Python应用开发——30天学习Streamlit Python包进行APP的构建(15):优化性能并为应用程序添加状态
Caching and state
优化性能并为应用程序添加状态!
Caching
缓存
Streamlit 为数据和全局资源提供了强大的缓存原语。即使从网络加载数据、处理大型数据集或执行昂贵的计算,它们也能让您的应用程序保持高性能。

本页仅包含有关 st.cache_data API 的信息。如需深入了解缓存及其使用方法,请查阅缓存。
st.cache_data
装饰器,用于缓存返回数据的函数(如数据帧转换、数据库查询、ML 推断)。
缓存对象以 "腌制 "形式存储,这意味着缓存函数的返回值必须是可腌制的。缓存函数的每个调用者都会获得自己的缓存数据副本。
您可以使用 func.clear() 清除函数的缓存,或使用 st.cache_data.clear() 清除整个缓存。
要缓存全局资源,请使用 st.cache_resource。有关缓存的更多信息,请访问 https://docs.streamlit.io/develop/concepts/architecture/caching。
| Function signature[source] | |
|---|---|
| st.cache_data(func=None, *, ttl, max_entries, show_spinner, persist, experimental_allow_widgets, hash_funcs=None) | |
| Parameters | |
| func (callable) | The function to cache. Streamlit hashes the function's source code. |
| ttl (float, timedelta, str, or None) | The maximum time to keep an entry in the cache. Can be one of:
Note that ttl will be ignored if persist="disk" or persist=True. |
| max_entries (int or None) | The maximum number of entries to keep in the cache, or None for an unbounded cache. When a new entry is added to a full cache, the oldest cached entry will be removed. Defaults to None. |
| show_spinner (bool or str) | Enable the spinner. Default is True to show a spinner when there is a "cache miss" and the cached data is being created. If string, value of show_spinner param will be used for spinner text. |
| persist ("disk", bool, or None) | Optional location to persist cached data to. Passing "disk" (or True) will persist the cached data to the local disk. None (or False) will disable persistence. The default is None. |
| experimental_allow_widgets (bool) | delete experimental_allow_widgets is deprecated and will be removed in a later version. Allow widgets to be used in the cached function. Defaults to False. Support for widgets in cached functions is currently experimental. Setting this parameter to True may lead to excessive memory use since the widget value is treated as an additional input parameter to the cache. |
| hash_funcs (dict or None) | Mapping of types or fully qualified names to hash functions. This is used to override the behavior of the hasher inside Streamlit's caching mechanism: when the hasher encounters an object, it will first check to see if its type matches a key in this dict and, if so, will use the provided function to generate a hash for it. See below for an example of how this can be used. |
代码
import streamlit as st@st.cache_data
def fetch_and_clean_data(url):# 从 URL 获取数据,然后进行清理。return datad1 = fetch_and_clean_data(DATA_URL_1)
