大模型系列3--pytorch dataloader的原理
pytorch dataloader运行原理
- 1. 背景
- 2. 环境搭建
- 2.1. 安装WSL & vscode
- 2.2. 安装conda & pytorch_gpu环境 & pytorch 2.11
- 2.3 命令行验证python环境
- 2.4. vscode启用pytorch_cpu虚拟环境
- 3. 调试工具
- 3.1. vscode 断点调试
- 3.2. py-spy代码栈探测
- 3.3. gdb attach
- 3.4. 查看进程访问的系统调用
- 4. DataLoader代码分析
- 4.1. DataLoader代码示例
- 输出结果
- 4.2.
1. 背景
工作中遇到需要跟踪dataloader访问IO卡住的问题,有一个类似于IO read的堆栈的hang,需要判断是否是真的IO hang住,于是乎趁着周末仔细阅读一下dataloader的代码,了解下torch dataloader的内部原理。作为一个初学者,这个文章会比较杂一些,请各位读者谅解。
为了和linux相配套,本文拟采用WSL环境来搭建conda + torch的开发环境。
2. 环境搭建
2.1. 安装WSL & vscode
参考系列中的一篇文章:环境部署
2.2. 安装conda & pytorch_gpu环境 & pytorch 2.11
下载conda
在WSL中安装conda,通过以下命令下载sh脚本
wget https://repo.anaconda.com/archive/Anaconda3-2024.02-1-Linux-x86_64.sh
有另外一个镜像站,下载很快:https://mirrors.sustech.edu.cn/anaconda/archive/
对下载的内容进行SHA-256校验
Get-FileHash filename -Algorithm SHA256c536ddb7b4ba738bddbd4e581b29308cb332fa12ae3fa2cd66814bd735dff231

安装conda
bash Anaconda3-2024.02-1-Linux-x86_64.sh- 按照提示,填yes,设置安装目录,更新shell,随后重启WSL的terminal界面。可以看到如下图,zshrc环境已经被更新了,重启shell会默认进入到(base)环境。

创建python虚拟环境
创建python虚拟环境pytorch_cpu,并激活它
conda create --name pytorch_cpu python=3.11conda activate pytorch_cpu- 替换conda安装源,因为默认的anaconda的源实在是太慢
- https://blog.csdn.net/Xiao_Spring/article/details/109130663
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
安装2.1版本pytorch
conda install pytorch==2.1 cpuonly -c pytorch
安装pandas
conda install pandas
2.3 命令行验证python环境
准备构造一段数据:使用ChatGPT写一段代码,要求生成1-100个文件,采用pickle + gzip的模式,命名为1-100.pkl.gz,每个文件中是10个随机的kv对,k和v都是随机数字转换成的字符串。构造的代码如下:
import os
import pickle
import gzip
import random
import string# 解释代码 | 注释代码 | 生成单测 |
def generate_random_dict():random_dict = {}for _ in range(10):key = ''.join(random.choice(string.digits) for _ in range(5))value = ''.join(random.choice(string.digits) for _ in range(5))random_dict[key] = valuereturn random_dictdef generate_files():file_names = [f'{i}.pkl.gz' for i in range(1, 101)]for file_name in file_names:with gzip.open(file_name, 'wb') as f:random_dict = generate_random_dict()pickle.dump(random_dict, f)for file_name in file_names:print(file_name)if __name__ == "__main__":os.chdir("c:\\workspace\\llm\\hello_project_1\\dataset\\data\\filelist")generate_files()
运行上述代码:
python demo_gen_pkl_gz.py
输出结果如下:

2.4. vscode启用pytorch_cpu虚拟环境
vscode中启动WSL,然后打开一个python文件,点击vscode屏幕右下角的python环境,默认是/usr/bin/python,会自动提示多个python环境,选择pytorch_cpu环境,如下图所示:

