构 二、默认成员函数 📒2.1构造函数 📒2.2拷贝…...

【Mac】Charles for Mac(HTTP协议抓包工具)及同类型软件介绍
软件介绍 Charles for Mac 是一款功能强大的网络调试工具,主要用于HTTP代理/HTTP监视器。以下是它的一些主要特点和功能: 1.HTTP代理:Charles 可以作为HTTP代理服务器,允许你查看客户端和服务器之间的所有HTTP和SSL/TLS通信。 …...

LVS集群及其它的NAT模式
1.lvs集群作用:是linux的内核层面实现负载均衡的软件;将多个后端服务器组成一个高可用、高性能的服务器的集群,通过负载均衡的算法将客户端的请求分发到后端的服务器上,通过这种方式实现高可用和负载均衡。 2.集群和分布式&#…...

【RNN练习】天气预测
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、环境及数据准备 1. 我的环境 语言环境:Python3.11.9编译器:Jupyter notebook深度学习框架:TensorFlow 2.15.0 2. 导…...

prompt第四讲-fewshot
文章目录 前提回顾FewShotPromptTemplateforamt格式化 前提回顾 前面已经实现了一个翻译助手了[prompt第三讲-PromptTemplate],prompt模板设计中,有说明、案例、和实际的问题 # -*- coding: utf-8 -*- """ Time : 2024/7/8 …...
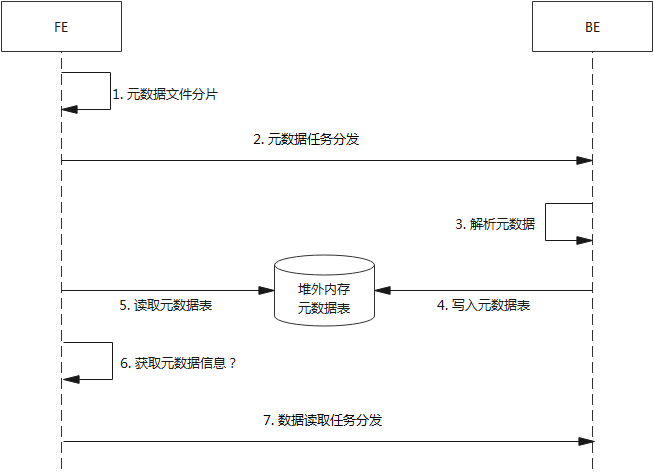
StarRocks分布式元数据源码解析
1. 支持元数据表 https://github.com/StarRocks/starrocks/pull/44276/files 核心类:LogicalIcebergMetadataTable,Iceberg元数据表,将元数据的各个字段做成表的列,后期可以通过sql操作从元数据获取字段,这个表的组成…...

阅读笔记——《Fuzz4All: Universal Fuzzing with Large Language Models》
【参考文献】Xia C S, Paltenghi M, Le Tian J, et al. Fuzz4all: Universal fuzzing with large language models[C]//Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024: 1-13.【注】本文仅为作者个人学习笔记,如有冒犯&…...

【C++】使用gtest做单元测试框架写单元测试
本文主要介绍在将gtest框架引入到项目里过程中遇到的问题。 我的需求如下: 用CMake构建项目。我要写一些测试程序验证某些功能,但是不想每一个测试都新建一个main函数。 因为新建一个main函数就要在CMakeList.txt里增加一个project,非常不方便。 于是我搜了下,C++里有没…...

Java类与对象
类是对现实世界中实体的抽象,是对一类事物的描述。 类的属性位置在类的内部、方法的外部。 类的属性描述一个类的一些可描述的特性,比如人的姓名、年龄、性别等。 [public] [abstract|final] class 类名 [extends父类] [implements接口列表] { 属性声…...

xlwings 链接到 指定sheet 从别的 excel 复制 sheet 到指定 sheet
重点 可以参考 宏录制 cell sheet.range(G4)cell.api.Hyperlinks.Add(Anchorcell.api, Address"", SubAddress"001-000-02301!A1")def deal_excel(self):with xw.App(visibleTrue) as app:wb app.books.open(self.summary_path, update_linksFalse)sheet…...

