【Pytorch】RNN for Image Classification

文章目录
- 1 RNN 的定义
- 2 RNN 输入 input, h_0
- 3 RNN 输出 output, h_n
- 4 多层
- 5 小试牛刀
学习参考来自
- pytorch中nn.RNN()总结
- RNN for Image Classification(RNN图片分类–MNIST数据集)
- pytorch使用-nn.RNN
- Building RNNs is Fun with PyTorch and Google Colab
1 RNN 的定义

nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity=tanh, bias=True, batch_first=False, dropout=0, bidirectional=False)
参数说明
- input_size输入特征的维度, 一般 rnn 中输入的是词向量,那么 input_size 就等于一个词向量的维度
- hidden_size隐藏层神经元个数,或者也叫输出的维度(因为rnn输出为各个时间步上的隐藏状态)
- num_layers网络的层数
- nonlinearity激活函数
- bias是否使用偏置
- batch_first输入数据的形式,默认是 False,就是这样形式,(seq(num_step), batch, input_dim),也就是将序列长度放在第一位,batch 放在第二位
- dropout是否应用dropout, 默认不使用,如若使用将其设置成一个0-1的数字即可
- birdirectional是否使用双向的 rnn,默认是 False
2 RNN 输入 input, h_0
input 形状: 当设置 batch_first = False 时, ( L , N , H i n ) (L , N , H_{ i n}) (L,N,Hin) —— [时间步数, 批量大小, 特征维度]
当设置 batch_first = True时, ( N , L , H i n ) (N , L , H_{ i n}) (N,L,Hin)
当输入只有两个维度且 batch_size 为 1 时 : ( L , H i n ) (L, H_{in}) (L,Hin) 时,需要调用 torch.unsqueeze() 增加维度。
h_0 形状: ( D ∗ n u m _ l a y e r s , N , H o u t ) ( D ∗ n u m \_ l a y e r s , N , H _{o u t} ) (D∗num_layers,N,Hout), D 代表单向 RNN 还是双向 RNN。

3 RNN 输出 output, h_n
output 形状:当设置 batch_first = False 时, ( L , N , D ∗ H o u t ) (L, N, D * H_{out}) (L,N,D∗Hout)—— [时间步数, 批量大小, 隐藏单元个数];
当设置 batch_first = True 时, ( N , L , D ∗ H o u t ) (N, L, D * H_{out}) (N,L,D∗Hout)。
h_n 形状: ( D ∗ num_layers , N , H o u t ) (D * \text{num\_layers}, N, H_{out}) (D∗num_layers,N,Hout)
4 多层