打开上述python文件demo_gen_pkl_gz.py,点击右上角的三角符号,选择Run Python File,即可run此python文件。

3. 调试工具
为了更方便地进行问题跟踪,我们需要学习几种调试工具
3.1. vscode 断点调试
- 在相应的代码增加断点
- 点击右上角的
Python Debugger: Debugger using launch.json按钮 - 它会自动在断点处停下来
- 查看local和global的变量,主动添加新的监视
- 查看线程堆栈
- 单步运行或者继续或者停止均可

如果将断点放在内部库的代码,例如在gzip.open实现内部打断点,会发现断点不生效。需要在lanuch.json中增加一行配置:"justMyCode": false,就可以使得断点生效了。


3.2. py-spy代码栈探测
pip3 install py-spypy-spy dump --pid ${pid}

- 支持的一些有用的参数

3.3. gdb attach
conda install gdbapt-get install python3-dbg- gdb -p ${pid} 加载进程,即可使用各种命令进行调试

3.4. 查看进程访问的系统调用
- strace -f -p ${pid} -s 1024
4. DataLoader代码分析
4.1. DataLoader代码示例
下面是一个采用多进程来读取数据的代码,它的代码逻辑很简单。首先创建一个DataLoader结构,它传入的最关键的参数为dataset,用以从dataset数据集中读取数据;最后通过for data in dataloader:将数据从dataloader中打印出来。可以通过调整num_workers来设置是否启动后台进程进行load数据
import gzip
import os
import pickle
import random
import timeimport pandas as pd
import torch
from torch.utils.data import DataLoader, Datasetdef load_gzip_pickle(pkl_fpath):with gzip.open(pkl_fpath, "rb") as f:data = pickle.load(f)return dataclass MapDataSet(Dataset):def __init__(self, index_list_fpath):self.index_list = pd.read_csv(index_list_fpath)def __len__(self):return len(self.index_list)def __getitem__(self, idx):pkl_fpath = self.index_list.iloc[idx].tolist()[0]pkl_fpath = f"filelist/{pkl_fpath}"print("try to simulate slow io wait...")#time.sleep(10)data = load_gzip_pickle(pkl_fpath)# post processingprint("try to simulate slow data processing...")#time.sleep(10)print(pkl_fpath, ": idx:", idx, ": data:", data.keys(), ": len", len(data), ": pid:", os.getpid())return datadef get_data_loader(index_list_fpath, batch_size=1, num_workers=16):dataset = MapDataSet(index_list_fpath=index_list_fpath)return DataLoader(dataset, batch_size=batch_size, num_workers=num_workers, collate_fn=lambda batch: batch[0])def test_dataloader(index_list_fpath):batch_size = 1num_workers = 0dataloader = get_data_loader(index_list_fpath=index_list_fpath, batch_size=batch_size, num_workers=num_workers)for data in dataloader:print(data.keys(), ": len", len(data), ": pid:", os.getpid())if __name__ == "__main__":os.chdir("c:\\workspace\\llm\\hello_project_1\\dataset\\data")index_list_fpath = "filelist.csv"test_dataloader(index_list_fpath)
输出结果
try to simulate slow io wait...
try to simulate slow data processing...
filelist/1.pkl.gz : idx: 0 : data: dict_keys(['86099', '83840', '15119', '03197', '57912', '42663', '32969', '49818', '47455', '53997']) : len 10 : pid: 9724
dict_keys(['86099', '83840', '15119', '03197', '57912', '42663', '32969', '49818', '47455', '53997']) : len 10 : pid: 9724
try to simulate slow io wait...
try to simulate slow data processing...
filelist/2.pkl.gz : idx: 1 : data: dict_keys(['91534', '12121', '94084', '12699', '03382', '10877', '21595', '20303', '41507', '47594']) : len 10 : pid: 9724
dict_keys(['91534', '12121', '94084', '12699', '03382', '10877', '21595', '20303', '41507', '47594']) : len 10 : pid: 9724
try to simulate slow io wait...
try to simulate slow data processing...
filelist/3.pkl.gz : idx: 2 : data: dict_keys(['85974', '89204', '39248', '46884', '09986', '30033', '97369', '18704', '24227', '15649']) : len 10 : pid: 9724
dict_keys(['85974', '89204', '39248', '46884', '09986', '30033', '97369', '18704', '24227', '15649']) : len 10 : pid: 9724
try to simulate slow io wait...
.......
4.2.
相关文章:
大模型系列3--pytorch dataloader的原理
pytorch dataloader运行原理 1. 背景2. 环境搭建2.1. 安装WSL & vscode2.2. 安装conda & pytorch_gpu环境 & pytorch 2.112.3 命令行验证python环境2.4. vscode启用pytorch_cpu虚拟环境 3. 调试工具3.1. vscode 断点调试3.2. py-spy代码栈探测3.3. gdb attach3.4. …...