风光摄影:相机设置和镜头选择
写在前面 博文内容为《斯科特凯尔比的风光摄影手册》读书笔记整理涉及在风景拍摄中一些相机设置,镜头选择的建议对小白来讲很实用,避免拍摄一些过曝或者过暗的风景照片理解不足小伙伴帮忙指正 😃,生活加油 99%的焦虑都来自于虚度时间和没有好…...
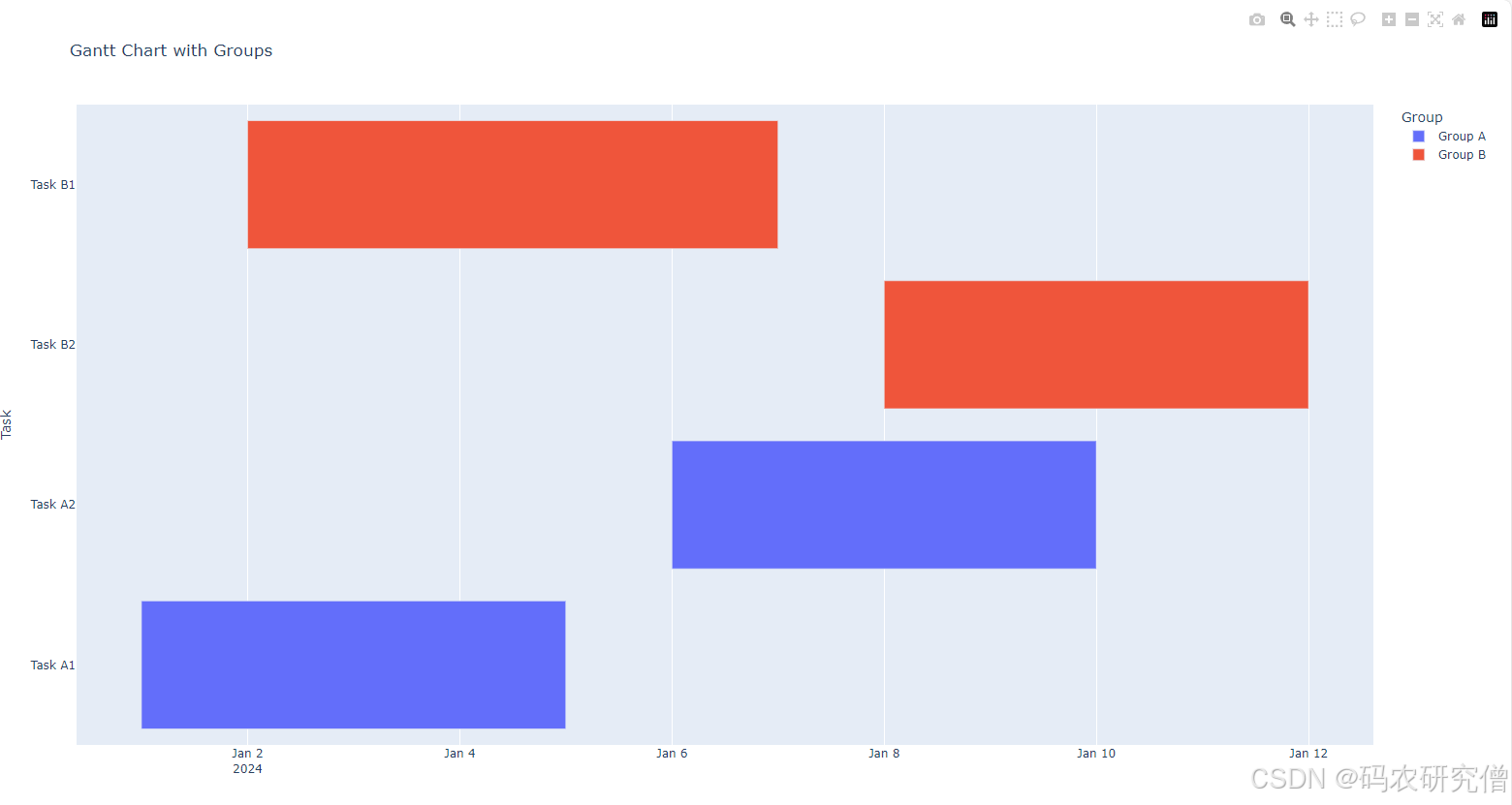
python制作甘特图的基本知识(附Demo)
目录 前言1. matplotlib2. plotly 前言 甘特图是一种常见的项目管理工具,用于表示项目任务的时间进度 直观地看到项目的各个任务在时间上的分布和进度 常用的绘制甘特图的工具是 matplotlib 和 plotly 主要以Demo的形式展示 1. matplotlib 功能强大的绘图库&a…...