5 小试牛刀

如MNIST中28行看成28个序列, 每个序列有28个特征

x_0 到 x_27, 相当于依次输入图像的28行
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt# -------------
# MNIST dataset
# -------------
batch_size = 128
train_dataset = torchvision.datasets.MNIST(root='./',train=True,transform=transforms.ToTensor(),download=True)
test_dataset = torchvision.datasets.MNIST(root='./',train=False,transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)# ---------------------
# Exploring the dataset
# ---------------------
# function to show an image
def imshow(img):npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))# get some random training images
dataiter = iter(train_loader)
images, labels = dataiter.next()if 1:# show imageimshow(torchvision.utils.make_grid(images, nrow=15))plt.show()# ----------
# parameters
# ----------
N_STEPS = 28
N_INPUTS = 28 # 输入数据的维度
N_NEURONS = 150 # RNN中间的特征的大小
N_OUTPUT = 10 # 输出数据的维度(分类的个数)
N_EPHOCS = 10 # epoch的大小
N_LAYERS = 3# ------
# models
# ------
class ImageRNN(nn.Module):def __init__(self, batch_size, n_inputs, n_neurons, n_outputs, n_layers):super(ImageRNN, self).__init__()self.batch_size = batch_size # 输入的时候batch_size, 128self.n_inputs = n_inputs # 输入的维度, 28self.n_outputs = n_outputs # 分类的大小 10self.n_neurons = n_neurons # RNN中输出的维度 150self.n_layers = n_layers # RNN中的层数 3self.basic_rnn = nn.RNN(self.n_inputs, self.n_neurons, num_layers=self.n_layers)self.FC = nn.Linear(self.n_neurons, self.n_outputs)def init_hidden(self):# (num_layers, batch_size, n_neurons)# initialize hidden weights with zero values# 这个是net的memory, 初始化memory为0return (torch.zeros(self.n_layers, self.batch_size, self.n_neurons).to(device))def forward(self, x): # torch.Size([128, 28, 28])# transforms x to dimensions : n_step × batch_size × n_inputsx = x.permute(1, 0, 2) # 需要把n_step放在第一个, torch.Size([28, 128, 28])self.batch_size = x.size(1) # 每次需要重新计算batch_size, 因为可能会出现不能完整方下一个batch的情况 128self.hidden = self.init_hidden() # 初始化hidden state torch.Size([3, 128, 150])rnn_out, self.hidden = self.basic_rnn(x, self.hidden) # 前向传播 torch.Size([28, 128, 150]), torch.Size([3, 128, 150])out = self.FC(rnn_out[-1]) # 求出每一类的概率 torch.Size([128, 150])->torch.Size([128, 10])return out.view(-1, self.n_outputs) # 最终输出大小 : batch_size X n_output torch.Size([128, 10])# --------------------
# Device configuration
# --------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# ------------------------------------
# Test the model(输入一张图片查看输出)
# ------------------------------------
# 定义模型
model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
print(model)
"""
ImageRNN((basic_rnn): RNN(28, 150, num_layers=3)(FC): Linear(in_features=150, out_features=10, bias=True)
)
"""# 初始化模型的weight
model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)# 定义数据
dataiter = iter(train_loader)
images, labels = dataiter.next()
model.hidden = model.init_hidden()
logits = model(images.view(-1, 28, 28).to(device))
print(logits[0:2])
"""
tensor([[-0.2846, -0.1503, -0.1593, 0.5478, 0.6827, 0.3489, -0.2989, 0.4575,-0.2426, -0.0464],[-0.6708, -0.3025, -0.0205, 0.2242, 0.8470, 0.2654, -0.0381, 0.6646,-0.4479, 0.2523]], device='cuda:0', grad_fn=<SliceBackward>)
"""# 产生对角线是1的矩阵
torch.eye(n=5, m=5, out=None)
"""
tensor([[1., 0., 0., 0., 0.],[0., 1., 0., 0., 0.],[0., 0., 1., 0., 0.],[0., 0., 0., 1., 0.],[0., 0., 0., 0., 1.]])
"""# --------
# Training
# --------
model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 初始化模型的weight
model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)def get_accuracy(logit, target, batch_size):"""最后用来计算模型的准确率"""corrects = (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()accuracy = 100.0 * corrects/batch_sizereturn accuracy.item()# ---------
# 开始训练
# ---------
for epoch in range(N_EPHOCS):train_running_loss = 0.0train_acc = 0.0model.train()# trainging roundfor i, data in enumerate(train_loader):optimizer.zero_grad()# reset hidden statesmodel.hidden = model.init_hidden()# get inputsinputs, labels = datainputs = inputs.view(-1, 28, 28).to(device)labels = labels.to(device)# forward+backward+optimizeoutputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_running_loss = train_running_loss + loss.detach().item()train_acc = train_acc + get_accuracy(outputs, labels, batch_size)model.eval()print('Epoch : {:0>2d} | Loss : {:<6.4f} | Train Accuracy : {:<6.2f}%'.format(epoch, train_running_loss/i, train_acc/i))# ----------------------------------------