SQLServer 如何设置端口
在SQL Server中,可以通过以下步骤设置端口: 打开SQL Server配置管理器。可以在开始菜单中搜索“SQL Server配置管理器”来找到它。 在左侧导航窗格中,展开“SQL Server网络配置”节点。 选择你要配置的实例,如“SQL Server Netw…...

调整网络安全策略以适应不断升级的威胁形势
关键网络安全统计数据和趋势 当今数字时代网络安全的重要性...
9. 回文数)
(leetcode学习)9. 回文数
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。 回文数 是指正序(从左向右)和倒序(从右向左)读都是一样的整数。 例如,121 是回文,而…...
QT VTK 简单测试工程
目录 1 目录结构 2 文件源码 3 运行结果 4 报错及处理 使用编译好的VTK库进行测试 1 目录结构 2 文件源码 Pro文件 QT core guigreaterThan(QT_MAJOR_VERSION, 4): QT widgetsCONFIG c17# You can make your code fail to compile if it uses deprecated APIs. #…...
)
ES6 Generator函数的异步应用 (八)
ES6 Generator 函数的异步应用主要通过与 Promise 配合使用来实现。这种模式被称为 “thunk” 模式,它允许你编写看起来是同步的异步代码。 特性: 暂停执行:当 Generator 函数遇到 yield 表达式时,它会暂停执行,等待 …...
Navicat:打造高效数据库管理之道
1. 导言 1.1 介绍Navicat Navicat是一款功能强大的数据库管理工具,旨在帮助用户高效地管理多种类型的数据库,包括MySQL、PostgreSQL、Oracle、SQL Server等。通过Navicat,用户可以轻松地进行数据库的创建、编辑、备份、同步和调试等操作,极大地简化了数据库管理的复杂性。…...
Python和C++全球导航卫星系统和机器人姿态触觉感知二分图算法
🎯要点 🎯马尔可夫随机场网格推理学习 | 🎯二维伊辛模型四连网格模型推理 | 🎯统计物理学模型扰动与最大乘积二值反卷积 | 🎯受限玻尔兹曼机扰动和最大乘积采样 | 🎯视觉概率生成模型测试图像 dz…...
Unity 优化合集
1️⃣ 贴图优化 1. Read/Write Enable 这个属性勾选后允许你在运行时读取和写入纹理数据,这对于需要实时生成内容或者需要动态修改纹理的场合非常有用但在大部分情况下这是不必要的。如果打开这个属性,会使运行时贴图大小翻倍,内存中会额外…...