# 实际上执行函数,因为这是第一次遇到它。d2 = fetch_and_clean_data(DATA_URL_1)
# 不执行函数。而是返回之前计算的值。这意味着现在 d1 中的数据与 d2 中的数据相同。d3 = fetch_and_clean_data(DATA_URL_2)
# 这是一个不同的 URL,因此函数会执行。这段代码是使用streamlit库来创建一个web应用程序。代码中定义了一个名为fetch_and_clean_data的函数,用于从指定的URL获取数据并进行清理处理。在函数上使用了@st.cache_data装饰器,表示对函数的结果进行缓存,以便在后续调用时可以直接返回之前计算的数值,而不必重新执行函数。
接下来,代码分别使用fetch_and_clean_data函数来获取和清理两个不同的URL所对应的数据。在第一次调用fetch_and_clean_data时,函数会执行并返回结果,并将结果缓存起来。在后续对相同URL的调用中,函数不会重新执行,而是直接返回之前缓存的结果。当传入不同的URL时,函数会重新执行以获取新的数据。
总之,这段代码展示了如何使用streamlit库来创建一个具有数据缓存功能的web应用程序,并在多次调用同一个函数时避免重复执行。
设置持续参数的命令如下:
import streamlit as st@st.cache_data(persist="disk")
def fetch_and_clean_data(url):# 从 URL 获取数据,然后进行清理。return data这段代码使用了Streamlit库,并定义了一个名为fetch_and_clean_data的函数,使用了@st.cache_data(persist="disk")装饰器。这表示该函数的结果将被缓存,并且可以选择将缓存持久化到磁盘上。
函数的作用是从指定的URL获取数据,然后对数据进行清理和处理,最后返回处理后的数据。在实际调用该函数时,如果输入的URL相同,函数将直接返回缓存中的结果,而不是重新执行获取和清理数据的操作。
默认情况下,缓存函数的所有参数都必须是散列的。任何名称以 _ 开头的参数都不会被散列。对于不可散列的参数,可以将其作为 "逃生舱口":
import streamlit as st@st.cache_data
def fetch_and_clean_data(_db_connection, num_rows):# 从 URL 获取数据,然后进行清理。return dataconnection = make_database_connection()
d1 = fetch_and_clean_data(connection, num_rows=10)
# 实际执行该函数,因为这是第一次遇到该函数。another_connection = make_database_connection()
d2 = fetch_and_clean_data(another_connection, num_rows=10)
# 不执行函数。相反,即使两次调用中的 _database_connection 参数不同,也会返回先前计算出的值。这段代码是使用Streamlit框架进行数据缓存的示例。在这段代码中,使用了`@st.cache_data`装饰器来缓存`fetch_and_clean_data`函数的结果,以便在后续调用中重复使用已经计算过的数值。
首先,通过`make_database_connection`函数建立了一个数据库连接`connection`,然后调用`fetch_and_clean_data`函数,并传入`connection`和`num_rows=10`作为参数。由于这是第一次调用该函数,因此实际执行了函数并返回了数据`d1`。
接着,又建立了另一个数据库连接`another_connection`,然后再次调用`fetch_and_clean_data`函数,并传入`another_connection`和`num_rows=10`作为参数。由于该函数的结果已经被缓存,所以这次并没有执行函数,而是直接返回之前计算过的数值,赋值给了`d2`。
这样,通过数据缓存,可以避免重复执行耗时的数据获取和清理操作,提高程序的运行效率。
缓存函数的缓存可按程序清除:
import streamlit as st@st.cache_data
def fetch_and_clean_data(_db_connection, num_rows):# 从 _db_connection 抓取数据,然后将其清理干净。return datafetch_and_clean_data.clear(_db_connection, 50)
# 清除所提供参数的缓存条目。fetch_and_clean_data.clear()
# 清除该函数的所有缓存条目。这段代码是使用Streamlit库来清除缓存数据的示例。首先,使用`@st.cache_data`装饰器来定义一个函数`fetch_and_clean_data`,该函数可以从数据库连接中获取数据并进行清理,然后返回处理后的数据。
接下来,使用`fetch_and_clean_data.clear(_db_connection, 50)`来清除使用指定参数调用函数时缓存的数据条目。这将清除使用给定数据库连接和行数调用函数时缓存的数据。
然后,使用`fetch_and_clean_data.clear()`来清除该函数的所有缓存条目,而不考虑调用时使用的参数。
这段代码展示了如何使用Strea
相关文章:
Python应用开发——30天学习Streamlit Python包进行APP的构建(15):优化性能并为应用程序添加状态
Caching and state 优化性能并为应用程序添加状态! Caching 缓存 Streamlit 为数据和全局资源提供了强大的缓存原语。即使从网络加载数据、处理大型数据集或执行昂贵的计算,它们也能让您的应用程序保持高性能。 本页仅包含有关 st.cache_data API 的信息。如需深入了解缓…...