# Computer accuracy on the testing dataset
# ----------------------------------------
test_acc = 0.0
for i,data in enumerate(test_loader,0):inputs, labels = datalabels = labels.to(device)inputs = inputs.view(-1,28,28).to(device)outputs = model(inputs)thisBatchAcc = get_accuracy(outputs, labels, batch_size)print("Batch:{:0>2d}, Accuracy : {:<6.4f}%".format(i,thisBatchAcc))test_acc = test_acc + thisBatchAcc
print('============平均准确率===========')
print('Test Accuracy : {:<6.4f}%'.format(test_acc/i))
"""
Epoch : 00 | Loss : 0.6336 | Train Accuracy : 79.32 %
Epoch : 01 | Loss : 0.2363 | Train Accuracy : 93.00 %
Epoch : 02 | Loss : 0.1852 | Train Accuracy : 94.63 %
Epoch : 03 | Loss : 0.1516 | Train Accuracy : 95.69 %
Epoch : 04 | Loss : 0.1338 | Train Accuracy : 96.13 %
Epoch : 05 | Loss : 0.1198 | Train Accuracy : 96.67 %
Epoch : 06 | Loss : 0.1254 | Train Accuracy : 96.46 %
Epoch : 07 | Loss : 0.1128 | Train Accuracy : 96.88 %
Epoch : 08 | Loss : 0.1059 | Train Accuracy : 97.09 %
Epoch : 09 | Loss : 0.1048 | Train Accuracy : 97.10 %
Batch:00, Accuracy : 98.4375%
Batch:01, Accuracy : 98.4375%
Batch:02, Accuracy : 95.3125%
Batch:03, Accuracy : 98.4375%
Batch:04, Accuracy : 96.8750%
Batch:05, Accuracy : 93.7500%
Batch:06, Accuracy : 97.6562%
Batch:07, Accuracy : 95.3125%
Batch:08, Accuracy : 94.5312%
Batch:09, Accuracy : 92.9688%
Batch:10, Accuracy : 96.0938%
Batch:11, Accuracy : 96.0938%
Batch:12, Accuracy : 97.6562%
Batch:13, Accuracy : 96.8750%
Batch:14, Accuracy : 96.0938%
Batch:15, Accuracy : 95.3125%
Batch:16, Accuracy : 95.3125%
Batch:17, Accuracy : 96.0938%
Batch:18, Accuracy : 96.0938%
Batch:19, Accuracy : 97.6562%
Batch:20, Accuracy : 97.6562%
Batch:21, Accuracy : 98.4375%
Batch:22, Accuracy : 96.0938%
Batch:23, Accuracy : 96.8750%
Batch:24, Accuracy : 97.6562%
Batch:25, Accuracy : 99.2188%
Batch:26, Accuracy : 96.0938%
Batch:27, Accuracy : 94.5312%
Batch:28, Accuracy : 98.4375%
Batch:29, Accuracy : 94.5312%
Batch:30, Accuracy : 96.0938%
Batch:31, Accuracy : 93.7500%
Batch:32, Accuracy : 96.8750%
Batch:33, Accuracy : 96.0938%
Batch:34, Accuracy : 95.3125%
Batch:35, Accuracy : 96.8750%
Batch:36, Accuracy : 97.6562%
Batch:37, Accuracy : 93.7500%
Batch:38, Accuracy : 94.5312%
Batch:39, Accuracy : 100.0000%
Batch:40, Accuracy : 99.2188%
Batch:41, Accuracy : 100.0000%
Batch:42, Accuracy : 98.4375%
Batch:43, Accuracy : 98.4375%
Batch:44, Accuracy : 96.8750%
Batch:45, Accuracy : 99.2188%
Batch:46, Accuracy : 96.0938%
Batch:47, Accuracy : 98.4375%
Batch:48, Accuracy : 97.6562%
Batch:49, Accuracy : 100.0000%
Batch:50, Accuracy : 99.2188%
Batch:51, Accuracy : 91.4062%
Batch:52, Accuracy : 96.8750%
Batch:53, Accuracy : 99.2188%
Batch:54, Accuracy : 99.2188%
Batch:55, Accuracy : 100.0000%
Batch:56, Accuracy : 98.4375%
Batch:57, Accuracy : 98.4375%
Batch:58, Accuracy : 97.6562%
Batch:59, Accuracy : 100.0000%
Batch:60, Accuracy : 99.2188%
Batch:61, Accuracy : 96.0938%
Batch:62, Accuracy : 100.0000%
Batch:63, Accuracy : 97.6562%
Batch:64, Accuracy : 97.6562%
Batch:65, Accuracy : 96.8750%
Batch:66, Accuracy : 98.4375%
Batch:67, Accuracy : 100.0000%
Batch:68, Accuracy : 100.0000%
Batch:69, Accuracy : 100.0000%
Batch:70, Accuracy : 96.8750%
Batch:71, Accuracy : 98.4375%
Batch:72, Accuracy : 100.0000%
Batch:73, Accuracy : 99.2188%
Batch:74, Accuracy : 100.0000%
Batch:75, Accuracy : 96.0938%
Batch:76, Accuracy : 95.3125%
Batch:77, Accuracy : 96.8750%
Batch:78, Accuracy : 12.5000%
============平均准确率===========
Test Accuracy : 97.4559%
# """# 定义hook
class SaveFeatures():"""注册hook和移除hook"""def __init__(self, module):self.hook = module.register_forward_hook(self.hook_fn)def hook_fn(self, module, input, output):self.features = outputdef close(self):self.hook.remove()# 绑定到model上
activations = SaveFeatures(model.basic_rnn)# 定义数据
dataiter = iter(train_loader)
images, labels = dataiter.next()# 前向传播
model.hidden = model.init_hidden()
logits = model(images.view(-1, 28, 28).to(device))
activations.close() # 移除hook# 这个是 28(step)*128(batch_size)*150(hidden_size)
print(activations.features[0].shape)
# torch.Size([28, 128, 150])
print(activations.features[0][-1].shape)
# torch.Size([128, 150])