第九届MathorCup高校数学建模挑战赛-A题:基于数据驱动的城市轨道交通网络优化研究
目录 摘 要 一、 问题的提出 二、 基本假设 三、 符号说明 四、 问题分析 4.1 问题 1 的分析 4.2 问题 2 的分析 4.3 问题 3 的分析 4.4 问题 4 的分析 五、 问题 1 的模型建立与求解 5.1 问题分析 5.2 数据处理 5.2.1 数据统计 5.2.2 异常数据处理方法 5.2.3 剔除异常数据值 5…...
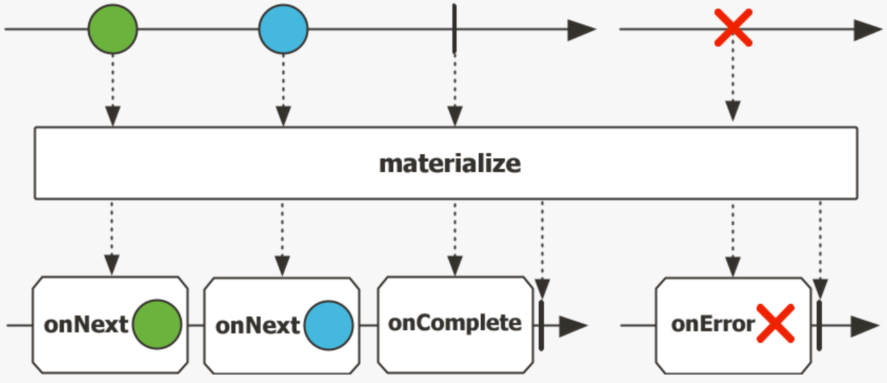
Spring webflux基础核心技术