python实现openssl的EVP_BytesToKey及AES_256_CBC加解密算法
python实现openssl EVP_BytesToKey(EVP_aes_256_cbc(), EVP_md5(), NULL, pass, passlen, 1, key, iv); 并实现AES 256 CBC加解密. # encoding:utf-8import base64 from Crypto.Cipher import AES from Crypto import Random from hashlib import md5def EVP_BytesToKey(passw…...

基于SpringBoot+VueJS+微信小程序技术的图书森林共享小程序设计与实现
注:每个学校每个老师对论文的格式要求不一样,故本论文只供参考,本论文页数达到60页以上,字数在6000及以上。 基于SpringBootVueJS微信小程序技术的图书森林共享小程序设计与实现 目录 基于SpringBootVueJS微信小程序技术的图书森…...
【css】image 使用 transform:scale 放大后显示不全的问题
css 可以用 transform: scale(1.2) 实现图片放大 1.2 倍显示的功能,在此基础上可以修改 transform-origin 为用户点击的坐标值优化体验。问题在于 origin 位于图片下方时,图片放大后出现滚动条,而滚动条的高度会忽略放大显示的图片的上半部分…...

损失函数简介
损失函数(Loss Function)是机器学习中用来衡量模型预测值与真实值之间差异的函数。在训练过程中,通过最小化损失函数来优化模型的参数,以提高模型的预测准确性。 以下是损失函数的主要用途和一些常用的损失函数类型: 损失函数的用途: 评估模型性能:损失函数提供了一个…...
2023睿抗CAIP-编程技能赛-本科组省赛(c++)
RC-u1 亚运奖牌榜 模拟 AC: #include<iostream> using namespace std; struct nation{int j,y,t; }a[2]; int main(){int n;cin>>n;for(int i1;i<n;i){int x,y;cin>>x>>y;if(y1) a[x].j;if(y2) a[x].y;if(y3) a[x].t;}cout<<a[0].j<<&…...

现在国内的ddos攻击趋势怎么样?想了解现在ddos的情况该去哪看?
目前,国内的DDoS攻击趋势显示出以下几个特征: 攻击频次显著增加:根据《快快网络2024年DDoS攻击趋势白皮书》,2023年DDoS攻击活动有显著攀升,总攻击次数达到1246.61万次,比前一年增长了18.1%。 攻击强度和规…...

微服务到底是个什么东东?
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。 每个服务运行在其独立的进程中,服务和服务间采用轻量级的通信机制互相沟通(通常是基于 HTTP 的…...

C++笔试强训5
文章目录 一、选择题1-5题6-10题 二、编程题题目一题目二 一、选择题 1-5题 x1,先x,再x–,while判断永远为真,故死循环 选D。 sizeof会计算\0,strlen不包括\0,并且strlen只计算\0之前的。 所以sizeof是10,strken是4 …...

初学51单片机之UART串口通信
CSDN其他博主的博文(自用)嵌入式学习笔记9-51单片机UART串口通信_51uart串口通讯-CSDN博客 CSDN其他博主的博文写的蛮好,如果你想了解51单片机UART串口可以点进去看看: UART全称Universal Asynchronous Receiver/Transmitter即通…...
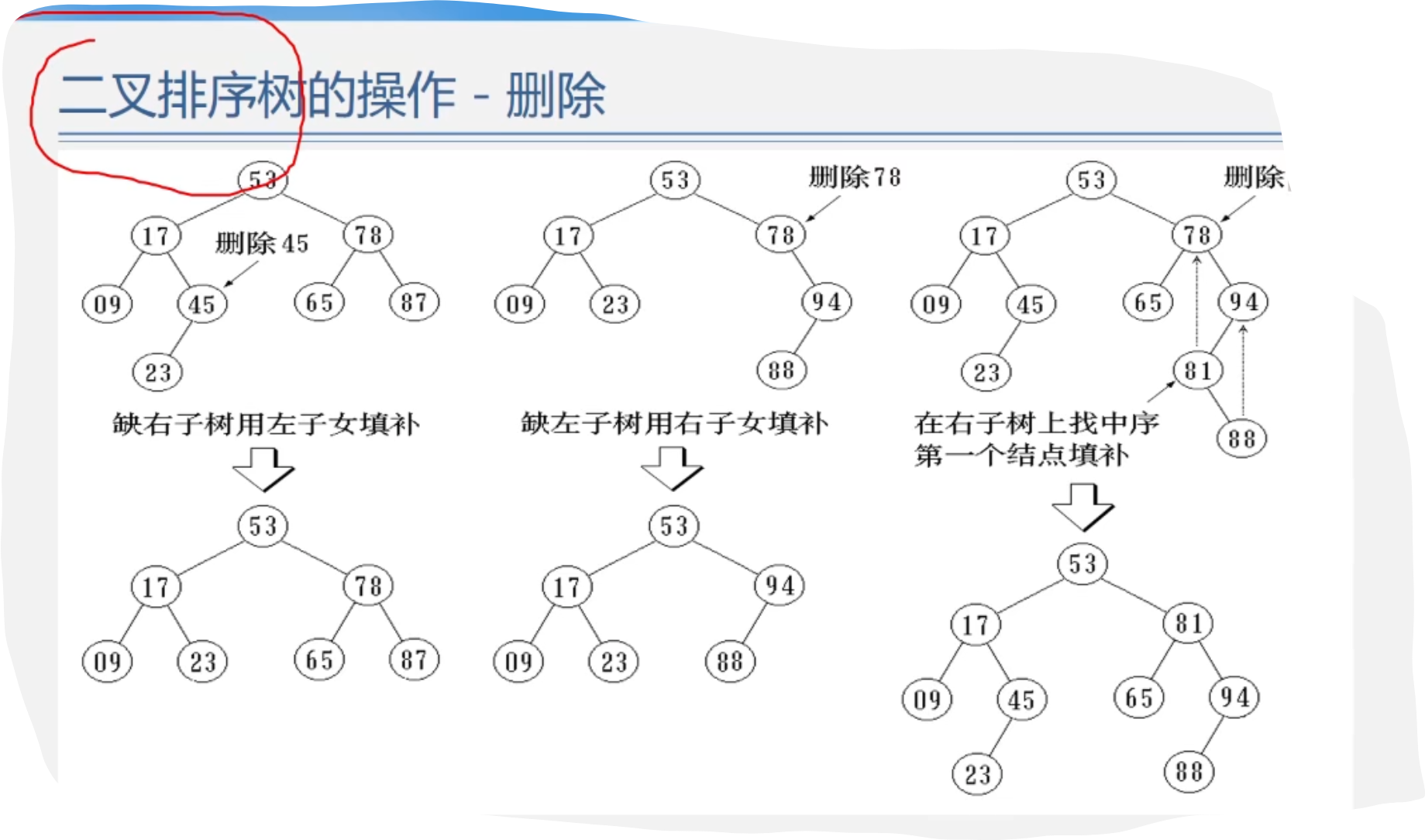
数据结构——查找(线性表的查找与树表的查找)
目录 1.查找 1.查找的基本概念 1.在哪里找? 2.什么查找? 3.查找成功与否? 4.查找的目的是什么? 5.查找表怎么分类? 6.如何评价查找算法? 7.查找的过程中我们要研究什么? 2.线性表…...