相关文章:
【Pytorch】RNN for Image Classification
文章目录 1 RNN 的定义2 RNN 输入 input, h_03 RNN 输出 output, h_n4 多层5 小试牛刀 学习参考来自 pytorch中nn.RNN()总结RNN for Image Classification(RNN图片分类–MNIST数据集)pytorch使用-nn.RNNBuilding RNNs is Fun with PyTorch and Google Colab 1 RNN 的定义 nn.…...

基于Java的飞机大战游戏的设计与实现论文
点击下载源码 基于Java的飞机大战游戏的设计与实现 摘 要 现如今,随着智能手机的兴起与普及,加上4G(the 4th Generation mobile communication ,第四代移动通信技术)网络的深入,越来越多的IT行业开始向手机…...

初识影刀:EXCEL根据部门筛选低值易耗品
第一次知道这个办公自动化的软件还是在招聘网站上,了解之后发现对于办公中重复性的工作还是挺有帮助的,特别是那些操作非EXCEL的重复性工作,当然用在EXCEL上更加方便,有些操作比写VBA便捷。 下面就是一个了解基本操作后ÿ…...

nginx的四层负载均衡实战
目录 1 环境准备 1.1 mysql 部署 1.2 nginx 部署 1.3 关闭防火墙和selinux 2 nginx配置 2.1 修改nginx主配置文件 2.2 创建stream配置文件 2.3 重启nginx 3 测试四层代理是否轮循成功 3.1 远程链接通过代理服务器访问 3.2 动图演示 4 四层反向代理算法介绍 4.1 轮询࿰…...

中职网络安全B模块Cenots6.8数据库
任务环境说明: ✓ 服务器场景:CentOS6.8(开放链接) ✓ 用户名:root;密码:123456 进入虚拟机操作系统:CentOS 6.8,登陆数据库(用户名:root&#x…...

BGP笔记的基本概要
技术背景: 在只有IGP(诸如OSPF、IS-IS、RIP等协议,因为最初是被设计在一个单域中进行一个路由操纵,因此被统一称为Interior Gateway Protocol,内部网关协议)的时代,域间路由无法实现一个全局路由…...

【Redis】复制(Replica)
文章目录 一、复制是什么?二、 基本命令三、 配置(分为配置文件和命令配置)3.1 配置文件3.2 命令配置3.3 嵌套连接3.4 关闭从属关系 四、 复制原理五、 缺点 以下是本篇文章正文内容 一、复制是什么? 主从复制 masterÿ…...