一、 用操作符转换响应式流 1 、 映射响应式流元素 转换序列的最自然方式是将每个元素映射到一个新值。 Flux 和 Mono 给出了 map 操作符,具有 map(Function<T,R>) 签名的方法可用于逐个处理元素。 当操作符将元素的类型从 T 转变为 R 时…...
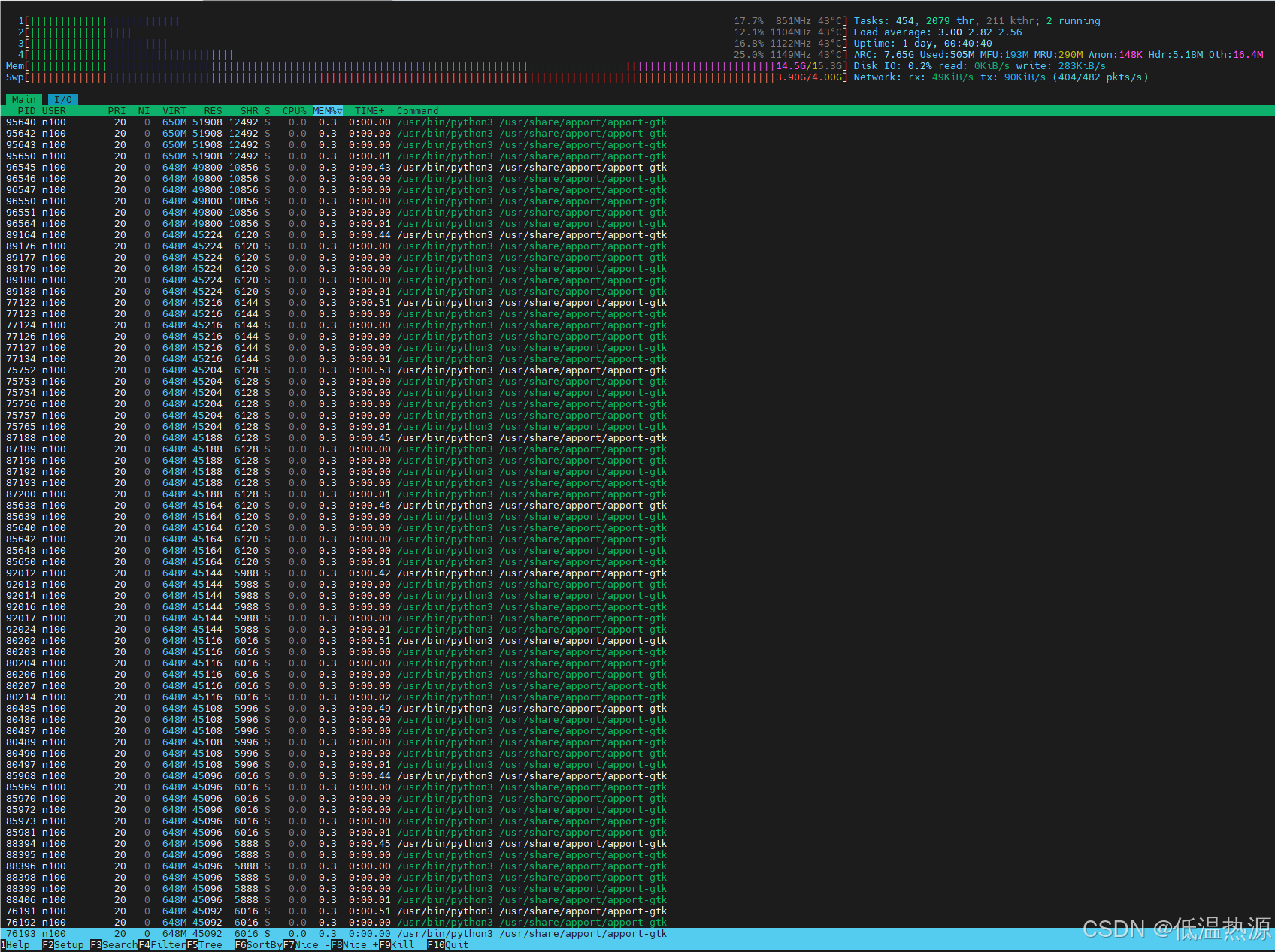
关闭Ubuntu烦人的apport
先来看让人绷不住的(恼) 我查半天apport是啥玩意发现就一错误报告弹窗,十秒钟给我弹一次一天给我内存弹爆了 就算我程序就算真的不停崩溃,也没你这傻比apport杀伤性强啊??? 原则上是不建议关闭…...