MySQL入门学习-深入索引.组合索引
在 MySQL 中,组合索引(也称为复合索引)是在多个列上创建的索引。以下是关于组合索引的详细信息: 一、组合索引的概念: - 组合索引是基于多个列创建的索引结构。它可以提高在这些列上进行查询的效率。 二、深入理解组…...

RABBITMQ的本地测试证书生成脚本
由于小程序要求必须访问wss的接口,因此需要将测试环境也切换到https,看了下官方的文档 RabbitMQ Web STOMP Plugin | RabbitMQ里面有这个信息 然后敲打GPT一阵子,把要求输入几个来回,得到这样一个脚本: generate_cer…...
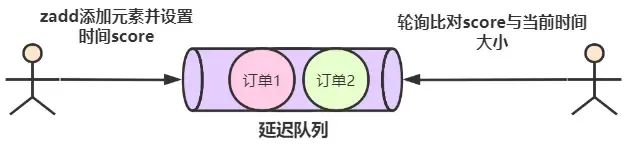
记录些Redis题集(4)
Redis 通讯协议(RESP) Redis 通讯协议(Redis Serialization Protocol,RESP)是 Redis 服务端与客户端之间进行通信的协议。它是一种二进制安全的文本协议,设计简洁且易于实现。RESP 主要用于支持客户端和服务器之间的请求响应交互…...

JVM:垃圾回收器
文章目录 一、介绍二、年轻代-Serial垃圾回收器三、老年代-SerialOld垃圾回收器四、年轻代-ParNew垃圾回收器五、老年代-CMS(Concurrent Mark Sweep)垃圾回收器六、年轻代-Parllel Scavenge垃圾回收器七、Parallel Old垃圾回收器八、G1垃圾回收器 一、介…...

Golang | Leetcode Golang题解之第228题汇总区间
题目: 题解: func summaryRanges(nums []int) (ans []string) {for i, n : 0, len(nums); i < n; {left : ifor i; i < n && nums[i-1]1 nums[i]; i {}s : strconv.Itoa(nums[left])if left < i-1 {s "->" strconv.It…...