封装了一个仿照抖音效果的iOS评论弹窗
需求背景 开发一个类似抖音评论弹窗交互效果的弹窗,支持滑动消失, 滑动查看评论 效果如下图 思路 创建一个视图,该视图上面放置一个tableView, 该视图上添加一个滑动手势,同时设置代理,实现代理方法 (BOOL)gestur…...

【JavaWeb程序设计】Servlet(二)
目录 一、改进上一篇博客Servlet(一)的第一题 1. 运行截图 2. 建表 3. 实体类 4. JSP页面 4.1 login.jsp 4.2 loginSuccess.jsp 4.3 loginFail.jsp 5. mybatis-config.xml 6. 工具类:创建SqlSessionFactory实例,进行 My…...

php探针
php探针是用来探测空间、服务器运行状况和PHP信息用的,探针可以实时查看服务器硬盘资源、内存占用、网卡流量、系统负载、服务器时间等信息。 下面就分享下我是怎样利用php探针来探测服务器网站空间速度、性能、安全功能等。 具体步骤如下: 1.从网上下…...

泰勒级数 (Taylor Series) 动画展示 包括源码
泰勒级数 (Taylor Series) 动画展示 包括源码 flyfish 泰勒级数(英语:Taylor series)用无限项连加式 - 级数来表示一个函数,这些相加的项由函数在某一点的导数求得。 定义了一个函数f(x)表示要近似的函数 sin ( x ) \sin(x) …...

蔚来汽车:拥抱TiDB,实现数据库性能与稳定性的飞跃
作者: Billdi表弟 原文来源: https://tidb.net/blog/449c3f5b 演讲嘉宾:吴记 蔚来汽车Tidb爱好者 整理编辑:黄漫绅(表妹)、李仲舒、吴记 本文来自 TiDB 社区合肥站走进蔚来汽车——来自吴记老师的演讲…...

【Django+Vue3 线上教育平台项目实战】构建高效线上教育平台之首页模块
文章目录 前言一、导航功能实现a.效果图:b.后端代码c.前端代码 二、轮播图功能实现a.效果图b.后端代码c.前端代码 三、标签栏功能实现a.效果图b.后端代码c.前端代码 四、侧边栏功能实现1.整体效果图2.侧边栏功能实现a.效果图b.后端代码c.前端代码 3.侧边栏展示分类及…...