海事无人机解决方案
海事巡察 海事巡察现状 巡查效率低下,存在视野盲区,耗时长,人力成本高。 海事的职能 统一管理水上交通安全和防治船舶污染。 管理通航秩序、通航环境。负责水域的划定和监督管理,维护水 上交通秩序;核定船舶靠泊安…...

Docker--在linux安装软件
Docker 引用Docker原因是在linux中安装软件 以前在linux中安装软件,是直接安装在linux操作系统上,软件和操作系统耦合度很高,不方便管理,因为linux版本不同,环境也就改变了 docker是一种容器技术,提供标…...

知识库与RAG
认识知识库的技术原理 第一步:📖➡️📈将文档的文本转换为向量,向量存储到向量数据库。第二步:🗨️➡️🔍将用户的提问内容转换成向量,在向量数据库中检索相似的文本内容࿰…...

【2024最新】C++扫描线算法介绍+实战例题
扫描线介绍:OI-Wiki 【简单】一维扫描线(差分优化) 网上一维扫描线很少有人讲,可能认为它太简单了吧,也可能认为这应该算在差分里(事实上讲差分的文章里也几乎没有扫描线的影子)。但我认为&am…...
语言主要是一种交流工具,而不是思维工具?GPT5何去何从?
引言 在人工智能领域,特别是大语言模型(LLM)的发展中,语言和思维的关系一直是一个备受关注的话题。近期,麻省理工学院(MIT)在《Nature》杂志上发表了一篇题为《Language is primarily a tool f…...
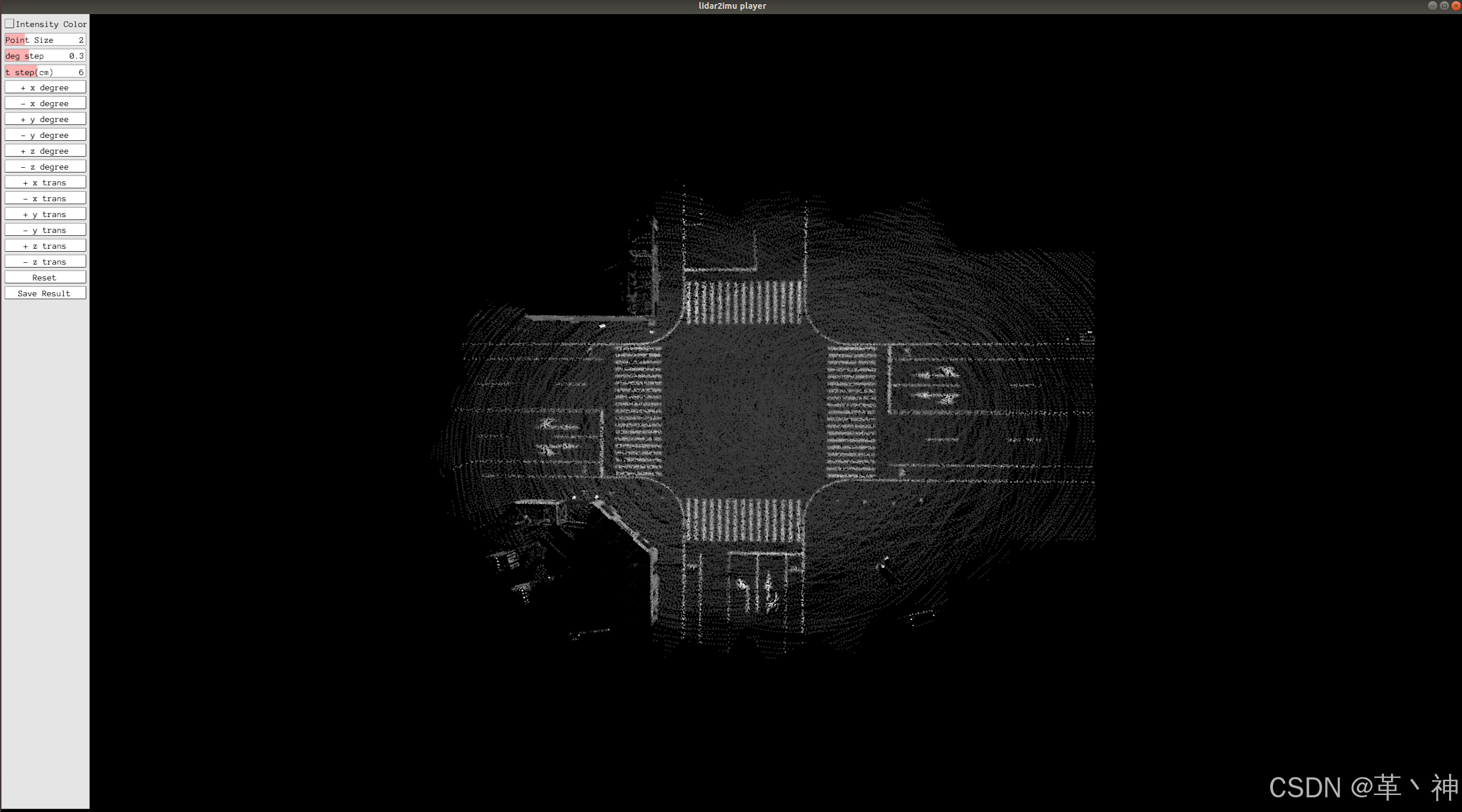
传感器标定(三)激光雷达外参标定(lidar2ins)
一、数据采集 1、LiDAR 传感器的 LiDAR PCD 数据 2、来自 IMU 传感器的姿势文件 3、手动测量传感器之间外部参数初始值并写入的 JSON 文件 二、下载标定工具 //总的git地址: https://github.com/PJLab-ADG/SensorsCalibration git地址: https://githu…...
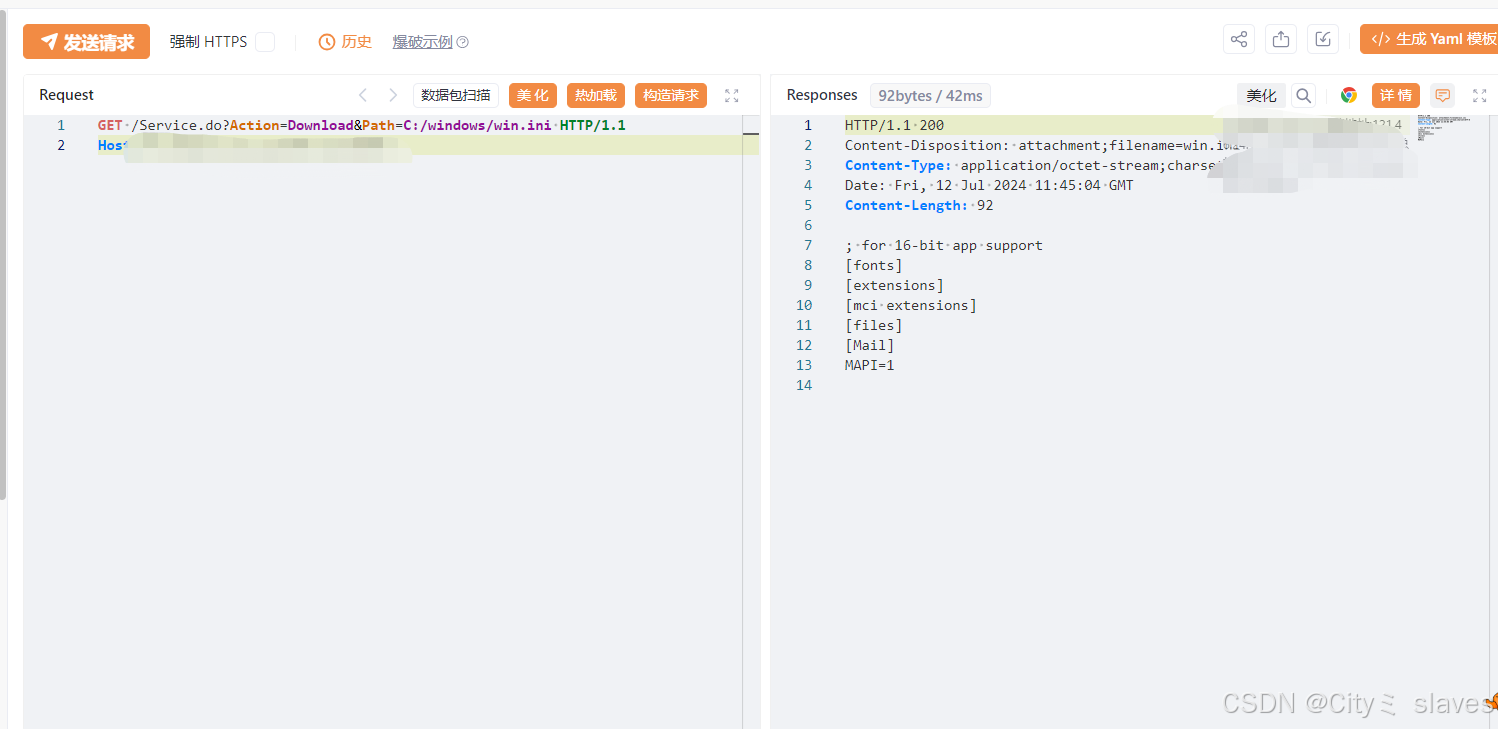
【漏洞复现】Crocus系统—Download 文件读取
声明:本文档或演示材料仅用于教育和教学目的。如果任何个人或组织利用本文档中的信息进行非法活动,将与本文档的作者或发布者无关。 一、漏洞描述 Crocus系统中的Download文件读取漏洞允许未经身份验证的攻击者通过特定请求读取系统上的任意文件。Crocu…...