单目3D和bev综述
文章目录 SOTA2D 检测单目3d检测3d bev cam范式1 Transformer attention is all you need 20172 ViT vision transformer ICLR 2021google3 swin transformer 2021 ICCV bestpaper MS4 DETR 20205 DETR3D 20216 PETR 20227 bevformerLSSbevdetcaddn指标 mAP NDS标注:…...

每日Attention学习11——Lightweight Dilated Bottleneck
模块出处 [TITS 23] [link] [code] Lightweight Real-Time Semantic Segmentation Network With Efficient Transformer and CNN 模块名称 Lightweight Dilated Bottleneck (LDB) 模块作用 改进的编码器块 模块结构 模块代码 import torch import torch.nn as nn import to…...

EM32DX-E4 IO 扩展模块
输入:0x6000-01 // 输入 0-15 6020H——00H IN0 计数【0~7】 ——01H IN0_SetCountMode S32 r/w 初始值默认为 0 设置 IN0 的计数方式:0 电平下 降沿,1 电平上升沿, 2 电平任意沿 ——02H IN0_Set…...

【数据结构与算法】选择排序篇----详解直接插入排序和哈希排序【图文讲解】
欢迎来到CILMY23的博客 🏆本篇主题为:【数据结构与算法】选择排序篇----详解直接插入排序和哈希排序 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏:Python | C | C语言 | 数据结构与算法 | 贪心算法 | Linux…...

瑞芯微RK3568与RK3566芯片选型指南:从接口差异到应用场景深度解析
1. 项目概述:为何要深挖这两颗“芯”?在嵌入式开发和智能硬件选型的圈子里,瑞芯微(Rockchip)的RK3568和RK3566是近两年曝光率极高的两颗“明星”芯片。很多刚接触的朋友第一眼看去,会觉得它们很像ÿ…...

通过curl命令直接调试Taotoken大模型接口的完整指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接调试Taotoken大模型接口的完整指南 对于开发者而言,直接使用curl命令调用HTTP API是一种基础且强大的…...

Taotoken用量看板如何帮助团队精确管理大模型API支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队精确管理大模型API支出 对于团队管理者而言,在大模型应用开发过程中,一个核心…...

tinychain进阶指南:如何实现区块链分叉与重组功能
tinychain进阶指南:如何实现区块链分叉与重组功能 【免费下载链接】tinychain A pocket-sized implementation of Bitcoin 项目地址: https://gitcode.com/gh_mirrors/ti/tinychain 区块链技术的核心魅力在于其去中心化的共识机制,而分叉与重组功…...

充电桩行业转型:从规模竞争到质量竞争,CCC认证锚定新赛道
过去五年,中国充电桩行业的核心叙事只有一个字:铺。谁能更快拿点位,谁能更快建站,谁能更快完成城市、县域、高速、社区的覆盖,谁就有资格坐上牌桌。功率数字不断攀升,铺设数量不断刷新,市场份额…...

从分钟到秒级:我们用 Fluss + Paimon 替换掉 Kafka + Iceberg,实时宽表终于不用 Flink 死扛了
从分钟到秒级:我们用 Fluss Paimon 替换掉 Kafka Iceberg,实时宽表终于不用 Flink 死扛了 📅 更新于 2026-05-21 | 🏷️ Fluss Paimon 湖流一体 实时数仓 架构升级 摘要:上一代湖仓一体架构中,Kafka …...

如何通过Play Integrity API完整检测Android设备安全状态
如何通过Play Integrity API完整检测Android设备安全状态 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-app 在移动应用生…...

如何利用Chanlun-Pro实现智能缠论量化交易:3步掌握市场结构识别
如何利用Chanlun-Pro实现智能缠论量化交易:3步掌握市场结构识别 【免费下载链接】chanlun-pro 基于缠中说禅所讲缠论理论,以便量化分析市场行情的工具 项目地址: https://gitcode.com/gh_mirrors/ch/chanlun-pro 在金融市场日益复杂的今天&#x…...

FactoryBluePrints项目深度解析:戴森球计划终极工厂蓝图优化指南
FactoryBluePrints项目深度解析:戴森球计划终极工厂蓝图优化指南 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints FactoryBluePrints项目是戴森球计划游戏中最为…...

第P5周:Pytorch实现运动鞋识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 个人体悟:今天学习了动态学习率有种豁然开朗的感觉,在引入该部分之后模型的学习速度和学习质量都得到了较大提升!...