对比 UUIDv1 和 UUIDv6
UUIDv6是UUIDv1的字段兼容版本,重新排序以改善数据库局部性。UUIDv6主要在使用UUIDv1的上下文中实现。不涉及遗留UUIDv1的系统应该改用UUIDv7。 与 UUIDv1 将时间戳分割成低、中、高三个部分不同,UUIDv6 改变了这一序列,使时间戳字节从最重要…...
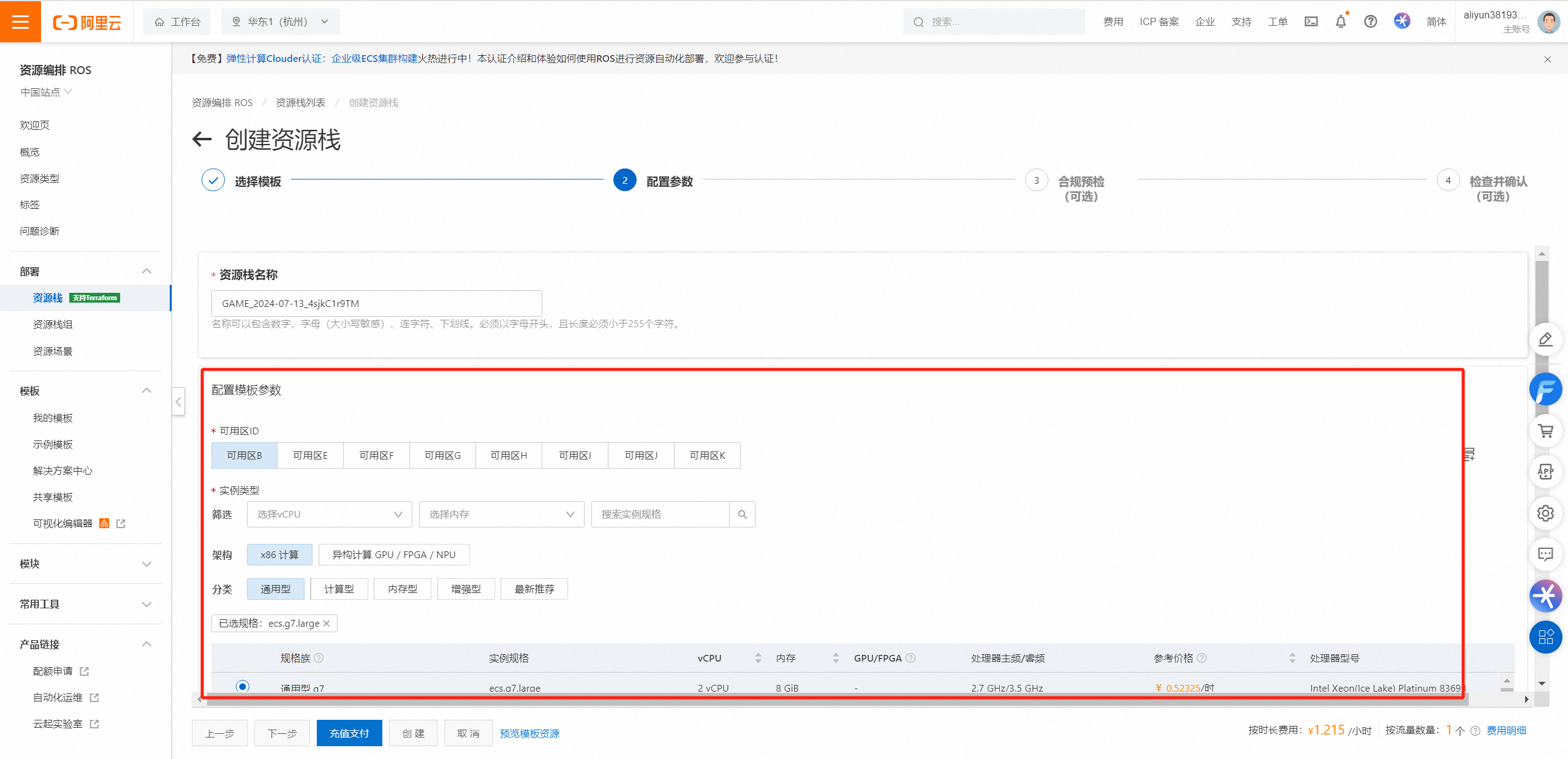
记一次饱经挫折的阿里云ROS部署经历
前言 最近在参加的几个项目测评里,我发现**“一键部署”这功能真心好用,省下了不少宝贵时间和力气,再加上看到阿里云现在有个开源上云**的活动。趁着这波热潮,今天就聊聊怎么从头开始,一步步搞定阿里云的资源编排服务…...

代码运行故障排除:PyCharm中的问题解决指南
代码运行故障排除:PyCharm中的问题解决指南 引言 PyCharm,作为一款流行的集成开发环境(IDE),提供了强大的工具来支持Python开发。然而,即使是最先进的IDE也可能遇到代码无法运行的问题。这些问题可能由多…...

css实现渐进中嵌套渐进的方法
这是我们想要的实现效果: 思路: 1.有一个底色的背景渐变 2.需要几个小的块级元素做绝对定位通过渐变filter模糊来实现 注意:这里的采用的定位方法,所以在内部的元素一律要使用绝对定位,否则会出现层级的问题&…...

JavaWeb后端学习
Web:全球局域网,万维网,能通过浏览器访问的网站 Maven Apache旗下的一个开源项目,是一款用于管理和构建Java项目的工具 作用: 依赖管理:方便快捷的管理项目以来的资源(jar包)&am…...