独立开发者如何利用Taotoken构建多模型备用方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken构建多模型备用方案 对于独立开发者而言,项目的技术栈选择与成本控制至关重要。在集成大模…...
)
【限时解密】Midjourney野兽派风格“原始态”生成协议:仅用/raw + 2个隐藏参数,绕过所有风格平滑化过滤(实测成功率提升67%)
更多请点击: https://codechina.net 第一章:Midjourney野兽派风格的美学本质与系统性失衡 野兽派(Fauvism)在视觉艺术中以高饱和色彩、粗犷笔触与主观情感压倒写实逻辑著称;当这一美学被Midjourney等扩散模型“转译”…...

百考通AI:答辩PPT智能生成,覆盖从开题到终答的全流程,让毕业答辩更从容
毕业答辩是学术生涯的关键一战,一份逻辑清晰、专业美观的PPT是顺利通关的核心保障,却也让无数毕业生熬夜奋战:从提炼研究核心到规划答辩流程,从设计页面排版到打磨讲稿,繁琐的准备工作常常让人焦头烂额。百考通AI&…...

TikTokDownload:5分钟搞定抖音去水印批量下载终极方案
TikTokDownload:5分钟搞定抖音去水印批量下载终极方案 【免费下载链接】TikTokDownload 抖音去水印批量下载用户主页作品、喜欢、收藏、图文、音频 项目地址: https://gitcode.com/gh_mirrors/ti/TikTokDownload 想要轻松保存抖音上的精彩内容却苦于官方水印…...

AIDD入门第七课:大语言模型是如何读懂文字,又如何走进药物发现的?
前几篇文章中,我们已经介绍了机器学习、深度学习、神经网络,以及CNN、RNN、Transformer等经典结构。今天这篇文章,进入一个更靠近当下AI浪潮的主题:大语言模型与自然语言处理。自然语言处理(Natural Language Processi…...

如何高效使用League Akari:提升英雄联盟体验的5个实用功能指南
如何高效使用League Akari:提升英雄联盟体验的5个实用功能指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款…...

Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节
Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节 当工业自动化遇上Python,pylogix库成为了连接AB PLC与Python世界的桥梁。但在处理数组、字符串和用户自定义数据类型(UDT)时,即便是经验丰富的开发…...

DownKyi终极教程:3步掌握B站视频下载,免费打造个人媒体库
DownKyi终极教程:3步掌握B站视频下载,免费打造个人媒体库 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、…...

GRBL-Plotter完全指南:从创意到实物的智能数控转换方案
GRBL-Plotter完全指南:从创意到实物的智能数控转换方案 【免费下载链接】GRBL-Plotter A GCode sender (not only for lasers or plotters) for up to two GRBL controller. SVG, DXF, HPGL import. 6 axis DRO. 项目地址: https://gitcode.com/gh_mirrors/gr/GR…...

终极AMD Ryzen调试指南:5个场景掌握SMUDebugTool硬件调优
终极AMD Ryzen调试指南:5个场景掌握SMUDebugTool硬件调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:/…...