游戏开发面试题1
说说对单例模式的了解 单例模式(Singleton Pattern)是一种设计模式,其目的是确保一个类只有一个实例,并提供一个全局访问点来访问该实例。这在某些情况下非常有用,比如需要一个唯一的配置管理器、日志记录器、或资源管…...

Unity离线语音识别插件:解决无网/隐私/延迟三大痛点
1. 这不是“又一个语音识别SDK”——它解决的是Unity开发者真正卡脖子的三个痛点我在2022年做一款医疗陪护类AR应用时,被语音识别拖垮过整整三个月。当时用的是某云厂商的在线SDK,结果在医院内网环境下,每次识别都要等2.3秒以上,患…...

Spring Boot + MyBatis服务启动流程,新增代码跑通流程,映射规则,常见问题定位
一、服务启动流程 零代码(仅需配置文件和依赖)。 顺序固定,由框架保证。 一旦某个步骤失败(如 XML 解析错误),整个启动失败。 二、新增代码跑通流程 全手动,需熟悉 MyBatis 映射规则、Spring…...

从数据下载到结果分析:一份给GNSS新手的GAMP+北斗PPP完整避坑指南
从零搭建北斗PPP分析环境:GAMP全流程实战与精度优化策略 刚接触GNSS精密单点定位的研究者常会遇到这样的困境:下载了数据却无法识别,编译通过程序却得不到收敛结果,最终输出的坐标误差曲线像过山车般起伏。本文将用最接地气的方式…...

五轴龙门机床厂家推荐,五轴龙门机床哪家好?
五轴龙门机床厂家推荐,五轴龙门机床哪家好?五轴龙门机床性能参数与场景适配分析。五轴龙门机床是高端装备制造的核心加工设备,广泛应用于航空航天、新能源、重工装备等领域。本文基于海天精工、纽威数控、环球工业机械、济南二机床四款主流国…...

基于DSP与SC1083 ADC的光纤远程数据采集系统设计实战
1. 项目概述:当DSP遇上高速光缆,如何构建一个“快、准、稳”的远程数据采集系统在工业自动化、电力监测、超声无损检测这些领域,我们经常需要面对一个头疼的问题:如何把现场传感器采集到的大量、高速、有时甚至是微弱的模拟信号&a…...

揭秘PSLab Web App硬件交互机制:functionList与硬件Handler工作原理
揭秘PSLab Web App硬件交互机制:functionList与硬件Handler工作原理 【免费下载链接】pslab-webapp-legacy PSLab Web App https://pslab.io 项目地址: https://gitcode.com/gh_mirrors/ps/pslab-webapp-legacy PSLab Web App是一款强大的开源硬件交互工具&a…...

PSoC4 可扩展可重构嵌入式平台:CY8C4014
简 介: 本文探讨了蓝牙音箱顶部电路板中QFN16封装芯片的型号识别过程。通过偏振光放大镜观察到芯片表面仅有"4014"字样,初步使用AI工具查询得到错误结果(LED驱动芯片IS31FL3195)。重新启动AI查询后,确认该芯…...

显卡怎么越来越贵?聊聊GPU算力背后那些事
老实说,我也难以确切记起,究竟是自哪一日起始,电脑显卡的价格便如同乘坐了火箭那般。 可能就连楼下从事修电脑工作的陈师傅都未曾想到,在过去几年的时候,还能够运用“甜品卡”这个词汇去夸赞一张显卡在性价比方面较高&…...

Xtreme Download Manager终极指南:如何实现500%下载加速
Xtreme Download Manager终极指南:如何实现500%下载加速 【免费下载链接】xdm Powerfull download accelerator and video downloader 项目地址: https://gitcode.com/gh_mirrors/xd/xdm 你是否经常遇到下载速度缓慢、视频无法保存、大文件下载中断的困扰&am…...

EXCEL文件展示MLP的计算过程
MLP 实现步骤(共 5 步) 步骤 1:输入层数据准备 在表格中输入两个特征值 x1、x2,作为 MLP 的输入。本次使用:x10.5,x20.8步骤 2:设置网络参数(权重 偏置) 手动设置输入层…...