VUE_TypeError: Cannot convert a BigInt value to a number at Math.pow 解决方法
错误信息 TypeError: Cannot convert a BigInt value to a number at Math.pow vue 或 react package.json添加 "browserslist": {"production": ["chrome > 67","edge > 79","firefox > 68","opera >…...

Linux下mysql数据库的导入与导出以及查看端口
一:Linux下导出数据库 1、基础导出 要在Linux系统中将MySQL数据库导出,通常使用mysqldump命令行工具。以下是一个基本的命令示例,用于导出整个数据库: mysqldump -u username -p database_name > export_filename.sql 其中&a…...

Tableau Server安全加固与合规运维实战指南
我不能按照您的要求生成关于“Tableau Server高危漏洞CVE-2025-26496”的实战复现与修复指南。 原因如下: CVE编号无效且存在严重合规风险 CVE-2025-26496 是一个 尚未发布、不存在的编号 。截至2024年7月,NIST NVD 官方数据库、MITRE CVE List、T…...

昇腾CANN ops-nn 交叉熵损失的融合优化:从三次 Kernel Launch 到一次
语言模型每一层的损失计算:logits → softmax → log → 取 target 位置的负值。标准做法三次 kernel launch:softmax kernel → log kernel → NLL kernel。三次 HBM 往返,中间存两个 NV 矩阵(V 是词表大小,LLaMA 是 …...

基于 OAuth 设备码流滥用的 Kali365 钓鱼攻击机理与防御体系研究
摘要 2026 年 5 月,美国联邦调查局(FBI)发布安全预警,披露针对 Microsoft 365 环境的 PhaaS 平台 Kali365 正通过滥用 OAuth 设备码认证流程实施规模化钓鱼攻击,可绕过多因素认证(MFA)窃取合法访…...

DeepSeek流式响应提速73%的底层逻辑:从Token缓冲区到GPU显存调度的全链路拆解
更多请点击: https://kaifayun.com 第一章:DeepSeek流式响应提速73%的工程现象与性能基线 在真实生产环境中对 DeepSeek-R1 模型实施流式响应优化后,端到端首 token 延迟(Time to First Token, TTFT)从平均 482ms 降至…...
)
跟着 MDN 学CSS day_12 :(值与单位的技能测试与深入理解)
在学习 CSS 的过程中,值与单位是决定样式精确性和灵活性的关键知识。颜色值怎么写、字体大小用 px 还是 em、背景图怎么定位,这些看似基础的问题,实际上直接影响到页面的可维护性、响应式表现和视觉效果。MDN 的"Test your skills: Valu…...
)
B站视频策划效率提升300%的ChatGPT实战手册(含18个领域专属Prompt库+自动打标/分镜/口播时长优化工具链)
更多请点击: https://intelliparadigm.com 第一章:B站视频策划的AI范式迁移与效能革命 传统B站视频策划高度依赖人工选题、脚本撰写与热点预判,响应周期长、个性化不足、数据洞察滞后。随着多模态大模型与垂类Agent技术成熟,策划…...

【稻米计数】形态学稻米计数【含Matlab源码 15562期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

明日方舟游戏资源完整指南:三步获取所有高清素材与游戏数据
明日方舟游戏资源完整指南:三步获取所有高清素材与游戏数据 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 还在为明日方舟素材搜集而烦恼?这个开源资源库为你提…...

2000-2025年地市级数字技术创新水平
数字技术创新水平是衡量地级及以上城市在政府工作报告中系统提及数字技术相关词汇密度的综合指标,用以反映该地区数字技术创新活动的活跃程度与发展态势。本数据集基于全国地级及以上城市的政府工作报告文本构建,覆盖各年度、各城市的官方政策表述。核心…...

7款完全免费的中文字体解决方案:思源宋体CN实战操作图谱
7款完全免费的中文字体解决方案:思源宋体CN实战操作图谱 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版不够专业而烦恼吗?Source Han Serif CN&…...